Pixel-Perfect:生成像素级深度细节深度提升
主页:https://pixel-perfect-depth.github.io

本文是生成式深度估计方法,生成的框架上面加了语义特征来捕捉图像细节,还能加速训练,实际效果确实如方法所述,但是似乎有一些小瑕疵,请看最后的实际效果。
abstract
本文提出 Pixel-Perfect Depth,一种基于像素空间扩散生成的单目深度估计模型,能够从预测的深度图中恢复高质量、无飞点(flying pixels)的点云。目前的生成式深度估计模型通常通过微调 Stable Diffusion 来实现出色的性能。然而,这类方法需要使用 VAE(变分自编码器)将深度图压缩到潜空间中,这一过程不可避免地会在边缘和细节处引入飞点伪影。
我们的模型通过直接在像素空间中执行扩散生成,避免了由 VAE 引起的伪影问题。为克服像素空间生成计算复杂度高的难题,我们提出了两个新的设计:
- 语义引导扩散 Transformer(Semantics-Prompted Diffusion Transformers, DiT) —— 将视觉基础模型(vision foundation models)提取的语义表征融入 DiT,以在扩散过程中提供语义提示,从而在增强细粒度视觉细节的同时,保持全局语义一致性;
- 级联 DiT 设计(Cascade DiT Design) —— 通过逐步增加 token 数量,以进一步提升模型的效率与精度。
在五个基准测试中,我们的模型在所有已发表的生成式深度估计方法中表现最佳,并且在边缘感知点云评估中显著优于其他所有模型。

1 Introduction
1.1提出问题
单目深度估计(MDE)是 3D 重建、新视角合成和机器人操作等任务中的核心问题。尽管现有模型在零样本场景中表现良好,但在将深度图转换为点云时常出现“飞点”(flying pixels),尤其在物体边界与细节区域。这一问题限制了模型在自由视角视频、机器人操作及沉浸式内容生成等应用中的实用性。
判别式模型(Depth anything v2;Metric3d;Metric3d v2;Depth pro):倾向于在深度不连续的边缘处输出前景和背景深度的中间值,以最小化回归损失,因此导致边缘模糊与飞点。
