00_k8s容器编排系统
00_k8s容器编排系统
k8s是谷歌几十年来研发的一套系统,更新了运维领域的玩法
内容很多,先快速练习玩法,知道什么就行
具体为什么在花时间慢慢的学习
0.参考官方资料
1. k8s能干什么
https://kubernetes.io/zh-cn/docs/concepts/overview/#why-you-need-kubernetes-and-what-can-it-do2.docker资料
https://docs.docker.com/get-started/3.kubeadm创建k8s集群
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/4.prometheus资料
https://prometheus.io/docs/introduction/overview/5.ansible安装k8s工具,阅读优秀剧本,也可以快速理解k8s架构,如何部署
https://github.com/easzlab/kubeasz6.阿里云k8s资料(生产最佳推荐)
https://www.aliyun.com/product/kubernetes7.查询k8s多版本的API黑科技
https://k8s.mybatis.io/v1.19/8.自动生成yaml黑科技
https://k8syaml.com/
1.k8s软件介绍
纯容器部署问题
纯docker 的运行模式,是一个docker主机,单独管理一堆容器应用,但是发现数量多了以后,配置复杂之后,难以维护管理多个容器,并且夸节点的容器集群,更是维护复杂。
- 业务容器数量庞大,那些容器部署在那些节点,使用哪些端口,如何记录,管理,需要登录到每台机器去管理?
- 跨主机通信,多个机器的容器之间相互调用如何做到,iptables规则手动维护?
- 跨主机容器之间相互调用,配置如何写,固定ip+端口?
- 如何实现业务高可用,多个容器对外提供服务如何实现负载均衡?
- 容器业务中断,如何可以感知到,如何重新启动新的容器?
- 如何实现滚动升级保证业务的连续性?
k8s是什么
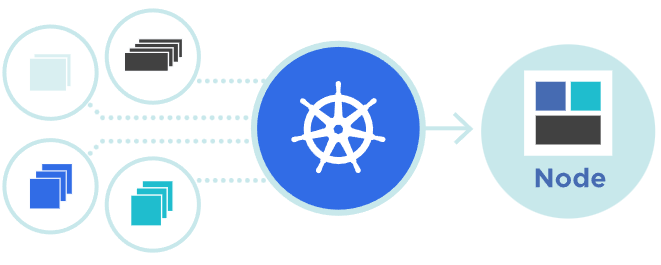
kubernetes称为k8s,适用于自动部署,扩缩和管理容器化应用程序的开源系统
它将组成应用程序的容器组合成逻辑单元,以便于管理和服务发现
kubernetes源自Google 15 年生产环境的运维经验,同时凝聚了社区的最佳创意和实践。
Google 每周运行数十亿个容器,Kubernetes 基于与之相同的原则来设计,能够在不扩张运维团队的情况下进行规模扩展。
从官方资料来看,就已经解决了上述提及的纯容器化管理的问题。

架构演进历史,为何出现k8s技术
官方资料
https://kubernetes.io/zh-cn/docs/concepts/overview/
总结就是
- 传统物理机部署,资源利用率低,难以迁移
- 升级虚拟化时代,基于vm技术实现资源隔离,是一个完整的os
