Ultralytics代码库深度解读【二】: TensorRT 引擎文件的构建与序列化
目录
- 1.前言
- 2. 命令解析的大致过程
- 3. TensorRT引擎(.engine)导出具体流程
- 3.1 导出器实例调用(任务分配)
- 3.2 引擎文件导出核心代码
- 3.2.1 检查硬件配置及TensorRT库导入
- 3.2.2 启动导出及准备相关文件
- 3.2.3 创建引擎
- 3.2.4 配置DLA(如果启用)
- 3.2.5 加载onnx文件
- 3.2.6 网络输入输出信息显示
- 3.2.7 动态形状配置(如果启用)
- 3.2.8 精度配置
- 3.2.9 引擎构建和保存
- 4 总结
1.前言
上篇文章(Ultralytics代码库深度解读【一】:onnx模型导出)我们详细讲述了.onnx模型的导出,.onnx 是一种通用的模型格式(Open Neural Network Exchange),目的是让不同框架(如 PyTorch、TensorFlow)训练的模型可以跨平台兼容,相当于模型的 “通用中间格式”。
.engine文件是英伟达(NVIDIA)TensorRT 框架生成的模型部署文件,它通常需要以 .onnx 模型作为输入,专门用于在英伟达硬件(如 GPU、 Jetson 系列嵌入式设备等)上进行高性能推理部署。
从本质上来说,它是经过 TensorRT 优化后的模型序列化文件,包含了模型的计算图结构、权重参数以及针对特定英伟达硬件优化的执行计划。这些优化可能包括层融合、精度校准(如 FP16、INT8 量化)、内核自动调优等,目的是最大限度发挥英伟达 GPU 的计算能力,提升模型推理速度。
本篇我们就详细说说适配于NVIDIA TensorRT平台的.engine文件导出详细过程。关于本文的内容,仍然有两点需要说明:
- 本帖所讲的代码库是我在购买亚博智能的jetson orin super开发套件的时候附赠的代码库,并非官方标准版,但因其Ultralytics官方代码相差不大,对于官方代码的学习仍然具有参考价值。
- 本帖以常见的YOLO V8模型导出为例,其他模型导出同理。
我们先来看看软件动态行为关系图吧(不严谨版本,纯手绘):
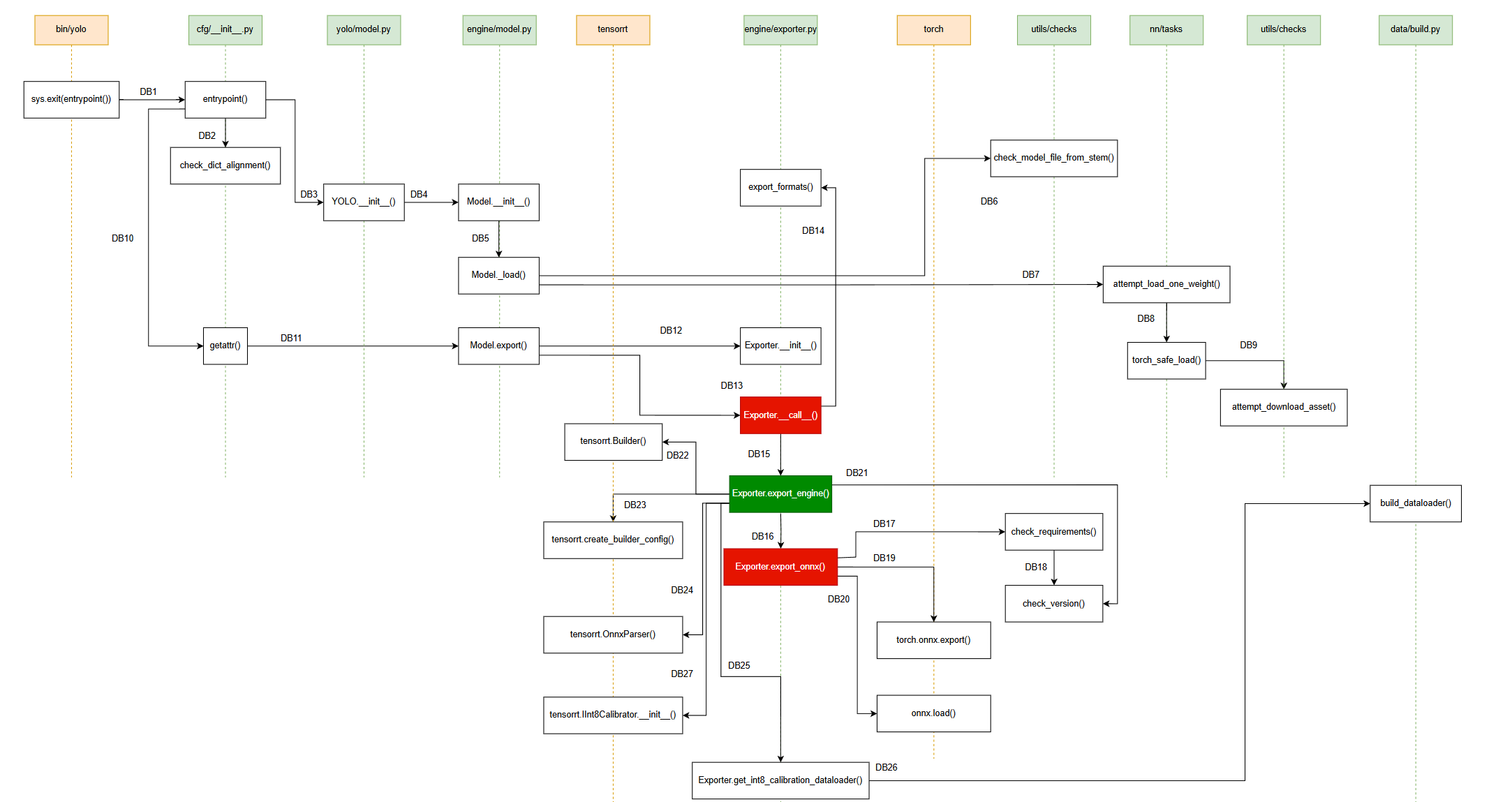
有了上篇文章作为铺垫,这篇就无需对参数的解析过程进行详细剖析,仅需关注TensorRT引擎文件(.engine)的具体导出过程进行探索。
💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗
2. 命令解析的大致过程
在上一篇帖子(Ultralytics代码库深度解读【一】:onnx模型导出)中,已经非常详细地讲述了具体的命令解析过程,这里再来大致说说。
- 作者在创建代码库的时候,
pyproject.toml文件中有相关命令解析的语句。 - 当我们在用pip安装ultralytics包时,会解析
pyproject.toml文件,然后在dist-info中生成 entry_points.txt 等元数据文件,并据此生成可执行脚本(如/bin/yolo) - 当我们输入
yolo export model=yolov8n.pt format=engine命令时,系统会找到脚本并执行,据此找到cfg/__init__.py的entrypoint函数。
💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗
3. TensorRT引擎(.engine)导出具体流程
3.1 导出器实例调用(任务分配)
前期有很多过程都与.onnx文件的导出方式,大家可直接参照上一篇帖子和我开头画的软件动态行为图把Exporter.__call__()前的步骤捋一遍。虽然同上次一样都有Exporter.__call__()函数的参与,但因这次传入的参数不一样,因此该函数的运行情况也是有所不同。我们详细看看。
self.run_callbacks("on_export_start")t = time.time()fmt = self.args.format.lower() # to lowercaseif fmt in {"tensorrt", "trt"}: # 'engine' aliasesfmt = "engine"if fmt in {"mlmodel", "mlpackage", "mlprogram", "apple", "ios", "coreml"}: # 'coreml' aliasesfmt = "coreml"
这里还是很贴心地添加了纠错机制,当我们的format参数为tensorrt或者trt时,系统会帮我们纠正过来,或者说,统一成engine。
fmts_dict = export_formats()fmts = tuple(fmts_dict["Argument"][1:]) # available export formats
从支持导出的格式中搜索是否可以导出我们想要的格式。
上篇已经分析过,代码库是支持导出engine格式的,我们可以再看一下:
def export_formats():"""Ultralytics YOLO export formats."""x = [["PyTorch", "-", ".pt", True, True, []],["TorchScript", "torchscript", ".torchscript", True, True, ["batch", "optimize"]],["ONNX", "onnx", ".onnx", True, True, ["batch", "dynamic", "half", "opset", "simplify"]],["OpenVINO", "openvino", "_openvino_model", True, False, ["batch", "dynamic", "half", "int8"]],["TensorRT", "engine", ".engine", False, True, ["batch", "dynamic", "half", "int8", "simplify"]],["CoreML", "coreml", ".mlpackage", True, False, ["batch", "half", "int8", "nms"]],["TensorFlow