而生成式模型(Repurposing diffusion-based image generators for monocular depth estimation;Lotus;Geowizard):通过建模像素级深度分布来避免直接回归,能更好地保留锐利边缘与精细结构。虽可保留锐利边缘,但依赖 VAE 进行潜空间压缩,导致结构细节丢失并产生飞点。图1,图2,图4


作者指出,理想的方案是直接在像素空间进行扩散生成深度,以避免 VAE 压缩引入的伪影。然而,像素空间扩散建模难度极高,主要在于如何同时保持全局语义一致性与局部精细结构。高分辨率生成研究表明,噪声注入往往破坏低频结构,说明像素空间生成的关键难点在于建模全局结构。

1.2本文
本文提出 Pixel-Perfect Depth —— 一种基于像素空间扩散Transformer的高质量、无飞点单目深度估计框架。像素空间高分辨率生成的主要难点在于全局结构建模。为此提出:
1.语义引导扩散Transformer(Semantics-Prompted Diffusion Transformer, SP-DiT)
将来自vision foundation models的高层语义表示融入扩散过程;使模型在生成细节的同时保持全局结构与语义一致;
为了缓解语义表示与DiT内部表示的不匹配导致的训练不稳定问题,作者设计了一种语义正则化方法,稳定训练并加速收敛;
2.级联 DiT 设计(Cascade DiT, Cas-DiT)
作者发现:扩散Transformer的早期层主要负责全局结构/低频信息,后期层负责高频细节。
基于这一观察,Cas-DiT 采用逐级缩小 patch 大小的策略:
- 早期层:较大 patch → token 少 → 易于建模全局结构;
- 后期层:较小 patch → token 多 → 精细生成局部细节;
- 这种由粗到细的级联设计既提升效率、降低计算量,又显著提升精度。
2 Related Work
2.1 Monocular Depth Estimation
