基于 go 的分布式缓存
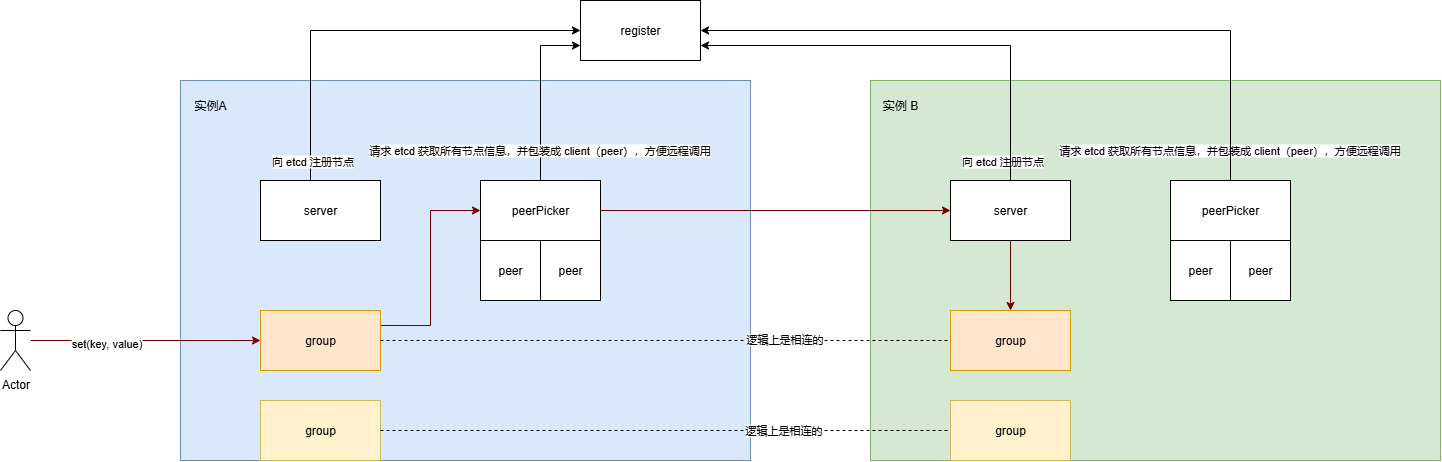
- register:注册中心,每个实例都会报错服务的名称和地址
- server:服务实例
- group:命名空间,每个服务实例都有相同的命名空间,这些 group 在逻辑上是相连的
- PeerPicker:采用一致性哈希把所有实例映射到哈希环上,负载均衡
- Peer:调用其它实例,底层通过 grpc 封装
文章目录
- register - 注册中心
- 代码解析
- 1. 配置 (`Config` 和 `DefaultConfig`)
- 2. 核心注册函数 (`Register`)
- 3. 辅助函数 (`getLocalIP`)
- 总结
- PeerPicker - 一致性哈希选择实例
- Map - 一致性哈希
- 核心概念解析
- 代码分段解析
- 1. `Map` 结构体
- 2. `New` 构造函数和 `Option` 模式
- 3. `Add` 和 `Remove` (添加/移除节点)
- 4. `Get(key string)` (核心查找逻辑)
- 5. 动态负载均衡机制
- 总结
- PeerPicker
- 总体目标
- 代码分段解析
- 1. 接口 (`PeerPicker`, `Peer`)
- 2. `ClientPicker` 结构体
- 3. 创建与初始化 (`NewClientPicker`)
- 4. 服务发现:动态核心
- 5. 核心逻辑: `PickPeer(key string)`
- 总结
- group - 缓存
- ByteView - 存储数据的格式
- store - 缓存接口
- lru - 最近最少使用算法
- Cache - 对 store 的封装
- group
- 核心目标与设计理念
- 代码分段解析
- 1. `Group` 结构体:缓存组的核心
- 2. `Get` 方法:核心读取路径 (Read Path)
- 3. `load` 和 `loadData` 方法:数据加载与防惊群
- 4. `Set` 和 `Delete` 方法:写入与删除路径 (Write Path)
- 总结
- server - 节点
- 总体目标
- 代码分段解析
- 1. `Server` 结构体:节点的核心
- 2. 配置选项 (`ServerOptions` 和函数式选项模式)
- 3. `NewServer` 方法:服务器的创建与初始化
- 4. `Start` 和 `Stop` 方法:生命周期管理
- 5. RPC 处理方法 (`Get`, `Set`, `Delete`)
- 总结
register - 注册中心
package registyimport ("fmt""log/slog""net""time""context"clientv3 "go.etcd.io/etcd/client/v3"
)// Config 定义etcd客户端配置
type Config struct {Endpoints []string // 集群地址DialTimeout time.Duration // 连接超时时间
}// DefaultConfig 提供默认配置
var DefaultConfig = &Config{Endpoints: []string{"localhost:2379"},DialTimeout: 5 * time.Second,
}// Register 注册服务到 etcd
func Register(svcName, addr string, stopCh <-chan error) error {cli, err := clientv3.New(clientv3.Config{Endpoints: DefaultConfig.Endpoints,DialTimeout: DefaultConfig.DialTimeout,})if err != nil {return fmt.Errorf("register service %s error: %v", svcName, err)}ip, err := getLocalIP()if err != nil {return fmt.Errorf("failed to get local IP: %v", err)}if addr[0] == ':' {addr = fmt.Sprintf("%s:%d", ip, addr)}grant, err := cli.Grant(context.Background(), 10)if err != nil {errC := cli.Close()if errC != nil {return fmt.Errorf("cli close error: %v", errC)}return fmt.Errorf("failed to create lease: %v", err)}// 注册服务,使用完整的 key 路径key := fmt.Sprintf("/services/%s/%s", svcName, addr)_, err = cli.Put(context.Background(), key, addr, clientv3.WithLease(grant.ID))if err != nil {errC := cli.Close()if errC != nil {return fmt.Errorf("cli close error: %v", errC)}return fmt.Errorf("failed to put key-value to etcd: %v", err)}keepAliveCh, err := cli.KeepAlive(context.Background(), grant.ID)if err != nil {errC := cli.Close()if errC != nil {return fmt.Errorf("cli close error: %v", errC)}return fmt.Errorf("failed to keep lease alive: %v", err)}go func() {defer func(cli *clientv3.Client) {err := cli.Close()if err != nil {slog.Warn("close etcd client err")}}(cli)for {select {case <-stopCh:// 服务注销,撤销租约ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)cli.Revoke(ctx, grant.ID)cancel()returncase resp, ok := <-keepAliveCh:if !ok {slog.Info("keep alive channel closed")return}slog.Debug("keep alive response", "resp", resp)}}}()slog.Info("registy success", "service", svcName, "addr", addr)return nil
}func getLocalIP() (string, error) {addrs, err := net.InterfaceAddrs()if err != nil {return "", err}for _, addr := range addrs {if ipNet, ok := addr.(*net.IPNet); ok && !ipNet.IP.IsLoopback() {if ipNet.IP.To4() != nil {return ipNet.IP.String(), nil}}}return "", fmt.Errorf("no valid local IP found")
}代码解析
1. 配置 (Config 和 DefaultConfig)
// Config 定义etcd客户端配置
type Config struct {Endpoints []string // 集群地址DialTimeout time.Duration // 连接超时时间
}// DefaultConfig 提供默认配置
var DefaultConfig = &Config{Endpoints: []string{"localhost:2379"},DialTimeout: 5 * time.Second,
}
Config结构体: 定义了连接 etcd 所需的配置,包括 etcd 服务器的地址列表 (Endpoints) 和连接超时时间 (DialTimeout)。DefaultConfig变量: 提供了一个默认配置,方便快速使用。默认连接本地的 etcd (localhost:2379),超时时间为 5 秒。
2. 核心注册函数 (Register)
这是实现服务注册最关键的函数。
func Register(svcName, addr string, stopCh <-chan error) error {
- 函数签名: 接收三个参数:
svcName: 服务的名称,例如 “user-service” 或 “product-api”。addr: 服务的网络地址,例如 “192.168.1.10:8080” 或仅仅是一个端口 “:8080”。stopCh: 一个只读的 channel,用于接收停止信号。当服务准备关闭时,会向这个 channel 发送消息,以便代码执行服务注销的逻辑。
函数内部执行流程:
-
连接 etcd:
cli, err := clientv3.New(...)使用配置创建一个 etcd 客户端实例 (
cli)。 -
获取并处理地址:
ip, err := getLocalIP() // ... if addr[0] == ':' {addr = fmt.Sprintf("%s%s", ip, addr) }如果传入的地址
addr是以:开头的(如:8080),代码会调用getLocalIP()函数获取本机的一个有效 IP 地址,并将其与端口拼接成一个完整的地址(如192.168.1.5:8080)。这样做是为了确保注册到 etcd 的地址是其他服务可以访问的。 -
创建租约 (Lease):
grant, err := cli.Grant(context.Background(), 10)这是服务注册中非常关键的一步。它向 etcd 请求一个租约,并设置了一个 10 秒的 TTL(Time-To-Live,存活时间)。
- 租约是什么? 租约就像一个有生命周期的“许可证”。所有与这个许可证关联的数据(Key-Value),都会在这个许可证过期后被 etcd 自动删除。
- 为什么用租约? 这是为了处理服务异常崩溃的情况。如果服务挂了,它就无法再为租约“续期”,租约会在 10 秒后过期,etcd 就会自动清理掉这个服务的信息,实现了服务故障的自动摘除。
-
注册服务 (Put Key-Value):
key := fmt.Sprintf("/services/%s/%s", svcName, addr) _, err = cli.Put(context.Background(), key, addr, clientv3.WithLease(grant.ID))- 它将服务信息作为一个 Key-Value 键值对写入 etcd。
- Key:
/services/服务名/服务地址,例如/services/user-service/192.168.1.5:8080。这种层级结构便于按服务名进行查询。 - Value: 服务地址
addr。 clientv3.WithLease(grant.ID): 最重要的一步,将这个键值对与刚刚创建的租约绑定。
-
保持租约存活 (KeepAlive):
keepAliveCh, err := cli.KeepAlive(context.Background(), grant.ID)为了不让租约在 10 秒后过期,客户端必须定期向 etcd 发送“心跳”来为租约续期。
cli.KeepAlive会自动处理这个心跳过程。它返回一个 channelkeepAliveCh,用于接收续约的响应。 -
启动后台 Goroutine 处理心跳和注销:
go func() {// ...for {select {case <-stopCh:// 服务注销...cli.Revoke(ctx, grant.ID)returncase resp, ok := <-keepAliveCh:// 处理心跳响应...}} }()这里启动了一个新的 goroutine 在后台运行,它同时监听两个 channel:
case <-stopCh: 如果从stopCh接收到信号,说明服务要正常关闭。此时会调用cli.Revoke()主动撤销租约,让 etcd 立即删除该服务的 Key,完成服务注销。case resp, ok := <-keepAliveCh: 不断地从心跳 channel 中读取响应。只要能成功读取,就说明心跳正常,租约被成功续期。如果这个 channel 被关闭 (ok变为false),通常意味着与 etcd 的连接断开,goroutine 也会退出。
3. 辅助函数 (getLocalIP)
func getLocalIP() (string, error) {// ...