- 升级容器时代,容器共享宿主机os,有自己的名称空间,有诸多特性
容器因具有许多优势变得流行起来,例如
- 敏捷应用程序的创建和部署,相比使用vm镜像相比提高了容器镜像创建的简便性和高效率
- 持续开发,集成和部署,通过快速简单的回滚(由于镜像不可变性)提供可靠且平凡的容器镜像构建和部署。
- 关注开发和运维的分离,在构建,部署时创建应用程序容器镜像,而不是在部署时,从而将应用程序与基础架构分离。
- 可观察性,不仅仅可以显示os级别的信息和指标,还可以在显示应用程序的运行状态和其他指标信号
- 夸开发,测试,和生产环境的一致性;在笔记本计算机上也可以和在云中运行一样的应用程序
- 跨云和操作系统发型发行版本的可移植性,可以在Ubuntu,coreos,本地和其他任何地方运行。
- 以应用程序为中心管理,提高抽象级别,在虚拟硬件上运行os到使用逻辑资源os上运行应用程序。
- 松散耦合性,分布式,弹性,解放的微服务,应用程序分解成较小的独立部分,并且可以动态部署和管理,而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序心性能
- 资源利用率:高效率和高密度
为什么出现k8s
容器是打包和运行应用程序的好方式
在生产环境中,你需要管理运行应用程序容器,并确保容器不会下线
例如,一个容器发生故障,则需要启动另一个容器
如果在这个过程中,是自动创建容器,自动生成新的容器,保证业务的高可用性
k8s就是实现容器自动化管理的一个框架系统。
k8s是一个平台框架
- k8s提供很多功能,简化了对容器的部署管理
- 基于容器对应用发布管理,更新,升级,降级
- 负载均衡,服务发信
- 跨主机,跨地区的的网络模式
- 自动扩缩容功能
- 支持丰富的插件
- k8s并不是很6,他本身只有自己的一些组件,额其他功能,如消息队列,数据库,存储等都需要额外安装在k8s上。
2.k8s核心架构组件
如何设计一个容器管理平台
- 集群架构,管理节点分发到容器到数据节点
- 如何部署业务容器到各数据节点
- N个数据节点,业务容器如何选择部署在最合理的节点
- 容器如何实现多副本,如何满足每一个机器部署一个容器模型
- 多副本如何实现集群内负载均衡
分布式系统,两类角色;管理节点和工作节点
架构分布系统,k8s分为2个节点master 控制节点,老板
node 工作节点,工人
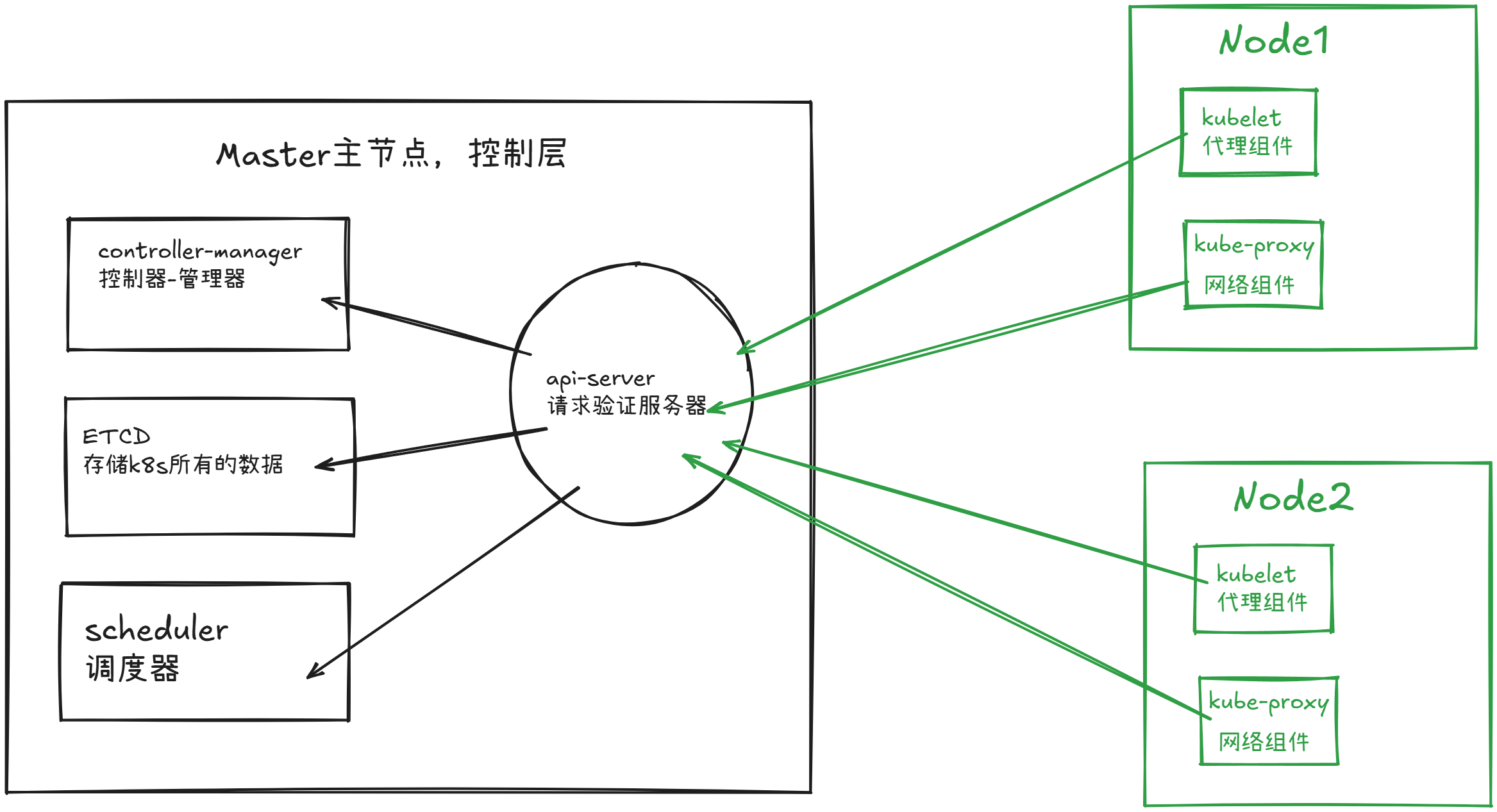
核心组件
kubernetes主要有以下几个核心组件组成:
-
etcd保存了整个集群的状态,分布式高新能数据库
-
api-server提供了资源操作的唯一入口,并提供认证,授权,访问控制,api注册和发现等机制;
-
controller manager复杂维护集群的状态,比如故障检测,自动扩展,滚动更新等
- Replication Container
- Node Controller
- ResourceQuota Controller
- Namespace Controller
- ServiceAccount Controller
