【论文阅读】DSPy-based neural-symbolic pipeline to enhance spatial reasoning in LLMs
论文题目:DSPy-based neural-symbolic pipeline to enhance spatial reasoning in LLMs
来源:Neural Networks 2025
话题:大语言模型;神经符号集成(Neural-symbolic integration);回答集编程(Answer Set Programming)
作者:

论文链接:https://www.sciencedirect.com/science/article/pii/S0893608025009025
源码:https://github.com/rong4ivy/DSPy_Based_Neural-Symbolic-Intergration
摘要
空间推理对大语言模型(LLMs)至关重要,但仍是一个长期存在的挑战。现有的神经符号方法只能提供部分解决方案,且存在设计不灵活、效果有限的问题。我们提出了一种神经符号框架,通过迭代反馈回路将LLMs与回答集编程(ASP)集成,使生成的逻辑程序能够精确可靠地精炼。该框架在两个基准数据集、多项推理任务和多个LLM上进行了评估,我们基于DSPy的管道达到了82–93%和71–80%的准确率,分别比直接提示、思维链以及一种两阶段“事实+规则”方法高出43%和25%。我们提出的轻量级“事实+规则”替代方案也在降低计算开销的同时,将基线性能提高了9–27%。推动这些提升的关键创新包括:(1)语义解析与逻辑推理的模块化分离;(2)LLM与ASP求解器之间基于迭代错误处理的反馈;(3)面向领域的高效符号表示。该系统具有强可解释性和泛化能力,可应用于多样且复杂的任务。此外,我们提出的系统能够显著推进具备类人、多组件推理能力的AI架构,助力通用人工智能的发展。
一、引言
空间推理是智能系统的核心能力之一,广泛应用于机器人导航、任务规划和环境理解等领域。它既包含对距离、角度、坐标等精确信息的定量推理,也涉及对方位(如“左边”“北方”)、拓扑(如“内部”“分离”)和邻近关系(如“附近”“远离”)等符号关系的定性推理。尽管大语言模型(LLMs)在常识推理任务中表现亮眼,但其训练目标仅为“预测下一个词”,缺乏对空间、物理和具身推理的足够“落地”能力。研究表明,即使是ChatGPT这类模型,在演绎逻辑、空间推理和非文本语义推理上仍显吃力,稍有扰动就会性能骤降。尤其在文本或视觉场景中理解真实世界布局时,LLMs存在明显“盲点”。早期改进工作主要围绕“提示工程”展开,如思维链(CoT)、由简到繁提示、自洽性、思维树、思维可视化等,试图把推理拆成透明步骤。然而,纯提示法难以保证严格逻辑一致性,一旦涉及多步规划、动态目标跟踪或细微语言消歧,模型就容易“跑题”、幻觉中间事实,导致结果不可靠。为此,学界转向神经符号AI——把神经网络的学习灵活性与符号系统的逻辑严谨性结合起来,被视为AI“第三波”。典型做法是让LLM把自然语言查询解析成形式逻辑,再由外部求解器执行。然而,现有神经符号方法普遍存在三大痛点:
- 跨领域泛化差,多步推理易掉链子;
- 神经与符号模块耦合松散,信息传递脆弱,错误级联;
- 几乎没有“迭代反馈”机制,无法让多智能体协同精炼输出。