SavedModel", "saved_model", "_saved_model", True, True, ["batch", "int8", "keras"]],["TensorFlow GraphDef", "pb", ".pb", True, True, ["batch"]],["TensorFlow Lite", "tflite", ".tflite", True, False, ["batch", "half", "int8"]],["TensorFlow Edge TPU", "edgetpu", "_edgetpu.tflite", True, False, []],["TensorFlow.js", "tfjs", "_web_model", True, False, ["batch", "half", "int8"]],["PaddlePaddle", "paddle", "_paddle_model", True, True, ["batch"]],["MNN", "mnn", ".mnn", True, True, ["batch", "half", "int8"]],["NCNN", "ncnn", "_ncnn_model", True, True, ["batch", "half"]],["IMX", "imx", "_imx_model", True, True, ["int8"]],]return dict(zip(["Format", "Argument", "Suffix", "CPU", "GPU", "Arguments"], zip(*x)))
经过切片后fmts = ("torchscript", "onnx", "openvino", "engine", "coreml", ...),显然是支持engine格式的。继续看后面的代码。
智能容错机制,当我们输入有偶尔的拼写错误的时候,软件可以帮我们纠正过来(导出类型)。
if fmt not in fmts:import difflib# Get the closest match if format is invalidmatches = difflib.get_close_matches(fmt, fmts, n=1, cutoff=0.6) # 60% similarity required to matchif not matches:raise ValueError(f"Invalid export format='{fmt}'. Valid formats are {fmts}")LOGGER.warning(f"WARNING ⚠️ Invalid export format='{fmt}', updating to format='{matches[0]}'")fmt = matches[0]
模糊匹配参数:n=1(最多1个匹配),cutoff=0.6(60%相似度)
示例:
输入 “engin” → 匹配 [“engine”] (自动更正)
输入 “xyz” → 无匹配 (抛出异常)
flags = [x == fmt for x in fmts]if sum(flags) != 1:raise ValueError(f"Invalid export format='{fmt}'. Valid formats are {fmts}")(jit,onnx,xml,engine,coreml,saved_model,pb,tflite,edgetpu,tfjs,paddle,mnn,ncnn,imx,) = flags # export booleansis_tf_format = any((saved_model, pb, tflite, edgetpu, tfjs))
flags这个标志会查询我们要导出的格式与支持的格式匹配的唯一性,运行后:
flags = [False, False, False, True, ...] # engine位置为True
只有在engine相对应的位置为True,其他位置都是False。确保了后续工作的正常开展。况且用布尔变量替代复杂的字符串比较后续代码可以直接使用 if engine: 而不是if fmt == "engine:"。
这部分代码是关于导出目标文件的硬件选择,是选择CPU还是GPU。
# Devicedla = Noneif fmt == "engine" and self.args.device is None:LOGGER.warning("WARNING ⚠️ TensorRT requires GPU export, automatically assigning device=0")self.args.device = "0"if fmt == "engine" and "dla" in str(self.args.device): # convert int/list to str firstdla = self.args.device.split(":")[-1]self.args.device = "0" # update device to "0"assert dla in {"0", "1"}, f"Expected self.args.device='dla:0' or 'dla:1, but got {self.args.device}."self.device = select_device("cpu" if self.args.device is None else self.args.device)
dla(全称:Deep Learning Accelerator,深度学习加速器,是一种专门为加速深度学习任务设计的硬件单元)。两个条件判断是关于engine格式文件导出任务的。
- 第一个if语句判断我们输入的命令中是否传入了
device参数,如果没有,那么提醒我们,并自动分配到GPU0进行文件导出工作。 - 第二个if语句判断我们传入的
device参数中是否包含dla,如果包含,则解析相应的具体值(0或者1),但设备仍然选择GPU0进行文件导出工作。
那么,我们传入的device参数到底是在选择GPU还是在选择DLA?