- Token Controller
- Service Controller
- Endpoints Controller
-
scheduler 复杂资源的调度,安装预定的策略将pod调度到相对应的node节点上
-
kubelet负责维护容器的生命周期,同时也负责volume和网络 cni的管理
- 运行在每一个node节点上的代理软件,脏活累活都是它干;
- pod管理:
- kubelet定期从所监听的数据源节点上pod/container的期望状态(运行什么容器,运行副本的数量,网络或者存储如何跑配置等等),并且调用对应的容器平台接口达到这个状态
- 容器健康检查
- kubelet创建容器之后会检查容器是否正常运行,如果容器出现了错误停止运行,就会根据pod设置的重启策略进行处理
- 容器监控
- kubelet会监控所在节点的资源使用情况,并且定时向master报告,资源数据都是通过cadvisor获取的,知道整个集群所有节点的资源使用情况,对于pod的调度和正常运行很关键。
-
Container runtime 负责镜像管理以及pod和容器的正常运行
-
Kube-proxy负责service提供cluster内部服务发现和负载均衡,主要提供iptables,的规则
-
kubectl:
- 命令行接口,用于对kubernetes集群运行命令
https://kubernetes.io/zh/docs/reference/kubectl/
组件架构图
- k8s集群是被一组node节点机器组成,这些节点上运行k8s管理的容器进程
- node节点机器上运行的容器被一个叫做Pod的组件管理
- 在安装完k8s之后,就能得到一个集群环境
- 集群是指一堆的node节点机器,这些节点机器运行pod,也就是容器
更多详细组件通信流程
在这里插入图片描述
k8s集群端口信息
Master
master nodes
| Protocol | Direction | Port Range | Purpose |
|---|---|---|---|
| TCP | Inbound | 6443* | Kubernetes API server |
| TCP | Inbound | 8080 | Kubernetes API insecure server |
| TCP | Inbound | 2379-2380 | etcd server client API |
| TCP | Inbound | 10250 | Kubelet API |
| TCP | Inbound | 10251 | kube-scheduler healthz |
| TCP | Inbound | 10252 | kube-controller-manager healthz |
| TCP | Inbound | 10253 | cloud-controller-manager healthz |
| TCP | Inbound | 10255 | Read-only Kubelet API |