针对这些痛点,我们提出一套全新的神经符号框架:用DSPy声明式框架把LLM与Answer Set Programming(ASP)搭成“迭代反馈回路”,在文本空间推理任务上验证。选择纯文本场景,可以先把符号推理难题独立出来,避免视觉感知带来的额外复杂度。实验在两个基准SpartQA与StepGame上进行,覆盖从简单网格到复杂自然语言描述的多种推理深度与语言结构。
我们的pipeline把“自然语言→ASP事实与规则→求解→答案”全过程拆成可复用、可优化的DSPy模块,通过solver返回的语法/语义错误信息,让LLM反复修正逻辑程序,直到可执行且结果可信。相比直接提示、思维链和轻量级“事实+规则”基线,该方法在StepGame上最高提升43%,在SpartQA上提升25%;轻量版“事实+规则”也能在降低计算开销的前提下提升9–27%。本文的贡献如下:
- 首次实证验证“LLM+ASP+迭代反馈”能显著提升LLM空间推理准确率,并在两大基准上刷新成绩。
- 系统梳理了ASP与空间推理结合的可复用知识模块,为后续神经符号设计提供蓝图。
- 提出模块化、可扩展的DSPy架构,实现LLM与符号求解器之间的可解释、可优化多阶段协同。
- 全面展示了DSPy在不同模型与推理深度下的泛化性与实用性,为复杂推理任务提供了一条自动化、低门槛的神经符号落地路径。
二、相关工作
2.1 神经符号集成
神经符号AI的理论基础来自认知“双过程”模型:系统1快速、直觉、联想;系统2缓慢、审慎、基于规则(Evans, 2003; Kahneman, 2011)。神经网络类似系统1,符号推理系统类似系统2 (Frankish, 2010; Sun, 2015)。集成目标就是把神经网络的学习灵活性与符号框架的精确可解释性结合起来,缓解LLM“流利但逻辑不一致”的顽疾(d’Avila Garcez et al., 2020; Nye et al., 2021; Zhang et al., 2023)。已有研究给出多种分类法:
- Ishay et al. (2024)与Šíř (2025)把集成划分为组合层(可复用模块)、功能层(组件互调)、嵌入层(符号约束写进网络损失)。
- Wan et al. (2024)进一步细分为Symbolic[Neural](符号为主,神经增强)、Neural|Symbolic(流水线互补)、以及把逻辑规则当软约束加入损失函数的方法。
- Gibaut et al. (2023)从架构实现角度总结为:顺序管道、带反馈的迭代架构、以及把符号约束直接嵌入计算图的嵌入式方法。
随着LLM兴起,其作为“语义解析器”的潜力被重新关注:先用LLM把自然语言转为逻辑形式,再交给外部求解器执行(Alyasiri et al., 2024; Parisi et al., 2022; Riegel et al., 2020; Weber et al., 2019; Yang et al., 2023a)。为此,研究者提出LLASP等微调方法,让模型专门生成ASP程序模式(Coppolillo et al., 2024)。然而,LLM并非原生接受形式语言训练,生成的程序常出现语法或语义错误,解析成功率在复杂数据集上可低至17% (Feng et al., 2024; Ishay et al., 2023)。尽管自精炼模块(Li et al., 2023; Pan et al., 2023)能部分修正,但精度提升有限,凸显出“神经↔符号”高效反馈回路的迫切需求。
