大型语言模型(LLM)文本中提取结构化信息:LangExtract(一)
文章目录
- 1 简介
- 1.1 安装
- 1.2 API KEY以及所支持的大模型
- 1.3 快速开始
- 1.4 并行化处理较长文档
- 1.5 定义ExampleData
- 1.5.1 GeminiSchema:高级结构化输出
- 1.5.2 基本命名实体识别
- 1.5.2 复杂关系提取
- 1.6 HTML无法展示
- 2 扩展功能
- 2.1 如何运行本地大模型Ollama
- 2.2 文本分块策略chunking
- 2.3 提示词生成与模板管理
- 2.4 模型推理与批处理
- 2.5 输出解析与对齐
- 2.6 顺序提取轮次
- 2.7 进度跟踪与调试
- 3 具体案例代码
- 3.1 使用qwen进行中文抽取
- 3.2 大众点评内容抽取-示例
1 简介
LangExtract 通过几项解决现实世界挑战的关键创新,在众多文本提取工具中脱颖而出:
- 精确的来源定位:每次提取都会映射到其在源文本中的确切位置,支持可视化高亮,便于追溯和验证。这意味着您总能看到每条信息的出处,使验证过程简单明了。
- 可靠的结构化输出:该库根据您的少量示例强制执行一致的输出架构,并利用 Gemini 等受支持模型中的可控生成来保证稳健、结构化的结果。这消除了原始 LLM 输出中常见的猜测和不一致性。
- 为长文档优化:LangExtract 通过文本分块、并行处理和多轮提取的优化策略,克服了大文档提取中“大海捞针”的难题。它能以同等的精度处理从短段落到整本小说的所有内容。
- 交互式可视化:即时生成独立的交互式 HTML 文件,在其原始上下文中可视化和审查数千个提取的实体。这使得大规模探索和验证结果变得轻而易举。
- 灵活的 LLM 支持:使用您偏好的模型,从云端 LLM(如 Google Gemini 系列)到通过内置 Ollama 接口使用的本地开源模型。其插件架构让添加对新提供商的支持变得简单。
- 领域适应性:仅需几个示例即可为任何领域定义提取任务。LangExtract 能适应您的需求,无需任何模型微调,使其易于用于专业用例。
github地址:
https://github.com/google/langextract
1.1 安装
pip install langextract
对于开发工作,您可以从源代码安装:
git clone https://github.com/google/langextract.git
cd langextract
pip install -e .
1.2 API KEY以及所支持的大模型
这里官方是gemini,
需要一个 API 密钥。将其设置为环境变量:
export LANGEXTRACT_API_KEY="your-api-key"
当然也可以使用其他大模型,通过openai的接口就可以实现:
# 第一种:factory的方式
from langextract import factory, visualization config = factory.ModelConfig(model_id="qwen",provider="OpenAILanguageModel",provider_kwargs={'api_key': "sk-bb",'base_url': 'url'}
)
model = factory.create_model(config)# 第二种:直接模型
from langextract.providers.openai import OpenAILanguageModel
model = OpenAILanguageModel(model_id='qwen-plus',base_url='https://dashscope.aliyuncs.com/compatible-mode/v1',api_key=apikey)
1.3 快速开始
import langextract as lx
import textwrapprompt = textwrap.dedent("""\按出现顺序提取人物、情感和关系。使用精确的文本进行提取。不要进行释义或使实体重叠。为每个实体提供有意义的属性以增加上下文信息。""")# 提供一个高质量的示例来指导模型
examples = [lx.data.ExampleData(text="ROMEO. 但是轻!什么光从那边的窗户透进来?那是东方,朱丽叶就是太阳。",extractions=[lx.data.Extraction(extraction_class="character",extraction_text="ROMEO",attributes={"emotional_state": "wonder"}),lx.data.Extraction(extraction_class="emotion",extraction_text="但是轻!",attributes={"feeling": "gentle awe"}),lx.data.Extraction(extraction_class="relationship",extraction_text="朱丽叶就是太阳",attributes={"type": "metaphor"}),])
]# 待处理的输入文本
input_text = "朱丽叶女士深情地凝望着星空,内心为罗密欧而痛苦"# 运行提取
result = lx.extract(text_or_documents=input_text,prompt_description=prompt,examples=examples,model_id="gemini-2.5-flash",
)# 将结果保存到 JSONL 文件
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl", output_dir=".")# 从文件生成可视化
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:if hasattr(html_content, 'data'):f.write(html_content.data) # 适用于 Jupyter/Colabelse:f.write(html_content)说明:
- 创建一个清晰的提示词,明确告诉 LLM 要提取什么
- 提供一个示例,展示预期的输出格式,ExampleData 类包含输入文本和预期的提取结果,而每个 Extraction 对象则指定要提取的内容(人物、情感、关系)、要提取的确切文本以及相关属性。
- 使用结构化数据类来定义提取模式
- result 对象是一个 AnnotatedDocument,包含在您的文本中找到的所有提取结果,并通过精确的字符位置显示每个提取结果的来源。
1.4 并行化处理较长文档
