【ComfyUI】SDXL Simple 实现高质量图像生成全流程
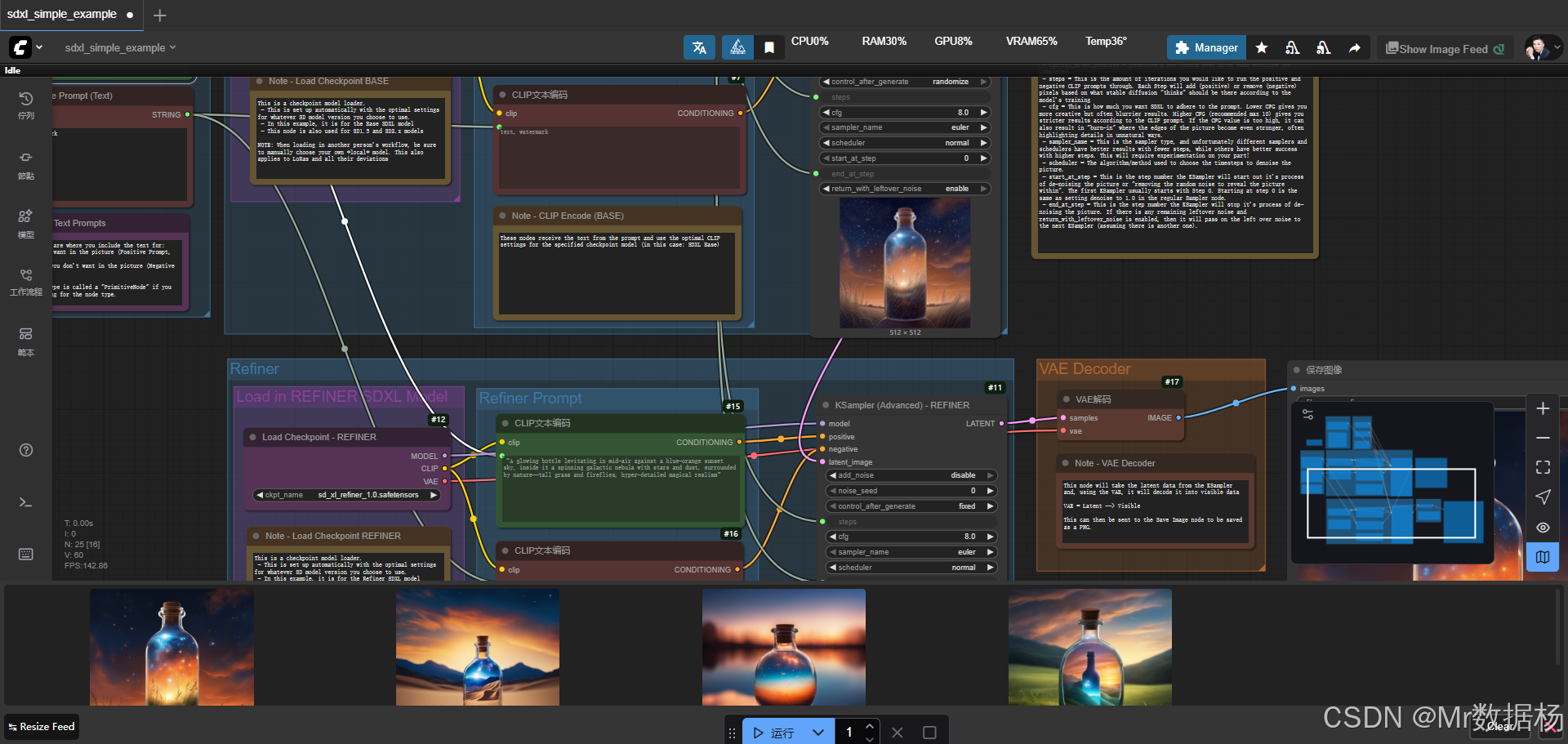
今天展示的案例是一个基于 SDXL Base 与 Refiner 双模型 的 ComfyUI 工作流,整体流程通过文本提示驱动图像生成,结合空潜变量图像设定和 KSampler 的多阶段迭代,使得作品能够在风格还原度和细节精修之间达到平衡。




通过效果演示,可以直观地理解这个工作流如何利用主模型生成初始构图,再借助精修模型增强细节与质感,从而实现更自然、更具层次感的最终画面。
@[TOC]
工作流介绍
该工作流以 Stable Diffusion XL 的 Base 模型和 Refiner 模型作为核心,依托 CLIP 文本编码器对正向和反向提示词进行条件约束,借助 KSampler 的多阶段采样实现图像的逐步生成与精修。整体设计中,空潜图像节点负责分辨率初始化,Step 控制节点用于设定迭代步数与切换点,最后通过 VAE 解码器将潜变量还原为可见图像,再由保存节点输出最终结果。
核心模型
在核心模型的使用上,工作流采用了双阶段的加载与调用。sd_xl_base_1.0 模型用于生成初始图像,其优势在于提供构图和整体画面;sd_xl_refiner_1.0 模型则专注于细节与纹理的优化处理。两者结合能够保证画面在宏观与微观层面的统一性,避免了单模型输出时可能存在的模糊与细节不足。
| 模型名称 | 说明 |
|---|---|
| sd_xl_base_1.0.safetensors | SDXL 基础模型,用于生成初始构图与画面框架 |
| sd_xl_refiner_1.0.safetensors | SDXL 精修模型,用于在初始图像基础上增强细节与纹理表现 |
Node节点
在节点设计上,该工作流覆盖了图像生成的完整链路。从 EmptyLatentImage 节点设置分辨率开始,正向与反向提示词通过 CLIPTextEncode 节点转换为条件约束,并输入到 KSampler (BASE) 节点完成初步采样。接着利用 KSampler (REFINER) 节点进行后续迭代精修,VAEDecode 节点负责将潜变量还原为真实图像,最终由 SaveImage 节点进行保存。通过这些节点的协作,工作流保证了从文本到图像的高效转化与稳定输出。
| 节点名称 | 说明 |
|---|---|
| EmptyLatentImage | 设定图像的分辨率与潜变量初始化 |
| CheckpointLoaderSimple (BASE) | 加载 SDXL Base 模型,负责初始图像生成 |
| CheckpointLoaderSimple (REFINER) | 加载 SDXL Refiner 模型,负责细节精修 |
| CLIPTextEncode | 将文本提示转化为条件输入,支持正向与反向约束 |
| KSampler (Advanced - BASE) | 使用 Base 模型进行初始采样与构图 |
| KSampler (Advanced - REFINER) | 使用 Refiner 模型对图像进行细节优化 |
| VAEDecode | 将潜变量解码为可见图像 |
| SaveImage | 输出最终生成的图像文件 |
工作流程
