Spring Boot:分布式事务高阶玩法
01 Spring Boot 分布式事务高阶玩法:从入门到精通
这玩意儿就像大型活动的总调度,得确保活动里所有环节(操作)要么全顺利完成,要么全取消,绝对不能出现有的环节进行到一半、有的还没开始的混乱情况。
02 为啥要有分布式事务
在以前单体应用的场景里,事务处理就像在自己家里整理物品,所有数据都集中在一个地方,要保证操作的原子性很简单。
但随着业务复杂度提升,应用逐渐变成分布式架构,各个服务就像分散在不同房间的工作人员,这时候想让所有操作保持一致,就必须靠分布式事务这个“超级协调者”来解决问题了。
03 Spring Boot 里的分布式事务支持
Spring Boot 对分布式事务的支持,就像给开发者配备了一套全能工具包。
其中,@Transactional 注解大家肯定不陌生,在单体应用里它就是事务管理的“得力助手”。但到了分布式场景,我们还有更强大的方案,比如基于 XA 协议的分布式事务管理器,以及 Seata 这样的开源框架。
基于 XA 协议的方案
XA 协议就像一套国际通用的“沟通标准”,它明确了数据库和事务管理器之间该如何传递事务相关的信息。
在 Spring Boot 里使用 XA 协议的分布式事务管理器,相当于给各个服务的数据库都配了“专属翻译”,让它们能精准地同步事务状态。
下面来看一段实际代码示例:假设我们有订单服务和库存服务两个模块,需要实现“创建订单的同时扣减库存”,并且要保证这两个操作要么都成功,要么都失败。
首先,配置 XA 数据源(以 MySQL 为例):
public class XADataSourceConfig {// 1. 配置数据源基础属性(如URL、用户名、密码,可从配置文件读取)@Beanpublic DataSourceProperties dataSourceProperties() {return new DataSourceProperties();}// 2. 构建 XA 数据源,指定使用 MySQL 的 XA 实现类@Beanpublic DataSource dataSource(DataSourceProperties properties) {// 通过数据源属性构建器,设置 XA 数据源类型return properties.initializeDataSourceBuilder().type(com.mysql.cj.jdbc.MysqlXADataSource.class) // 关键:使用 MySQL XA 数据源.build();}
}
然后,配置分布式事务管理器:
public class XATransactionConfig {// 注入上面配置好的 XA 数据源@Autowiredprivate DataSource dataSource;// 配置 JTA 事务管理器(XA 协议的实现核心)@Beanpublic PlatformTransactionManager transactionManager() throws SQLException {// 1. 创建事务管理器工厂,关联 XA 数据源TransactionManagerFactory tmFactory = new TransactionManagerFactory(dataSource);// 2. 创建用户事务工厂,负责生成事务实例UserTransactionFactory utFactory = new UserTransactionFactory();// 3. 构建 JTA 事务管理器,整合上述两个工厂return new JtaTransactionManager(utFactory, tmFactory);}
}
最后,在业务代码中使用 @Transactional 注解开启事务:
@Service
public class OrderService {// 注入订单数据访问层(操作订单表)@Autowiredprivate OrderRepository orderRepository;// 注入库存服务(远程调用或本地调用,此处假设为本地服务)@Autowiredprivate StockService stockService;// 关键:添加 @Transactional 注解,声明该方法需要事务管理@Transactional(rollbackFor = Exception.class) // 遇到任何异常都回滚public void createOrder(Order order) {// 步骤1:保存订单(操作订单数据库)orderRepository.save(order);// 步骤2:扣减库存(操作库存数据库)stockService.decreaseStock(order.getProductId(), order.getQuantity());}
