后训练技术介绍
一、简介
通常训练语言模型的时候,我们首先是需要从大量数据集中进行一次训练,得到一个基础模型。但此时训练出来的模型,由于其接受数据的冗杂性(数据可能来自各个领域),其泛化能力强但是如果要应用于某一专业领域——比如只用于医学领域或在线客服对话等,效果不会太好。从安全角度来说,为了避免信息泄露,我们有必要在预先训练出的基础模型上,再对它进行一次训练,以达到实现某一特定功能的目的,这就是后训练。后训练的目的是为了获得定制化的大模型。
二、预训练
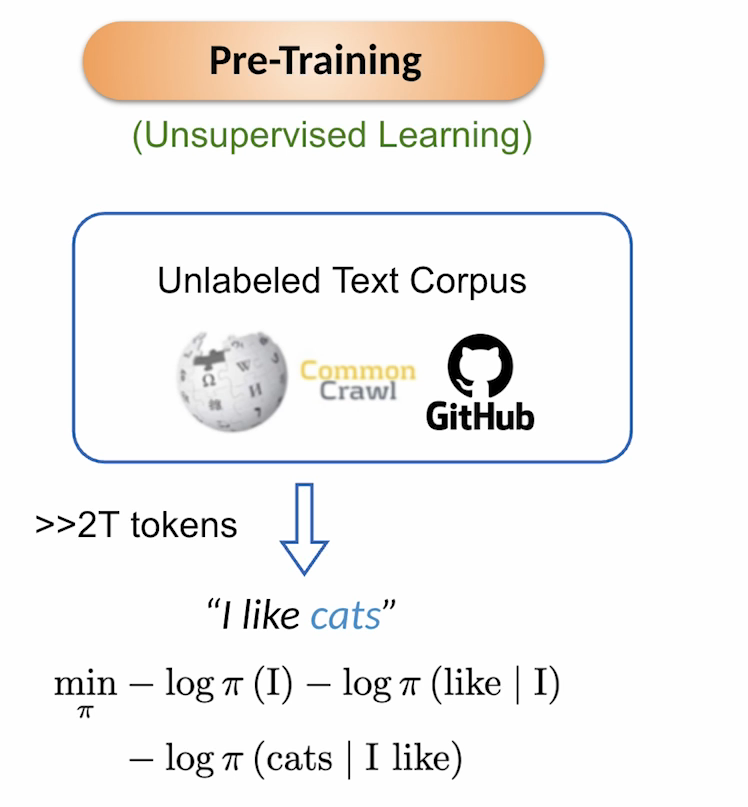
预训练通常是无监督学习,其数据来源于大规模无标注文本语料(如维基百科、Common Crawl等),通常训练规模庞大——超过2万亿。其优化方式之一是最小化负对数概率,以“我喜欢猫”为例,模型会优先最小化“我”的负对数概率,然后在给定“我”的条件下,最小化“喜欢”的负对数似然(类似条件概率),最后是最小化给定“我喜欢”时“猫”的负对数似然。这样训练出来的模型可以通过一个词预测出下一个词,类似于做文本生成任务。
三、后训练方法
模型在经过预训练后,并不能直接应用,而是根据实际需求进行“再加工”以生成特定的模型,这是后训练的目的,而后训练的数据集规模一般远远少于预训练。而后训练的方法分为三种。
1.监督微调(SFT)
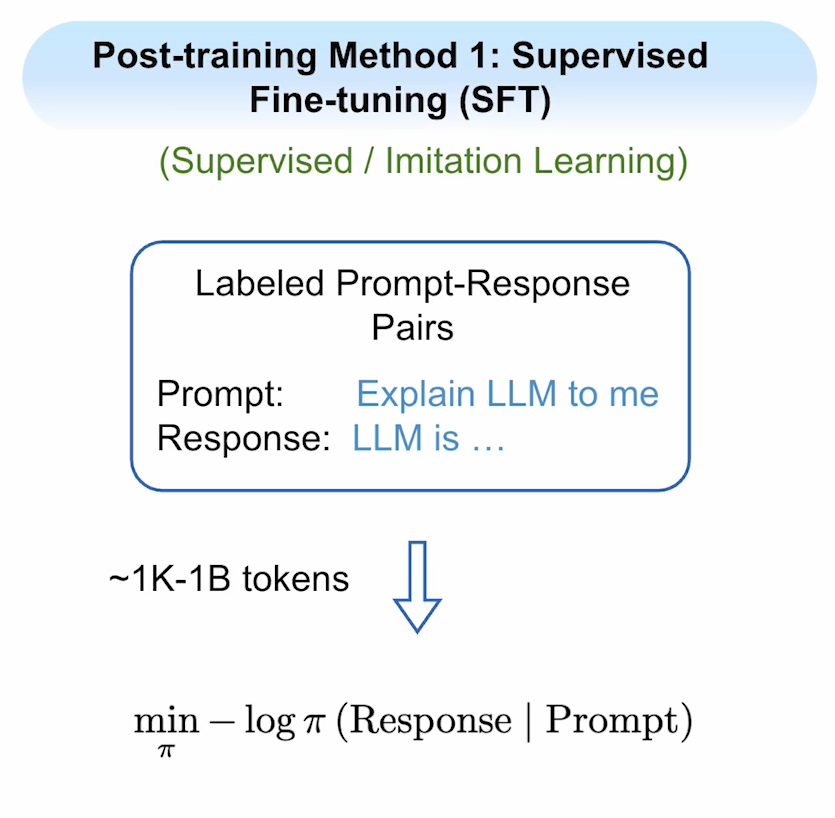
这是最简单也是应用最多的一种方法,它属于有监督学习范畴。需要创建提示标记-响应对数据集(1000-10亿),其中提示一般是给模型的指令,响应是我们期望模型给出的回答。它的训练特点是:仅针对响应标记训练,而不涉及到提示。