具体说来,这与我们传入的格式有关:
# device参数的真正含义:
device=0 # 直接在GPU 0上构建和运行
device=dla:0 # 在GPU上构建,在DLA核心0上运行
device=dla:1 # 在GPU上构建,在DLA核心1上运行
我们的jetson设备上只有1个GPU,所以当我们传入其他编号的时候,程序会抛出异常,并给出相应的提示。
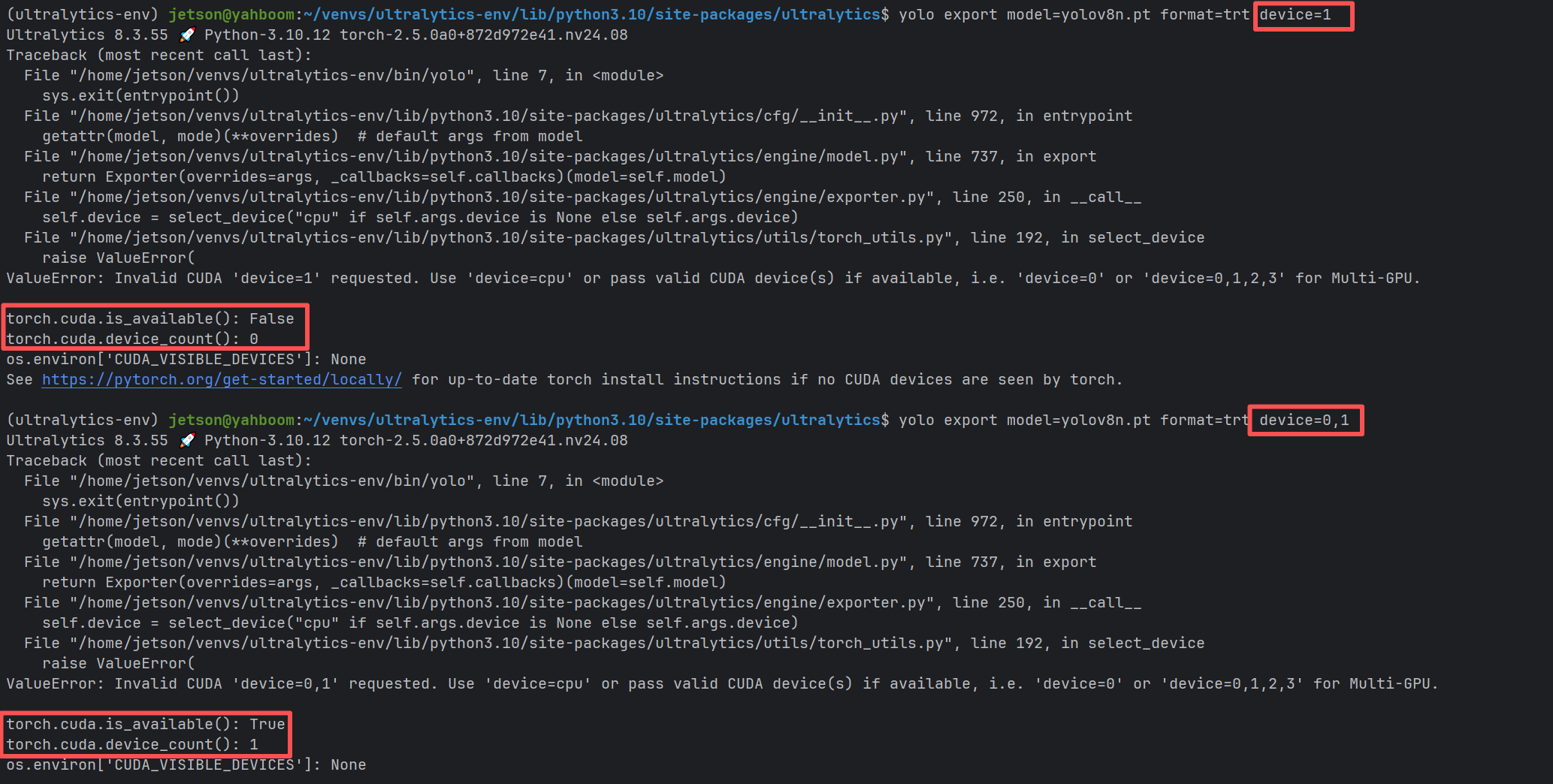
因此,无论是否传入device参数,系统都会默认将GPU 0分配给我们,用以导出有引擎文件,我们能决定的,就是将来在哪部分硬件来执行。
也就是说,我们只能选择将来模型部署的硬件,而不能决定导出所使用的硬件。
- 导出硬件(构建阶段)
必须在GPU上进行:无论最终要在什么硬件上部署,导出过程都需要在支持CUDA的GPU上执行
原因:TensorRT引擎构建需要完整的CUDA环境和TensorRT工具链
固定性:这个过程无法改变,始终在GPU上完成 - 部署硬件(运行阶段)
可以是DLA、GPU或其他支持的硬件:这是我们真正可以决定的部分
通过参数指定:使用device=dla:0或device=0来指定目标运行硬件
接下来就是具体配置我们选择的硬件设备。
self.device = select_device("cpu" if self.args.device is None else self.args.device)
后面还有个很重要的过程,就是参数兼容性检查,由于在onnx模型导出的时候并不涉及half和int8这两个参数,因此上篇文章没有讲。
# Argument compatibility checksvalidate_args(fmt, self.args, fmts_dict["Arguments"][flags.index(True) + 1])if imx and not self.args.int8:LOGGER.warning("WARNING ⚠️ IMX only supports int8 export, setting int8=True.")self.args.int8 = Trueif not hasattr(model, "names"):model.names = default_class_names()model.names = check_class_names(model.names)if self.args.half and self.args.int8:LOGGER.warning("WARNING ⚠️ half=True and int8=True are mutually exclusive, setting half=False.")self.args.half = Falseif self.args.half and onnx and self.device.type == "cpu":LOGGER.warning("WARNING ⚠️ half=True only compatible with GPU export, i.e. use device=0")self.args.half = Falseassert not self.args.dynamic, "half=True not compatible with dynamic=True, i.e. use only one."self.imgsz = check_imgsz(self.args.imgsz, stride=model.stride, min_dim=2) # check image sizeif self.args.int8 and engine:self.args.dynamic = True # enforce dynamic to export TensorRT INT8if self.args.optimize:assert not ncnn, "optimize=True not compatible with format='ncnn', i.e. use optimize=False"assert self.device.type == "cpu", "optimize=True not compatible with cuda devices, i.e. use device='cpu'"if self.args.int8 and tflite:assert not getattr(model, "end2end", False), "TFLite INT8 export not supported for end2end models."if edgetpu:if not LINUX:raise SystemError("Edge TPU export only supported on Linux. See https://coral.ai/docs/edgetpu/compiler")elif self.args.batch != 1: # see github.com/ultralytics/ultralytics/pull/13420LOGGER.warning("WARNING ⚠️ Edge TPU export requires batch size 1, setting batch=1.")self.args.batch = 1if isinstance(model, WorldModel):LOGGER.warning("WARNING ⚠️ YOLOWorld (original version) export is not supported to any format.\n""WARNING ⚠️ YOLOWorldv2 models (i.e. 'yolov8s-worldv2.pt') only support export to ""(torchscript, onnx, openvino, engine, coreml) formats. ""See https://docs.ultralytics.com/models/yolo-world for details.")if self.args.int8 and not self.args.data:self.args.data = DEFAULT_CFG.data or TASK2DATA[getattr(model, "task", "detect")] # assign default dataLOGGER.warning("WARNING ⚠️ INT8 export requires a missing 'data' arg for calibration. "f"Using default 'data={self.args.data}'.")
先通过validate_args()函数检查输入参数的有效性,如果输入了无法处理的参数,则会抛出异常。
