Attention Is All You Need - Transformer经典之作
目录
前言
背景
模型架构
编码器(Encoder)
解码器(Decoder)
编码解码器的堆叠
注意力机制
缩放点积的注意力机制
多头注意力机制 MHA
Transformer 中注意力机制的应用
前馈神经网络 FNN
嵌入和 Softmax
嵌入
softmax
参数共享
嵌入权重缩放
位置编码 Positional Encoding
为什么使用自注意力机制
训练
训练数据与批处理
硬件与训练进度
优化器
正则化
残差 dropout
标签平滑(Label Smoothing)
结论
PyTorch 官方提供的 Transformer 架构的定义
传统 LSTM 和 GRU 为序列建模与转换任务的主流方法,Transformer 彻底颠覆了传统的递归结构,只使用注意力机制来编码和解码序列信息。这也是标题的来源:Attention Is All You Need
背景
多头注意力机制弥补了长距离关系学习困难的痛点,这也是Transformer的创新架构。
这里补充介绍 “自注意力”:
自注意力,是一种将单个序列的不同位置联系起来以计算序列表示的注意力机制。自注意力已成功应用于多种任务,包括阅读理解、抽象概括、文本蕴含和学习与任务无关的句子表征等。
Transformer 是第一个完全依赖自注意力来计算其输入和输出表示的转换模型。
ps: 注意力机制,自注意力,多头注意力的对比
注意力机制的Q和K是不同来源的,输入的qkv是不同的
关注输入中重要的部分自注意力机制的Q和K则都是来自于同一组的元素,输入的qkv都是同一个来源x,三者是同源的。关注输入中的相关性
多头注意力是自注意力+多头:生成多组qkv
可以捕捉更多的信息,可以并行处理
模型架构
Transformer 使用编码器-解码器架构,如下图:
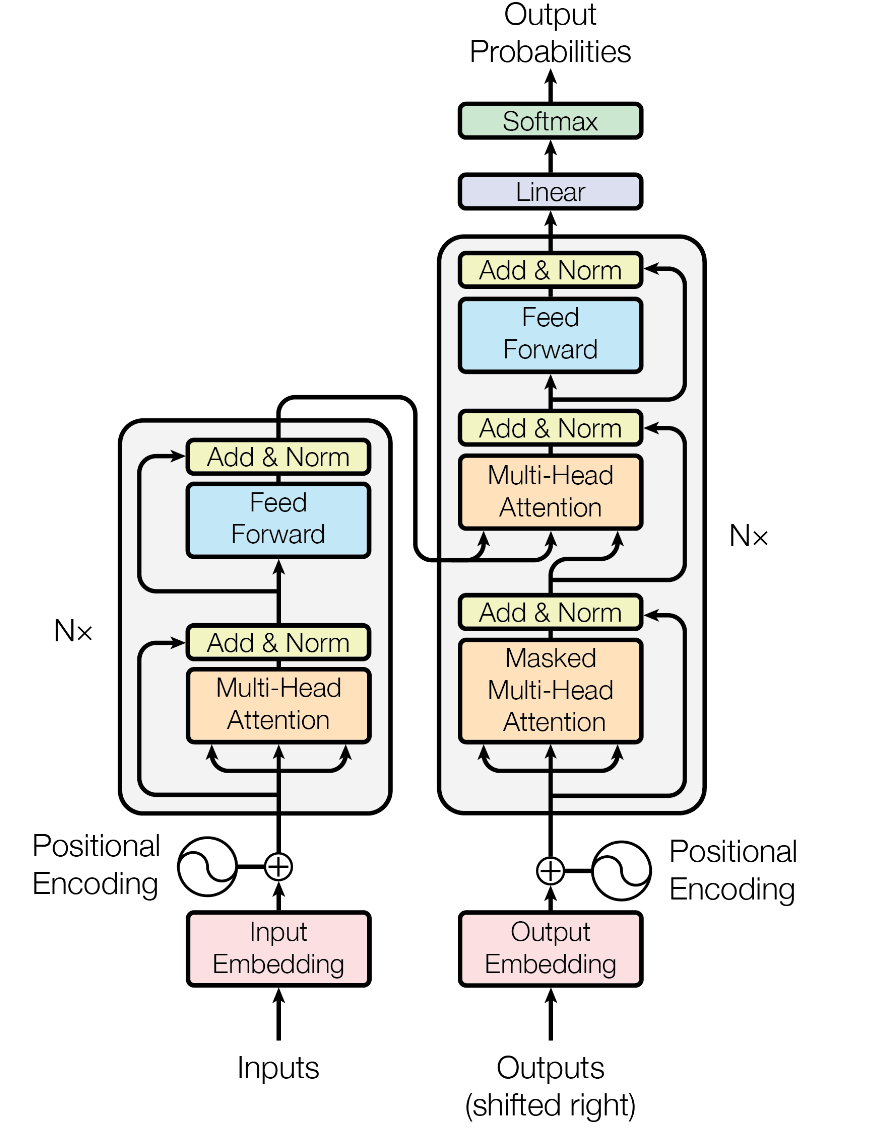
具有以下主要模块:
编码器(Encoder)
多头自注意力机制(Multi-Head Self-Attention)
前馈神经网络(Feedforward Neural Network)
归一化(Layer Normalization)
残差连接(Residual Connection)
解码器(Decoder)
Masked Multi-Head Self-Attention掩码多头自注意力
编码-解码多头注意力(Encoder-Decoder Multi-head-Attention)
前馈神经网络(FFN)
编码解码器的堆叠
编码器由 6 个相同的层堆叠而成。每个层包含两个子层:多头自注意力机制和前馈神经网络
解码器的结构和编码器类似:但是为了关注编码器的输出,并且为了让信息右向移动,子层为3个:掩码多头自注意力、编码-解码多头注意力、前馈神经网络
注意力机制
注意力机制就是对一系列的 query 和一系列的 key-value 对,判断q对不同v的重要程度。
Q(查询,想 “找什么”)、K(键,“有什么信息”)、V(值,“信息的具体内容”)
缩放点积的注意力机制
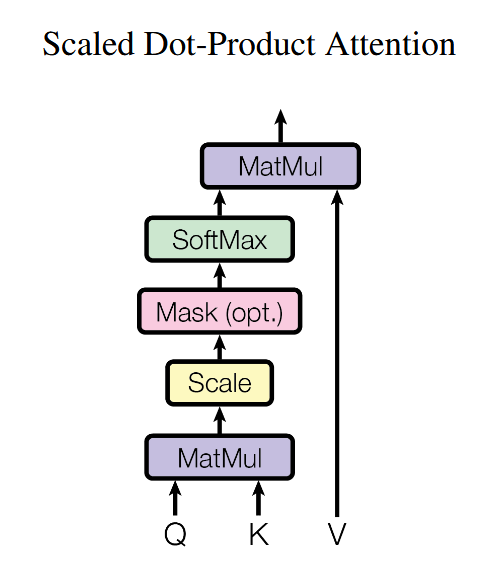
这里创新性的引入了缩放因子dk,与传统的注意力机制相比,缩放的点积注意力计算速度更快。缩放因子用于调节注意力计算的规模,以确保对于不同大小的输入,注意力权重的计算结果都能保持在合理的范围内。
