netty18罗汉——布袋罗汉(encoder)
因揭陀尊者——布袋罗汉无量寿佛、乾坤宝袋 欢喜如意、其乐陶陶,因揭陀相传是印度一位捉蛇人,他捉蛇是为了方便行人免被蛇咬。他捉蛇后拔去其毒牙而放生于深山,因发善心而修成正果。他的布袋原是载蛇的袋。
这期主要目录:
- 两种编码方法
-
Transformer 编码器
一.netty编码器
回忆一下之前在解码器一节讲的,netty解码器是用包装器和模板模式进行解码操作的,提供了两种解码方式:
1.通过ByteToMessageDecoder 将二进制数据转换成对象
2.通过MessageToMessageDecoder将对象数据转换成对象
现在来看看编码器:
它也是用模板模式,提供两种编码方式:
1.通过MessageToByteEncoder将Pojo转换为二进制数据包
2.通过MessageToMessageEncoderjin将对象数据转换成对象
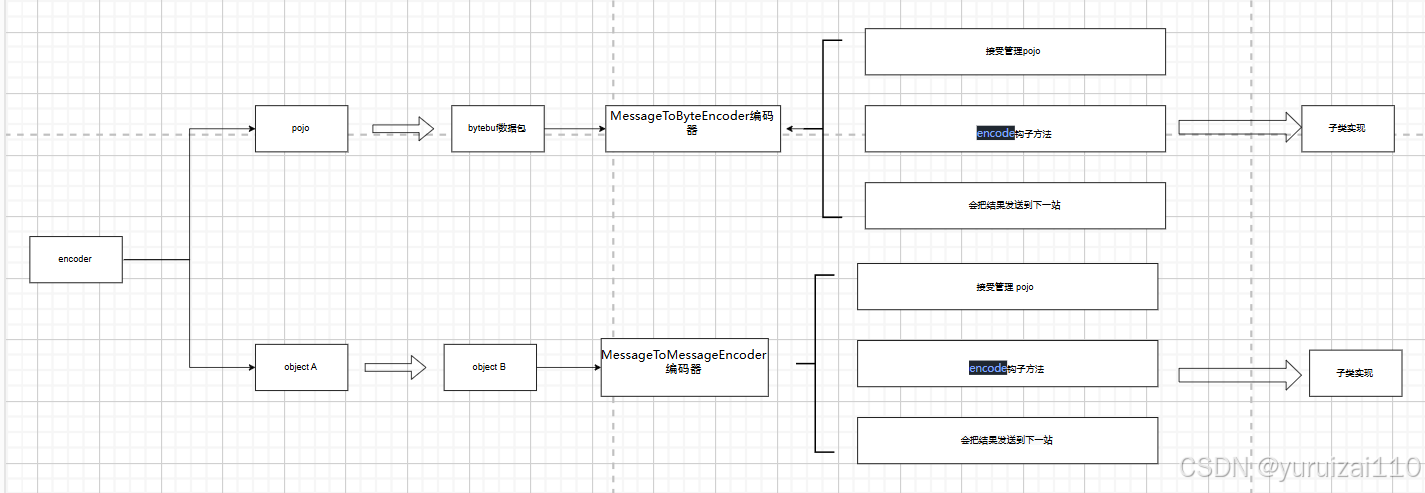
一共经历三个过程:
a.接受上一个上一个出站处理器的数据。处理器后面单独一个章节讲。
b.子类实现钩子方法,处理业务逻辑之后,写入list集合中。
c.最后把结果发送到下一个出站处理器上。
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
CodecOutputList out = null;
try {
if (acceptOutboundMessage(msg)) {
out = CodecOutputList.newInstance();
@SuppressWarnings("unchecked")
I cast = (I) msg;
try {
//钩子方法
encode(ctx, cast, out);
} finally {
ReferenceCountUtil.release(cast);
}
if (out.isEmpty()) {
out.recycle();
out = null;
throw new EncoderException(
StringUtil.simpleClassName(this) + " must produce at least one message.");
}
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable t) {
throw new EncoderException(t);
} finally {
if (out != null) {
final int sizeMinusOne = out.size() - 1;
if (sizeMinusOne == 0) {
ctx.write(out.get(0), promise);
} else if (sizeMinusOne > 0) {
// Check if we can use a voidPromise for our extra writes to reduce GC-Pressure
// See https://github.com/netty/netty/issues/2525
ChannelPromise voidPromise = ctx.voidPromise();
