上手大模型应用LangChain
一、LangChain 框架总览
LangChain 是一个专为大语言模型(LLM)应用设计的开发框架,旨在帮助开发者将 LLM 与外部数据、工具和应用场景无缝集成。LangChain 的设计理念在于将复杂的模型调用流程模块化,并通过链式调用的方式将各个功能单元连接起来,形成一个高内聚低耦合的整体系统。这一架构优势使得开发者可以根据需求灵活组合各个模块,快速搭建从对话系统、问答机器人到复杂自动化任务的各类智能应用。
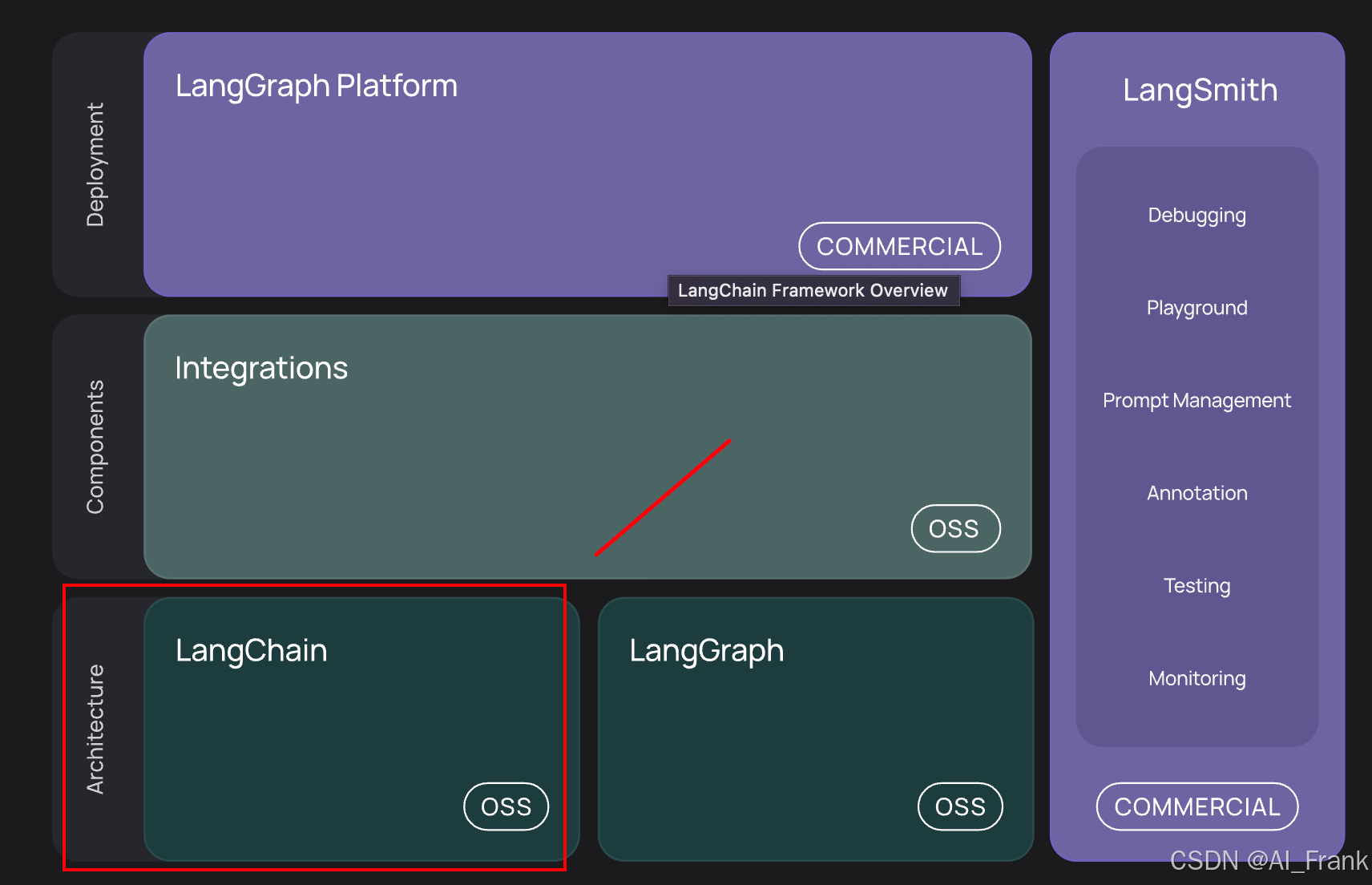
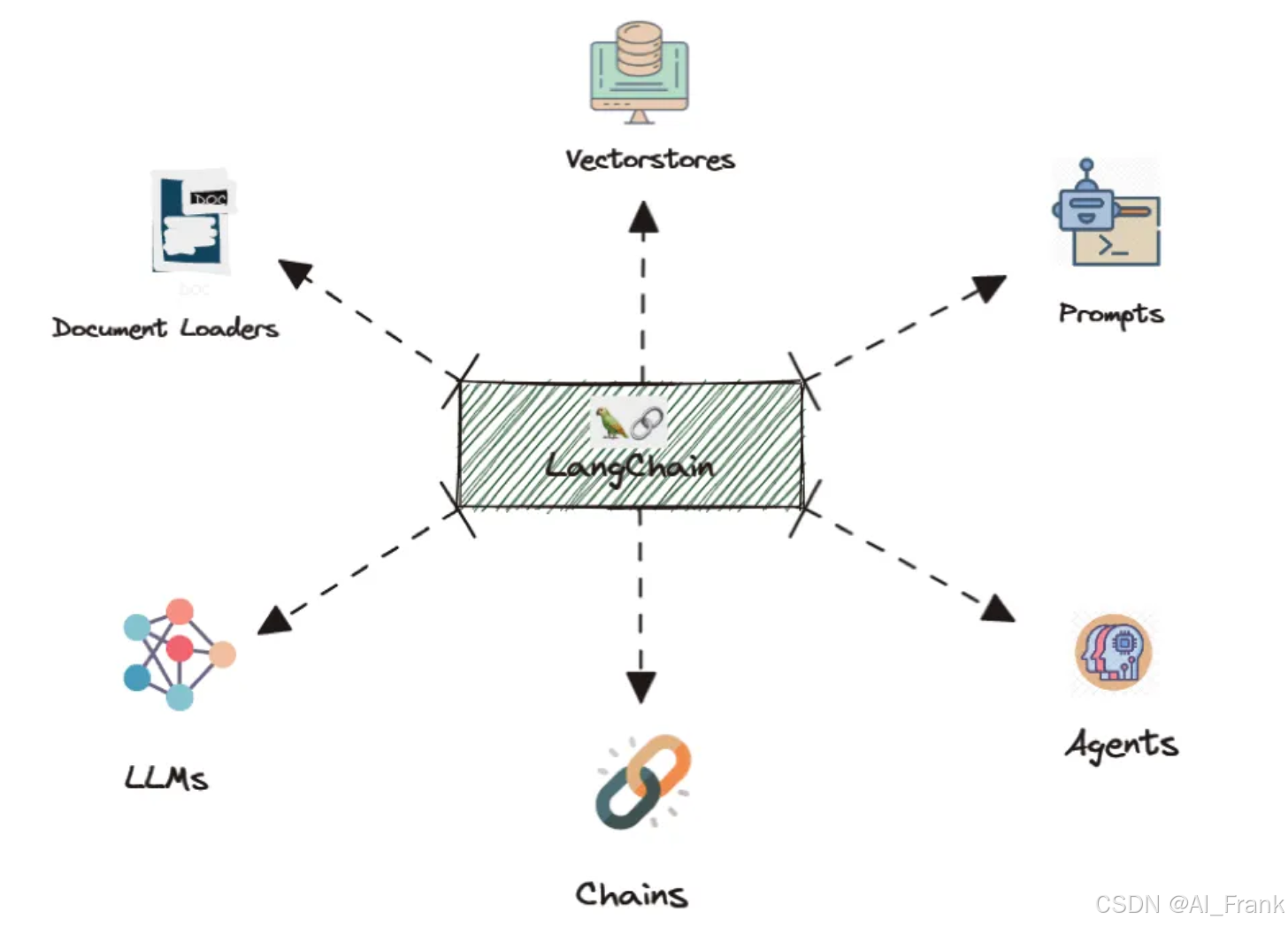
LangChain 框架主要包含以下几大核心模块:
- LLM Wrappers:对各大语言模型的 API 进行封装,实现统一接口调用,简化模型切换。
- Prompt Templates:通过模板化的方式构造动态提示词,支持灵活的上下文参数传入。
- Chains:将多个处理步骤(例如提示生成、模型调用、结果后处理)串联成一个完整流程,实现端到端的任务执行。
- Memory:用于存储和管理对话历史及上下文,确保连续对话的逻辑性和关联性。
