【ProtoBuf】快速上手
目录
一.创建.proto文件
二.使用protoc命令进行编译
三.序列化与反序列化的使用
四.小结Protobuf使用过程
对ProtoBuf的完整学习,将使⽤项⽬推进的⽅式完成教学:即对于ProtoBuf知识内容的展开,会对 ⼀个项⽬进⾏⼀个版本⼀个版本的升级去讲解ProtoBuf对应的知识点。
在后续的内容中,将会实现⼀个通讯录项⽬。
对通讯录⼤家应该都不陌⽣,⼀般,通讯录中包含了⼀ 批的联系⼈,每个联系⼈⼜会有很多的属性,例如姓名、电话等等。
随着对通讯录项⽬的升级,我们对ProtoBuf的学习与使⽤就越深⼊。
在快速上⼿中,会编写第⼀版本的通讯录1.0。
在通讯录1.0版本中,将实现:
- 对⼀个联系⼈的信息使⽤PB进⾏序列化,并将结果打印出来。
- 对序列化后的内容使⽤PB进⾏反序列,解析出联系⼈信息并打印出来。
- 联系⼈包含以下信息:姓名、年龄。
通过通讯录1.0,我们便能了解使⽤ProtoBuf初步要掌握的内容,以及体验到ProtoBuf的完整使⽤流 程。
一.创建.proto文件
文件命名规范
创建 .proto 文件时,文件名应使用全小写字母,多个单词之间使用下划线连接,遵循蛇形命名法(snake_case)。例如:lower_snake_case.proto。
在实际项目中,建议根据文件定义的消息类型或服务功能来命名,使其具有描述性和可识别性。
代码格式规范
在编写 .proto 文件代码时,应采用 2 个空格 作为缩进单位,保持代码层次清晰统一。这种缩进方式既能保证代码的可读性,又能在不同编辑环境中保持一致的显示效果。
基于此规范,我们为通讯录 1.0 版本创建文件:contacts.proto
注释规范
为增强代码的可维护性,建议向文件中添加适当的注释说明。Protocol Buffers 支持以下注释方式:
- 单行注释:使用 // 符号
- 多行注释:使用 /* ... */ 符号
注释应简洁明了,重点描述消息字段的用途、约束条件或业务逻辑。
语法版本指定
Protocol Buffers 语言版本 3(简称 proto3)是最新的 .proto 文件语法标准。
proto3 在语法设计上更加简洁,提升了开发效率,同时支持更广泛的编程语言,包括 Java、C++、Python、Go、C# 等。
在 .proto 文件里,必须使用 syntax = "proto3"; 明确指定使用 proto3 语法,且此声明必须位于文件首行(注释除外)。如果未指定语法版本,编译器将默认使用 proto2 语法。
在通讯录 1.0 的 contacts.proto 文件中,语法指定如下:
syntax = "proto3";包声明规范
package 是一个可选的声明符,用于定义 .proto 文件的命名空间,它在项目范围内应保持唯一性。包声明的主要作用是避免消息类型命名冲突,特别是在大型项目或多模块系统中。
在通讯录 1.0 的 contacts.proto 文件中,包声明如下:
syntax = "proto3";
package contacts;包名通常采用反向域名命名法(如:com.example.project),但在单一项目或模块内,也可使用简洁的模块名,如示例中的 contacts。
消息(message)
在 Protocol Buffers 中,消息(message) 是用于定义结构化数据对象的核心构建块。通过消息定义,我们可以明确指定对象包含的各个属性字段及其数据类型,从而构建出符合业务需求的复杂数据结构。
消息定义语法
在 .proto 文件中定义消息类型的基本格式如下:
message 消息类型名 {// 字段定义
}基于上述规范,我们在 contacts.proto 文件中为联系人定义消息结构:
syntax = "proto3";
package contacts;// 定义联系人消息类型