}
这个函数的作用是遍历当前机器的所有网络接口,找到一个非环回(non-loopback,即不是 127.0.0.1)的 IPv4 地址并返回。这是为了得到一个在局域网内可以被其他服务访问到的 IP 地址。
总结
这个 registy 包提供了一个健壮的服务注册流程:
- 启动时:服务调用
Register函数,将自己的服务名和地址注册到 etcd,并与一个租约绑定。 - 运行时:一个后台 goroutine 会持续向 etcd 发送心跳,为租约续期,确保服务信息不过期。
- 正常关闭时:服务通过
stopCh发送信号,代码会主动撤销租约,服务信息被立即从 etcd 中删除。 - 异常崩溃时:服务无法再发送心跳,租约会在 TTL(10秒)后自动过期,etcd 会自动删除服务信息。
这个机制完美地结合了主动注销和被动故障检测,是基于 etcd 实现服务发现(Service Discovery)的标准模式。
PeerPicker - 一致性哈希选择实例
Map - 一致性哈希
package consistenthashimport ("errors""fmt""log/slog""math""sort""sync""sync/atomic""time"
)// Map 一致性哈希实现
type Map struct {mu sync.RWMutex// 配置信息config *Config// 哈希环keys []int// 哈希环到节点的映射hashMap map[int]string// 节点到虚拟节点数量的映射nodeReplicas map[string]int// 节点负载统计nodeCounts map[string]int64// 总请求数totalRequests int64
}// Option 配置选项
type Option func(*Map)// New 创建一致性哈希实例
func New(opts ...Option) *Map {m := &Map{config: DefaultConfig,hashMap: make(map[int]string),nodeReplicas: make(map[string]int),nodeCounts: make(map[string]int64),}for _, opt := range opts {// 函数切片opt(m)}m.startBalancer() // 启动负载均衡器return m
}// WithConfig 设置配置
func WithConfig(config *Config) Option {return func(m *Map) {m.config = config}
}// Add 添加节点
func (m *Map) Add(nodes ...string) error {if len(nodes) == 0 {return errors.New("nodes is empty")}m.mu.Lock()defer m.mu.Unlock()slog.Debug("正在添加节点 (Adding nodes)...", "nodes", nodes)for _, node := range nodes {if node == "" {continue}// 为节点添加虚拟节点m.addNode(node, m.config.DefaultReplicas)}// 重新排序sort.Ints(m.keys)slog.Info("节点添加完成,重新排序哈希环 (Nodes added, resorting hash ring)", "total_keys", len(m.keys))return nil
}// Remove 移除节点
func (m *Map) Remove(node string) error {if node == "" {return errors.New("invalid node")}m.mu.Lock()defer m.mu.Unlock()replicas := m.nodeReplicas[node]if replicas == 0 {slog.Warn("尝试移除不存在的节点 (Attempted to remove non-existent node)", "node", node)return fmt.Errorf("no replicas for node %s", node)}slog.Debug("正在移除节点 (Removing node)...", "node", node, "replicas", replicas)for i := 0; i < replicas; i++ {hash := int(m.config.HashFunc([]byte(fmt.Sprintf("%s-%d", node, i))))delete(m.hashMap, hash)for j := 0; j < len(m.keys); j++ {if m.keys[j] == hash {m.keys = append(m.keys[:j], m.keys[j+1:]...)break}}}delete(m.nodeReplicas, node)delete(m.nodeCounts, node)slog.Info("节点移除完成 (Node removed)", "node", node, "total_keys", len(m.keys))return nil
}// Get 获取节点
func (m *Map) Get(key string) string {if key == "" {return ""}m.mu.RLock()defer m.mu.RUnlock()if len(m.keys) == 0 {return ""}hash := int(m.config.HashFunc([]byte(key)))idx := sort.Search(len(m.keys), func(i int) bool {return m.keys[i] >= hash})// 处理边界情况if idx == len(m.keys) {idx = 0}node := m.hashMap[m.keys[idx]]// 注意: Get 是高频调用,默认不在该函数中添加日志以避免性能影响// 但下面的原子操作是线程安全的count := m.nodeCounts[node]m.nodeCounts[node] = count + 1atomic.AddInt64(&m.totalRequests, 1)return node
}// addNode 添加节点的虚拟节点
func (m *Map) addNode(node string, replicas int) {for i := 0; i < replicas; i++ {hash := int(m.config.HashFunc([]byte(fmt.Sprintf("%s-%d", node, i))))m.keys = append(m.keys, hash)m.hashMap[hash] = node}m.nodeReplicas[node] = replicas
}// checkAndRebalance 检查并重新平衡虚拟节点
func (m *Map) checkAndRebalance() {totalReqs := atomic.LoadInt64(&m.totalRequests)slog.Debug("检查负载均衡 (Checking for rebalance)...", "total_requests", totalReqs)if totalReqs < 1000 {return // 样本太少,不进行调整}avgLoad := float64(totalReqs) / float64(len(m.nodeReplicas))var maxDiff float64for node, count := range m.nodeCounts {diff := math.Abs(float64(count) - avgLoad)slog.Debug("节点负载详情 (Node load detail)", "node", node, "count", count, "avg_load", avgLoad, "diff", diff)if diff > maxDiff {maxDiff = diff}}// 如果负载不均衡度超过阈值,调整虚拟节点if maxDiff/avgLoad > m.config.LoadBalanceThreshold {slog.Info("检测到负载不均衡,触发重新平衡 (Load imbalance detected, triggering rebalance)","threshold", m.config.LoadBalanceThreshold,"max_diff_ratio", maxDiff/avgLoad)m.rebalanceNodes()}
}// rebalanceNodes 重新平衡节点
func (m *Map) rebalanceNodes() {m.mu.Lock()defer m.mu.Unlock()slog.Info("开始重新平衡节点 (Starting node rebalance)")avgLoad := float64(atomic.LoadInt64(&m.totalRequests)) / float64(len(m.nodeReplicas))for node, count := range m.nodeCounts {currentReplicas := m.nodeReplicas[node]loadRatio := float64(count) / avgLoadvar newReplicas intif loadRatio > 1 {// 负载过高,减少虚拟节点newReplicas = int(float64(currentReplicas) / loadRatio)} else {// 负载过低,增加虚拟节点newReplicas = int(float64(currentReplicas) * (2 - loadRatio))}// 确保在限制范围内if newReplicas < m.config.MinReplicas {newReplicas = m.config.MinReplicas}if newReplicas > m.config.MaxReplicas {newReplicas = m.config.MaxReplicas}if newReplicas != currentReplicas {slog.Info("调整节点的虚拟副本数 (Adjusting node replicas)","node", node,"load_ratio", fmt.Sprintf("%.2f", loadRatio),"old_replicas", currentReplicas,"new_replicas", newReplicas)// 重新添加节点的虚拟节点// 注意:这里需要先移除旧的虚拟节点,再添加新的replicas := m.nodeReplicas[node]for i := 0; i < replicas; i++ {hash := int(m.config.HashFunc([]byte(fmt.Sprintf("%s-%d", node, i))))delete(m.hashMap, hash)for j := 0; j < len(m.keys); j++ {if m.keys[j] == hash {m.keys = append(m.keys[:j], m.keys[j+1:]...)break}}}m.addNode(node, newReplicas)}}// 重置计数器for node := range m.nodeCounts {m.nodeCounts[node] = 0}atomic.StoreInt64(&m.totalRequests, 0)// 重新排序sort.Ints(m.keys)slog.Info("节点重新平衡完成,重置计数器并排序哈希环 (Node rebalance finished, counters reset and ring sorted)")
}// GetStats 获取负载统计信息
func (m *Map) GetStats() map[string]float64 {m.mu.RLock()defer m.mu.RUnlock()stats := make(map[string]float64)total := atomic.LoadInt64(&m.totalRequests)if total == 0 {return stats}for node, count := range m.nodeCounts {stats[node] = float64(count) / float64(total)}return stats
}// 将checkAndRebalance移到单独的goroutine中
func (m *Map) startBalancer() {go func() {slog.Info("后台负载均衡器已启动 (Background load balancer started)")ticker := time.NewTicker(time.Second)defer ticker.Stop()for range ticker.C {m.checkAndRebalance()}}()
}这段代码的核心目标是解决分布式系统中如何将请求或数据均匀地分配到一组动态变化的节点(服务器)上的问题。
它主要实现了以下功能:
- 一致性哈希:当添加或删除节点时,只会影响到少量的数据映射,最大程度地减少数据迁移。
- 虚拟节点:通过为每个物理节点创建多个虚拟节点,使得数据在哈希环上分布得更加均匀。
- 动态负载均衡:它会持续监控每个节点的请求负载,如果发现负载不均,会自动增加低负载节点的虚拟节点数量、减少高负载节点的虚拟节点数量,从而实现负载的自动平衡。
核心概念解析
在深入代码之前,我们先理解几个关键概念:
- 哈希环 (Hash Ring):想象一个 0 到 232−12^{32}-1232−1 的闭环(像一个钟面)。代码中的
keys数组就是一个排好序的哈希环,存储了所有虚拟节点的哈希值。 - 虚拟节点 (Virtual Nodes / Replicas):为了避免节点在环上分布不均导致的数据倾斜,我们不直接将物理节点(如服务器 IP)放到环上,而是为每个物理节点创建多个“分身”,即虚拟节点。例如,节点
A可以有A-1,A-2, …A-10等多个虚拟节点,每个虚拟节点都有自己的哈希值。代码中的nodeReplicas记录了每个物理节点有多少个虚拟节点。 - 请求路由 (Request Routing):当一个请求的 key (例如,一个用户 ID) 到来时,计算它的哈希值,然后在环上顺时针寻找离它最近的一个虚拟节点,这个虚拟节点所属的物理节点就是处理该请求的节点。
代码分段解析
1. Map 结构体
这是整个一致性哈希算法的核心数据结构,存储了所有状态。
type Map struct {mu sync.RWMutex // 读写锁,保证并发安全config *Config // 配置信息 (如哈希函数, 虚拟节点数)keys []int // 哈希环,一个有序的整数切片,存储所有虚拟节点的哈希值hashMap map[int]string // 从虚拟节点哈希值到物理节点名称的映射nodeReplicas map[string]int // 物理节点到其虚拟节点数量的映射nodeCounts map[string]int64 // 统计每个物理节点处理的请求数totalRequests int64 // 统计总请求数
}
mu: 因为节点可能会被动态添加或删除,所以需要用读写锁来保护内部数据在并发访问时的一致性。
2. New 构造函数和 Option 模式
func New(opts ...Option) *Map {// ... 初始化m.startBalancer() // 启动后台负载均衡器return m
}
- 使用
Option函数式选项模式来创建Map实例,这是一种灵活的配置方式。 - 最重要的一点是,在创建实例时,它调用
m.startBalancer()启动了一个后台 goroutine,这个 goroutine 会周期性地检查并执行负载均衡。
3. Add 和 Remove (添加/移除节点)
-