- Retrieval-Augmented Generation (RAG):利用文档加载、向量化和检索技术,从外部知识库中获取相关信息,辅助生成更加准确、事实性更强的回答。
- Agents:提供高级智能体功能,自动决策调用不同工具或子链,实现多能力协同工作,适应复杂任务需求。
- Document Loaders 与 Vectorstores:用于从多种数据源加载文档并转换为向量,支撑语义搜索和知识库问答。
这种模块化设计理念使得 LangChain 不仅适用于简单的对话系统构建,更能扩展到复杂的多任务场景中,大大提升了大语言模型在各类实际应用中的灵活性和可靠性。
二、LangChain 模块详解
1. LLM Wrappers
功能与优势:
- 封装统一: 通过统一的接口封装不同提供商(如 OpenAI、Anthropic、Cohere 等)的 LLM API,使得调用方式保持一致,便于切换和扩展。
- 参数调优: 支持诸如
temperature、max_tokens、top_p等生成参数的灵活配置,帮助用户根据场景需求微调生成风格。
示例代码:
from langchain.llms import OpenAI
# 初始化 OpenAI 模型,设定temperature为 0.7
llm = OpenAI(temperature=0.7, openai_api_key="YOUR_OPENAI_API_KEY")
response = llm("请介绍一下 LangChain 框架。")
print(response)
通过 LLM Wrappers,开发者能够专注于业务逻辑,而不必过多关心底层 API 的差异。

2. Prompt Templates
功能与优势:
- 动态提示构造: 使用模板化的方式构造提示词,允许将动态变量(例如用户输入、上下文信息)注入模板中。
- 可维护性: 避免硬编码提示内容,便于后续修改和扩展,也方便统一管理提示词的风格和格式。
示例代码:
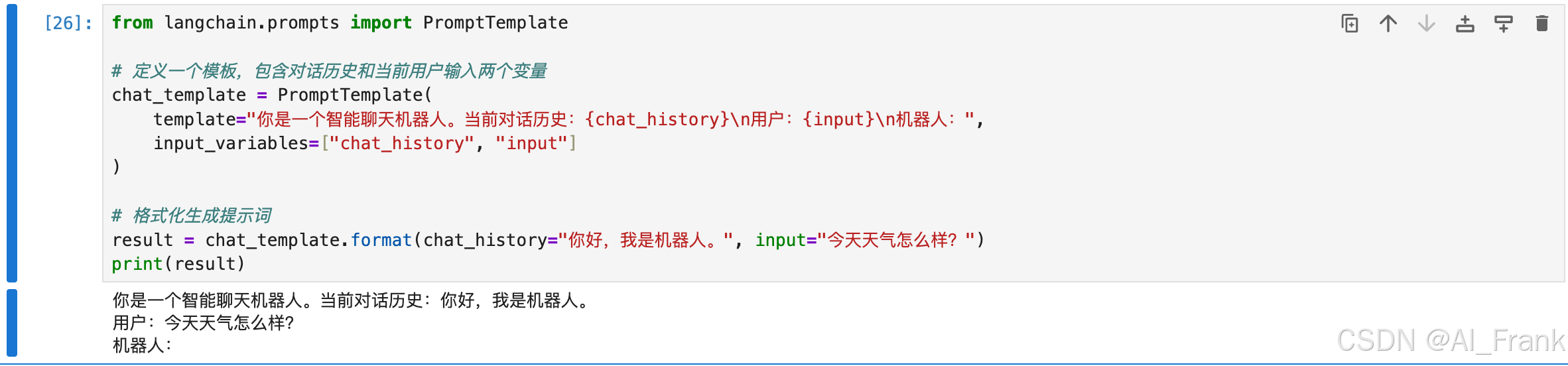
from langchain.prompts import PromptTemplate
# 定义一个模板,包含对话历史和当前用户输入两个变量
chat_template = PromptTemplate(
template="你是一个智能聊天机器人。当前对话历史:{chat_history}\n用户:{input}\n机器人:",
input_variables=["chat_history", "input"]
)
# 格式化生成提示词
result = chat_template.format(chat_history="你好,我是机器人。", input="今天天气怎么样?")