// 包含联系人的基本信息和联系方式
message PeopleInfo {// 在此处添加联系人相关字段// 例如:姓名、电话、邮箱等
}消息字段
在 Protocol Buffers 的消息(message)中,属性字段的定义遵循标准格式:
字段类型 字段名 = 字段唯一编号;- 字段类型
该表格展⽰了定义于消息体中的标量数据类型,以及编译.proto⽂件之后⾃动⽣成的类中与之对应的 字段类型。在这⾥展⽰了与C++语⾔对应的类型。
| .proto 类型 | 说明 | C++ 类型 |
|---|---|---|
double | 双精度浮点数 | double |
float | 单精度浮点数 | float |
int32 | 使用变长编码[1]。负数编码效率低,如可能为负值,建议使用 sint32 | int32 |
int64 | 使用变长编码[1]。负数编码效率低,如可能为负值,建议使用 sint64 | int64 |
uint32 | 无符号32位整数,使用变长编码[1] | uint32 |
uint64 | 无符号64位整数,使用变长编码[1] | uint64 |
sint32 | 有符号32位整数,使用变长编码[1],对负数编码效率更高 | int32 |
sint64 | 有符号64位整数,使用变长编码[1],对负数编码效率更高 | int64 |
fixed32 | 定长4字节无符号整数,当值常大于 2²⁸ 时比 uint32 更高效 | uint32 |
fixed64 | 定长8字节无符号整数,当值常大于 2⁵⁶ 时比 uint64 更高效 | uint64 |
sfixed32 | 定长4字节有符号整数 | int32 |
sfixed64 | 定长8字节有符号整数 | int64 |
bool | 布尔值 | bool |
string | 包含 UTF-8 和 ASCII 编码的字符串,长度不超过 2³² | string |
bytes | 任意字节序列,长度不超过 2³² | string |
[1] 关于变长编码:变长编码是指经过 Protocol Buffers 编码后,原本固定4字节或8字节的数值可能会被压缩为更少的字节数,具体长度取决于数值的大小。这种编码方式对于小数值特别高效,但会为大数值付出少量额外开销。
字段唯一编号
1.字段编号的本质
- 字段编号是 Protocol Buffers 序列化和反序列化机制的基石。
- 它并非一个简单的顺序标识,而是消息中每个字段的永久且唯一的身份标识符。
- 您可以将其理解为每个字段在二进制数据流中的“身份证号码”。
- 当数据被序列化时,系统并不携带字段的名称(如 name 或 age),而是携带其字段编号和对应的值。
- 接收方通过同样的 .proto 文件定义,根据字段编号来识别数据的含义,从而重建消息对象。
2.字段编号的核心特性:不可变性
- 这是字段编号最重要、最需要严格遵守的特性。一旦您的消息格式被投入使用(即已经有序列化后的数据被保存或通过网络传输),该消息类型中所有字段的编号就绝对不能更改。
- 原因:想象一下,您将字段 username 的编号从 1 改为 2。那么,之前所有存储的编号为 1 的 username 数据,在新版本的程序中将被无法识别,或者更糟,被错误地解释为另一个字段。这会导致数据损坏和解析失败,是破坏向后兼容性的致命操作。
- 删除字段的处理:如果您删除了一个字段,一个非常好的实践是使用 reserved 关键字将其编号或字段名“保留”起来,以防止未来的开发者无意中重复使用这个编号,从而引发兼容性问题。
3.字段编号的范围与禁区
- 字段编号有其有效的取值范围和明确的禁区。
- 有效范围:从 1 到 536,870,911 (即 2²⁹ - 1)。这个范围极其广阔,为任何规模的应用都提供了充足的编号空间。