Add(nodes ...string):- 加写锁 (
m.mu.Lock()) 以保证操作的原子性。 - 遍历要添加的节点列表。
- 对每个节点,调用
addNode()方法,根据配置中的DefaultReplicas(默认虚拟节点数)创建多个虚拟节点。 - 每个虚拟节点通过
fmt.Sprintf("%s-%d", node, i)生成唯一的字符串,然后计算哈希值。 - 将哈希值存入
m.keys,并将哈希值 -> 节点名的映射存入m.hashMap。 - 所有节点添加完毕后,调用
sort.Ints(m.keys)对哈希环进行重新排序,这对于后续的查找至关重要。
- 加写锁 (
-
Remove(node string):- 同样加写锁。
- 根据
m.nodeReplicas找到该节点对应的所有虚拟节点。 - 遍历并删除这些虚拟节点在
m.keys和m.hashMap中的数据。 - 从
m.nodeReplicas和m.nodeCounts中删除该节点。
4. Get(key string) (核心查找逻辑)
这是最高频调用的函数,用于根据一个 key 找到它应该被路由到的节点。
func (m *Map) Get(key string) string {// ...m.mu.RLock() // 加读锁defer m.mu.RUnlock()// ...hash := int(m.config.HashFunc([]byte(key)))// 使用二分查找快速定位idx := sort.Search(len(m.keys), func(i int) bool {return m.keys[i] >= hash})if idx == len(m.keys) {idx = 0 // 如果没找到,说明 key 的哈希值比所有节点都大,回到环的起点}node := m.hashMap[m.keys[idx]] // 获取物理节点// 原子操作,更新负载计数m.nodeCounts[node] = m.nodeCounts[node] + 1atomic.AddInt64(&m.totalRequests, 1)return node
}
- 加读锁:因为只是查询,所以使用读锁,允许多个
Get操作并发执行。 - 计算哈希:计算输入
key的哈希值。 - 二分查找 (
sort.Search):这是性能的关键。它在排好序的m.keys(哈希环) 中,使用二分查找来快速找到第一个大于或等于 key 哈希值的虚拟节点。这等同于在环上顺时针寻找最近的节点。 - 环形处理:如果
idx等于len(m.keys),意味着 key 的哈希值超过了环上所有虚拟节点的哈希值。根据环形结构,它应该被分配给环上的第一个节点(idx = 0)。 - 更新负载:找到节点后,通过原子操作更新该节点的请求计数和总请求计数。这些数据是后续动态负载均衡的基础。
5. 动态负载均衡机制
这是此实现的精髓所在。
-
startBalancer():- 在
New()中被调用,启动一个后台 goroutine。 - 它使用一个
time.Ticker(默认每秒触发一次),周期性地调用checkAndRebalance()。
- 在
-
checkAndRebalance():- 检查时机:首先检查总请求数,如果样本太少(如小于 1000),则不进行调整,避免因数据不足导致误判。
- 计算负载:计算出平均每个节点的负载 (
avgLoad)。 - 判断失衡:遍历所有节点,计算每个节点的负载与平均负载的差异。如果
最大差异 / 平均负载超过了配置的阈值 (LoadBalanceThreshold),则认为负载不均衡,触发rebalanceNodes()。
-
rebalanceNodes():- 加写锁:因为要大规模修改哈希环。
- 调整策略:
- 对于负载过高的节点 (
loadRatio > 1),按比例减少其虚拟节点数。 - 对于负载过低的节点 (
loadRatio < 1),按比例增加其虚拟节点数。 - 新的虚拟节点数会有一个上下限(
MinReplicas,MaxReplicas)以防止过度调整。
- 对于负载过高的节点 (
- 执行调整:先移除该节点所有旧的虚拟节点,然后根据计算出的新数量,重新添加虚拟节点。
- 重置和排序:调整完所有节点后,重置负载计数器 (
nodeCounts,totalRequests),并对哈希环 (m.keys) 重新排序。
总结
这个 consistenthash 包实现了一个功能完备且智能的一致性哈希算法。它的优点非常突出:
- 高性能:
Get操作使用二分查找,时间复杂度为 O(logN)O(\log N)O(logN),其中 N 是虚拟节点的总数。 - 并发安全:使用读写锁和原子操作,可以在高并发环境下安全使用。
- 高可用:当节点增删时,影响范围最小化,符合一致性哈希的核心思想。
- 自适应负载均衡:最亮眼的功能。它能自动感知节点的负载压力,并通过动态调整虚拟节点权重(数量)来“削峰填谷”,使得整个系统负载更加平滑,大大提升了系统的稳定性和资源利用率。
PeerPicker
package mainimport ("fmt""go-cache/consistenthash""go-cache/registy""log""log/slog""strings""sync""time""context""github.com/sirupsen/logrus"clientv3 "go.etcd.io/etcd/client/v3"
)const defaultSvcName = "kama-cache"// PeerPicker 定义了peer选择器的接口
type PeerPicker interface {PickPeer(key string) (peer Peer, ok bool, self bool)Close() error
}// Peer 定义了缓存节点的接口
type Peer interface {Get(group string, key string) ([]byte, error)Set(ctx context.Context, group string, key string, value []byte) errorDelete(group string, key string) (bool, error)Close() error
}// ClientPicker 实现了PeerPicker接口
type ClientPicker struct {selfAddr stringsvcName stringmu sync.RWMutexconsHash *consistenthash.Mapclients map[string]*ClientetcdCli *clientv3.Clientctx context.Contextcancel context.CancelFunc
}// PickerOption 定义配置选项
type PickerOption func(*ClientPicker)// WithServiceName 设置服务名称
func WithServiceName(name string) PickerOption {return func(p *ClientPicker) {p.svcName = name}
}// PrintPeers 打印当前已发现的节点(仅用于调试)
func (p *ClientPicker) PrintPeers() {p.mu.RLock()defer p.mu.RUnlock()log.Printf("当前已发现的节点:")for addr := range p.clients {log.Printf("- %s", addr)}
}// NewClientPicker 创建新的 ClientPicker 实例
func NewClientPicker(addr string, opts ...PickerOption) (*ClientPicker, error) {ctx, cancel := context.WithCancel(context.Background())picker := &ClientPicker{selfAddr: addr,svcName: defaultSvcName,clients: make(map[string]*Client),consHash: consistenthash.New(),ctx: ctx,cancel: cancel,}for _, opt := range opts {opt(picker)}cli, err := clientv3.New(clientv3.Config{Endpoints: registy.DefaultConfig.Endpoints,DialTimeout: registy.DefaultConfig.DialTimeout,})if err != nil {cancel()return nil, fmt.Errorf("failed to create etcd client: %v", err)}picker.etcdCli = cli// 启动服务发现if err := picker.startServiceDiscovery(); err != nil {cancel()cli.Close()return nil, err}return picker, nil
}// startServiceDiscovery 启动服务发现
func (p *ClientPicker) startServiceDiscovery() error {// 先进行全量更新if err := p.fetchAllServices(); err != nil {return err}// 启动增量更新go p.watchServiceChanges()return nil
}// watchServiceChanges 监听服务实例变化
func (p *ClientPicker) watchServiceChanges() {watcher := clientv3.NewWatcher(p.etcdCli)watchChan := watcher.Watch(p.ctx, "/services/"+p.svcName, clientv3.WithPrefix())for {select {case <-p.ctx.Done():watcher.Close()returncase resp := <-watchChan:p.handleWatchEvents(resp.Events)}}
}// handleWatchEvents 处理监听到的事件
func (p *ClientPicker) handleWatchEvents(events []*clientv3.Event) {p.mu.Lock()defer p.mu.Unlock()for _, event := range events {addr := string(event.Kv.Value)if addr == p.selfAddr {continue}switch event.Type {case clientv3.EventTypePut:if _, exists := p.clients[addr]; !exists {p.set(addr)logrus.Infof("New service discovered at %s", addr)}case clientv3.EventTypeDelete:if client, exists := p.clients[addr]; exists {client.Close()p.remove(addr)logrus.Infof("Service removed at %s", addr)}}}
}// fetchAllServices 获取所有服务实例
func (p *ClientPicker) fetchAllServices() error {ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)defer cancel()resp, err := p.etcdCli.Get(ctx, "/services/"+p.svcName, clientv3.WithPrefix())if err != nil {return fmt.Errorf("failed to get all services: %v", err)}p.mu.Lock()defer p.mu.Unlock()for _, kv := range resp.Kvs {addr := string(kv.Value)if addr != "" && addr != p.selfAddr {p.set(addr)slog.Info("Discovered service", "addr", addr)}}return nil
}// set 添加服务实例
func (p *ClientPicker) set(addr string) {if client, err := NewClient(addr, p.svcName, p.etcdCli); err == nil {p.consHash.Add(addr)p.clients[addr] = clientslog.Info("Added service", "addr", addr)} else {slog.Error("Failed to create service", "addr", addr)}
}// remove 移除服务实例
func (p *ClientPicker) remove(addr string) {p.consHash.Remove(addr)delete(p.clients, addr)
}// PickPeer 选择 peer 节点
func (p *ClientPicker) PickPeer(key string) (Peer, bool, bool) {p.mu.RLock()defer p.mu.RUnlock()if addr := p.consHash.Get(key); addr != "" {if client, ok := p.clients[addr]; ok {return client, true, addr == p.selfAddr}}return nil, false, false
}// Close 关闭所有资源
func (p *ClientPicker) Close() error {p.cancel()p.mu.Lock()defer p.mu.Unlock()var errs []errorfor addr, client := range p.clients {if err := client.Close(); err != nil {errs = append(errs, fmt.Errorf("failed to close client %s: %v", addr, err))}}if err := p.etcdCli.Close(); err != nil {errs = append(errs, fmt.Errorf("failed to close etcd client: %v", err))}if len(errs) > 0 {return fmt.Errorf("errors while closing: %v", errs)}return nil
}// parseAddrFromKey 从etcd key中解析地址
func parseAddrFromKey(key, svcName string) string {prefix := fmt.Sprintf("/services/%s/", svcName)if strings.HasPrefix(key, prefix) {return strings.TrimPrefix(key, prefix)}return ""
}
这段 Go 代码实现了一个分布式缓存系统中至关重要的组件:一个动态节点选择器 (dynamic peer picker)。它的主要工作是判断集群中的哪个节点(或称“对等节点”)应该负责处理一个特定的缓存键。
它巧妙地将 etcd 的服务发现机制与一致性哈希图相结合,以一种可扩展且容错的方式实现了这一目标。
总体目标
想象一下,你运行了多个缓存服务器。当一个针对键(比如 "user:123")的请求到达时,接收该请求的服务器如何知道是应该自己处理,还是应该将其转发给另一个服务器呢?