print(result)
这种方式使得提示词生成变得非常灵活,并且能够根据不同的场景动态调整。
3. Chains
功能与优势:
- 模块组合: 将多个模块(例如提示生成、模型调用、结果处理)串联起来,形成一个完整的执行流程。
- 复用性: 每个 Chain 都是一个独立的功能单元,可以单独测试和复用,同时多个 Chain 也可以嵌套组合,满足复杂业务逻辑需求。
示例代码:
from langchain.chains import LLMChain
# 将 LLM 与 Prompt Template 组合成一个对话链
chat_chain = LLMChain(llm=llm, prompt=chat_template)
response = chat_chain.predict(chat_history="之前的对话记录", input="请介绍一下 LangChain 的优势。")
print(response)
通过 Chains 模块,复杂的任务可以分解为多个简单步骤,每个步骤都经过精细设计和测试,从而形成高效稳定的整体流程。

4. Memory
功能与优势:
- 上下文管理: 在多轮对话中保存用户输入和机器人回复的历史记录,使得每次生成回答时都能参考前文上下文,保持对话连贯性。
- 多种实现: 支持基于内存缓冲、文件或数据库的持久化存储,开发者可根据实际需求选择合适的实现方式。
示例代码:
from langchain.memory import ConversationBufferMemory
# 使用对话缓冲记忆,存储对话历史信息
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
Memory 模块对于实现具有上下文感知的对话系统至关重要,它能够大幅提升生成回答的相关性和连贯性。
5. Retrieval-Augmented Generation(RAG)
功能与优势:
- 知识补充: 通过结合外部知识库,对用户输入进行向量检索,提取相关信息,并将其作为生成回答的上下文补充,提高回答的准确性与事实性。
- 流程概览: 包括文档加载、文本嵌入(向量化)、向量存储、相似度检索,再将检索到的文档与原始问题一起传递给 LLM 生成最终回答。
详细示例代码:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# 示例文档列表,实际项目中可从文件或数据库加载
texts = [
"LangChain 是一个用于构建大模型应用的框架,支持多模块整合。",
"RAG 技术通过向量检索提供外部知识,提升回答的准确性。",
"Agents 模块能够根据用户意图自动选择调用不同工具。"
]
# 生成嵌入,将文本转化为向量表示
embeddings = OpenAIEmbeddings(openai_api_key="YOUR_OPENAI_API_KEY")
vectorstore = FAISS.from_texts(texts, embeddings)
retriever = vectorstore.as_retriever()
# 构建基于检索的问答链
from langchain.chains import RetrievalQA
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# 测试 RAG 模块
response = rag_chain.run("请介绍一下 RAG 技术的优势。")
print(response)