| TCP | Inbound | 10256 | kube-proxy healthz |
node
Worker node(s)
| Protocol | Direction | Port Range | Purpose |
|---|---|---|---|
| TCP | Inbound | 4194 | Kubelet cAdvisor |
| TCP | Inbound | 10248 | Kubelet healthz |
| TCP | Inbound | 10249 | kube-proxy metrics |
| TCP | Inbound | 10250 | Kubelet API |
| TCP | Inbound | 10255 | Read-only Kubelet API |
| TCP | Inbound | 10256 | kube-proxy healthz |
| TCP | Inbound | 30000-32767 | NodePort Services** |
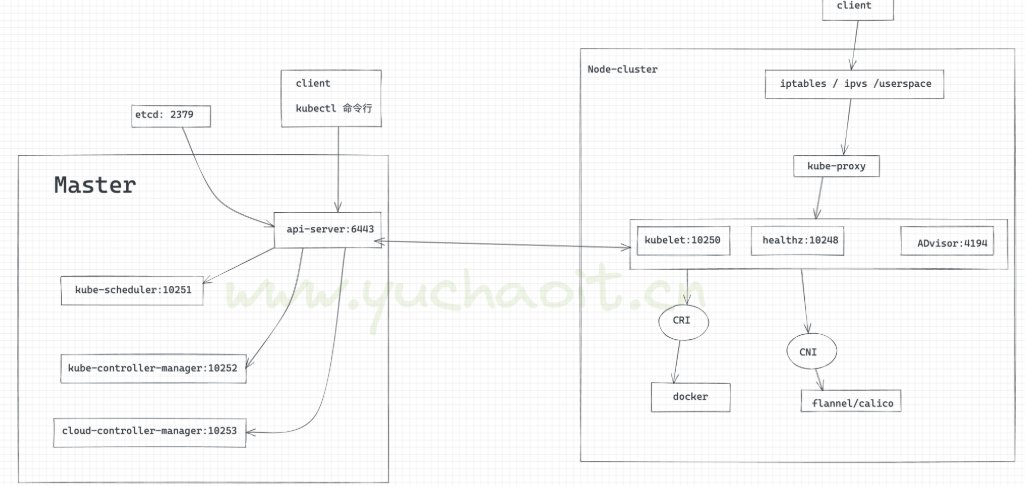
组件通信流程
kubernetes主要有以下几个核心组件组成
- etcd保持整个集群的状态
- aip Server 提供了资源操作的唯一入口,并提供认证,授权,访问控制,api注册和发现等机制
- Controller Manger负责维护集群的状态,自动扩展,滚动更新
- scheduler负责资源的调度,安装预定的调度策略将pod调度到相对应的机器上
- kubelet负责维护容器的生命周期,同时也负责volume和网络的管理
- Container Runtime负责镜像管理以及Pod和容器的真正运行(CRI)
- Kube-proxy负责为Service提供cluster内部服务发现和负载均衡
3.master节点组件
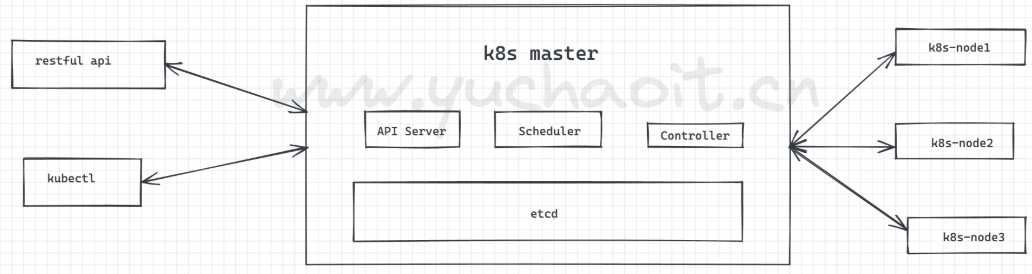
api-server
- 提供k8s api接口处理所有的rest操作,接收允许的请求,以及更新etcd中的对象
- 是增删改查的唯一入口
- 对请求进行认证,授权检查
scheduler
- 资源的调度
- 根据etcd里写入资源的状态,决定pod绑定到哪个node
controller manager
控制器,管理器
- 负责保障node的健康状态
- 资源对象的控制中心,k8s中有很多控制器
https://pkg.go.dev/k8s.io/kubernetes/pkg/controller$ cd kubernetes/pkg/controller/
$ ls -d */
deployment/ job/ podautoscaler/
cloud/ disruption/ namespace/
replicaset/ serviceaccount/ volume/
cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/
...
