建设一个网站需要用到几个语言洛阳网站制作公司
1.Introduction
Zero-Shot Learning是为了解决在实际应用中,我们没有充足的训练数据对于每一个类别。在测试过程中也有很多类别没有出现在训练样本中。
为了解决这些问题,针对不同的学习模型, 提出了一些解决方法。
1.few-shot learning/one-shot learing: 该方法用来解决在某些类别在训练数据中出现较少,此时需要利用其它类别中包含的知识。
2.open set recognition: 模型会在训练时考虑没有见过的类别,模型最终会判断一个测试样例是否数据未见过的类别,但是不能判断其具体是哪个类别。
3.**cumulative learing、class-incremental learning:**在模型学习完后,根据此时新的、此前未见过的标签数据来调整模型。
4.
1.1 Overview of Zero-Shot learing
Definition: 给出已知标签的训练实例,学习一个分类器fu():X−>Uf^u():X->Ufu():X−>U,使得该分类器能预测实例XteX^{te}Xte的类别YteY^{te}Yte,其中YteY^{te}Yte是未知的标签。
零样本学习属于迁移学习的一个子领域:零样本学习的目的是把在训练实例DtrD^{tr}Dtr中学到的知识迁移到测试实例中,训练实例和测试实例的标签空间是相斥的。
Auxiliary information: 对于未见过的类别,由于没有带标签的实例可用,因此一些辅助信息是必要的。这些信息应该包含所有关于unseen classes的信息。同时为了保证这些信息是有用的,其必须和feature space中的实例有关。
在当前的zero-shot learning中,辅助信息通常是一些semantic information,它形成了一个包含已知和未知类别的空间,通常称其为semantic space。

1.2 Learning Settings
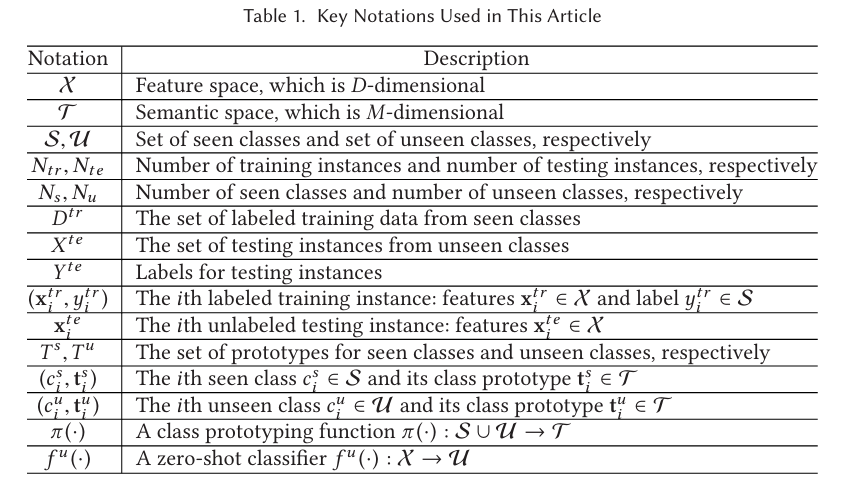
归纳式(inductive): 模型训练时完全不知道测试集的信息,只能靠训练集学一个通用的映射。
传导式(transductive) 模型训练时提前看到了测试数据。即使他们没有标签,也可以用来帮助学习。
这和传统半监督学习中的“transductive”有点不一样,在ZSL中,更细化为两层:
(a)对unseen classes的传导(class-transductive)
1.模型在学习时,已经引入了关于测试类别的信息。
比如说训练时不只知道seen类别,还知道unseen类别的语义描述(比如“马”:有四条腿、有鬓毛,会跑)。即模型在训练时知道自己以后要预测哪些unseen类,有针对性的优化。
(b)对具体测试样本的传导(instance-transductive)
训练时能访问到测试集中具体的未标注样本。
除了知道“马”的语义描述,训练时模型还提前拿到了一堆“马”的图片(但没有标签),用它们来调整特征空间或分布。
故我们可以将ZSL分为三种学习场景:
**领域漂移(domain shift):**即训练时的分布与测试中unseen类别的分布之间的差异,往往导致性能下降。
2.Semantic spaces
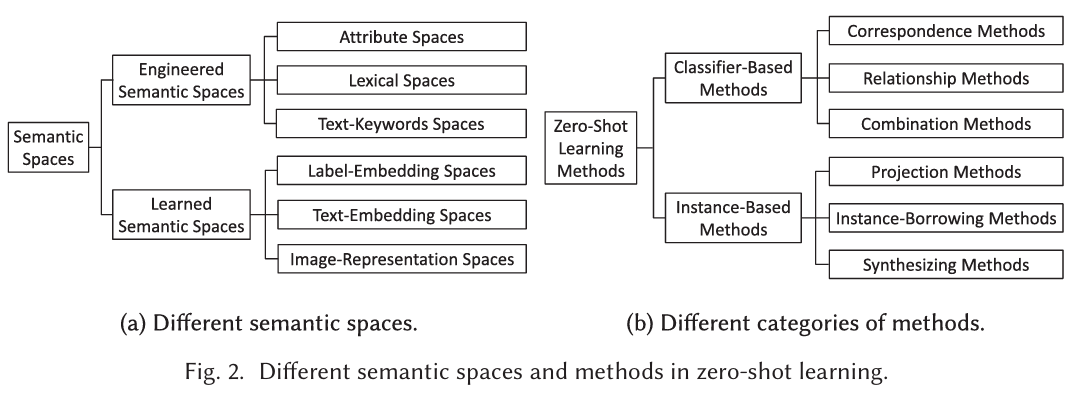
2.1 Engineered Semantic Spaces
