【HarmonyOS】异步并发和多线程并发
文章目录
- 一、并发
- 二、异步并发
- 1、Promise
- 2、async/await
- 三、多线程并发
- 1、基本概念
- 1.1 多线程并发模型
- 1.2 内存共享模型
- 1.3 Actor模型
- 2、TaskPool
- 2.1 TaskPool运作机制
- 2.2 注意事项
- 2.3 @Concurrent装饰器
- 2.3.1 并发函数返回Promise
- 2.3.2 并发异步函数中使用Promise
- 2.4 示例
- 3、Worker
- 3.1 Worker运作机制
- 3.2 注意事项
- 3.2.1 创建Worker的注意事项
- 3.2.2 文件路径注意事项
- 3.2.3 生命周期注意事项
- 3.3 示例
- 3.3.1 同模块内使用
- 3.3.2 跨har包加载Worker
- 4、TaskPool和Worker的对比
- 4.1 实现特点对比
- 4.2 适用场景对比
一、并发
并发指在同一时间内,多个任务同时执行。在多核设备上,任务可以在不同CPU上并行执行。对于单核设备,尽管多个任务不会同时并行,但CPU会在某个任务休眠或进行I/O操作时切换任务,调度其他任务,提高CPU的资源利用率。
| 概念 | 定义 | 特点 | 实际 |
|---|---|---|---|
| 并发 | 多个线程在单个核心运行,同一时间只能一个线程运行,内核不停切换线程,看起来像同时运行 | 微观上串行,宏观上并行 | 多个任务交替执行(单核 CPU 分时调度),看似“同时”运行 |
| 并行 | 每个线程分配给独立的 CPU 核心,线程真正的同时运行 | 微观和宏观上都是同时进行 | 多个任务真正同时执行(需多核 CPU 或多台机器) |
ArkTS提供了异步并发和多线程并发两种处理策略。
- 异步并发是指异步代码在执行到一定程度后暂停,并在未来某个时间点继续执行,同一时间只有一段代码执行。ArkTS通过
Promise和async/await提供异步并发能力,适用于单次I/O任务。 - 多线程并发允许同时执行多段代码。UI主线程继续响应用户操作和更新UI,后台线程执行耗时操作,避免应用卡顿。ArkTS通过TaskPool和Worker提供多线程并发能力,适用于耗时任务等并发场景。
二、异步并发
Promise和async/await是标准的JS异步语法,提供异步并发能力。异步代码执行时会被挂起,稍后继续执行,确保同一时间只有一段代码在运行。鸿蒙完全支持ES6 Promise标准。
Promise提供了一种优雅的方式来处理异步操作的结果,避免了传统回调函数可能导致的"回调地狱"问题。
以下是典型的异步并发使用场景:
- I/O 非阻塞操作:网络请求、文件读写、定时器等。
- 任务轻量且无 CPU 阻塞:单次任务执行时间短。
- 逻辑依赖清晰:任务有明确的顺序或并行关系。
异步编程的核心思想是避免阻塞操作对程序执行的影响。当程序遇到可能耗时的操作(如网络请求、文件读写等)时,不会等待操作完成,而是继续执行后续代码,当异步操作完成时再通过回调或Promise的方式处理结果。这种方式特别适合处理用户界面相关的任务,确保界面始终保持响应。
1、Promise
Promise是一种用于处理异步操作的对象,可将异步操作转换为类似同步操作的风格,便于代码编写和维护。Promise通过状态机制管理异步操作的不同阶段,有三种状态:pending(进行中)、fulfilled(已完成,也叫resolved)和rejected(已拒绝)。创建后处于pending状态,异步操作完成后转换为fulfilled或rejected状态。
Promise提供了then、catch、finally方法来注册回调函数,以处理异步操作的成功或失败结果。当Promise状态改变时,回调函数会被加入微任务队列等待执行,依赖事件循环机制在宏任务执行完成后优先执行微任务,从而保证回调函数的异步调度。
最基本的用法是通过构造函数实例化一个Promise对象,传入一个带有两个参数的函数,称为executor函数。executor函数接收两个参数:resolve和reject,分别表示异步操作成功和失败时的回调函数。
const promise: Promise<number> = new Promise((resolve: Function, reject: Function) => {// ...