这段代码就解决了这个问题。ClientPicker 会持续监控一个中心的 etcd 注册表,从而知道当前有哪些服务器在线。然后,它使用一个一致性哈希环,将任意给定的键映射到一个特定的服务器。这使得它成为了这个分布式缓存的“交通控制器”或“路由器”。
代码分段解析
1. 接口 (PeerPicker, Peer)
type PeerPicker interface {PickPeer(key string) (peer Peer, ok bool, self bool)// ...
}type Peer interface {Get(group string, key string) ([]byte, error)// ...
}
Peer: 定义了一个远程缓存节点能做什么。它是对另一个服务器连接的抽象,允许你Get(获取)、Set(设置)或Delete(删除)数据。PeerPicker: 定义了主组件需要遵守的契约。其核心方法PickPeer是逻辑的核心:给定一个键,它返回应该与之通信的正确的Peer。
2. ClientPicker 结构体
这是节点管理逻辑的具体实现和中枢神经系统。
type ClientPicker struct {selfAddr string // 它自己的网络地址 (例如, "10.0.0.1:8080")svcName string // 在 etcd 中的服务名 (例如, "kama-cache")mu sync.RWMutex // 读写锁,保护对客户端和哈希图的并发访问consHash *consistenthash.Map // 用于路由的一致性哈希映射clients map[string]*Client // 一个从地址到活动客户端连接的映射etcdCli *clientv3.Client // 用于与 etcd 通信的客户端ctx context.Contextcancel context.CancelFunc // 用于优雅关闭
}
- 它知道自己的地址 (
selfAddr),以避免向自己发起网络请求。 consHash是我们之前看到的一致性哈希实现,它维护着哈希环。clients是一个“电话簿”,记录了到所有其他已知节点的活动连接。
3. 创建与初始化 (NewClientPicker)
当一个 ClientPicker 被创建时:
- 它会初始化自己的状态(地址、空映射等)。
- 它创建一个带有
cancel函数的context,这是管理后台任务生命周期的标准 Go 模式。 - 它连接到
etcd。 - 最重要的是,它调用
startServiceDiscovery()来开始寻找它的对等节点。
4. 服务发现:动态核心
这是代码中最关键的部分。它确保了对等节点列表始终保持最新。它分两个阶段工作:
阶段一:引导启动 (fetchAllServices)
- 当一个节点启动时,它会向
etcd发起一个Get请求,获取前缀为/services/kama-cache/的所有键值对。 - 这会拉取到集群中当前所有已注册节点的快照。
- 它遍历这些节点,并调用
p.set()将每一个节点添加到它的一致性哈希环中,并建立一个客户端连接。
阶段二:持续监听 (watchServiceChanges 和 handleWatchEvents)
- 在初始拉取之后,它会启动一个后台 goroutine 来创建一个
etcd watcher。 - 这个 watcher 会高效地监听
/services/kama-cache/前缀下的任何变动。它不需要持续地轮询etcd。 - 当一个新节点加入集群时,
etcd会发送一个PUT事件。handleWatchEvents捕捉到这个事件,并调用p.set(addr)来添加这个新节点。 - 当一个节点离开集群时(无论是正常关闭还是崩溃导致
etcd的租约过期),etcd会发送一个DELETE事件。handleWatchEvents捕捉到这个事件,关闭到该节点的连接,并调用p.remove(addr)将其从哈希环和客户端映射中移除。
5. 核心逻辑: PickPeer(key string)
这是缓存系统其他部分会调用的函数,用于为某个键找到正确的节点。
func (p *ClientPicker) PickPeer(key string) (Peer, bool, bool) {p.mu.RLock() // 使用读锁以支持高并发defer p.mu.RUnlock()// 1. 向一致性哈希映射询问,获取负责该 key 的节点地址addr := p.consHash.Get(key)// 2. 检查地址是否是自己的地址if addr == p.selfAddr {return nil, true, true // 返回 self=true,表示是自己}// 3. 在客户端映射中查找该地址对应的连接if client, ok := p.clients[addr]; ok {return client, true, false // 返回该节点、成功状态和 self=false}return nil, false, false // 没有找到节点
}
这个逻辑简单而强大:
- 它询问
consistenthash.Map,哪个节点的地址 (addr) 负责给定的key。 - 它检查返回的
addr是否是它自己的地址 (selfAddr)。如果是,它返回self=true,告诉调用者应该在本地处理请求,而不是发起网络调用。 - 如果地址属于另一个节点,它就在
clients映射中查找活动的客户端连接并返回它。
总结
这段代码扮演了一个分布式系统的智能粘合剂的角色。它创建了一个 ClientPicker,该选择器能够:
- 连接到一个
etcd集群。 - 通过在启动时拉取列表,然后“监听”实时变化(节点的加入或离开)来发现所有其他的对等节点。
- 维护一个包含所有活动节点的、最新的一致性哈希环。
- 提供一个简单的
PickPeer方法,该方法可以为任意给定的键即时确定正确的节点,从而在整个集群中实现高效和正确的请求路由。
group - 缓存
ByteView - 存储数据的格式
type ByteView struct {b []byte
}func (b ByteView) Len() int {return len(b.b)
}func (b ByteView) ByteSLice() []byte {return cloneBytes(b.b)
}func (b ByteView) String() string {return string(b.b)
}func (b ByteView) ToString() string {return string(b.b)
}func cloneBytes(b []byte) []byte {c := make([]byte, len(b))copy(c, b)return c
}
store - 缓存接口
package storeimport "time"type Value interface {// 返回数据大小Len() intToString() string
}type Store interface {Get(key string) (Value, bool)Set(key string, value Value) errorSetWithExpiration(key string, value Value, expiration time.Duration) errorDelete(key string) boolClear()Len() intClose()
}// CacheType 缓存类型
type CacheType stringconst (LRU CacheType = "lru"LRU2 CacheType = "lru2"
)// Options 通用缓存配置选项
type Options struct {MaxBytes int64 // 最大的缓存字节数(用于 lru)BucketCount uint16 // 缓存的桶数量(用于 lru-2)CapPerBucket uint16 // 每个桶的容量(用于 lru-2)Level2Cap uint16 // lru-2 中二级缓存的容量(用于 lru-2)CleanupInterval time.DurationOnEvicted func(key string, value Value)
}func NewOptions() Options {return Options{MaxBytes: 8192,BucketCount: 16,CapPerBucket: 512,Level2Cap: 256,CleanupInterval: time.Minute,OnEvicted: nil,}
}// NewStore 创建缓存存储实例
func NewStore(cacheType CacheType, opts Options) Store {switch cacheType {case LRU2:return newLRU2Cache(opts)case LRU:return newLRUCache(opts)default:return newLRUCache(opts)}
}
lru - 最近最少使用算法
package storeimport ("container/list""log/slog""sync""time"
)// lruCache 是基于标准库 list 的 LRU 缓存实现
type lruCache struct {mu sync.RWMutexlist *list.List // 双向链表,用于维护 LRU 顺序items map[string]*list.Element // 键到链表节点的映射expires map[string]time.Time // 过期时间映射maxBytes int64 // 最大允许字节数usedBytes int64 // 当前使用的字节数onEvicted func(key string, value Value)cleanupInterval time.DurationcleanupTicker *time.TickercloseCh chan struct{} // 用于优雅关闭清理协程
}// lruEntry 表示缓存中的一个条目
type lruEntry struct {key stringvalue Value
}func newLRUCache(opts Options) *lruCache {// 设置默认清理间隔cleanupInterval := opts.CleanupIntervalif cleanupInterval <= 0 {cleanupInterval = time.Minute}c := &lruCache{list: list.New(),items: make(map[string]*list.Element),expires: make(map[string]time.Time),maxBytes: opts.MaxBytes,onEvicted: opts.OnEvicted,cleanupInterval: cleanupInterval,closeCh: make(chan struct{}),}// 启动定期清理协程c.cleanupTicker = time.NewTicker(c.cleanupInterval)go c.cleanupLoop()return c
}// Get 获取缓存项,如果存在且未过期则返回
func (c *lruCache) Get(key string) (Value, bool) {c.mu.RLock()elem, ok := c.items[key]if !ok {c.mu.RUnlock()slog.Info("LRU 没有查找到数据", "key", key)return nil, false}if expTime, hasExp := c.expires[key]; hasExp && time.Now().After(expTime) {c.mu.RUnlock()// 异步删除过期项,避免在读锁内操作go c.Delete(key)slog.Info(key + " expired.")return nil, false}// 获取值并释放读锁entry := elem.Value.(*lruEntry)value := entry.valuec.mu.RUnlock()c.mu.Lock()if _, ok := c.items[key]; ok {c.list.MoveToFront(elem)c.mu.Unlock()}slog.Info("查询到数据", "key", key, "value", value.ToString())return value, true
}// Set 添加或更新缓存项
func (c *lruCache) Set(key string, value Value) error {return c.SetWithExpiration(key, value, 0)
}// SetWithExpiration 添加或更新缓存项,并设置过期时间
func (c *lruCache) SetWithExpiration(key string, value Value, expiration time.Duration) error {if value == nil {c.Delete(key)return nil}c.mu.Lock()defer c.mu.Unlock()// 计算过期时间var expTime time.Timeif expiration > 0 {expTime = time.Now().Add(expiration)c.expires[key] = expTime} else {delete(c.expires, key)}if elem, ok := c.items[key]; ok {oldElem := elem.Value.(*lruEntry)c.usedBytes += int64(value.Len() - oldElem.value.Len())oldElem.value = valuec.list.MoveToFront(elem)return nil}// 添加新项entry := &lruEntry{key: key, value: value}elem := c.list.PushBack(entry)c.items[key] = elemc.usedBytes += int64(len(key) + value.Len())// 检查是否需要淘汰旧项c.evict()return nil
}// Delete 从缓存中删除指定键的项
func (c *lruCache) Delete(key string) bool {c.mu.Lock()defer c.mu.Unlock()if elem, ok := c.items[key]; ok {c.removeElement(elem)slog.Info("删除数据", "key", key, "value", elem.Value.(*lruEntry).key)return true}return false