2.2 回答集编程(ASP)
神经符号系统虽然把“感知”与“推理”解耦,但仍需一条表达力强、鲁棒的符号脊梁。ASP凭借形式严谨、基于模型的语义以及对非单调推理的原生支持,成为神经符号场景下的优选语言(Brewka et al., 2011)。ASP是一种声明式编程范式:开发者只需描述“问题是什么、解应满足哪些性质”,求解过程交由底层求解器完成。与Prolog的“自上而下、目标驱动”不同,ASP采用“自下而上、模型论”方法,计算出所有满足规则与约束的稳定模型(回答集)。ASP的表达能力建立在四大构件之上:
事实(Facts):形式为p(t1,…,tn)的基本无条件语句,其中p是谓词,t1,…,tn是项。 规则(Rules):Head:- Body的推理陈述,其中Head是一个原子,Body由字面的连接组成。规则使新信息能够从已知的事实中逻辑地推断出来。 约束(Constraints):带有空heads的特殊规则,写为“:- Body”,通过强制执行逻辑限制过滤掉无效的答案集。 查询(Queries):目标导向的结构,从知识库中检索特定信息,通常通过指定的谓词(其扩展表示答案)表示。 |
ASP擅长处理缺省假设、信息不完整、开放世界等非单调任务,并已用于调度、诊断、资源分配等NP-hard问题(Erdem et al., 2016; Gamblin et al., 2022; Ricca et al., 2010)。为了处理不确定性,NeurASP (Yang et al., 2020)把神经网络输出解释为ASP原子的概率分布;HPASP(Azzolini & Riguzzi, 2024)进一步引入可信语义,支持离散与连续随机变量。
语法层面,ASP区分大小写:变量首字母大写,常量/谓词/原子小写;_表示匿名变量;运算符:-、,、|、not、~分别对应蕴含、合取、析取、默认否定与经典否定;域限制用:标记。相比一阶逻辑,ASP独有选择规则、基数约束与聚合运算(#count、#sum、#min、#max),极大增强了组合建模能力。
在空间推理场景,ASP通过block/1、object/5、is/3、location/3等基础谓词,可对静态与动态空间关系进行精确编码,并借助逆对称、传递闭包等规则实现多跳链式推理(Cohn & Renz, 2008; Mitra et al., 2019)。
三、方法
我们提出一条基于DSPy的“神经-符号”流水线,把大语言模型(LLM)与回答集编程(ASP)求解器通过“生成-报错-修正”迭代回路紧密结合。图1给出整体四阶段架构:Convert → Refine → SymbolicReasoning → Evaluate;其中Refine与SymbolicReasoning形成最多三轮的反馈循环。以下按模块详述。
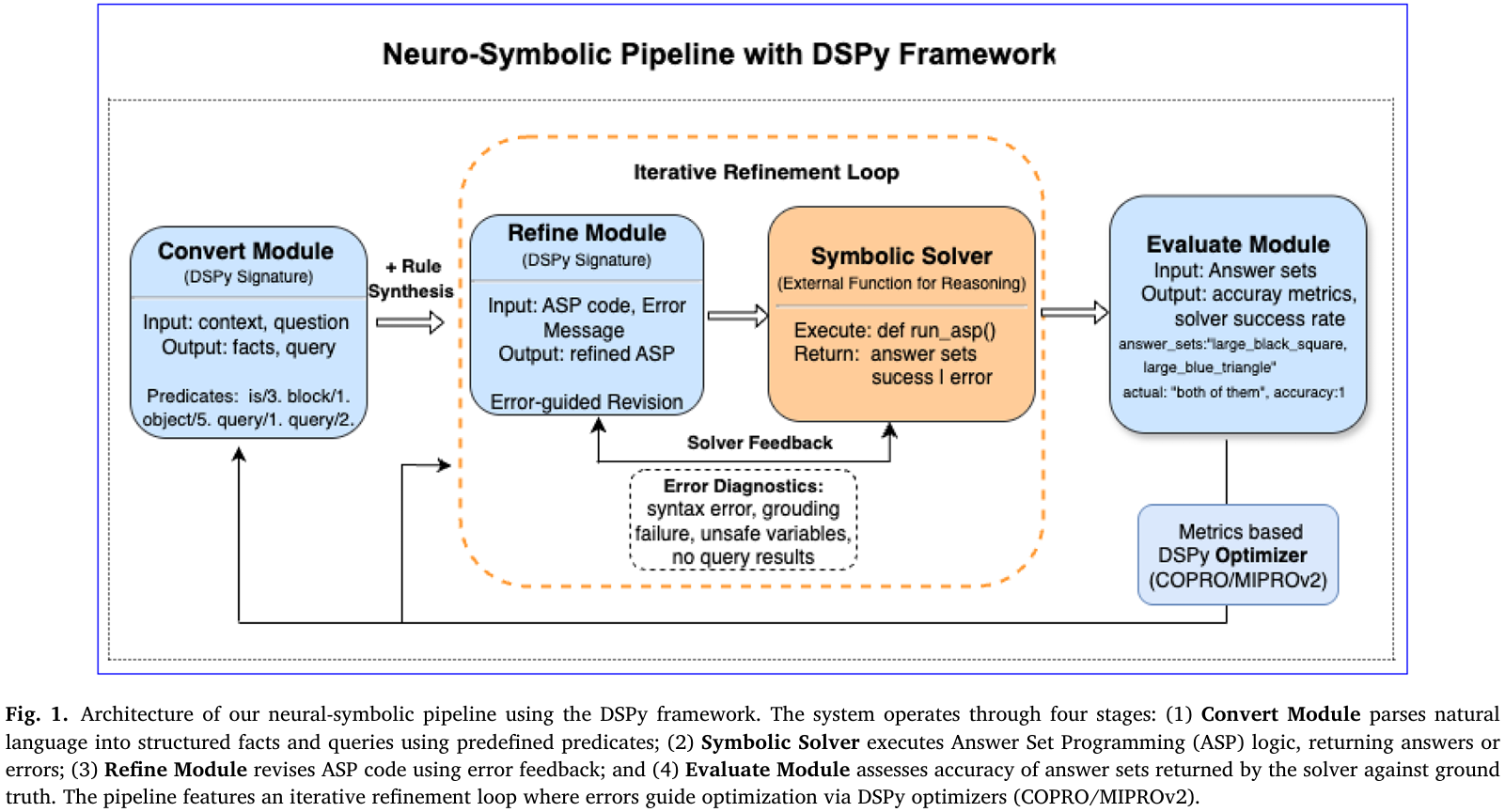
3.1 基准数据集
- StepGame:合成网格数据集,定义9种空间关系(8方向+重叠),含1–10跳共10子集,每子集10k样本。我们每跳随机抽200例,共2000例,保证复杂度全覆盖。
- SpartQA:源自NLVR语料,含3-block复杂场景,平均句长是StepGame的2.5倍,支持YN/FR/CO/FB四种题型并带量化词(all/only)。我们每题型抽300例,共1200例,覆盖语言与空间多样性。