})
Promise对象创建后,可以使用then方法和catch方法指定fulfilled状态和rejected状态的回调函数。then方法可接受两个参数,一个处理fulfilled状态的函数,另一个处理rejected状态的函数。只传一个参数则表示当Promise对象状态变为fulfilled时,then方法会自动调用这个回调函数,并将Promise对象的结果作为参数传递给它。使用catch方法注册一个回调函数,用于处理“失败”的结果,即捕获Promise的状态改变为rejected状态或操作失败抛出的异常。Promise还可以使用finally注册回调函数,无论Promise最终状态如何(fulfilled或rejected),都会执行该回调函数。
// 使用 then 方法定义成功的回调,catch 方法定义失败的回调
promise.then((result: number) => {// ... // 成功时执行
}).catch((error: Error) => {// ... // 失败时执行
});// 无论成功还是失败都会执行
promise.finally(() => {// ...
})
2、async/await
async/await是用于处理异步操作的Promise语法糖,使编写异步代码更加简单和易读。使用async关键字声明异步函数,并使用await关键字等待Promise的解析(fulfilled或rejected),以同步方式编写异步操作的代码。
async函数返回Promise对象,实现异步操作。函数内部可包含零个或多个await关键字,await会暂停执行,直到关联的Promise完成状态转换(fulfilled或rejected)。若函数执行过程中抛出异常,该异常将直接触发返回的Promise进入rejected状态,错误对象可通过catch方法或then的第二个回调参数捕获。
需要注意的是,等待异步操作时,需将操作包在async函数中,并搭配await使用,且await关键字只在async函数内有效。同时也可使用try/catch块来捕获异常。
三、多线程并发
鸿蒙还提供了传统的多线程编程支持。通过Worker线程,开发者可以将繁重的计算任务转移到后台线程执行,避免阻塞主线程。鸿蒙的多线程模型经过精心设计,既保证了线程间通信的效率,又确保了系统的稳定性。
多线程编程在处理大量数据计算、图像处理、加密解密等CPU密集型任务时表现出色。通过合理的线程池管理和任务分配,可以充分利用多核处理器的并行计算能力,显著提升应用性能。
1、基本概念
- 进程
进程是操作系统分配资源(CPU、内存、文件等)和独立运行程序的基本单位,每个进程拥有隔离的内存空间和系统资源,是正在执行的程序的实例。
- 线程
线程是操作系统能够调度的最小执行单元,是进程(Process)中的一个独立控制流。
多线程 是指一个进程中运行多个线程,共享进程资源(如文件句柄、内存),但各自独立执行。
并发模型用于实现不同应用场景中的并发任务。常见的并发模型有基于内存共享的模型和基于消息通信的模型。
Actor并发模型是基于消息通信的典型并发模型。开发者无需处理锁带来的复杂问题,且具备高并发度,因此应用广泛。
当前ArkTS提供了TaskPool和Worker两种并发能力,两者均基于Actor并发模型实现。
1.1 多线程并发模型
内存共享并发模型指多线程同时执行任务,这些线程依赖同一内存资源并且都有权限访问,线程访问内存前需要抢占并锁定内存的使用权,没有抢占到内存的线程需要等待其他线程释放使用权再执行。
Actor并发模型每一个线程都是一个独立Actor,每个Actor有自己独立的内存,Actor之间通过消息传递机制触发对方Actor的行为,不同Actor之间不能直接访问对方的内存空间。
Actor并发模型与内存共享并发模型相比,不同线程间的内存是隔离的,因此不会发生线程竞争同一内存资源的情况。无需处理内存上锁问题,从而提高开发效率。
Actor并发模型中,不同Actor之间不共享内存,需通过消息传递机制传递任务和结果。
1.2 内存共享模型
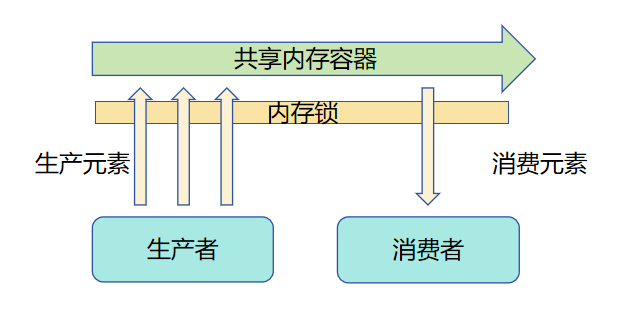
为了避免不同生产者或消费者同时访问同一块共享内存容器时产生脏读、脏写现象,同一时间只能有一个生产者或消费者访问该容器。即不同生产者和消费者需争夺使用容器的锁。当一个角色获取锁后,其他角色需等待该角色释放锁,才能重新尝试获取锁以访问该容器。
1.3 Actor模型
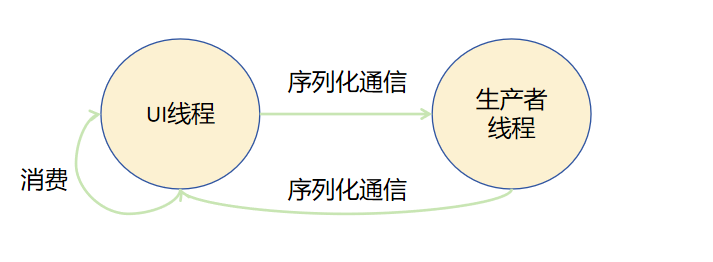
Actor模型中,不同角色之间并不共享内存,生产者线程和UI线程都有自己的虚拟机实例,两个虚拟机实例之间拥有独占的内存,相互隔离。生产者生产出结果后,通过序列化通信将结果发送给UI线程。UI线程消费结果后,再发送新的生产任务给生产者线程。
也可以等待生产者完成所有任务,通过序列化通信将结果发送给UI线程。UI线程接收后,由消费者统一消费结果。
2、TaskPool
任务池(taskpool)的作用是为应用程序提供多线程运行环境,降低资源消耗并提升系统性能,且您无需关心线程的生命周期。您可以使用任务池API创建后台任务(Task),并进行如执行任务或取消任务等操作。
HarmonyOS 提供的轻量级并发调度工具,负责管理后台任务的创建、分发和执行,支持将任务分配到多线程执行(利用多核 CPU 实现并行),避免主线程阻塞(如 UI 卡顿)。