该工作流的执行过程围绕文本提示的条件约束与多阶段采样展开。首先通过 EmptyLatentImage 节点定义潜变量图像的分辨率,随后加载 Base 模型和 Refiner 模型,分别承担初始构图与细节精修的任务。文本提示经由 CLIP 编码器处理后输入到 Base 阶段的 KSampler 中,结合正向和反向约束逐步生成画面。在达到指定迭代步数后,潜变量携带剩余噪声被传递到 Refiner 阶段的 KSampler,由精修模型完成细节强化与纹理优化。最终输出结果由 VAE 解码成可见图像,并交由 SaveImage 节点保存。整个流程逻辑清晰,实现了从文本描述到高质量图像的多层次生成。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 分辨率初始化 | 创建潜变量图像并设定宽高参数 | EmptyLatentImage |
| 2 | 模型加载 | 分别加载 SDXL Base 与 Refiner 模型,准备基础与精修框架 | CheckpointLoaderSimple (BASE/REFINER) |
| 3 | 文本条件处理 | 将正向与反向提示词转化为条件约束输入 | CLIPTextEncode |
| 4 | 初始采样 | Base 模型在潜变量上进行迭代采样,生成构图与主体画面 | KSampler (Advanced - BASE) |
| 5 | 细节精修 | Refiner 模型接收潜变量并优化细节与纹理表现 | KSampler (Advanced - REFINER) |
| 6 | 图像解码 | 潜变量经由 VAE 解码为可见图像 | VAEDecode |
| 7 | 结果输出 | 将生成的最终图像保存为文件 | SaveImage |
应用场景
该工作流在实际使用中适合多种创作需求。它不仅能够满足通用的 AI 绘画任务,也能够在需要画面细节表现力的应用中展现优势。通过 Base 模型提供稳定的构图和场景框架,Refiner 模型进一步增强画面质感,使其更贴近真实效果或艺术化要求。在插画设计、概念艺术、影视前期分镜以及数字人场景渲染中,都能够发挥重要作用。典型用户群体涵盖了 AI 艺术创作者、游戏美术设计师、影视动画前期团队以及数字内容开发者。最终展示的内容既可以是单幅精美图像,也可以作为后续视频或交互作品的素材。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 插画与概念设计 | 快速生成构图并精修细节 | 独立艺术家、插画师 | 高质量的艺术插画 | 提升效率并保证画面表现力 |
| 游戏美术 | 设计角色与场景草图 | 游戏美术团队 | 游戏内角色、场景素材 | 构图清晰,细节饱满 |
| 影视前期 | 制作分镜与氛围设定图 | 动画及影视团队 | 场景分镜图、氛围图 | 真实感与艺术表现兼顾 |
| 数字人场景 | 渲染背景或特定场景元素 | 虚拟人研发者 | 数字人展示背景、叠加场景 | 增强沉浸感与专业度 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
ComfyUI使用教程、开发指导、资源下载
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用