- 明确禁区:19000 到 19999 这连续的 1000 个编号被 Protocol Buffers 的官方实现内部预留。如果您在 .proto 文件中使用了这个范围内的编号,编译器在编译时会生成警告。这些编号被保留用于库本身的特定功能或未来扩展,开发者应完全避免使用。
4.字段编号与编码效率的艺术
- Protocol Buffers 采用了一种称为“变长整数编码”的聪明机制,这使得较小的整数在序列化后占用的字节数更少。字段编号的取值直接影响了序列化后数据的体积,因此编号的分配是一门值得优化的艺术。
- 编码后的二进制数据,每个字段的“标签”(包含字段编号和类型信息)所占用的字节数是可变的:
- 编号 1 至 15:仅需 1 个字节 进行编码。
- 编号 16 至 2047:需要 2 个字节 进行编码。
- 编号越大,所需字节数可能越多。
基于这一原理,我们得出以下至关重要的优化策略:
必须将最频繁使用、最关键的字段分配在 1 到 15 这个“黄金编号段”内。 这包括所有会被反复传输、在业务中处于核心地位的字段。
例如,在一个用户消息中,user_id、name 等字段理应获得 1-15 的编号。
同时,您还应当有远见地为未来可能引入的新的高频字段预留出一些 1-15 范围内的宝贵编号。而那些不常使用或数据量较大的可选字段(如长描述、二进制数据块),则可以分配给 16 及以上的编号。
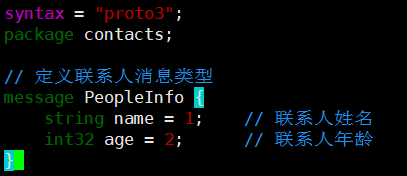
基于上述规范,我们更新 contacts.proto 文件,为联系人消息添加姓名和年龄字段:
syntax = "proto3";
package contacts;message PeopleInfo {string name = 1;int32 age = 2;
}
我们保存退出
二.使用protoc命令进行编译
protoc命令的核心作用是:将人类可读的 .proto 文件(协议定义文件)编译成计算机可用的 C++ 代码。
基本语法结构如下:
protoc [选项参数] 要编译的文件现在我们来逐一分解每个部分:
1. protoc - 编译器本身
- 这是什么:这是 Protocol Buffer 官方提供的命令行编译工具,就像 gcc 之于 C++,javac 之于 Java。
- 做什么用:它读取 .proto 文件,并根据你指定的语言(如 C++, Java, Python 等),生成对应的类、函数和代码文件。这些生成的代码用于在你的程序中序列化(将数据转换成二进制格式)和反序列化(从二进制格式解析回数据)结构化数据。
2. --proto_path=导入路径 或 -I 导入路径
- 这个选项参数,用于告诉 protoc:“当你在 .proto 文件中遇到 import 语句时,应该去哪些目录里寻找被导入的文件”。
- .proto 文件经常需要导入其他 .proto 文件(比如一些公共的定义)。
- protoc 需要一个“工作目录”来解析这些导入语句。
- 如何工作:假设你的 .proto 文件里有 import "foo/bar.proto";,同时你设置了 --proto_path=/path/to/my_protos。那么,protoc 就会去 /path/to/my_protos/foo/bar.proto 寻找这个文件。
- 可以多次指定:如果你的文件分散在多个不同的目录,你可以多次使用这个参数,例如 -I ./src -I ./dependencies。protoc 会按顺序在这些路径中搜索。
- 默认值:如果你不指定这个参数,protoc 默认就在当前命令行所在目录进行搜索。
- 简写:--proto_path=/some/dir 可以简写为 -I /some/dir。
3. --cpp_out=DST_DIR
- 它告诉 protoc 两件事:
- --cpp_out:生成 C++ 语言的代码。如果你想生成 Java 代码,就用 --java_out;生成 Python 代码,就用 --python_out。