def validate_args(format, passed_args, valid_args):# Only check valid usage of these argsexport_args = ["half", "int8", "dynamic", "keras", "nms", "batch"]assert valid_args is not None, f"ERROR ❌️ valid arguments for '{format}' not listed."custom = {"batch": 1, "data": None, "device": None} # exporter defaultsdefault_args = get_cfg(DEFAULT_CFG, custom)for arg in export_args:not_default = getattr(passed_args, arg, None) != getattr(default_args, arg, None)if not_default:assert arg in valid_args, f"ERROR ❌️ argument '{arg}' is not supported for format='{format}'"
后续的代码比较多,但是都不难理解。有两个条件判断需要注意:
if self.args.half and self.args.int8:LOGGER.warning("WARNING ⚠️ half=True and int8=True are mutually exclusive, setting half=False.")self.args.half = False
如果我们在导出的时候,量化想同时进行half字节和int8的量化,那么导出的时候无法同时满足,软件会优先保证int8量化,毕竟整型的运算肯定比浮点运算效率更高。
if self.args.int8 and engine:self.args.dynamic = True # enforce dynamic to export TensorRT INT8
这部分也比较好理解,如果在导出引擎文件时想采用int8量化,那么将dynamic配置为True ,也就是说,模型部署后可支持可变尺寸的输入。
还有配置self.args.data,如果启用了int8,那么后续的calibration(校准器)会用到这个参数。
self.args.data = DEFAULT_CFG.data or TASK2DATA[getattr(model, "task", "detect")] # assign default data
我们先来看看DEFAULT_CFG.data。

是空值,接着看看后面的TASK2DATA
TASK2DATA = {"detect": "coco8.yaml","segment": "coco8-seg.yaml","classify": "imagenet10","pose": "coco8-pose.yaml","obb": "dota8.yaml",
}
TASK2DATA算是找到了,具体的self.args.data值,与具体的任务类型有关,软件中设置的是detect,也就是检测任务,这样self.args.data的值也就变成了coco8.yaml。我们看看运行的打印效果:

与预期的一致。
这就是 Exporter.__ call __() 处理传入参数的完整过程!每个参数都经过了严格的验证、标准化和适配,确保导出过程的稳定性和兼容性。
后面就是直接分配任务到各个接口进行处理了,逻辑非常简单。
# Exportsf = [""] * len(fmts) # exported filenamesif jit or ncnn: # TorchScriptf[0], _ = self.export_torchscript()if engine: # TensorRT required before ONNXf[1], _ = self.export_engine(dla=dla)if onnx: # ONNXf[2], _ = self.export_onnx()if xml: # OpenVINOf[3], _ = self.export_openvino()if coreml: # CoreMLf[4], _ = self.export_coreml()if is_tf_format: # TensorFlow formatsself.args.int8 |= edgetpuf[5], keras_model = self.export_saved_model()if pb or tfjs: # pb prerequisite to tfjsf[6], _ = self.export_pb(keras_model=keras_model)if tflite:f[7], _ = self.export_tflite(keras_model=keras_model, nms=False, agnostic_nms=self.args.agnostic_nms)if edgetpu:f[8], _ = self.export_edgetpu(tflite_model=Path(f[5]) / f"{self.file.stem}_full_integer_quant.tflite")if tfjs:f[9], _ = self.export_tfjs()if paddle: # PaddlePaddlef[10], _ = self.export_paddle()if mnn: # MNNf[11], _ = self.export_mnn()if ncnn: # NCNNf[12], _ = self.export_ncnn()if imx:f[13], _ = self.export_imx()
由于我们需要导出engine格式的模型,所以跳转到export_engine()接口中去执行,顺便把我们配置的dla值也传进去。
