深度学习之YOLO系列YOLOv3
简介
上两篇博客我们介绍了YOLOv1与v2,还说了目标检测算法与解释了YOLO评价指标的一些专业。今天我们来继续探索YOLOv2的模型
深度学习之YOLO系列YOLOv2
深度学习之YOLO系列YOLOv1
深度学习之YOLO系列了解基本知识
一、YOLOv3
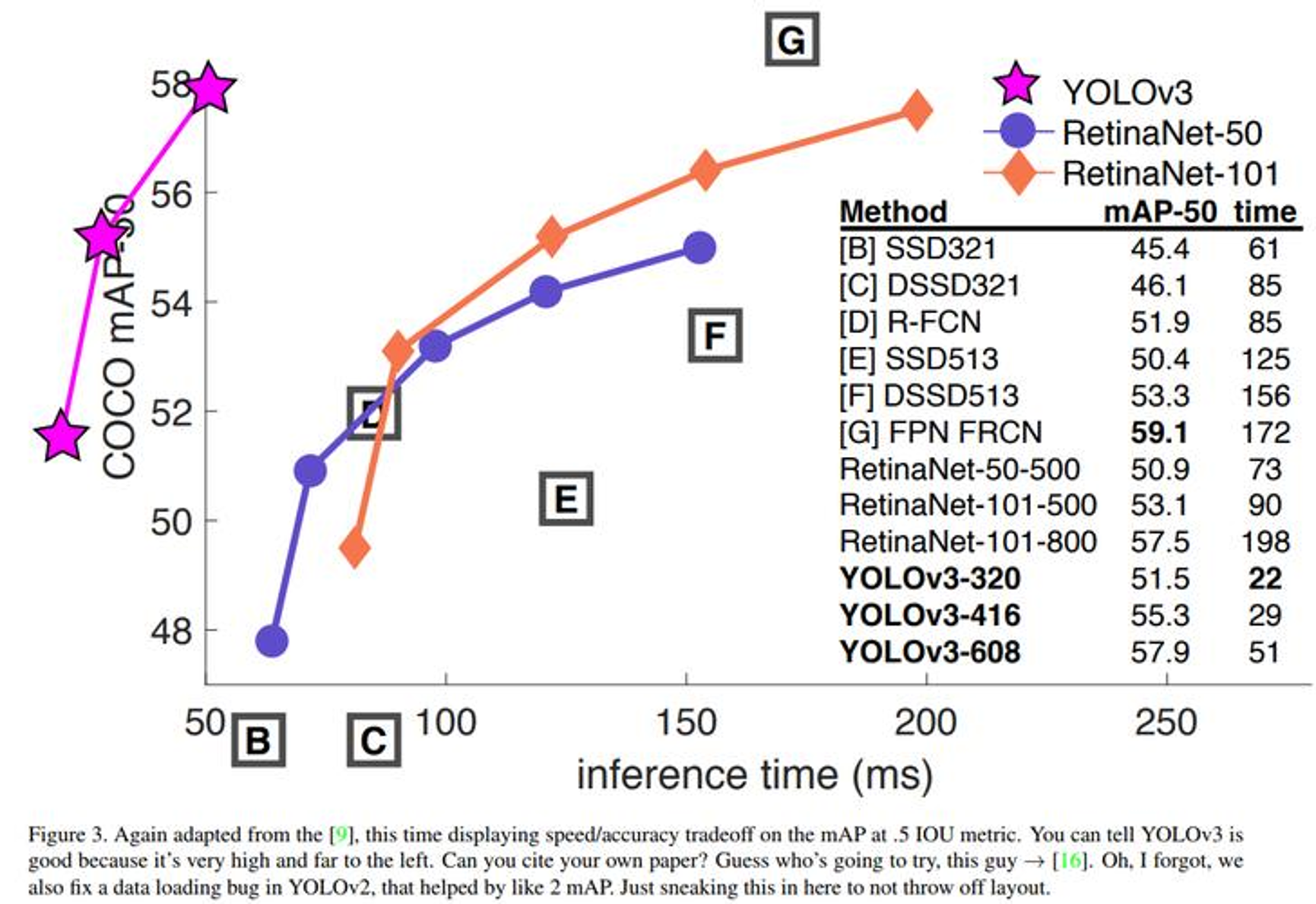
- 终于到 V3 了,最大的改进就是网络结构,使其更适合小目标检测
- 特征做的更细致,融入多持续特征图信息来预测不同规格物体
- 先验框更丰富了,3 种 scale,每种 3 个规格,一共 9 种
- softmax 改进,预测多标签任务
1、3个scale
为了能检测到不同大小的物体,设计了三个尺度scale
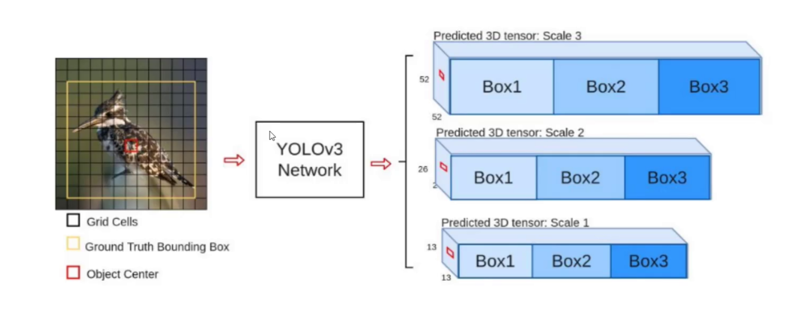
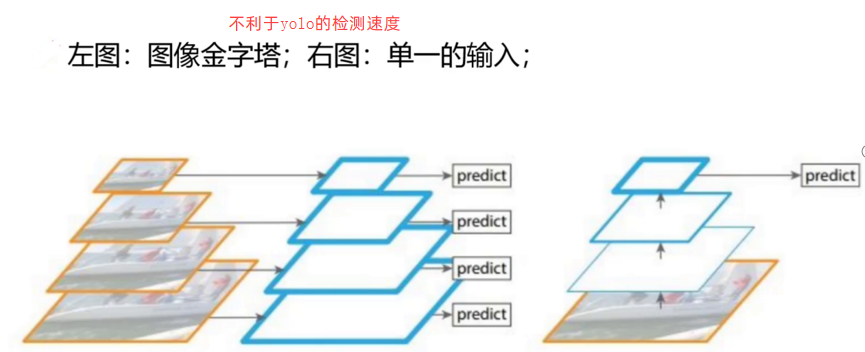
scale变换的经典方法:
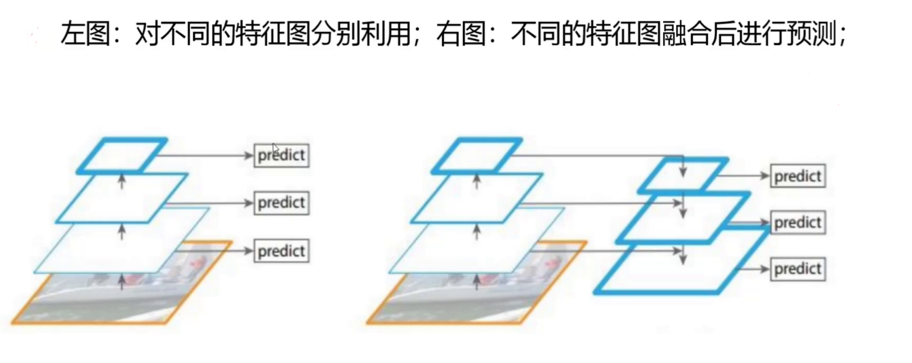
不同特征图融合后进行预测:YOLOv3
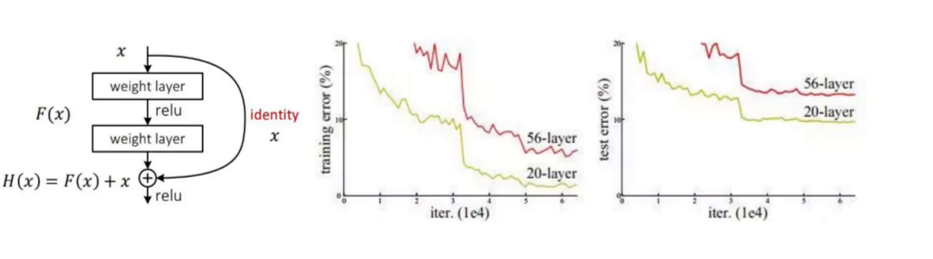