- 需通过
new taskpool.Task(函数, 参数1, 参数2...)创建任务实例。 - 需通过
taskpool.execute(任务实例)提交任务并执行。
创建同一优先级的任务时,可以自行决定其执行顺序。任务的实际执行顺序与调用任务池API提供的任务执行接口的顺序一致。任务的默认优先级为MEDIUM。
当同一时间待执行的任务数量大于任务池工作线程数量,任务池会根据负载均衡机制进行扩容,增加工作线程数量,减少整体等待时长。同样,当执行的任务数量减少,工作线程数量大于执行任务数量,部分工作线程处于空闲状态,任务池会根据负载均衡机制进行缩容,减少工作线程数量。
2.1 TaskPool运作机制
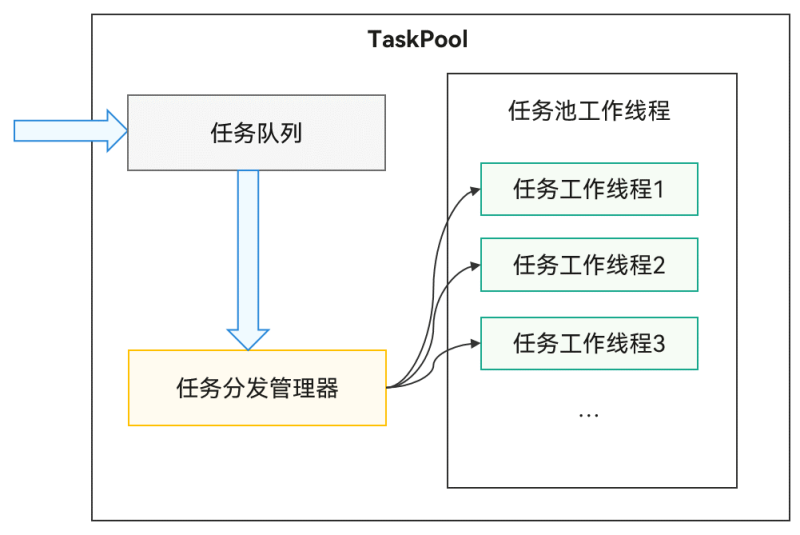
TaskPool支持在宿主线程提交任务到任务队列,系统选择合适的工作线程执行任务,并将结果返回给宿主线程。接口易用,支持任务执行、取消和指定优先级。通过系统统一线程管理,结合动态调度和负载均衡算法,可以节约系统资源。系统默认启动一个任务工作线程,任务多时会自动扩容。工作线程数量上限由设备的物理核数决定,内部管理具体数量,确保调度和执行效率最优。长时间无任务分发时会缩容,减少工作线程数量。
2.2 注意事项
-
实现任务的函数需要使用
@Concurrent装饰器标注,且仅支持在.ets文件中使用。 -
从API version 11开始,跨并发实例传递带方法的实例对象时,该类必须使用装饰器
@Sendable装饰器标注,且仅支持在.ets文件中使用。 -
实现任务的函数入参需满足序列化支持的类型。。目前不支持使用
@State装饰器、@Prop装饰器、@Link装饰器等装饰器修饰的复杂类型。 -
不支持在
TaskPool工作线程中使用AppStorage。 -
TaskPool不支持指定任务所运行的线程,任务会被分配到空闲的线程中执行。如果需要指定任务所运行的线程,建议使用Worker。
2.3 @Concurrent装饰器
使用TaskPool时,执行的并发函数必须用该装饰器修饰,否则无法通过校验。
仅支持在Stage模型的工程中使用。仅支持在.ets文件中使用。允许标注为async函数或普通函数。禁止标注为generator、箭头函数、类方法。不支持类成员函数或者匿名函数。允许使用局部变量、入参和通过import引入的变量,禁止使用闭包变量。
标记函数为 “可并发执行的任务函数”,必须满足以下规则(否则执行报错):
- 函数返回值必须是
Promise类型(或能隐式转换为Promise的类型,如async函数的返回值)。 - 函数参数和返回值必须是 可序列化类型(如基本类型
number/string、数组、简单对象,避免传递 UI 组件、复杂引用类型)。 - 若函数是
async类型,需确保内部Promise已 “决议”(resolved/rejected),不能返回 “pending 状态的 Promise”。
2.3.1 并发函数返回Promise
// 1. testPromise:非 async 函数,直接返回已决议的 Promise
@Concurrent
function testPromise(args1: number, args2: number): Promise<number> {return new Promise<number>((resolve, reject) => {resolve(args1 + args2); // Promise立即决议(resolved),值为3});
}
// 普通函数(非async),返回一个 “立即决议” 的Promise(创建后直接调用resolve)。// 2. testPromise1:async 函数,返回未显式 await 的 Promise(关键错误点)
@Concurrent
async function testPromise1(args1: number, args2: number): Promise<number> {return new Promise<number>((resolve, reject) => {resolve(args1 + args2); // Promise虽立即决议,但未被await});
}
// async函数,返回一个Promise,但未用await关键字等待该 Promise 决议。
// 不合法!async函数的返回值会被自动包装为Promise,若内部返回的是 “未 await 的 Promise”,ArkTS 会判定为 “返回 pending 状态的 Promise”(尽管实际已决议,但语法上未显式等待),违反@Concurrent规则。// 3. testPromise2:async 函数,返回显式 await 的已决议 Promise
@Concurrent
async function testPromise2(args1: number, args2: number): Promise<number> {return await new Promise<number>((resolve, reject) => {resolve(args1 + args2); // Promise立即决议,且被await等待});
}