etcd
k8s使用数据库,持久化所有的资源写在etcd
kebectl
kubectl 是管理k8s集群的客户端工具
运行通过kubectl命令和api-server交互,获得反馈,从而实现对k8s集群的管理
4.node节点的组成
node节点主要是kubelet和api-server通信,pod管理,也就是docer管理
以及kube-proxy实现网络代理功能
k8s重要资源(学会k8s就靠这个)
node
这个不属于k8s资源,属于重要概念
Node是pod真正运行的主机,可以是虚拟机,也可以物理机
为了管理pod每一个Node节点上就要运行Container runtime 比如docker,kubelet,kube-proxy服务
Container
这个不属于k8s部署,属于重要概念
Container 容器是一种便携式,轻量级的操作系统虚拟化技术
它使用的是namespace隔离不同的软件运行环境,并且通过镜像自包含软件的运行环境,从而使得容器可以很方便的在任何地方运行。
由于容器体积小启动快,因此可以在每一个容器镜像中打包一个应用程序,对于一对一的应用镜像关系有很多好处,使用容器,不需要与外部的基础架构环境绑定,每一个应用程序都不需要外部依赖,更不需要与外部的基础架构环境依赖,完美解决了从开发到生产环境的一致性问题。
容器同样比虚拟机更加通明,这有助于检测和管理。尤其是容器进程生命周期基础设施管理,而不是被进程管理器隐藏在容器内部,最后每一个应用程序容器封装,管理容器部署等同于管理应用程序部署。
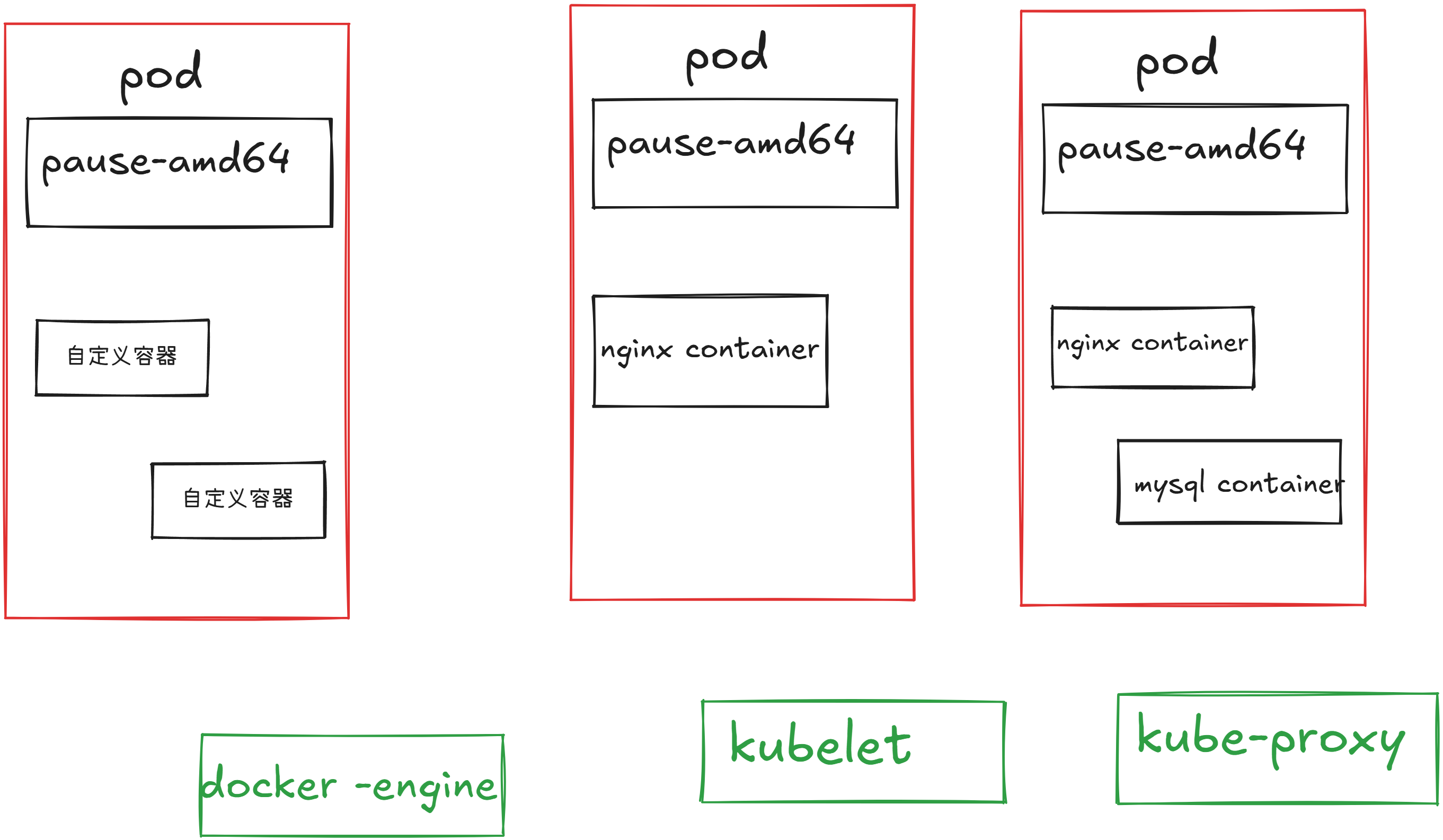
1.pod
- kubernetes使用pod来管理容器,每一个pod可以包含一个或者多个精密相关的容器。
- pod是一组紧密相关的容器集合,他们共享进程间通信和Network namespaces是kubernetes调度的基本单位
- pod内的多个容器共享网络和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务
- pod的设计理念是支持多个容器在一个pod中共享网络地址和系统文件,可以通过进程通信和文件共享
- pod是k8s集群所有业务的基础,可以看为k8s集群中的小机器人
- 小机器人分别是Deployment,Job,DaemonSet,statefulSet
- pod在k8s集群中运行部署应用或服务的最小单元,他可以支持多容器
- pod的ip是随机变化的,删除pod,ip变化
- pod内都有一个根容器
- 一个pod内可以有一个,或者多个容器
- 一个pod内的所有容器,共享根容器的网络名称空间,文件系统,进程资源
- 一个pod内网络地址,由根容器提供

创建pod请求走向
kubernetes多组件之间的通信原理
- api Server负责etcd存储的所有操作系统,只有api-server直接操作etcd
- api-server内对外提供统一的rest api 其他组件均通过 api-server进行通信
- Controller manager ,scheduler , kube-proxy,和kubelet等通过检测资源变化等情况,并对资源做相对应的操作

- 怎么说
1. 运维执行创建pod的请求(一个yaml文件、记录了业务应用的名字,镜像,如何部署等信息),提交给api-server
2.api-server接收请求后将资源清单的信息写入etcd
3.etcd存好信息后反馈api-server
4.api-server告知scheduler事件信息,schduler发现有一个新pod但是没绑定node,通过资源清单信息以及算法选择合适的node进行和pod绑定