3.2 基线方法
- Direct Prompting:零示例直接回答。
- Chain-of-Thought Prompting:DSPy内置CoT模块,提示“Let’s work through this spatial reasoning problem step by step”。
- Facts+Rules Prompting:两阶段轻量神经符号法,LLM先抽事实,再用自然语言套用给定规则做推理,无外部求解器。
3.3 神经-符号流水线(DSPy)
整条流水线用DSPy声明式模块搭建,核心签名如下:
Convert(context,question)→(facts,query) Refine(facts,query,asp_code,error)→(refined_asp) |
阶段1 Convert (Natural language to facts and query):自然语言→ASP事实与查询
对StepGame使用简化谓词:
is(obj1,relation,obj2). query(obj1,obj2). |
对SpartQA使用richer谓词:
block(a;b;c). object(ID,Size,Color,Shape,Block). is(obj1,rel,obj2). |
关系集合固定为{left,right,above,below,near,far,inside,touching},大小写与arity强制一致。
为每题型提供5-shot示例,量化句自动转为ASP聚合:
query(Block):-block(Block),#count{O:object(O,_,black,_,Block)}>=1,not object(_,_,black,_,OtherBlock),OtherBlock!=Block. |
阶段2 Refine (ASP code via feedback-driven iteration):利用求解器报错迭代修正
初次由LLM把facts+手工规则模板拼成完整ASP程序,调用外部run_asp_and_get_answer(asp_code)。
该函数返回两类信息:
- 执行状态:syntax_error/grounding_error/unsafe_var/sat_no_result/ok
- 若ok则返回答案集,否则返具体错误信息
Refine模块把错误映射到手工修订策略:
- syntax_error→检查标点、括号、谓词arity
- grounding_error→检查变量是否未绑定
- unsafe_var→确保变量全部出现在事实或查询体
- sat_no_result→补全缺省关系或添加闭合规则
最多迭代3轮,直到程序通过或达到上限。
阶段3 SymbolicReasoning (Logic execution via solver):确定性求解
通过Clingo求解最终ASP程序,得到稳定模型(答案集)。示例推理规则(方向闭包):
is(Y,left,X):-is(X,right,Y). is(Y,above,X):-is(X,below,Y). |
传递链规则(网格偏移):
is(X,Rel,Z):-is(X,Rel,Y),is(Y,Rel,Z),transitive(Rel). |