}
在这个例子里,createOrder 方法上的 @Transactional 注解就像“事务指挥官”,会协调“保存订单”和“扣减库存”两个操作,确保它们处于同一个分布式事务中,要么全成功,要么全回滚。
基于 Seata 框架的方案
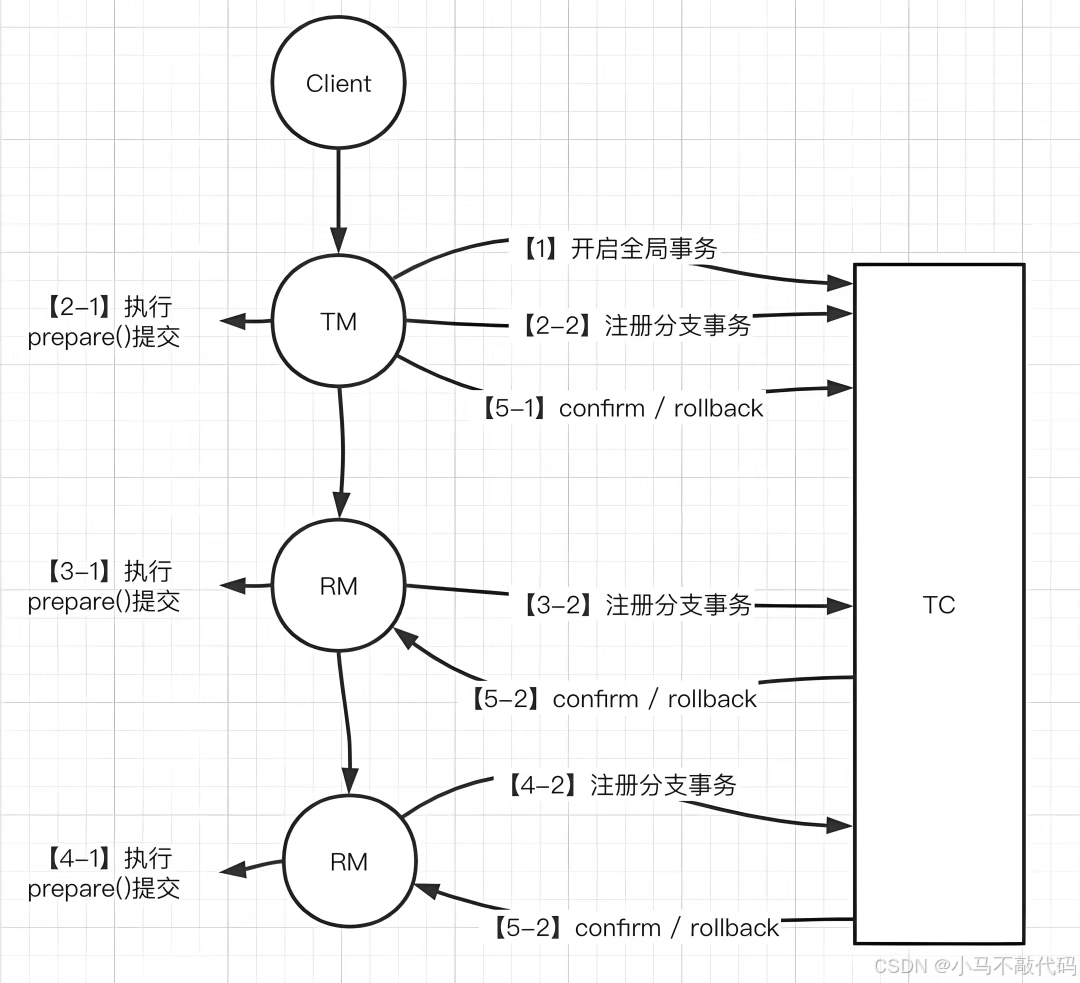
Seata 就像一个更智能、更灵活的“分布式事务指挥官”,它有三个核心组件:
• TC(Transaction Coordinator):事务协调器,相当于“调度中心”,负责管理全局事务状态;
• TM(Transaction Manager):事务管理器,负责发起和控制全局事务的生命周期;
• RM(Resource Manager):资源管理器,负责管理数据库资源,执行本地事务的提交或回滚。
使用 Seata 实现分布式事务,步骤如下:
首先,在项目的 pom.xml 中引入 Seata 依赖:
<!-- 引入 Spring Cloud Alibaba Seata 依赖,整合 Seata 与 Spring Boot -->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId><!-- 建议指定版本,与 Seata 服务器版本保持一致 --><version>2.2.6.RELEASE</version>
</dependency>
然后,在 application.yaml 中配置 Seata 客户端:
seata:# 1. 应用唯一标识,与 Spring 应用名保持一致application-id: ${spring.application.name}# 2. 事务分组,需与 Seata 服务器配置的分组一致tx-service-group: my_test_tx_group# 3. 开启数据源自动代理(Seata 实现事务拦截的关键)enable-auto-data-source-proxy: true# 4. 客户端详细配置client:rm: # 资源管理器配置async-commit-buffer-limit: 10000 # 异步提交缓冲区大小lock: # 锁相关配置retry-interval: 10 # 锁重试间隔(毫秒)retry-times: 30 # 锁重试次数retry-policy-branch-rollback-on-conflict: true # 冲突时回滚分支事务tm: # 事务管理器配置commit-retry-count: 5 # 提交重试次数rollback-retry-count: 5 # 回滚重试次数undo: # undo 日志配置(用于事务回滚)data-validation: true # 数据校验(防止脏写)log-serialization: jackson # 日志序列化方式log-table: undo_log # 存储 undo 日志的表名
最后,在业务代码中使用 @GlobalTransactional 注解开启全局事务:
@Service
public class OrderService {@Autowiredprivate OrderRepository orderRepository;@Autowiredprivate StockService stockService;// 关键:使用 @GlobalTransactional 注解,声明全局分布式事务@GlobalTransactional(rollbackFor = Exception.class)public void createOrder(Order order) {// 步骤1:保存订单(本地事务)orderRepository.save(order);// 步骤2:调用库存服务扣减库存(远程事务分支)stockService.decreaseStock(order.getProductId(), order.getQuantity());}
}
这里的 @GlobalTransactional 注解就像“全局事务圣旨”,会通知所有涉及的服务(订单服务、库存服务),让它们按照 Seata 的规则协同执行,确保全局事务的一致性。
04 总结
分布式事务虽然逻辑复杂,但有了 Spring Boot 提供的基础支持,再加上 Seata 这样成熟的框架,开发者也能轻松应对。
这就像掌握了一门“系统稳定性魔法”,能让我们的分布式系统更可靠、更少出问题。