AI原生应用架构白皮书 - AI应用开发框架及上下文工程
AI应用开发框架及上下文工程
- 一、AI应用开发框架:从单智能体到多智能体协同
- 1.1 智能体的定义与核心开发范式
- 1.2 单智能体:基础架构与实践挑战
- 1.2.1 单智能体架构特点
- 1.3 工作流:确定性流程编排
- 1.3.1 链式工作流(Chain)
- 1.3.2 路由工作流(Routing)
- 1.3.3 并行工作流(ParallelAgent)
- 1.3.4 循环工作流(LoopAgent)
- 1.4 多智能体系统:自主协作与动态决策
- 1.4.1 典型模式:LLM Routing Agent
- 1.4.2 多智能体开发关键考量
- 二、从单进程到分布式:智能体的规模化部署
- 2.1 分布式智能体的核心驱动力
- 2.2 A2A协议:分布式智能体的“通信标准”
- 2.2.1 A2A协议核心角色与元素
- 2.2.2 A2A协议工作流程
- 三、消息驱动的智能体开发:应对AI场景的异步挑战
- 3.1 AI场景对消息队列的特殊需求
- 3.2 核心优化:轻量级主题(Lite-Topic)
- 3.3 智能资源调度:优先级与定速消费
- 四、上下文工程:超越提示词,构建AI的“动态认知环境”
- 4.1 上下文工程与提示词工程的核心差异
- 4.2 核心组件:构建动态认知环境
- 4.3 RAG技术:上下文工程的核心支撑
- 4.3.1 RAG基础范式
- 4.3.2 RAG工程化挑战与优化
- 4.4 RAG的未来方向:从事实检索到推理智能
- 4.5 上下文管理与记忆系统
- 总结
在AI原生应用的技术体系中,开发框架决定了智能体的“骨架”,上下文工程则赋予其“灵活思考”的能力。《AI原生应用架构白皮书》系统拆解了智能体开发范式、分布式部署方案及上下文工程的核心技术,本文将提炼核心内容,带您掌握从智能体构建到上下文优化的全流程实践逻辑。
一、AI应用开发框架:从单智能体到多智能体协同
AI应用开发框架围绕“智能体(Agent)”构建,根据任务复杂度衍生出不同开发范式,核心目标是解决大模型“不确定性”与业务“确定性需求”的矛盾。
1.1 智能体的定义与核心开发范式
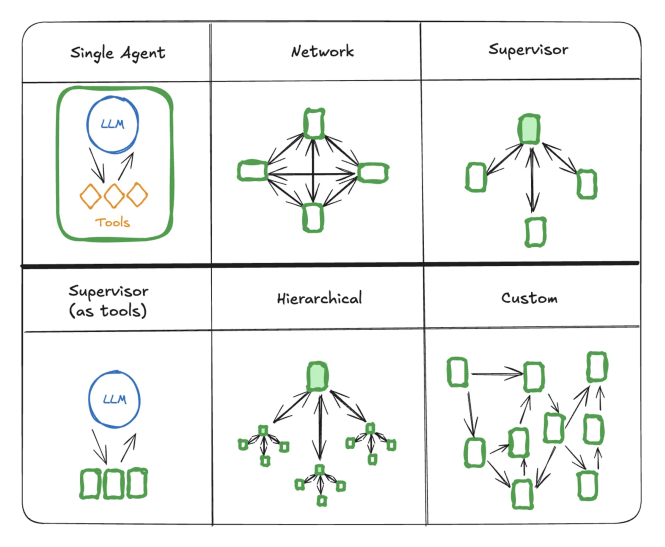
智能体是具备自主理解、规划、记忆、工具使用能力的数字化实体,例如“规划北京周末旅行”的智能助理,可自主拆解任务(查机票、选酒店)、调用工具(预订API)、结合记忆(用户偏好)完成目标。其主流开发范式分为四类,核心差异在于任务拆分与协作方式:
| 开发范式 | 核心逻辑 | 适用场景 | 局限性 |
|---|---|---|---|
| 简单LLM应用 | 直接调用模型API生成内容,无外部交互能力 | 基础内容生成(如写文案、问答) | 无记忆、无工具,无法应对复杂任务 |
| 单智能体(Single Agent) | 为LLM添加RAG(知识库)、Tool(工具)、Memory(记忆),形成“增强型LLM” | 场景化交互(如智能客服、个人助理) | 工具过多时决策混乱,复杂任务可维护性差 |
| 工作流(Workflow) | 将复杂任务拆分为有序步骤,按预定义流程编排子智能体 | 流程固定的任务(如生成调研报告、审核文章) | 灵活性低,无法应对动态任务分支 |