2、残差连接
YOLOv3使用了ResNet残差网络的思想,堆叠更多的层再进行特征提取
二、核心网络架构
- 没有池化和全连接层,全部卷积
- 下采样通过 stride 为 2 实现
- 3 种 scale,更多先验框
- 基本上当下经典做法全融入了
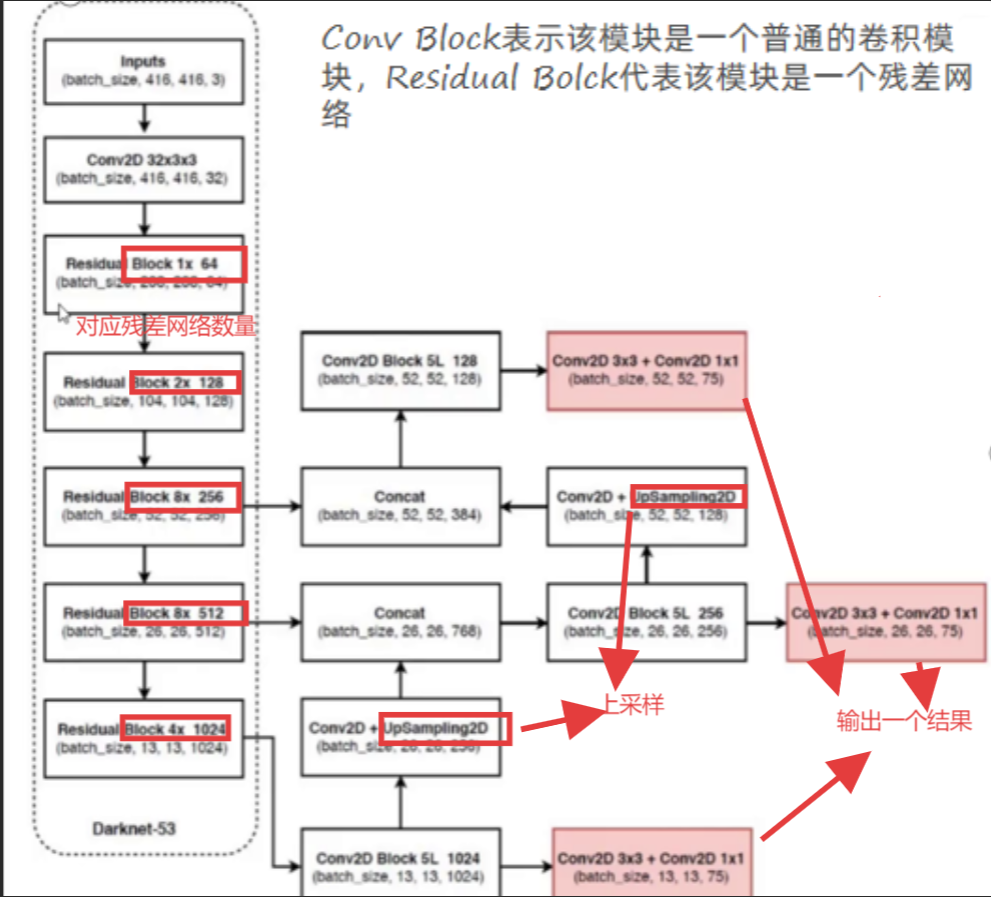
没有池化层和全连接层,全部卷积,下采样通过stride卷积核滑动步长为2来实现,使用3种scale尺度,更多的先验框
1、输入映射到输出
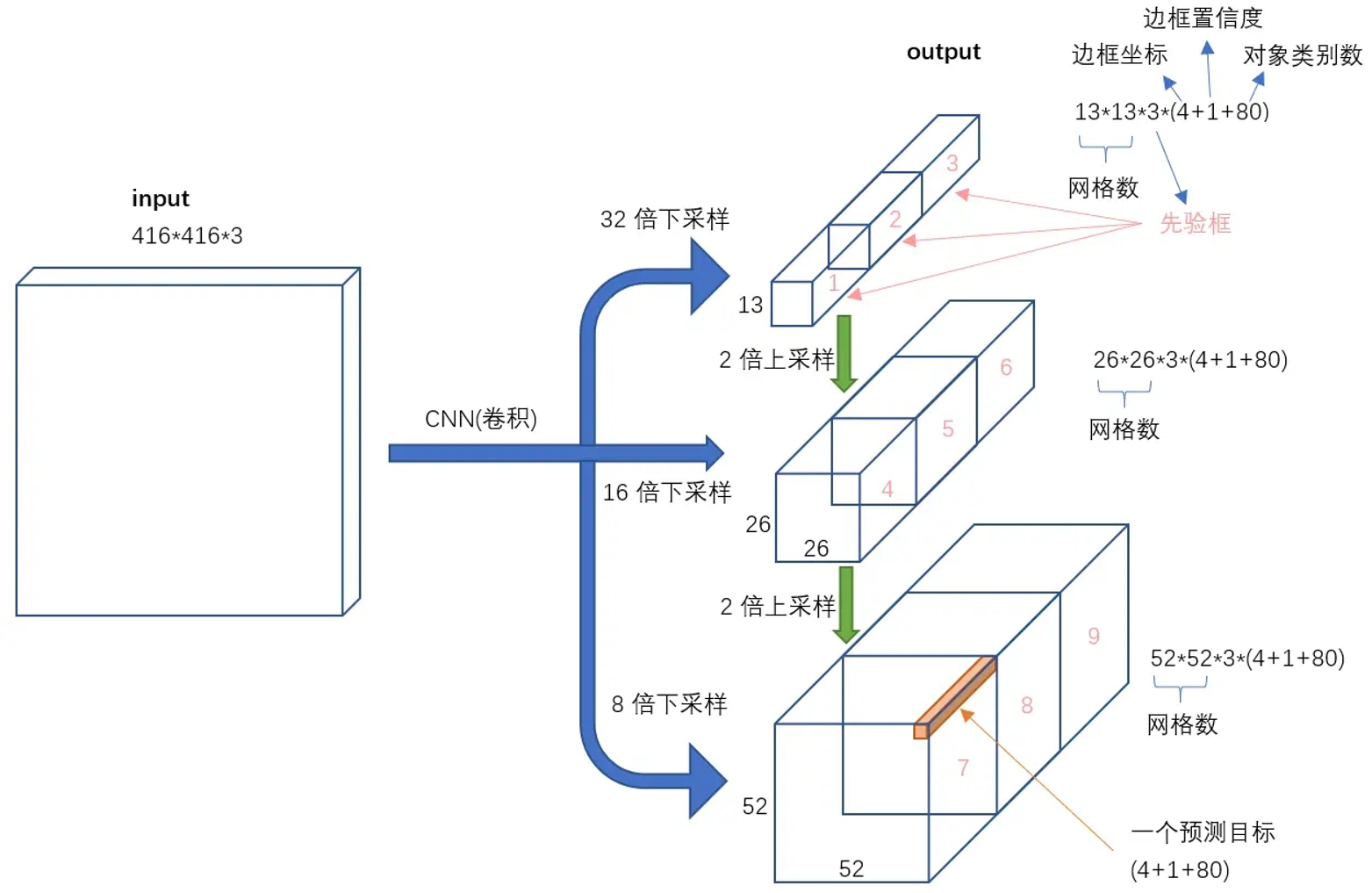
2、9种先验框
YOLOv2使用了5个先验框,这里的v3使用了9种先验框
例如,13*13的特征图上使用(116x90)、(156x198)、(373x326)的先验框
26*26的特征图上使用(30x61)、(62x45)、(59x119)的先验框
52*52的特征图上使用(10x13)、(16x30)、(33x23)的先验框

大的先验框在感受野大的特征图中检测