boolean isVoidPromise = promise == voidPromise;
for (int i = 0; i < sizeMinusOne; i ++) {
ChannelPromise p;
if (isVoidPromise) {
p = voidPromise;
} else {
p = ctx.newPromise();
}
ctx.write(out.getUnsafe(i), p);
}
//写入下一个出站处理器
ctx.write(out.getUnsafe(sizeMinusOne), promise);
}
out.recycle();
}
}
}使用,子类实现钩子方法:
public class Integer2ByteEncoder extends MessageToByteEncoder<Integer> {
@Override
public void encode(ChannelHandlerContext ctx, Integer msg, ByteBuf out)
throws Exception {
// 原始数据
// 目标 bytebuf
out.writeInt(msg);
Logger.info("encoder Integer = " + msg);
}
}二. 来看看transform里面的编码器
我这里不讲一系列复杂的计算公式,核心用一个大家都能看的懂的例子来简单聊聊:
transform = 编码器+解码器
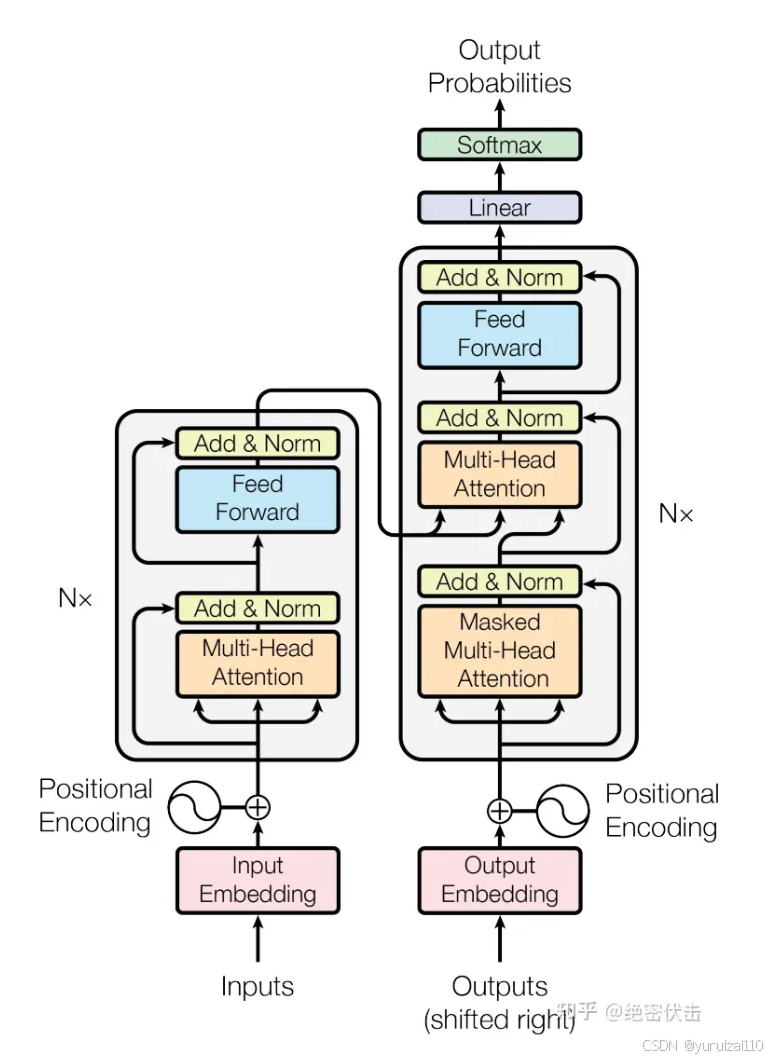
重点来看编码器:
可以看到编码器有多个,每一个编码器由是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。

编码器我觉得非常重要,它主要是理解输入信息的。
来看看它是怎样理解信息的:
1. 理解自注意力机制:多线程思维模式
举个例子:想象你是侦探,正在调查一起案件:需要同时分析:
- 现场照片(当前证据)
- 目击者口供(相关线索)
- 案犯档案(历史记录)
核心运作原理
| 步骤 | 侦探操作 | 对应技术术语 | 作用 |
| 1 | 标记线索重要性 | Generate Query Matrix | 确定需要重点调查的方向(如凶器类型) |
| 2 | 筛选关键证据 | Compute Key Matrix | 从现场提取与凶器相关的物证(如刀痕形状) |
| 3 | 整合有效信息 | Calculate Value Matrix | 结合口供和档案锁定嫌疑人 |
动态权重分配
假设案件有3个线索(A/B/C),自注意力会为每个线索分配关注强度:
关注度 = (A × 关注B的重要性) + (B × 关注C的重要性) + (C × 关注A的重要性)
数值越大 → 越需要重点关注该线索
自动学习 → 侦探会根据案件进展动态调整关注重点
总结一下:动态关注输入序列不同部分的能力。
2.理解 残差连接 + LayerNorm
举个例子:《给全班同学拍照》假设你是摄影师,既要拍出清晰的照片(保留原始信息),又要调整光线对比度(优化效果),最后还要把照片分享给全班同学(统一格式)。
2.1 残差连接(Residual Connection)
类比操作:拍照时直接复制一张底片备用
为什么要备份?
