idea生成数据集调研
目录
hypogen-dr1
地址
来源论文
简介
样例
LiveIdeaBench
地址
简介
样例
AI IDea Bench
地址
来源论文
简介
样例
HypoBench
地址
来源论文
简介
样例
discoverybench
地址
来源论文
简介
样例
hypogen-dr1
地址
hypogen-dr1![]() https://huggingface.co/datasets/UniverseTBD/hypogen-dr1
https://huggingface.co/datasets/UniverseTBD/hypogen-dr1
来源论文
Sparks of Science: Hypothesis Generation Using Structured Paper Data
简介
该数据集包含约5500个结构化的问题-假设配对,均摘自顶级计算机科学会议。
从NeurIPS 2023(3218篇论文)和ICLR 2024(2260篇论文)这两场顶级计算机科学会议中被录用的论文中整理出数据集,最终得到5478个独特样本。随后,采用OpenAI的o1模型进行结构化提取步骤。对于每篇论文,我们首先从摘要中提取Bit、Flip和Spark三个关键要素,并引导o1模型识别其中的传统假设、创新方法,以及核心洞见的精炼4至6字概括。此外,我们还运用了高效的并行处理方法,并设置了重试机制,每项提取最多尝试三次,以确保输出的高质量。
对于提供全文的论文,我们使用一个专门的提示词来提取其中的“推理链”部分,引导模型重现从“Bit”到“Flip”的思维演进过程。这一步骤会从全文中移除摘要部分,以避免内容重复。随后,我们对论文进行处理,生成第一人称叙述,详细描述科学家的构思过程。处理后的结果以JSON格式存储,并附上论文ID、标题、作者、发表期刊、年份及引用信息等元数据。此外,我们还从作者近期提交的论文以及2024年至2025年间的相关研究工作中,独立构建了一个包含50个假设的测试集。
样例

LiveIdeaBench
地址
LiveIdeaBench --- LiveIdeaBench![]() https://liveideabench.com/
https://liveideabench.com/
简介
这个数据集是相当于试验记录。
原论文通过关键词激发ideas,这个论文的评价尺度可以学习。
样例
与我方向无关,略
AI IDea Bench
地址
https://ai-idea-bench.github.io/![]() https://ai-idea-bench.github.io/
https://ai-idea-bench.github.io/
来源论文
https://arxiv.org/abs/2504.14191![]() https://arxiv.org/abs/2504.14191
https://arxiv.org/abs/2504.14191
简介
精选了ICLR 2025前2%的论文、CVPR 2024的亮点论文、ECCV 2024的口头报告、NeurIPS 2024的焦点与口头报告,以及ICML 2024的焦点与口头报告。此外,我们还纳入了NAACL 2024、EMNLP 2024和ACL 2024的长篇及主会报告。考虑到部分论文可能在正式提交前已通过arXiv发布预印本,我们使用了arXiv API。 以排除2023年10月3日之前发表的论文。最终,我们共整理出3,495篇论文,这些论文将作为AI Idea Bench 2025数据集的基准真实数据。