- =DST_DIR:指定生成的 C++ 代码文件应该被放在哪个目标目录里。
- 详细解释:
- OUT_DIR 或 DST_DIR:这是你希望存放生成的 .pb.h(头文件)和 .pb.cc(实现文件)的目录。这个目录必须已经存在,protoc 不会自动创建它。
- 例如,你设置 --cpp_out=./generated,那么所有生成的 C++ 文件都会被放在当前目录下的 generated 文件夹里。
4. .proto文件的路径
- 这是什么:这是你要编译的源文件(.proto文件)的路径,即你的协议定义文件(.proto文件)。
- 详细解释:
- 这是命令的最后一个参数,它告诉 protoc 具体要编译哪个文件。
- 这个路径可以是相对路径,也可以是绝对路径。
- 关键点:这个路径的解析,与 --proto_path (-I) 规则有关。protoc 会尝试在所有指定的 IMPORT_PATH 下寻找这个.proto文件。
我们看看简单的例子
- 最简情况(90%的情况都这样用)
假设:
- 你的 .proto 文件叫 message.proto
- 它和你在同一个文件夹
- 你希望生成的C++代码也在这个文件夹
命令:
protoc --cpp_out=. message.proto结果: 生成了 message.pb.h 和 message.pb.cc 两个文件
- 稍微复杂一点
假设:
- 你的 .proto 文件在 proto 文件夹里
- 你希望生成的代码在 generated 文件夹里
命令:
protoc --cpp_out=generated proto/message.proto结果: 在 generated 文件夹里生成了 message.pb.h 和 message.pb.cc
- 如果报"import找不到"错误
命令改成:
protoc --proto_path=proto --cpp_out=generated message.proto解释:
- --proto_path=proto 告诉编译器:"所有import都去proto文件夹里找"
- 这样就不会报import错误了

我们可以去.h文件里面看看
vim contacts.pb.h往下翻就能看到PeopleInfo类,这个就是我们在message
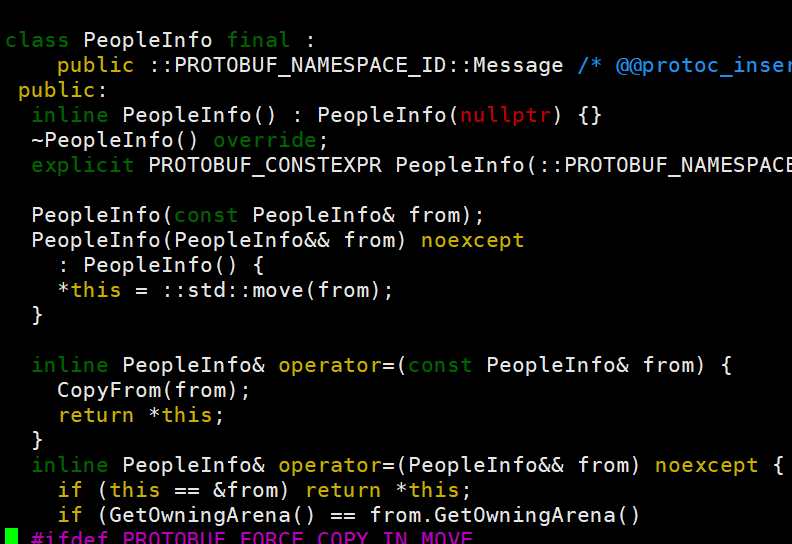
我们往下翻
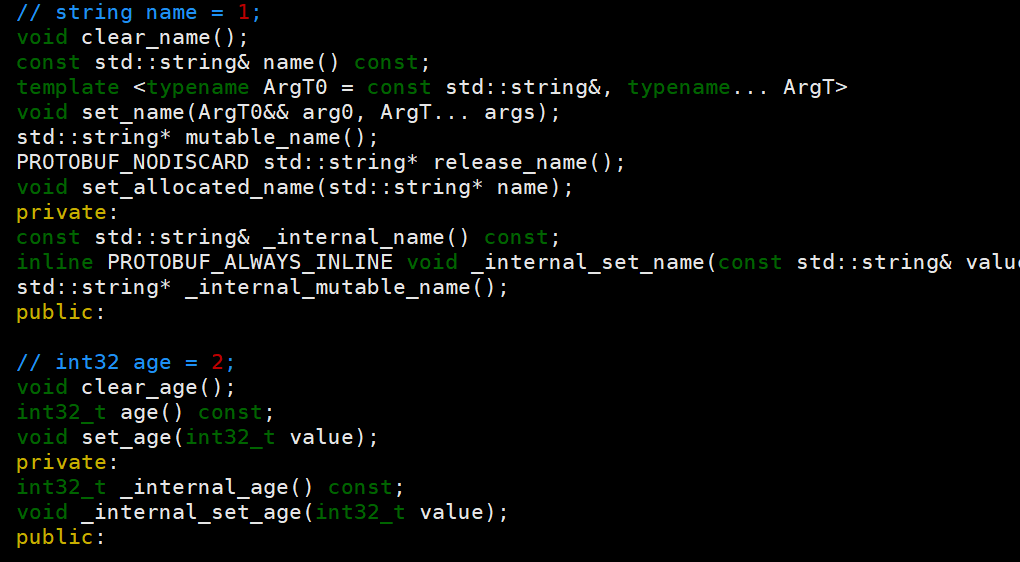
对于string类型的字段(例如name):
-
clear_name():清空字段值,使其变为空字符串。
-
name() const:返回字段值的常量引用(只读)。
-
set_name(...):设置字段值。可以接受一个字符串(常量引用或移动语义)或多个参数(用于构造字符串)。
-
mutable_name():返回字段值的可变指针,可以通过该指针修改字符串内容。如果字段没有被设置,则会分配一个空字符串。
-
release_name():释放字段对字符串的所有权,返回该字符串的指针,并将字段置为空字符串。调用者负责删除返回的字符串。
-
set_allocated_name(std::string* name):将给定的字符串指针设置到字段,并取得该指针的所有权。注意:不能传入栈上的字符串地址。
对于int32类型的字段(例如age):
-
clear_age():将字段值清零。
-
age() const:返回字段值。
-
set_age(int32_t value):设置字段值。
但是到这里我们还是没有发现序列化和反序列化的代码啊?我们就去

我们发现这个PeopleInfo继承自Message类
这个Message类又继承自MessageLite类,而MessageLite类里面就有序列化和反序列化方法