如果直接修改原图导致模糊(梯度消失),还可以用备份图恢复清晰画面
实际作用:
输出 = 当前处理结果 + 备份图
(数学表达式:y = F(x) + x)
2.2 LayerNorm(层归一化)
类比操作:调整照片的曝光度和对比度
具体步骤:
① 测量全班同学的身高平均值(计算均值μ)
② 统计身高差异程度(计算方差σ²)
③ 将每个人的身高调整到标准范围((身高-μ)/√σ²)
实际作用:
标准化处理 = (x - μ) / √(σ² + ε)
(ε是防止除零的小常数)
2.3 组合效果
拍照流程:
拍摄原始照片 → 备份底片(残差连接)
调整曝光 → 统一成班级标准格式(LayerNorm)
输出最终合影 → 全班同学都能看懂(稳定特征表示)
为什么要两者结合呢?
残差连接负责保留关键信息,LayerNorm负责优化信息格式
3.理解 前馈网络
示例:《班级春游策划书编写》,先做一份计划书:
- 收集信息(自注意力阶段完成的)
- 深度思考(前馈网络的使命)
- 输出成果(最终特征表示)
1. 输入特征
- 已获得的信息:
- 同学特长清单(词嵌入)
- 座位分布图(位置编码)
- 自注意力阶段的讨论记录(初步特征)
2.前缀过程
| 步骤 | 操作 | 技术原理 | 理解要点 |
|---|---|---|---|
| 第一步 | 信息扩展 | 第一层全连接(扩大信息维度) | 像把草稿纸写满初步想法 |
| 第二步 | 灵感迸发 | ReLU激活函数(非线性变换) | 像突然想到绝妙主意 |
| 第三步 | 精炼总结 | 第二层全连接(压缩信息维度) | 像把杂乱思路整理成条理清晰的提纲 |
3. 输出成果
- 最终计划书包含:
- 游玩路线规划(语义理解)
- 物资分配方案(语法结构)
- 应急预案(上下文关联)
为什么要有前缀网络?
前馈网络就像班级里的"智囊团",在收集基础信息后,通过深入分析和创造性思考,最终产出高质量的策划方案。
来吧,我以《班级春游策划书编写》完整理一下编码器的工作流程:
核心步骤:
1.输入嵌入
- 每个同学的信息卡(单词)都会被翻译成数字密码(词嵌入)
- 特别记录每位同学的特长(添加词性、情感等额外信息)
2.位置编码
- 给每个座位贴上独特的编号(位置编码)
- 这样班长就知道:"坐在窗边的小明"和"后排的小红"是不同的人
3.小组讨论会(自注意力机制)
- 每个同学轮流发言:
a. 全神贯注听老师讲话(Query=关注重点)
b. 记笔记抄黑板(Key=获取关键信息)
c. 整理发言稿(Value=整合有用内容) - 多头注意力就像同时开多个微信群聊:
关注天气的小红群
研究景点的历史群
讨论午餐的美食群
4.信息加工厂(前馈网络)
把收集的信息放进大脑深度思考:"小明的摄影爱好和景点拍照的关系"
5.质量检测员(LayerNorm & 残差连接)
- 检查处理后的信息有没有错误
- 如果发现遗漏重要内容(残差连接),就补充上之前的讨论记录
整个编码器就像班级春游的筹备流程:
1.收齐所有同学的特长和物品清单 → 输入嵌入
2.标记每个同学的位置 → 位置编码
3.每位同学同时倾听其他人的建议 → 自注意力
4.班长综合各方意见写计划 → 前馈网络
5.老师复查修改方案 → 层归一化和残差连接
梳理到这,你大概知道AI是怎么理解输入的。
好了,解码器就是对编码器理解后的输出。
总结一下,这期主要讲解了netty编码器的工作原理和transform编码器的工作原理。大家可以对比理解一下。