对于每篇论文,我们采用Deepseek V3模型提取被引次数最高的十篇文献,随后由两位资深研究人员仔细评估这一候选名单,并最终遴选出五项既可行又合理的研究作为文献来源。
总结了目标文献所解决的问题,并明确了这些问题所属的研究领域,以及用于应对这些挑战的具体方法。在这一提取过程中,我们对方法进行了匿名化处理,既省略了其具体名称,又详细描述了各方法步骤。同时,我们还对目标文献的匿名化主题进行了概括,以进一步促进创意的生成。
样例
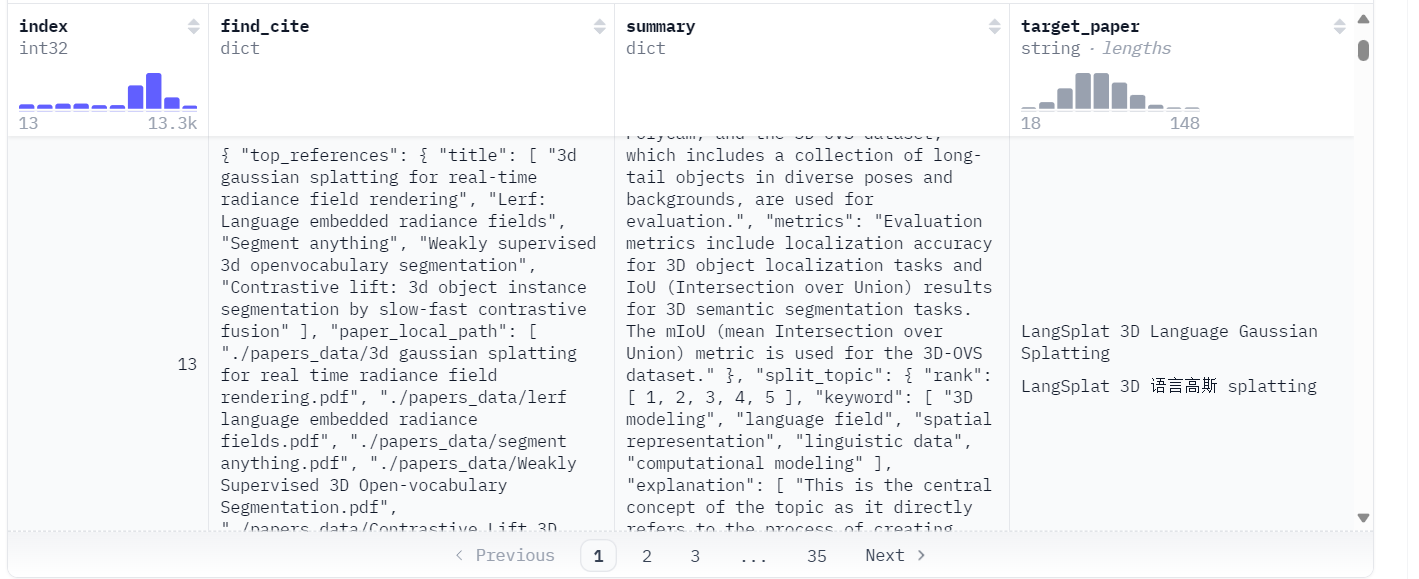
summary:
{ "主题": "LangSplat 采用了一种新颖的方法,通过 3D 高斯 Splatting 构建 3D 语言场,能够在 3D 空间内实现精确且高效的开放词汇查询。", "修订主题": "本文的主题是 3D 语言场建模。", "动机": "当前的 3D 语言场建模方法,如基于 NeRF 的方法,在速度和准确性方面存在显著局限性。这些方法难以实现精确的 3D 语言场,且渲染过程成本高昂。LangSplat 通过提出一种更高效和精确的 3D 语言场建模方法来解决这些问题,利用 3D 高斯 Splatting 和 SAM 的层次语义来提高性能和效率。", "方法": { "目标设计总结": "LangSplat 利用 3D 高斯 Splatting 进行高效渲染,并引入场景特定的语言自动编码器以降低内存成本。" } 它还采用 SAM 进行精确的物体分割,并利用层次语义来处理点模糊问题。","targeted_designs_details": { "design_name": [ "带语言特征的 3D 高斯 splatting", "场景特定的语言自动编码器", "带 SAM 的层次语义" ], "description": [ "LangSplat 将 3D 场景表示为一组 3D 高斯集合,每个高斯都通过从 CLIP 特征中提取的语言嵌入进行增强。这种方法允许在高位分辨率下高效渲染语言特征,绕过了基于 NeRF 方法的昂贵渲染过程。", "为了减少存储高维 CLIP 嵌入相关的内存成本,LangSplat 引入了一个场景特定的语言自动编码器。该自动编码器将 CLIP 特征压缩到低维潜在空间中,显著降低了内存需求,同时保持了语言特征的准确性。", "LangSplat 利用 Segment Anything Model (SAM)获取精确的物体掩码和层次语义。" ] } 这种方法使模型能够准确捕捉物体边界和语义层次,无需在多个尺度上进行密集搜索,从而提高了基于语言的查询的效率和准确性。" ], "problems_solved": [ "解决了基于 NeRF 的渲染的低效和高计算成本问题。", "缓解了高维语言嵌入显式建模相关的内存爆炸问题。", "解决了点模糊问题,通过提供精确的物体分割和层次语义,提高了 3D 语言场的准确性。" ] }, "datasets": "用于评估的 LERF 数据集,使用 iPhone 应用 Polycam 捕获,以及包含各种姿态和背景中长尾物体集合的 3D-OVS 数据集。", "metrics": "评估指标包括 3D 物体定位任务的定位精度和 3D 语义分割任务的 