9种尺度的先验框 YOLO3延续了K-means聚类得到先验框的尺寸方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。 分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。

3、COCO数据集介绍
COCO数据集是一个可用于图像检测(image detection),语义分割(semantic segmentation)和图像标题生成(image captioning)的大规模数据集。它有超过330K张图像(其中220K张是有标注的图像),包含150万个目标,80个目标类别(object categories:行人、汽车、大象等),91种材料类别(stuff categoris:草、墙、天空等),每张图像包含五句图像的语句描述,且有250,000个带关键点标注的行人。
下载网址:官网下载链接
4、Logistic分类器
YOLOv3用多个独立的Logistic分类器替代了传统目标检测模型中常用的Softmax分类层
Softmax函数将神经网络的输出转换为概率分布,所有类别的概率之和为1。然而,Softmax函数的是每个样本只属于一个类别。但在更复杂的目标检测场景中,一个物体可能同时属于多个类别,例如一个人可能同时被标记为“人”和“行人”。这种情况下,Softmax函数就不再适用,因为它会强制每个样本只属于一个类别。
在Logistic分类器(逻辑回归)中,每个类别的预测是独立进行的。对于输入样本,分类器会为每个类别计算一个概率值,表示该样本属于该类别的可能性。
Logistic分类器通常使用Sigmoid函数(也称为Logistic函数)作为激活函数。Sigmoid函数将神经网络的输出映射到(0, 1)区间,表示样本属于某个类别的概率。Sigmoid函数的数学表达式为如下图,其中,z是神经网络的原始输出
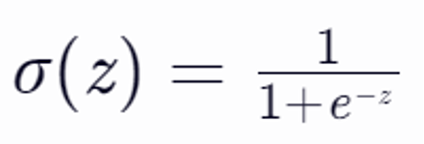
假设有一个图像分类任务,需要识别图像中是否包含“猫”、“狗”和“鸟”三种动物。使用Logistic分类器时,模型会为每个类别(猫、狗、鸟)分别计算一个概率值。例如: 图像A:猫的概率=0.8,狗的概率=0.3,鸟的概率=0.1 图像B:猫的概率=0.2,狗的概率=0.7,鸟的概率=0.6 设定阈值为0.5,则: 图像A会被标记为“猫”(因为猫的概率>0.5),而不会被标记为“狗”或“鸟”(因为它们的概率<0.5)。 图像B会被标记为“狗”和“鸟”(因为它们的概率都>0.5),而不会被标记为“猫”(因为猫的概率<0.5)。