5.将要pod和node绑定的信息告诉api-server
6.api-server将调度结果写入etcd
7.etcd更新好pod信息后继续反馈api-server
8.此时kubelet组件(目标node)watch到有一个新pod被分配过来了,获取pod信息,根据pod描述内容创建对应容器
9.kubelet反馈pod创建结果(docker信息)给api-server,且写入etcd
10.最终结束一个pod的完整创建流程。
2.Label(爱问的点)
Label是识别kubernetes对象标签,可以key/value的方式附加到对象上。
Label不提供唯一性,并且实际上经常是很多对象如(pods)都是用相同的label来标志具体的应用。
Label 定义好后其他对象可以使用 Label Selector 来选择一组相同 label 的对象(比如 ReplicaSet 和 Service 用 label 来选择一组 Pod)。Label Selector 支持以下几种方式:
1. label就像身份证标签一样,用于标识k8s的对象。
2. 我们传统的对机器上应用查找,都是基于ip:port,但是在k8s里,更多匹配关系,都是通过label来查找。
3.Namespace
k8s里可以基于namespace管理不同环境下的资源,也是一个重要资源,形成一个项目组。
Namespace 是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。常见的 pods, services, replication controllers 和 deployments 等都是属于某一个 namespace 的(默认是 default)而 node, persistentVolumes 等则不属于任何 namespace。
4. controller
k8s控制器种类很多,用来不通的场景,如何更好的管理pod
1. 上面于超老师也说了,POD可以理解为k8s里面的干活的小机器人,不同的类型都要用不同的机器人去执行。2. 控制这些小机器人的控制器,就主要分为
Replication Controller
- 也叫RC控制器,副本控制器、控制pod的副本数
- RC是K8s集群中最早的保证Pod高可用的API对象。
- 通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。
- 指定的数目可以是多个也可以是1个;
- 当少于指定数目,RC就会启动运行新的Pod副本;
- 多于指定数目,RC就会杀死多余的Pod副本。
- 严格根据你定义的数量,确保POD数量
即使在指定数目为1的情况下,通过RC运行Pod也比直接运行Pod更明智,因为RC也可以发挥它高可用的能力,保证永远有1个Pod在运行。(pod挂了,容器就挂了,机器人也就挂了,有控制在,就不怕应用挂了)
RC是K8s较早期的技术概念,比如控制小机器人提供高可用的Web服务,启动如3个pod副本,也就是3套应用后端。
Replica Set,RS
RS是RC控制器的下一代,也提供副本数,确保pod(容器的高可用)。
RS控制器一般不会直接用,而是结合另一种控制器(Deployment)以及更多参数使用。
Deployment
部署控制器、主要用k8s部署应用就是靠这个。
Deployment表示用户对K8s集群的一次更新操作。
部署是一个比RS应用模式更广的API对象,可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。
滚动升级一个服务,实际是创建一个新的RS,然后逐渐将新RS中副本数增加到理想状态,将旧RS中的副本数减小到0的复合操作;