通过 RAG 模块,聊天机器人可以在回答过程中引入外部文档信息,确保输出内容更具准确性和参考依据。

6. Agents 模块
功能与优势:
- 多能力整合: Agents 模块允许系统根据用户输入的意图自动选择调用不同的工具或子链,例如常规对话、知识检索、数据计算等。
- 自动决策: 利用零样本(zero-shot)技术,智能体能够理解输入语句的上下文,并选择最合适的处理方式,从而实现更复杂的任务。
详细示例代码:
from langchain.agents import initialize_agent, Tool
# 定义两个工具:一个用于常规聊天,一个用于知识检索(RAG)
tools = [
Tool(
name="Chat",
func=chat_chain.run, # 调用普通对话链
description="用于处理一般对话和交流。"
),
Tool(
name="KnowledgeRetrieval",
func=rag_chain.run, # 调用知识检索链
description="用于回答需要检索外部知识的问题。"
)
]
# 初始化智能体,自动决策选择工具
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
Agents 模块极大地增强了聊天机器人的灵活性,使得机器人在面对不同类型问题时能够自动调度最合适的模块进行处理。
7. Document Loaders 与 Vectorstores
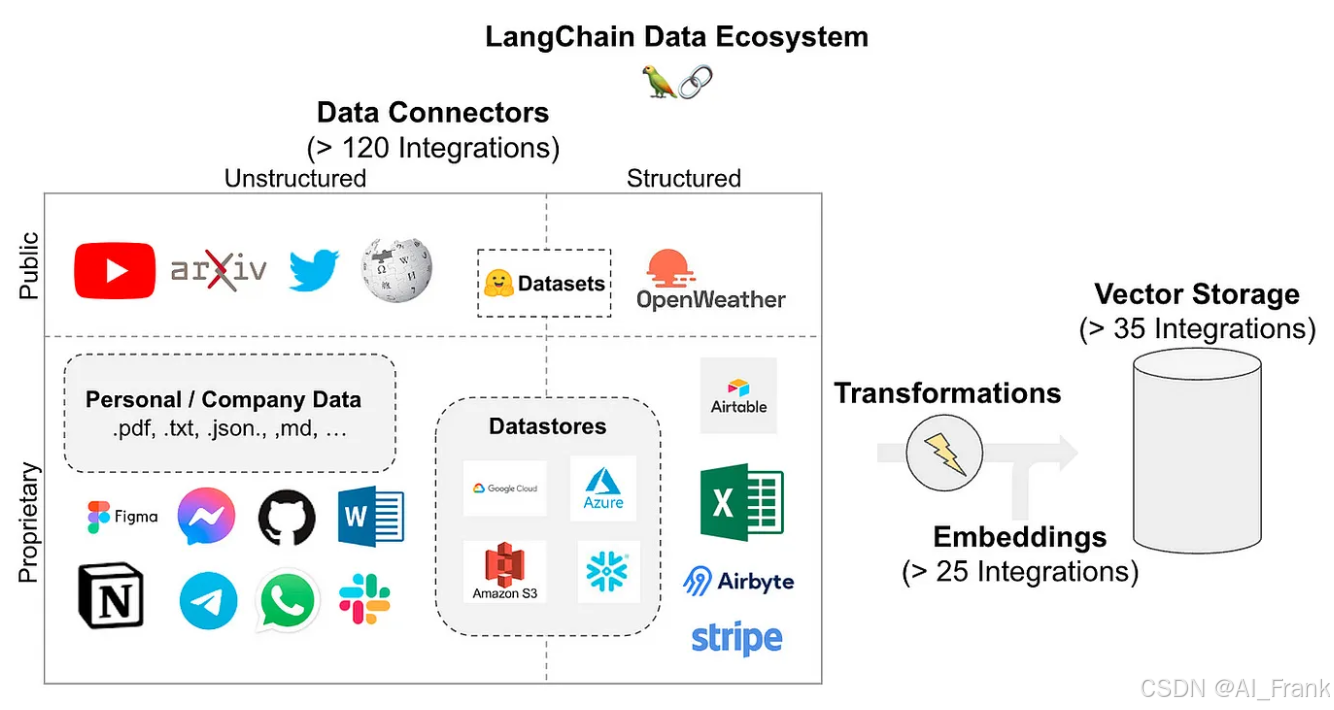
功能与优势:
- 文档加载: 提供多种数据源的接口,方便开发者将文件、网页、数据库等内容加载进来。
- 向量存储: 将文本数据通过嵌入模型转换为向量,并利用向量数据库(如 FAISS)实现高效的语义搜索。
下面给出一个详细的示例,演示如何使用 Document Loaders 从本地文档(例如文本文件或 PDF 文件)加载数据,并利用 Vectorstores(以 FAISS 为例)将文档转换为向量后实现语义搜索。这个示例既展示了如何加载文档,也演示了如何使用向量库进行相似度检索,帮助你构建基于知识库问答的系统。
示例代码:Document Loaders 与 Vectorstores 详细示例
# 导入必要模块
from langchain.document_loaders import TextLoader, PyPDFLoader # 支持加载文本和PDF
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# ----------------------------
# 1. 文档加载部分
# ----------------------------
# 示例1:加载本地文本文件
# 假设你有一个文本文件 "example.txt"
text_loader = TextLoader("example.txt")
documents_text = text_loader.load()
print("加载的文本文件内容:")
for doc in documents_text:
print(doc.page_content)
# 示例2:加载本地 PDF 文件
# 假设你有一个 PDF 文件 "example.pdf"
pdf_loader = PyPDFLoader("example.pdf")
documents_pdf = pdf_loader.load()
print("加载的 PDF 文件内容:")
