机器学习实践项目(一)- Rossman商店销售预测 - 预处理数据
前一篇博文分析完了数据,我们现在要开始处理数据。最终参与算法训练的所有字段都不能有空值,所以我们现在要想办法填充test测试集中的空值。
test.fillna(1, inplace = True)
test.isnull().sum()
前面说过,test测试集中值为空的字段只有open字段,且只有11条记录,这些记录全部都是622门店的,且根据我们对该门店前几个月的分析,缺失的那几天该门店应该也是营业的,所以我们不妨把所有缺失的Open字段都填充为1.
运行后重新统计test测试集的空值情况如下:
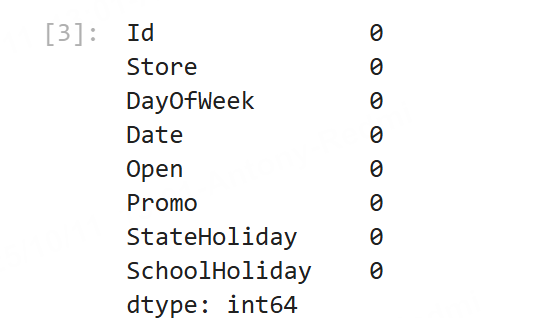
课件当前test测试集的值也完整了。接下来就要处理store门店主数据,按照上篇文章的分析,门店主数据中缺失的字段我们准备全部填充0,所以执行以下代码:
# 这些空值的字段无从知晓取值,所以直接置为0
store.fillna(0, inplace = True)
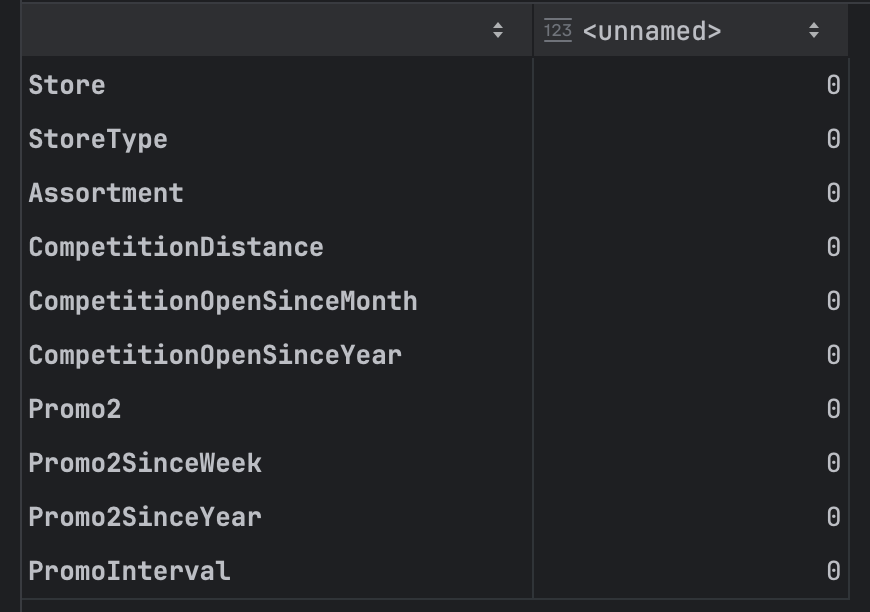
store.isnull().sum()
填充完毕后,再次统计空值发现门店数据集都完整了。
好,那到此为止,数据的完整性预处理便结束了,所有字段都已经没有空值。预处理最后一步,把门店数据集分别合并到训练集和测试集上去:
# 正式舍弃训练集中销售金额不大于0的记录
cond = train['Sales'] > 0
train = train[cond]
# 把训练集和门店集进行左连接left join,主键是Store字段
train = pd.merge(train, store, on = 'Store', how = 'left')
# 把测试集和门店集进行左连接left join,主键是Store字段
test = pd.merge(test, store, on = 'Store', how = 'left')display(train.shape, test.shape)
这里注意,在处理训练集时,只留下了金额大于0的销售记录,金额小于等于0的记录都抛弃掉了,这是因为有些门店可能产生了退款等异常情况,导致营业额为负,这显然属于异常数据,因此要抛弃。
合并完,打印两个数据集的行列数值,发现字段数量(列数)都已经合并:
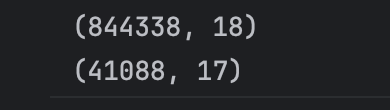
好,预处理已经完成,接下来就要进行特征工程的处理了。