2.直接偏好优化(DPO)
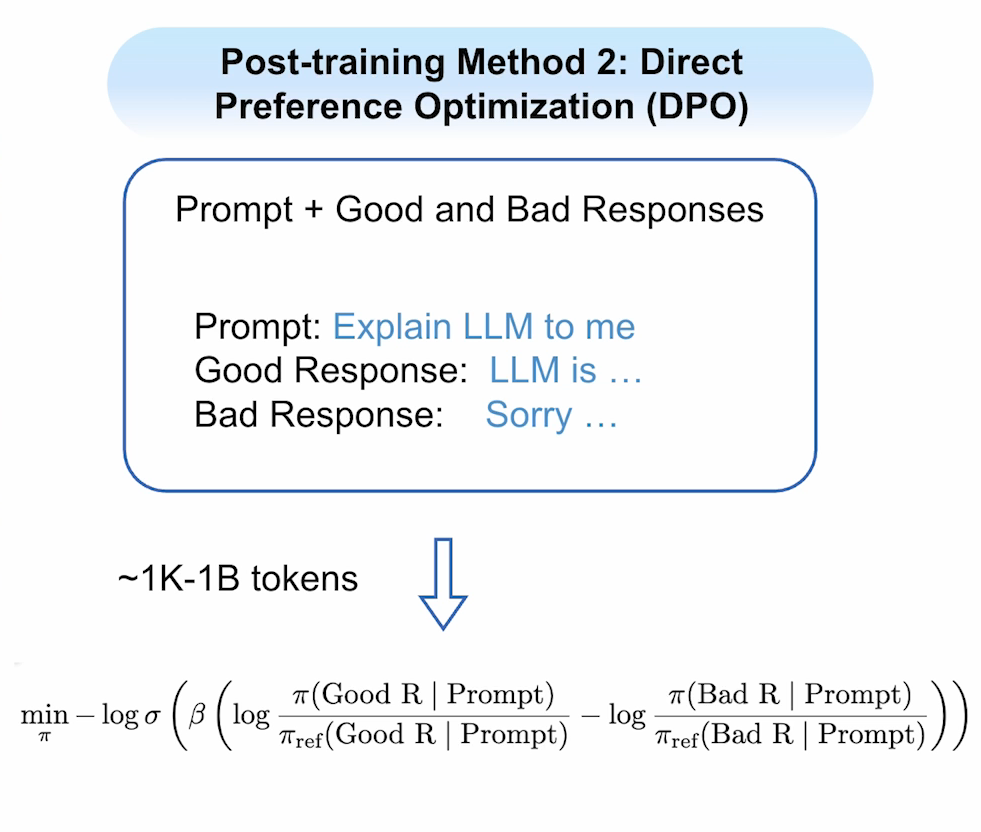
这个方法需要创建包含提示在内的优质响应和劣质相应数据集,其训练函数较之SFT更复杂。它会根据任一提示,生成多个响应并筛选出优质和劣质响应。训练目的是使其远离劣质响应并靠近优质响应,这个与SFT不同点在于:前者只需要尽量靠近正确答案即可,而这个不仅需要靠近正确答案,还需要远离错误答案。打个比方:以在学校学习为例,SFT就是老师告诉你需要向某个好学生学习(比如说小王);而DPO就是老师告诉你,不仅需要跟小王学习,还不要像小张这个坏学生学习。
3.在线强化学习(Online RL)
这个方法与前面都不同的是,它仅需要准备提示词和奖励函数即可。模型会根据提示,生成对应响应,再经过一个奖励函数给出评分,这使得模型会寻找出使得奖励最大的响应。它就相当于开放性主题作文:写什么都是对的,但是有评分标准给出最优的主题。

四、后学习要素
后学习的成功离不开良好的数据结构设计(不同的后学习方法需要不同的数据集结构),高效快捷的算法和合理的评价系统,分三点叙述:
1. 数据与算法协同设计
针对SFT,我们需要设计出提示标记和响应标记对;针对DPO,我们需要设计提示标记、良响应标记和劣响应标记;针对在线强化学习,我们又只需要设计提示标记和奖励函数。因此针对不同的后训练方法,需要设计出兼容的数据集。
2. 可靠高效的算法库
有了兼容的数据集,还需要设计对应算法,这就需要我们使用可靠的算法库来实现。HuggingFace TRL有前述的大部分算法,除此之外还有Open RLHF、veRL和Nemo RL等更精密、内存效率更高的库。