3.2 引擎文件导出核心代码
上面已经提到,在Exporter.__ call __() 方法中,通过调用Exporter.export_engine()方法实现了引擎文件的导出,接下来我们重点看看这个方法。
3.2.1 检查硬件配置及TensorRT库导入
@try_exportdef export_engine(self, dla=None, prefix=colorstr("TensorRT:")):"""YOLO TensorRT export https://developer.nvidia.com/tensorrt."""assert self.im.device.type != "cpu", "export running on CPU but must be on GPU, i.e. use 'device=0'"f_onnx, _ = self.export_onnx() # run before TRT import https://github.com/ultralytics/ultralytics/issues/7016try:import tensorrt as trt # noqaexcept ImportError:if LINUX:check_requirements("tensorrt>7.0.0,!=10.1.0")import tensorrt as trt # noqacheck_version(trt.__version__, ">=7.0.0", hard=True)check_version(trt.__version__, "!=10.1.0", msg="https://github.com/ultralytics/ultralytics/pull/14239")
assert断言,因无法用CPU进行模型导出,所以如果选择了CPU,会直接抛出异常。- 执行onnx模型导出(具体的导出细节参考上篇帖子)。
- 导入
TensorRT库,如果不能导入,则尝试在线安装,然后再次进行版本检查(check_requirements()和check_version()函数的大致逻辑,我在上篇帖子4.2 onnx导出核心代码中有进行梳理)。
3.2.2 启动导出及准备相关文件
# Setup and checksLOGGER.info(f"\n{prefix} starting export with TensorRT {trt.__version__}...")is_trt10 = int(trt.__version__.split(".")[0]) >= 10 # is TensorRT >= 10assert Path(f_onnx).exists(), f"failed to export ONNX file: {f_onnx}"f = self.file.with_suffix(".engine") # TensorRT engine filelogger = trt.Logger(trt.Logger.INFO)if self.args.verbose:logger.min_severity = trt.Logger.Severity.VERBOSE
- 再次版本检查,确定TensorRT版本是否为10.x或更高
- 文件验证,确保ONNX文件已成功生成
- 给输出文件添加.engine后缀
- 创建TensorRT日志记录器,支持详细日志模式
- 根据
verbose参数的设定值值配置logger
TensorRT的Logger有以下几个级别(从详细到简略):
VERBOSE: 最详细的日志,包含大量调试信息INFO: 一般信息,显示构建过程的关键步骤WARNING: 警告信息ERROR:错误信息INTERNAL_ERROR: 内部错误信息
实际效果
当verbose=False时(默认):只显示基本的构建信息,较为简洁适合生产环境使用
当verbose=True时:显示详细的构建过程信息,包括每一层的优化信息、内存分配详情等,适合调试和开发时使用
如何配置❓
直接在启动导出的时候,在命令行中输入即可,比如:
# 启用详细日志
yolo export model=yolov8n.pt format=engine verbose=True
或者
yolo export model=yolov8n.pt format=engine verbose
3.2.3 创建引擎
# Engine builderbuilder = trt.Builder(logger)config = builder.create_builder_config()workspace = int(self.args.workspace * (1 << 30)) if self.args.workspace is not None else 0if is_trt10 and workspace > 0:config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace)elif workspace > 0: # TensorRT versions 7, 8config.max_workspace_size = workspaceflag = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)network = builder.create_network(flag)half = builder.platform_has_fast_fp16 and self.args.halfint8 = builder.platform_has_fast_int8 and self.args.int8
这部分代码基本基本逻辑如下:
- 创建TensorRT构建器实例,并创建了构建配置对象
- 工作空间设置:如果
TensorRT 10+版本,使用set_memory_pool_limit,而如果是TensorRT 7/8版本,则使用max_workspace_size,工作空间用于优化过程中的临时内存 - 设置其他相关参数:
3.1 flag:显式批处理,启用显式批处理模式,支持动态批处理大小
3.2 network:创建TensorRT网络定义
3.3 half:是否采用半字节量化导出(builder.platform_has_fast_fp16默认为True)
3.4 int8:是否采用int8量化模式(builder.platform_has_fast_int8默认为True)
