基于python写的PDF表格提取到excel文档
PDF表格提取工具是我基于Python开发的桌面应用程序,用于从PDF文件中自动识别并提取表格的内容,并将其转换为Excel格式文件。工具比较轻量,免安装使用,能够智能识别PDF文档中的表格结构,并将表格数据准确提取到Excel文件中。该工具采用现代化的图形用户界面,操作简单直观,支持批量处理多个PDF文件,大大提高了文档处理的效率。
处理前,pdf文档的表格数据
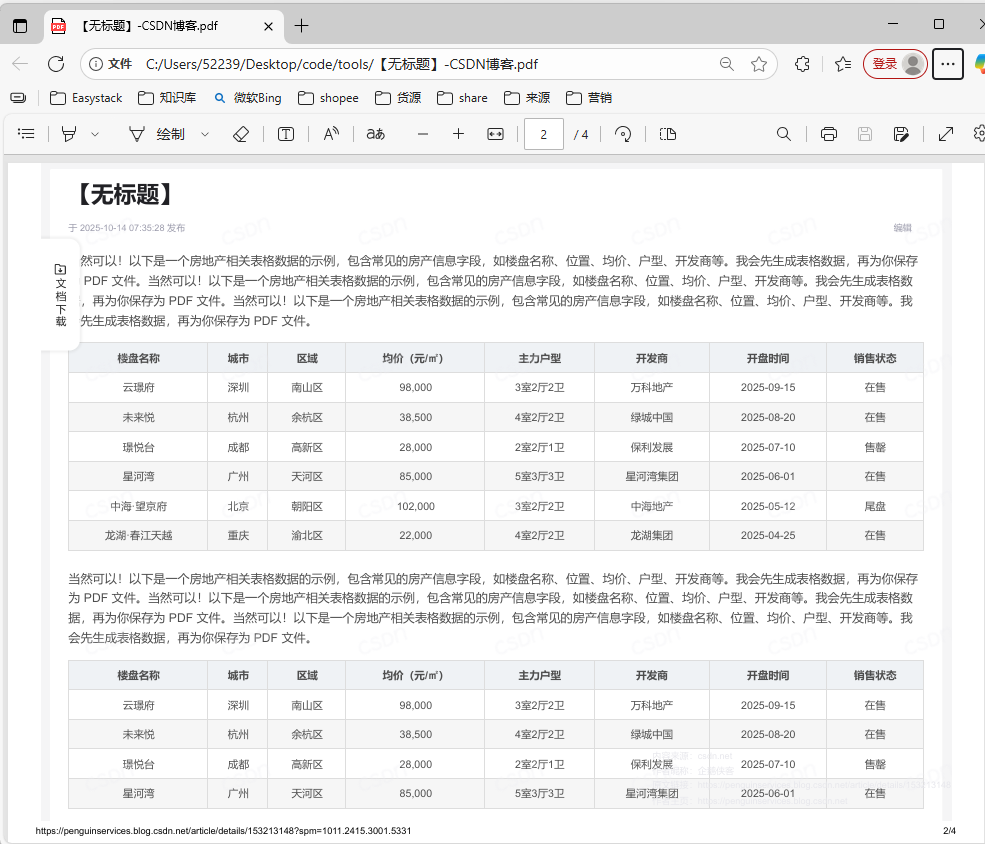
使用工具处理后,pdf文档的表格数据提取保存在excel表格的数据
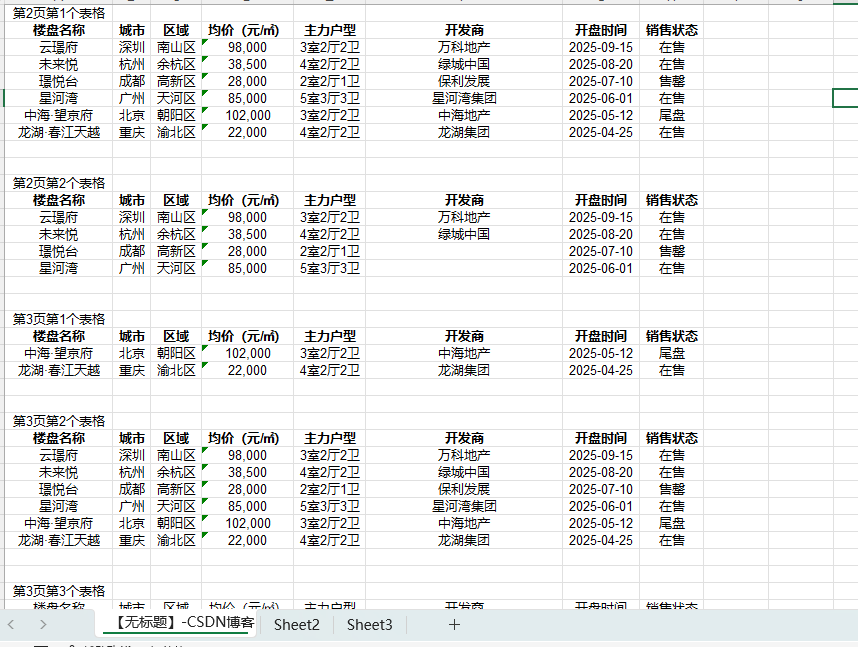
主要功能
智能表格识别:自动识别PDF文档中的表格结构、支持复杂表格格式的解析、跳过无表格内容的PDF文件;
批量处理:支持同时选择多个PDF文件进行处理、每个PDF文件生成独立的Excel文件、自动以PDF文件名命名对应的Excel文件;
灵活输出:支持自定义保存目录、自动创建输出文件夹、保持原始表格的格式和结构;
用户友好界面:基于wxPython的现代化GUI界面、实时显示处理进度和详细日志、支持文件列表显示和目录选择;
优势特点
- ✅ 操作简单:图形化界面,无需编程知识
- ✅ 处理高效:支持批量处理,节省大量时间
- ✅ 识别准确:智能识别表格结构,提取准确率高
- ✅ 格式保持:保持原始表格的布局和格式
- ✅ 错误处理:完善的错误提示和日志记录
使用步骤
-
启动应用程序:双击运行
pdfToexcel.exe可执行文件; -
选择PDF文件:点击
选择文件按钮,在文件对话框中选择一个或多个PDF文件,选中的文件会显示在文件列表中; -
设置保存目录:点击
选择目录按钮,选择Excel文件的保存位置,默认保存到程序目录下的output文件夹 -
开始处理:点击
开始执行按钮,观察日志窗口中的处理进度,等待处理完成提示; -
查看结果:处理完成后会弹出成功提示,在指定的保存目录中查看生成的Excel文件,每个PDF文件对应一个同名的Excel文件。
使用场景
- 文档数字化:将纸质文档中的表格转换为电子表格
- 数据整理:批量提取PDF报告中的表格数据
- 格式转换:将PDF表格转换为可编辑的Excel格式
- 办公自动化:提高文档处理效率,减少手工录入
写在最后
这个工具其实是我老婆给我提的,她平时很多工作场景都要处理文档数据,不想让他那么辛苦,利用自己的专业能力+AI大法写了这个工具。当然对于需要从PDF报告中提取表格数据的用户来说,它能够显著提高工作效率,减少手工录入的工作量。特别是在财务、统计、报告分析等领域,这种自动化工具能够节省大量时间。
夸克网盘下载:https://pan.quark.cn/s/6b82fa99bd6b
迅雷网盘下载:https://pan.xunlei.com/s/VObVUwNFOlhokUUCOExq1KRQA1?pwd=fmqb#