}// Clear 清空缓存
func (c *lruCache) Clear() {c.mu.Lock()defer c.mu.Unlock()// 如果设置了回调函数,遍历所有项调用回调if c.onEvicted != nil {for _, elem := range c.items {entry := elem.Value.(*lruEntry)c.onEvicted(entry.key, entry.value)}}c.list.Init()c.items = make(map[string]*list.Element)c.expires = make(map[string]time.Time)c.usedBytes = 0
}// Len 返回缓存中的项数
func (c *lruCache) Len() int {c.mu.RLock()defer c.mu.RUnlock()return c.list.Len()
}// removeElement 从缓存中删除元素,调用此方法前必须持有锁
func (c *lruCache) removeElement(elem *list.Element) {entry := elem.Value.(*lruEntry)c.list.Remove(elem)delete(c.items, entry.key)delete(c.expires, entry.key)c.usedBytes += int64(len(entry.key) + entry.value.Len())if c.onEvicted != nil {c.onEvicted(entry.key, entry.value)}
}// evict 清理过期和超出内存限制的缓存,调用此方法前必须持有锁
func (c *lruCache) evict() {// 先清理过期项now := time.Now()for key, expTime := range c.expires {if now.After(expTime) {if elem, ok := c.items[key]; ok {c.removeElement(elem)}}}for c.maxBytes > 0 && c.usedBytes > c.maxBytes && c.Len() > 0 {elem := c.list.Front()if elem != nil {c.removeElement(elem)}}
}// cleanupLoop 定期清理过期缓存的协程
func (c *lruCache) cleanupLoop() {for {select {case <-c.cleanupTicker.C:c.mu.Lock()c.evict()c.mu.Unlock()case <-c.closeCh:return}}
}// Close 关闭缓存,停止清理协程
func (c *lruCache) Close() {if c.cleanupTicker != nil {c.cleanupTicker.Stop()close(c.closeCh)}
}// GetWithExpiration 获取缓存项及其剩余过期时间
func (c *lruCache) GetWithExpiration(key string) (Value, time.Duration, bool) {c.mu.RLock()defer c.mu.RUnlock()elem, ok := c.items[key]if !ok {return nil, 0, false}now := time.Now()if expTime, hasExp := c.expires[key]; hasExp {if now.After(expTime) {// 已过期return nil, 0, false}ttl := expTime.Sub(now)c.list.MoveToBack(elem)return elem.Value.(*lruEntry).value, ttl, true}// 无过期时间c.list.MoveToBack(elem)return elem.Value.(*lruEntry).value, 0, true
}// GetExpiration 获取键的过期时间
func (c *lruCache) GetExpiration(key string) (time.Time, bool) {c.mu.RLock()defer c.mu.RUnlock()expTime, ok := c.expires[key]return expTime, ok
}// UpdateExpiration 更新过期时间
func (c *lruCache) UpdateExpiration(key string, expiration time.Duration) bool {c.mu.Lock()defer c.mu.Unlock()if _, ok := c.items[key]; !ok {return false}if expiration > 0 {c.expires[key] = time.Now().Add(expiration)} else {delete(c.items, key)}return true
}// UsedBytes 返回当前使用的字节数
func (c *lruCache) UsedBytes() int64 {c.mu.RLock()defer c.mu.RUnlock()return c.usedBytes
}// MaxBytes 返回最大允许字节数
func (c *lruCache) MaxBytes() int64 {c.mu.RLock()defer c.mu.RUnlock()return c.maxBytes
}// SetMaxBytes 设置最大允许字节数并触发淘汰
func (c *lruCache) SetMaxBytes(maxBytes int64) {c.mu.Lock()defer c.mu.Unlock()c.maxBytes = maxBytesif maxBytes > 0 {c.evict()}
}
Cache - 对 store 的封装
package mainimport ("go-cache/store""log/slog""sync""sync/atomic""time""context"
)// Cache 是对底层缓存存储的封装
type Cache struct {mu sync.RWMutexstore store.Store // 底层存储实现opts CacheOptions // 缓存配置选项hits int64 // 缓存命中次数misses int64 // 缓存未命中次数initialized int32 // 原子变量,标记缓存是否已初始化closed int32 // 原子变量,标记缓存是否已关闭
}// CacheOptions 缓存配置选项
type CacheOptions struct {CacheType store.CacheType // 缓存类型: LRU, LRU2 等MaxBytes int64 // 最大内存使用量BucketCount uint16 // 缓存桶数量 (用于 LRU2)CapPerBucket uint16 // 每个缓存桶的容量 (用于 LRU2)Level2Cap uint16 // 二级缓存桶的容量 (用于 LRU2)CleanupTime time.Duration // 清理间隔OnEvicted func(key string, value store.Value) // 驱逐回调
}// DefaultCacheOptions 返回默认的缓存配置
func DefaultCacheOptions() CacheOptions {return CacheOptions{CacheType: store.LRU,MaxBytes: 8 * 1024 * 1024, // 8MBBucketCount: 16,CapPerBucket: 512,Level2Cap: 256,CleanupTime: time.Minute,OnEvicted: nil,}
}// NewCache 创建一个新的缓存实例
func NewCache(opts CacheOptions) *Cache {return &Cache{opts: opts,}
}// ensureInitialized 确保缓存已初始化
func (c *Cache) ensureInitialized() {// 快速检查缓存是否已初始化,避免不必要的锁争用if atomic.LoadInt32(&c.initialized) == 1 {return}// 双重检查锁定模式c.mu.Lock()defer c.mu.Unlock()if c.initialized == 0 {// 创建存储选项storeOpts := store.Options{MaxBytes: c.opts.MaxBytes,BucketCount: c.opts.BucketCount,CapPerBucket: c.opts.CapPerBucket,Level2Cap: c.opts.Level2Cap,CleanupInterval: c.opts.CleanupTime,OnEvicted: c.opts.OnEvicted,}// 创建存储实例c.store = store.NewStore(c.opts.CacheType, storeOpts)// 标记为已初始化atomic.StoreInt32(&c.initialized, 1)slog.Info("Cache initialized with type",slog.Any("type", c.opts.CacheType),slog.Int64("max_bytes", c.opts.MaxBytes),)}}// Add 向缓存中添加一个 key-value 对
func (c *Cache) Add(key string, value ByteView) {if atomic.LoadInt32(&c.closed) == 1 {slog.Info("Cache is closed")return}c.ensureInitialized()if err := c.store.Set(key, value); err != nil {slog.Error("Error adding to cache", "key", key, "value", value, "error", err)}
}// Get 从缓存中获取值
func (c *Cache) Get(ctx context.Context, key string) (value ByteView, ok bool) {if atomic.LoadInt32(&c.closed) == 1 {return ByteView{}, false}// 如果缓存未初始化,直接返回未命中if atomic.LoadInt32(&c.initialized) == 0 {atomic.AddInt64(&c.misses, 1)return ByteView{}, false}c.mu.RLock()defer c.mu.RUnlock()val, found := c.store.Get(key)if !found {atomic.AddInt64(&c.misses, 1)return ByteView{}, false}// 更新命中计数atomic.AddInt64(&c.hits, 1)// 转换并返回if bv, ok := val.(ByteView); ok {return bv, true}slog.Warn("Type assertion failed", "type", val, "value", val)atomic.AddInt64(&c.misses, 1)return ByteView{}, false
}// AddWithExpiration 向缓存中添加一个带过期时间的 key-value 对
func (c *Cache) AddWithExpiration(key string, value ByteView, expirationTime time.Time) {if atomic.LoadInt32(&c.closed) == 1 {slog.Warn("Cache is closed")return}c.ensureInitialized()// 计算过期时间expiration := time.Until(expirationTime)if expiration <= 0 {slog.Info("Cache expiration time is too small")return}// 设置到底层存储if err := c.store.SetWithExpiration(key, value, expiration); err != nil {slog.Error("Error adding to cache", "key", key, "value", value, "error", err)}
}// Delete 从缓存中删除一个 key
func (c *Cache) Delete(key string) bool {if atomic.LoadInt32(&c.closed) == 1 || atomic.LoadInt32(&c.initialized) == 0 {return false}c.mu.RLock()defer c.mu.RUnlock()return c.store.Delete(key)
}// Clear 清空缓存
func (c *Cache) Clear() {if atomic.LoadInt32(&c.closed) == 1 || atomic.LoadInt32(&c.initialized) == 0 {return}c.mu.Lock()defer c.mu.Unlock()c.store.Clear()// 重置统计信息atomic.StoreInt64(&c.hits, 0)atomic.StoreInt64(&c.misses, 0)
}// Len 返回缓存的当前存储项数量
func (c *Cache) Len() int {if atomic.LoadInt32(&c.closed) == 1 || atomic.LoadInt32(&c.initialized) == 0 {return 0}c.mu.RLock()defer c.mu.RUnlock()return c.store.Len()
}// Close 关闭缓存,释放资源
