(CVPR 2025 最佳论文)【源码复现】VGGT: Visual Geometry Grounded Transformer”
核心思想:
提出一个feed-forward transformer-based 模型,在单幅 / 多幅 / 大量视角输入下一次前向推断出摄像机参数、深度图、点图(point maps)与3D 点跟踪等一整套 3D 属性,并在多个3D任务上取得极好效果——且多次在论文/项目页中声明比依赖后处理的传统视觉几何 pipeline 更快、更简单。

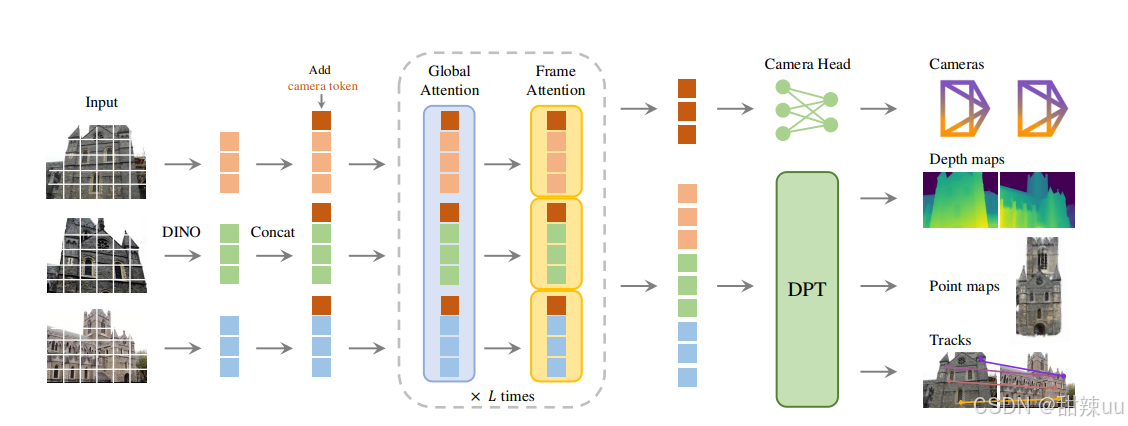
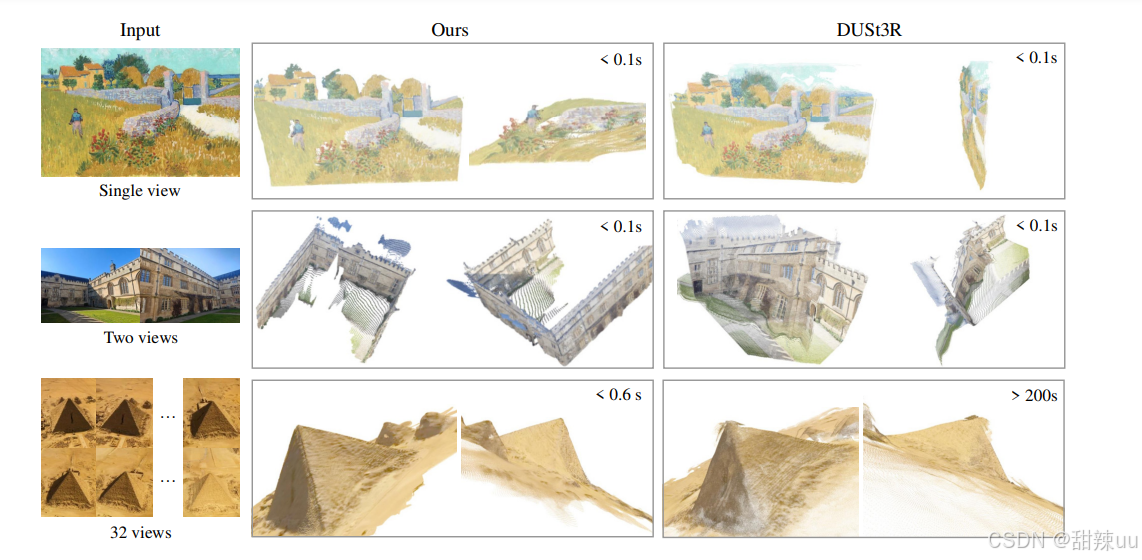

提出一个feed-forward transformer-based 模型,在单幅 / 多幅 / 大量视角输入下一次前向推断出摄像机参数、深度图、点图(point maps)与3D 点跟踪等一整套 3D 属性,并在多个3D任务上取得极好效果——且多次在论文/项目页中声明比依赖后处理的传统视觉几何 pipeline 更快、更简单。