优秀网站设计参考水果商城的设计与实现
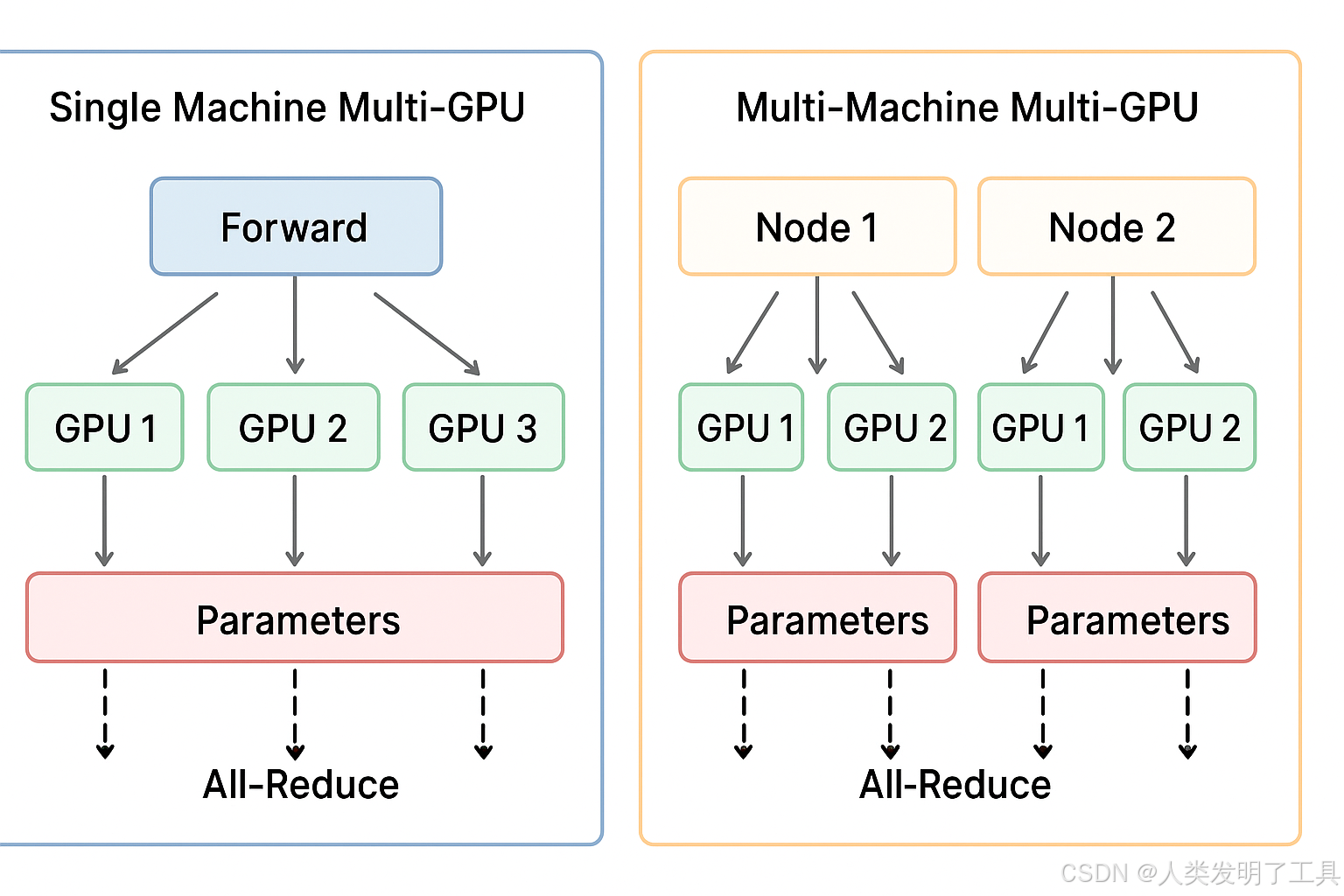
1. 单机多卡训练(Single Machine, Multi-GPU)
概念
- 在同一台服务器上,有多块 GPU。
- 一个训练任务利用所有 GPU 并行加速训练。
- 数据集存放在本地硬盘或共享存储上。
核心原理
-
数据并行(Data Parallelism)
- 将一个 batch 划分成多个 mini-batch,每块 GPU 处理一个 mini-batch。
- 每个 GPU 都有完整的模型副本。
- 前向计算在各自 GPU 独立进行。
- 反向传播结束后,通过 梯度同步(All-Reduce)聚合梯度,再更新模型参数。
- All-Reduce: 梯度求和取平均 + 同步更新,这样保证梯度是基于全局 batch 的估计
-
梯度同步方式
- PyTorch 的
DistributedDataParallel(DDP) 或 TensorFlow 的 MirroredStrategy 都使用 NCCL(NVIDIA Collective Communication Library)在 GPU 间高速同步。- 多GPU训练中,不同GPU需要频繁交换数据(如梯度)。如果直接用通用通信方式(比如通过CPU或普通网络库),效率极低。
- NCCL(NVIDIA Collective Communications Library, NVIDIA 集合通信库)多GPU和多节点环境优化的通信库。
- 由于在同一台机器,带宽高、延迟低,通信成本较低。
- PyTorch 的
优缺点
-
优点:
- 实现简单,通信效率高。
- 训练速度明显提升。
-
缺点:
- 受限于单机 GPU 数量和显存大小。
- 数据量非常大时无法容纳。
实现要点
- 使用
torch.nn.DataParallel(老方法)或torch.nn.parallel.DistributedDataParallel(推荐)。 - Batch size 可以拆分到每张 GPU。
- 注意随机种子和数据划分,保证每个 GPU 数据不同。
2. 多机多卡训练(Multi-Machine, Multi-GPU)
概念
- 训练任务跨多台服务器,每台服务器有多块 GPU。
- 每台机器称为 Node,每块 GPU 称为 Rank。