LangExtract 在处理较长文档时才能真正发挥其优势。以下是如何以更高的准确性处理整本书的方法:
# 直接从古腾堡计划处理《罗密欧与朱丽叶》
result = lx.extract(text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",prompt_description=prompt,examples=examples,model_id="gemini-2.5-flash",extraction_passes=3, # 通过多次遍历提高召回率max_workers=20, # 并行处理以提高速度max_char_buffer=1000 # 使用更小的上下文以提高准确性
)
扩展规模的关键参数:
- extraction_passes:运行多个提取周期以查找更多实体(会增加 API 成本)
- max_workers:启用并行处理以更快获得结果
- max_char_buffer:控制分块大小,以便在长文本上获得更好的准确性
1.5 定义ExampleData
LangExtract 中的模式通常从示例数据构建,这些数据展示了您希望模型遵循的结构。ExampleData 类封装输入文本及预期的提取结果:
from langextract.core import data# 创建包含药物提取的示例数据
example = data.ExampleData(text="患者口服 400 毫克布洛芬,每四小时一次,持续两天。",extractions=[data.Extraction(extraction_class="dosage",extraction_text="400 mg"),data.Extraction(extraction_class="route", extraction_text="PO"),data.Extraction(extraction_class="medication",extraction_text="Ibuprofen")]
)
1.5.1 GeminiSchema:高级结构化输出
对于支持结构化输出的提供商(如 Google 的 Gemini),GeminiSchema 通过将示例转换为 JSON Schema 定义提供强大的字段级验证:
from langextract.providers.schemas import gemini
from langextract.core import data# 创建带属性的示例
examples = [data.ExampleData(text="患者患有糖尿病。",extractions=[data.Extraction(extraction_class="condition",extraction_text="diabetes",attributes={"chronicity": "chronic"})])
]# 从示例构建模式
gemini_schema = gemini.GeminiSchema.from_examples(examples)# 获取生成的 JSON 模式
schema_dict = gemini_schema.schema_dict
print(schema_dict)
# {
# "type": "object",
# "properties": {
# "extractions": {
# "type": "array",
# "items": {
# "type": "object",
# "properties": {
# "condition": {"type": "string"},
# "condition_attributes": {
# "type": "object",
# "properties": {
# "chronicity": {"type": "string"}
# },
# "nullable": True
# }
# }
# }
# }
# },
# "required": ["extractions"]
# }# 转换为提供商配置
provider_config = gemini_schema.to_provider_config()
# 返回:{
# "response_schema": {...},
# "response_mime_type": "application/json"
# }
1.5.2 基本命名实体识别
最常见的:
examples = [data.ExampleData(text="患者给予 250 毫克静脉注射头孢唑林,每日三次。",extractions=[data.Extraction(extraction_class="dosage", extraction_text="250 mg"),data.Extraction(extraction_class="route", extraction_text="IV"),data.Extraction(extraction_class="medication", extraction_text="Cefazolin"),data.Extraction(extraction_class="frequency", extraction_text="TID")])
]schema = gemini.GeminiSchema.from_examples(examples)
1.5.2 复杂关系提取
用于提取带属性的关联实体:
examples = [data.ExampleData(text="患者每日服用 100 毫克阿司匹林以维护心脏健康。",extractions=[data.Extraction(extraction_class="medication",extraction_text="Aspirin",attributes={"medication_group": "Aspirin"}),data.Extraction(extraction_class="dosage",extraction_text="100mg", attributes={"medication_group": "Aspirin"}),data.Extraction(extraction_class="frequency",extraction_text="daily",attributes={"medication_group": "Aspirin"})])
]schema = gemini.GeminiSchema.from_examples(examples)
1.6 HTML无法展示
No valid extractions to animate.,
HTML无法展示且报错
原因:
只有当 extraction.char_interval 存在且其 start_pos 和 end_pos 都不是 None 时,才被视为有效。