class MessageLite {public:// ==================== 序列化方法 ====================/*** 将消息序列化并输出到输出流* @param output 输出流指针* @return 成功返回true,失败返回false*/bool SerializeToOstream(ostream* output) const; // 将序列化后数据写入文件流/*** 将消息序列化到指定的内存数组* @param data 目标内存地址* @param size 内存缓冲区大小* @return 成功返回true,失败返回false(通常由于缓冲区不足)*/bool SerializeToArray(void *data, int size) const;/*** 将消息序列化到字符串* @param output 目标字符串指针* @return 成功返回true,失败返回false*/bool SerializeToString(string* output) const;// ==================== 反序列化方法 ====================/*** 从输入流读取数据并反序列化为消息对象* @param input 输入流指针* @return 成功返回true,失败返回false(数据格式错误或读取失败)*/bool ParseFromIstream(istream* input); // 从流中读取数据,再进行反序列化/*** 从内存数组反序列化为消息对象* @param data 源数据地址* @param size 数据大小* @return 成功返回true,失败返回false(数据格式错误)*/bool ParseFromArray(const void* data, int size);/*** 从字符串反序列化为消息对象* @param data 包含序列化数据的字符串* @return 成功返回true,失败返回false(数据格式错误)*/bool ParseFromString(const string& data);// 注意:所有序列化/反序列化方法都是线程安全的// 序列化后的数据格式是平台无关的,支持跨平台数据传输
};三.序列化与反序列化的使用
创建⼀个测试⽂件main.cc,⽅法中我们实现:
- 对⼀个联系⼈的信息使⽤PB进⾏序列化,并将结果打印出来。
- 对序列化后的内容使⽤PB进⾏反序列,解析出联系⼈信息并打印出来。
我们编写一个main.cpp
#include <iostream>
#include "contacts.pb.h" // 引入编译生成的头文件using namespace std;int main() {string people_str;// .proto文件声明的package,通过protoc编译后,会为编译生成的C++代码声明同名的命名空间// 其范围是在.proto 文件中定义的内容// 序列化contacts::PeopleInfo people_src;people_src.set_age(20);people_src.set_name("张珊");// 调用序列化方法,将序列化后的二进制序列存入string中if (!people_src.SerializeToString(&people_str)) {cout << "序列化联系人失败。" << endl;return -1;}// 打印序列化结果cout << "序列化后的 people_str: " << people_str << endl;// 反序列化contacts::PeopleInfo people_dst;// 调用反序列化方法,读取string中存放的二进制序列,并反序列化出对象if (!people_dst.ParseFromString(people_str)) {cout << "反序列化出联系人失败." << endl;return -1;}// 打印结果cout << "Parse age: " << people_dst.age() << endl;cout << "Parse name: " << people_dst.name() << endl;return 0;