阶段4 Evaluate (Answer mapping and scoring):答案映射与评分
由于ASP返回的是原子集合,需映射回题干选项:
- 对YN题,把空答案集→“no”,非空→“yes”
- 对FR题,取is/3第三参数并去重
- 对CO/FB题,允许多答案,采用partial-match指标:全对才给1分,部分对给0.5,错给0
模糊匹配用Levenshtein≥80%处理横线/下划线差异。
图2展示了自然语言描述到ASP代码的完整转换实例,其左侧给出一段关于三个区块(A、B、C)及其内部物体方位关系的自然语言场景描述;右侧列出对应的ASP事实、规则与查询代码,包括:
- 用block/1声明区块;
- 用object/5刻画每个物体的ID、尺寸、颜色、形状、所属区块;
- 用is/3表示物体间的方向、邻近、上下等关系;
- 用逆对称、传递、链式规则补全隐含关系;
最后给出四条示例查询(YN/FB/FR题型),展示如何直接对场景进行符号提问与自动回答。

3.4 配置与加速
- 模型:LLaMA-3-70B,DeepSeek-V3-Chat,GPT-4o;temperature=0.3,max_tokens=5000,cache=True
- ASP求解:Python嵌Clingo,单线程不安全→采用multiprocessing.Pool,每进程独立Clingo控制对象;M4Pro芯片上32进程batch_size=10,速度提升2–4倍
- 日志:全程WARNING级别记录ASP代码、错误诊断与DSPy编译结果,便于复现与调试
通过以上设计,流水线在保持模块可复用与声明式优化的同时,实现了自然语言到可靠符号推理的端到端自动化。
四、实验和结果
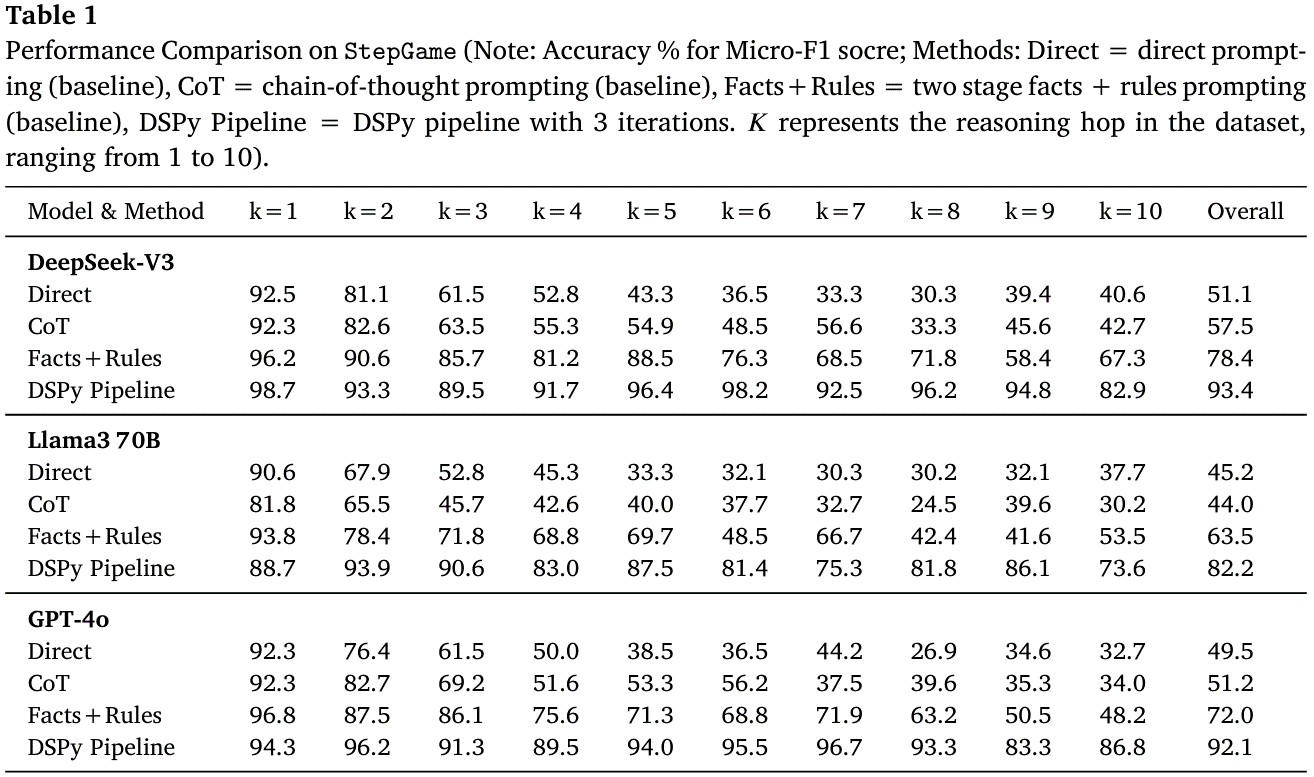
- StepGame全跳数对比:在1–10跳子集上,用DeepSeek-V3、Llama-3-70B、GPT-4o分别运行四种方法(Direct/CoT/Facts+Rules/完整DSPy Pipeline)。结果表明DSPy管道整体准确率达82.2–93.4%,比最强基线Facts+Rules再提高14–25个百分点,且在高跳数场景优势更明显(见Table 1)。
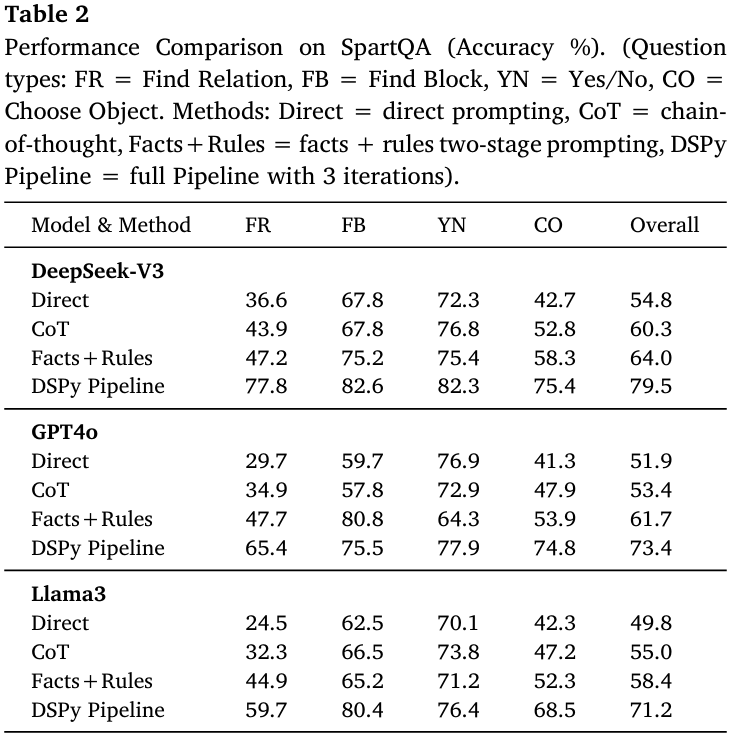
- SpartQA四题型对比:对FR/FB/YN/CO四类问题各300例,同一套模型-方法组合测试。DSPy管道把整体准确率从54.8–64.0%提升到71.2–79.5%,其中Find Relation与Choose Object题型提升最显著,验证符号搜索对多对象关系的价值(见Table 2)。
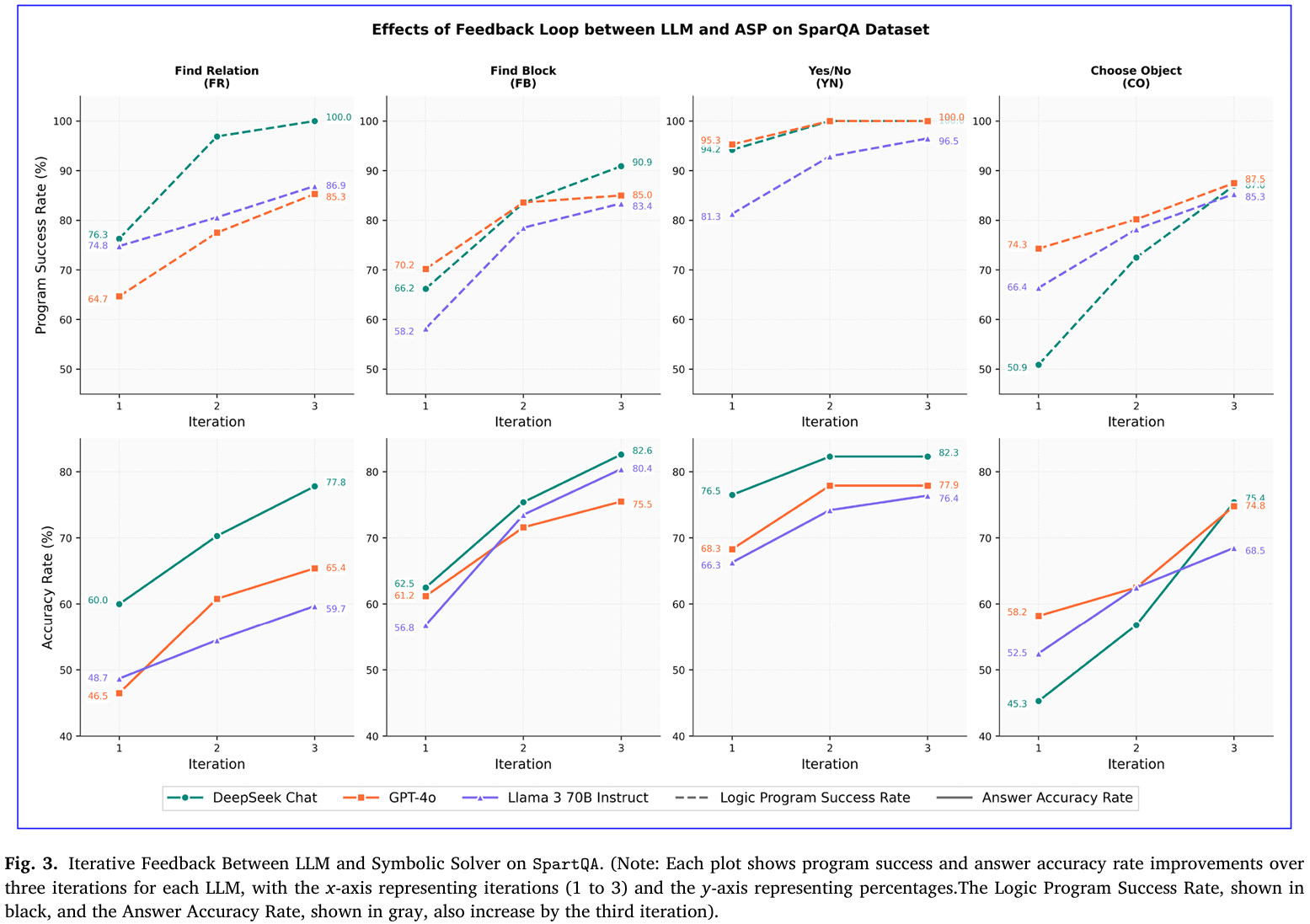
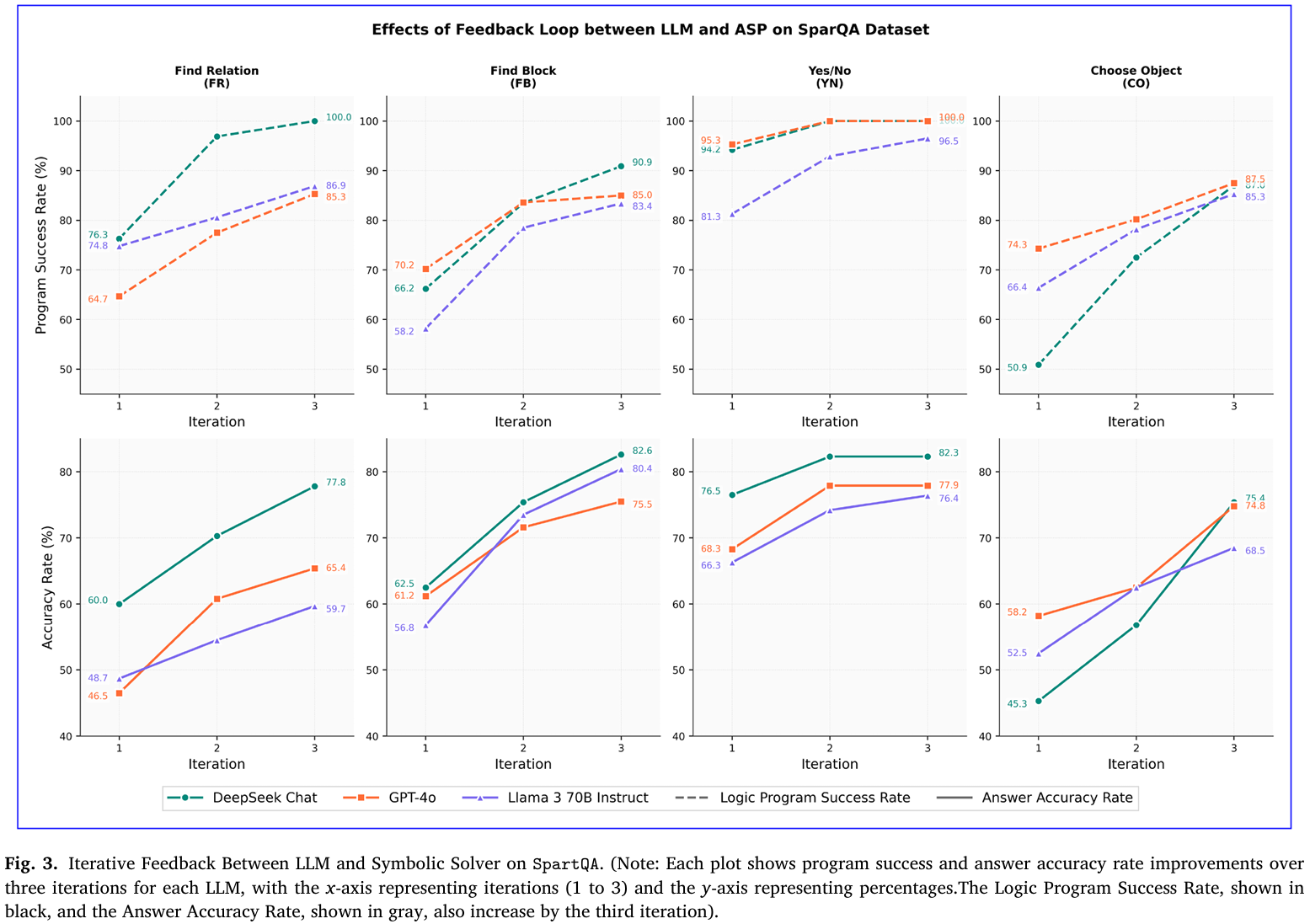
- 迭代反馈消融SpartQA:跟踪三轮“生成-报错-修正”循环,记录程序可执行率与答案准确率。三模型均在第1轮获得最大跃升,DeepSeek可执行率从71.9%升至94.5%,准确率从61.1%升至79.5%,证实反馈机制主要收益来自首轮(见Figure 3)。
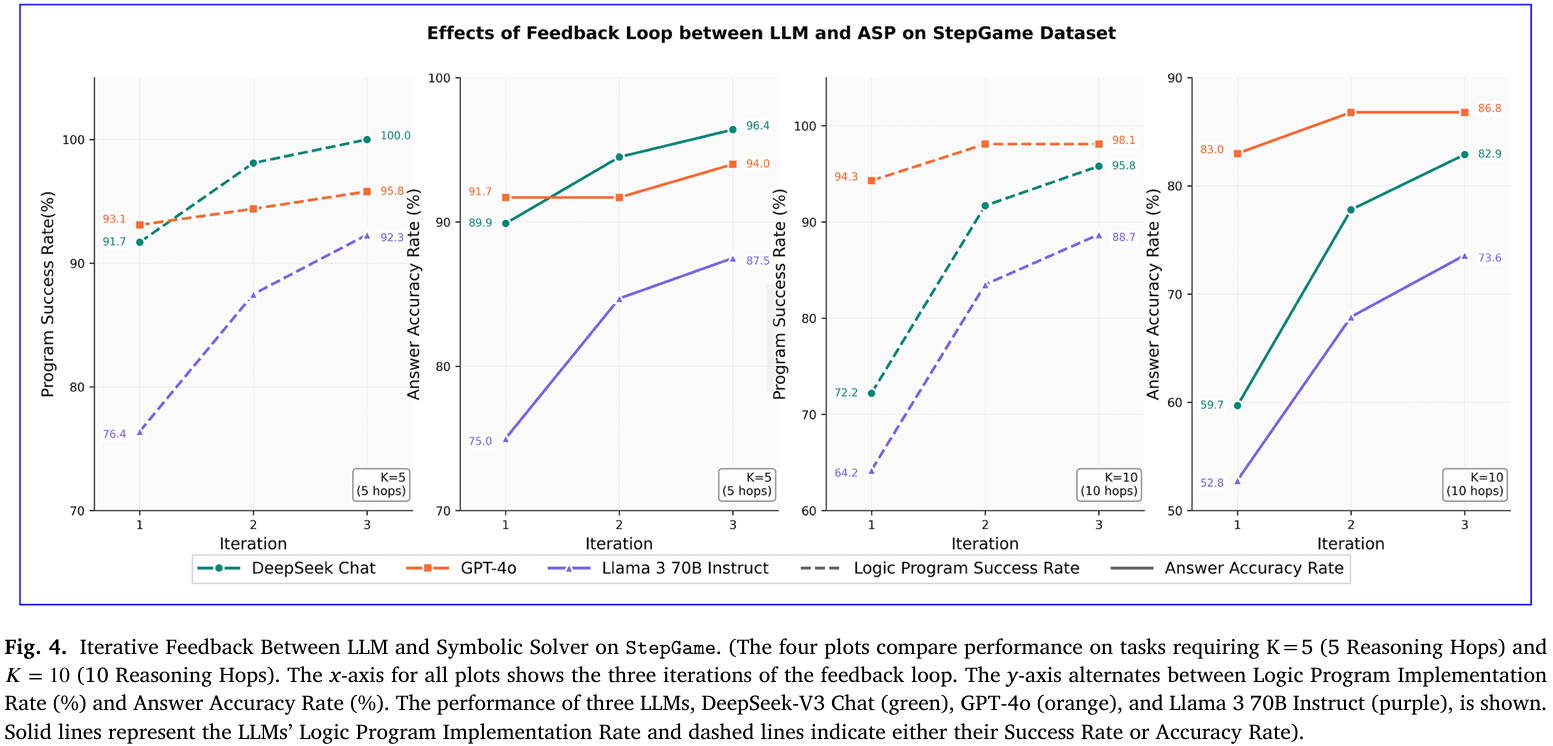
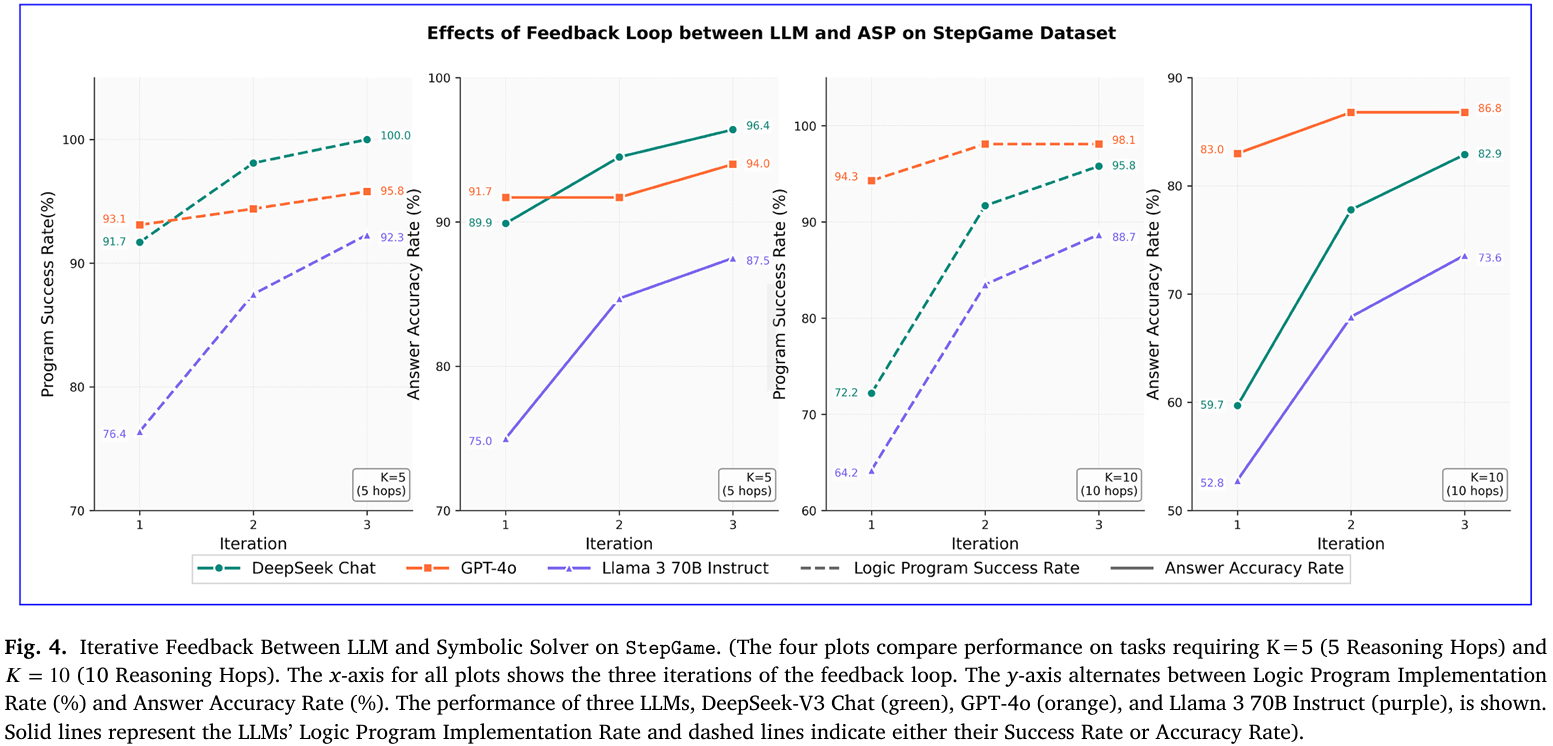