早期的单目深度估计方法主要依赖人工设计特征 [46, 23]。随着神经网络的兴起,该领域发生了巨大变革,但最初的深度学习方法 [12, 11] 在跨数据集泛化方面表现不佳。为了解决这一问题,研究者引入了尺度不变损失(scale-invariant loss)与相对深度损失(relative loss) [43],从而实现了多数据集联合训练 [31, 72, 7, 63, 61, 59, 57, 62, 44]。
近期研究的重点转向了提升模型的泛化能力 [68, 4]、深度一致性 [66, 6, 26, 28] 以及度量尺度准确性(metric scale) [3, 32, 33, 74, 17, 75, 25, 40, 34],并逐渐趋向采用 Transformer 架构 [42]。同时,有研究 [60, 65] 尝试利用点云表示来改进深度估计性能。
近年来,部分方法 [27, 9, 49, 47, 48, 79] 开始探索使用扩散模型(diffusion models)进行度量深度估计。然而,与这些方法不同,本文的模型聚焦于相对深度估计,在各种真实场景中展现出更好的泛化性与更精细的细节表现。尤其是本文提出的 语义引导扩散 Transformer(Semantics-Prompted DiT),将预训练的高层语义特征引入扩散过程,显著提升了模型性能。
最近,Bae 等人 [29] 率先提出通过微调 Stable Diffusion [45] 来进行深度估计,展示了强大的零样本相对深度预测能力。随后一些工作 [18, 16, 54, 78, 2] 尝试改进其性能与推理速度,但它们均基于潜空间扩散模型(latent diffusion model),需要借助 VAE 将深度图压缩到潜空间中。相比之下,本文提出的模型完全在像素空间中训练和生成,无需 VAE 压缩。
3 Method
3.1 Pixel-Perfect Depth
给定一张输入图像,我们的目标是估计出一张**像素级精确、在转换为点云时无飞点(flying pixels)的深度图。现有模型 [29, 14, 18, 68, 4] 通常由于各自的建模范式存在内在缺陷而产生飞点问题。