所以出现 char_interval: None 表明你的 extraction 数据里没有字符区间(char_interval),或者 JSON/字典加载时该字段为 null/缺失,导致所有 extraction 都被过滤掉,最终没有可播放的高亮项,HTML 就只会显示那个提示。
修复的办法:
- 最直接:如果你能确定文本唯一出现位置,自动填充 char_interval
- 如果精确匹配失败,尝试常用文本正规化
2 扩展功能
2.1 如何运行本地大模型Ollama
Ollama 示例展示了如何使用本地托管的语言模型运行 LangExtract。这对于希望在不依赖云 API 的情况下进行实验,或需要在本地处理敏感数据的用户来说是理想选择。
运行 Ollama 示例前,您需要安装并设置 Ollama:
# 拉取推荐模型
ollama pull gemma2:2b
您有两种便捷方式运行 Ollama 示例:
方式 1:本地执行
# 进入 ollama 示例目录
cd examples/ollama# 在单独的终端中启动 Ollama
ollama serve# 运行演示脚本
python demo_ollama.py
方式 2:Docker 执行
如需完全容器化的体验,请使用 Docker Compose:
# 进入 ollama 示例目录
cd examples/ollama# 这将拉取模型并运行所有服务
docker-compose up
对于较慢的模型或大型提示词,您可能需要增加超时时间:
import langextract as lxresult = lx.extract(text_or_documents=input_text,prompt_description=prompt,examples=examples,model_id="llama3.1:70b", # 较大模型可能需要更多时间timeout=300, # 5 分钟model_url="http://localhost:11434",
)
2.2 文本分块策略chunking
在进行任何提取之前,必须将大型文档分解为适合 LLM 上下文窗口的小型可管理分块。
chunk_iter = chunking.ChunkIterator(text=large_document_text,max_char_buffer=1000, # 每个分块的最大字符数document=document
)
分块策略十分精密——尽可能尊重句子边界,在换行处分割以保持可读性,并能处理超出缓冲区大小的单个词元。这既确保了文本语义的保存,又使其能被 LLM 有效处理。
2.3 提示词生成与模板管理
文本分块后,管道会为 LLM 生成适当的提示词。
prompt_template = prompting.PromptTemplateStructured(description="提取医学实体及其属性"
)
prompt_template.examples.extend(examples) # 添加少样本示例
提示词生成系统设计灵活,根据提供的示例支持少样本学习和零样本提取。
2.4 模型推理与批处理
Annotator 类协调整个推理过程。它通过批处理最大化效率,同时将多个分块发送给 LLM:
batch_scored_outputs = self._language_model.infer(batch_prompts=batch_prompts,**kwargs,
)
批处理对性能至关重要——batch_length 参数控制同时处理的分块数量,而 max_workers 决定并行度。这种设计使管道能够跨不同硬件和 API 速率限制高效扩展。
2.5 输出解析与对齐
LLM 生成响应后,resolver.py中的 Resolver 类接管结果解析和对齐工作。该组件负责:
- 从 LLM 响应中解析结构化输出(JSON/YAML)
- 将提取的实体对齐回源文本的原始位置
- 处理部分匹配和模糊对齐等边缘情况
aligned_extractions = resolver.align(annotated_chunk_extractions,chunk_text,token_offset,char_offset,**kwargs,
)
2.6 顺序提取轮次
管道最强大的功能之一是支持顺序提取轮次,由 extraction_passes 参数控制。当设置大于 1 时,管道会执行多次独立提取尝试并合并非重叠结果:
# 执行 3 轮提取以提高召回率
extracted_data = extract(text_or_documents=text,examples=examples,extraction_passes=3, # 多轮次提高召回率# ... 其他参数
)
2.7 进度跟踪与调试
管道通过 progress 模块提供全面的进度跟踪,在提取过程中显示实时反馈:
progress_bar = progress.create_extraction_progress_bar(batches, model_info=model_info, disable=not show_progress
)
调试模式提供函数调用、参数、返回值和计时信息的详细日志,便于开发过程中排查问题。
3 具体案例代码
3.1 使用qwen进行中文抽取
主要参考:LangExtract 学习
这里将代码简单优化后贴过来,笔者针对个别代码,
是有过微调的,
笔者使用的langextract版本为:Version: 1.0.6
import langextract as lx
import textwrap
import json
import os
import traceback
from langextract.data import ExampleData, Extraction
from langextract import extract
from langextract import factory, visualization
from langextract.providers.openai import OpenAILanguageModel# 1. Define the prompt and extraction rules
prompt = textwrap.dedent("""Extract names and theories from wikipedia.Use exact text for extractions. Do not paraphrase or overlap entities.Provide meaningful and summarized attributes for each entity to add context.Use Chinese for all attributes."""