也就是说,硬件平台支持fp16和int8两种量化类型,在 TensorRT 模型导出过程中,half(FP16,半精度浮点)和 int8 量化是两种常用的模型优化技术,它们的核心作用是在保证模型精度损失可接受的前提下,显著提升模型的推理性能并降低资源消耗。
3.2.4 配置DLA(如果启用)
# Optionally switch to DLA if enabledif dla is not None:if not IS_JETSON:raise ValueError("DLA is only available on NVIDIA Jetson devices")LOGGER.info(f"{prefix} enabling DLA on core {dla}...")if not self.args.half and not self.args.int8:raise ValueError("DLA requires either 'half=True' (FP16) or 'int8=True' (INT8) to be enabled. Please enable one of them and try again.")config.default_device_type = trt.DeviceType.DLAconfig.DLA_core = int(dla)config.set_flag(trt.BuilderFlag.GPU_FALLBACK)
这部分软件也比较好理解,主要有以下几个步骤:
- 平台验证,确保软件运行在jetson平台上,否则DLA无效。
- 必须保证
half和int8参数有一个为真,也就是说,启用了模型量化,否则在DLA上执行会慢很多 - 进行设备的相关配置:
3.1 设置默认设备类型为DLA
3.2 指定DLA核心(0或1)
3.3 启用GPU回退机制
这个回退机制该如何理解呢?
GPU回退机制是一种容错机制,当TensorRT尝试在DLA上运行某些层时,如果这些层不被DLA支持或由于某些原因无法在DLA上执行,TensorRT会自动将这些层回退到GPU上执行,而不是直接报错或失败。这样一来整个网络可以在DLA和GPU之间混合执行。
为什么会这样呢?相较于GPU,DLA是专用的深度学习单元,所以会有一些局限性。比方说:
😟只支持特定类型的层(卷积、激活函数、池化等)
😟对输入输出格式有严格要求
😟不支持动态尺寸
😟有批处理大小限制
所以,如果启用了DLA,那么会优先在DLA上运行神经网络,如果遇到了限制,则会将这些运算回退到GPU上进行运行。
3.2.5 加载onnx文件
# Read ONNX fileparser = trt.OnnxParser(network, logger)if not parser.parse_from_file(f_onnx):raise RuntimeError(f"failed to load ONNX file: {f_onnx}")
使用ONNX解析器将ONNX模型加载到TensorRT网络中,如果解析失败则抛出运行时错误。
3.2.6 网络输入输出信息显示
# Network inputsinputs = [network.get_input(i) for i in range(network.num_inputs)]outputs = [network.get_output(i) for i in range(network.num_outputs)]for inp in inputs:LOGGER.info(f'{prefix} input "{inp.name}" with shape{inp.shape} {inp.dtype}')for out in outputs:LOGGER.info(f'{prefix} output "{out.name}" with shape{out.shape} {out.dtype}')
获取网络的输入和输出信息,包含了输入输出的名称、形状和数据类型。
3.2.7 动态形状配置(如果启用)
if self.args.dynamic:shape = self.im.shapeif shape[0] <= 1:LOGGER.warning(f"{prefix} WARNING ⚠️ 'dynamic=True' model requires max batch size, i.e. 'batch=16'")profile = builder.create_optimization_profile()min_shape = (1, shape[1], 32, 32) # minimum input shapemax_shape = (*shape[:2], *(int(max(1, workspace) * d) for d in shape[2:])) # max input shapefor inp in inputs:profile.set_shape(inp.name, min=min_shape, opt=shape, max=max_shape)config.add_optimization_profile(profile)
为动态输入尺寸创建优化配置文件,设置最小、最优和最大输入形状,支持在推理时使用不同尺寸的输入(关于动态输入,上篇文章已经有所解释,此处不再赘述)。
3.2.8 精度配置
if int8:config.set_flag(trt.BuilderFlag.INT8)config.set_calibration_profile(profile)config.profiling_verbosity = trt.ProfilingVerbosity.DETAILEDclass EngineCalibrator(trt.IInt8Calibrator):def __init__(self,dataset, # ultralytics.data.build.InfiniteDataLoaderbatch: int,cache: str = "",) -> None:trt.IInt8Calibrator.