- 适合大规模数据集或模型,单机无法容纳。
核心原理
-
分布式数据并行(Distributed Data Parallel, DDP)
- 每个 GPU 依然保留完整模型副本。
- 每个 GPU 处理自己分配的 mini-batch。
- 梯度通过 All-Reduce 在所有 GPU 间同步,包括跨机通信。
- AllReduce 的设计就是 每个 GPU 都计算自己负责的部分,然后通过网络传递累加,最终所有 GPU 得到相同结果。
-
通信机制
- 跨机通信通常通过高速网络(InfiniBand 或 10/25/100GbE)进行。
- 需要指定 Master Node IP 和端口,其他节点通过 NCCL 或 Gloo 与 Master 节点通信。
- 训练框架(如 PyTorch DDP、Horovod)负责梯度同步。
-
梯度同步策略
- 每次反向传播完成后,将梯度在所有 GPU 汇总并平均,然后更新模型。
- 可使用 梯度压缩 / 分层同步 优化跨机通信开销。
优缺点
-
优点:
- 可以训练超大模型或超大数据集。
- 扩展性好,GPU 数量理论上无限。
-
缺点:
- 实现复杂,需要网络配置和多机同步。
- 跨机通信延迟高,成为训练瓶颈。
- 出错排查困难(网络、节点故障、不同版本依赖)。
实现要点
- 确定每个 GPU 的 global rank(全局编号)。
- 配置
MASTER_ADDR、MASTER_PORT。 - 使用
torch.distributed.launch或torchrun启动训练。 - 注意 Batch size 调整(全局 batch = 每 GPU batch × GPU 数 × 节点数)。
- 数据集划分需要确保不同节点不重复读取。
3. 核心区别总结
| 维度 | 单机多卡 | 多机多卡 |
|---|---|---|
| 训练范围 | 一台机器 | 多台机器 |
| GPU 通信 | 同机高速互连(PCIe/NVLink) | 网络跨机(Ethernet/InfiniBand) |
| 实现复杂度 | 低 | 高,需要网络配置 |
| 扩展性 | 受限于单机 GPU 数量 | 高,可扩展到上百 GPU |
| 通信开销 | 低 | 高,可能成为瓶颈 |
| 框架示例 | PyTorch DDP、MirroredStrategy | PyTorch DDP、Horovod |