)# 2. Provide a high-quality example to guide the model
examples = [lx.data.ExampleData(text="""2018年全市平均降水量为590毫米,与2017年降水量592毫米基本持平,比多年平均值585毫米多1%""",extractions=[lx.data.Extraction(extraction_class="时间",extraction_text="2018",),lx.data.Extraction(extraction_class="数据名称",extraction_text="平均降水量",),lx.data.Extraction(extraction_class="数值",extraction_text="590毫米",),],),
]input_text = """
2024 年全市降水量 782mm,比 2023 年降水量 727mm 多 7.6%,比多年平均值 569mm 多 37.4%。
全市地表水资源量 24.50 亿 m3,地下水与地表水资源不重复量 28.39 亿 m3,水资源总量 52.89 亿 m3,比多年平均 27.35 亿 m3多 93.4%。
"""apikey = 'sk-12345678910'
model = OpenAILanguageModel(model_id='qwen-plus',base_url='https://dashscope.aliyuncs.com/compatible-mode/v1',api_key=apikey)# 6. 运行提取
result = extract(text_or_documents=input_text,prompt_description=prompt,examples=examples,model=model
)print(f"✔️ 提取完成!共提取 {len(result.extractions)} 个实体")# 7. 检查char_interval及提取结果详情
print("\n提取结果详情:")
for i, extraction in enumerate(result.extractions, 1):print(f" {i}. '{extraction.extraction_text}' [{extraction.extraction_class}]")print(f" char_interval: {extraction.char_interval}")print(f" alignment_status: {extraction.alignment_status}")if extraction.attributes:for key, value in extraction.attributes.items():print(f" {key}: {value}")print()# 8. 保存结果
lx.io.save_annotated_documents([result], output_name="official_test_results.jsonl", output_dir=".")
print("✔️ 结果已保存到: official_test_results.jsonl")# 9. 生成可视化
print("\n生成可视化...")
html_content = visualization.visualize("official_test_results.jsonl")
# 保存HTML文件
with open("official_test_visualization.html", "w", encoding="utf-8") as f:f.write(html_content.data)
print("✔️ 可视化已保存到: official_test_visualization.html")笔者这里通过OpenAILanguageModel使用的是qwen模型;
同时没有修改中文配置,也可以进行分析与HTML显示
笔者是可以直接运行,并得到:
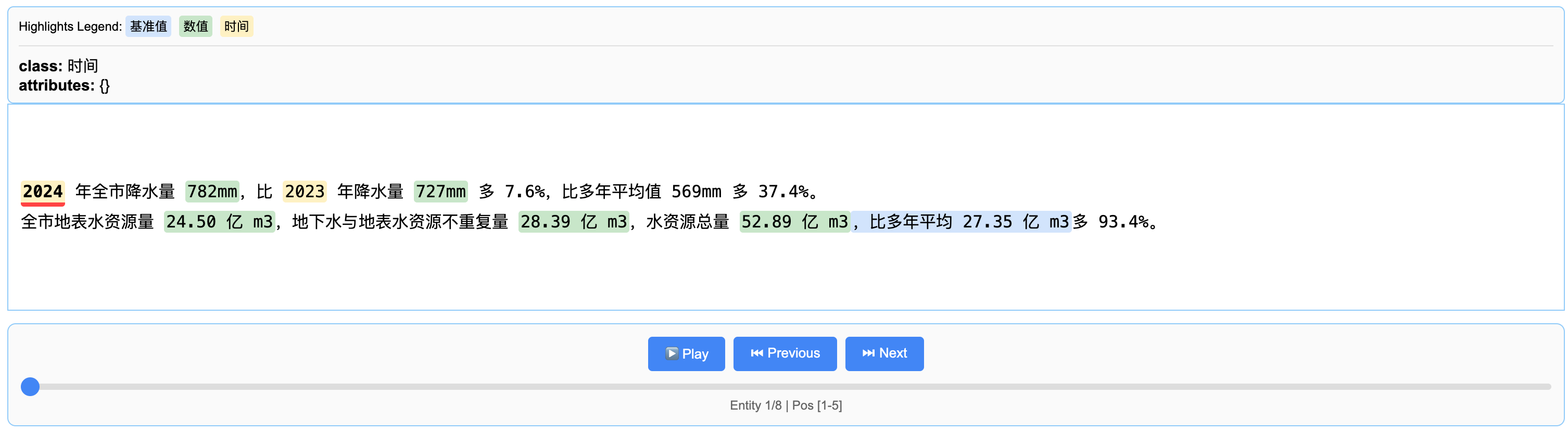
3.2 大众点评内容抽取-示例
import langextract as lx
import textwrap
import random
from langextract.providers.openai import OpenAILanguageModel# 1. 随机生成中文评论
