[嵌入式系统-85]:GPU内部结构
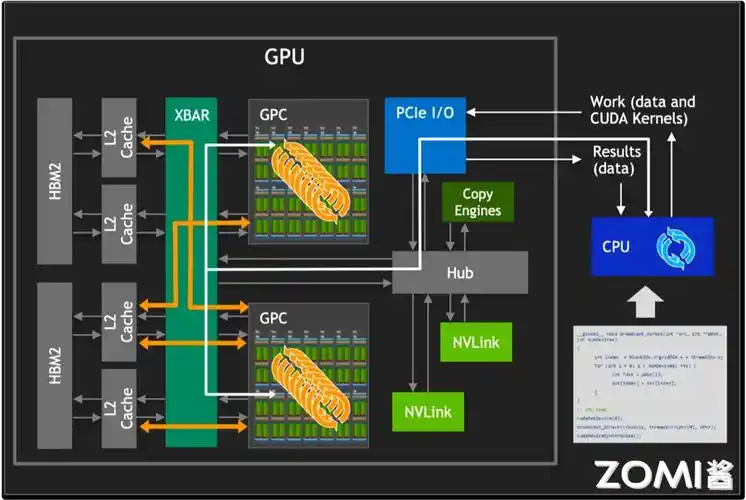
GPU(图形处理单元,Graphics Processing Unit)是一种高度并行化的处理器,最初设计用于加速图形渲染任务,但如今广泛应用于高性能计算、人工智能、深度学习等领域。其内部结构与CPU有显著不同,主要体现在高度并行架构和大规模数据吞吐能力上。
以下是现代GPU的典型内部结构及其核心组件:
一、GPU整体架构层级
GPU Die(芯片)
- 包含多个流式多处理器(SM)、内存控制器、缓存系统、互连网络等。
- 制造工艺:如台积电5nm、NVIDIA Ada Lovelace或AMD RDNA3架构。
Host Interface(主机接口)
- 负责与CPU通信,通常通过PCIe总线连接。
- 支持DMA(直接内存访问)以实现高效数据传输。
Memory Subsystem(内存子系统)
- GDDR6/GDDR6X 或 HBM(高带宽内存)
- 高速显存提供极高的内存带宽(可达1TB/s以上)
- 显存控制器分布在芯片周围,支持多通道并行访问
Cache Hierarchy(缓存层次)
- L1 Cache:每个SM拥有私有L1缓存 + 共享内存(Shared Memory)
- L2 Cache:全局统一缓存,所有SM共享
- 只读缓存(Texture Cache, Const Cache)
二、核心计算单元:Streaming Multiprocessor (SM)
这是NVIDIA术语;AMD称之为Compute Unit (CU)
SM的主要组成部分:
| 组件 | 功能说明 |
|---|---|
| CUDA Cores / ALUs | 基本算术逻辑单元,执行浮点/整数运算(FP32, INT32)<br>NVIDIA中称为CUDA Core,实际是ALU流水线 |
| Tensor Cores | 专用矩阵乘法单元,用于AI加速(混合精度计算:FP16, BF16, TF32, INT8, FP8)<br>支持4x4x4矩阵乘加操作,极大提升DL性能 |
| RT Cores | 光线追踪专用硬件,加速边界体积层次(BVH)遍历和光线-三角形求交测试 |
| Warp Scheduler | 调度“warp”(一组32个线程)到执行单元<br>隐藏内存延迟,提高利用率 |
| Dispatch Units | 将指令分发给不同的执行单元(如INT、FP、TENSOR) |
| Register File | 每个线程拥有独立寄存器空间<br>容量大(数千KB),支持大量并发线程 |
| Shared Memory / L1 Cache | 可配置为软件控制的高速片上内存(类似SRAM)<br>用于线程块(block)内协作 |
示例:NVIDIA A100 GPU 拥有 108 个 SM,每个 SM 包含:
- 64 个 FP32 CUDA Core
- 4 个 Tensor Core
- 4 个 warp 调度器
- 128 KB 可分割为 shared memory 和 L1 cache
三、并行执行模型(SIMT架构)
GPU采用 SIMT(Single Instruction, Multiple Thread) 架构:
- 所有线程被组织成 warp(NVIDIA,32线程) 或 wavefront(AMD,64线程)
- 同一个warp中的线程执行相同的指令,但作用于不同数据
- 当出现分支分歧(divergence)时,串行执行不同路径,降低效率
例如:
if (threadIdx.x % 2 == 0)a = a + 1;
elseb = b - 1;
会导致同一warp内的线程分两路执行,性能下降。
四、内存体系结构
| 内存类型 | 特性 | 访问速度 | 范围 |
|---|---|---|---|
| Global Memory | 显存(VRAM),最大容量(如24GB) | 最慢(~1ns级延迟) | 所有线程可访问 |
| Shared Memory | 片上SRAM,由程序员管理 | 极快(接近寄存器) | Block内线程共享 |
| L1 / L2 Cache | 自动缓存global memory数据 | 快 | 全局 |
| Constant / Texture Memory | 只读缓存内存,优化特定访问模式 | 中等 | 全局 |
| Registers | 每线程专用寄存器文件 | 最快 | 私有 |
| Local Memory | 实际位于global memory,用于溢出变量 | 慢 | 线程私有 |
五、典型GPU架构演进(以NVIDIA为例)
| 架构 | 代表产品 | 关键特性 |
|---|---|---|
| Turing | RTX 20系列 | 引入RT Core和Tensor Core,实时光追 |
| Ampere | A100, RTX 30系列 | 第二代RT Core,第三代Tensor Core,支持稀疏化 |
| Hopper | H100 | 引入Transformer Engine,FP8支持,MMA指令增强 |
| Ada Lovelace | RTX 40系列 | 第三代RT Core,第四代Tensor Core,DLSS 3(帧生成) |
六、AMD GPU对比(RDNA/RDNA3架构)
| 组件 | AMD术语 | 对应NVIDIA |
|---|---|---|
| Compute Unit (CU) | 相当于SM | Stream Multiprocessor |
| SIMD Units | 4个向量单元 | 类似warp调度 |
| AI Accelerator | Matrix Cores(部分型号) | Tensor Cores |
| Infinity Cache | 大容量片上缓存 | ——(类似L3) |
七、应用场景对结构的影响
| 应用类型 | 结构需求 |
|---|---|
| 游戏渲染 | 强调纹理单元、ROPs、光栅化效率 |
| 深度学习训练 | 高密度Tensor Core、大显存、HBM |
| 科学计算 | FP64性能、ECC内存支持 |
| 推理部署 | INT8/FP8低精度支持、能效比高 |
总结:GPU结构特点
✅ 高度并行:成千上万个核心同时工作
✅ 高内存带宽:远超CPU的显存带宽
✅ SIMT执行模型:单指令多线程,适合规则数据并行
✅ 异构计算平台:配合CPU进行任务分工(CPU负责控制流,GPU负责数据并行)
✅ 专用加速单元:Tensor Core、RT Core 提升AI与图形性能