为什么是根号?当 dk 较大时,Q 乘 K的转置 的数值会变得过大→Softmax 饱和→梯度趋近于 0。因此,除以根号dk使得分布更加平稳,提高训练稳定性。
代码实现:
import torch
import torch.nn.functional as F
import mathdef scaled_dot_product_attention(Q, K, V, mask=None):"""缩放点积注意力计算。参数:Q: 查询矩阵 (batch_size, seq_len_q, embed_size)K: 键矩阵 (batch_size, seq_len_k, embed_size)V: 值矩阵 (batch_size, seq_len_v, embed_size)mask: 掩码矩阵,用于屏蔽不应该关注的位置 (可选)返回:output: 注意力加权后的输出矩阵attention_weights: 注意力权重矩阵"""embed_size = Q.size(-1) # embed_size# 计算点积并进行缩放scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(embed_size)# 如果提供了掩码矩阵,则将掩码对应位置的分数设为 -infif mask is not None:scores = scores.masked_fill(mask == 0, float('-inf'))# 对缩放后的分数应用 Softmax 函数,得到注意力权重attention_weights = F.softmax(scores, dim=-1)# 加权求和,计算输出output = torch.matmul(attention_weights, V)return output, attention_weights
多头注意力机制 MHA
多头注意力机制是将 query、key 和 value 进行 h 次投影,如图:
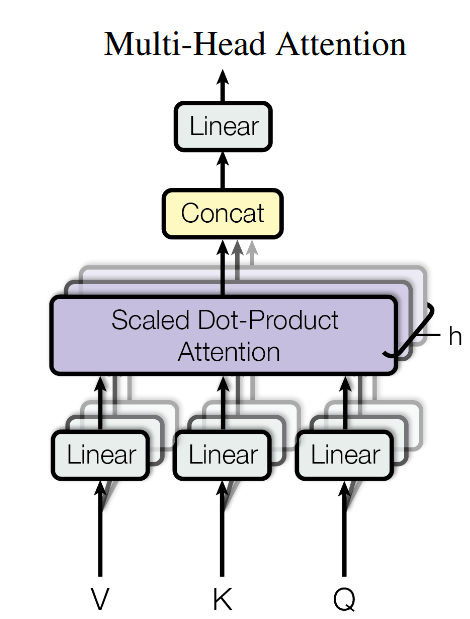
多头注意力用来关注输入的不同子空间,提高学习能力,增强模型对不同特征的理解。
Transformer 中注意力机制的应用
多头自注意力机制
Masked Multi-Head Self-Attention掩码多头自注意力
编码-解码多头注意力(Encoder-Decoder Multi-head-Attention)
前馈神经网络 FNN
除了注意力子层,我们的编码器和解码器中的每一层都包含一个全连接的前馈网络。
FNN 使用的是 ReLU 激活函数,为模型引入非线性表达能力。
嵌入和 Softmax
嵌入
将离散的 “输入 token(如源语言单词)” 和 “输出 token(如目标语言单词)”,都转化为维度为d_model的连续向量
嵌入层包含输入嵌入和输出嵌入。
代码实现:
import torch
import torch.nn as nn
import mathclass Embeddings(nn.Module):"""嵌入,将 token ID 转换为固定维度的嵌入向量,并进行缩放。参数:vocab_size: 词汇表大小。d_model: 嵌入向量的维度。"""def __init__(self, vocab_size, d_model):super(Embeddings, self).__init__()self.embed = nn.Embedding(vocab_size, d_model)self.scale_factor = math.sqrt(d_model)def forward(self, x):"""前向传播函数。参数:x: 输入张量,形状为 (batch_size, seq_len),其中每个元素是 token ID。返回:缩放后的嵌入向量,形状为 (batch_size, seq_len, d_model)。"""return self.embed(x) * self.scale_factor