for doc in documents_pdf:
print(doc.page_content)
# ----------------------------
# 2. 向量化与向量存储部分
# ----------------------------
# 使用 OpenAIEmbeddings 将文档转换为向量
# 请替换 YOUR_OPENAI_API_KEY 为你的实际 OpenAI API 密钥
embeddings = OpenAIEmbeddings(openai_api_key="YOUR_OPENAI_API_KEY")
# 将加载的文档(这里以文本文件为例)转换为向量存储
vectorstore = FAISS.from_documents(documents_text, embeddings)
# ----------------------------
# 3. 相似度检索示例
# ----------------------------
# 定义一个查询
query = "请介绍一下 LangChain 框架的优势。"
# 使用向量库进行相似度检索,获取与查询最相关的文档
results = vectorstore.similarity_search(query)
print("检索结果:")
for doc in results:
print(doc.page_content)
这些模块常常与 RAG 模块配合使用,构成一个强大的知识库问答系统。
三、整合示例代码:构建具备 RAG 与 Agents 能力的聊天机器人
以下示例代码将整合前面讲解的各个模块,构建一个能够自动判断并调用相应工具的多能力聊天机器人。
# 导入必要模块
from langchain_community.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, RetrievalQA
from langchain.memory import ConversationBufferMemory
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.agents import initialize_agent, Tool
# 1. 初始化语言模型(请替换 YOUR_OPENAI_API_KEY 为真实 API 密钥)
llm = OpenAI(temperature=0.7, openai_api_key="YOUR_OPENAI_API_KEY")
# 2. 设置常规聊天部分
chat_template = PromptTemplate(
template="你是一个智能聊天机器人。当前对话历史:{chat_history}\n用户:{input}\n机器人:",
input_variables=["chat_history", "input"]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
chat_chain = LLMChain(llm=llm, prompt=chat_template, memory=memory)
# 3. 设置 RAG 模块(知识检索部分)
# 构建简单知识库
texts = [
"LangChain 是一个用于构建大模型应用的框架。",
"RAG 能够利用知识库检索相关信息,提升回答准确性。",
"Agents 模块可以自动决策并调用不同工具完成复杂任务。"
]
embeddings = OpenAIEmbeddings(openai_api_key="YOUR_OPENAI_API_KEY")