- 迭代反馈消融StepGame(K=5 vs K=10):选取中等难度(5跳)与最高难度(10跳)子集,同样观察三轮迭代。K=10时DeepSeek准确率由59.7%增至82.9%,提升23.2个百分点,而K=5仅增7个百分点,表明反馈收益随推理深度增加而放大(见Figure 4)。
- DSPy自动优化器测试:用BootstrapFewShot、COPRO、MIPROv2对管道进行端到端prompt优化,训练集仅5例。Llama-3在SpartQA-FR上最终准确率再提8.5%,但GPT-4o几乎无增益;综合计算开销与提升幅度,说明优化器对多阶段迭代管道的边际效益有限。
五、消融研究
- 迭代反馈贡献度SpartQA:在SpartQA四题型上跟踪三轮“生成-报错-修正”循环,记录程序可执行率与答案准确率。首轮即带来最大跃升,DeepSeek可执行率从71.9%→94.5%,准确率从61.1%→79.5%,后续收益递减,证明反馈机制主要价值在首轮快速纠错(见Figure 3)。
- 迭代反馈贡献度(StepGame,K=5 vs. K=10):选取5跳(中难)与10跳(最高难)子集重复三轮实验,比较同模型同批次的可执行率与准确率。K=10时DeepSeek准确率提升23.2个百分点,远高于K=5的7个百分点,说明反馈收益随推理深度线性放大;Llama-3在K=10亦从52.8%→73.6%,证实反馈对复杂链式推理必不可少(见Figure 4)。
- DSPy自动优化器评估:用BootstrapFewShot、COPRO、MIPROv2对整条管道进行端到端prompt优化,训练集仅5例,目标分别为“程序可执行率”、“最终准确率”及二者加权。Llama-3在SpartQA-FR上再提8.5%,但GPT-4o无增益;整体 token 开销增加2–3倍,收益-成本比低,说明优化器对多阶段迭代管道的边际效益有限。
六、综合讨论
- 管道优势总结:通过“LLM解析-ASP求解-迭代反馈”三段式架构,把感知与推理彻底分离,使LLM专注语义解析,ASP负责确定性空间推理。该结构在StepGame与SpartQA上均取得SOTA,且错误可追溯至具体逻辑子句,证明模块化+符号反馈可同时提升准确率、可解释性与鲁棒性。
- trade-off分析:完整管道平均需2–3次LLM调用,15–35%样本进入第二轮,5–15%进入第三轮,延迟与token成本随之增加;而轻量“Facts+Rules”两调用即可拿到70–90%的管道收益,说明在精度-资源权衡场景中可退化成中间方案。领域敏感性亦明显:结构化StepGame收益最大,自然语言更复杂的SpartQA仍需更多迭代,提示神经符号方法需针对领域微调。
- 实现洞察与生态呼吁:经验显示,LLM常混淆ASP与Prolog语法,且不同求解器错误信息不一致,导致调试摩擦高。作者呼吁符号社区共建“统一错误报告与核心语法子集”,减少LLM side的prompt工程负担;否则每换一套逻辑语言就需重写的现状,将限制神经符号系统的跨域推广。
七、结论
本研究提出了一种全面的神经符号框架,通过系统结合自然语言理解与形式逻辑推理,显著增强了LLM的空间推理能力。我们的DSPy管道在两个基准数据集上实现了substantial的性能提升:在StepGame上达到82–93%的准确率,在SpartQA上达到71–80%的准确率。这些结果分别比基线方法高出37–43%和16–25%。简化的“事实+规则”方法也能在比完整迭代管道显著降低复杂度和开销的情况下,将基线性能平均提升25–30%。这些结果确立了神经符号集成作为复杂空间推理任务的可行途径,其能力超越了纯神经方法。