func (c *Cache) Close() {// 如果已经关闭,直接返回if !atomic.CompareAndSwapInt32(&c.closed, 0, 1) {return}c.mu.Lock()defer c.mu.Unlock()// 关闭底层存储if c.store != nil {if closer, ok := c.store.(interface{ Close() }); ok {closer.Close()}c.store = nil}// 重置缓存状态atomic.StoreInt32(&c.initialized, 0)slog.Debug("Cache closed", "hits", atomic.LoadInt64(&c.hits), "misses", atomic.LoadInt64(&c.misses))
}// Stats 返回缓存统计信息
func (c *Cache) Stats() map[string]interface{} {stats := map[string]interface{}{"initialized": atomic.LoadInt32(&c.initialized) == 1,"closed": atomic.LoadInt32(&c.closed) == 1,"hits": atomic.LoadInt64(&c.hits),"misses": atomic.LoadInt64(&c.misses),}if atomic.LoadInt32(&c.initialized) == 1 {stats["size"] = c.Len()// 计算命中率totalRequests := stats["hits"].(int64) + stats["misses"].(int64)if totalRequests > 0 {stats["hit_rate"] = float64(stats["hits"].(int64)) / float64(totalRequests)} else {stats["hit_rate"] = 0.0}}return stats
}
group
package mainimport ("fmt""go-cache/singleflight""log/slog""sync""sync/atomic""time""context""errors"
)var (groupsMu sync.RWMutexgroups = make(map[string]*Group)
)// ErrKeyRequired 键不能为空错误
var ErrKeyRequired = errors.New("key is required")// ErrValueRequired 值不能为空错误
var ErrValueRequired = errors.New("value is required")// ErrGroupClosed 组已关闭错误
var ErrGroupClosed = errors.New("cache group is closed")// Getter 加载键值的回调函数接口
type Getter interface {Get(ctx context.Context, key string) ([]byte, error)
}// GetterFunc 函数类型实现 Getter 接口
type GetterFunc func(ctx context.Context, key string) ([]byte, error)// Get 实现 Getter 接口
func (f GetterFunc) Get(ctx context.Context, key string) ([]byte, error) {return f(ctx, key)
}// Group 是一个缓存命名空间
type Group struct {name stringgetter GettermainCache *Cachepeers PeerPickerloader *singleflight.Groupexpiration time.Duration // 缓存过期时间,0表示永不过期closed int32 // 原子变量,标记组是否已关闭stats groupStats // 统计信息
}// groupStats 保存组的统计信息
type groupStats struct {loads int64 // 加载次数localHits int64 // 本地缓存命中次数localMisses int64 // 本地缓存未命中次数peerHits int64 // 从对等节点获取成功次数peerMisses int64 // 从对等节点获取失败次数loaderHits int64 // 从加载器获取成功次数loaderErrors int64 // 从加载器获取失败次数loadDuration int64 // 加载总耗时(纳秒)
}// GroupOption 定义Group的配置选项
type GroupOption func(*Group)// WithExpiration 设置缓存过期时间
func WithExpiration(d time.Duration) GroupOption {return func(g *Group) {g.expiration = d}
}// WithPeers 设置分布式节点
func WithPeers(peers PeerPicker) GroupOption {return func(g *Group) {g.peers = peers}
}// WithCacheOptions 设置缓存选项
func WithCacheOptions(opts CacheOptions) GroupOption {return func(g *Group) {g.mainCache = NewCache(opts)}
}// NewGroup 创建一个新的 Group 实例
func NewGroup(name string, cacheBytes int64, getter Getter, opts ...GroupOption) *Group {if getter == nil {panic("nil Getter")}// 创建默认缓存选项cacheOpts := DefaultCacheOptions()cacheOpts.MaxBytes = cacheBytesg := &Group{name: name,getter: getter,mainCache: NewCache(cacheOpts),loader: &singleflight.Group{},}// 应用选项for _, opt := range opts {opt(g)}// 注册到全局组映射groupsMu.Lock()defer groupsMu.Unlock()if _, exists := groups[name]; exists {slog.Warn("group already exists, will be replaced", "name", name)}groups[name] = gslog.Info("cache group created", "name", name, "cacheBytes", cacheBytes, "expiration", g.expiration)return g
}// GetGroup 获取指定名称的组
func GetGroup(name string) *Group {groupsMu.RLock()defer groupsMu.RUnlock()return groups[name]
}// Get 从缓存获取数据
func (g *Group) Get(ctx context.Context, key string) (ByteView, error) {// 检查组是否已关闭if atomic.LoadInt32(&g.closed) == 1 {return ByteView{}, ErrGroupClosed}if key == "" {return ByteView{}, ErrKeyRequired}// 从本地缓存获取view, ok := g.mainCache.Get(ctx, key)if ok {atomic.AddInt64(&g.stats.localHits, 1)return view, nil}atomic.AddInt64(&g.stats.localMisses, 1)// 尝试从其他节点获取或加载return g.load(ctx, key)
}// Set 设置缓存值
func (g *Group) Set(ctx context.Context, key string, value []byte) error {// 检查组是否已关闭if atomic.LoadInt32(&g.closed) == 1 {return ErrGroupClosed}if key == "" {return ErrKeyRequired}if len(value) == 0 {return ErrValueRequired}// 检查是否是从其他节点同步过来的请求isPeerRequest := ctx.Value("from_peer") != nil// 创建缓存视图view := ByteView{b: cloneBytes(value)}// 设置到本地缓存if g.expiration > 0 {g.mainCache.AddWithExpiration(key, view, time.Now().Add(g.expiration))} else {g.mainCache.Add(key, view)}// 如果不是从其他节点同步过来的请求,且启用了分布式模式,同步到其他节点if !isPeerRequest && g.peers != nil {go g.syncToPeers(ctx, "set", key, value)}return nil
}// Delete 删除缓存值
func (g *Group) Delete(ctx context.Context, key string) error {// 检查组是否已关闭if atomic.LoadInt32(&g.closed) == 1 {return ErrGroupClosed}if key == "" {return ErrKeyRequired}// 从本地缓存删除g.mainCache.Delete(key)// 检查是否是从其他节点同步过来的请求isPeerRequest := ctx.Value("from_peer") != nil// 如果不是从其他节点同步过来的请求,且启用了分布式模式,同步到其他节点if !isPeerRequest && g.peers != nil {go g.syncToPeers(ctx, "delete", key, nil)}return nil
}// syncToPeers 同步操作到其他节点
func (g *Group) syncToPeers(ctx context.Context, op string, key string, value []byte) {if g.peers == nil {return}// 选择对等节点peer, ok, isSelf := g.peers.PickPeer(key)if !ok || isSelf {return}// 创建同步请求上下文syncCtx := context.WithValue(context.Background(), "from_peer", true)var err errorswitch op {case "set":err = peer.Set(syncCtx, g.name, key, value)case "delete":_, err = peer.Delete(g.name, key)}if err != nil {slog.Error("Failed to sync %s to peer", "op", op, "err", err)slog.Warn("failed to sync", "op", op, "key", key, "value", string(value), "err", err)}
}// Clear 清空缓存
func (g *Group) Clear() {// 检查组是否已关闭if atomic.LoadInt32(&g.closed) == 1 {return}g.mainCache.Clear()slog.Info("cache group cleared", "group", g.name)
}// Close 关闭组并释放资源
func (g *Group) Close() error {// 如果已经关闭,直接返回if !atomic.CompareAndSwapInt32(&g.closed, 0, 1) {return nil}// 关闭本地缓存if g.mainCache != nil {g.mainCache.Close()}// 从全局组映射中移除groupsMu.Lock()delete(groups, g.name)groupsMu.Unlock()slog.Info("cache group closed", "group", g.name)return nil
}// load 加载数据
func (g *Group) load(ctx context.Context, key string) (value ByteView, err error) {// 使用 singleflight 确保并发请求只加载一次startTime := time.Now()viewi, err := g.loader.Do(key, func() (interface{}, error) {return g.loadData(ctx, key)})// 记录加载时间loadDuration := time.Since(startTime).Nanoseconds()atomic.AddInt64(&g.stats.loadDuration, loadDuration)atomic.AddInt64(&g.stats.loads, 1)if err != nil {atomic.AddInt64(&g.stats.loaderErrors, 1)return ByteView{}, err}view := viewi.(ByteView)// 设置到本地缓存if g.expiration > 0 {g.mainCache.AddWithExpiration(key, view, time.Now().Add(g.expiration))} else {g.mainCache.Add(key, view)}return view, nil
}// loadData 实际加载数据的方法
