Elasticsearch:创建一个定制的 DeepSeek 嵌入推理端点
今天很高兴阅读了同事写的文章 “Elasticsearch 推理 API 增加了开放的可定制服务”。我马上就想到了如何把它应用到 DeepSeek 中。这是因为截止目前为止,我们还没有为 DeepSeek 做任何的推理端点 API 的创建。
创建 DeepSeek 服务
我们可以仿照之前的文章 “Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用”。我们使用 Ollama 来部署自己的 DeepSeek。等我们部署完毕后,我们可以通过如下的方式来检验我的安装是否成功:
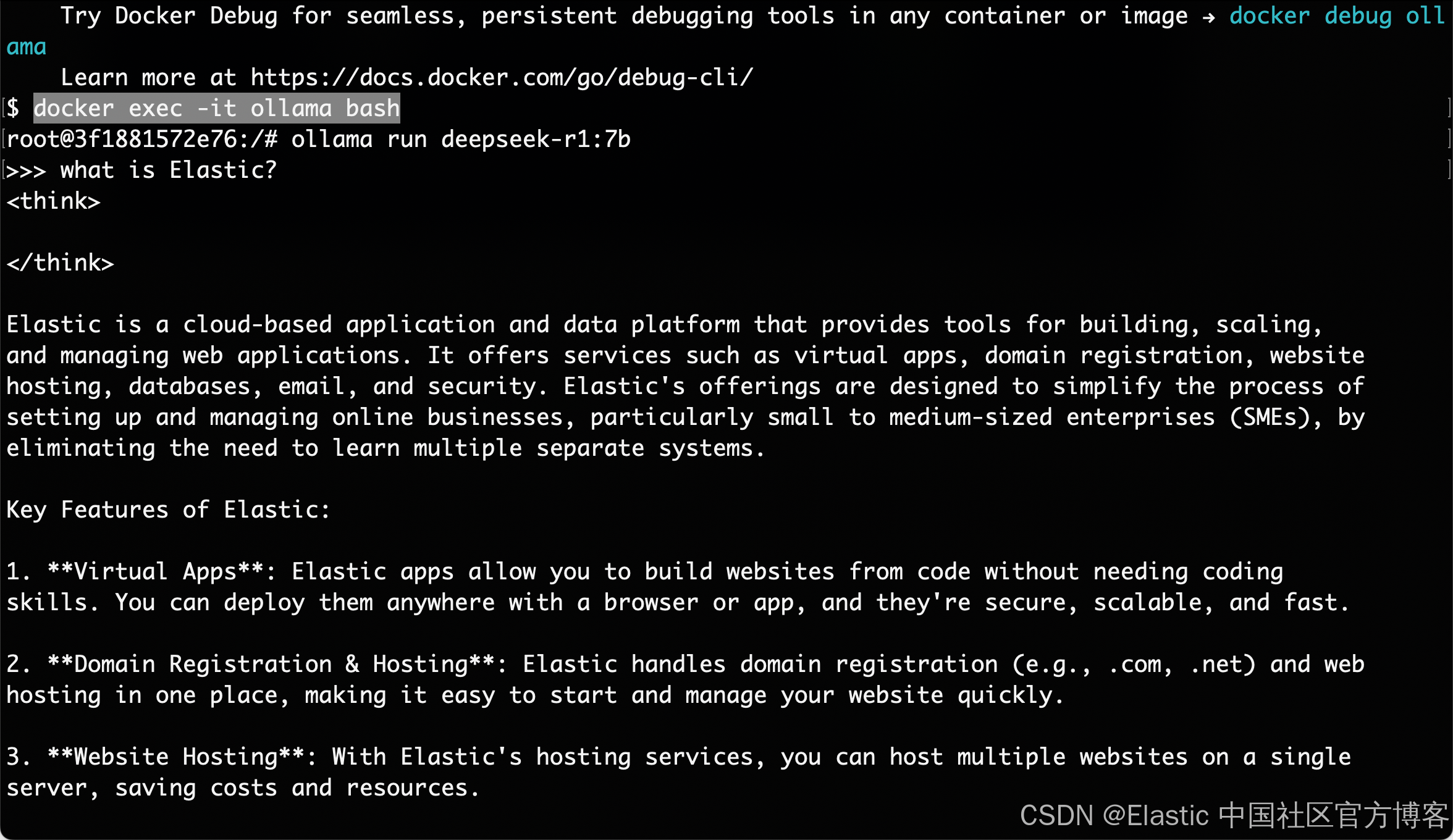
从上面的输出中,我们可以看到我们的 DeepSeek 的部署是成功的。
通过 CURL 命令来测试我们的嵌入输出
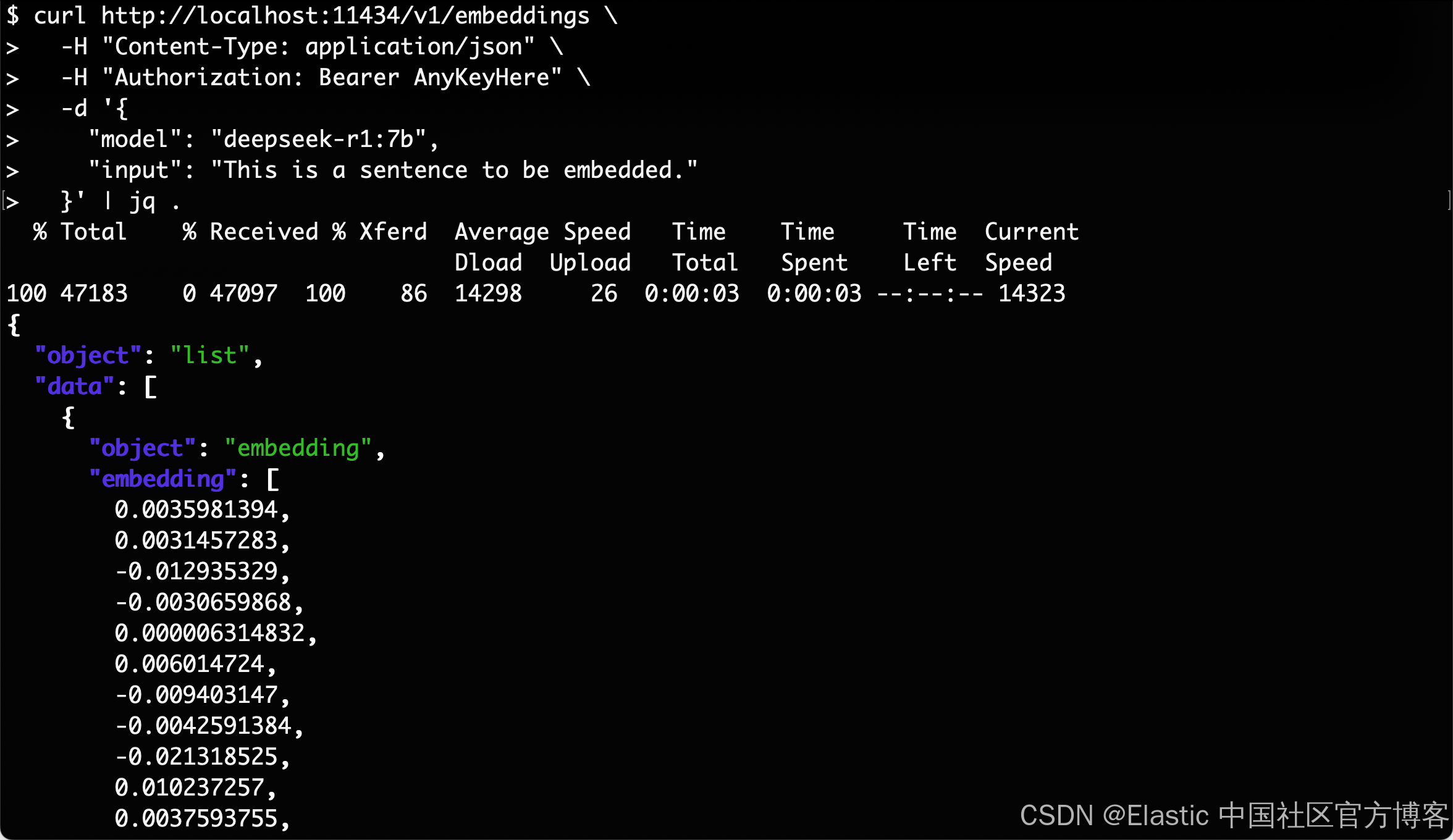
我们在 terminal 中打入如下的命令:
curl http://localhost:11434/v1/embeddings \-H "Content-Type: application/json" \-H "Authorization: Bearer AnyKeyHere" \-d '{"model": "deepseek-r1:7b","input": "This is a sentence to be embedded."}'| jq .我们可以看到如下的输出:
创建自己的嵌入端点
根据上面的输出,也参考我们的文章 “Elasticsearch 推理 API 增加了开放的可定制服务”,我们设计出如下的 endpoint API:
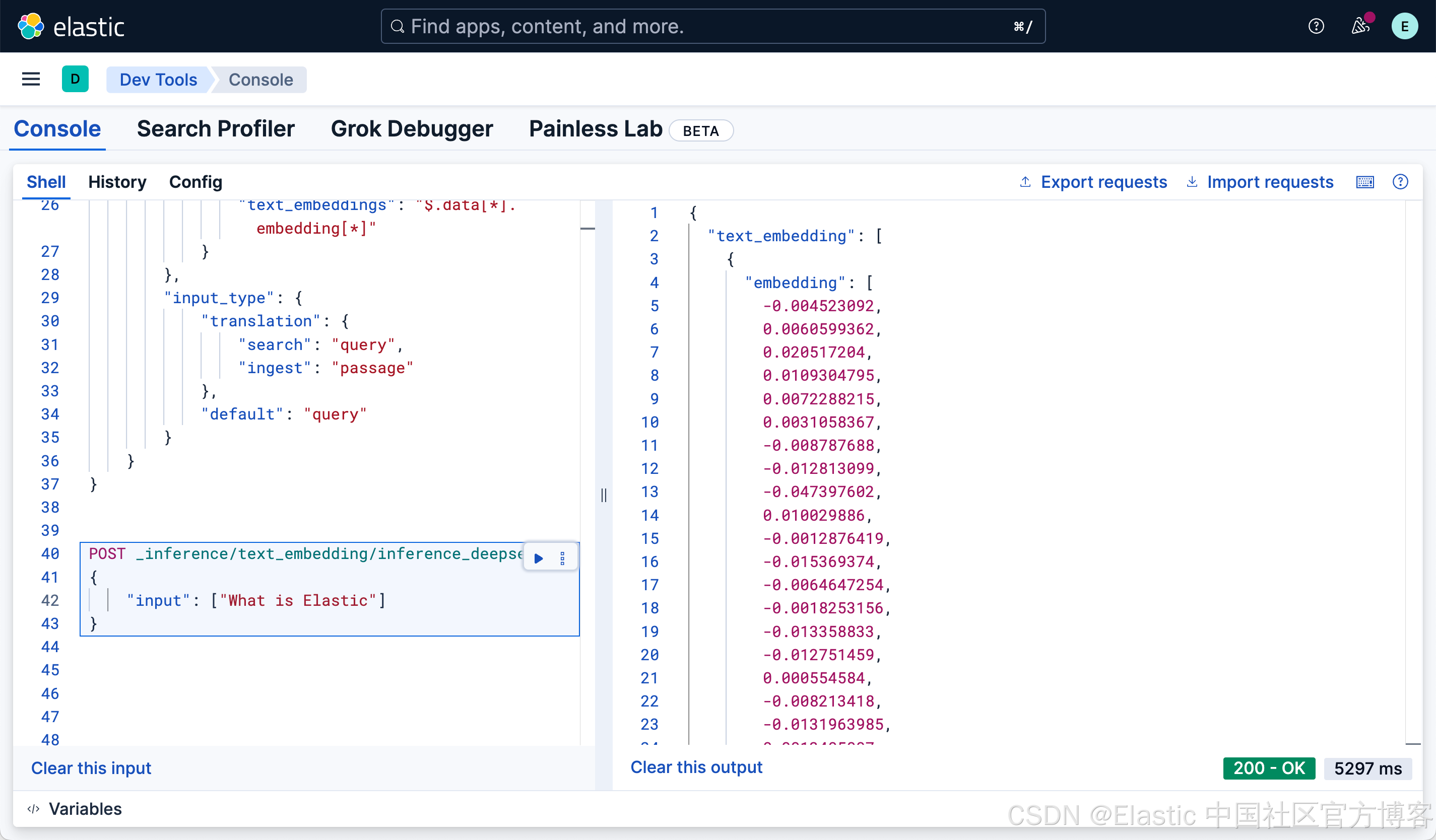