这一成功得益于三项关键创新:(1)通过模块化管道有效分离语义解析与逻辑推理,系统地将自然语言翻译为可执行逻辑程序;(2)LLM与ASP求解器之间的迭代反馈机制,利用求解器诊断信息精炼程序,提高逻辑程序执行率;(3)稳健的、面向领域的知识表示,实现快速可靠的符号推理,并辅以解析、接地和求解失败的全面错误处理。三者之中,迭代反馈机制尤其宝贵——大部分提升发生在第一次精炼迭代中,随后收益递减。
神经符号方法重新将LLM概念化为嵌入协调系统的智能体,为整合多种推理形式的多元件架构铺平了道路。我们的架构不再仅仅聚焦于提升单一模型的准确率,而是强调互补计算组件间交互的优化。随着AI研究向通用人工智能(AGI)迈进,这种集成愈发重要。它提供了一种实用策略,将神经网络的适应性与知识丰富性与符号推理的精确性、透明性和逻辑严谨性结合起来。通过弥合这些范式,神经符号系统不仅提升了可靠性与可解释性,也为可扩展、可信且与人类对齐的智能奠定了基础,代表了实现未来AGI的关键一步。
八、阅读笔记
①DSPy与Facts+Rules Prompting的区别:
- Facts+Rules在把自然语言转成“事实”后,仍在自然语言层面套用给定规则做推理,不调用ASP求解器,也不生成正式逻辑程序。DSPy负责生成可执行的ASP程序,随后由Clingo求解器做严格逻辑推理,结果完全由符号引擎决定。
- Facts+Rules一次性提示,无反馈回路;若事实或规则写错,模型无法自行纠正。DSPy引入Refine模块,根据Clingo返回的语法/语义错误进行最多三轮迭代修正,直至程序可执行并得出答案。
- Facts+Rules仅需2次LLM调用,无外部依赖,速度快,但精度上限约为完整管道的70–90%。DSPy需2–3次调用(约15–35%样本进入第二轮,5–15%进入第三轮),token与延迟增加2–3倍,但换来10–25%的绝对准确率提升,并具备完全可解释、可验证的符号推理轨迹。
②DSPy推理Demo:
(1) 自然语言输入(StepGame 5-hop样例)
Context: A is left of B. B is above C. C is right of D. D is below E. E is left of F. Question: What is the relation of A to F? |
(2) DSPy Convert模块输出(首轮)
% ---------- facts ---------- is(a,left,b). is(b,above,c). is(c,right,d). is(d,below,e). is(e,left,f). % ---------- rules ---------- inverse(left,right). inverse(right,left). inverse(above,below). inverse(below,above). is(Y,R2,X) :- is(X,R1,Y), inverse(R1,R2), X!=Y. transitive(above;below;left;right). is(X,R,Z) :- is(X,R,Y), is(Y,R,Z), transitive(R), X!=Y, Y!=Z, X!=Z. % ---------- query ---------- query(Rel) :- is(a,Rel,f). |