本文的深度在像素空间而非潜空间中执行扩散生成。这种方式能够直接建模像素级的深度分布,尤其是物体边缘的深度不连续性。
然而,直接在高分辨率(如 1024×768)的像素空间中训练生成式扩散模型计算量巨大、优化困难。
为解决这些挑战,本文进一步提出两项关键设计:语义引导扩散 Transformer(Semantics-Prompted DiT)和 级联 Transformer 结构(Cascaded DiT Design)。
3.2 Generative Formulation
我们采用 Flow Matching [35, 36, 1] 作为深度估计框架的生成核心。Flow Matching 通过一阶常微分方程(ODE)学习从高斯噪声到数据样本的连续变换过程。在本研究中,我们建模的是从高斯噪声到深度样本的变换:

小结
1.生成原理:Flow Matching
Flow Matching 作为生成机制,它学习一个从噪声到深度图的连续变换函数。与扩散模型类似,但直接建模速度场(流场),不需要计算噪声残差或概率密度。
2.训练阶段
- 将真实深度 x0与噪声 x1 进行线性插值,得到中间样本 xt;
- 模型
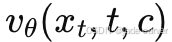 预测速度方向;
预测速度方向; - 以均方误差(MSE)训练,使预测流场逼近真实流场
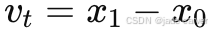 。
。
3.推理阶段
从纯噪声 x1 出发,按时间反向积分 ODE,将噪声逐步转化为深度图 x0。
Flow Matching 提供了一种连续且稳定的生成过程;计算上比传统扩散模型更高效;适合 Pixel-Perfect Depth 的像素空间建模需求,可生成更加平滑且无伪影的深度图。
3.3 Semantics-Prompted Diffusion Transformers
Semantics-Prompted DiT(语义引导扩散Transformer)建立在 DiT [39] 的基础上,完全采用 Transformer 架构,没有任何卷积层。
这种设计具有三个核心目标:
- 保持全局语义一致性(global semantic consistency);
- 提升细节层次的深度预测(fine-grained visual details);
- 维持架构的简洁性与可扩展性(simplicity & scalability)。
相比于以往的模型(如 Depth Anything v2、Marigold),它直接在像素空间进行扩散建模,并结合高层语义引导,使模型能在高分辨率下仍然收敛良好。

但是这样会有问题:直接在像素空间进行扩散训练会导致模型:因为有噪声导致难以捕捉全局结构并且无法准确预测细节;训练不稳定。为了解决这个问题,作者引入了高层语义引导机制。


3.4 Cascade DiT Design
虽然前面的 Semantics-Prompted DiT 大幅提升了生成质量,但直接在像素空间执行扩散仍然计算量极大。为此,作者提出 Cascade DiT Design(级联式 DiT 设计) —— 通过在不同阶段使用不同的 patch 尺寸(即 token 数量),实现一种由粗到细(coarse-to-fine) 的高效建模流程。
该设计主要基于这样的一个经验:早期 Transformer block 主要学习 全局结构与低频信息(如大体轮廓、物体位置等);后期 block 则关注 细节与高频信息(如边缘、纹理、深度变化等)。
基于此,作者将 DiT 分为两个阶段,通过逐步增加分辨率(减小 patch 尺寸)来提升深度预测的精细度。
1.粗阶段(Coarse Stage)
使用 较大的 patch size,即每个 token 表示更大区域。
- 处理的 token 数量减少 → 计算量显著降低。
- 专注学习全局结构、低频深度信息。
- 与语义引导模块(SP-DiT)提取的高层语义表示更契合。
2.细阶段(Fine Stage / SP-DiT)
- 使用 较小的 patch size,即更多 token。
- 模型能聚焦局部细节与高频深度变化。
- 在粗阶段的基础上进行细化生成,实现像素级精度。