softmax
Transformer 利用 softmax 将解码器的输出转换为预测的下一个 token 的概率。
代码实现:
import torch
import torch.nn as nndef softmax(x):exp_x = torch.exp(x)sum_exp_x = torch.sum(exp_x, dim=-1, keepdim=True)return exp_x / sum_exp_x# 测试向量
x = torch.tensor([1.0, 2.0, 3.0])# 根据公式实现的 Softmax
result = softmax(x)# 使用 nn.Softmax
softmax = nn.Softmax(dim=-1)
nn_result = softmax(x)print("根据公式实现的 Softmax 结果:", result)
print("nn.Softmax 的结果:", nn_result)
参数共享
为了减少模型的参数量,降低过拟合的风险,在两个嵌入层(输入嵌入、输出嵌入)和 softmax 之前的线性变换层之间共享同一权重矩阵
嵌入权重缩放
为了避免点积过大导致 Softmax 梯度消失,在嵌入层中,将权重矩阵乘以 根号 d_model。
为什么需要缩放?假设嵌入层的权重矩阵参数服从 “均值为 0、方差为 1/d_model” 的初始化:
- 若不缩放,嵌入向量的方差会是 “权重方差 × 输入维度”(输入是 one-hot 向量,维度为词表大小),容易导致向量值过大;
- 乘以根号 d_model 后,可让嵌入向量的方差被 “拉回 1 左右”
位置编码 Positional Encoding
由于模型不包含递归和卷积,为了使模型能够利用序列的顺序,引入了位置编码,将输入序列中单词的顺序加入词嵌入(Embedding)中。
常见的位置编码实现方式:
- 正弦-余弦位置编码(Sinusoidal Positional Encoding)(对序列长度没有限制)
- 可训练位置编码(Learnable Positional Encoding)(对序列长度有限制)RoPE : 位置编码的改进
不直接将位置信息作为向量与词向量相加,而是在注意力机制的 Query(查询)和 Key(键)计算时,将输入向量视为复数,在复数平面上进行旋转,通过旋转操作将位置信息融入输入嵌入中
为什么使用自注意力机制
在传统的循环神经网络(RNN)中,信息是逐步传递的,这种逐步传递导致了 RNN 在捕捉长距离依赖时可能面临的挑战,尤其是在处理长序列时效果不佳。
相比之下,Transformer 利用自注意力机制直接将每个位置与所有其他位置进行关联,避免了逐步传递的过程,使得任意两个位置之间的信息传递路径变得极为直接和高效。这种直接的路径传递方式使得 Transformer 能够更有效地捕捉到长距离的依赖关系,而不受序列长度的限制。