3. 合适的评估体系
有了数据和优化算法,还需要合适的评估体系来体现模型在训练前后的差异。现有流行语言模型评估标准包括:
-
对话机器人竞技场:基于人类偏好的聊天评估
-
替代人类评判的LLM评估:
AlpacaEval、MT Bench、Arena Hard -
指令模型静态基准:
LiveCodeBench(热门代码基准)、AIME 2024/2025(高难度数学评估) -
知识与推理数据集:
GPQA、MMLU Pro -
指令遵循评估:
IFEval -
函数调用与智能体评估:
BFCL、NexusBench、TauBench、ToolSandbox(后两者专注多工具使用场景)
需要注意的是,提升单一方面能力比较简单,难的是如何在不降低模型其他方面的评分下提高某一领域的评分。
五、后学习场景
后学习并非什么时候都要的,如果不是问非常专业或者专门处理某一事情的时候,往往不必经过后学习。
- 如果仅仅需要模型遵循少量的指令,可以仅通过提示词工程(prompt)完成,但其缺点是不稳定。
- 如果需要实时查询数据库,检索增强生成或者基于搜索的方式可能会适用。
- 应用于专业领域交互语言模型时,一般需要持续的预训练结合标准的后训练,并且后训练的数据尽可能多些(至少10亿),再让其学习交互规则。
- 当需要严格遵循大量指令(20条以上),或者需要提升特定技能(如构建强SQL模型、函数调用模型或数学推理模型)时,后训练是最恰当的——但应该要注意避免其它方面的退化现象。
来自课程:https://github.com/datawhalechina/Post-training-of-LLMs#
整理学习笔记用