PUT _inference/text_embedding/inference_deepseek
{"service": "custom","service_settings": {"secret_parameters": {"api_key": "AnyKeyHere"},"url": "http://localhost:11434/v1/embeddings","headers": {"Authorization": "Bearer ${api_key}","Content-Type": "application/json"},"request": "{ \"model\": \"deepseek-r1:7b\",\"input\": ${input}}","response": {"json_parser": {"text_embeddings": "$.data[*].embedding[*]"}},"input_type": {"translation": {"search": "query","ingest": "passage"},"default": "query"}}
}运行完上面命令后,我们可以使用如下的命令来进行检验:
POST _inference/text_embedding/inference_deepseek
{"input": ["What is Elastic"]
}
这样我们就完成了我们的 DeepSeek 嵌入模型的 endpoint 设计。
定制 chat completion endpoint
按照同样的机制,我们来定制一个专为 DeepSeek 的 chat completion 推理端点:
PUT _inference/completion/inference_deepseek_chat
{"service": "custom","service_settings": {"secret_parameters": {"api_key": "AnyKeyHere"},"url": "http://localhost:11434/api/generate","headers": {"Authorization": "Bearer ${api_key}","Content-Type": "application/json"},"request": "{ \"model\": \"deepseek-r1:7b\", \"stream\": false, \"prompt\": ${input} }","response": {"json_parser": {"completion_result": "$.response"}},"input_type": {"default": "input"}}
}我们想在 Kibana 中进行测试。由于我们的 Kibana 在默认的情况下,如果一个请求超过 30s 还没有完成的话,那么它就会自动地 timeout,即便你在 API 中有设置 timeout 的值超过 30s。为此,我们在 config/kibana.yml 中加入如下的语句:
elasticsearch.requestTimeout: 180000也就是说超过 180s,才会 timeout。这样我们在 Kibana 中发出如下的命令:
POST /_inference/completion/inference_deepseek_chat?timeout=180s
{"input": "System: You are a helpful assistant.\nUser: Tell me about Elasticsearch Inference Service."
}注意:在生产环境中千万不要设置这么大的 timeout 值。
我们可以看到如下的结果: