性能测试实战:JMeter全攻略

文章目录
- 性能测试理论
- 性能是什么
- 性能测试
- 性能测试的目的
- 性能测试策略
- 基准测试
- 负载测试
- 稳定性测试
- 压力测试
- 并发测试
- 测试策略汇总
- 性能测试指标(6)
- 1)响应时间
- 2)并发数
- 3)吞吐量⭐
- 4)资源利用率
- 5) 点击率
- 6)错误率
- 性能测试流程
- JMeter性能测试
- JMeter VS LoadRunner
- LoadRunner
- JMeter
- jmeter环境配置
- JMeter常用目录介绍
- 汉化JMeter
- JMeter元件、组件介绍
- 1.JMeter元件和组件(9元件n组件)
- 2. 组件的作用域和执行顺序
- 线程组
- 取样器
- 察看结果树
- 参数化
- 组件-用户定义的变量
- 组件- 用户参数
- 组件- CSV数据文件设置
- 函数
- 断言
- 响应断言
- JSON断言
- 持续时间断言
- JMeter关联
- 正则提取器
- JSON提取器
- XPath提取
- 使用说明:
- 跨线程组接口关联
- JMeter属性
- 函数__Setproperty
- Beanshell取样器
- 函数__property
- JMeter脚本录制
- 过滤
- JMeter直连数据库
- 配置元件-JDBC Connection Configuration
- 一、MySQL 9.x对应的JDBC驱动版本
- 二、JMeter核心配置步骤
- 1. 驱动安装
- 2. JDBC Connection Configuration(连接池配置)
- 三、关键注意事项
- 四、配置验证
- 取样器-JDBC请求
- JDBC Request(执行SQL)
- 一、Parameter Values(参数值)
- 二、Parameter types(参数类型)
- 三、Result variable name(结果变量名)
- 四、Query timeout (seconds)(查询超时时间)
- (五) Handle ResultSet的常见选项及作用
- 总结:何时需要配置这些项?
- 取样器-Debugger Sample
- 配置与使用方法
- 适用场景
- 逻辑控制器
- IF控制器
- 循环控制器
- ForEach控制器
- 定时器
- 同步定时器synchronizing Timer
- 固定定时器
- 常数吞吐量定时器 Constant Throughput Timer
- 监听器
- 聚合报告
- 一、聚合报告的添加步骤
- 二、聚合报告核心指标解读(按列说明)
- 三、聚合报告的解读逻辑(优先级排序)
- 1. 第一步:先看「Error %(错误率)」—— 确认系统稳定性
- 2. 第二步:看「Throughput(吞吐量)」—— 确认系统处理能力
- 3. 第三步:看「响应时间指标」—— 确认用户体验
- 4. 第四步:看「网络流量」—— 排查网络瓶颈
- 四、常见问题与注意事项
- 五、总结
- 用表格查看结果(View Results in Table)
- 核心作用
- 输出形式(关键列)
- 适用场景
- 汇总报告(Summary Report)
- 核心作用
- 输出形式(关键列)
- 适用场景
- 与聚合报告的区别
- 响应时间图(Response Time Graph)
- 核心作用
- 输出形式
- 适用场景
- 断言结果(Assertion Results)
- 核心作用
- 输出形式(关键列)
- 适用场景
- Transactions per Second(TPS图)
- 核心作用
- 输出形式
- 适用场景
- 简单数据写入器(Simple Data Writer)
- 核心作用
- 输出形式
- 适用场景
- 总结:不同场景如何选择报告?
性能测试理论
功能测试测系统达到需求说明
性能测试看系统实现的好不好
性能是什么
- 时间:响应时间快慢
- 资源:消耗系统资源多少
性能测试
使用自动化工具,模拟不同的测试场景(测试策略),对系统的各项指标进行测试和评估(性能指标)
性能测试的目的
- 评估当前系统的能力
- 寻找系统瓶颈,优化性能
- 评估软件是否满足未来的需求
性能测试策略
基准测试
-
作用:得到当前系统的性能基准
-
分类:
- 单用户测试:
比如执行多次登录,观察登录成功的耗时----得到系统登录接口耗时 - 建立基准线,评估环境变化对指标的影响,以得到后续性能测试优化方向
- 基准线:商城V1.0版本,模拟5W用户在8CPU16G服务器运行,下单时间是5s
- 商城V2.0 模拟5w用户在8CPU16G服务器运行,下单时间
- 商城V1.0 模拟10W用户在8CPU16G服务器运行,下单时间
- 商城V1.0 模拟5W用户在8CPU32G服务器运行,下单时间
- 基准线:商城V1.0版本,模拟5W用户在8CPU16G服务器运行,下单时间是5s
- 单用户测试:
-
用途:
- 提供参考指标:
- 给版本升级、系统配置等变化后 提供性能指标参考
- 为多用户等综合测试场景提供参考依据
- 提供参考指标:
负载测试
-
作用:找到系统最大负载量
-
怎么测:逐步增加负载量,确保满足系统性能指标的情况下,找到系统所能承受的最大负载量的测试
-
类比:
假如,电梯规范从1楼到5楼要10s。
乘坐电梯时都有两个指标,最大称重量1000kg 最多乘客13人,是怎么得出来的?
进行负载测试,先得到性能指标:从1楼到5楼要10s;在看负载量①重量②人数对人数进行测试:
- 载1人从1楼到5楼,记录时间:1s
- 载3人从1楼到5楼,记录时间:2s
- 载5人从1楼到5楼,记录时间:3.5s
- 载10人从1楼到5楼,记录时间:6.5s
- 载12人从1楼到5楼,记录时间:9s
- 载13人从1楼到5楼,记录时间:9.5s
- 载15人从1楼到5楼,记录时间:12s
- 载20人从1楼到5楼,记录时间:绳子断了
所以最大载客量是13人
稳定性测试
- 前提:在用户要求的稳定环境之下 执行
- 怎么测:在服务器稳定环境下,运行规定时间,观察系统的性能指标,满足要求再上线
- 何为稳定环境:
- 用户规定的稳定环境:
- ≤负载测试得到的最大负载量的情况下,运行
- 举例:
- 场景1:用户要求最大负载量是15的情况下,稳定运行3天
稳定环境就是乘15人3天不间断的上下,这种情况下需要先解决负载测试不达标的bug,先将系统的最大负载量达到稳定环境标准。 - 场景2:用户要求最大负载量是10的情况下,稳定运行3天
稳定环境就是乘10人的情况下,3天不间断的上下,观察电梯的性能指标
- 场景1:用户要求最大负载量是15的情况下,稳定运行3天
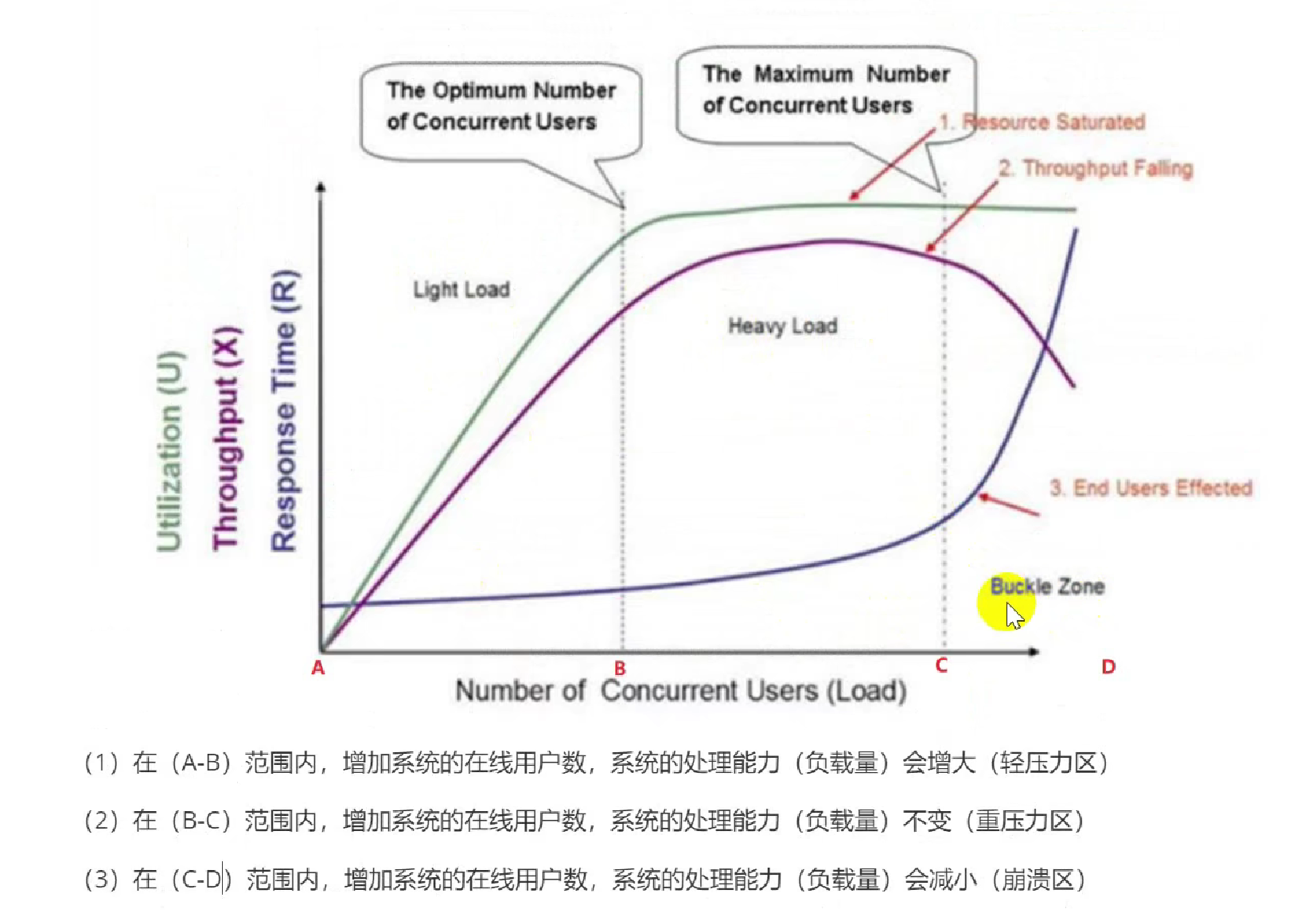
压力测试
- 作用:观察系统超过最大负载量的峰值情况下,系统的容错能力和恢复能力。就是看超过这个临界点,系统会不会崩溃 以及 崩溃了多久能恢复。做一个预案。
- 强负载情况下,系统是否存在隐患,以及系统的容错能力和恢复能力
- 怎么做:
- 极限情况下,做破坏性测试(上图的C-D)–破坏性压力测试
- 高负载情况下,长时间高负载(上图的A-B)—稳定性压力测试
并发测试
- 极短的时间内,模拟大量请求,观察系统的处理能力
- 场景:秒杀、抢红包
- 对比负载测试,并发测试更注重时间是极短的时间
测试策略汇总
| 基准测试 | 负载测试 | 稳定性测试 | 压力测试 | 并发测试 |
|---|---|---|---|---|
| 建立性能基准 | 找到系统稳定运行时的最大负载量 | 评估到最大负载量后,观察在稳定情况下长时间运行 | 破坏性压力测试 稳定性压力测试 | 短时间内模拟大量请求 |
| 评估软件能力 为后续测试提供数据参考 或提供一个影响指标的数据 | 找到系统瓶颈 | 预防,看系统的容错能力和恢复能力,做预案 |
性能测试指标(6)
1)响应时间
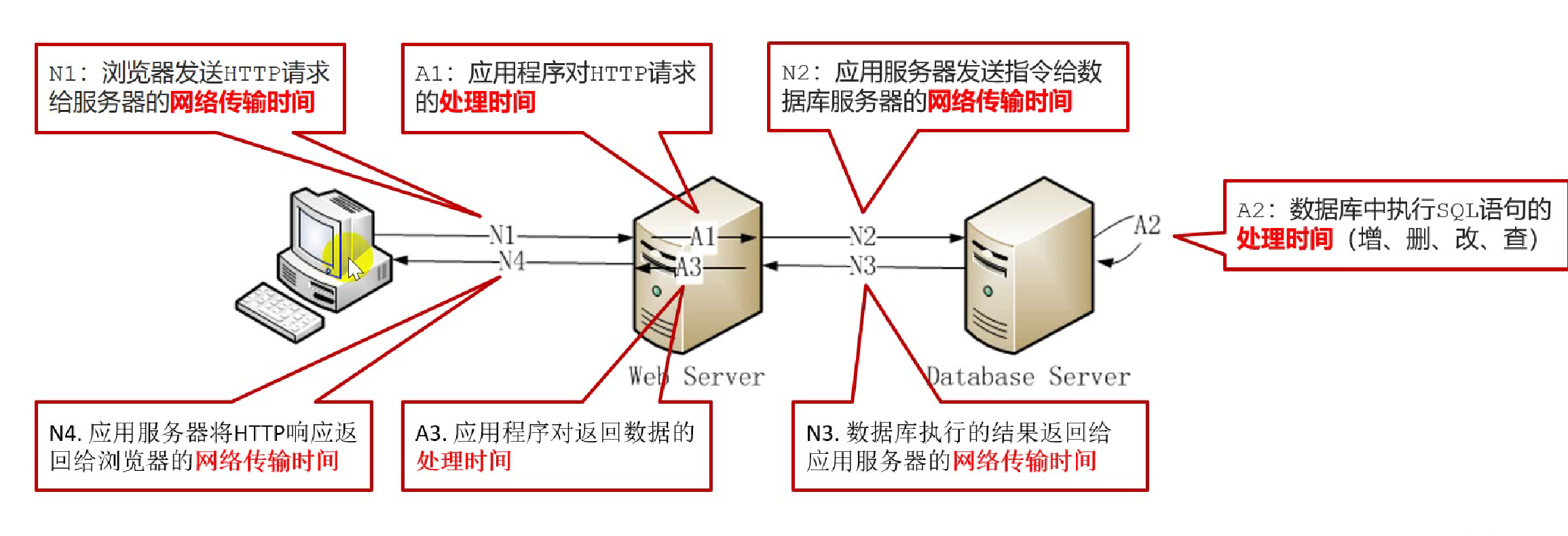
从客户端发送请求开始 到 服务器将数据返回给客户端结束。(处理请求时间+网络传输时间)
从浏览器开始发送请求到服务器将数据返回给浏览器的时间
2)并发数
并发(用户)数:某一时刻同时向服务器发送请求的用户数
3)吞吐量⭐
- 吞吐量:单位时间内处理用户请求数量
- 直接能反映系统质量的
- 业务角度:给用户说“事务数/小时”“查询次数/天”
- 网络角度:“字节数/h”
- 技术角度:TPS(transaction per seconds )每秒事务处理数;QPS (query per seconds)每秒的查询次数
事务VS请求:一个事务是一个业务,可能包含一个或多个请求。
- 示例:
- 搜索–请求a接口即可–每秒最大处理15个------>搜索的TPS是15 QPS也是15
- 下单流程–请求商品列表接口、请求支付接口—每秒最大处理列表接口15个,每秒最大处理支付接口15个----下单的TPS是15 QPS是30
4)资源利用率
系统各资源的使用情况。计算公式:(已使用资源/总资源)*100%
资源指标:
- CPU (大小)
- 内存(大小)
- 磁盘IO (读写速率)
- 网络(传输速率。可以调整带宽大小)
5) 点击率
web端独有。指访问一个页面,加载图片、音频、文字等各资源的请求总数量
6)错误率
系统在负载情况下,失败业务的占比。
注意 不是功能性bug,是功能问题解决完毕后进行性能测试,且让系统处于一个高负载的情况下,观察处理业务的失败率。
性能测试流程
1)需求分析
熟悉项目背景
业务
明确测试指标
2)测试计划和方案
-
测什么
-
谁来测
-
怎么测
3)测试用例编写
4)用例执行
5)执行结果分析、调优
- 测试人员分析提交bug
- 开发人员进行调优。
6)测试报告
- 测试过程
- 测试结果
- 风险
- 总结
对本次性能测试做总结,对未来测试提供依据。
JMeter性能测试
JMeter VS LoadRunner
LoadRunner
- 基于C语言开发的,脚本也需要C语言
- 支持多种协议,常见的Web(HTTP\HTML)、Windows sockets、FTP、等等
- 模拟大量用户,万级别
- 能监控系统的各项性能指标
- 秒级的报告
- 支持IP欺骗(比如业务会对同一IP的频繁请求做次数限制,通过IP欺骗-变换IP模拟并发绕过这个业务限制)
- 付费,无法定制化
- 不支持扩展
JMeter
- 基于Java,开源免费
- 支持多协议
- 支持多用户(没有LoadRunner多)
- 支持扩展(类似python语言中的第三方库)
- 免费
- 分钟级别的报告
- 不支持IP欺骗
| 工具 | 语言 | 监控系统指标 | 报告 | 多用户 | 扩展 | IP欺骗 | 收费 |
|---|---|---|---|---|---|---|---|
| LoadRunner | C | 是 | 是,秒级 | 支持,w级别 | 不支持 | 支持 | 收费 |
| Jmeter | Java | 是 | 是,分钟级别 | 支持 | 支持 | 不支持 | 免费 |
jmeter环境配置
-
部署Java的jdk(jmeter基于Java语言)
- http://www.oracle.com/ 下载解压到本地
- 32位系统安装32位的jdk
- 64位系统安装64位的jdk
- https://www.oracle.com/cn/java/technologies/downloads/#jdk25-windows
- 配置Java环境变量
- %Java_HOME%\bin
- %Java_HOME%\jre\bin
- 验证Java环境部署成功
- 打开cmd输入java指令
- http://www.oracle.com/ 下载解压到本地
-
安装jmeter
- https://jmeter.apache.org/download_jmeter.cgi 下载安装包
- 解压到本地
- 配置环境变量
- %Jmeter_HOME%\lib\ext\ApacheJmeter_core.jar
- %Jmeter_HOME%\lib\jorphan.jar
- 验证
- 打开安装目录双击bin\jmeter.bat 可以运行成功
- 或 双击 ApacheJMeter.jar
- 或 输入命令 java - jar ApacheJmeter.jar
JMeter常用目录介绍
- bin目录:可执行文件 配置文件
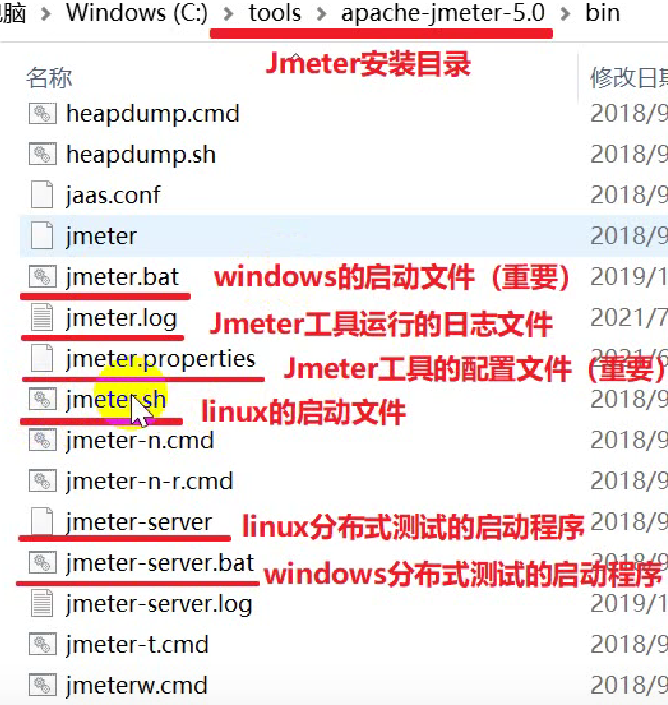
- docs 目录:JMeter的api文档,用于开发扩展组件
- printable_docs目录:用户帮助手册
- lib目录:存放JMeter依赖的jar包 和用户扩展所以来的jar包
汉化JMeter
-
临时性
- options->choose language
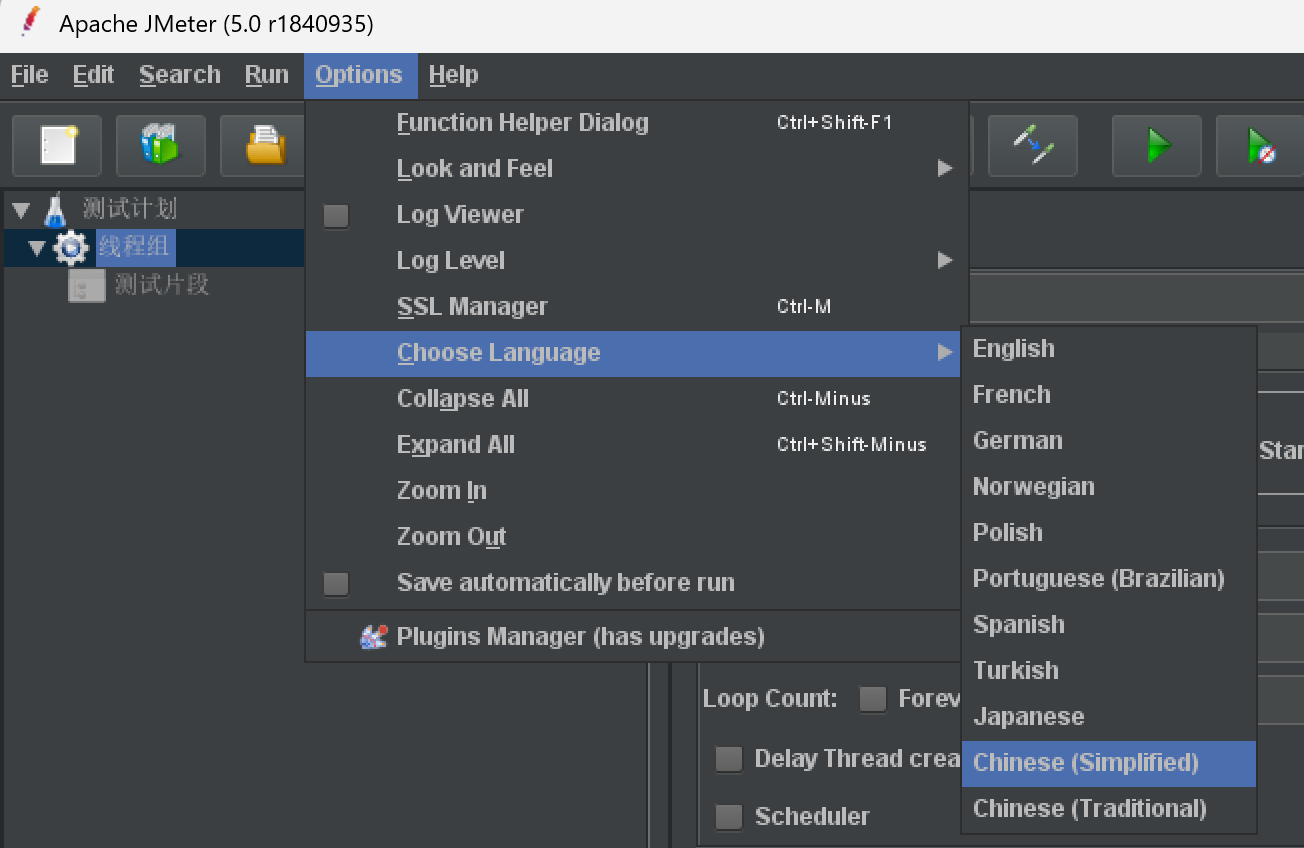
- options->choose language
-
永久性
- 改配置文件 Bin\JMeter.properties
- 修改37行,改为language=zh_CN,去掉#
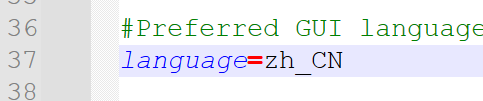
- 修改37行,改为language=zh_CN,去掉#
- 重启JMeter
- 改配置文件 Bin\JMeter.properties
JMeter元件、组件介绍
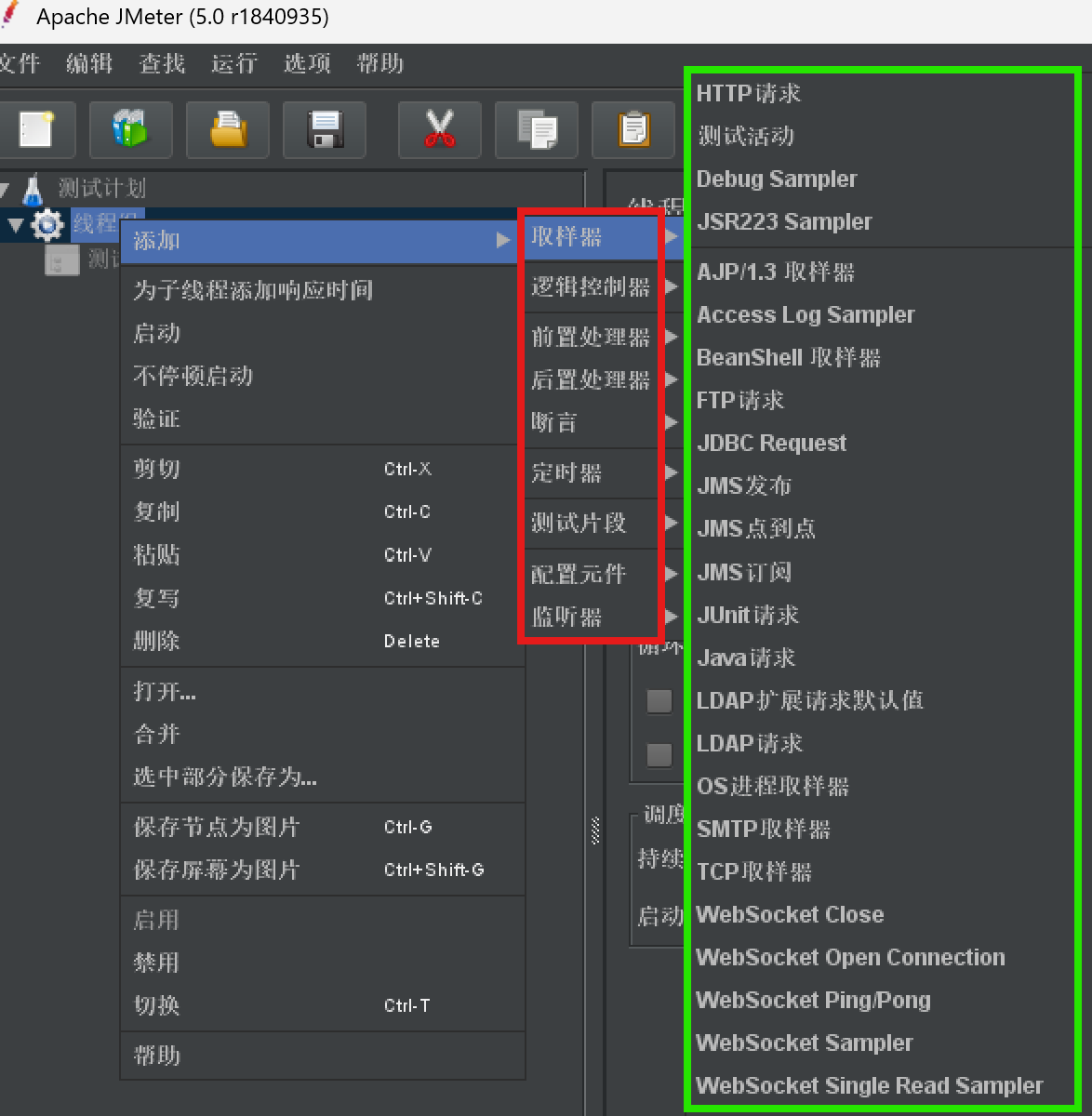
1.JMeter元件和组件(9元件n组件)
- 元件:是装着具有相同功能的容器(像python面向对象中的类)
- 配置元件:初始化数据
- 取样器:发送请求
- 逻辑控制器:控制元件的执行顺序
- 前置处理器:发送请求前对请求参数进行预处理
- 后置处理器:收到响应后提取响应结果
- 断言:对提取到的响应进行判断
- 定时器:设置等待
- 监听器:观察脚本的运行结果
- 测试片段:封装一段代码,给其他脚本调用的啊
- 组件:是每个功能的具体实现方法
- 比如取样器中的HTTP请求、FTP请求等等
2. 组件的作用域和执行顺序
-
作用域:
- 取样器:是核心,没有作用域,和其他元件独立
- 逻辑控制器:只对其子节点有效
- 其他元件:
- 如果父节点是取样器,那么只对其父节点这个取样器有效
- 如果父节点不是取样器,那么对父节点所有的后代节点都有效。
-
执行顺序:
- 同一个作用域下相同元件:
- 从上到下按顺序
- 同一个作用域下的不同元件:
🤔代码写接口测试脚本时的步骤,我们类比到jmeter元件中:
1. 初始化数据、配置等—配置元件
2. 请求参数赋值—前置处理器
3. 模拟请求—取样器
4. 获取响应数据—后置处理器
5. 断言响应—断言
6. 观察控制台运行结果—监控器
由此得出,jmeter元件的执行顺序,只有一个特殊是定时器在取样器之前:
配置元件–>前置处理器—>定时器—>取样器—>后置处理器—>断言—>监听器
- 同一个作用域下相同元件:
结合以上作用域和执行顺序,分析下图的执行顺序:
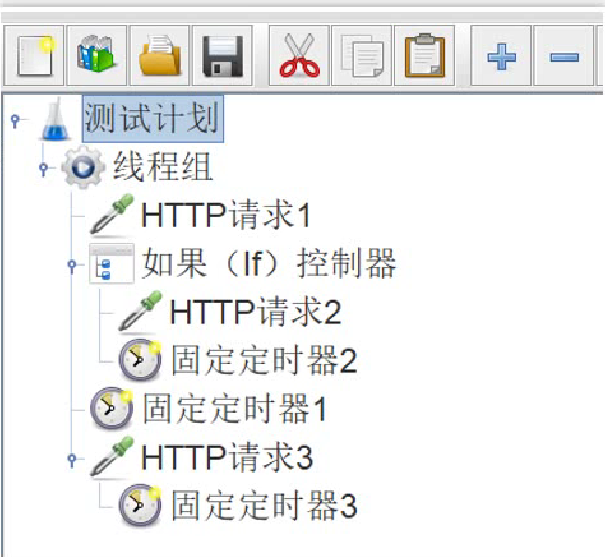
- 作用域分析:
- 请求1、2、3(取样器)没有作用域;
- 如果IF控制器(逻辑控制器)只对其子节点有效;
- 定时器1、2、3(其他元件)
- 定时器1 父节点是线程组(非取样器),对线程组下的所有节点生效
- 定时器2 父节点是逻辑控制器(非取样器),对IF控制器下的所有节点(请求2)生效
- 定时器3 父节点是请求3(取样器),只对请求3生效
- 顺序分析:
- 配置元件–前置处理器–定时器–取样器–后置处理器–断言–监听器
- 请求1、2、3是按顺序执行
分析得到最终执行顺序:
固定定时器1 - HTTP请求1 - 固定定时器1 - 固定定时器2 - HTTP请求2 - 固定定时器1- 固定定时器3 - HTTP请求3
线程组
-
是什么:
- 执行测试的一组用户
- 就是模拟用户的行为
-
分类:
- 普通线程组:执行测试用例
- Setup线程组:在普通线程组之前执行(可以把初始化步骤放这里,类似unittest框架中的SetupClass)
- Teardown线程组:所有脚本之后执行
-
特点:
- 可以模拟单个用户、多个用户
- 可以添加多个线程组
- 线程组之间可以并行、也可以串行
- 线程组之间可以并行、也可以串行
-
配置:
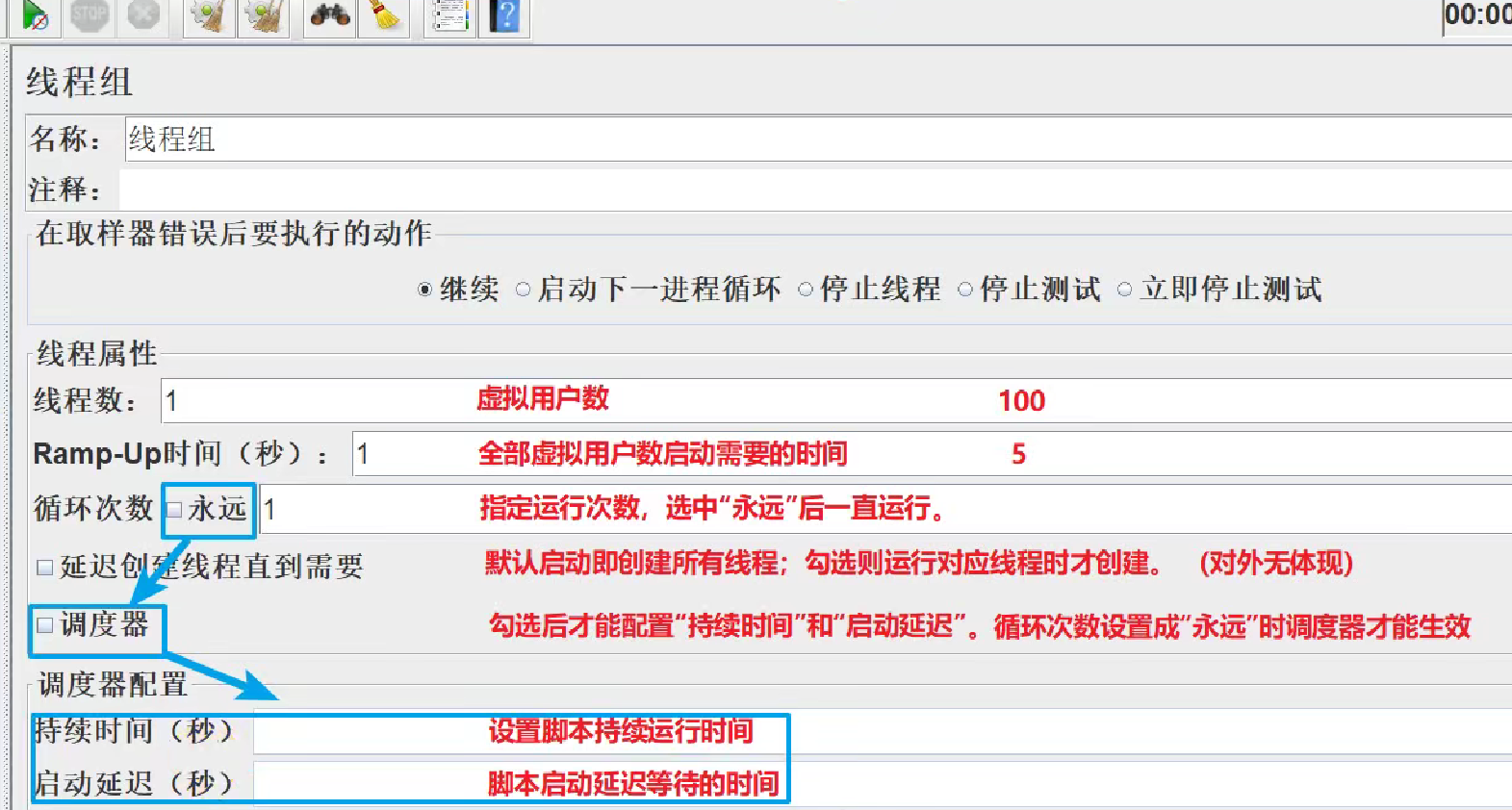
-
案例:
- x
- x
- x
- x
- x
-
分析:
- 案例1:模拟2个线程数,循环3次
- 案例2:模拟3个线程数,循环2次
- 区别:
- 线程数:模拟用户数,用户数= 负载量
- 循环次数:改变运行时间,时间= 压力
取样器
- 作用:发送请求
- 添加方法:在【测试计划】/【线程组】右击【添加】-【取样器】-【HTTP请求】
- 组件各部分介绍:
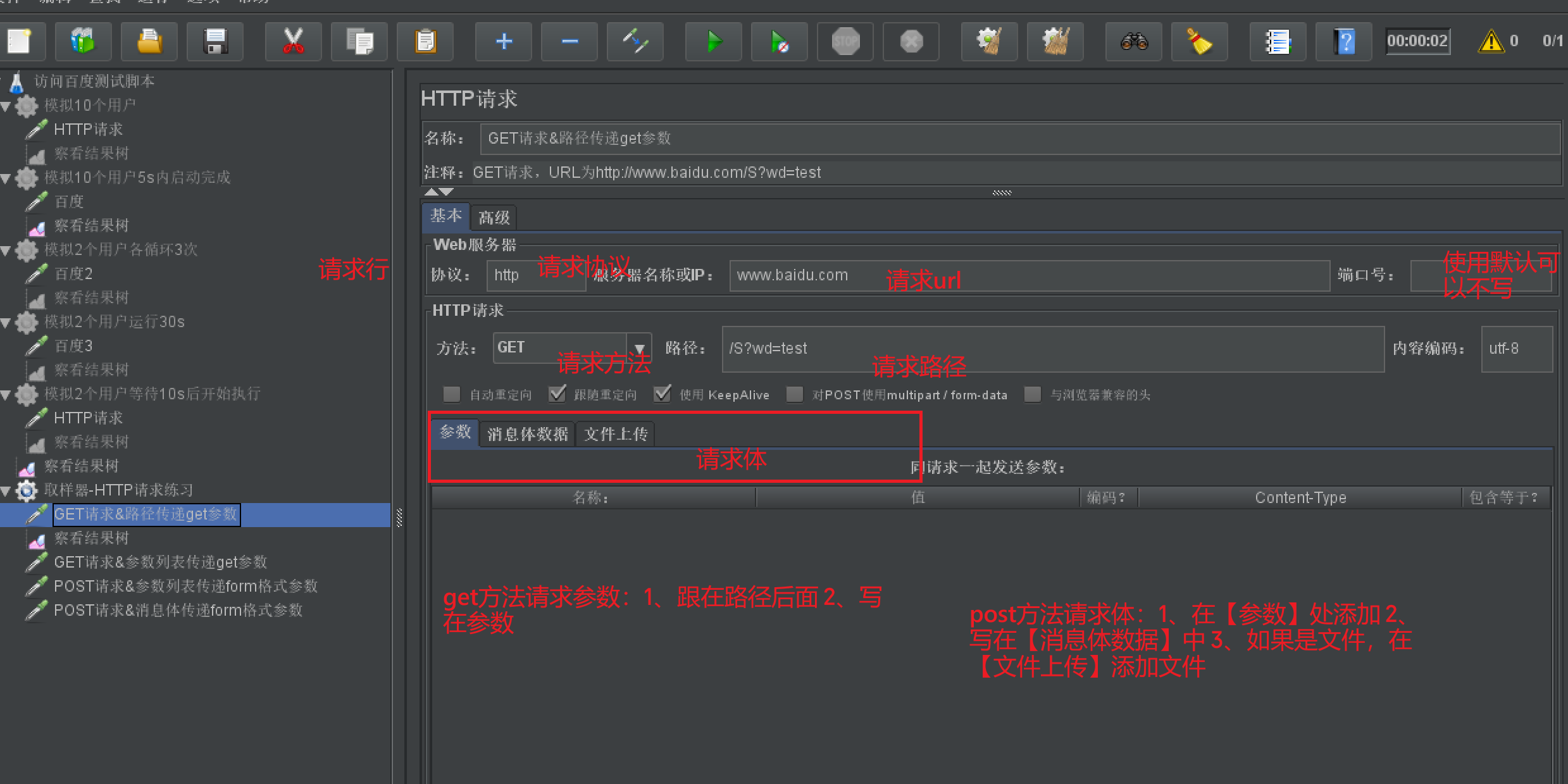
察看结果树
-
作用:查看接口请求和响应信息
-
添加方法:【测试计划】/【线程组】 右击 【添加】-【监听器】-【察看结果树】
-
组成部分介绍:
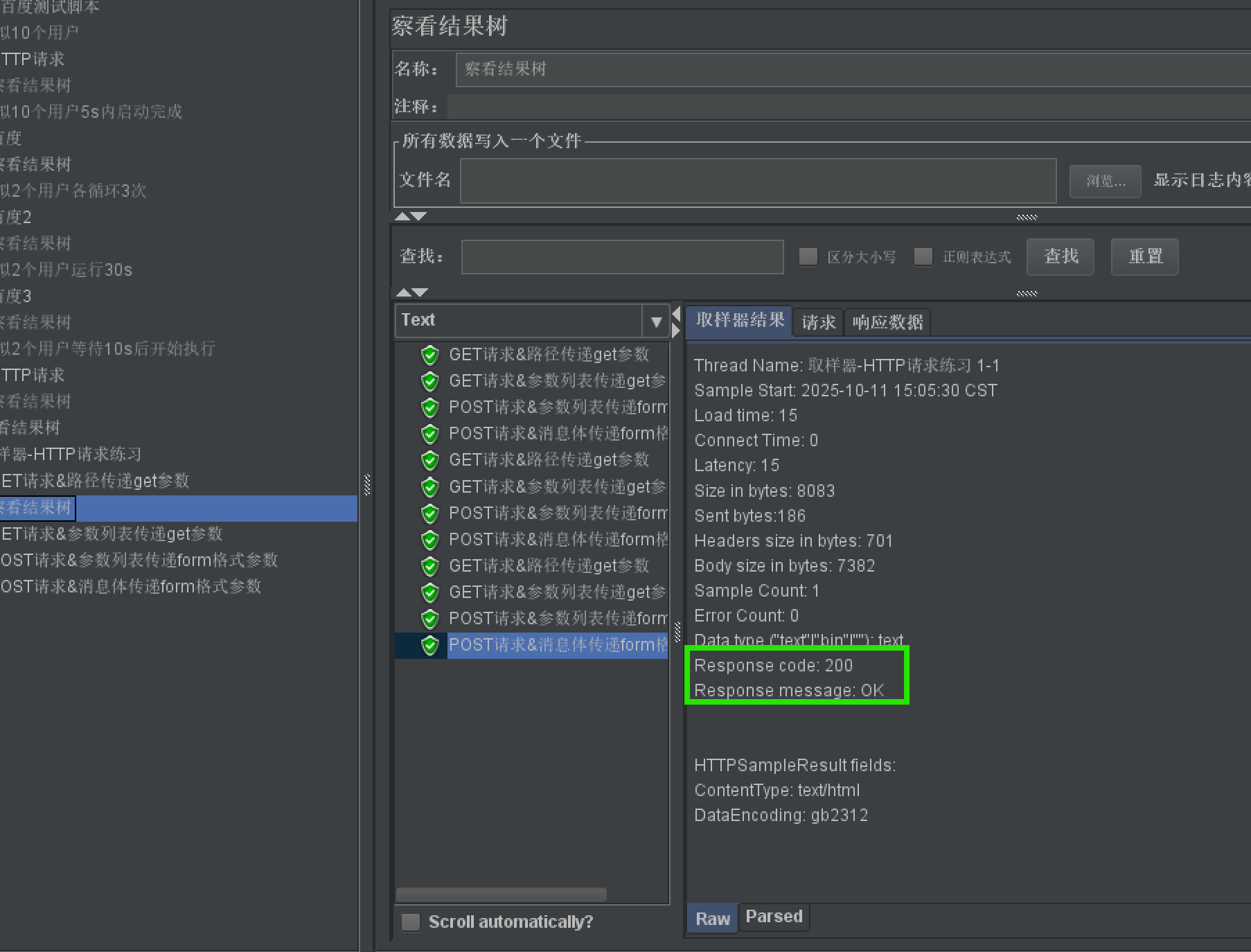
- 取样器结果
- 请求:
- requests body
- requests headers
- 响应信息:
- response body
- response headers
-
解决中文乱码:
- 配置文件Bin\JMeter.properties:sampleresult.default.encoding=UTF-8
- 重启JMeter
参数化
- 是什么:用参数替代固定数据执行测试脚本
- 作用:用不同的参数(数据),调用相同的测试脚本,实现数据驱动测试
- 本质:将【测试数据】与【测试脚本】实现分离
- 实现方式:
- 回想之前代码中的参数化方式:
- 参数可以来源于【变量】—全局变量
- 参数可以来自【参数】— 函数中的参数
- 参数可以来自【文件】— 从文件读取数据
- 参数可以来自【数据库】— 连接数据库从数据库读
- 参数可以来自【函数】— 编写函数生成数据
- 对应JMeter中,也是类似方法:
- 用户定义的变量
- 用户参数
- CSV配置文件
- 数据库
- 函数
- 回想之前代码中的参数化方式:
组件-用户定义的变量
- 作用:设置变量,供请求时使用,实现参数化
- 场景:设置【全局变量】一般用于设置公用的部分,比如 请求行信息
- 使用:
-
- 添加组件:【测试计划】/【线程组】/【取样器】右击 【添加】-【配置元件】- 【用户定义的变量】
-
- 添加变量:key:value
-
- 使用变量:${key}
-
- 注意:
- 注意配置元件的作用域
- 使用示例:

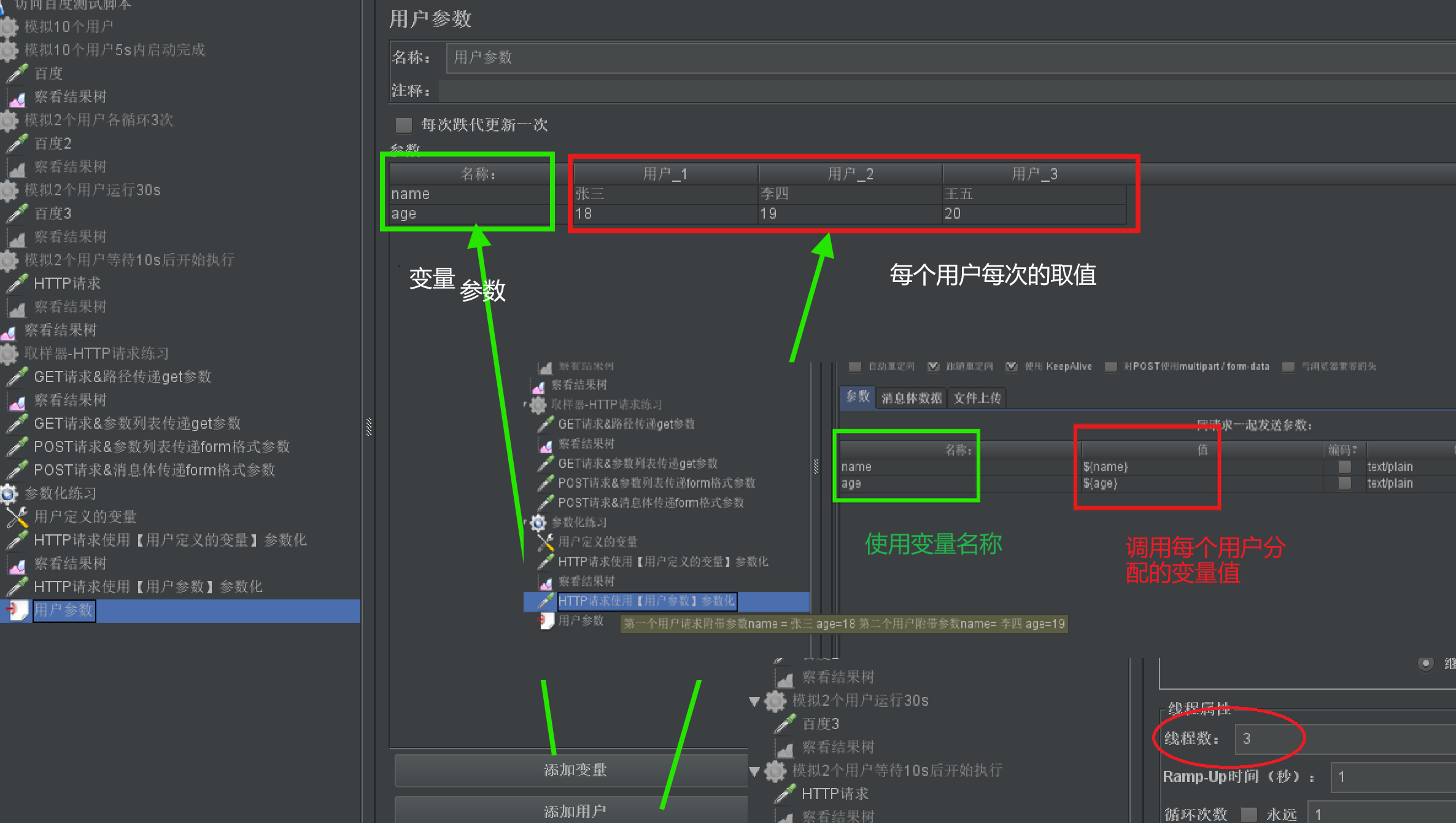
组件- 用户参数
- 作用:针对相同的参数,不同的用户访问时分配不同的值
- 应用场景:给请求参数传递不同的参数值
- 使用步骤:
- 设置线程组的线程数
-
- 添加组件【线程组】右击【添加】-【前置处理器】-【用户参数】
-
- 定义用户参数: 【添加变量】key 【添加用户】每个用户对应的value
-
- 使用用户参数:${key}
- 示例:
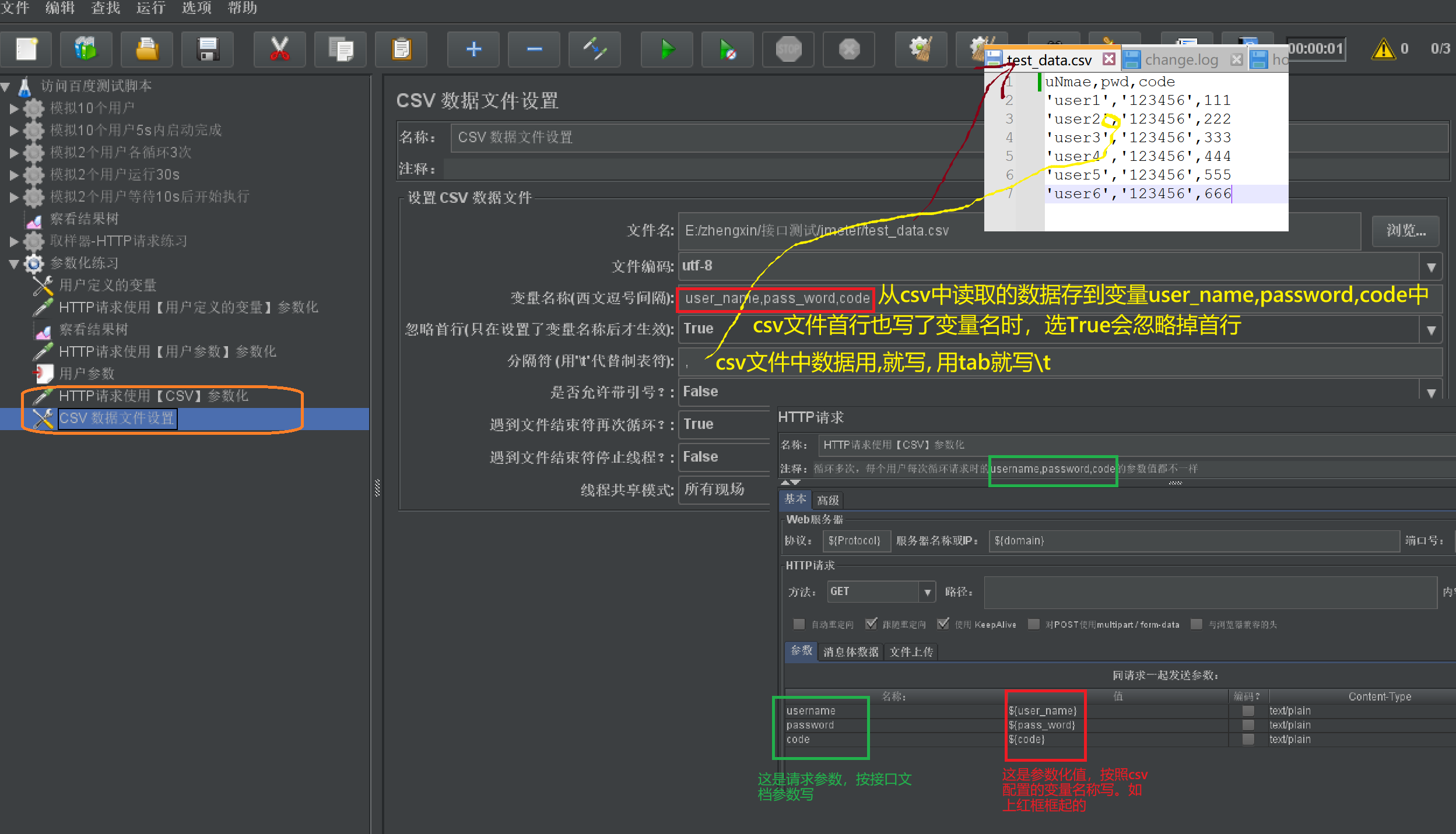
组件- CSV数据文件设置
- 作用:
- 每个用户每次循环请求,参数都传不同的值(用户参数是针对用户区分参数的,每个用户每次循环取到的是一样的参数值)
- 步骤:
- 设置线程组n个,循环m次
- 明确请求参数比如username,password,code
- 准备数据csv文件
- 添加csv组件:
- 【线程组】右击【添加】-【配置元件】-【CSV数据文件设置】
- 选择csv文件 并按下图根据需求配置
- 在请求参数中使用csv变量:
- ${key}
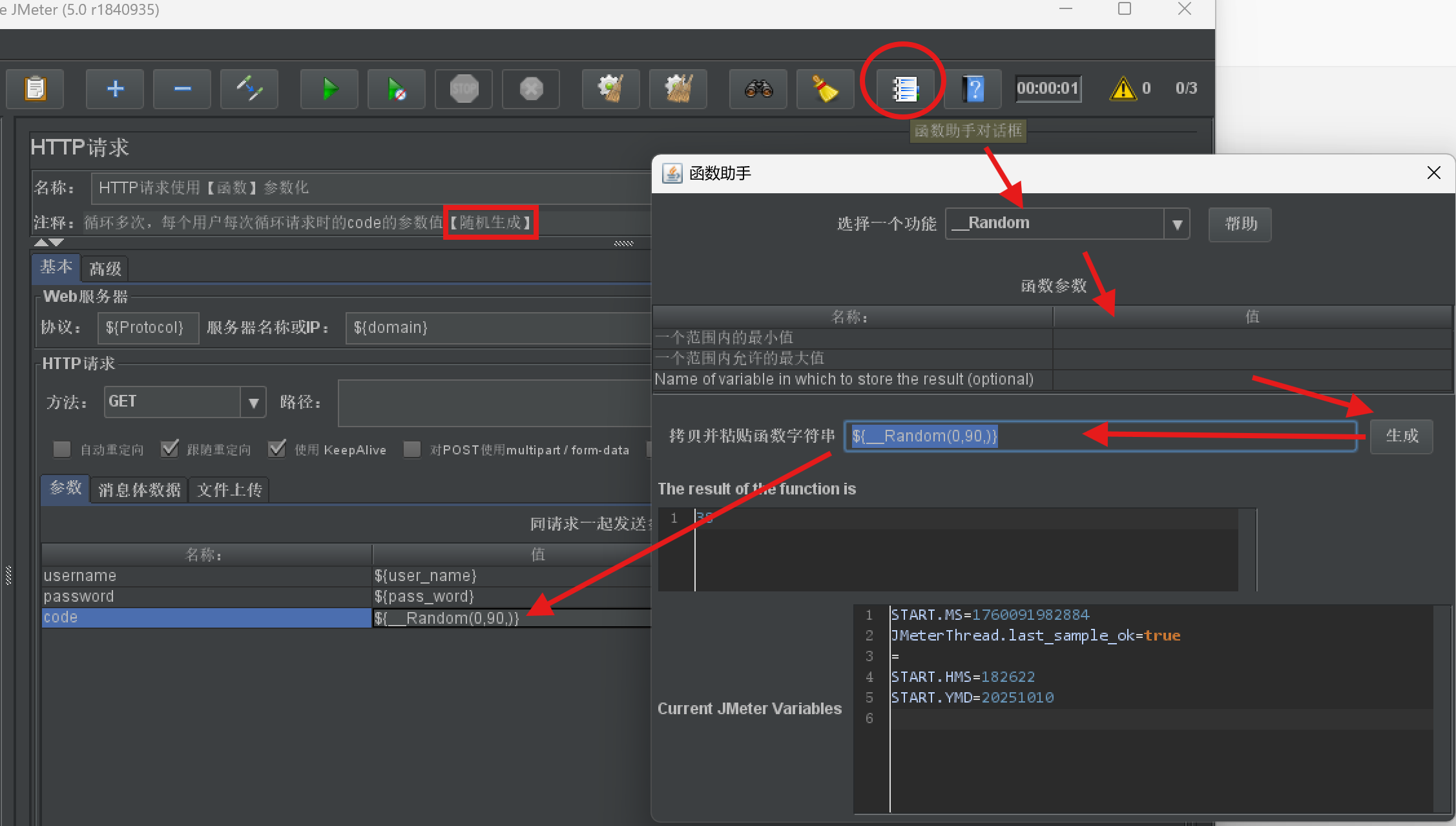
函数
- 作用:
- 按需生成参数值
- 比如大量的数据
- 比如随机数据
- 。。
JMeter提供了丰富的函数
- 按需生成参数值
- 步骤:
- 打开函数生成助手
- 选择合适的函数
- 根据需求生成
- 在请求参数中使用生成值
- 示例:
断言
- 作用:JMeter代替人工校验接口请求的结果是否符合预期
- 常用分类:
- 响应断言
- JSON断言
- 持续时间断言
- 使用:
- 【取样器】右击【添加】-【断言】-【选择合适的断言】
响应断言
- 作用:断言任何格式的响应结果
- 使用:
- 【取样器】右击【添加】-【断言】-【响应断言】
- 使用说明:
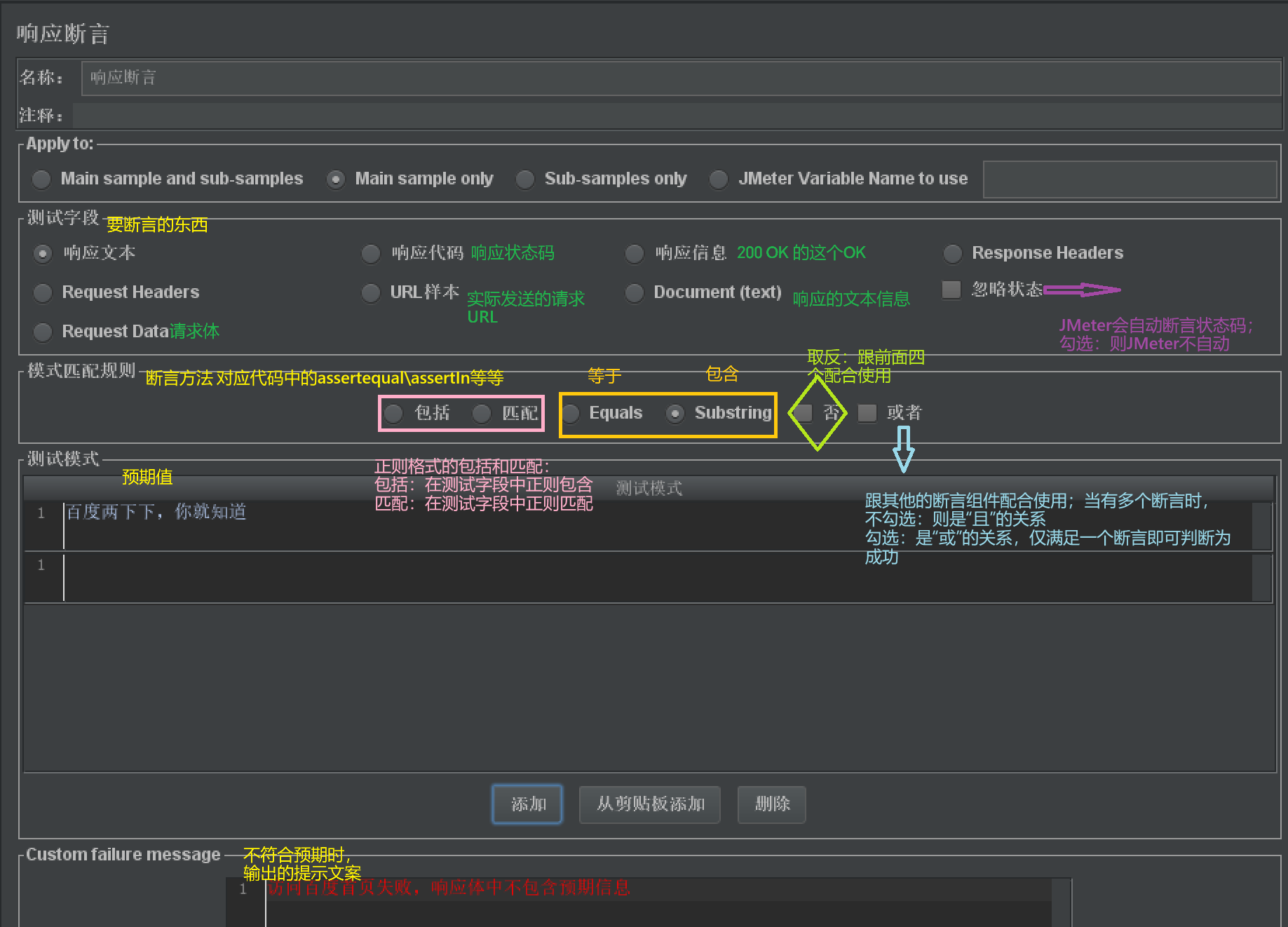

JSON断言
- 作用:
- 校验json格式的响应数据
- 更具体
- 使用说明:
- assert json path exists: 要校验的json字段路径
- additionally assert value:额外校验json字段的值。不勾选则只校验字段存在
- match as regular expression: 以正则表达式校验值。需与additionally assert value同时勾选才生效,否则仅校验路径
- expected value: 预期值
- expect NULL: 预期值为空时勾选。需与additionally assert value同时勾选才生效
- invert assertion : 反选-当满足以上条件时会断言错误。
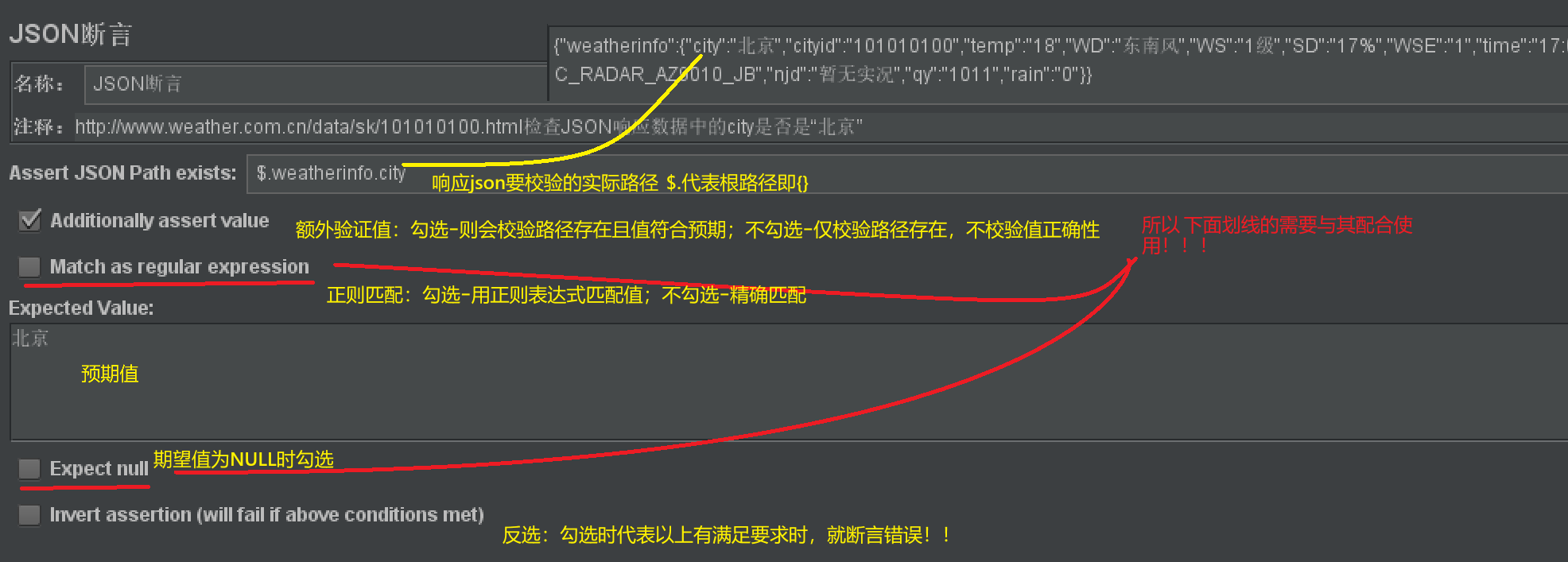
- 添加步骤:
- 【取样器】右击【添加】-【断言】-【JSON断言】
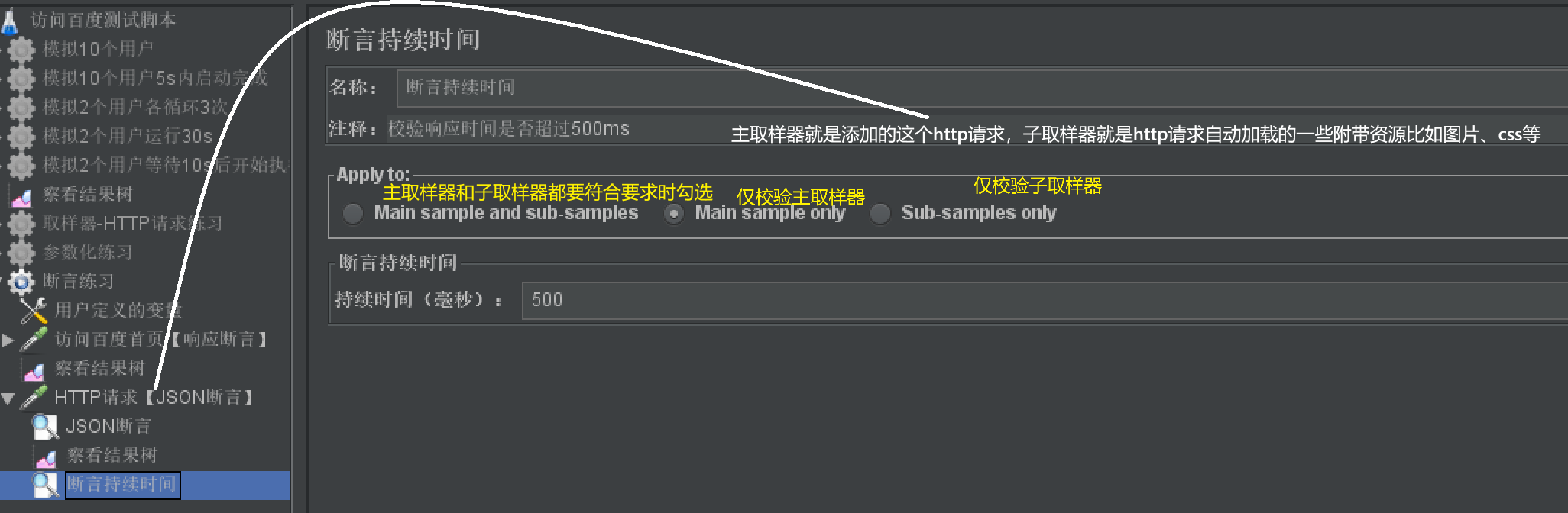
持续时间断言
- 作用:
- 验证响应时间
- 步骤:
- 【取样器】右击【添加】-【断言】-【断言持续时间】
- 使用说明:
JMeter关联
- 作用:
- 接口关联,用于业务功能接口测试
- 一个接口的响应结果作为下一个请求的参数
- 比如加购物车接口,需依赖先登录接口再访问商品列表接口
- 使用说明:
- 添加
- 步骤:
正则提取器
- 作用:
- 提取响应数据的指定内容,给之后的请求使用
- 可提取任意格式的响应数据
- 适用场景:
- 不规范的html等
- 优缺点:
- 支持任意格式的内容
- 但需要谨慎编写正则表达式
- 维护成本
- 添加步骤:
- 【取样器】右击【添加】-【后置处理器】-【正则提取器】
- 使用说明:
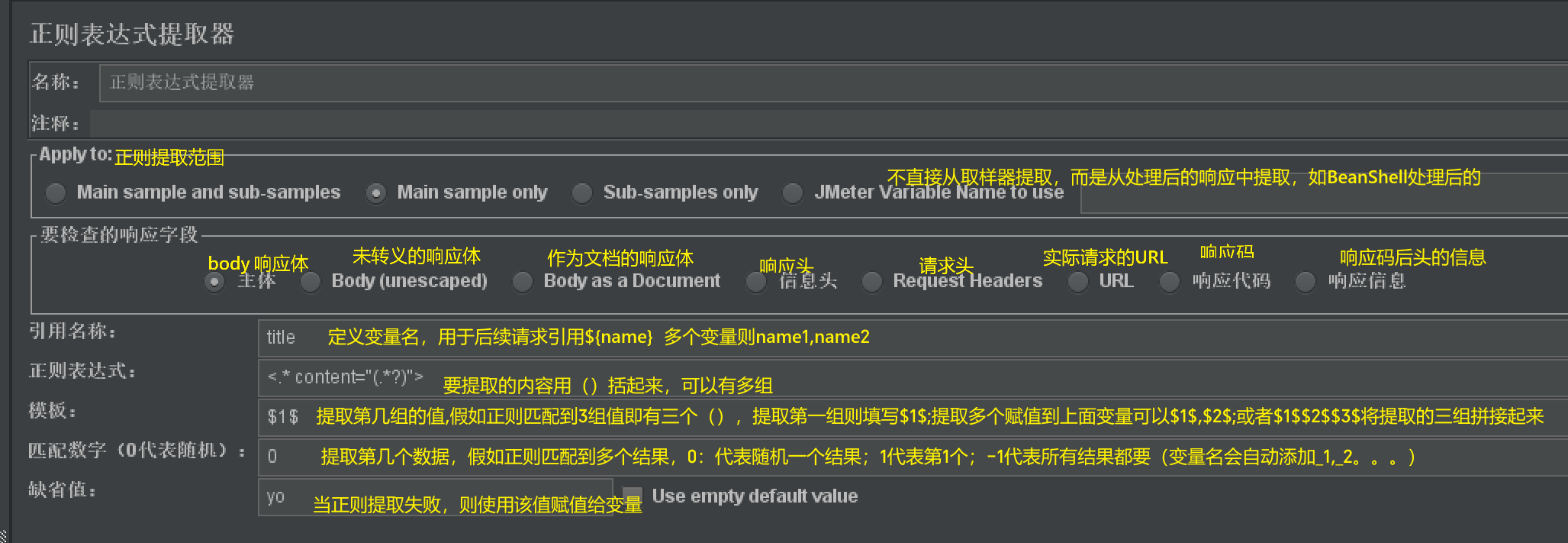
- 要检查的响应字段(提取来源):
- body: 从完整的响应体中提取
- Body unescaped: 从未转义的响应体中提取
- 处理方式:直接获取响应体的原始文本内容,但会自动处理响应中的 “转义字符”(如 JSON 中的"转为",\转为\等),最终呈现为 “人类可读的原始文本”。
- 本质:以 “纯文本” 形式呈现响应体,保留原始的字符顺序和结构,但消除了计算机存储时的转义符号(让文本更易读)。
例: - 原始响应体(带转义):{“name”:“张三”,“info”:“地址:“北京市””}
- Body(unescaped)处理后:{“name”:“张三”,“info”:“地址:“北京市””}
- 适用场景:
- 提取token时使用
- 非结构化文本(JSON、纯文本)、正则提取
- Body as a Docunment: 作为文档的body
- 处理方式:将响应体视为 “结构化文档”(如 HTML、XML、XHTML 等),JMeter 会自动对其进行语法解析和规范化处理(如补全未闭合的标签、修正嵌套错误、统一标签大小写等),最终生成一个 “符合规范的结构化文档对象”。
- 本质:不是直接处理原始文本,而是先将响应体解析为 “可被结构化查询(如 XPath)识别的文档模型”,方便基于层级结构提取数据。
- 原始响应体(不规范 HTML):< div >< p >测试(缺少闭合标签< /p>< /div>)
- Body as a Document处理后:自动补全为< div>< p>测试< /p>< /div>(规范化结构)
- 适用场景:
- 结构化文档(HTML、XML)、XPath 提取
- 引用名称:
- 作用:定义变量名称,供其他请求使用
- 可以定义多个变量名称:name1,name2,…
- 使用方法:${变量名称}
- 作用:定义变量名称,供其他请求使用
- 正则表达式:
- . 匹配除换行符外的任意字符
- ※ 量词,匹配前面字符1个或多个
- ?
- 跟在字符后,代表匹配前面字符1个或0个
- 跟踪量词后,代表非贪婪式匹配
- ()把要匹配的值放到括号中,可以匹配多组
- 比如要从{“name”:“zx”,“age”:“18”}中用正则匹配到name值
- 正则表达式:“name”:“(.*?)”
- 比如匹配到name值和age值
- 正则表达式:“name”:“(.* ?)“,“age”:”(. *?)”
- 比如要从{“name”:“zx”,“age”:“18”}中用正则匹配到name值
- 贪婪匹配 VS 非贪婪匹配
- 贪婪匹配:
- 尽可能多的匹配,匹配到最后一个截至字符之前
- 如上面那个例子,如果正则表达式不带?:“name”:“(.*)”
- 结果会匹配到 zx",“age”:"18
- 非贪婪匹配:
- 尽可能少的匹配,匹配到截至字符第一次出现之前
- 如上面例子,正则表达式加上?
- 结果会匹配到zx
- 贪婪匹配:
- 模板:
- 作用:正则表达式可能提取多组值,如上面的name和age.模板就是将提取到的多组值进行拼接或赋值给不同变量
- 使用:
- 赋值给同一个变量:
- 仅要第一个name:$ 1$
- 要拼接后的:$ 1$$ 2$
- 赋值给不同变量:
- $ 1$, $ 2$
- 就会将zx赋值给变量name,18赋值给变量age
- $ 1$, $ 2$
- 赋值给同一个变量:
- 匹配数字:
- 作用:当正则表达式匹配到多个结果时,指定使用哪个结果
- 比如,响应体中有多个{“name”:“zx”,“age”:“18”},{“name”:“zx2”,“age”:“19”},{“name”:“zx3”,“age”:“20”} 都满足正则表达式
- 0:代表随机一组数据
- 1 :代表提取第1组数据:zx和18
- -1 :代表提取所有数据
- 提取后变量名会自动加后缀_1,_2,_3,如name_1= zx name_2 = zx1…
- 作用:当正则表达式匹配到多个结果时,指定使用哪个结果
- 要检查的响应字段(提取来源):
JSON提取器
- 作用:提取json格式的响应内容
- 添加步骤:【取样器】右击【添加】-【后置处理器】-【JSON处理器】
- 使用说明:
XPath提取
跨线程组接口关联
JMeter属性
- 作用:
- 将提取到的接口响应信息存储到JMeter属性中,供跨线程组的请求使用该属性【类似代码中的全局变量】
- 实现跨线程组、线程的数据共享
- 添加步骤:
-
- 提取线程组1中的请求结果
-
- 线程组1中的请求结果中设置为JMeter属性
- 【线程组1】右击【添加】-【取样器】-【BeanShell取样器】-使用【函数__SetProperty 将变量设置为JMeter属性】
-
- 其他线程组均可访问该属性
- 使用【函数__property提取JMeter属性】
-
函数__Setproperty
- 作用:将变量存储为JMeter属性
- 使用说明:
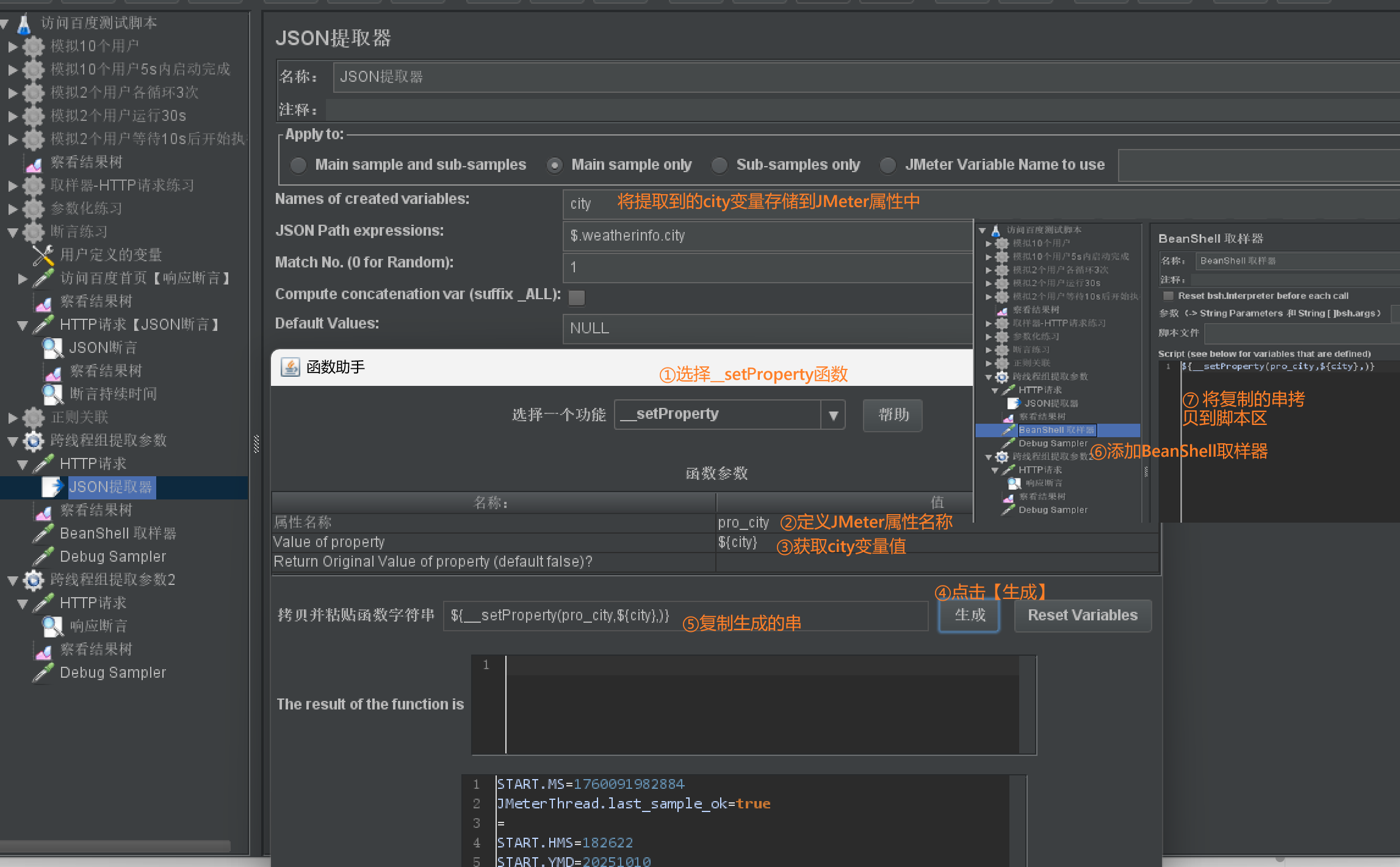
- 生成的语法说明:
- $(__setProperty(属性名称, ${线程变量名},))
- 第一个参数:属性名称,用于后续其他线程访问
- 第二个参数:线程变量名,获取到该值并将它存储到属性名称中
- 第三个参数:作用域,空代表全局
Beanshell取样器
-
作用:
- 执行JAVA like脚本,实现复杂逻辑
- 通过内置的vars、pros完成线程内变量和JMeter属性的转换
-
使用说明:
- 可以执行__SetProperty函数生成的语法,将线程变量设置为全局属性
- 可以自定义编写java like脚本,实现变量转换数据共享
- vars对象
- 作用:操作线程变量
- 语法:
- 获取线程变量
vars.get('key') - 设置线程变量
vars.put('key1','value1')
- 获取线程变量
- props对象
- 作用: 操作JMeter属性
- 语法:
- 获取全局变量
props.get('pro_key') - 设置全局变量
props.put('pro_key1','value1')
- 获取全局变量
- vars对象
-
示例:
- 获取线程变量token值 并将其存储为全局变量pro_token
//提取token值
String token = vars.get('token')
//对token进行特殊处理
String beanshell_token = 'beaner'+token
//将处理后的token设置为全局变量
props.put('pro_token',beanshell_token)
函数__property
- 作用:提取JMeter属性
- 使用说明:
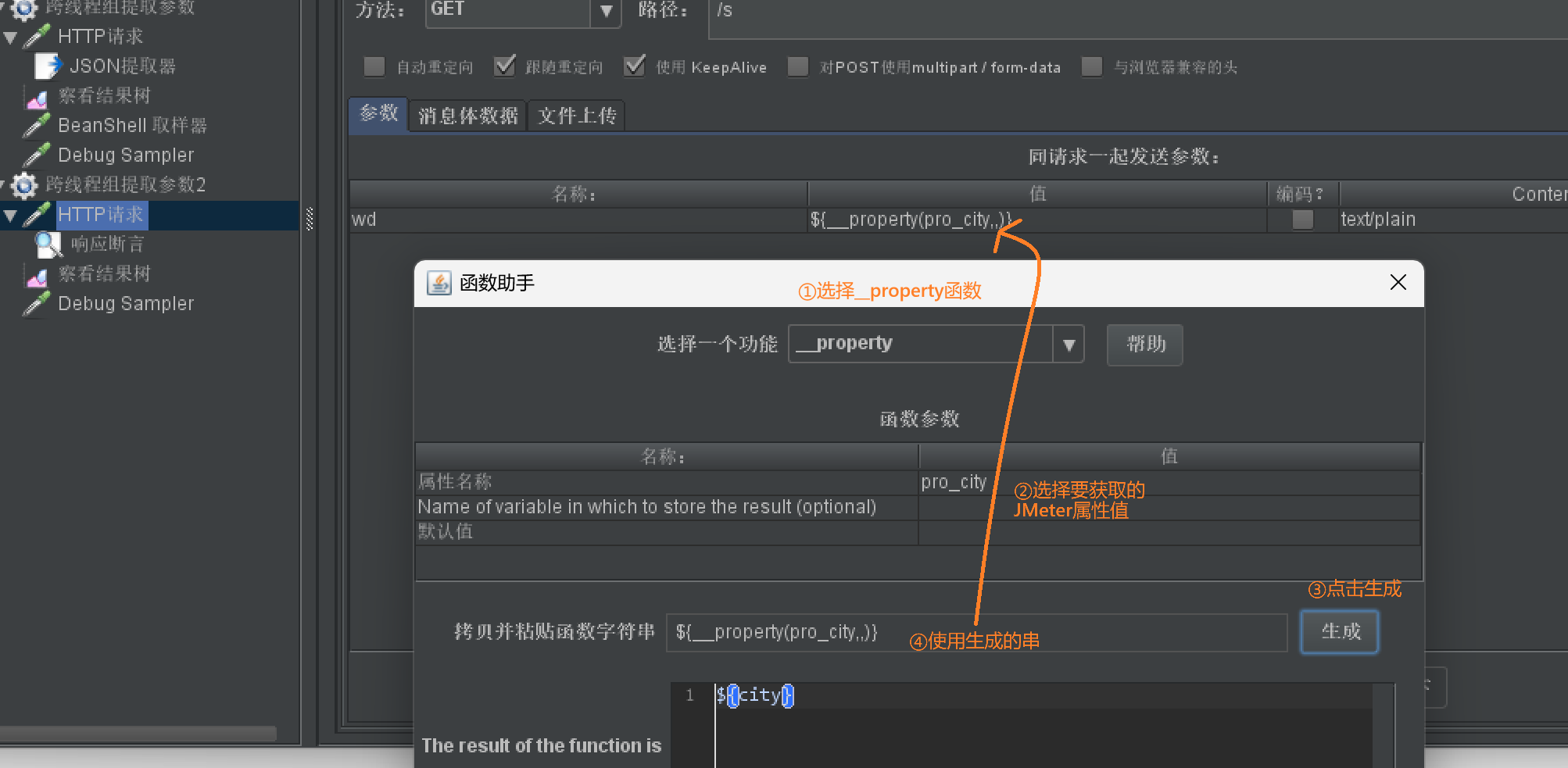
JMeter脚本录制
- 作用:抓包
- 使用步骤
-
- 【测试计划】右击【添加】-【非测试元件】-【HTTP代理服务器】
-
- 配置【HTTP代理服务器】
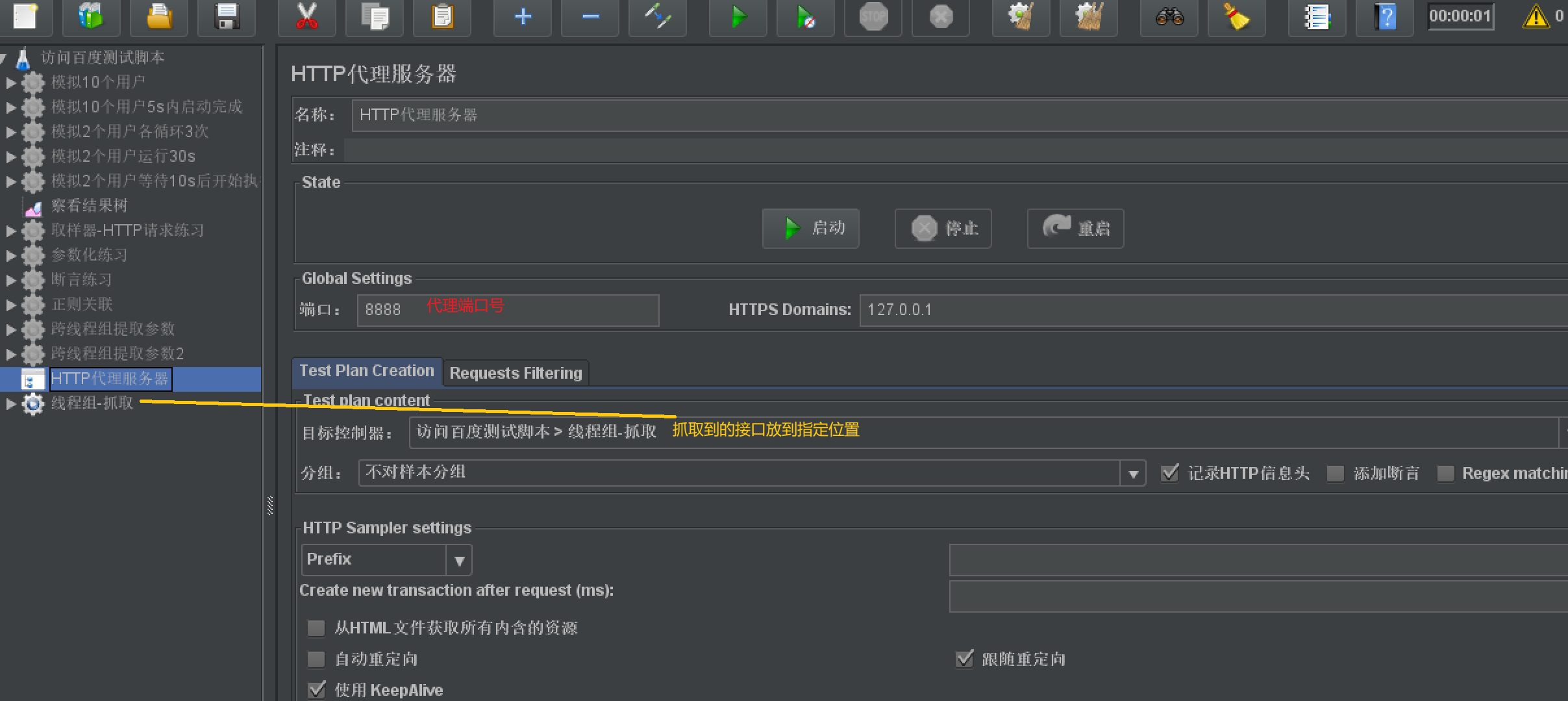
- 配置【HTTP代理服务器】
-
- 设置系统代理服务器
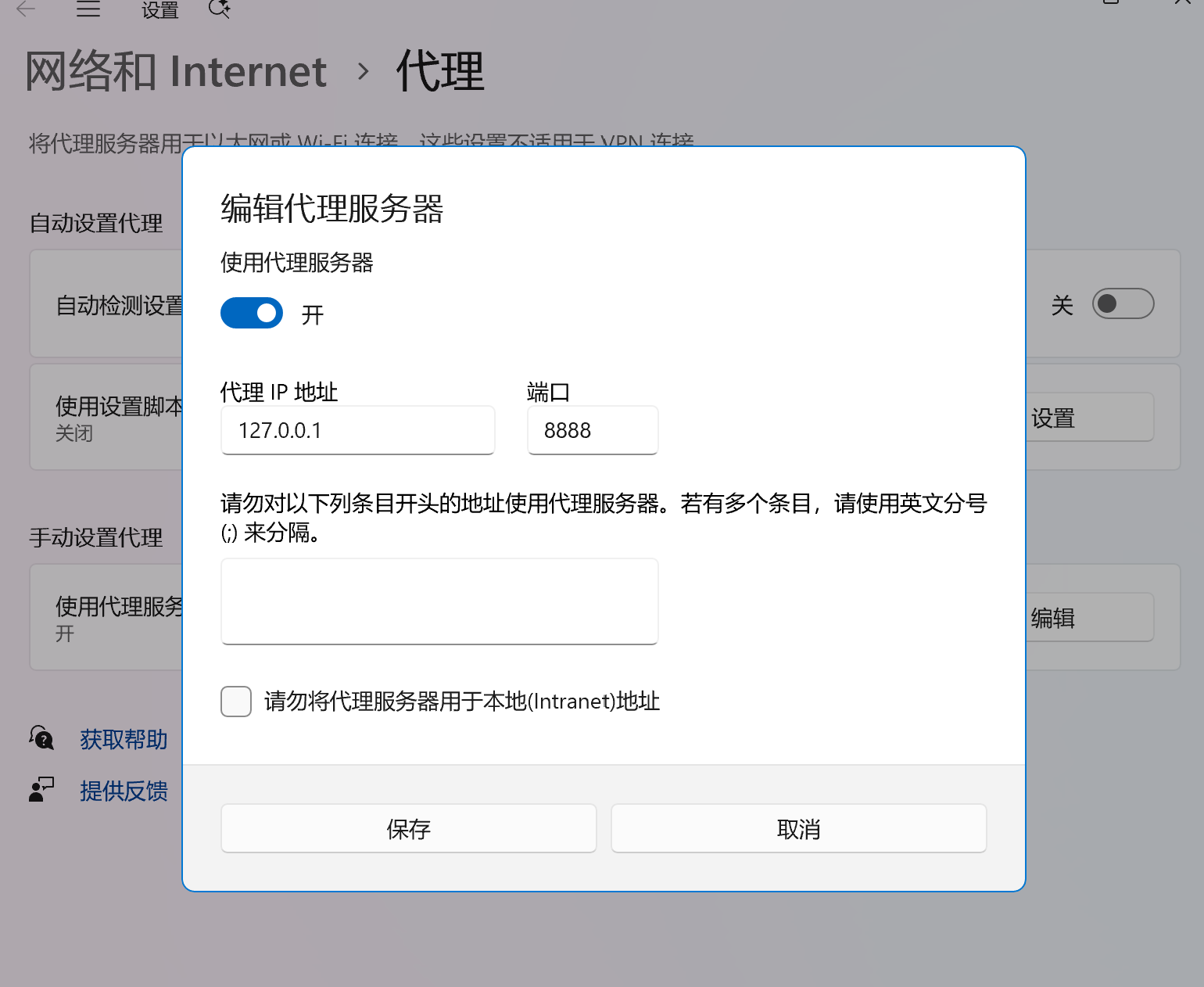
- 设置系统代理服务器
-
- 启动,开始访问浏览器
-
过滤
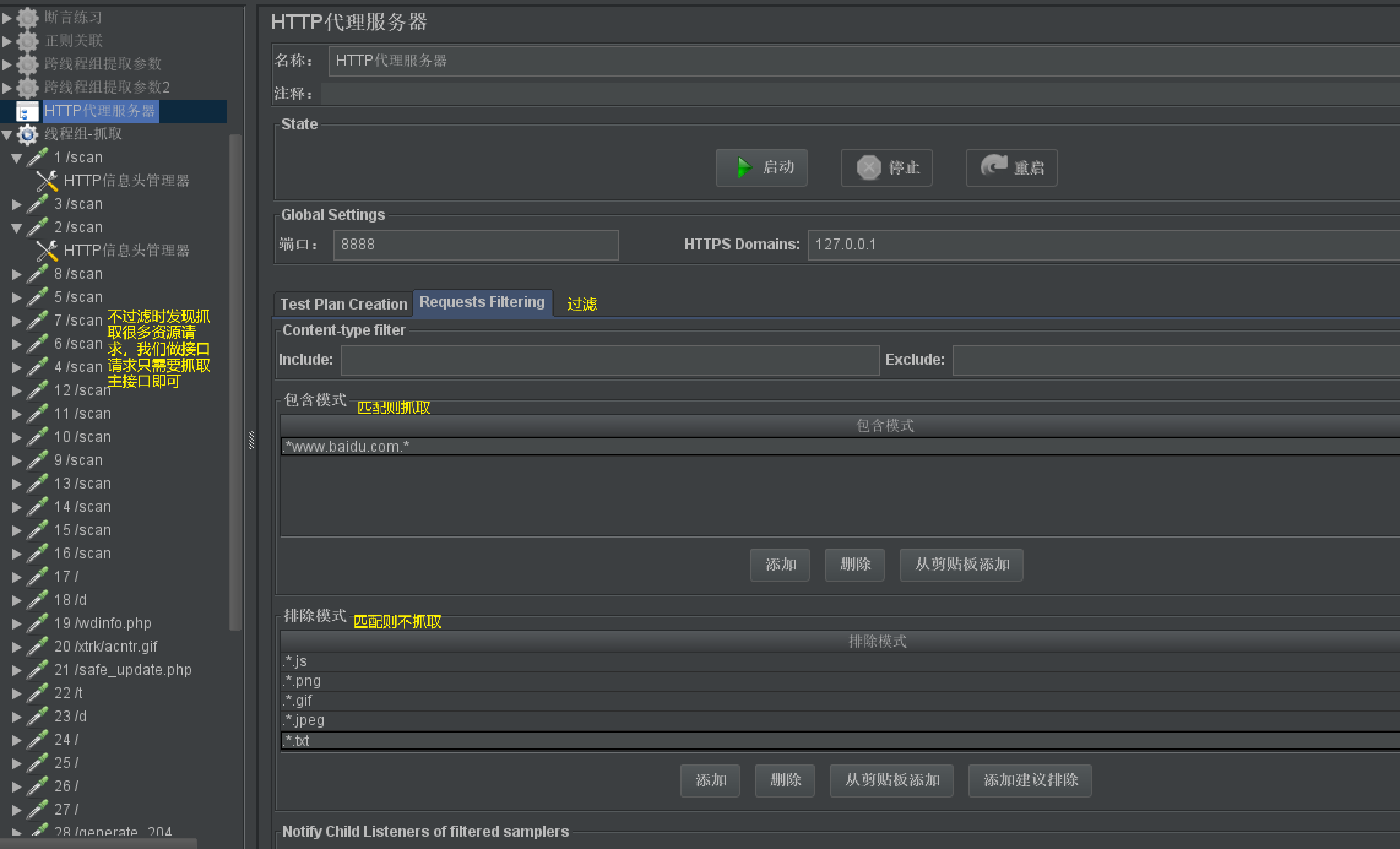
JMeter直连数据库
- 作用:
- 用于参数化
- 用于校验数据(断言)
- 用于构造数据
- 用于删除数据
- 使用步骤:
-
- 下载数据库相关jar包,放到jmeter安装目录的lib\ext目录下
JDBC是Java访问数据库的标准接口,依赖各数据库驱动jar包,根据数据库类型和版本下载对应驱动
- (一)在各数据库官网下
- mysql官方下载网站(需选择对应版本的 zip 包,解压后获取 jar)
- Oracle:Oracle官网(需注册 Oracle 账号,下载对应 ojdbc 版本)
- SQL Server:Microsoft 官网
- (二)Maven 中央仓库(推荐,无需注册)
- 访问Maven 中央仓库 ,搜索驱动名称(如mysql-connector-java),选择对应版本后,点击 “Files” 下载jar包(无需下载 pom 或源码)。例:搜索mysql-connector-java → 选择 8.0.33 → 下载mysql-connector-java-8.0.33.jar。
- (三)数据库自带jar
- 数据库安装目录部分数据库安装时会自带 JDBC 驱动(如 Oracle 的ORACLE_HOME/jdbc/lib/目录下有ojdbc.jar),可直接复制使用。
- 下载数据库相关jar包,放到jmeter安装目录的lib\ext目录下
-
- 重启JMeter
-
- 配置数据库连接信息
- 【线程组】右击【添加】-【配置元件】-【JDBC Connection Configuration】
-
- 发送JDBC请求
- 【线程组】右击【添加】-【取样器】- 【JDBC请求】
-
配置元件-JDBC Connection Configuration
- 作用: 定义数据库连接池,配置数据库连接基本信息
- 使用说明:
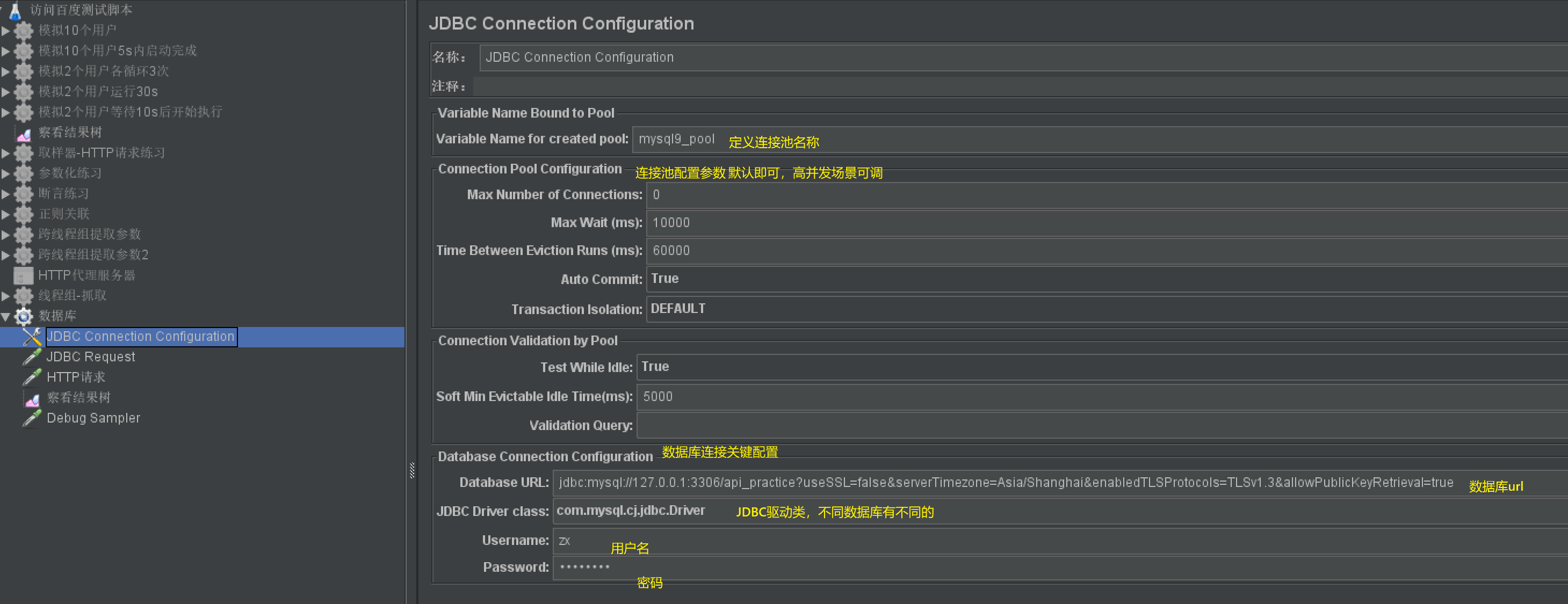
目前MySQL 9.x(如9.0及以上版本)是MySQL的较新版本(延续了8.x的架构演进),其JDBC驱动适配、连接配置与8.x类似,但需注意驱动版本兼容性和细节调整。以下是MySQL 9.x在JMeter中的完整配置指南:
一、MySQL 9.x对应的JDBC驱动版本
MySQL 9.x的JDBC驱动仍使用官方的 mysql-connector-java(由Oracle维护),版本选择需满足:
- 推荐驱动版本:
9.0.x(如9.0.0、9.0.1,与MySQL 9.x主版本匹配) - 兼容性说明:
- MySQL 9.x驱动(9.0.x)向下兼容MySQL 8.x,但不兼容5.x(5.x数据库需用8.0.x或5.1.x驱动);
- 若暂时没有9.0.x驱动,8.0.30+版本的驱动也可连接MySQL 9.x(但可能缺失9.x新增特性的支持)。
二、JMeter核心配置步骤
1. 驱动安装
将下载的mysql-connector-java-9.0.0.jar放入JMeter的lib目录(如D:\apache-jmeter-5.6\lib\),重启JMeter使驱动生效。
2. JDBC Connection Configuration(连接池配置)
添加路径:右键线程组 → 添加 → 配置元件 → JDBC Connection Configuration
关键配置项(针对MySQL 9.x):
| 配置项 | 具体值/说明 |
|---|---|
| Variable Name of Pool | 自定义连接池名称(如mysql9_pool),需与后续JDBC请求的“Variable Name”一致。 |
| Driver class | com.mysql.cj.jdbc.Driver(MySQL 8.x及以上统一使用此驱动类,9.x延续该类)。 |
| Connection URL | 格式:jdbc:mysql://[IP地址]:[端口]/[数据库名]?参数1&参数2&... 示例: jdbc:mysql://127.0.0.1:3306/testdb?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&enabledTLSProtocols=TLSv1.3 必选参数说明: - useSSL=false:禁用SSL(测试环境常用,生产环境可按需开启);- serverTimezone=Asia/Shanghai:指定时区(MySQL 8.x+强制要求,9.x延续);- enabledTLSProtocols=TLSv1.3:MySQL 9.x默认增强了TLS协议,需指定支持的协议版本(否则可能报“SSL握手失败”);- allowPublicKeyRetrieval=true:允许获取服务器公钥(可选,避免权限相关错误)。 |
| Username | 数据库登录账号(如root)。 |
| Password | 数据库登录密码(如123456)。 |
三、关键注意事项
-
JDK版本要求:
MySQL 9.x驱动(9.0.x)最低支持JDK 11+,若JMeter使用JDK 8会报“类版本不兼容”错误,需升级JMeter的JDK至11或更高版本(查看JMeter的JDK版本:启动JMeter,控制台首行显示Java Version)。 -
TLS协议兼容性:
MySQL 9.x默认启用TLS 1.3,若驱动版本过低(如8.0.20以下),可能因不支持TLS 1.3导致“SSL handshake failed”,解决方案:- 升级驱动至8.0.30+或9.0.x;
- 连接URL中添加
enabledTLSProtocols=TLSv1.3(明确指定协议)。
-
时区必须配置:
与MySQL 8.x一样,9.x强制要求指定serverTimezone(如Asia/Shanghai),否则会报“The server time zone value is unrecognized”错误。
四、配置验证
添加“查看结果树”和“Debug Sampler”,运行测试后:
- 若“JDBC Request”的响应显示SQL执行结果,则配置成功;
- 若报错“Communications link failure”,检查IP、端口、防火墙;
- 若报错“Unknown system variable”,检查驱动版本是否适配MySQL 9.x。
总结:MySQL 9.x在JMeter中的配置与8.x类似,核心是使用9.0.x驱动、正确配置com.mysql.cj.jdbc.Driver和包含时区、TLS协议的连接URL,并确保JDK版本≥11。
取样器-JDBC请求
- 作用:执行SQL语句
- 使用说明:
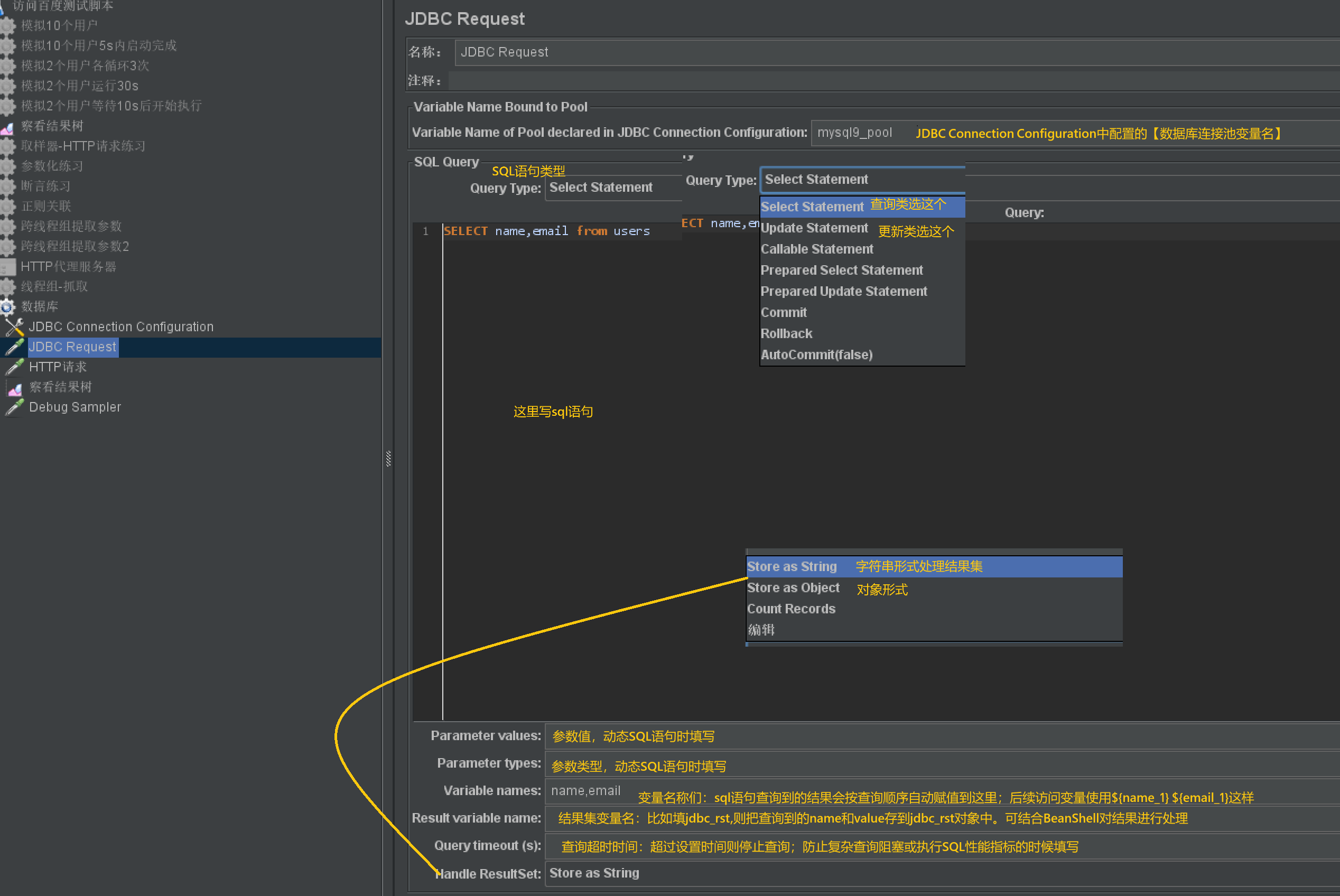
JDBC Request(执行SQL)
添加路径:右键线程组 → 添加 → 取样器 → JDBC Request
核心配置:
| 配置项 | 说明 |
|---|---|
| Variable Name of Pool | 填写与连接池配置一致的名称(如mysql9_pool),绑定连接池。 |
| Query Type | 根据SQL类型选择: - 查询用“Select Statement”; - 增删改用“Update Statement”。 |
| Query | 填写SQL语句(末尾不要加;),示例:SELECT id, name FROM users WHERE age > 18 |
| Variable names | 提取结果到变量(如userId,name,后续用${userId_1}取第一个id)。 |
在JMeter的JDBC Request中,Parameter Values、Result variable name、Parameter types、Query timeout等配置项用于处理带参数的SQL语句、结果集的复杂处理、参数类型匹配和执行超时控制。这些配置在实际测试中(尤其是动态SQL、复杂结果处理场景)非常关键,以下是详细说明:
一、Parameter Values(参数值)
- 作用
当SQL语句中包含占位符(?) 时(即预处理语句,如INSERT INTO user(name, age) VALUES(?, ?)),Parameter Values用于填写占位符对应的具体值,实现“动态传参”。 - 语法与用法
- 多个参数用逗号分隔,顺序必须与SQL中占位符的顺序一致。
- 字符串类型的参数需用单引号包裹(或根据数据库语法规则),数字类型直接写值。
- 适用场景
-
- 动态插入数据:测试时需要向表中插入不同的测试数据(如不同的用户名、年龄)。
- 例:SQL为
INSERT INTO user(name, age) VALUES(?, ?),需插入用户"test1"(20岁)和"test2"(30岁): - 若一次插入一条,
Parameter Values填'test1', 20; - 若结合CSV数据文件(多组数据),可通过变量引用(如
${name}, ${age})。
-
- 带条件的查询/更新:SQL条件为动态值(如根据不同
id查询用户)。
- 例:SQL为
SELECT * FROM user WHERE id = ?,Parameter Values填100(查询id=100的用户)。
- 带条件的查询/更新:SQL条件为动态值(如根据不同
-
二、Parameter types(参数类型)
- 作用
指定Parameter Values中参数的数据类型,确保与数据库字段的类型匹配(如整数、字符串、日期等),避免因类型不兼容导致SQL执行失败。 - 语法与用法
- 与
Parameter Values一一对应,多个类型用逗号分隔,顺序必须一致。 - 类型需使用JDBC规范的类型名称(对应
java.sql.Types类中的常量),常见类型如下:
- 与
| 常用类型 | 说明 | 对应数据库字段示例 |
|---|---|---|
INTEGER | 整数类型 | MySQL的int,Oracle的NUMBER(10) |
VARCHAR | 字符串类型 | MySQL的varchar,Oracle的VARCHAR2 |
DATE | 日期类型(仅日期) | MySQL的date |
TIMESTAMP | 时间戳类型(日期+时间) | MySQL的datetime |
DECIMAL | 高精度小数类型 | MySQL的decimal(10,2) |
-
适用场景
只要SQL中使用了占位符(即填写了Parameter Values),就必须配置Parameter types,否则可能出现“类型转换错误”。例:
- SQL:
INSERT INTO user(name, age, reg_time) VALUES(?, ?, ?) Parameter Values:'test', 25, '2023-10-01 12:00:00'- 对应
Parameter types:VARCHAR, INTEGER, TIMESTAMP
- SQL:
三、Result variable name(结果变量名)
-
作用
将SQL执行的完整结果集(ResultSet) 存储到指定的JMeter变量中,后续可通过BeanShell等脚本对结果集进行复杂处理(如遍历、统计、条件判断等)。 -
语法与用法
- 填写自定义变量名(如
userResult),无需符号包裹。 - 存储的是Java的
ResultSet对象,需通过BeanShell的vars.getObject("变量名")获取并操作。
- 填写自定义变量名(如
-
适用场景
-
- 复杂结果处理:查询结果需要遍历多条数据,或进行计算(如求和、平均值)。
例:查询user表中所有年龄>18的用户,需统计这些用户的数量:
Result variable name填adultUsers;- 添加BeanShell后置处理器,脚本:
- 复杂结果处理:查询结果需要遍历多条数据,或进行计算(如求和、平均值)。
// 获取结果集 ResultSet rs = vars.getObject("adultUsers"); int count = 0; // 遍历结果集统计数量 while(rs.next()) {count++; } // 将统计结果存入变量 vars.put("adultCount", String.valueOf(count));-
后续可通过
${adultCount}引用统计结果。 -
- 获取结果集元数据:需要获取字段名、字段类型等信息(如动态验证表结构)。
-
四、Query timeout (seconds)(查询超时时间)
-
作用
- 设置SQL语句的最大执行时间(单位:秒)。若SQL执行时间超过该值,JMeter会强制终止执行,并标记为“超时失败”。
-
语法与用法
- 填写非负整数:
0表示“不超时”(默认值);5表示超时时间为5秒。
- 填写非负整数:
-
适用场景
-
防止长耗时SQL阻塞测试:执行复杂查询(如多表关联、大数据量统计)时,可能因耗时过长导致测试卡住,设置超时时间可控制风险。
例:执行SELECT * FROM large_table WHERE status = 1(表中数据量100万+),设置Query timeout为10(最多允许执行10秒,超时则失败)。 -
验证SQL性能:测试SQL的响应时间是否在预期范围内(如核心查询必须在3秒内完成,超时则视为不达标)。
-
(五) Handle ResultSet的常见选项及作用
不同 JMeter 版本的选项名称可能略有差异,但核心逻辑一致,常见选项如下:
-
- Store as String(默认选项)
-
作用:
将结果集(ResultSet)转换为字符串格式(类似表格的文本形式),存储在 JMeter 的响应数据中,可在 “查看结果树” 中直接查看。
存储形式:结果会以 “列名 + 值” 的结构化字符串呈现,例如:
id,name,age
1,张三,20
2,李四,25 -
适用场景:
需要直观查看查询结果(如调试阶段验证 SQL 是否正确);
不需要对结果进行复杂处理,仅需确认 “是否有数据” 或 “数据是否符合预期”。
-
- Store as Object
- 作用:
将结果集以Java 对象(ResultSet 实例) 的形式存储(不转换为字符串),需通过Result variable name配置的变量名引用(如userResult)。
特点:保留结果集的原始结构(可通过 Java 方法遍历、获取字段值等),但 “查看结果树” 中不会显示具体数据(仅显示 “ResultSet stored as object”)。 - 适用场景:
需要通过 BeanShell、Groovy 等脚本对结果集进行复杂处理(如遍历多条记录、筛选特定数据、计算总和等);
例:结合Result variable name使用,脚本中通过vars.getObject(“userResult”)获取结果集对象,再调用rs.next()遍历数据。
-
- Count Records
- 作用:
不存储完整结果集,仅统计查询返回的记录行数,并将行数存储在变量中(变量名为${__jmeter.ResultSet.rowCount})。 - 特点:结果集中的具体数据会被忽略,仅保留 “记录数” 这一统计值。
- 适用场景:
只关心 “查询返回了多少条数据”(如验证 “新增数据后,查询总数是否 + 1”);
避免存储大量数据导致内存占用过高(如查询 10 万条记录时,仅统计行数更高效)。
-
- Nothing
- 作用:完全不处理结果集,既不存储字符串,也不保留对象,更不统计行数。
- 特点:“查看结果树” 中不会显示任何查询结果(响应数据为空)。
- 适用场景:
执行查询仅为 “触发某种数据库行为”(如刷新视图、预热缓存),无需关注结果;
希望最大化性能(减少结果处理的资源消耗)。
总结:何时需要配置这些项?
| 配置项 | 触发条件(何时需要配置) |
|---|---|
Parameter Values | SQL语句包含占位符(?),需要动态传入参数(如INSERT、带变量条件的SELECT)。 |
Parameter types | 与Parameter Values配套使用,只要有参数就必须指定类型,确保类型匹配。 |
Result variable name | 需要对查询结果进行复杂处理(遍历、统计、元数据获取),而非简单提取字段值。 |
Query timeout | 执行可能耗时较长的SQL(如复杂查询、大数据量操作),需控制执行时间或验证性能。 |
这些配置项的核心价值是:让JMeter的数据库操作更灵活(支持动态参数)、更可控(超时控制)、更强大(复杂结果处理),适用于需要深度数据库交互的测试场景(如数据准备、结果验证、性能校验等)。
取样器-Debugger Sample
-
作用:是一个专门用于调试和排查脚本问题的组件,它的核心作用是:收集并展示JMeter运行时的关键数据(如变量、属性、系统信息等),帮助测试人员验证变量提取是否正确、参数传递是否生效、属性是否跨线程组共享等。
-
核心功能
Debug Sampler本身不会发送任何实际请求(如HTTP请求、数据库请求),也不会影响测试流程,它的唯一作用是:
在运行测试时,自动收集当前JMeter的线程变量(vars)、全局属性(props)、系统属性、环境变量等数据,并以结构化的形式输出,供测试人员在“查看结果树”中查看。 -
主要展示内容
Debug Sampler默认会输出以下几类关键信息(可通过配置控制显示范围):-
- 线程变量(Variables):
显示当前线程组内的所有线程变量(如通过提取器提取的token、userId,或通过BeanShell设置的vars.put("key", "value")变量)。
例:token=abc123、userId=100。
- 线程变量(Variables):
-
- JMeter属性(Properties):
显示全局属性(如通过__SetProperty函数或props.put()设置的跨线程组属性)。
例:globalToken=abc123(跨线程组共享的属性)。
- JMeter属性(Properties):
-
- 系统属性(System Properties):
显示JMeter运行的系统环境信息(如JDK版本、JMeter安装路径、操作系统信息等)。
例:java.version=11.0.18、user.dir=D:\apache-jmeter-5.6。
- 系统属性(System Properties):
-
- 环境变量(Environment Variables):
显示操作系统的环境变量(如PATH、JAVA_HOME等)。
- 环境变量(Environment Variables):
-
配置与使用方法
-
添加Debug Sampler:
右键线程组 → 添加 → 取样器 → Debug Sampler。 -
配置选项:
Debug Sampler的配置非常简单,主要有两个可选参数(默认即可满足大部分需求):Name:自定义名称(如“调试用户信息”);Properties to display:指定要显示的信息类型(默认All,即显示所有信息;也可选择Variables only仅显示线程变量,Properties only仅显示全局属性等)。
-
查看结果:
添加“查看结果树”组件,运行测试后,在“查看结果树”中找到Debug Sampler的响应,即可看到结构化的变量、属性等信息。
适用场景
Debug Sampler是JMeter调试的“利器”,以下场景必须使用:
-
验证变量提取是否正确:
用正则提取器、JSON提取器等提取变量后,通过Debug Sampler查看变量值是否符合预期(如token是否成功提取,避免因提取失败导致后续请求报错)。 -
检查跨线程组属性是否生效:
跨线程组共享属性时(如线程组1设置globalToken,线程组2使用),通过Debug Sampler在两个线程组中分别查看globalToken是否存在且值正确。 -
排查参数传递问题:
当请求参数引用变量(如${userId})但运行结果不符合预期时,通过Debug Sampler确认变量是否存在、值是否正确(避免因变量名拼写错误、未提取到值等导致参数无效)。 -
查看系统环境信息:
调试驱动加载失败(如JDBC驱动)、版本不兼容等问题时,可通过“System Properties”查看JDK版本、JMeter版本等信息,辅助定位问题(如驱动版本与JDK版本不匹配)。
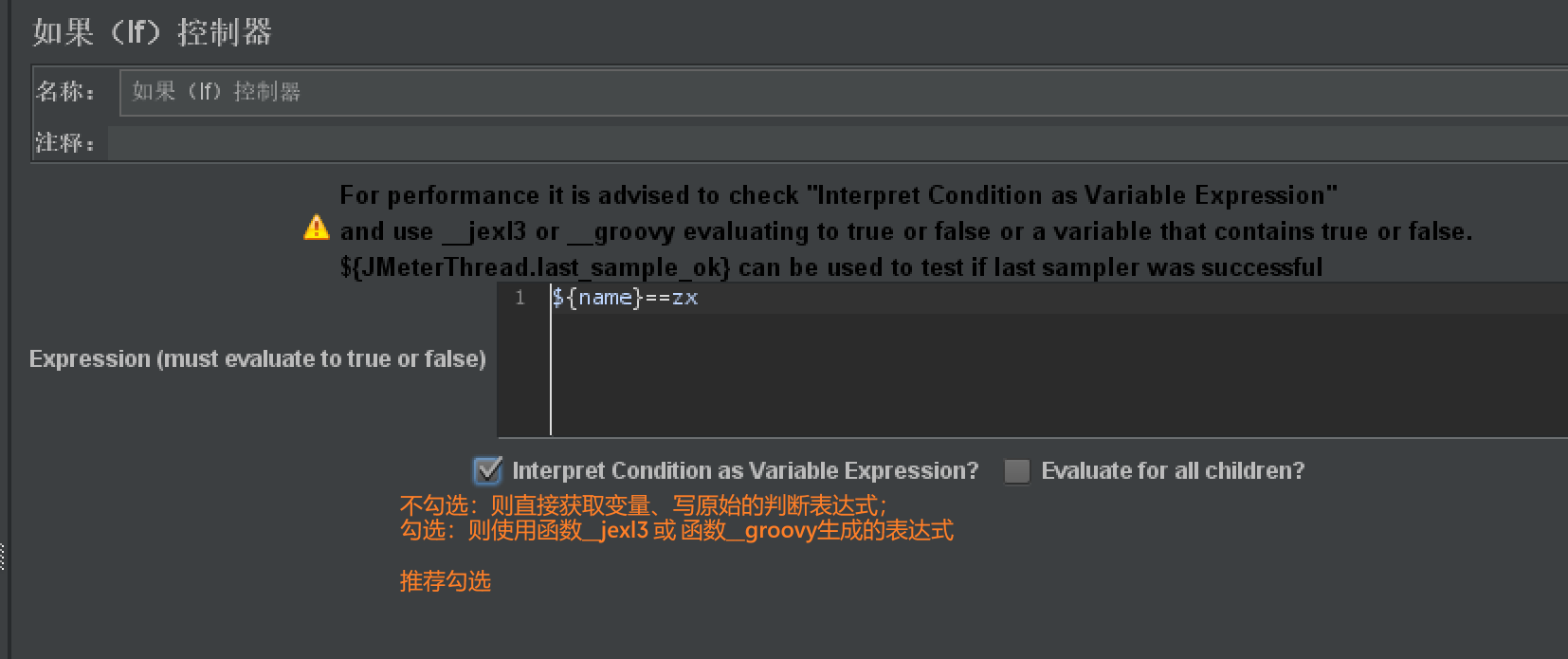
逻辑控制器
IF控制器
- 作用:控制元件是否执行
- 使用步骤:【线程组】右击【添加】-【逻辑控制器】-【IF控制器】
- 使用说明:
循环控制器
- 作用:控制元件循环执行次数
- 使用步骤:【线程组】右击【添加】-【逻辑控制器】-【循环控制器】
- 使用说明:
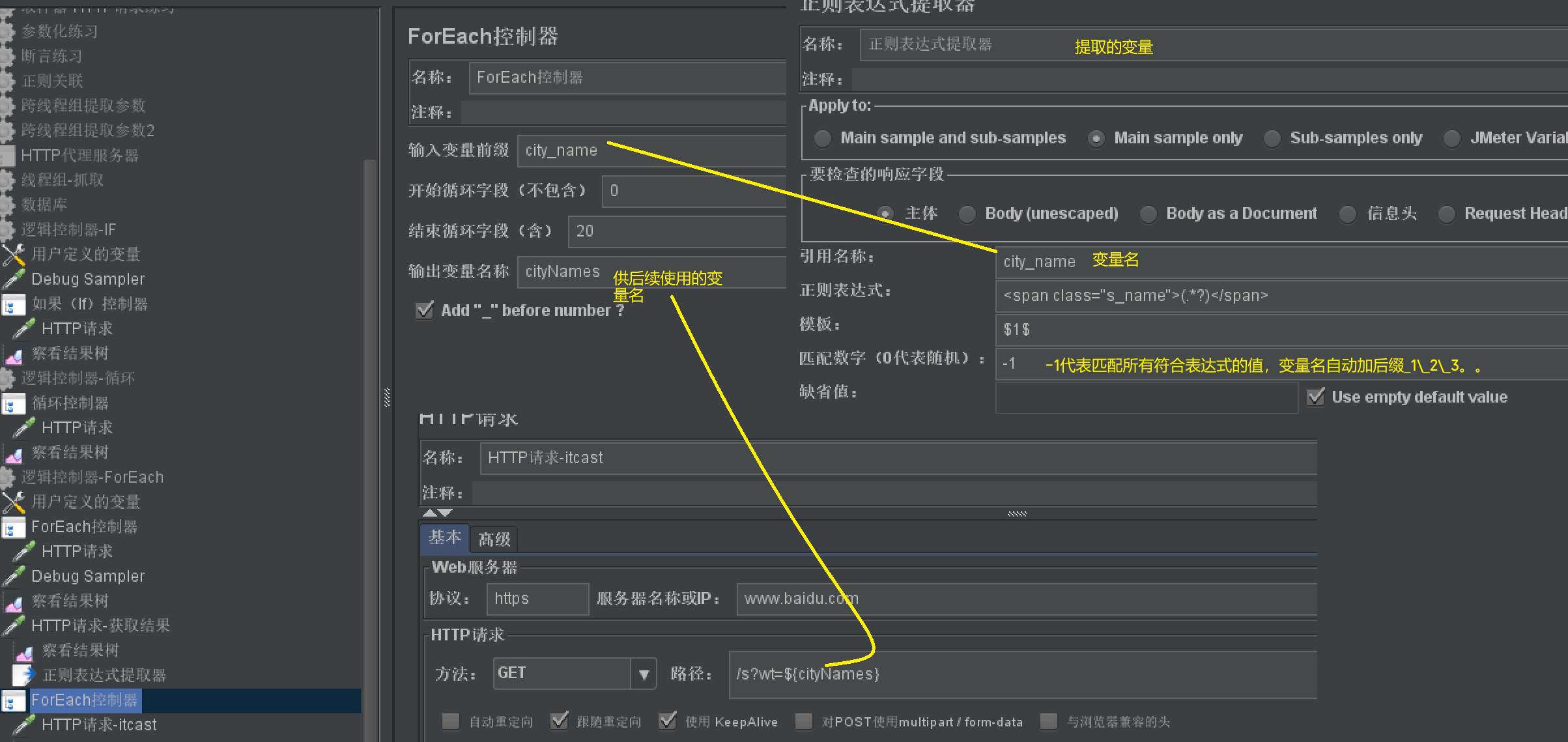
ForEach控制器
- 作用:类似代码的for循环,循环读取容器中的每个变量
- 使用场景:比如正则提取器中提取到多个数据,又选择-1,此时就是多个结果集,变量名后缀依次添加后缀_1_2、。。。;此时就需要foreach循环来接收每个值
- 使用步骤:【线程组】-【逻辑控制器】-【ForEach控制器】
- 使用说明:
定时器
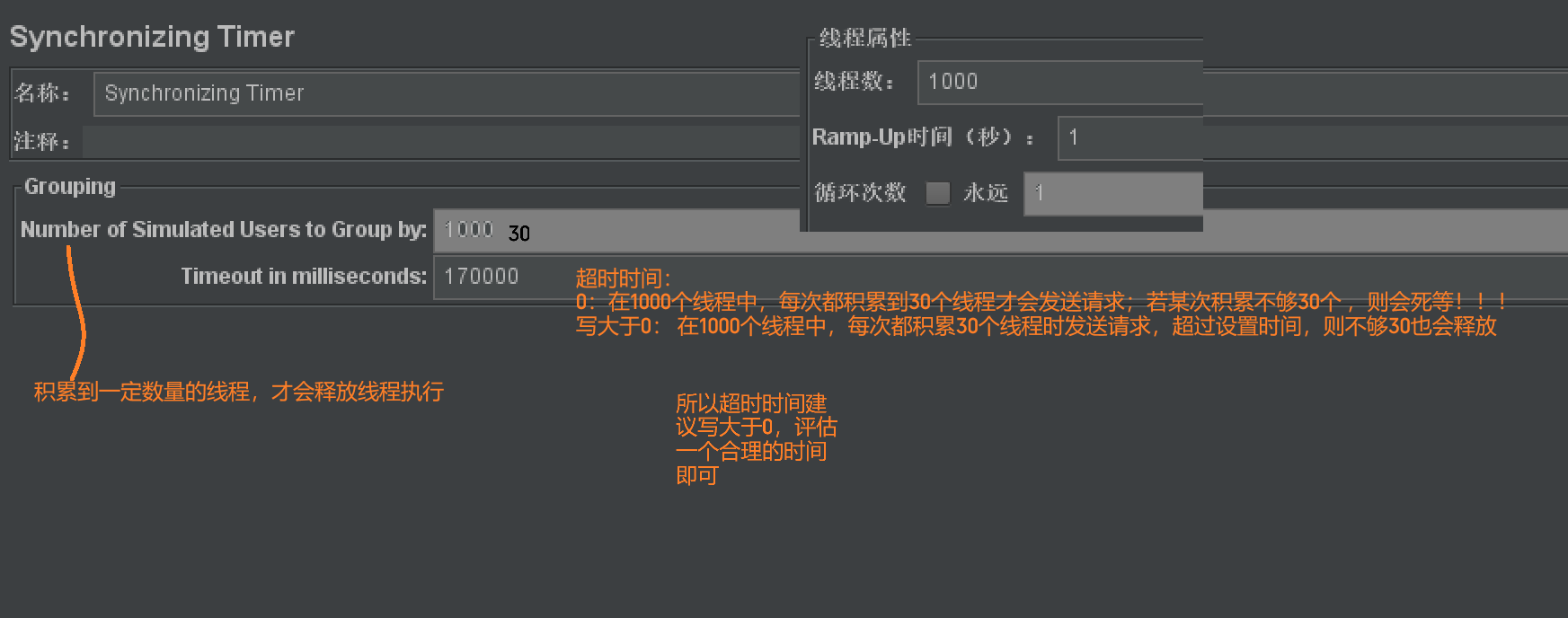
同步定时器synchronizing Timer
- 作用:阻塞线程,积累到一定数量的线程数后才开始同时发送请求
- 场景:模拟同步并发
- 模拟1W人抢红包
- 模拟1W人秒杀
- 使用说明:
- 【线程组】设置并发用户数量
- 【线程组】-【取样器】-【HTTP取样器】 添加要测试的接口
- 【HTTP取样器】-【定时器】-【synchronizing Timer】
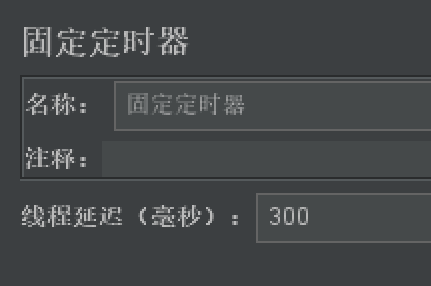
固定定时器
- 作用:控制组件启动时间
- 场景:比如密码验证接口,如果密码错误超过3次则会锁定5min,5min后才会成功
- 使用步骤:
【线程组】-【取样器】-【固定定时器】
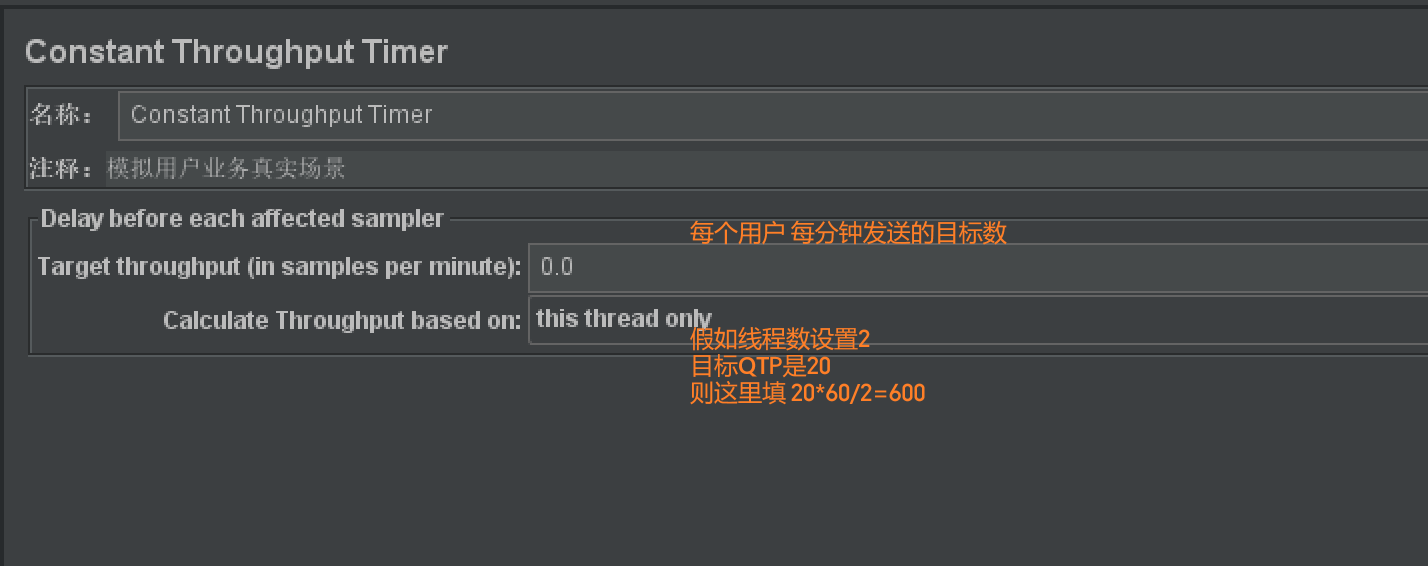
常数吞吐量定时器 Constant Throughput Timer
- 作用:以指定的吞吐量执行,模拟用户真实的业务场景
- 场景:【稳定性测试】以固定的吞吐量条件下运行
- 使用步骤:
【线程组】循环次数设置成【永远】
【取样器】-【Constant Throughput Timer】
监听器
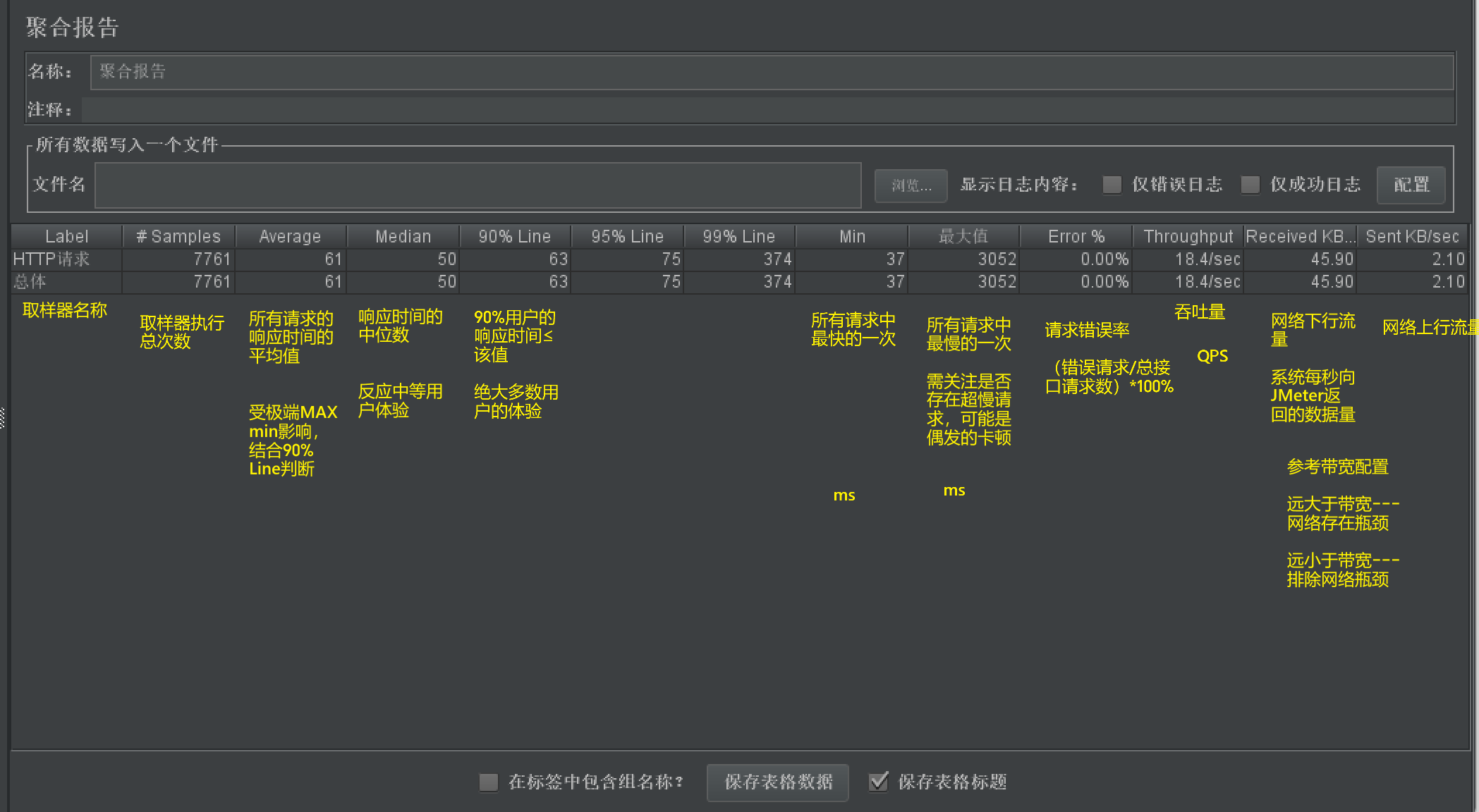
聚合报告
在JMeter中,聚合报告(Aggregate Report) 是最常用的测试结果分析组件之一,它以表格形式汇总了所有取样器(如HTTP请求、JDBC请求)的关键性能指标(响应时间、吞吐量、错误率等),帮助测试人员快速判断系统的性能表现和稳定性。以下是详细的查看指南,包括组件添加、指标解读、结果分析逻辑和注意事项。
一、聚合报告的添加步骤
首先需要在测试计划中添加聚合报告,步骤如下:
- 右键目标线程组(或“测试计划”)→ 选择 添加 → 监听器 → 聚合报告;
- (可选)右键聚合报告 → 修改列,可勾选/取消勾选需要显示的指标(如隐藏“Sent KB/sec”,仅保留核心指标)。
二、聚合报告核心指标解读(按列说明)
聚合报告的表格包含多个列,每个列对应一个关键性能指标,需重点关注以下核心列(按重要性排序):
| 列名(英文/中文) | 定义与单位 | 核心含义与解读 |
|---|---|---|
| Label(标签) | 取样器名称 | 对应测试计划中的取样器(如“登录请求”“查询订单”),同名取样器会合并统计(如需分开统计,需确保取样器名称唯一)。 |
| # Samples(样本数) | 整数(次) | 该取样器的总执行次数(= 线程数 × 循环次数,若勾选“调度器”则按时间计算)。样本数需足够多(如≥1000),统计结果才具参考性。 |
| Error %(错误率) | 百分比(%) | 该取样器执行失败的次数占总次数的比例(错误次数 / # Samples × 100%)。关键判断: - 0%:无错误,稳定性达标; - >0%:需排查错误原因(如接口报错、参数错误、服务器异常)。 |
| Throughput(吞吐量) | 次数/时间(默认:req/sec) | 系统单位时间内处理的请求数(即QPS,Queries Per Second),是衡量系统“处理能力”的核心指标。 计算逻辑: 总请求数 / 测试总耗时(秒),支持切换单位(如req/min、req/hour)。 |
| Average(平均响应时间) | 毫秒(ms) | 所有请求的响应时间平均值(总响应时间 / # Samples)。注意:平均值易受极端值(如个别超慢请求)影响,需结合百分位值(90% Line等)综合判断。 |
| Median(中位数响应时间) | 毫秒(ms) | 将所有响应时间按从小到大排序后,中间位置的数值(50%的请求响应时间≤该值,50%≥该值)。比Average更能反映“中等用户体验”。 |
| 90% Line(90%百分位响应时间) | 毫秒(ms) | 90%的请求响应时间≤该值(仅10%的请求响应时间超过该值)。 核心意义:代表“绝大多数用户的体验”(如90% Line≤500ms,说明90%用户的请求能在500ms内完成),是性能测试的核心达标指标。 |
| 95% Line / 99% Line(95%/99%百分位响应时间) | 毫秒(ms) | 逻辑同90% Line:95%/99%的请求响应时间≤该值。 99% Line更严格,代表“极端用户的体验”(需优先保障核心接口的99% Line达标)。 |
| Min(最小响应时间) | 毫秒(ms) | 所有请求中响应最快的一次耗时(参考意义较低,仅反映“最优情况”)。 |
| Max(最大响应时间) | 毫秒(ms) | 所有请求中响应最慢的一次耗时(需关注是否存在“超慢请求”,如Max=10s,可能是服务器偶发卡顿)。 |
| Received KB/sec(每秒接收数据量) | 千字节/秒(KB/s) | 系统每秒向JMeter返回的数据量(反映网络下行流量),若数值异常高(如远超带宽上限),可能存在网络瓶颈。 |
| Sent KB/sec(每秒发送数据量) | 千字节/秒(KB/s) | JMeter每秒向系统发送的数据量(反映网络上行流量),通常数值较小,参考意义较低。 |
三、聚合报告的解读逻辑(优先级排序)
拿到聚合报告后,需按以下优先级分析,快速定位问题:
1. 第一步:先看「Error %(错误率)」—— 确认系统稳定性
- 若Error % > 0%(如5%):
先排查错误原因(通过“查看结果树”查看失败请求的响应信息),常见原因包括:- 接口返回错误码(如400参数错误、500服务器内部错误);
- 线程并发过高导致服务器拒绝连接(如“Connection refused”);
- 变量提取失败(如token未正确传递)。
- 若Error % = 0%:继续分析性能指标。
2. 第二步:看「Throughput(吞吐量)」—— 确认系统处理能力
- 对比“预期吞吐量”(如需求要求核心接口QPS≥100):
- 实际Throughput ≥ 预期:处理能力达标;
- 实际Throughput < 预期:需优化系统(如优化SQL、增加服务器资源、减少接口耗时)。
- 例:测试“登录接口”,10线程循环100次,总耗时100秒,Throughput = 10×100 / 100 = 10 req/sec(QPS=10)。
3. 第三步:看「响应时间指标」—— 确认用户体验
重点关注 90% Line、95% Line、99% Line(比Average更真实),对比“预期响应时间”(如需求要求90%请求≤800ms):
- 若90% Line ≤ 预期:绝大多数用户体验达标;
- 若90% Line > 预期:需优化接口耗时(如减少数据库查询、压缩响应数据);
- 注意:若Max远大于99% Line(如99% Line=800ms,Max=10s),需排查是否存在偶发瓶颈(如服务器GC停顿、网络波动)。
4. 第四步:看「网络流量」—— 排查网络瓶颈
- 若Received KB/sec 远超服务器带宽上限(如服务器带宽100Mbps,实际流量200Mbps):
可能是网络带宽不足导致响应时间变长,需升级带宽; - 若流量正常(远低于带宽上限):排除网络瓶颈,问题出在系统本身(如CPU、内存、数据库)。
四、常见问题与注意事项
-
同名取样器合并统计:
若多个取样器名称相同(如两个“查询用户”取样器),聚合报告会将它们的结果合并计算,导致数据不准确。解决方案:确保每个取样器名称唯一(如“查询用户-接口A”“查询用户-接口B”)。 -
样本数不足导致统计失真:
若# Samples过少(如<100),Average、90% Line等指标可能不具参考性(如个别慢请求会拉高平均值)。解决方案:增加线程数或循环次数,确保样本数≥1000。 -
Throughput单位切换:
默认单位是“req/sec(每秒请求数)”,若测试时间短(如10秒),可切换为“req/min”更直观(右键Throughput列→选择单位)。 -
忽略“Min”指标:
Min仅代表“最快一次请求”,无法反映系统真实性能(可能是偶然的快响应),无需重点关注。 -
结合其他监听器辅助分析:
聚合报告仅提供汇总数据,若需定位具体问题(如哪个请求慢、为什么报错),需配合:- 查看结果树:查看失败请求的响应详情、慢请求的耗时分布;
- 用表格查看结果:查看每个请求的详细耗时、参数;
- 服务器监控(如Prometheus、JConsole):查看CPU、内存、数据库连接数等系统指标。
五、总结
聚合报告的核心价值是“快速概览系统性能”,查看流程可简化为:
先看错误率(稳定性)→ 再看吞吐量(处理能力)→ 最后看百分位响应时间(用户体验)→ 排除网络瓶颈。
通过这一流程,能快速判断系统是否达标,并定位需要优化的方向(如错误排查、性能优化、带宽升级)。
在JMeter中,除了聚合报告,还有多个常用监听器(报告组件),它们以表格、图表或结构化文本形式输出测试结果,分别适用于“详细数据查看”“趋势分析”“断言验证”等不同场景。以下是最常用的6类报告,按“使用频率+实用性”排序说明:
用表格查看结果(View Results in Table)
核心作用
以表格形式展示每一条请求的详细数据(而非聚合汇总),可直观看到单条请求的耗时、状态、参数等,是“排查单条请求问题”的核心工具。
输出形式(关键列)
| 列名 | 含义 |
|---|---|
| Sample Label | 取样器名称(如“登录请求”) |
| Sample Time | 该请求的响应时间(毫秒) |
| Status | 请求状态(Success/Failure) |
| Bytes | 响应数据大小(字节) |
| Sent Bytes | 请求数据大小(字节) |
| Latency | 延迟时间(从发送请求到接收第一个字节的时间,毫秒) |
| Error Message | 失败时的错误信息(如“404 Not Found”) |
适用场景
- 排查单条请求失败原因:直接查看“Error Message”,快速定位问题(如参数错误、接口报错);
- 分析个别慢请求:筛选“Sample Time”较大的行,查看是否有偶发的超慢请求(聚合报告的“Max”指标仅能看到最大值,表格可看具体是哪条请求);
- 验证参数传递正确性:结合“Request Data”列(需右键勾选显示),查看请求参数是否正确传递(如
token是否生效)。
汇总报告(Summary Report)
核心作用
与“聚合报告”类似,也是汇总取样器的关键性能指标,但输出更简洁(少了“95% Line”“99% Line”等严格指标),适合快速概览测试结果。
输出形式(关键列)
比聚合报告少“95% Line”“99% Line”“Received KB/sec”等列,核心保留:
Label(标签)、# Samples(样本数)、Error %(错误率)、Throughput(吞吐量)、Average(平均响应时间)、Median(中位数)、Min(最小)、Max(最大)。
适用场景
- 快速查看核心指标:不需要严格的百分位值(95%/99% Line)时,用汇总报告更简洁;
- 轻量测试场景:如接口功能+简单性能验证,无需复杂的性能分析,汇总报告足够满足需求。
与聚合报告的区别
- 聚合报告:指标更全面(含90%/95%/99% Line),适合严格的性能测试分析;
- 汇总报告:指标更精简,适合快速概览或轻量测试。
响应时间图(Response Time Graph)
核心作用
以折线图形式展示响应时间随时间的变化趋势,直观反映“响应时间是否稳定”“是否存在阶段性延迟”。
输出形式
- X轴:时间(测试开始后的分钟/秒);
- Y轴:响应时间(毫秒);
- 每条线代表一个取样器(不同颜色区分)。
适用场景
- 分析响应时间稳定性:若折线平稳(无大幅波动),说明系统响应时间稳定;若折线突然飙升(如某时间点响应时间从200ms涨到2000ms),可能是服务器资源不足(如CPU飙升)或网络波动;
- 定位性能瓶颈出现的时间点:结合测试过程,判断是“并发量增加时”还是“测试后期(如内存泄漏)”出现响应时间变长;
- 对比不同取样器的响应时间:同一图表中查看多个取样器的响应时间,快速识别“哪个接口最耗时”。
断言结果(Assertion Results)
核心作用
专门展示所有断言的执行结果(如响应断言、JSON断言、JDBC断言等),帮助排查“为什么请求成功但断言失败”的问题。
输出形式(关键列)
| 列名 | 含义 |
|---|---|
| Sample Label | 关联的取样器名称 |
| Assertion Name | 断言名称(如“验证code=200”) |
| Status | 断言状态(Success/Failure) |
| Failure Message | 断言失败时的原因(如“预期code=200,实际code=500”) |
适用场景
- 排查断言失败原因:当“用表格查看结果”显示请求“Success”但断言失败时,通过此报告查看具体是哪个断言失败、失败原因(如JSON断言的预期值不匹配);
- 验证多断言的执行情况:一个取样器添加多个断言(如同时验证code=200和msg=“success”)时,查看所有断言是否都通过。
Transactions per Second(TPS图)
核心作用
以折线图形式展示每秒完成的事务数(TPS)随时间的变化趋势,是“衡量系统处理能力稳定性”的核心可视化工具(TPS=Throughput,聚合报告的Throughput是平均值,TPS图是实时趋势)。
输出形式
- X轴:时间(测试开始后的分钟/秒);
- Y轴:TPS(每秒完成的请求数);
- 每条线代表一个取样器(或事务控制器)。
适用场景
- 分析TPS稳定性:若折线平稳(如稳定在100 TPS),说明系统处理能力稳定;若折线波动大(如从100降到20),可能是服务器瓶颈(如CPU满了、数据库连接耗尽);
- 验证系统最大TPS:在逐步增加并发的测试中,观察TPS是否随并发增加而上升,或上升到一定值后不再增长(此时的TPS即为系统最大处理能力);
- 对比不同场景的TPS:如“单接口测试”和“多接口混合测试”的TPS差异,判断是否存在接口间资源竞争。
简单数据写入器(Simple Data Writer)
核心作用
将测试结果以文本文件(如.csv/.txt)形式保存到本地,后续可通过Excel、Python等工具进行自定义分析(如计算自定义指标、画个性化图表)。
输出形式
可自定义保存的字段(右键“配置”勾选),常用字段包括:
时间戳、取样器名称、响应时间、状态、错误信息、请求参数、响应数据等。
适用场景
- 自定义数据分析:JMeter自带报告无法满足需求时(如计算“不同时间段的错误率”“按用户维度统计响应时间”),导出数据后用Excel/Python处理;
- 测试结果存档:将测试数据保存到文件,方便后续对比不同版本(如V1.0和V2.0的性能差异);
- 大规模测试:测试数据量过大时,本地监听器卡顿,导出文件后再分析更高效。
总结:不同场景如何选择报告?
| 需求场景 | 推荐报告 |
|---|---|
| 排查单条请求失败/慢请求 | 用表格查看结果 |
| 严格的性能指标分析(90%/99% Line) | 聚合报告 |
| 快速概览核心指标 | 汇总报告 |
| 查看响应时间/TPS趋势 | 响应时间图 + TPS图 |
| 排查断言失败原因 | 断言结果 |
| 自定义分析/结果存档 | 简单数据写入器 |
实际测试中,通常会组合使用多个报告(如“聚合报告+TPS图+用表格查看结果”),既看汇总指标,也看趋势和单条数据,全面分析系统性能。
https://www.bilibili.com/video/BV1S6hwzQEfz?vd_source=246e7e2186abd71f69fd22b13aaae39b&p=2&spm_id_from=333.788.player.switch
https://www.bilibili.com/video/BV12W4y197qU/?vd_source=246e7e2186abd71f69fd22b13aaae39b