这种级联式设计的优点是:可以显著减少计算开销:早期阶段 token 少,计算负担轻,同时保持高精度以便于后期阶段对细节进行补充;其次,这样的设计非常符合人类视觉层次结构:先整体感知、再关注细节;最后就是提升深度估计的效率与质量,兼顾全局一致性与细节精度。
4 Experiments
模型在高质量的 Hypersim 合成数据集上训练,该数据集提供约 54,000 个干净的三维真值样本,分辨率为 1024×768。模型的零样本相对深度性能在五个真实世界数据集(NYUv2、KITTI、ETH3D、ScanNet 和 DIODE)上进行评估,采用 绝对相对误差(AbsRel) 和 δ₁ 精度 两个标准指标,同时通过作者提出的 边缘感知点云指标 检验点云的飞点情况。所有定量实验使用 512×512 模型,而定性可视化结果使用 1024×768 模型,以验证 Pixel-Perfect Depth 在精度和几何一致性上的表现。
4.2 Ablations and Analysis
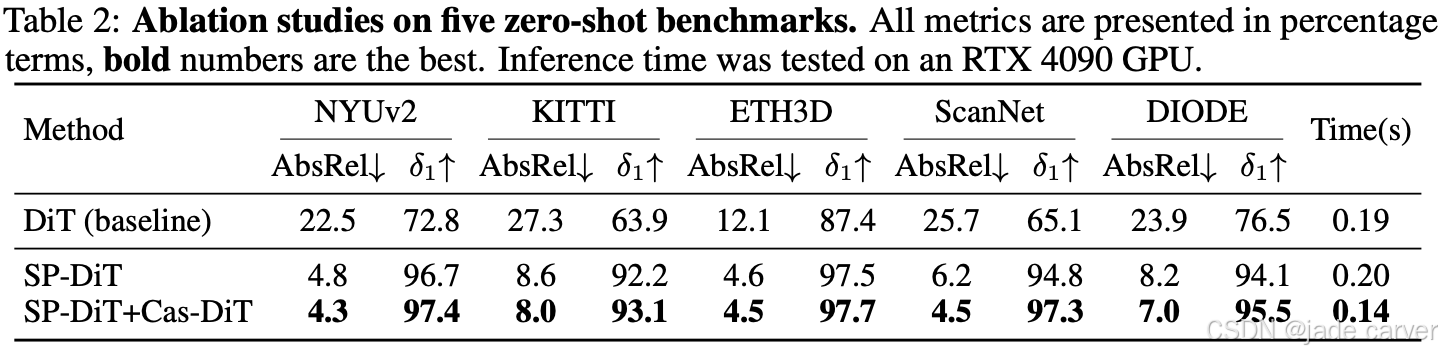
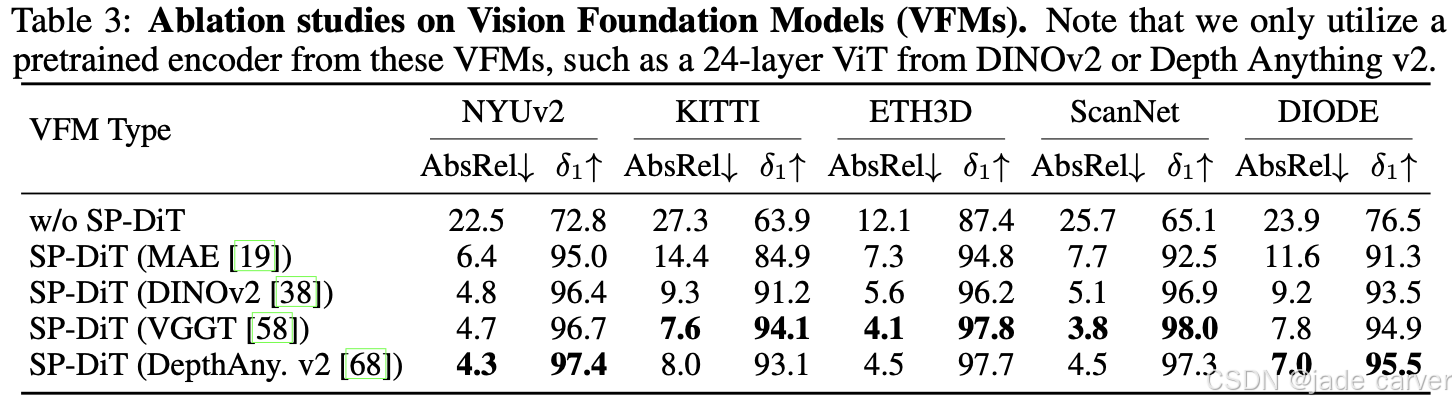
以 DiT [39] 作为基线,逐步验证各模块对性能的贡献。结果表明,直接在高分辨率像素空间进行扩散生成计算量大且优化困难,导致全局语义和细节表现不足。引入 Semantics-Prompted DiT(SP-DiT) 后,这些问题得到显著改善,例如在 NYUv2 数据集的 AbsRel 指标上提升了 78%。进一步采用 Cascaded DiT Design(Cas-DiT)的粗到细级联策略,通过逐步增加 token 数量,不仅显著提高效率(在 RTX 4090 GPU 上推理时间减少约 30%),还能更好地建模全局上下文,从而提升深度估计精度。此外,对不同视觉基础模型(MAE、DINOv2、Depth Anything v2、VGGT)的消融结果显示,SP-DiT 结合这些预训练编码器均能显著提升性能,验证了语义引导模块在模型中的有效性。

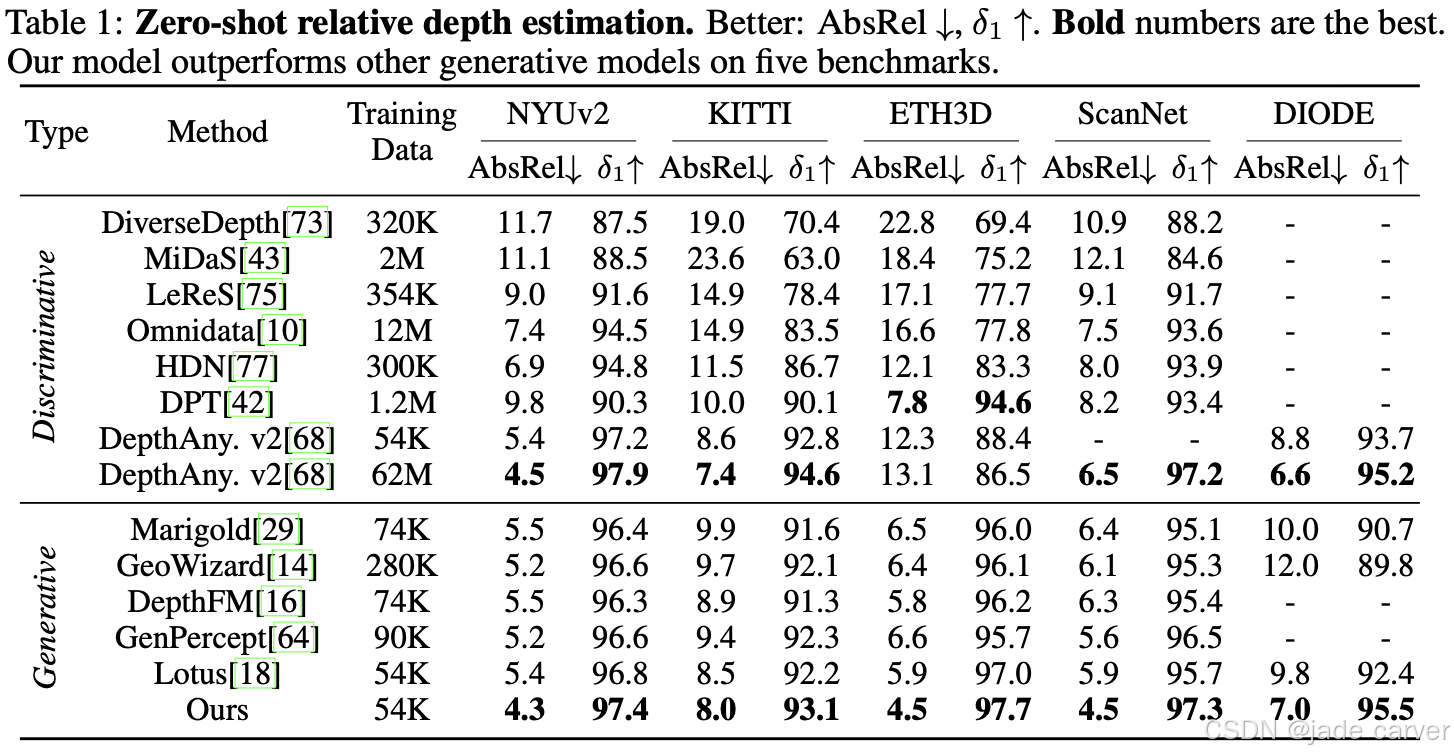
4.3 Zero-Shot Relative Depth Estimation
