nlp第七节——文本匹配任务
一、智能问答
1.对用户问题进行预处理
2.使用处理后的问题,与faq库中问题计算相似度(faq库即知识库,是很多问答对组成的集合)
3.按照相似度分值排序
4.返回最相似问题对应的答案
其中语义相似度计算是faq问答的核心
二、语义相似度计算
编辑距离:
两个字符串之间,由一个转成另一个所需的最少编辑操作次数。编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。(动态规划)
优点是可解释性强,不需要训练模型。
缺点是受无关词影响,没有考虑语序和语义,如您好和你好,不好和你好,虽然前者语义相似度更高,但是编辑距离与后者相同。
jaccard相似度:
根据两个集合中,不同元素所占的比例,来衡量两个样本之间的相似度
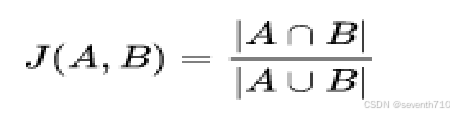
优点是语序不影响分数,不需要训练模型,缺点是没有考虑字词之间的相似度,而且非一致文本可能出现满分。
BM25算法:
通过TF、IDF值刻画语义相似度:TF值等于某个词在某类别中出现的次数/该类别词总数,IDF值等于总类别数/该词出现的总类别数加一(平滑)
优点是弱化了无关词的影响,统计模型快,缺点是仍然没有考虑字词间的语义相似度,对于新增类别,需要重新计算模型。
word2vec:
将训练出的词向量拼接成句向量然后过池化层,形成句向量的信息,然后计算两个句向量的夹角余弦值。优点是考虑了字词间的相似度,且可对知识库内问题优先计算句向量,缺点是可能存在一词多义的情况,且词向量不能完全概括句向量的信息。
深度学习:
表示型文本匹配:
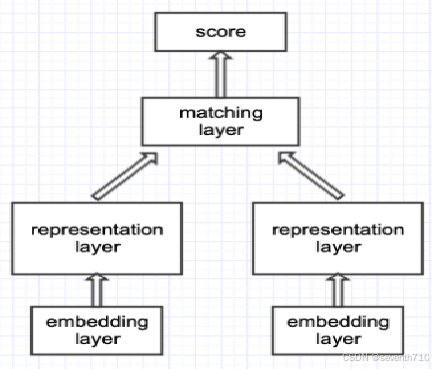
本质是先用encoder将文本转化成向量,然后用余弦距离、欧式距离、MLP层等计算两句话的语义相似度,在反向传播的过程中,优化的参数主要是encoder部分的参数(如bert),这里将模型训练完成后,调用模型时,两句话共享模型内的所有参数(所以这里本质上训练的是文本表示的方法,多一个类别不需要重新训练模型,而如果用文本分类的方法进行文本匹配的话,多一个类别的时候至少要重新训练最后一层linear层的参数)。
交互型文本匹配:
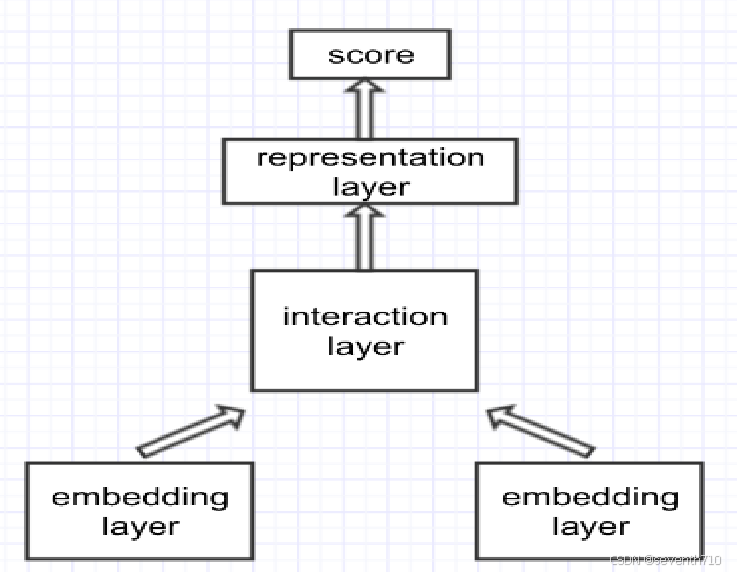
本质上先用共享的embedding层给两句话编码,然后共同进入交互层,以attention(类似于bert的第二种编码方式)的方式进行再编码,然后再计算语义相似度。
表示型vs交互型:
表示型文本匹配训练好i的模型可以直接对文本进行向量化,但是在训练中不找到文本的重点;相反,交互型文本匹配每输入一段文本,就要与每个类别都进行交互,耗时太长,优点是可以掌握文本重点**(比如今天下雨了 vs 今天下雪了 重点是下雨和下雪,今天下雨了 vs 明天下雨了 重点是今天和明天)**