这样一个复合操作用一个RS是不太好描述的,所以用一个更通用的Deployment来描述。
以K8s的发展方向,未来对所有长期服务型的的业务的管理,都会通过Deployment来管理。
(LNMP就是典型代表,需要高可用、负载均衡的应用集群,积极更新多个后端、这些所有的)
长期服务型的应用特点在于业务应用提供访问,有的Node上可能有改pod、有的Node可以没有;
DaemonSet
- 后台支撑服务集控制器的功能在于关注k8s中的Node(物理机、虚拟机)
- 能保证每个节点上都有一个此类的Pod在运行
- 这种特性,就很实用用于部署如监控软件的agent,采集每一个目标Node的资源数据。
- 节点可以所有集群中的机器,也可能是基于NodeSelector选定的部分节点。
- DaemonSet主要用于
- 日志采集
- 监控采集
- 存储
- 这几类服务的运行
SeatefulSet
有状态服务集在k8s1.3版本后发布,之前于超老师说过,nginx此类的应用一般是无状态的,可以随意创建,删除;
还有一种就是有状态(stateful)的应用、
RC、RS、deployment主要提供无状态服务的部署,其pod的名字也都是随机生成的,一个pod挂了随意重建一个就好,pod的名字、在哪个node启动都无所谓,只要保证pod总数即可。而stateful用来控制有状态服务,每一个pod的名字是预先定义好的,不能更改;
无状态的pod一般不会挂载存储、保证pod共享状态即可,可以随意创建,删除;
有状态的pod,pod都会单独挂在一个存储,如果pod出了问题,其他节点要重新创建pod,并且获取原有pod的存储信息,继续提供有状态服务。这个特性明显就是提供给数据库使用。
5.Service
上述讲的pod控制器,是实现了pod、容器被创建在目标Node机器,以及确保了数量、副本数;
但是目前还没说,这些pod改如何访问?分散在不同的机器,通过什么ip去访问?
一个pod是一个运行服务的实例,随时可能在某一个Node上运行,另一个Node上以一个新pod启动的话,IP又变化了。
因此没法确定ip、port去访问具体的pod。
因此Service组件就诞生了,为了解决服务发现、负载均衡的能力。
服务发现就是指针对客户端的访问请求,找到对应后端的pod实例。
在k8s里,客户端访问的服务入口就是service组件、Service定义了集群内部的一个虚拟ip作为入口,用来将后端的pod服务暴露给集群外的用户访问。
问题是,pod会随时随地被销毁,创建,ip也不固定,Service又是如何找到Pod?因此k8s为了解决这个问题,在Pod_IP之外创建了一个ClusterIP,这个IP创建后就不再变化了,除非主动被删除重建。因此我们会创建ClusterIP类型的Service资源,然后通过label标签和具体的pod绑定关系,因此实现了集群内pod的负载均衡,ClusterIP的请求被转发给了后端的pod。
问题又来了、ClusterIP可以让我们访问到后端的pod、但是ClusterIP也还是k8s集群内的虚拟IP,只能在集群内部的机器访问。
集群外的用户如何访问?
如运维小于只能通过浏览器去访问k8s所在机器的物理网卡提供的真实IP:PORT去访问。
因此最终k8s提供了一种叫做NodePort的方式,实现了端口映射
https://kubernetes.io/zh-cn/docs/concepts/services-networking/connect-applications-service/
小结pod id ,pod的ip
clusterip ,service提供集群内负载均衡访问pod的ip
nodeport、可以在集群外访问到集群内资源。