__init__(self)self.dataset = datasetself.data_iter = iter(dataset)self.algo = trt.CalibrationAlgoType.ENTROPY_CALIBRATION_2self.batch = batchself.cache = Path(cache)def get_algorithm(self) -> trt.CalibrationAlgoType:"""Get the calibration algorithm to use."""return self.algodef get_batch_size(self) -> int:"""Get the batch size to use for calibration."""return self.batch or 1def get_batch(self, names) -> list:"""Get the next batch to use for calibration, as a list of device memory pointers."""try:im0s = next(self.data_iter)["img"] / 255.0im0s = im0s.to("cuda") if im0s.device.type == "cpu" else im0sreturn [int(im0s.data_ptr())]except StopIteration:# Return [] or None, signal to TensorRT there is no calibration data remainingreturn Nonedef read_calibration_cache(self) -> bytes:"""Use existing cache instead of calibrating again, otherwise, implicitly return None."""if self.cache.exists() and self.cache.suffix == ".cache":return self.cache.read_bytes()def write_calibration_cache(self, cache) -> None:"""Write calibration cache to disk."""_ = self.cache.write_bytes(cache)# Load dataset w/ builder (for batching) and calibrateconfig.int8_calibrator = EngineCalibrator(dataset=self.get_int8_calibration_dataloader(prefix),batch=2 * self.args.batch, # TensorRT INT8 calibration should use 2x batch sizecache=str(self.file.with_suffix(".cache")),)elif half:config.set_flag(trt.BuilderFlag.FP16)
这里稍微有点复杂,如果我们启用了int8量化,那么就需要重写TensorRT官方库中校准器的一些方法,由于trt.IInt8Calibrator是个抽象类,很多方法需要用户在实现的时候进行自定义。所以这里出现了非常奇特的语法现象:函数中定义了一个类。这也很好地彰显了python语言灵活的特点。
这样一来就拥有了一个定制化的校准器。校准器本质上是一个精度优化工具,它通过实际数据来补偿量化过程中的信息损失,确保INT8模型在保持高性能的同时尽可能维持原始精度。
具体的配置是这样的:
dataset(数据集):如果我们没有指定数据集,系统就会给分配默认数据集(coco8)。batch:2 * self.args.batch,而self.args.batch的值默认为1(如果我们不显式地配置)在Model.export()方法中找到:
custom = {"imgsz": self.model.args["imgsz"],"batch": 1,"data": None,"device": None, # reset to avoid multi-GPU errors"verbose": False,}
cache:缓存文件,就是在导出引擎文件的时候,软件生成的cache文件。

校准缓存包含:
- 每层的量化参数(scale和zero_point)
- 校准过程中的统计信息
- 校准算法的配置参数
缓存的好处:
- 避免重复校准,节省时间
- 确保相同配置下的结果一致性
- 支持增量构建
algo(算法):trt.CalibrationAlgoType.ENTROPY_CALIBRATION_2基于KL散度最小化信息损失
🚩get_int8_calibration_dataloader这个函数负责为TensorRT INT8量化校准准备数据加载器。现在再看看这个函数是如何运行的:
def get_int8_calibration_dataloader(self, prefix=""):"""Build and return a dataloader suitable for calibration of INT8 models."""LOGGER.info(f"{prefix} collecting INT8 calibration images from 'data={self.args.data}'")data = (check_cls_dataset if self.model.task == "classify" else check_det_dataset)(self.args.data)# TensorRT INT8 calibration should use 2x batch sizebatch = self.args.batch * (2 if self.args.format == "engine" else 1)dataset = YOLODataset(data[self.args.split or "val"],data=data,task=self.model.task,imgsz=self.imgsz[0],augment=False,batch_size=batch,)n = len(dataset)if n < 300:LOGGER.warning(f"{prefix} WARNING ⚠️ >300 images recommended for INT8 calibration, found {n} images.")return build_dataloader(dataset, batch=batch, workers=0) # required for batch loading