// async函数,内部用await等待 Promise 决议后再返回。// 4. testPromise3:非 async 函数,返回 Promise.resolve 快捷创建的已决议 Promise
@Concurrent
function testPromise3() {return Promise.resolve(1); // 快捷方式创建已决议的Promise,值为1
}
// 普通函数,用Promise.resolve(1)直接返回已决议的 Promise(语法糖,等价于new Promise(resolve => resolve(1)))。// 5. testPromise4:async 函数,返回基本类型(隐式转换为 Promise)
@Concurrent
async function testPromise4(): Promise<number> {return 1; // async函数返回基本类型,自动包装为已决议的Promise<number>
}
// async函数,直接返回基本类型1,而非 Promise。// 6. testPromise5:async 函数,返回 await 延迟决议的 Promise
@Concurrent
async function testPromise5(): Promise<string> {return await new Promise((resolve) => {setTimeout(() => {resolve('Promise setTimeout after resolve'); // 1秒后决议}, 1000)});
}
// async函数,内部Promise通过setTimeout延迟 1 秒决议,且用await等待决议完成。
2.3.2 并发异步函数中使用Promise
testPromiseError:async函数,在Promise.then中主动抛错
@Concurrent
async function testPromiseError() {await new Promise<number>((resolve, reject) => {resolve(1); // 第一步:Promise先决议为成功(resolved),值为1}).then(() => {throw new Error('testPromise error'); // 第二步:在then回调中主动抛出Error})
}
错误逻辑拆解:
-
内部创建的 Promise 调用
resolve(1),进入then回调(因为 Promise 成功决议)。 -
在
then回调中,通过throw new Error(...)主动抛出一个错误对象 —— 根据 Promise 规则,“then 中抛错” 会导致后续的 Promise 被 拒绝(rejected),错误信息为抛出的 Error 对象。 -
函数是
async类型,await会等待上述 Promise 结果:由于 Promise 最终被拒绝,await会将错误 “透传” 给外层,导致taskpool.execute返回的 Promise 进入catch分支。
错误特征:
- 错误类型是
Error对象,错误信息为testPromise error。 - 错误来源是 “开发者主动抛错”,而非 Promise 自身的 reject。
testPromiseError1:async函数,await被reject的Promise
@Concurrent
async function testPromiseError1() {await new Promise<string>((resolve, reject) => {reject('testPromiseError1 error msg'); // Promise直接决议为拒绝(rejected)})
}
错误逻辑拆解:
-
内部创建的 Promise 未调用
resolve,而是直接调用reject('错误信息')——Promise 从创建时就决议为拒绝,拒绝原因是字符串testPromiseError1 error msg。 -
函数是
async类型,await会等待这个被拒绝的 Promise:根据async/await规则,“await 一个被拒绝的 Promise” 会直接触发外层 Promise 拒绝,错误信息为reject的参数(此处是字符串,非 Error 对象)。
错误特征:
- 错误类型是 原始字符串(而非 Error 对象),错误信息为
testPromiseError1 error msg。 - 错误来源是 “Promise 主动调用 reject”,属于 “预期内的拒绝”(如网络请求失败、参数错误等场景常用此方式返回错误)。
testPromiseError2:非async函数,直接返回被reject的Promise
@Concurrent
function testPromiseError2() {return new Promise<string>((resolve, reject) => {reject('testPromiseError2 error msg'); // 返回一个被拒绝的Promise})
}
错误逻辑拆解:
-
函数是 普通函数(非 async),直接返回一个 Promise 对象。
-
该 Promise 调用