func (g *Group) loadData(ctx context.Context, key string) (value ByteView, err error) {// 尝试从远程节点获取if g.peers != nil {peer, ok, isSelf := g.peers.PickPeer(key)if ok && !isSelf {value, err := g.getFromPeer(ctx, peer, key)if err == nil {atomic.AddInt64(&g.stats.peerHits, 1)return value, nil}atomic.AddInt64(&g.stats.peerMisses, 1)slog.Warn("failed to get from peer", "key", key, "peer", peer)}}// 从数据源加载bytes, err := g.getter.Get(ctx, key)if err != nil {return ByteView{}, fmt.Errorf("failed to get data: %w", err)}atomic.AddInt64(&g.stats.loaderHits, 1)return ByteView{b: cloneBytes(bytes)}, nil
}// getFromPeer 从其他节点获取数据
func (g *Group) getFromPeer(ctx context.Context, peer Peer, key string) (ByteView, error) {bytes, err := peer.Get(g.name, key)if err != nil {return ByteView{}, fmt.Errorf("failed to get from peer: %w", err)}return ByteView{b: bytes}, nil
}// RegisterPeers 注册PeerPicker
func (g *Group) RegisterPeers(peers PeerPicker) {if g.peers != nil {panic("RegisterPeers called more than once")}g.peers = peersslog.Info("register peers for group", "group", g.name)
}// Stats 返回缓存统计信息
func (g *Group) Stats() map[string]interface{} {stats := map[string]interface{}{"name": g.name,"closed": atomic.LoadInt32(&g.closed) == 1,"expiration": g.expiration,"loads": atomic.LoadInt64(&g.stats.loads),"local_hits": atomic.LoadInt64(&g.stats.localHits),"local_misses": atomic.LoadInt64(&g.stats.localMisses),"peer_hits": atomic.LoadInt64(&g.stats.peerHits),"peer_misses": atomic.LoadInt64(&g.stats.peerMisses),"loader_hits": atomic.LoadInt64(&g.stats.loaderHits),"loader_errors": atomic.LoadInt64(&g.stats.loaderErrors),}// 计算各种命中率totalGets := stats["local_hits"].(int64) + stats["local_misses"].(int64)if totalGets > 0 {stats["hit_rate"] = float64(stats["local_hits"].(int64)) / float64(totalGets)}totalLoads := stats["loads"].(int64)if totalLoads > 0 {stats["avg_load_time_ms"] = float64(atomic.LoadInt64(&g.stats.loadDuration)) / float64(totalLoads) / float64(time.Millisecond)}// 添加缓存大小if g.mainCache != nil {cacheStats := g.mainCache.Stats()for k, v := range cacheStats {stats["cache_"+k] = v}}return stats
}// ListGroups 返回所有缓存组的名称
func ListGroups() []string {groupsMu.RLock()defer groupsMu.RUnlock()names := make([]string, 0, len(groups))for name := range groups {names = append(names, name)}return names
}// DestroyGroup 销毁指定名称的缓存组
func DestroyGroup(name string) bool {groupsMu.Lock()defer groupsMu.Unlock()if g, exists := groups[name]; exists {g.Close()delete(groups, name)slog.Info("destroyed cache group", "group", name)return true}return false
}// DestroyAllGroups 销毁所有缓存组
func DestroyAllGroups() {groupsMu.Lock()defer groupsMu.Unlock()for name, g := range groups {g.Close()delete(groups, name)slog.Info("destroyed cache group", "group", name)}
}
这段 Go 代码定义了一个分布式缓存系统的核心组件:Group。可以把它理解为一个拥有特定命名空间(例如 “user-cache” 或 “product-cache”)的缓存管理器。
这个 Group 非常强大,它统一了本地缓存、对等节点(分布式)缓存和数据源(回源) 的数据获取逻辑,并内置了防止“缓存惊群”的机制。
核心目标与设计理念
Group 的目标是为用户提供一个简单的 Get, Set, Delete 接口来操作缓存,而将复杂的内部逻辑完全封装起来。这些复杂逻辑包括:
- 分层缓存:优先从本地内存获取,失败则尝试从其他远程节点获取,如果都失败了,最后才从最慢的数据源(如数据库)加载。
- 分布式协作:通过
PeerPicker接口,它可以知道一个key应该由哪个节点负责,并向其发起请求。 - 防止缓存惊群 (Cache Stampede):使用
singleflight机制,确保在缓存失效的瞬间,即使有成百上千个并发请求访问同一个key,也只有一个请求会真正去加载数据,其他请求则会等待这个结果,从而避免了对底层数据源的冲击。 - 数据统计与监控:内置了详细的统计功能,可以监控命中率、加载时间、来源等关键指标。
- 生命周期管理:可以被创建、获取、销毁,并能优雅地关闭。
代码分段解析
1. Group 结构体:缓存组的核心
type Group struct {name string // 缓存组的名字,全局唯一getter Getter // 当缓存未命中时,用于加载数据的回调函数 (回源)mainCache *Cache // 底层的本地缓存实例 (例如 LRU 缓存)peers PeerPicker // 节点选择器,用于在分布式环境中找到 key 对应的节点loader *singleflight.Group // 防止缓存惊群的加载器expiration time.Duration // 缓存的过期时间closed int32 // 标记组是否关闭 (原子变量保证并发安全)stats groupStats // 各种统计信息
}
getter(回源加载器): 这是Group的灵魂。当一个数据在所有缓存层(本地和远程)都找不到时,Group就会调用这个用户提供的getter函数去获取“源数据”(比如从数据库查询)。peers(节点选择器): 这是实现分布式能力的关键。它帮助Group决定一个key是应该在本地处理,还是应该去问集群里的哪个“兄弟节点”。loader(singleflight): 这是一个重要的性能优化工具。它确保对于同一个key的数据加载过程,在同一时间内只执行一次。
2. Get 方法:核心读取路径 (Read Path)
这是最复杂也最能体现其设计思想的方法。当调用 g.Get("some-key") 时,会发生以下事情:
-
检查状态:首先检查
Group是否已经关闭。 -
查找本地缓存 (
mainCache):- 命中:如果在本地内存中找到了数据,立即增加
localHits计数,并直接返回结果。这是最快的路径。 - 未命中:如果本地没有,增加
localMisses计数,然后进入下一步。
- 命中:如果在本地内存中找到了数据,立即增加
-
调用
load方法: 本地既然没有,就需要从其他地方加载。load方法负责这个过程。
3. load 和 loadData 方法:数据加载与防惊群
load 方法的逻辑非常精妙:
-
g.loader.Do(key, ...): 它做的第一件事不是直接去加载数据,而是将真正的加载逻辑包裹在singleflight的Do方法里。- 作用:如果此时有 100 个 goroutine 都在请求同一个
key,singleflight会保证只有一个 goroutine 会去执行传入的函数(即g.loadData),其他 99 个则会阻塞等待,直到那个 goroutine 完成并返回结果。所有等待者都会收到同一份结果。这就是防止缓存惊群的关键。
- 作用:如果此时有 100 个 goroutine 都在请求同一个
-
g.loadData(key, ...): 这是被singleflight保护的、真正的加载逻辑。- 尝试从远程节点获取:
- 它会调用
g.peers.PickPeer(key)来找到负责这个key的远程节点。 - 如果找到了一个远程节点(并且不是自己),它会调用
g.getFromPeer向该节点发起网络请求。 - 如果远程节点成功返回数据,增加
peerHits计数,将数据返回。 - 如果远程节点获取失败,增加
peerMisses计数,并继续执行下一步(回源)。
- 它会调用
- 回源 (Fallback to Source):
- 如果集群中没有其他节点,或者从远程节点获取失败,那么就到了最后一步:调用用户传入的
g.getter.Get(...)方法。 - 这个
getter会从最终数据源(如数据库、API 服务等)获取数据。 - 成功后,增加
loaderHits计数。
- 如果集群中没有其他节点,或者从远程节点获取失败,那么就到了最后一步:调用用户传入的
- 尝试从远程节点获取:
-
填充本地缓存:
load方法在从singleflight获得数据后(无论是从远程节点还是数据源加载的),会把这份数据存入g.mainCache中,以便下一次请求能够快速命中本地缓存。
4. Set 和 Delete 方法:写入与删除路径 (Write Path)
这两个方法处理数据的变更。
- 本地操作:首先,它们会直接修改或删除本地缓存 (
g.mainCache) 中的数据。 - 分布式同步 (
syncToPeers):- 一个关键的检查是
isPeerRequest。它通过检查context中是否有"from_peer"这个标记来判断当前操作是否是由另一个节点同步过来的。 - 如果这是一个原始请求(不是同步请求),并且配置了分布式节点 (
g.peers != nil),它会启动一个 goroutine 去执行syncToPeers。 syncToPeers会找到负责该key的节点,并向其发送一个Set或Delete请求。在发送请求时,它会在context中加入"from_peer": true标记,以防止接收方节点再次进行同步,从而避免无限循环。
- 一个关键的检查是
总结
这个 Group 模块是一个设计精良、功能完备的缓存管理单元。它优雅地整合了多种缓存策略:
- 对于读操作 (
Get):实现了本地缓存 -> 远程节点缓存 -> 数据源的三级回退策略,并用singleflight解决了高并发下的缓存惊群问题。 - 对于写操作 (
Set/Delete):实现了更新本地 -> 异步同步到对应远程节点的策略,并通过context标记避免了同步风暴。
通过将这些复杂的逻辑封装在一个 Group 中,上层应用可以像使用一个简单的本地缓存一样使用这个强大的分布式缓存系统。
server - 节点
package mainimport ("crypto/tls""fmt"pb "go-cache/pb""go-cache/registy""net""sync""time""github.com/sirupsen/logrus"clientv3 "go.etcd.io/etcd/client/v3""golang.org/x/net/context""google.golang.org/grpc""google.golang.org/grpc/credentials""google.golang.org/grpc/health"healthpb "google.golang.org/grpc/health/grpc_health_v1"
)// Server 定义缓存服务器
type Server struct {pb.UnimplementedKamaCacheServeraddr string // 服务地址svcName string // 服务名称groups *sync.Map // 缓存组grpcServer *grpc.Server // gRPC服务器etcdCli *clientv3.Client // etcd客户端stopCh chan error // 停止信号opts *ServerOptions // 服务器选项
}// ServerOptions 服务器配置选项
type ServerOptions struct {EtcdEndpoints []string // etcd端点DialTimeout time.Duration // 连接超时MaxMsgSize int // 最大消息大小TLS bool // 是否启用TLSCertFile string // 证书文件KeyFile string // 密钥文件
}// DefaultServerOptions 默认配置
var DefaultServerOptions = &ServerOptions{EtcdEndpoints: []string{"localhost:2379"},DialTimeout: 5 * time.Second,MaxMsgSize: 4 << 20, // 4MB
}// ServerOption 定义选项函数类型
type ServerOption func(*ServerOptions)// WithEtcdEndpoints 设置etcd端点