IoU(交并比)结果。" mIoU(平均交并比)指标用于 3D-OVS 数据集。" }, "split_topic": { "rank": [ 1, 2, 3, 4, 5 ], "keyword": [ "3D 建模", "语言领域", "空间表示", "语言数据", "计算建模" ], "explanation": [ "这是该主题的核心概念,因为它直接指代三维表示的创建过程,这是该主题的基础。", "这个术语至关重要,因为它指定了建模的领域,该领域涉及语言或文本数据,将其与其他类型的 3D 建模区分开来。", "这个关键词是相关的,因为 3D 建模本质上处理空间维度以及语言或文本数据在空间中的表示方式。", "这是必要的,因为它突出了正在建模的数据类型,强调了语言与 3D 表示之间的联系。", "这个术语很重要,因为它描述了用于创建和分析 3D 语言场模型的 方法或技术。" ] } }
HypoBench
地址
HypoBench – 向系统化和原则化假设生成基准测试迈进 --- HypoBench – Towards Systematic and Principled Benchmarking for Hypothesis Generation (chicagohai.github.io)![]() https://chicagohai.github.io/HypoBench/
https://chicagohai.github.io/HypoBench/
来源论文
https://arxiv.org/abs/2504.11524
简介
HypoBench 提供了一个全面的框架,用于评估模型生成能够解释观察现象的合理假设的能力。我们的基准测试:
- 结合了 12 个领域和 194 个数据集的真实世界和合成数据集
- 评估假设质量的多维度,重点在于解释力
- 实现不同方法和模型之间的系统性比较
样例
与我的方向无关,不看了。
discoverybench
地址
discoverybench![]() https://huggingface.co/datasets/allenai/discoverybench
https://huggingface.co/datasets/allenai/discoverybench
来源论文
DISCOVERYBENCH: Towards Data-Driven Discoverywith Large Language Models
简介
对于 数据优先方法:我们根据公开的公共数据集(D),如全国纵向调查(NLS)、全球生物多样性信息设施(GBIF)以及世界银行开放数据(WBOD),这些数据集均附有工作流详细信息,筛选出相关论文;2)随后,我们尝试用Python复现这些工作流。
从设计上采用的数据优先方法,仅限于上述众所周知的公开数据集。为了提升领域、数据集及工作流的多样性,我们还引入了一种 代码优先方法为了超越流行的公共数据集。在此方法中,我们首先根据附有可用数据集的科学论文搜索代码仓库,然后尝试用现有代码或从头开始、结合对相关论文的解读,以Python语言复现这些数据集。
专有/非开放数据集。我们最终确定了一份包含14个存储库的候选列表,但最终只有其中3个通过了我们针对其假设的所有检查,被纳入基准测试2中。
样例
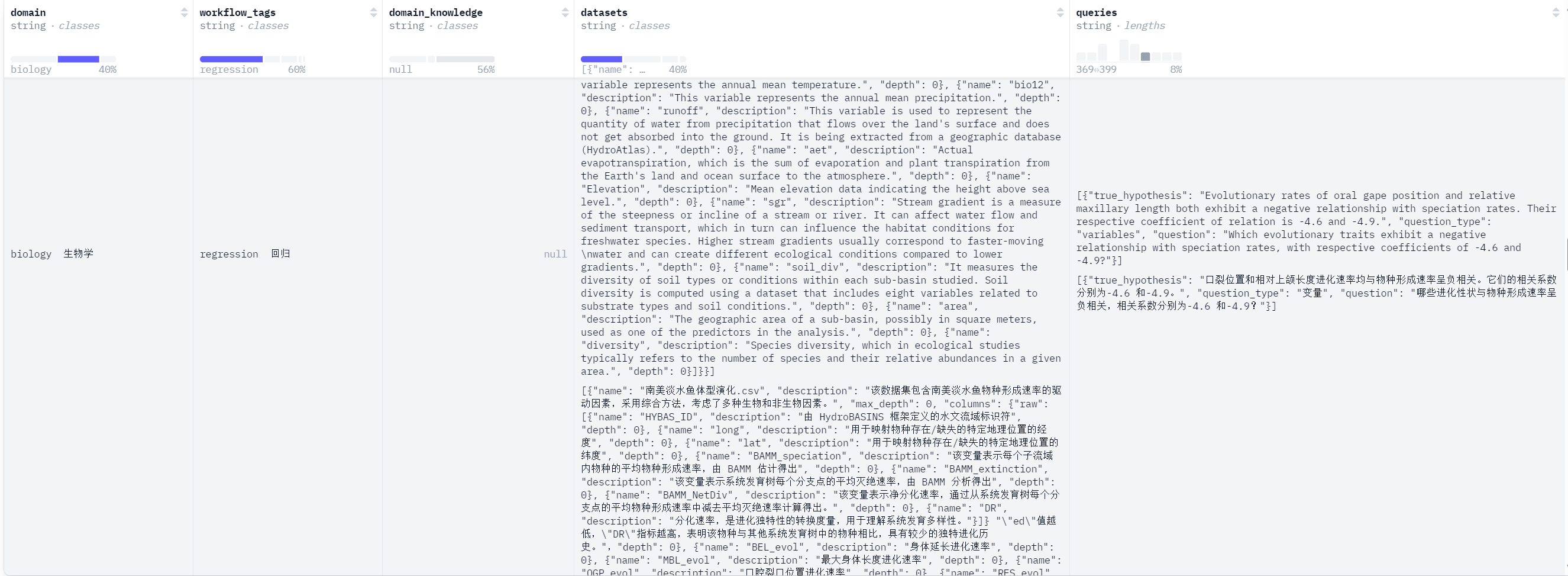
看着像找到能复现的论文,如何又复现了一遍,确认了结论。