reject('错误信息'),决议为拒绝 —— 由于函数返回的是 “已拒绝的 Promise”,符合@Concurrent对 “返回 Promise 类型” 的要求(@Concurrent允许返回被拒绝的 Promise,仅禁止返回 pending 状态的 Promise)。 -
taskpool.execute执行此任务时,会直接接收这个被拒绝的 Promise,因此进入catch分支。
错误特征:
- 错误类型是 原始字符串,错误信息为
testPromiseError2 error msg。 - 错误来源与
testPromiseError1类似(Promise reject),但函数类型不同(非 async),错误传播更直接(无await中间层)。
2.4 示例
- 一:
// 支持普通函数、引用入参传递
@Concurrent
function printArgs(args: string): string {console.info("func: " + args);return args;
}async function taskpoolExecute(): Promise<void> {// taskpool.execute(task)let task: taskpool.Task = new taskpool.Task(printArgs, "create task, then execute");console.info("taskpool.execute(task) result: " + await taskpool.execute(task));// taskpool.execute(function)console.info("taskpool.execute(function) result: " + await taskpool.execute(printArgs, "execute task by func"));
}taskpoolExecute();
- 二:
// b.ets
export let c: string = "hello";// 引用import变量
// a.ets(与b.ets位于同一目录中)
import { c } from "./b";@Concurrent
function printArgs(a: string): string {console.info(a);console.info(c);return a;
}async function taskpoolExecute(): Promise<void> {// taskpool.execute(task)let task: taskpool.Task = new taskpool.Task(printArgs, "create task, then execute");console.info("taskpool.execute(task) result: " + await taskpool.execute(task));// taskpool.execute(function)console.info("taskpool.execute(function) result: " + await taskpool.execute(printArgs, "execute task by func"));
}taskpoolExecute();
3、Worker
Worker的主要作用是为应用程序提供一个多线程的运行环境,实现应用程序执行过程与宿主线程分离。通过在后台线程运行脚本处理耗时操作,避免计算密集型或高延迟任务阻塞宿主线程。
Worker是与主线程并行的独立线程。创建Worker的线程称为宿主线程,Worker自身的线程称为Worker线程。创建Worker时传入的URL文件在Worker线程中执行,可以处理耗时操作,但不能直接操作UI。
Worker的主要作用是为应用程序提供多线程运行环境,使应用程序在执行过程中与宿主线程分离,在后台线程中运行脚本处理耗时操作,避免计算密集型或高延迟任务阻塞宿主线程。由于Worker一旦创建不会主动销毁,若不处于任务状态会一直运行,造成资源浪费,应及时销毁空闲的Worker。
Worker的上下文环境和UI线程的上下文环境是独立的,Worker线程不支持UI操作。
3.1 Worker运作机制
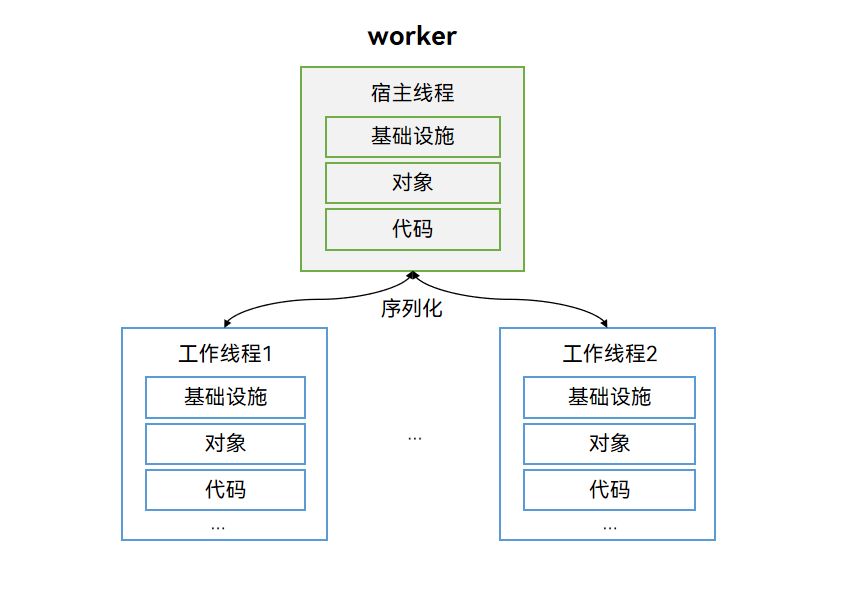 创建Worker的线程称为宿主线程(不局限于主线程,Worker线程也支持创建Worker子线程)。Worker子线程(或Actor线程、工作线程)是Worker自身运行的线程。每个Worker子线程和宿主线程拥有独立的实例,包含独立执行环境、对象、代码段等。因此,启动每个Worker存在一定的内存开销,需要限制Worker子线程的数量。Worker子线程和宿主线程通过消息传递机制通信,利用序列化、引用传递或转移所有权的机制完成命令和数据的交互。
创建Worker的线程称为宿主线程(不局限于主线程,Worker线程也支持创建Worker子线程)。Worker子线程(或Actor线程、工作线程)是Worker自身运行的线程。每个Worker子线程和宿主线程拥有独立的实例,包含独立执行环境、对象、代码段等。因此,启动每个Worker存在一定的内存开销,需要限制Worker子线程的数量。Worker子线程和宿主线程通过消息传递机制通信,利用序列化、引用传递或转移所有权的机制完成命令和数据的交互。