vectorstore = FAISS.from_texts(texts, embeddings)
retriever = vectorstore.as_retriever()
# 构建知识检索链
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# 4. 定义 Agents 工具,将常规聊天和知识检索工具集成到智能体中
tools = [
Tool(
name="Chat",
func=chat_chain.run,
description="用于一般聊天和对话交流。"
),
Tool(
name="KnowledgeRetrieval",
func=rag_chain.run,
description="用于回答需要知识库检索的问题。"
)
]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
# 5. 启动聊天机器人,自动根据用户输入选择调用哪种工具
def multi_capability_chatbot():
print("欢迎使用多能力聊天机器人!输入 '退出' 结束对话。")
while True:
user_input = input("用户:")
if user_input.strip().lower() == "退出":
break
# 使用 agent 自动决策,选择调用 Chat 或 KnowledgeRetrieval 工具
response = agent.run(user_input)
print("机器人:", response)
if __name__ == "__main__":
multi_capability_chatbot()
代码解析
- 常规聊天部分:
利用PromptTemplate、LLMChain与ConversationBufferMemory构建基础对话链,记录对话上下文,实现连续对话。 - RAG 模块:
- 构造简单的知识库,将文本经过嵌入后存入 FAISS 向量库;
- 通过
RetrievalQA链实现基于检索的问答,适合处理需要外部知识支持的问题。
- Agents 模块:
- 定义两个工具:一个处理普通对话,一个调用知识检索链;
- 使用
initialize_agent创建智能体,基于用户输入自动决策调用哪个工具。 - 在交互过程中,智能体会根据输入内容判断问题是否需要知识库支持,从而调用相应工具,提升回答准确性与上下文关联性。
- 整合效果:
用户无需区分提问类型,只需自然对话,机器人便能智能判断并选择合适的回答方式,无论是日常对话还是需要检索外部知识的问题,都能给出较为准确和丰富的回答。
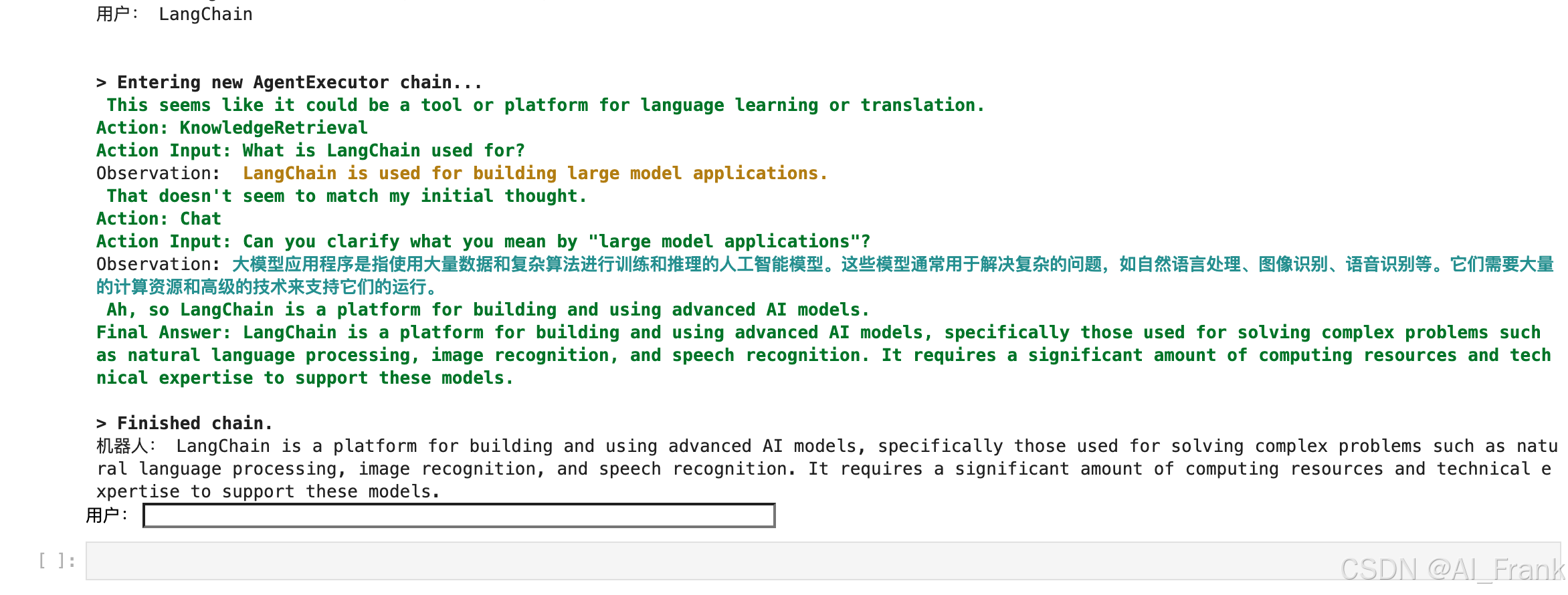
三、结语
通过本文,我们详细介绍了 LangChain 各模块的功能,包括新增的 RAG 模块和 Agents 模块,并展示了如何将它们整合到一个多能力聊天机器人中。这样的设计不仅实现了常规对话,还能利用知识库进行外部信息检索,从而为用户提供更准确、更上下文相关的回答。希望本文的示例和讲解能为您在大语言模型应用开发方面提供有价值的参考与启示,助力构建更加智能和灵活的对话系统。
注意:后续大家也可以接入其他LLM模型,详细细节可以参考官网:
langChain:https://python.langchain.com/docs/introduction/
llm模型汇总:https://huggingface.co/models