在人工构建的语义空间中,每个维度都是由人类设计的。该语义空间有很多种,每一种都有一个独一无二的数据来源和方式来构建。
Attribute spaces. 是由一系列某种属性构成的语义空间。在ZSL是最为广泛运用的一种空间。对于动物图像识别任务,动物的某个特征是一个属性,比如说身体颜色、栖息地等等。这些属性构成了语义空间,每一个属性是一个维度。又可分为二元属性空间和连续属性空间。
Lexical space. 由词汇信息构成的空间。
常见做法:1.word embedding 直接使用类别名通过word2vec/GloVe/fastText/BERT得到词向量,这些词向量所在的向量空间,就是lexical space。 2.词汇属性描述 类别通过一组词汇属性描述,比如“has stripes,has four legs,eats grass”,这些词语的embedding属性表示拼接后构成lexical space。
优点:
- 不需要人工标注属性,只需利用类别名/文本描述;
- 词向量天然能捕捉语义关系。
缺点:
- 类别名的词向量可能过于粗糙,例如"seal"可能是海豹或是封印。
- 对细粒度分类不够准确(如”sparrow"和"robin"的词向量差别很小
learned semantic space
是指模型自动学出来的语义表示空间,在这个空间里:每个类别用一个prototype向量表示,向量维度没有明确的含义,向量整体编码了类别的语义信息。
这种空间既可以来自预训练模型,也可以专门为ZSL任务训练。

3 Methods
3.1 Classifier-Based Methods
**核心思想:**不直接在目标类别上训练模型,而是通过辅助的“语义空间(semantic space)”或“描述信息”来间接建立分类器,使得模型能够对从未见过的类别进行识别。
根据构建分类器方法的不同,又可进一步分为(1)correspondence methods(2)relationship methods(3)combination methods。
3.1.1 correspondence methods
该方法的流程:
Step1: 语义表示(获得prototype)
每个类别yyy都有一个prototype ϕ\phiϕ(y),可以是属性向量,也可以是词向量。
Step2:学习seen类的分类器参数
对每个seen类ysy_sys训练一个one-vs-rest二分类器,得到分类器参数WysW_{y_s}Wys。得到一组 (prototype,classifier参数) 对:(ϕ(ys),Wys),ys∈Yseen(\phi(y_s),W_{y_s}),y_s \in Y_{seen}(ϕ(ys),Wys),ys∈Yseen
Step3:学习correspondence函数
学习一个映射函数g(⋅):Wys≈g(ϕ(ys))g(\cdot):W_{y_s}\approx g(\phi(y_s))g(⋅):Wys≈g(ϕ(ys))
本质是让模型学会如何把prototype转化为分类器参数。
Step4:推理unseen类
测试时给定一个unseen类yuy_uyu,生成对应的分类器参数:Wyu=g(ϕ(yu))W_{y_u}=g(\phi(y_u))Wyu=g(ϕ(yu))
Step5:Zero-shot分类
用生成的分类器参数,在测试样本的特征空间中进行分类:
y^=arg max f(x;Wy),y∈Yunseen\hat{y}=arg \ max\ f(x;W_y),y\in Y_{unseen}y^=arg max f(x;Wy),y∈Yunseen