3.2 注意事项
-
创建Worker时,提供手动和自动两种创建方式,推荐使用自动创建方式。
-
不同线程中上下文对象是不同的,因此Worker线程只能使用线程安全的库,例如UI相关的非线程安全库不能在Worker子线程中使用。
-
不支持在多个HAP之间共享使用相同的Worker线程文件。
-
不支持在
Worker工作线程中使用AppStorage。 -
在Worker文件中禁止使用
export语法导出任何内容,否则会导致jscrash问题。
3.2.1 创建Worker的注意事项
Worker线程文件需要放在"{moduleName}/src/main/ets/"目录层级之下,否则不会被打包到应用中。有手动和自动两种创建Worker线程目录及文件的方式。
- 手动创建:开发者手动创建相关目录及文件,通常是在ets目录下创建一个workers文件夹,用于存放worker.ets文件,需要配置build-profile.json5的相关字段信息,确保Worker线程文件被打包到应用中。
"buildOption": {"sourceOption": {"workers": ["./src/main/ets/workers/worker.ets"]}
}
- 自动创建:DevEco Studio支持一键生成Worker,在对应的{moduleName}目录下任意位置,单击鼠标右键 > New > Worker,即可自动生成Worker的模板文件及配置信息,无需再手动在build-profile.json5中进行相关配置。
3.2.2 文件路径注意事项
使用Worker模块的具体功能时,需先构造Worker实例对象。构造函数与API版本相关,且需传入Worker线程文件的路径(scriptURL)。
// 导入模块
import { worker } from '@kit.ArkTS';const worker1: worker.ThreadWorker = new worker.ThreadWorker('entry/ets/workers/worker.ets');
构造函数中的scriptURL要求如下:
- scriptURL的组成包含{moduleName}/ets和相对路径relativePath。
- relativePath是Worker线程文件相对于"{moduleName}/src/main/ets/"目录的相对路径。
- 加载Ability中的Worker线程文件:
加载Ability中的worker线程文件。路径规则:{moduleName}/ets/{relativePath}。
- 加载HSP中Worker线程文件
加载HSP中的worker线程文件。路径规则:{moduleName}/ets/{relativePath}。
- 加载HAR中Worker线程文件
加载HAR中worker线程文件存在以下两种情况:
- @标识路径加载形式:所有种类的模块加载本地HAR中的Worker线程文件,加载路径规则:@{moduleName}/ets/{relativePath}。
- 相对路径加载形式:本地HAR加载该包内的Worker线程文件,路径规则为:创建Worker对象所在文件与Worker线程文件的相对路径。
3.2.3 生命周期注意事项
- Worker的创建和销毁会消耗较多的系统资源,建议开发者合理管理并重复使用已创建的Worker。Worker空闲时仍会占用资源,当不需要Worker时,可以调用terminate()接口或close()方法主动销毁Worker。若Worker处于已销毁或正在销毁等非运行状态时,调用其功能接口,会抛出相应的错误。
- Worker的数量由内存管理策略决定,设定的内存阈值为1.5GB和设备物理内存的60%中的较小值。在内存允许的情况下,系统最多可以同时运行64个Worker。尝试创建的Worker数量超出上限时,系统将抛出错误:“Worker initialization failure, the number of workers exceeds the maximum.”。实际运行的Worker数量会根据当前内存使用情况实时调整。当所有Worker和主线程的累积内存占用超过设定的阈值时,系统将触发内存溢出(OOM)错误,导致应用程序崩溃。
3.3 示例
3.3.1 同模块内使用
-
DevEco Studio支持一键生成Worker,在对应的{moduleName}目录下任意位置,单击鼠标右键 > New > Worker,即可自动生成Worker的模板文件及配置信息。本文以创建“worker”为例。
支持手动创建Worker文件,具体方式和注意事项请参阅创建Worker的注意事项。
-
导入Worker模块。
// Index.ets import { ErrorEvent, MessageEvents, worker } from '@kit.ArkTS' -
在宿主线程中,通过调用ThreadWorker的constructor()方法创建Worker对象,并注册回调函数。