我们将 Pixel-Perfect Depth 与近期深度估计模型 [68, 4, 29, 18, 16] 在五个真实世界基准数据集上进行比较。结果显示(见 Table 1)
4.4 Edge-Aware Point Cloud Evaluation
为了评估模型在物体边缘的深度预测精度及点云质量,我们提出 边缘感知点云评估(Edge-Aware Point Cloud Evaluation)。Pixel-Perfect Depth 的目标是生成像素级精确的深度图,从而得到无飞点的干净点云,而飞点通常出现在物体边缘,这是由于这些区域深度预测不准确造成的。
现有评估基准和指标(如 NYUv2、KITTI 的 AbsRel、δ1)多集中于平坦区域,难以反映边缘飞点问题。为此,我们在 Hypersim [44] 官方测试集上进行评估,该数据集提供高质量的真实点云,且未用于训练。我们使用 Canny 算子从真值深度图中提取边缘掩码,并在这些边缘附近计算预测点云与真值点云的 Chamfer Distance,从而量化边缘深度精度。

补充:

5.sweet环节-实测效果
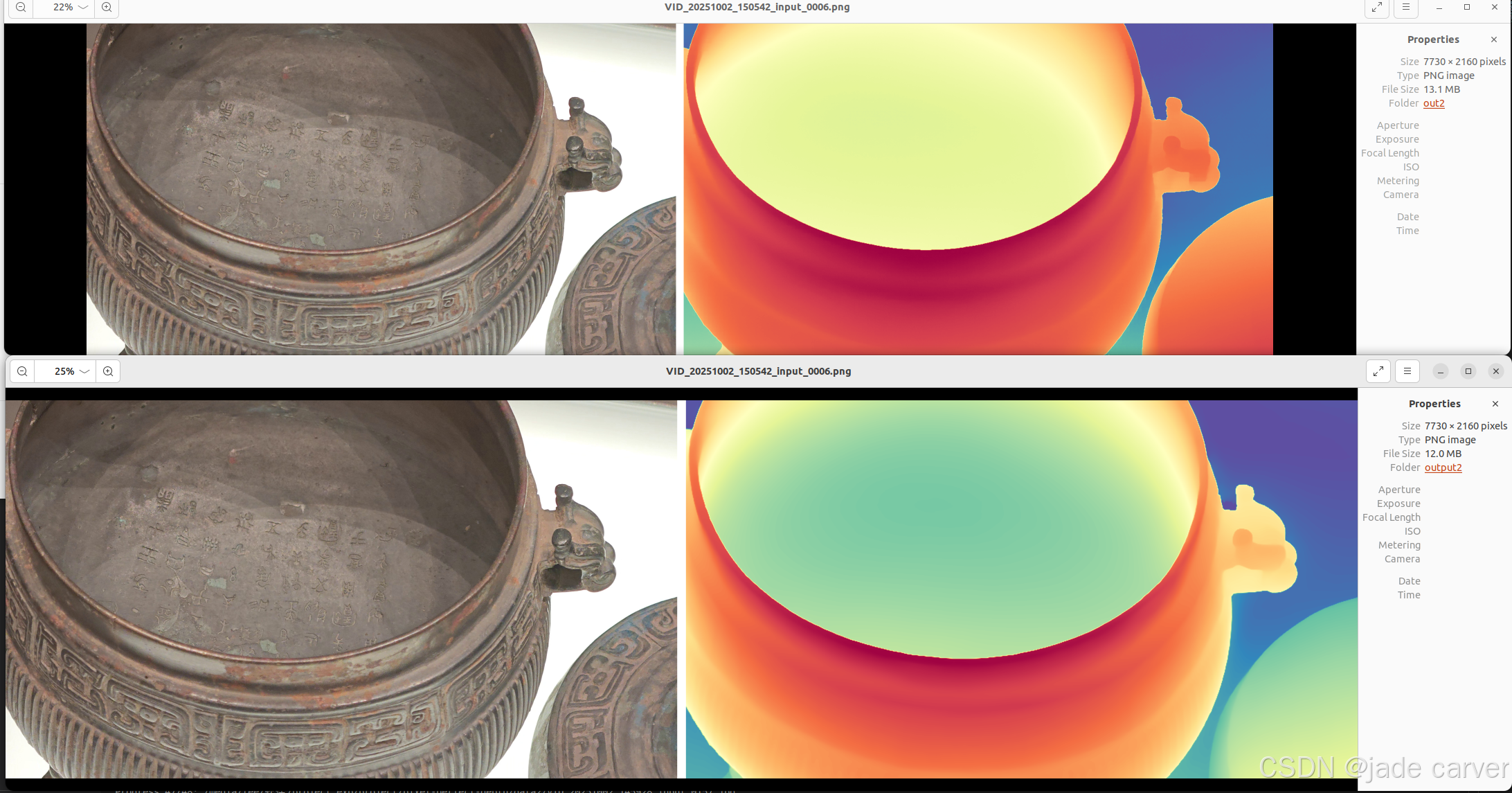
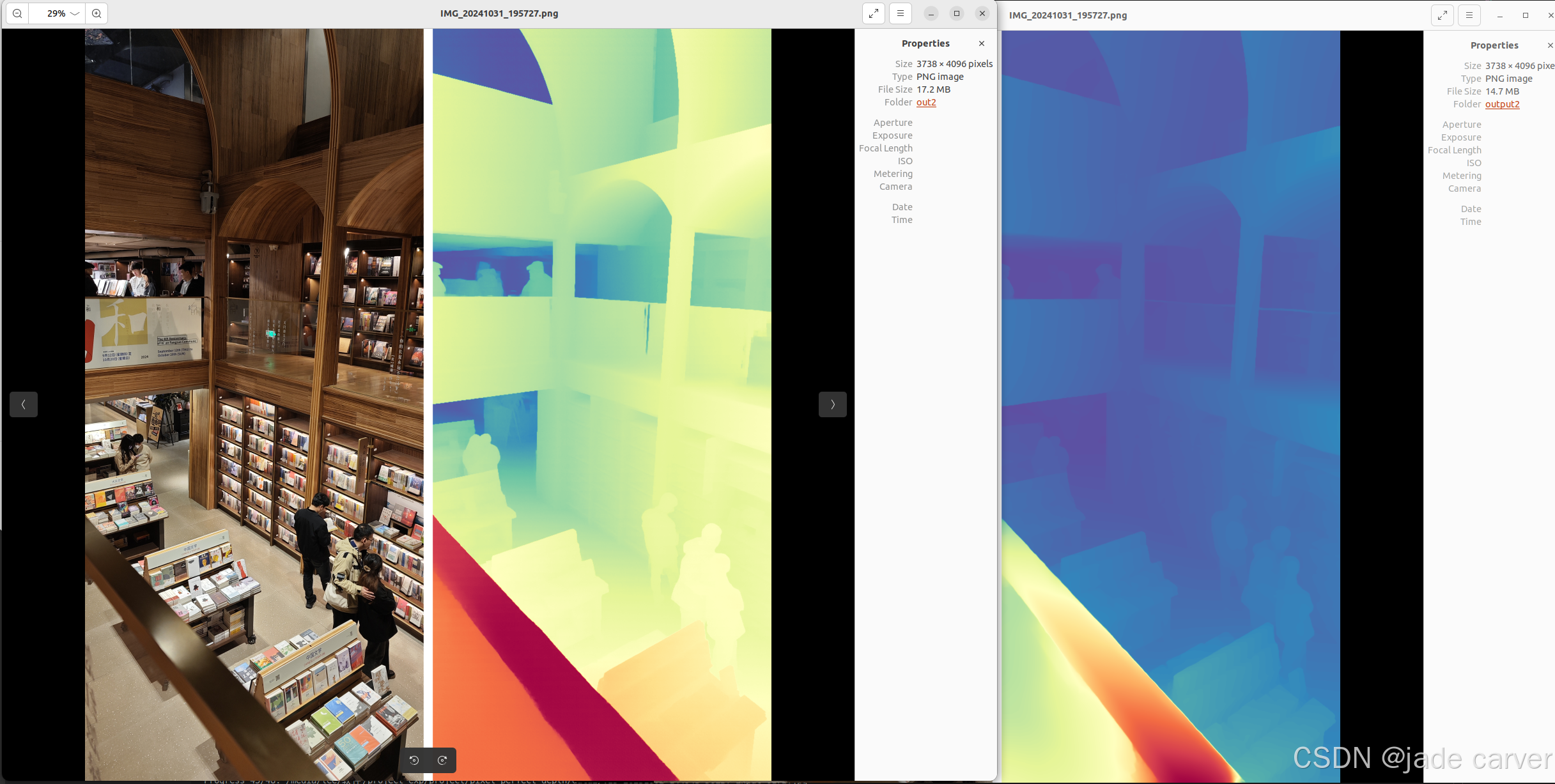
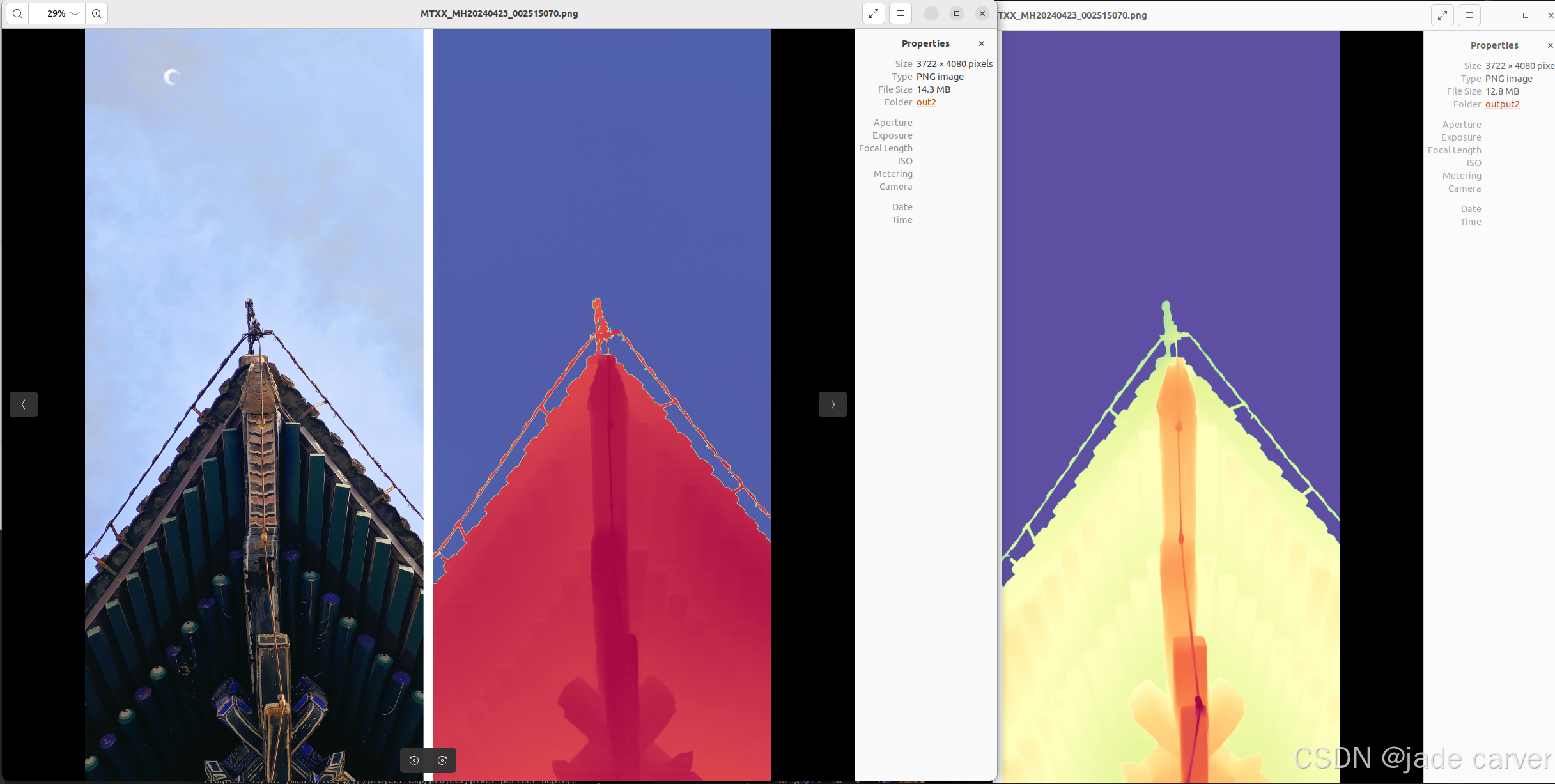
从左到右依次:原图、pixel-perfect depth、depth anything v2
从上到下:pixel-perfect depth、depth anything v2,本文方法可以从上述理论看出细节必定会有提升,比如边缘位置。
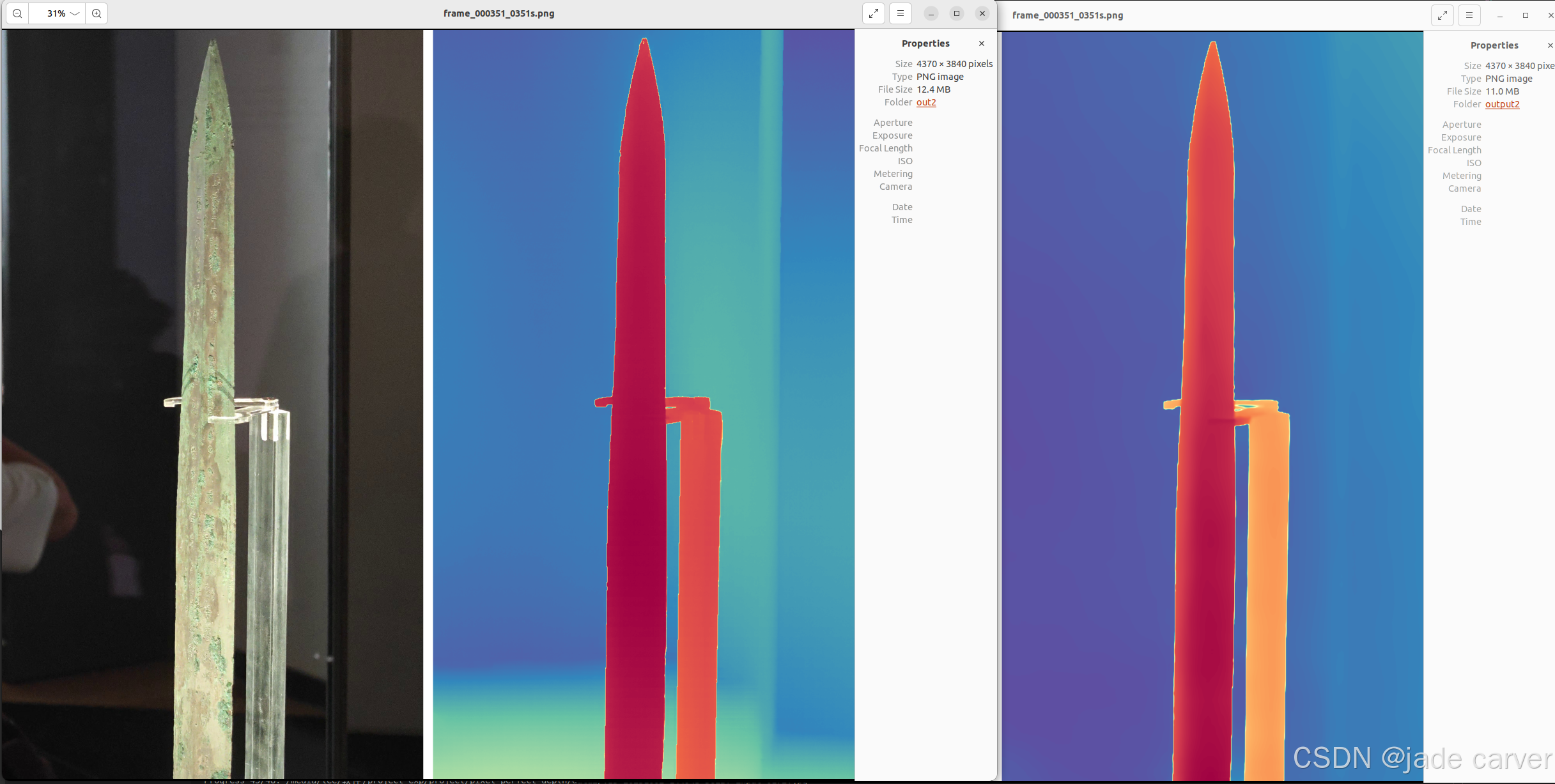
物体级别
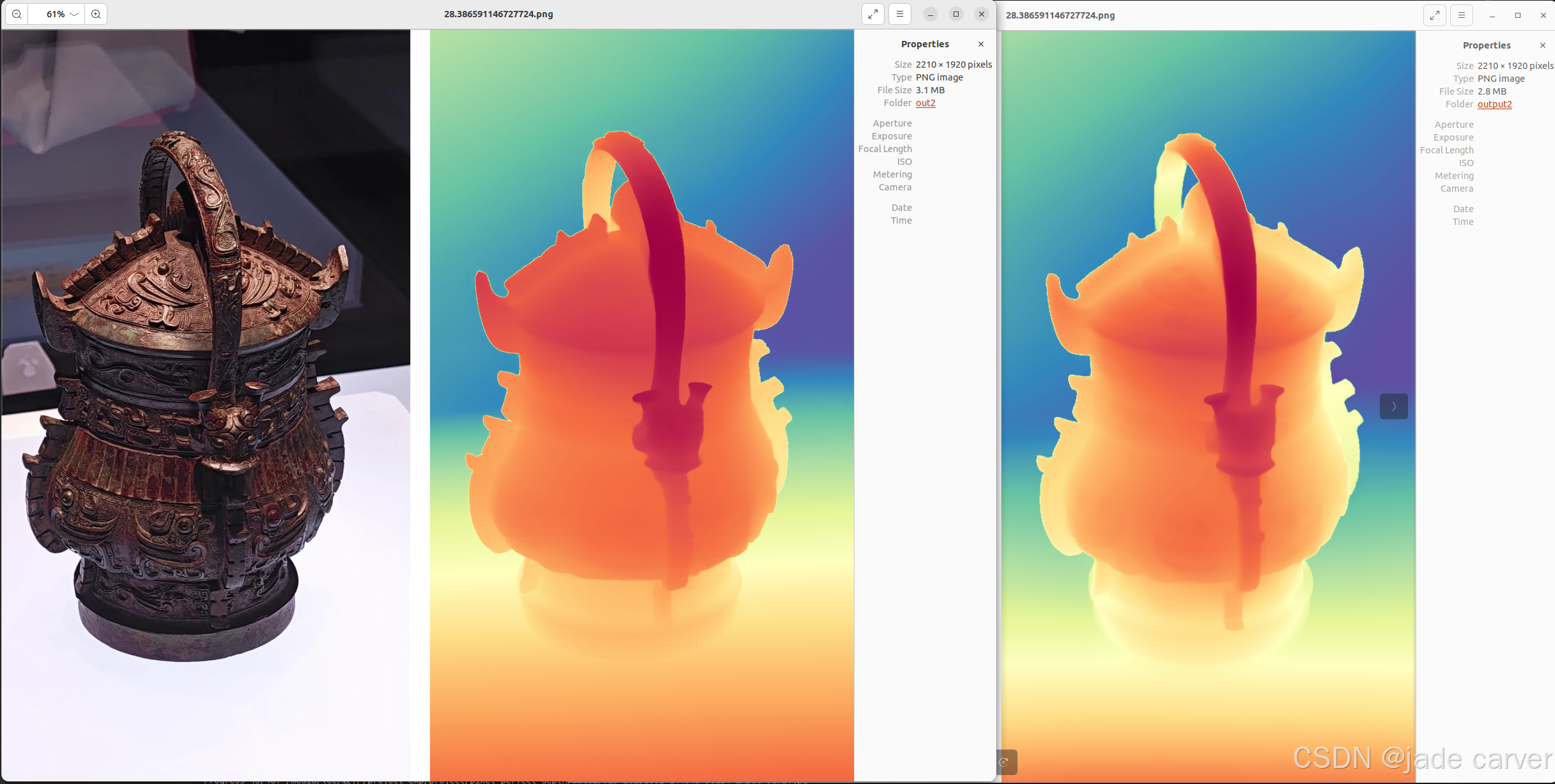
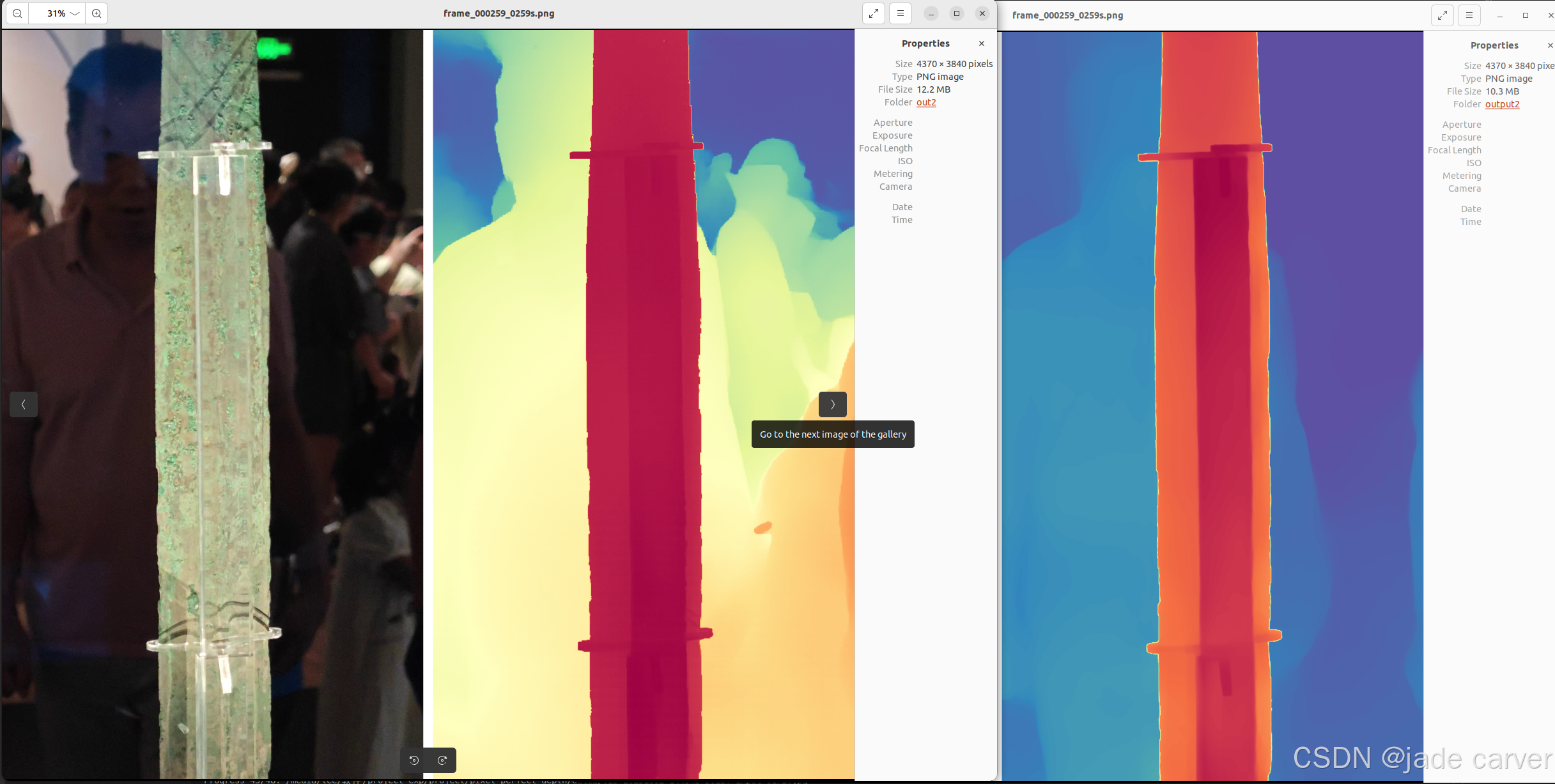
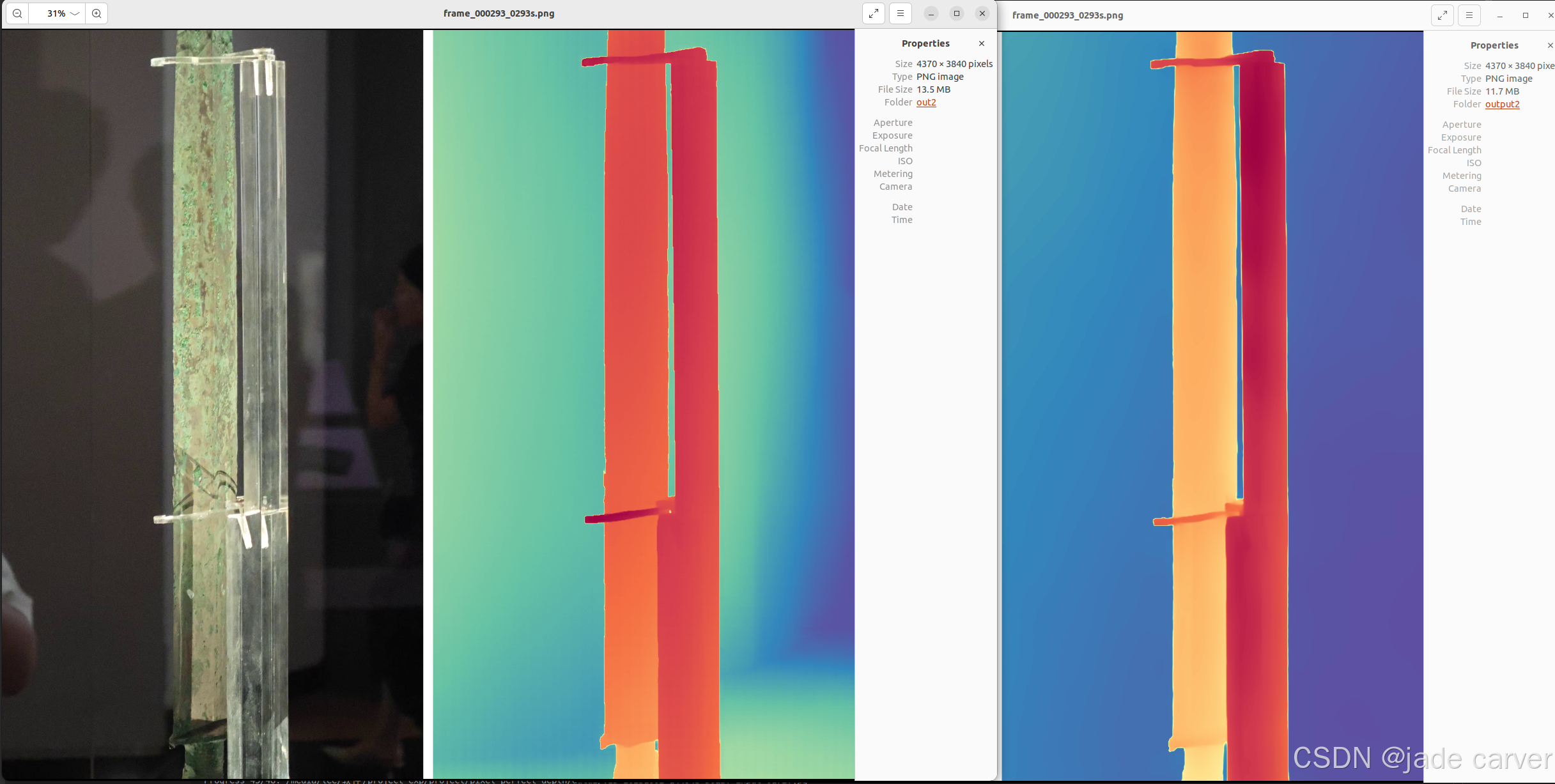
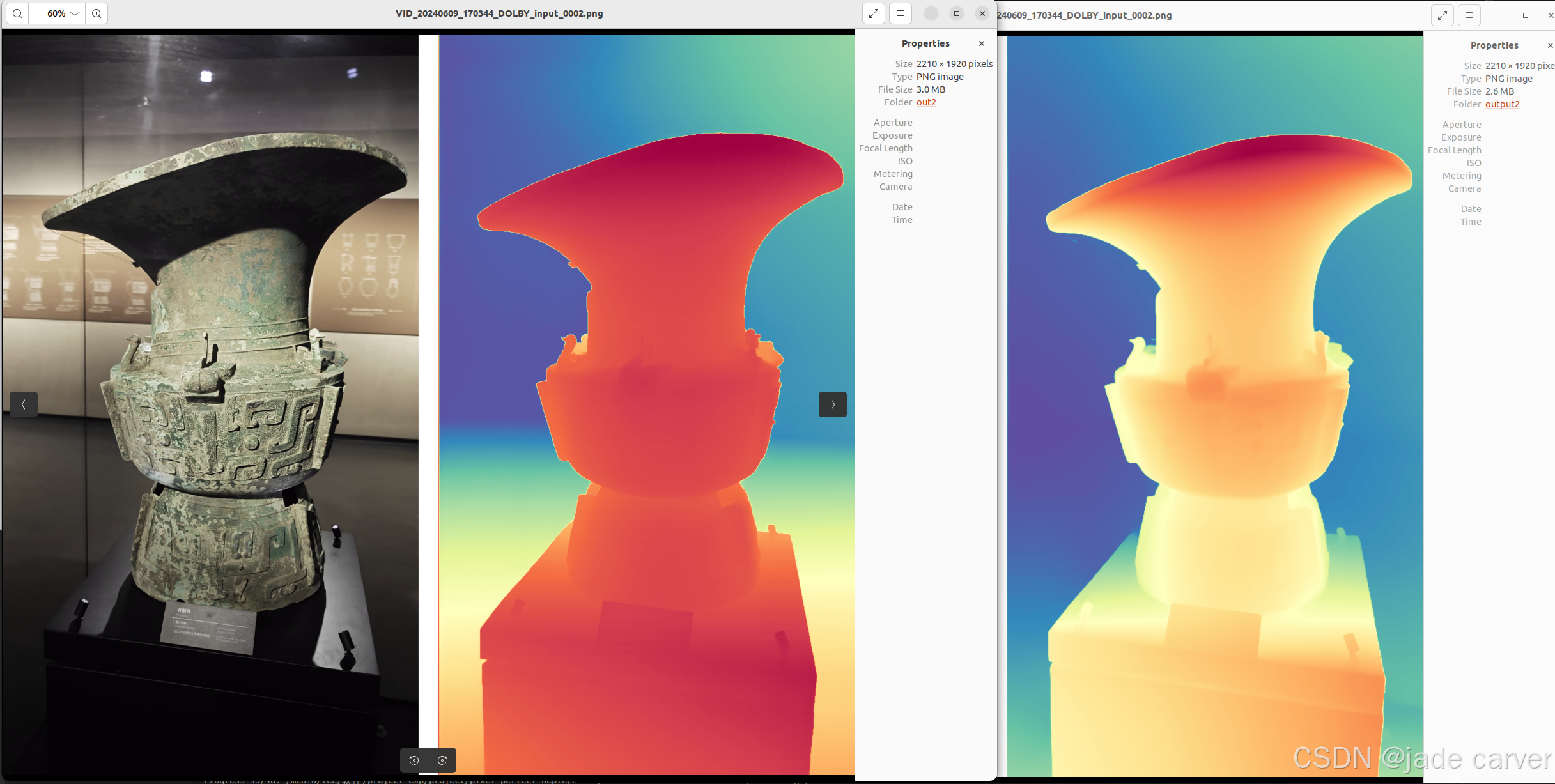