def generate_random_chinese_review():restaurants = ["海底捞", "西贝莜面村", "外婆家", "小龙坎", "肯德基"]dishes = ["火锅", "烤肉", "酸菜鱼", "麻辣烫", "炸鸡"]adjectives = ["好吃", "美味", "棒", "赞", "一般", "差"]feelings = ["非常满意", "满意", "还行", "不满意", "很失望"]review_templates = [f"{random.choice(restaurants)}的{random.choice(dishes)}{random.choice(adjectives)},{random.choice(feelings)}!",f"今天去了{random.choice(restaurants)},点了{random.choice(dishes)},味道{random.choice(adjectives)},服务{random.choice(feelings)}。",f"推荐{random.choice(restaurants)}的{random.choice(dishes)},简直是{random.choice(adjectives)}到爆!",f"对{random.choice(restaurants)}有点失望,{random.choice(dishes)}味道{random.choice(adjectives)},下次不会再来了。"]return random.choice(review_templates)# 生成若干条评论
num_reviews = 2
reviews = [generate_random_chinese_review() for _ in range(num_reviews)]# 2. 定义抽取规则和示例
prompt = textwrap.dedent("""从大众点评评论中抽取以下信息:- 餐厅名称 (restaurant_name)- 菜品名称 (dish_name)- 评价 (rating),可以是正面、中性或负面- 情感 (sentiment),可以是满意、不满意或失望使用评论中的确切文本进行抽取。不要转述或重叠实体。为每个实体提供有意义的属性以增加上下文。
""")examples = [lx.data.ExampleData(text="海底捞的番茄锅底很好吃,服务也非常好,非常满意!",extractions=[lx.data.Extraction(extraction_class="restaurant_name",extraction_text="海底捞"),lx.data.Extraction(extraction_class="dish_name",extraction_text="番茄锅底"),lx.data.Extraction(extraction_class="rating",extraction_text="很好吃",attributes={"type": "正面"}),lx.data.Extraction(extraction_class="sentiment",extraction_text="非常满意",attributes={"type": "满意"}),]),lx.data.ExampleData(text="西贝莜面村的莜面一般般,感觉不值这个价,有点不满意。",extractions=[lx.data.Extraction(extraction_class="restaurant_name",extraction_text="西贝莜面村"),lx.data.Extraction(extraction_class="dish_name",extraction_text="莜面"),lx.data.Extraction(extraction_class="rating",extraction_text="一般般",attributes={"type": "中性"}),lx.data.Extraction(extraction_class="sentiment",extraction_text="不满意",attributes={"type": "不满意"}),])
]# aliyun
apikey = 'sk-12234567890'result = lx.extract(text_or_documents= ''.join(reviews) ,prompt_description=prompt,examples=examples,model = OpenAILanguageModel(model_id='qwen-plus',base_url='https://dashscope.aliyuncs.com/compatible-mode/v1',api_key=apikey)
)# all_results.append(result)
print(f"Extracted {len(result.extractions)} entities from {len(result.text):,} characters")# Save and visualize the results
lx.io.save_annotated_documents([result], output_name="dianping_extraction_results.jsonl", output_dir=".")# Generate the interactive visualization
html_content = lx.visualize("dianping_extraction_results.jsonl")
with open("dianping_extraction_results.html", "w") as f:f.write(html_content.data)笔者代码生成一些点评文本,并使用进行抽取。
但是这段代码的HTML无法生成,具体情况参考【1.6】的情况