// Index.ets @Entry @Component struct Index {@State message: string = 'Hello World';build() {RelativeContainer() {Text(this.message).id('HelloWorld').fontSize(50).fontWeight(FontWeight.Bold).alignRules({center: { anchor: '__container__', align: VerticalAlign.Center },middle: { anchor: '__container__', align: HorizontalAlign.Center }}).onClick(() => {// 创建Worker对象let workerInstance = new worker.ThreadWorker('entry/ets/workers/worker.ets');// 注册onmessage回调,捕获宿主线程接收到来自其创建的Worker通过workerPort.postMessage接口发送的消息。该回调在宿主线程执行workerInstance.onmessage = (e: MessageEvents) => {let data: string = e.data;console.info('workerInstance onmessage is: ', data);}// 注册onmessageerror回调,当Worker对象接收到无法序列化的消息时被调用,在宿主线程执行workerInstance.onmessageerror = () => {console.error('workerInstance onmessageerror');}// 注册onexit回调,当Worker销毁时被调用,在宿主线程执行workerInstance.onexit = (e: number) => {// Worker正常退出时,code为0;异常退出时,code为1console.info('workerInstance onexit code is: ', e);}// 发送消息给Worker线程workerInstance.postMessage('1');})}.height('100%').width('100%')} } -
在Worker文件中注册回调函数。
// worker.ets import { ErrorEvent, MessageEvents, ThreadWorkerGlobalScope, worker } from '@kit.ArkTS';const workerPort: ThreadWorkerGlobalScope = worker.workerPort;// 注册onmessage回调,当Worker线程收到来自其宿主线程通过postMessage接口发送的消息时被调用,在Worker线程执行 workerPort.onmessage = (e: MessageEvents) => {let data: string = e.data;console.info('workerPort onmessage is: ', data);// 向宿主线程发送消息workerPort.postMessage('2'); }// 注册onmessageerror回调,当Worker对象接收到一条无法被序列化的消息时被调用,在Worker线程执行 workerPort.onmessageerror = () => {console.error('workerPort onmessageerror'); }// 注册onerror回调,捕获Worker在执行过程中发生的异常,在Worker线程执行 workerPort.onerror = (err: ErrorEvent) => {console.error('workerPort onerror err is: ', err.message); }
3.3.2 跨har包加载Worker
-
在HAR中创建Worker线程文件相关内容。
// worker.ets workerPort.onmessage = (e: MessageEvents) => {console.info('worker thread receive message: ', e.data);workerPort.postMessage('worker thread post message to main thread'); } -
在entry模块的oh-package.json5文件中配置HAR包的依赖。
// 在entry模块配置har包的依赖 {"name": "entry","version": "1.0.0","description": "Please describe the basic information.","main": "","author": "","license": "","dependencies": {"har": "file:../har"} } -
在entry模块中加载HAR包中的Worker线程文件。