(3) Clingo求解(run_asp_and_get_answer)
命令(step_mini.lp是把Convert模块生成的ASP事实、规则与查询保存成纯文本文件后,用来让Clingo执行的临时文件名字):
clingo --outf=2 step_mini.lp |
返回的稳定模型(答案集):
Answer: 1 is(a,left,f) is(a,above,f) query(left) query(above) |
(4) Evaluate映射
取query/1原子集合→{left, above} 与gold标准“left & above”完全匹配→准确率=1 |
(5) 若首轮报错,Refine 模块如何工作(示例)
假设Convert首轮把is(d,below,e).误写为:
is(d,above,e). |
Clingo返回sat but no query result。
Refine提示模板(节选自附录C3):
The solver found no query result, which means the facts may contradict the expected spatial chain. Please check: 1. Whether each directional assertion in the context is correctly encoded without flipping up/down or left/right. 2. Add the missing inverse or transitive rule if omitted. |
LLM依据提示自动修正为is(d,below,e).并补全缺失的传递规则;第二轮即可得到正确答案。
③Convert模块在本质上是LLM实现的NLP到ASP。
④Clingo是最主流的回答集编程(ASP)求解器,由波茨坦大学开发,把“事实+规则”直接编译成布尔约束后调用SAT引擎,一次性算出所有稳定模型(答案集)。它支持整数、聚合、优化语句和Lua脚本,被广泛用于规划、调度、空间推理等组合问题。Clingo的安装:
# macOS brew install clingo # Ubuntu sudo apt install clingo |
⑤只要Clingo返回ok(无语法/语义错误且能查到查询结果),流水线就直接进入SymbolicReasoning→Evaluate,跳过Refine模块,不再做第二轮LLM调用。
⑥SymbolicReasoning阶段是调用Clingo对Convert(或Refine)生成的.lp文件求解,得到稳定模型(答案集)后原样返回给下游Evaluate模块。
⑦Evaluate是一段纯Python的小脚本:先把Clingo给出的答案原子(query(...)括号里的内容就是答案原子,例如query(left)中的left)抠出来,统一大小写和符号,再跟标准答案比对——单选题(YN、FR)要完全对上,多选题(FB、CO)部分对也给分,最后算平均准确率,全程不调用LLM,只干“字符串对答案”这一件事。