}代码书写完成后,编译main.cc,⽣成可执⾏程序TestProtoBuf :
g++ main.cc contacts.pb.cc -o TestProtoBuf -std=c++11 -lprotobuf- -lprotobuf:必加,不然会有链接错误。
- -std=c++11:必加,使⽤C++11语法。
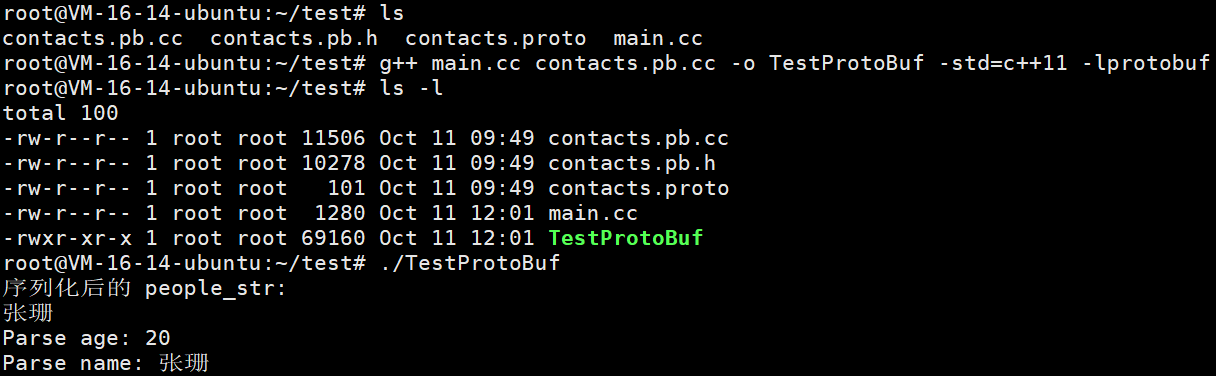
由于ProtoBuf是把联系⼈对象序列化成了⼆进制序列,这⾥⽤string来作为接收⼆进制序列的容器。 所以在终端打印的时候会有换⾏等⼀些乱码显⽰。
所以相对于xml和JSON来说,因为被编码成⼆进制,破解成本增⼤,ProtoBuf编码是相对安全的。
可以看到我们这里的序列化和反序列化的过程都是通过上面使用protoc命令编译生成的.cpp文件和.h文件里面的api来实现的。这就是protobuf的核心优势——完全不需要关系怎么进行序列化,反序列化,我们只需要会调用API即可。
四.小结Protobuf使用过程
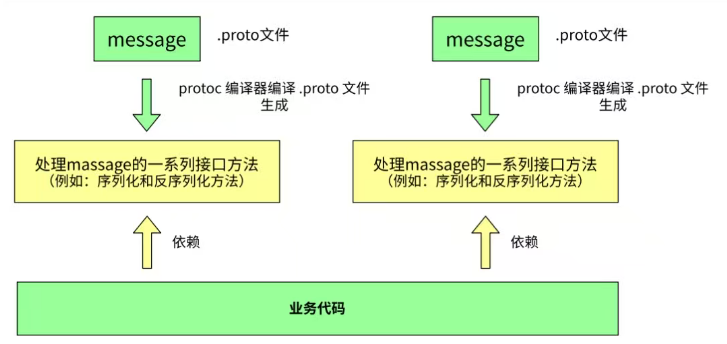
-
编写.proto文件,这一步的核心目的是定义结构化消息类型(message)及其包含的字段属性。通过声明数据类型和字段规则,我们建立了一套与语言无关的数据结构模板。
-
使用Protocol Buffers提供的protoc编译器对.proto文件进行编译。该步骤会生成一系列与目标编程语言对应的接口代码,这些代码分别存储在新生成的头文件(C++)或类文件(如Java、Python等)中,为后续的数据操作提供支持。
-
在项目代码中引入生成的头文件或类文件,并依赖其提供的接口,可以便捷地对.proto文件中定义的各个字段进行赋值与读取。同时,借助自动生成的序列化与反序列化方法,能够轻松将消息对象转换为字节流,或从字节流还原为对象。
总结来说,ProtoBuf的实际使用离不开通过编译生成的头文件与源文件。
借助这一代码生成机制,开发人员无需再手动编写繁琐且易错的协议解析代码——这类工作不仅重复性高、复杂度大,而且难以保证跨版本与跨平台的兼容性,可谓“吃力不讨好”。
通过ProtoBuf,我们可以将更多精力集中于业务逻辑的实现,从而提升开发效率并降低协议层的维护成本。
为什么说“离不开生成的头文件/类文件”?
因为所有这些你直接使用的类(如 Person)、方法(如 SerializeToString 和 ParseFromString)都不是你手写的,而是 protoc 编译器根据你的 .proto 文件自动生成的。
没有编译这一步,你就没有这些现成的、可靠的工具来操作数据。
“吃力不讨好”体现在哪里?
如果没有 ProtoBuf,你需要手动设计一套序列化格式(比如用逗号分隔的CSV,或者复杂的JSON然后手动解析),并自己编写代码来:
-
把内存中的对象一个字段一个字段地拼接成字节流。
-
从字节流里一个字节一个字节地解析出每个字段的值,并做类型检查。
-
当数据结构发生变化(比如增加一个字段)时,需要同时维护新旧版本的解析代码,非常容易出错,兼容性极难保证。
ProtoBuf 通过一个 .proto 文件作为唯一的、明确的“数据合同”,然后自动为各种语言生成底层操作代码,完美地解决了上述所有麻烦。
开发者只需要关注“数据是什么”(定义proto)和“如何使用数据”(调用生成的API),而不用关心“数据怎么变成字节流”这个复杂且易错的过程。