// Index.ets import { worker } from '@kit.ArkTS';@Entry @Component struct Index {@State message: string = 'Hello World';build() {RelativeContainer() {Text(this.message).id('HelloWorld').fontSize(50).fontWeight(FontWeight.Bold).alignRules({center: { anchor: '__container__', align: VerticalAlign.Center },middle: { anchor: '__container__', align: HorizontalAlign.Center }}).onClick(() => {// 通过@标识路径加载形式,加载har中Worker线程文件let workerInstance = new worker.ThreadWorker('@har/ets/workers/worker.ets');workerInstance.onmessage = () => {console.info('main thread onmessage');};workerInstance.postMessage('hello world');})}.height('100%').width('100%')} }
4、TaskPool和Worker的对比
4.1 实现特点对比
| 实现 | TaskPool | Worker |
|---|---|---|
| 内存模型 | 线程间隔离,内存不共享。 | 线程间隔离,内存不共享。 |
| 参数传递机制 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。支持ArrayBuffer转移、SharedArrayBuffer共享和Sendable引用传递。 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。支持ArrayBuffer转移、SharedArrayBuffer共享和Sendable引用传递。 |
| 参数传递 | 直接传递,无需封装。 | 消息对象唯一参数,需要自己封装。 |
| 方法调用 | 直接传入并调用@Concurrent修饰的方法。 | 在Worker线程中解析消息并调用对应方法。 |
| 返回值 | 异步调用后默认返回。 | 主动发送消息,需在onmessage中解析并赋值。 |
| 生命周期 | TaskPool自动管理其生命周期,无需关注任务负载。 | 开发者需自行管理Worker的数量和生命周期。 |
| 任务池个数上限 | 自动管理,无需配置。 | 同个进程下,最多支持同时开启64个Worker线程,实际数量由进程内存决定。 |
| 任务执行时长上限 | 3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时),长时任务无执行时长上限。 | 无限制。 |
| 设置任务的优先级 | 支持配置任务优先级。 | 从API version 18开始,支持配置Worker线程优先级。 |
| 执行任务的取消 | 支持取消已经发起的任务。 | 不支持。 |
| 线程复用 | 支持。 | 不支持。 |
| 任务延时执行 | 支持。 | 不支持。 |
| 设置任务依赖关系 | 支持。 | 不支持。 |
| 串行队列 | 支持。 | 不支持。 |
| 任务组 | 支持。 | 不支持。 |
| 周期任务 | 支持。 | 不支持。 |
| 异步队列 | 支持。 | 不支持。 |
4.2 适用场景对比
TaskPool和Worker均支持多线程并发能力。由于TaskPool的工作线程会绑定系统的调度优先级,并支持负载均衡(自动扩缩容),相比之下,Worker需要开发者自行创建,存在创建耗时。因此,性能方面TaskPool优于Worker,推荐在大多数场景中使用TaskPool。
TaskPool偏向于独立任务,任务在线程中执行时,无需关注线程的生命周期。超长任务(大于3分钟且非长时任务)会被系统自动回收。而Worker适用于长时间占据线程的任务,需要开发者主动管理线程的生命周期。
常见开发场景及适用说明如下:
- 运行时间超过3分钟的任务(不包括Promise和async/await异步调用的耗时,如网络下载、文件读写等I/O任务的耗时):例如后台进行1小时的预测算法训练等CPU密集型任务,需要使用Worker。场景示例可参考常驻任务开发指导。
- 有关联的一系列同步任务:例如在一些需要创建、使用句柄的场景中,每次创建的句柄都不同,必须永久保存该句柄,以确保后续操作正确执行,需要使用Worker。场景示例可参考使用Worker处理关联的同步任务。
- 需要设置优先级的任务:在API version 18 之前,Worker不支持设置调度优先级,需要使用TaskPool。从API version 18开始,Worker支持设置调度优先级,开发者可以根据使用场景和任务特性选择使用TaskPool或Worker。例如图像直方图绘制场景,后台计算的直方图数据会用于前台界面的显示,影响用户体验,需要高优先级处理,且任务相对独立,推荐使用TaskPool。
- 需要频繁取消的任务:如图库大图浏览场景。为提升体验,系统会同时缓存当前图片左右各两张图片。当往一侧滑动跳到下一张图片时,需取消另一侧的缓存任务,此时需使用TaskPool。
- 大量或调度点分散的任务:例如大型应用中的多个模块包含多个耗时任务,不建议使用Worker进行负载管理,推荐使用TaskPool。场景示例可参考批量数据写数据库场景。