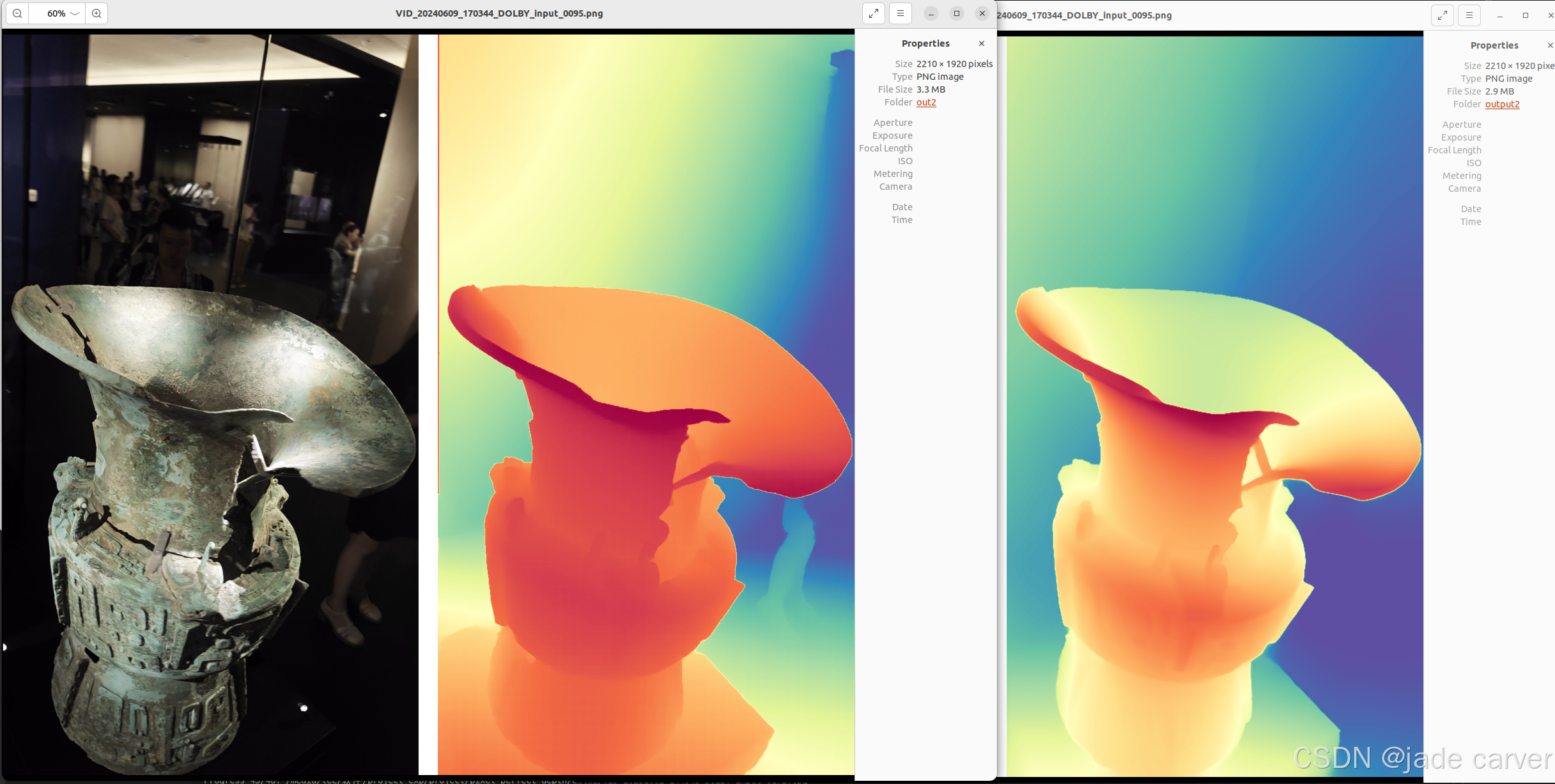


结论:相差无几,差别在于,depth anything v2在极其靠近的地方能保留细节,而本文方法则在中等距离范围上能保留细节(对比剑旁边的人)
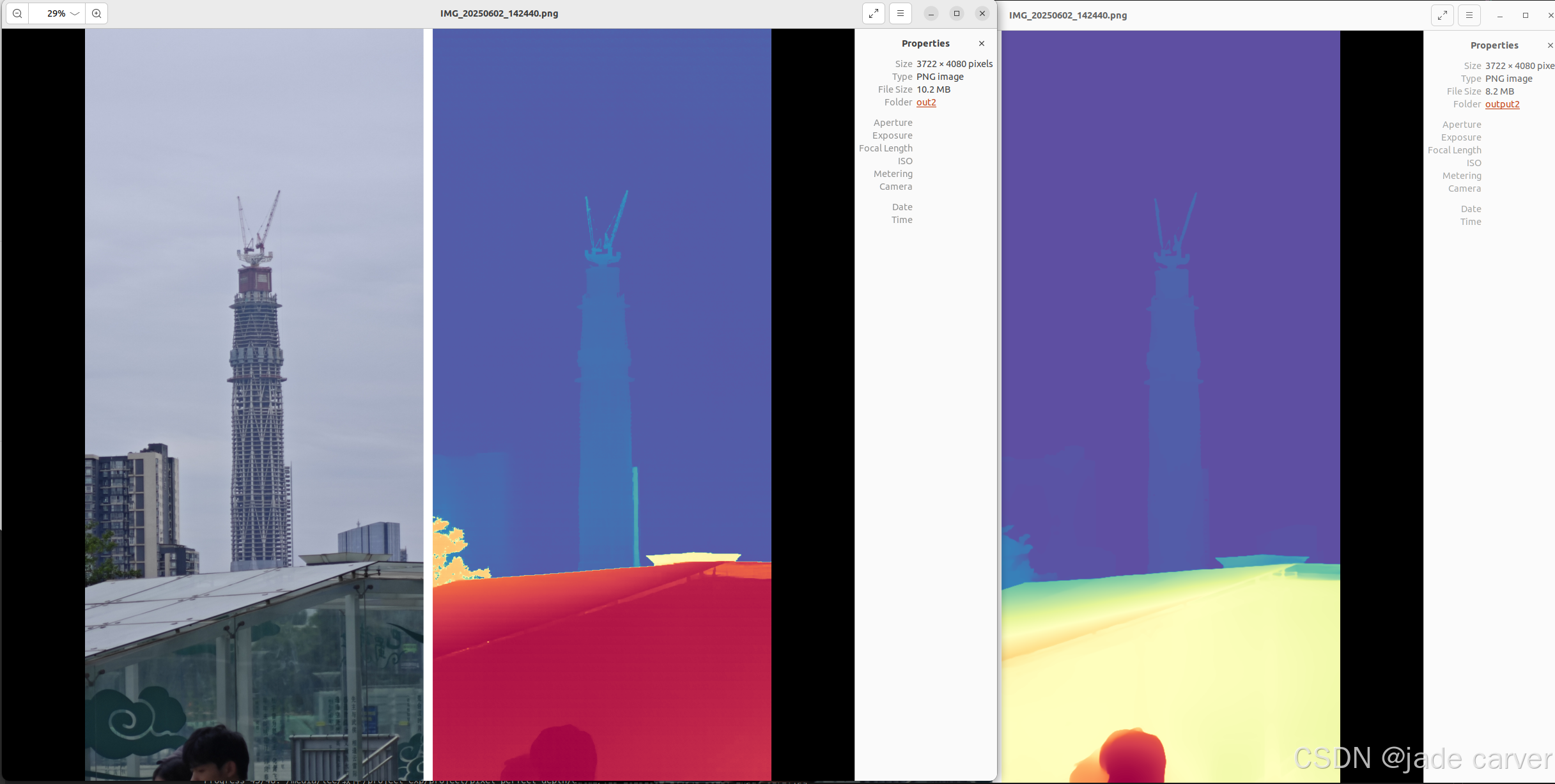
室内外中等距离图像
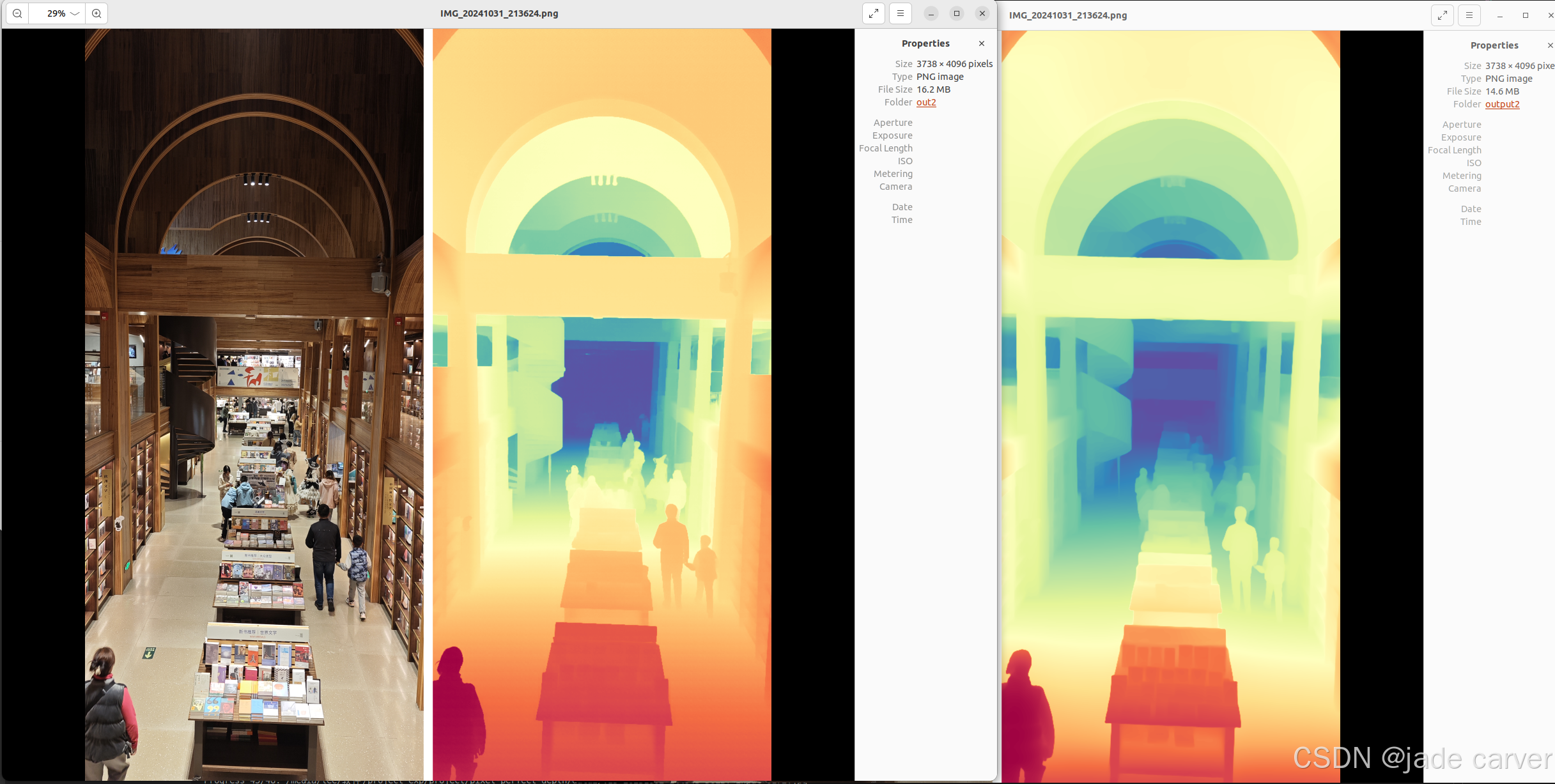
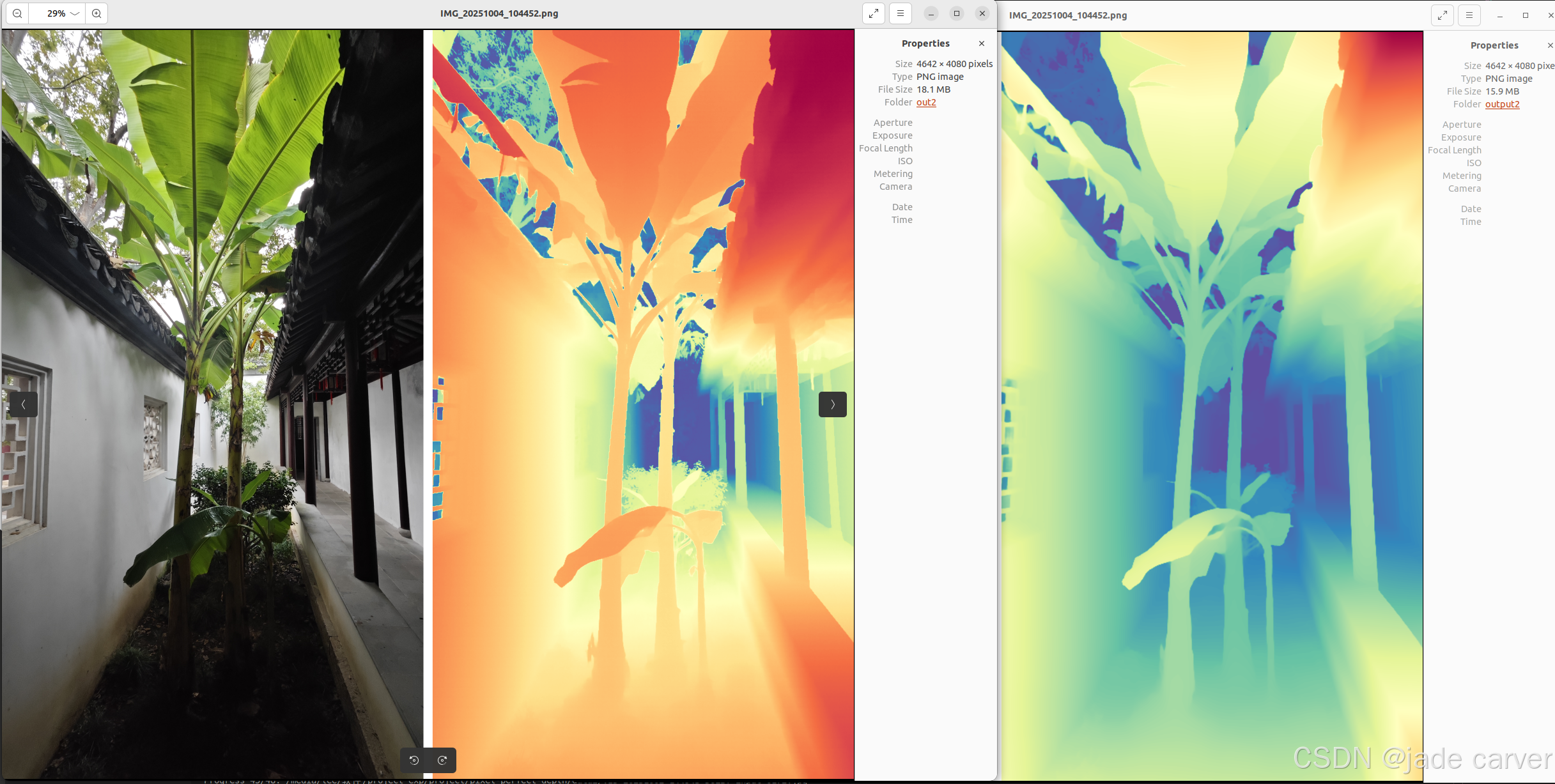
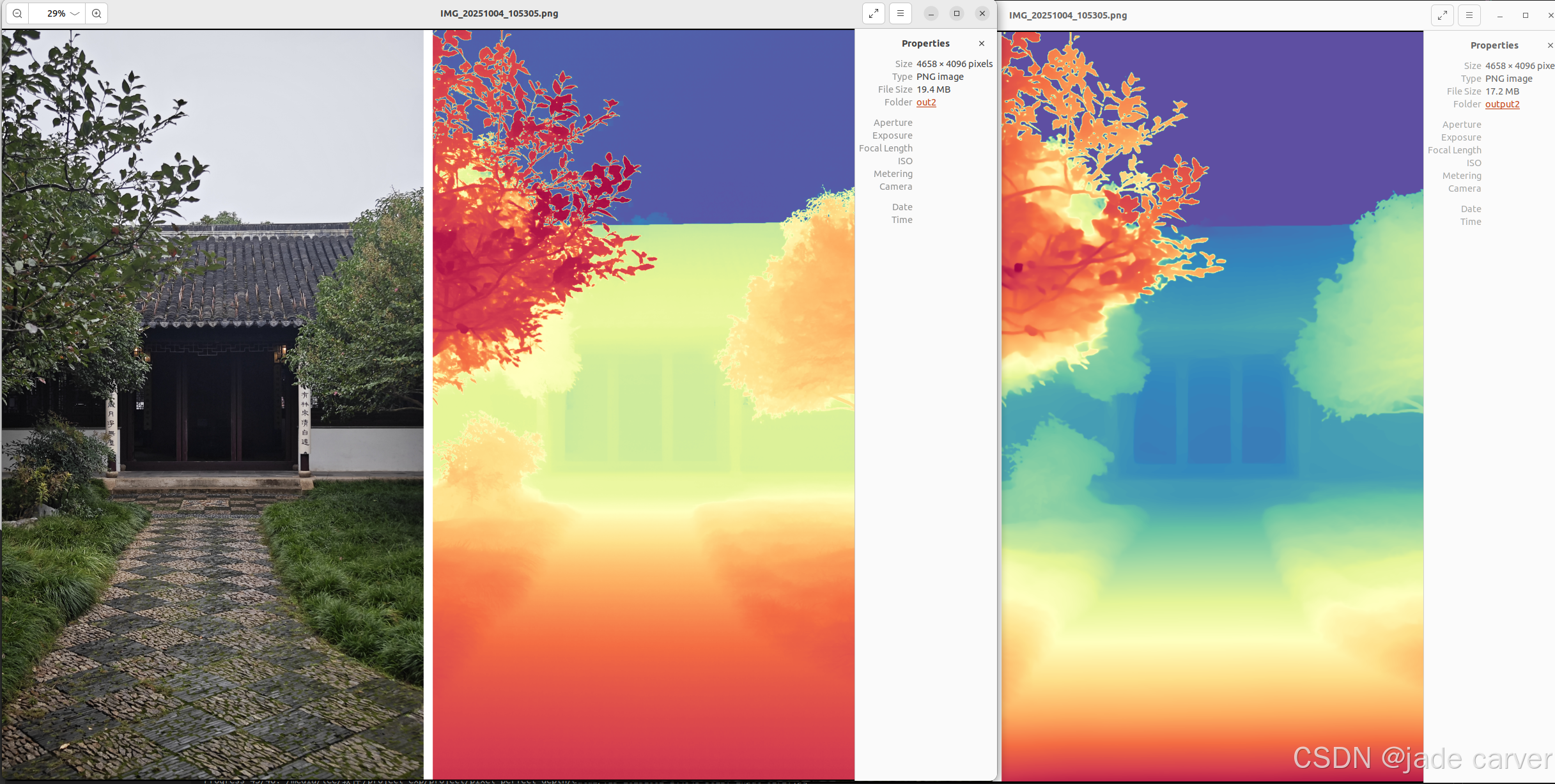
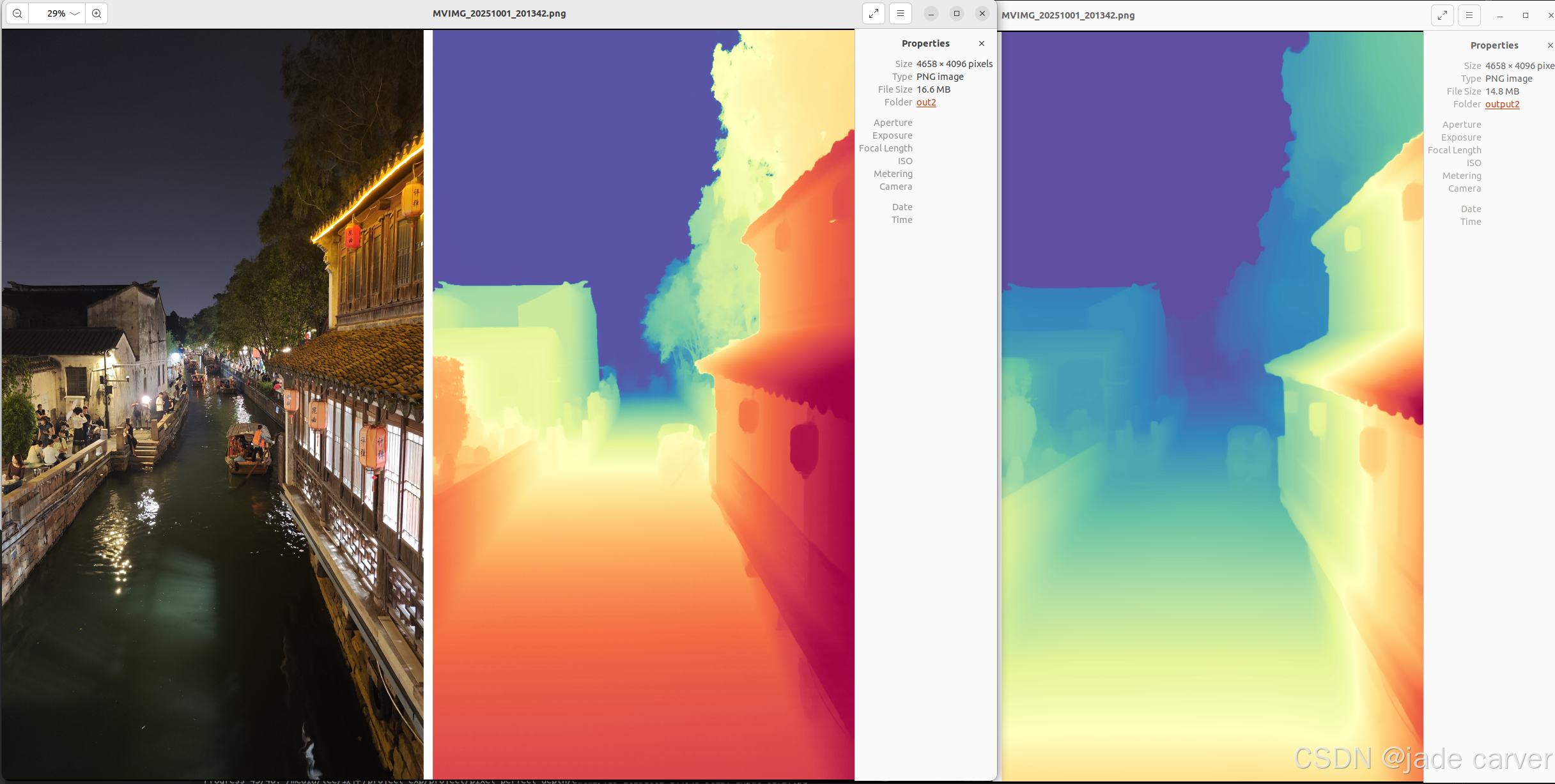






结论:对于树枝等细节本文方法较好,而对于远距离的位置,depth anything v2较好
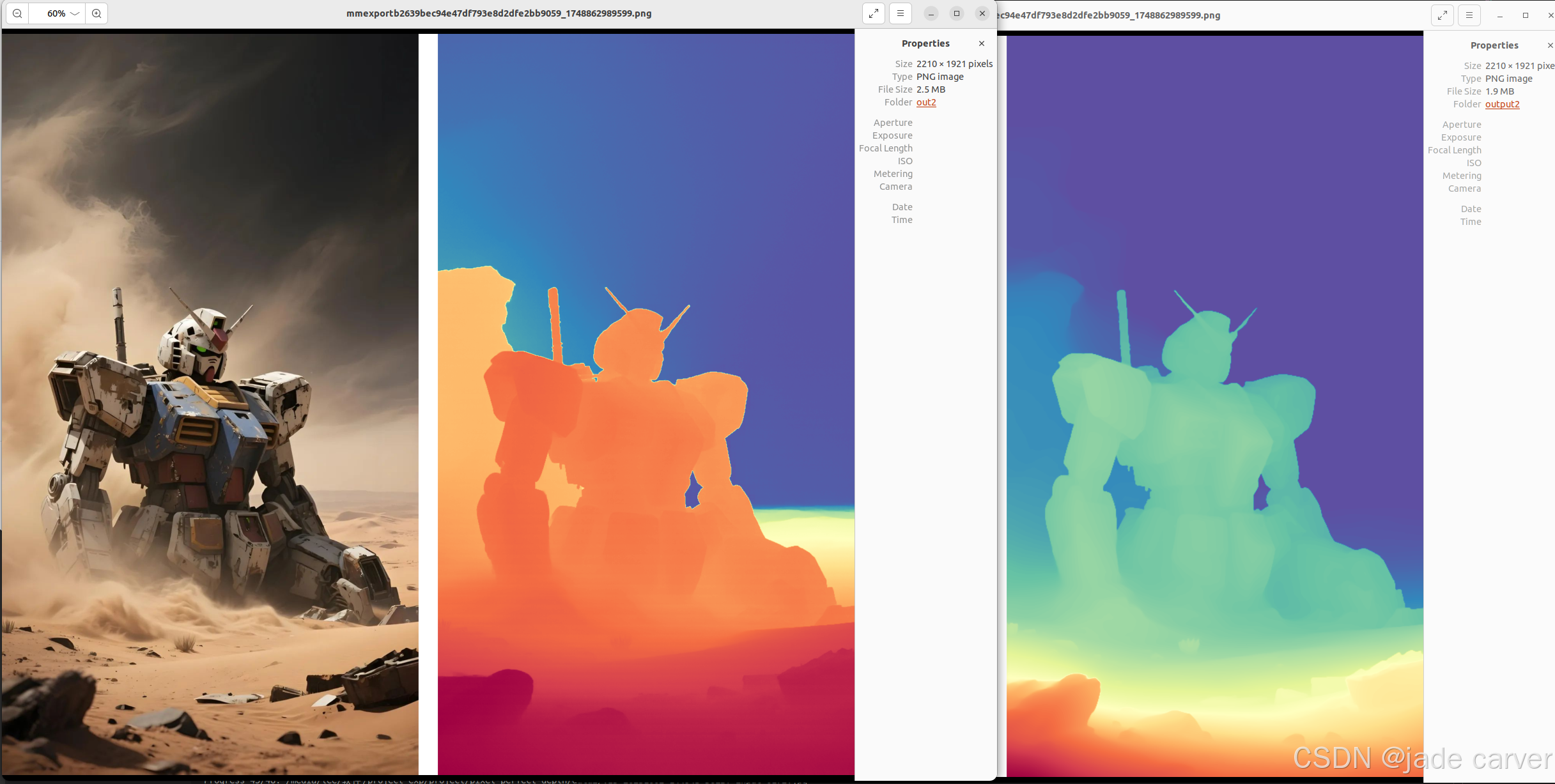
大型场景
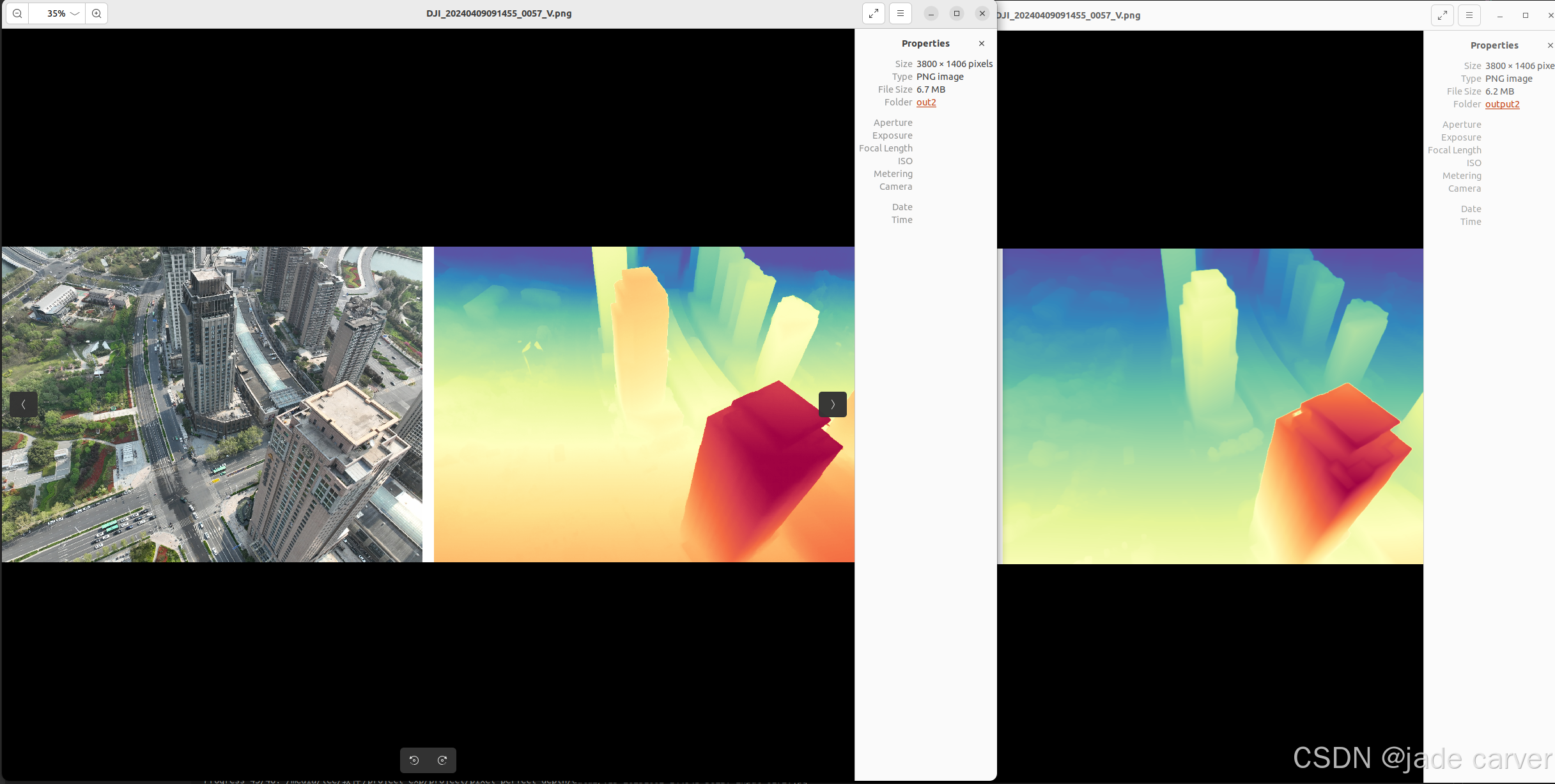
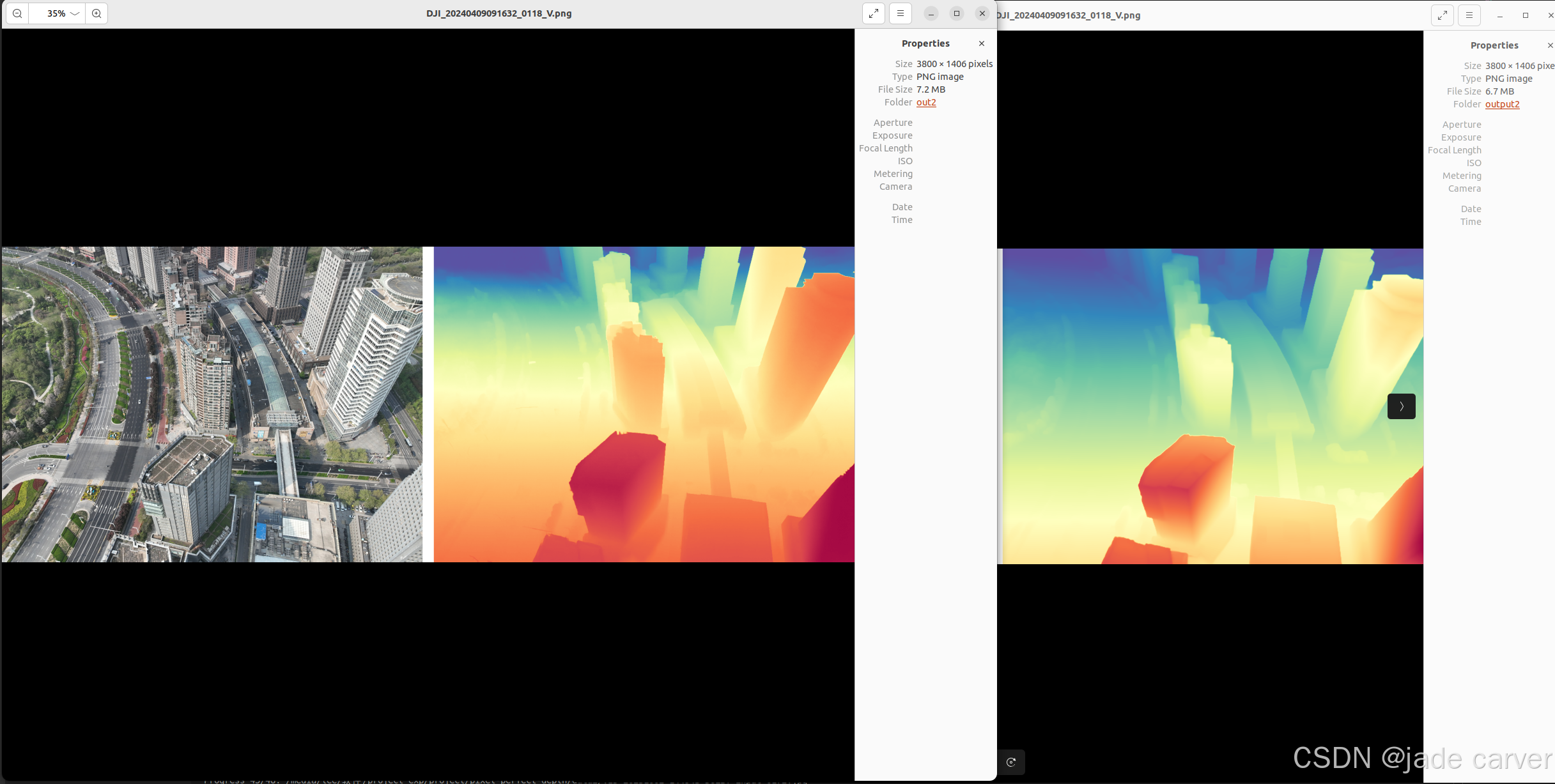
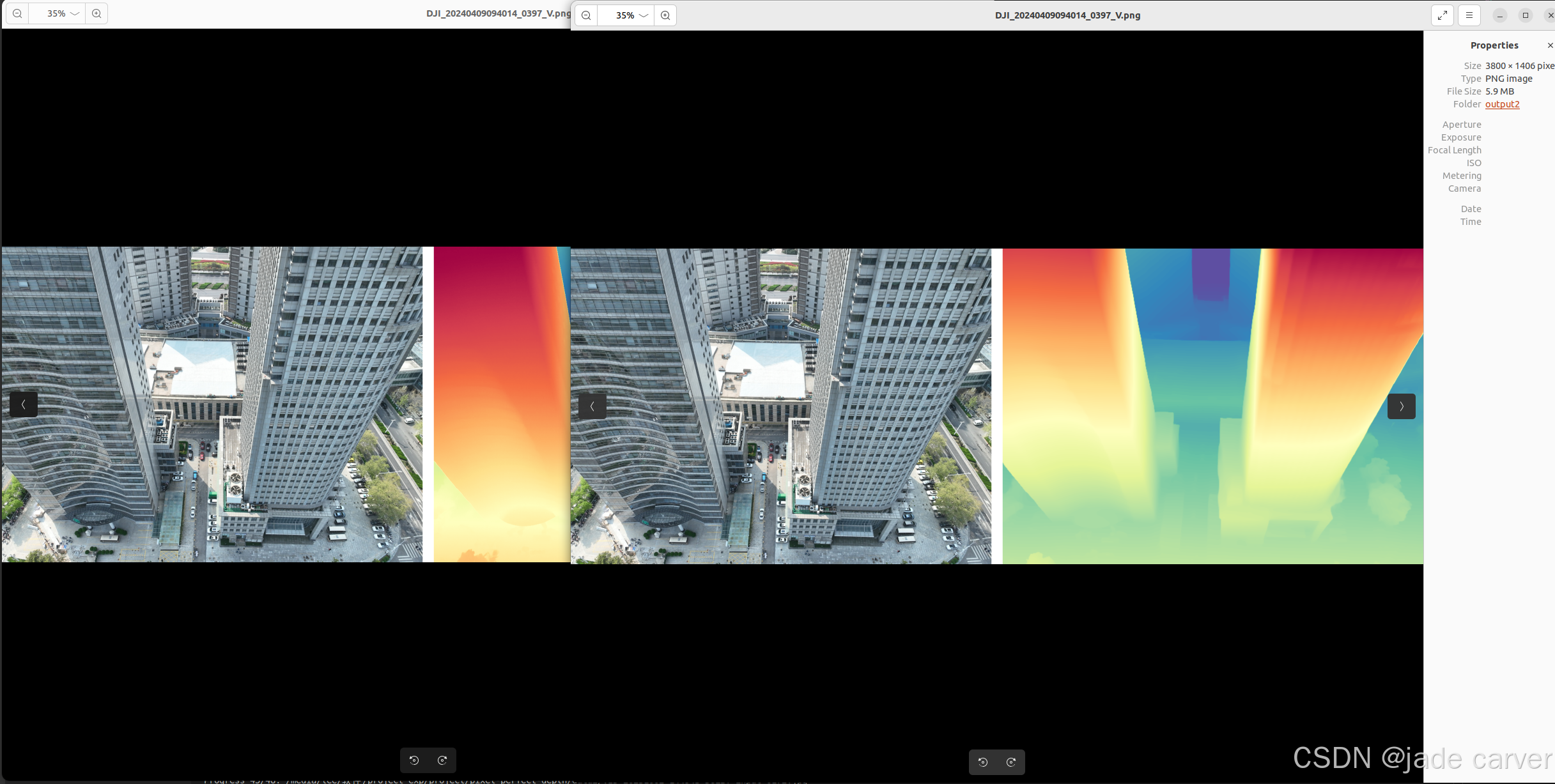
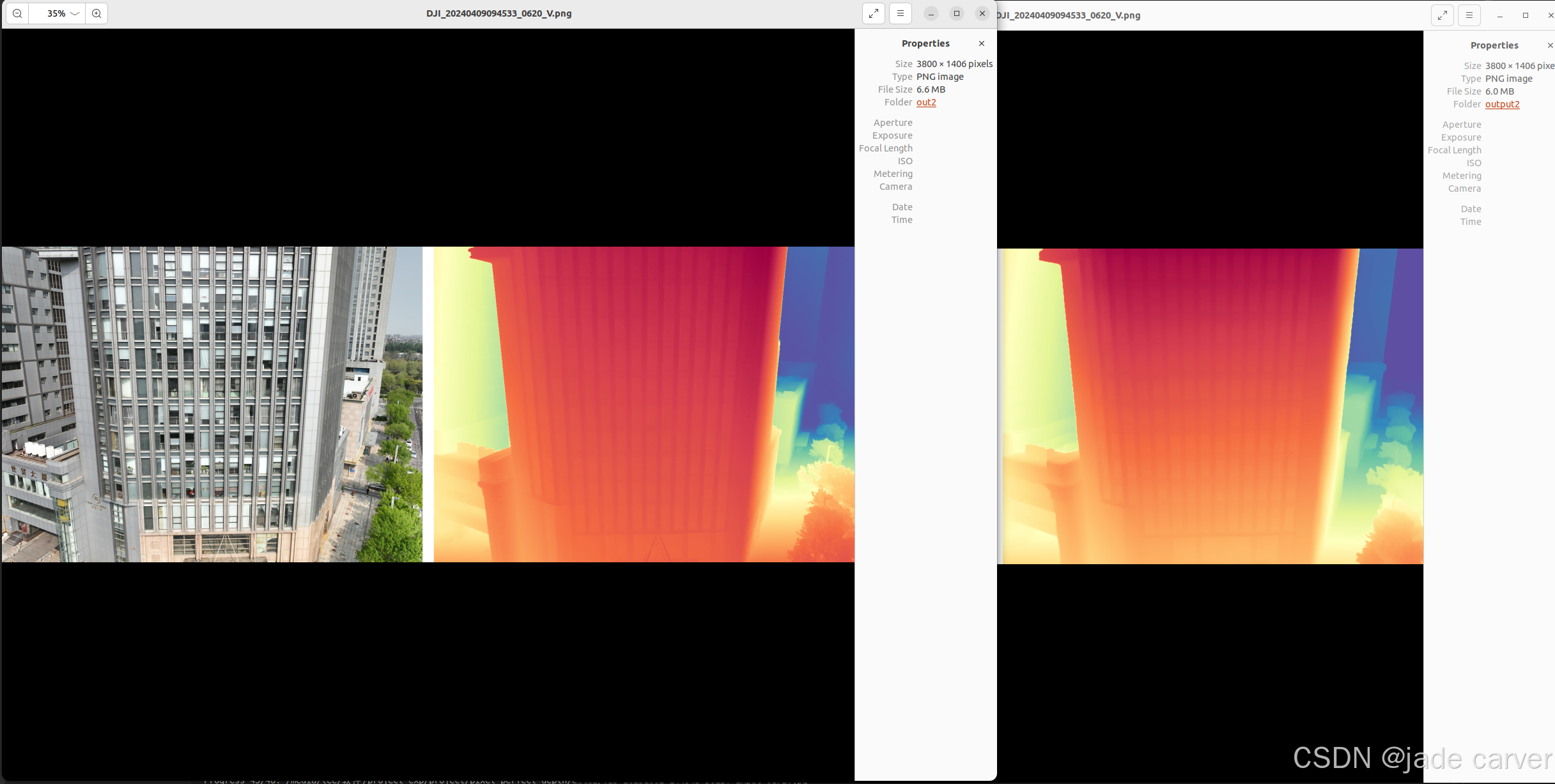
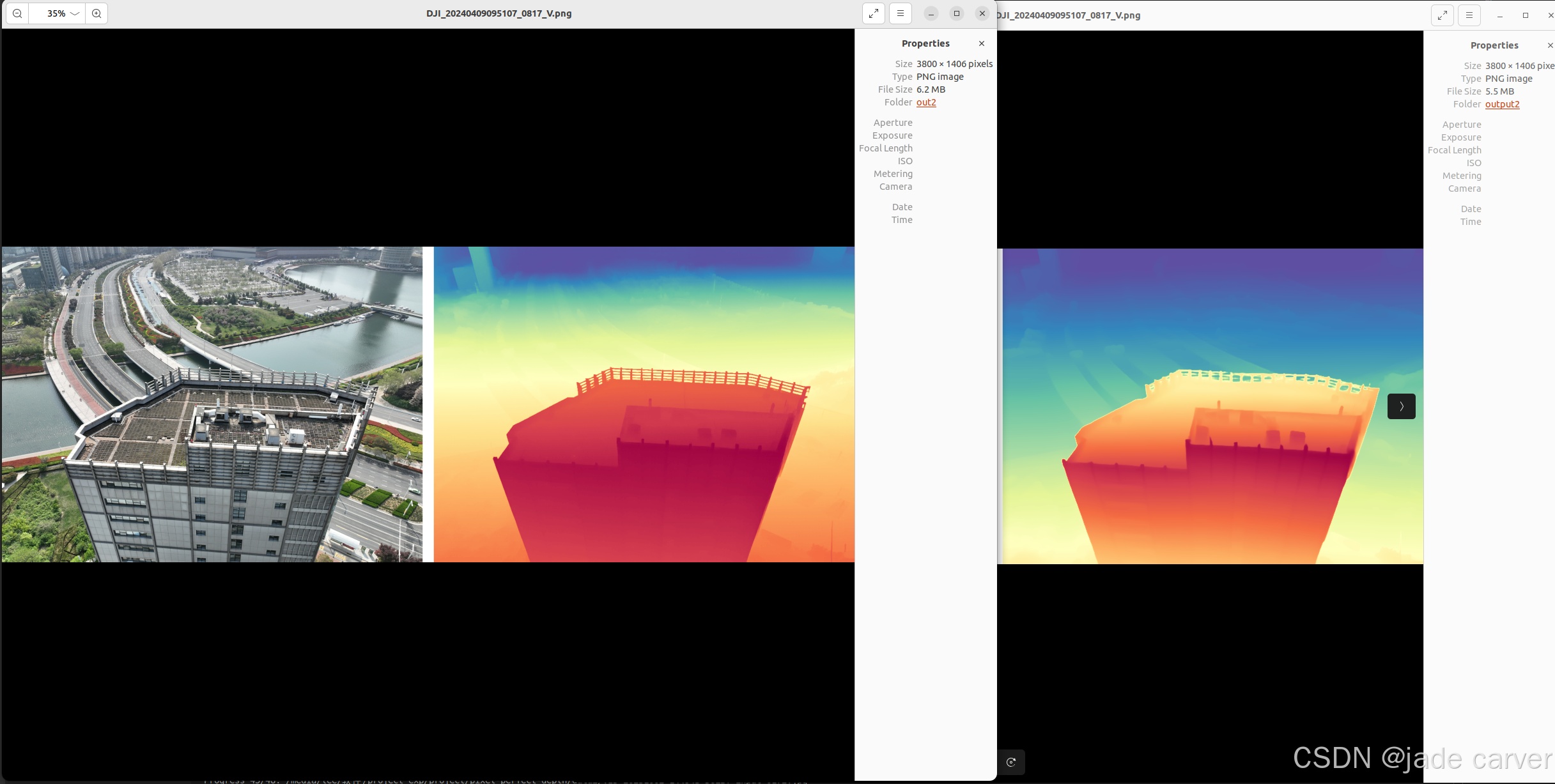


结论:同等距离水平上,本文方法在细节效果上相比depth anything v2表现较好,也就是说,只要估计得到深度值,细节上是相对较好的。但是在超远距离情况下,或者超近距离情况下,会有丢失深度的情况
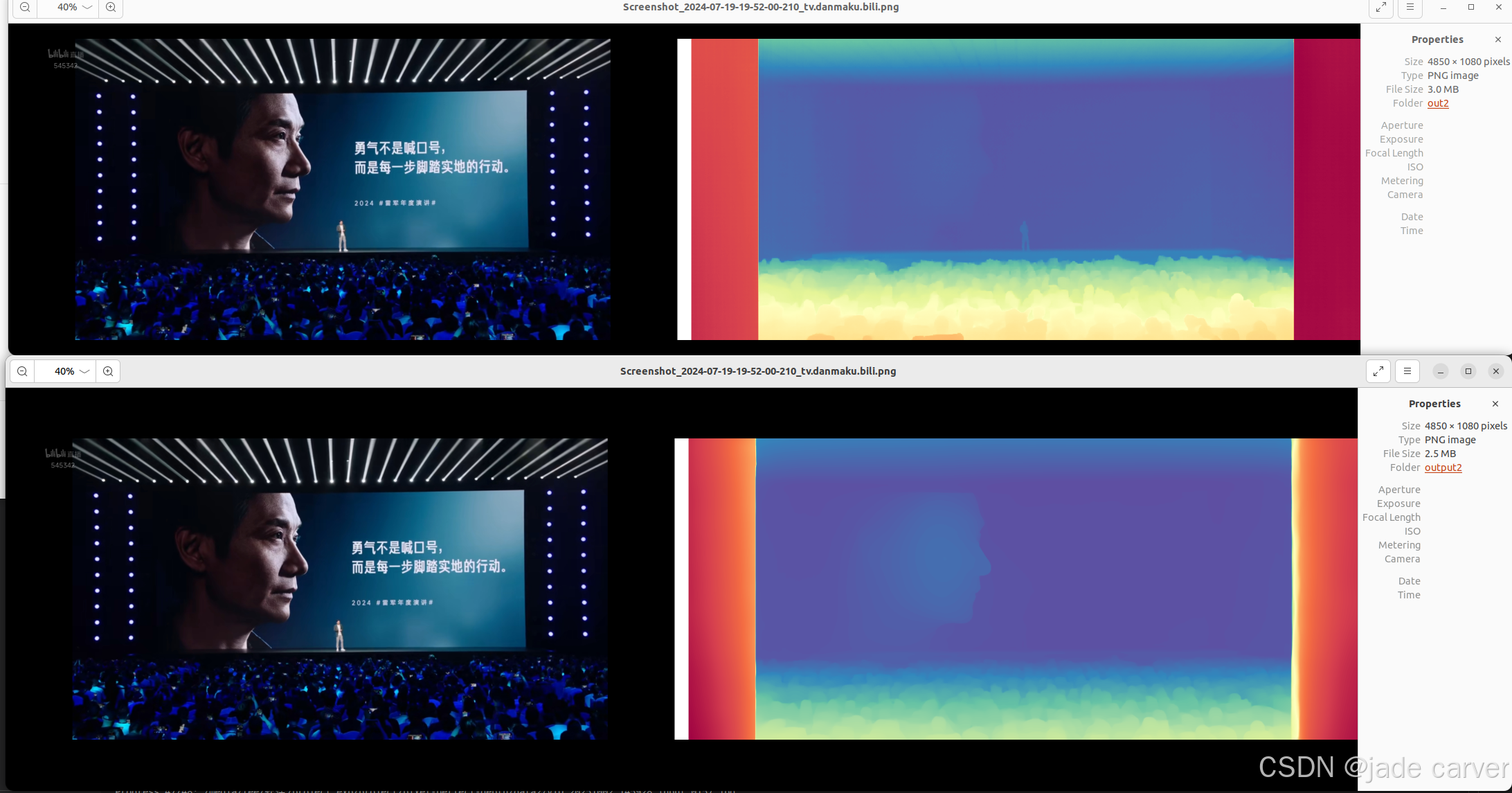
play一下
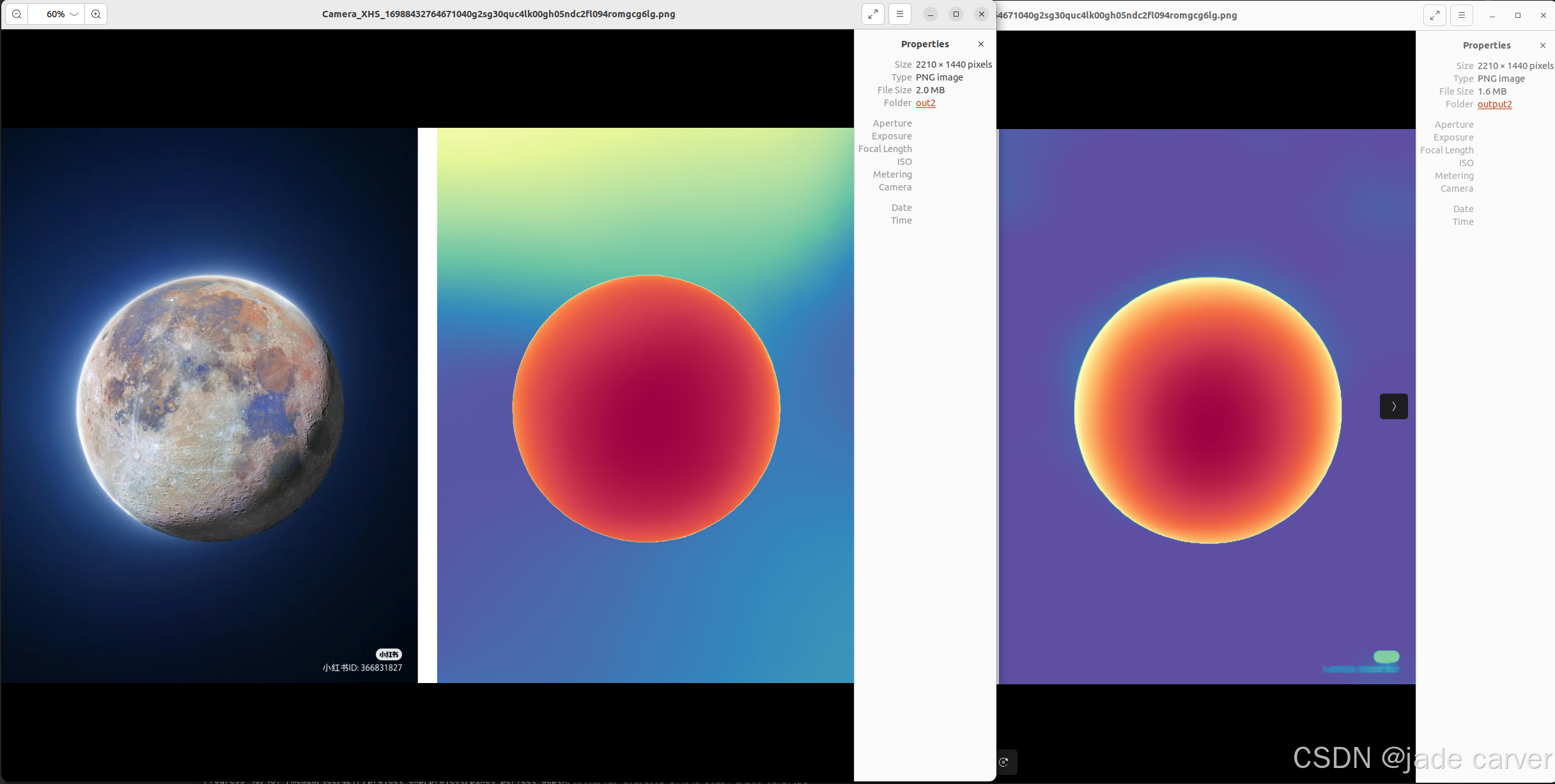
depth anything v2还是稳啊!
好帅!
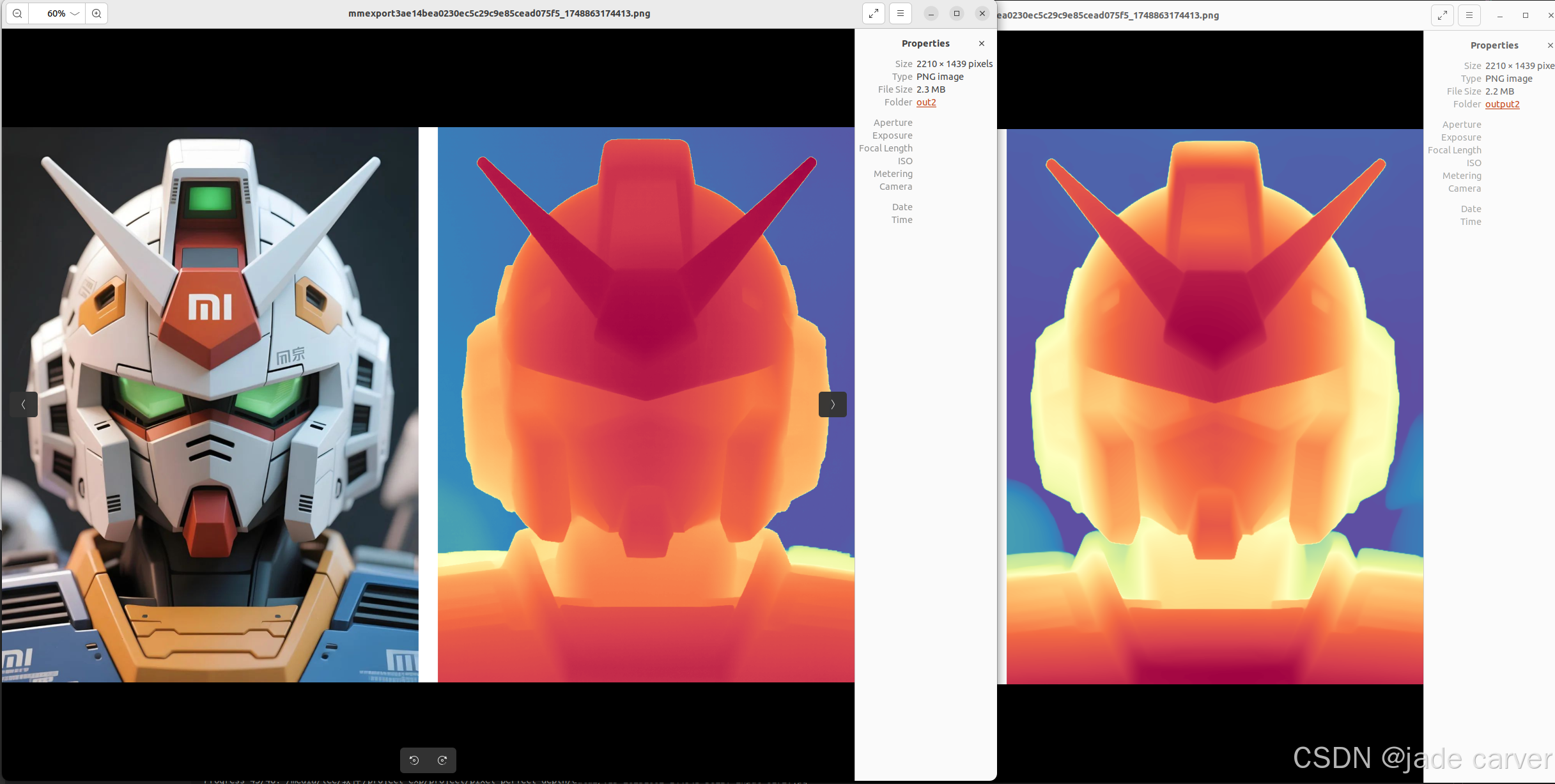
mi字型高达,本文是xiaomi ev出品
接着帅!
牛逼!