func WithEtcdEndpoints(endpoints []string) ServerOption {return func(o *ServerOptions) {o.EtcdEndpoints = endpoints}
}// WithDialTimeout 设置连接超时
func WithDialTimeout(timeout time.Duration) ServerOption {return func(o *ServerOptions) {o.DialTimeout = timeout}
}// WithTLS 设置TLS配置
func WithTLS(certFile, keyFile string) ServerOption {return func(o *ServerOptions) {o.TLS = trueo.CertFile = certFileo.KeyFile = keyFile}
}// NewServer 创建新的服务器实例
func NewServer(addr, svcName string, opts ...ServerOption) (*Server, error) {options := DefaultServerOptionsfor _, opt := range opts {opt(options)}// 创建etcd客户端etcdCli, err := clientv3.New(clientv3.Config{Endpoints: options.EtcdEndpoints,DialTimeout: options.DialTimeout,})if err != nil {return nil, fmt.Errorf("failed to create etcd client: %v", err)}// 创建gRPC服务器var serverOpts []grpc.ServerOptionserverOpts = append(serverOpts, grpc.MaxRecvMsgSize(options.MaxMsgSize))if options.TLS {creds, err := loadTLSCredentials(options.CertFile, options.KeyFile)if err != nil {return nil, fmt.Errorf("failed to load TLS credentials: %v", err)}serverOpts = append(serverOpts, grpc.Creds(creds))}srv := &Server{addr: addr,svcName: svcName,groups: &sync.Map{},grpcServer: grpc.NewServer(serverOpts...),etcdCli: etcdCli,stopCh: make(chan error),opts: options,}// 注册服务pb.RegisterKamaCacheServer(srv.grpcServer, srv)// 注册健康检查服务healthServer := health.NewServer()healthpb.RegisterHealthServer(srv.grpcServer, healthServer)healthServer.SetServingStatus(svcName, healthpb.HealthCheckResponse_SERVING)return srv, nil
}// Start 启动服务器
func (s *Server) Start() error {// 启动gRPC服务器lis, err := net.Listen("tcp", s.addr)if err != nil {return fmt.Errorf("failed to listen: %v", err)}// 注册到 etcdstopCh := make(chan error)go func() {if err := registy.Register(s.svcName, s.addr, stopCh); err != nil {logrus.Errorf("failed to register service: %v", err)close(stopCh)return}}()logrus.Infof("Server starting at %s", s.addr)return s.grpcServer.Serve(lis)
}// Stop 停止服务器
func (s *Server) Stop() {close(s.stopCh)s.grpcServer.GracefulStop()if s.etcdCli != nil {s.etcdCli.Close()}
}// Get 实现Cache服务的Get方法
func (s *Server) Get(ctx context.Context, req *pb.Request) (*pb.ResponseForGet, error) {group := GetGroup(req.Group)if group == nil {return nil, fmt.Errorf("group %s not found", req.Group)}view, err := group.Get(ctx, req.Key)if err != nil {return nil, err}return &pb.ResponseForGet{Value: view.ByteSLice()}, nil
}// Set 实现Cache服务的Set方法
func (s *Server) Set(ctx context.Context, req *pb.Request) (*pb.ResponseForGet, error) {group := GetGroup(req.Group)if group == nil {return nil, fmt.Errorf("group %s not found", req.Group)}// 从 context 中获取标记,如果没有则创建新的 contextfromPeer := ctx.Value("from_peer")if fromPeer == nil {ctx = context.WithValue(ctx, "from_peer", true)}if err := group.Set(ctx, req.Key, req.Value); err != nil {return nil, err}return &pb.ResponseForGet{Value: req.Value}, nil
}// Delete 实现Cache服务的Delete方法
func (s *Server) Delete(ctx context.Context, req *pb.Request) (*pb.ResponseForDelete, error) {group := GetGroup(req.Group)if group == nil {return nil, fmt.Errorf("group %s not found", req.Group)}err := group.Delete(ctx, req.Key)return &pb.ResponseForDelete{Value: err == nil}, err
}// loadTLSCredentials 加载TLS证书
func loadTLSCredentials(certFile, keyFile string) (credentials.TransportCredentials, error) {cert, err := tls.LoadX509KeyPair(certFile, keyFile)if err != nil {return nil, err}return credentials.NewTLS(&tls.Config{Certificates: []tls.Certificate{cert},}), nil
}这段 Go 代码定义了一个gRPC 服务器,它是分布式缓存集群中每个节点的“骨架”和“通信中心”。
这个服务器负责处理来自其他节点(或客户端)的网络请求,并将其委托给前一个代码中我们分析过的 Group 模块来执行实际的缓存操作。同时,它还负责向 etcd 注册自己,以便集群中的其他成员能够发现它。
下面我将为你详细解释其设计和工作流程。
总体目标
Server 的目标是将内部复杂的缓存逻辑(由 Group 提供)通过一个标准化的、高性能的网络接口(gRPC)暴露出去。它承担了以下几个关键职责:
- 网络监听与服务:启动一个 gRPC 服务,监听一个指定的网络地址和端口,准备接收请求。
- 服务注册:在启动时,向
etcd服务注册中心注册自己的地址,宣告“我上线了,可以提供缓存服务”。 - 请求路由:接收 gRPC 请求(如
Get,Set,Delete),解析请求参数,并找到对应的Group来处理这些请求。 - 安全通信:支持 TLS,确保节点间的数据传输是加密的、安全的。
- 生命周期管理:能够优雅地启动和停止。停止时会从
etcd注销自己,确保不会有请求被发送到一个已经下线的节点。 - 健康检查:内置了 gRPC 的标准健康检查服务,便于外部系统(如 Kubernetes、Prometheus)监控其运行状态。
代码分段解析
1. Server 结构体:节点的核心
type Server struct {pb.UnimplementedKamaCacheServer // gRPC 生成的桩代码,提供默认实现addr string // 服务器监听的地址,如 "localhost:8080"svcName string // 在 etcd 中注册的服务名groups *sync.Map // (当前代码未使用,但可能是为未来动态管理group预留的)grpcServer *grpc.Server // 底层的 gRPC 服务器实例etcdCli *clientv3.Client // etcd 客户端,用于服务注册stopCh chan error // 用于发送停止信号的 channelopts *ServerOptions // 服务器的配置选项
}
grpcServer: 这是真正负责处理网络通信的引擎。etcdCli和svcName: 这两个字段是实现服务发现的关键。服务器用它们来告诉etcd:“我是 ‘svcName’ 服务的一个实例,我的地址是 ‘addr’”。
2. 配置选项 (ServerOptions 和函数式选项模式)
type ServerOptions struct {// ...
}
func WithEtcdEndpoints(endpoints []string) ServerOption {// ...
}
- 代码使用了非常优雅的函数式选项模式 (
Functional Options Pattern)。这使得创建Server时配置非常灵活,可以只配置需要的选项,其他使用默认值。例如NewServer(addr, name, WithTLS("cert.pem", "key.pem"))。
3. NewServer 方法:服务器的创建与初始化
这是创建服务器实例的构造函数,它执行了一系列初始化步骤:
- 应用配置:解析传入的
ServerOption,设置etcd地址、TLS 等配置。 - 连接 Etcd:创建一个
etcd客户端,为后续的服务注册做准备。 - 创建 gRPC 服务器:
- 初始化
grpc.Server。 - 如果启用了 TLS (
opts.TLS == true),它会调用loadTLSCredentials加载证书和私钥,并将安全凭证应用到 gRPC 服务器上。
- 初始化
- 注册服务:这是最关键的步骤之一。
pb.RegisterKamaCacheServer(srv.grpcServer, srv): 这行代码的作用是**“连接”**。它告诉grpcServer:“任何实现了KamaCacheServer接口的 RPC 调用(比如Get,Set),都应该由srv这个对象(即我们正在创建的Server实例)的同名方法来处理”。healthpb.RegisterHealthServer(...): 注册标准的健康检查服务。
4. Start 和 Stop 方法:生命周期管理
-
Start():net.Listen("tcp", s.addr): 在指定的地址上打开一个 TCP 监听端口。registy.Register(...): 在一个新的 goroutine 中调用Register函数,将自己注册到etcd。注册成功后,这个 goroutine 会通过心跳机制维持租约。s.grpcServer.Serve(lis): 这是一个阻塞调用。它启动 gRPC 服务器的主循环,开始接收和处理来自客户端或其他节点的请求。程序会一直停留在这里直到服务器停止。
-
Stop():close(s.stopCh): 关闭stopCh通道。这会向registy.Register中的 goroutine 发送一个停止信号,使其主动从etcd中撤销租约并注销服务。s.grpcServer.GracefulStop(): 优雅地停止 gRPC 服务器。它不会立即切断现有连接,而是会停止接收新连接,并等待当前正在处理的请求完成后再关闭。s.etcdCli.Close(): 关闭与 etcd 的连接,释放资源。
5. RPC 处理方法 (Get, Set, Delete)
这些方法是 gRPC 服务的具体实现。它们是连接网络层和业务逻辑层(Group)的桥梁。
-
工作流程:
- 接收到一个 gRPC 请求 (
req)。 - 从请求中获取
group名称。 - 调用
GetGroup(req.Group)从全局的groups映射中找到对应的Group实例。 - 调用该
group实例的Get,Set,Delete方法来执行真正的缓存逻辑。 - 将
group返回的结果打包成 gRPC 的响应格式并返回。
- 接收到一个 gRPC 请求 (
-
关键细节 (
Set方法):ctx = context.WithValue(ctx, "from_peer", true)在
Set和Delete方法中(示例中Set更明显),它向context中添加了"from_peer": true标记。这是为了通知group.Set方法,这个请求是从另一个对等节点同步过来的,而不是一个原始的用户请求。group.Set看到这个标记后,就不会再尝试将这个变更同步给其他节点,从而避免了无限的同步循环。
总结
这个 Server 模块是整个分布式缓存节点的入口和执行器。它将之前我们看到的所有组件串联起来:
- 它通过 gRPC 提供了一个高性能、标准化的网络接口。
- 它使用
registy模块在启动时向etcd注册自己,并在关闭时注销,从而实现了服务的动态发现。 - 它接收网络请求后,将其无缝地传递给
Group模块,让Group去处理复杂的缓存读写、回源和节点间数据获取逻辑。
简而言之,Server 让抽象的 Group 缓存逻辑变成了一个可以在网络中被发现、被访问、能够与其他节点协同工作的、有生命周期的具体服务实例。