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size):"""自注意力(Self-Attention)机制。参数:embed_size: 输入序列的嵌入维度(每个向量的特征维度)。"""super(SelfAttention, self).__init__()self.attention = Attention(embed_size) # 使用通用Attention模块def forward(self, x, mask=None):"""前向传播函数。参数:x: 输入序列 (batch_size, seq_len, embed_size)mask: 掩码矩阵 (batch_size, seq_len, seq_len)返回:out: 自注意力加权后的输出 (batch_size, seq_len, embed_size)attention_weights: 注意力权重矩阵 (batch_size, seq_len, seq_len)"""# 在自注意力机制中,q, k, v 都来自同一输入序列# q = k = v = xout, attention_weights = self.attention(x, x, x, mask)return out, attention_weights训练
训练数据与批处理
在标准的 WMT 2014 英德数据集(WMT 2014 English-German dataset)上进行训练,数据集包含约 450 万个句子对。
硬件与训练进度
在一台配备 8 块 NVIDIA P100 GPU 的机器上训练模型。对于本文中所述超参数下的基础模型,每一步训练约耗时 0.4 秒。基础模型共训练 10 万步,总耗时约 12 小时。
优化器
Adam 优化器
正则化
残差 dropout
对每个子层的输出应用 dropout,dropout 率设置为 Pdrop=0.1
标签平滑(Label Smoothing)
标签平滑是一种防止模型过度自信、缓解过拟合的训练技巧。
结论
总结 Transformer 是第一个完全基于注意力的序列转导模型,用多头自注意力替换编码器-解码器架构中最常用的循环层。
对于翻译任务,Transformer可以比基于循环或卷积层的架构更快地进行训练。
未来计划将模型应用于处理图像、音频和视频等大型输入和输出领域,使生成的序列更少是另一个研究目标。
用来训练和评估我们的模型的代码开源在:tensorflow/tensor2tensor: Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research. (github.com)
PyTorch 官方提供的 Transformer 架构的定义
import torch.nn as nn
# 使用 Transformer base 参数
d_model = 512 # 嵌入维度
N = 6 # 编码器和解码器的层数
h = 8 # 多头注意力的头数
d_ff = 2048 # 前馈神经网络的隐藏层维度
dropout = 0.1 # Dropout 概率model = nn.Transformer(
d_model=d_model,
nhead=h,
num_encoder_layers=N,
num_decoder_layers=N,
dim_feedforward=d_ff,
dropout=dropout,
batch_first=True
)print(model)