我们是检测任务,所以dataset赋值就等价于下面的表达式:
data = check_det_dataset(self.args.data)
下面是batch大小设置,使用2倍的self.args.batch,在Model.export()方法中,将batch的值设为了1,并传入Export中,作为Export的batch参数。
custom = {"imgsz": self.model.args["imgsz"],"batch": 1,"data": None,"device": None, # reset to avoid multi-GPU errors"verbose": False,} # method defaultsargs = {**self.overrides, **custom, **kwargs, "mode": "export"} # highest priority args on the rightreturn Exporter(overrides=args, _callbacks=self.callbacks)(model=self.model)
所以这里的batch值为2。
检查数据集大小,如果少于300张图像会发出警告,因为推荐使用至少300张图像进行INT8校准以获得更好的精度。
最后返回一个数据加载器,大概包含以下信息(这个追溯的过程比较复杂,可以从BaseDataset类的__getitem__方法入手):
{'img': tensor, # 图像张量,形状为 [batch_size, 3, height, width]'cls': tensor, # 类别标签,形状为 [batch_size, num_objects]'bboxes': tensor, # 边界框坐标,形状为 [batch_size, num_objects, 4]# ... 其他可能的字段
}
这里dataset参数的函数调用关系有点乱,大概是下面这样:
get_int8_calibration_dataloader()
├── check_det_dataset() 或 check_cls_dataset() # 加载数据集配置
├── YOLODataset() # 创建数据集对象
├── build_dataloader() # 创建数据加载器
│ └── InfiniteDataLoader() # 返回数据加载器实例
└── 返回数据加载器给EngineCalibrator└── EngineCalibrator.dataset = 数据加载器└── self.data_iter = iter(数据加载器)└── get_batch()中通过next(self.data_iter)获取图像数据
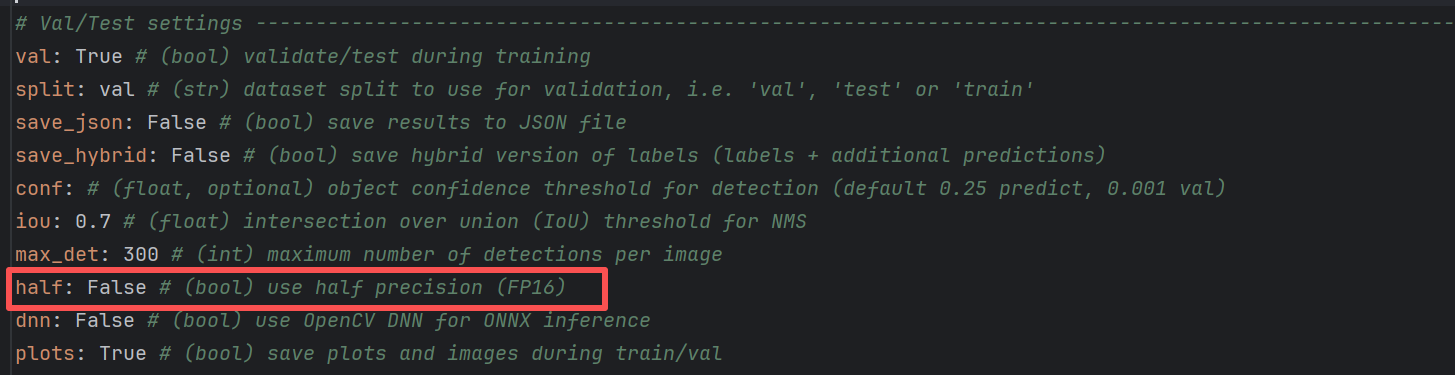
另外int8和half这两个参数是有默认值的,在上一篇文章的4.2章节中我们有提及。默认参数的传递过程大致如下:
default.yaml → DEFAULT_CFG_DICT → get_cfg() → Exporter.args → export_onnx()
打开default.yaml文件,就可以看到相关的配置。
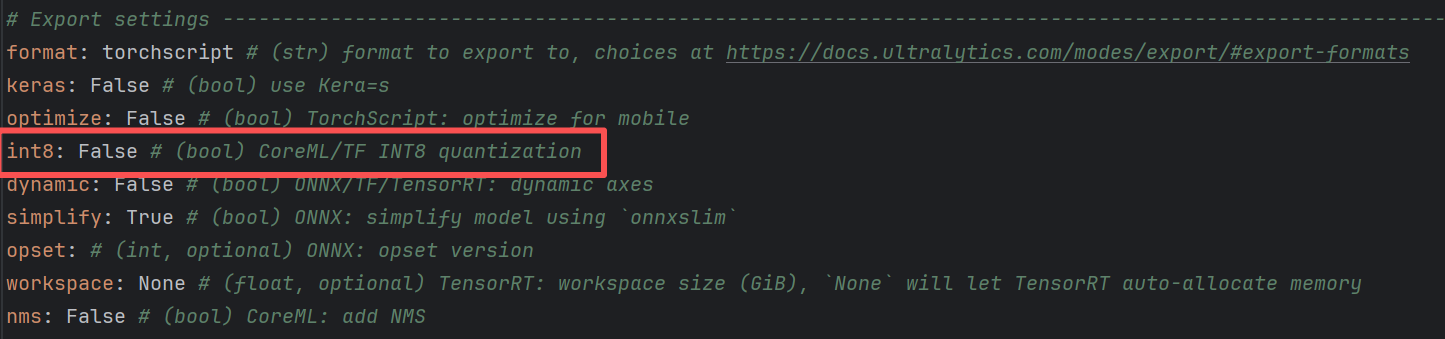
3.2.9 引擎构建和保存
# Write filebuild = builder.build_serialized_network if is_trt10 else builder.build_enginewith build(network, config) as engine, open(f, "wb") as t:# Metadatameta = json.dumps(self.metadata)t.write(len(meta).to_bytes(4, byteorder="little", signed=True))t.write(meta.encode())# Modelt.write(engine if is_trt10 else engine.serialize())
- 根据TensorRT版本选择合适的构建方法
- 构建TensorRT引擎
- 将元数据和引擎数据写入文件
在3.2.2小节我们会发现,当TensorRT的版本在≥10时is_trt10会变成True,那么为什么不同的版本会导致TensorRT引擎的构建方式有所不同呢❓
这是因为TensorRT在版本10中对API进行了重大重构,改变了引擎构建的方式:
TensorRT 7/8 (旧版本):
engine = builder.build_engine(network, config)
serialized_engine = engine.serialize() # 需要显式序列化
TensorRT 10+ (新版本):
serialized_engine = builder.build_serialized_network(network, config)
# 直接返回序列化的引擎,无需额外的.serialize()调用
所以,如果不是10+版本的TensorRT,则在代码编写的时候,稍微麻烦一些,但从效果上来说,没有什么区别,这样一来,软件就做到了对不同版本TensorRT的适配。
在上面的程序中,提及了序列化引擎的概念,那么什么是序列化引擎呢?
TensorRT引擎本质上是一个复杂的对象,包含:
1️⃣ 网络结构信息
2️⃣ 层级优化信息
3️⃣ 内存布局
4️⃣ 硬件特定的优化配置
序列化就是将这些信息打包成连续的字节数据,在推理的时候,直接加载引擎文件,反序列化即可。
举个例子
如果不序列化,每次启动应用都要:
- 解析ONNX文件(5秒)
- 优化网络结构(60秒)
- 内存布局规划(30秒)
总计:约1.5-2分钟纯开销!😧
使用序列化引擎:
- ✨加载序列化数据(0.5秒)
- ✨反序列化(0.5秒)
总计:1秒开销!😊
这就好比我们传统的嵌入式开发中,每次软件更新,会先经历耗时的编译过程,编译完生成一个hex文件,将其烧录进MCU中,然后每次MCU运行软件的时候,无需本地编译就可以直接运行。
💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗💗
4 总结
本文梳理了TensorRT 引擎文件导出的基本过程。关于DLA单元的基本工作原理,以及量化操作的更多细节等内容,敬请关注后续更新!!!