| 多智能体系统(Multi-Agent) | 多个子智能体自主协作,通过模型决策流程(非固定规则) | 跨领域复杂任务(如软件开发、科学研究) | 调试难度高,交互路径不可预测 |
1.2 单智能体:基础架构与实践挑战
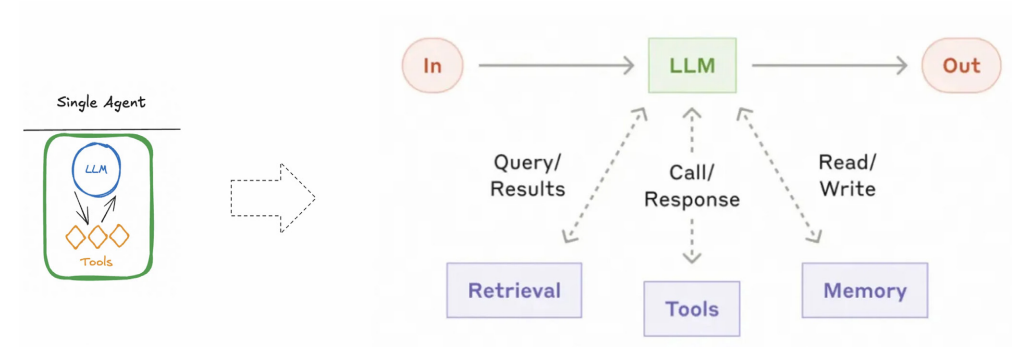
单智能体是AI应用的“最小功能单元”,架构核心是**“LLM为脑,RAG+Tool+Memory为辅助”**,即通过外部组件弥补大模型“知识固化、无状态、无工具”的局限。
1.2.1 单智能体架构特点
- 简单性:无需拆分任务,开发者仅需将工具、知识库等上下文传递给模型,由模型自主决策;
- 依赖性:性能高度依赖底层模型能力,需模型具备精准的工具选择、推理规划能力;
- 局限性:面对复杂场景易暴露问题,例如“工具过多导致决策混乱”“多轮对话上下文膨胀(Token消耗高)”“专业任务(如代码生成)能力不足”。
1.3 工作流:确定性流程编排
工作流通过预定义步骤编排多个子智能体,核心是“可控性”,适合流程清晰、对稳定性要求高的场景。主流工作流类型包括:
1.3.1 链式工作流(Chain)
- 逻辑:将任务拆分为连续子步骤,上一步输出作为下一步输入,形成“流水线”;
- 示例:生成文章→翻译→审核(先由“写作智能体”生成初稿,再由“翻译智能体”转英文,最后“审核智能体”校验);
- 优势:步骤透明,易调试,确保任务按序执行。
1.3.2 路由工作流(Routing)
- 逻辑:先对输入分类,再路由到对应子智能体,实现“分而治之”;
- 示例:客服系统中,将“普通咨询”路由到基础问答智能体,“退款请求”路由到财务处理智能体,“技术问题”路由到工程师智能体;
- 优势:精准匹配能力,降低单一智能体的复杂度,同时可按问题复杂度分配模型(简单任务用小模型,复杂任务用大模型)。
1.3.3 并行工作流(ParallelAgent)
- 逻辑:多个子智能体同时执行任务,结果汇总后输出;
- 示例:智能搜索助手,同时调用“AI领域搜索智能体”和“微服务领域搜索智能体”,再由“汇总智能体”合并结果;
- 优势:提升任务处理效率,适合多领域信息并行获取场景。
1.3.4 循环工作流(LoopAgent)
- 逻辑:子智能体循环执行,直至满足终止条件(如迭代次数、结果达标);
- 示例:文章优化任务,“写作智能体”生成初稿→“审核智能体”提出修改意见→循环迭代3次后输出最终版本;
- 优势:支持迭代优化,适合需要反复打磨的任务。
1.4 多智能体系统:自主协作与动态决策
多智能体系统是“团队协作模式”,每个子智能体有专属角色(如产品经理、程序员、测试工程师),通过模型驱动的动态流程协作,而非固定规则。其核心差异在于**“自主性”**:工作流是“按剧本演戏”,多智能体是“按目标自主协作”。
1.4.1 典型模式:LLM Routing Agent
由大模型决策“下一步调用哪个子智能体”,实现动态流程调度:
- 示例:“文章/诗歌生成系统”中,用户输入“写关于西湖的内容”,LLM Routing Agent先判断需求类型(散文/诗歌),再路由到“散文智能体”或“诗歌智能体”;
- 优势:灵活应对模糊需求,无需预定义所有流程分支;
- 挑战:模型决策可能出错,需通过Prompt优化(明确子智能体能力描述)提升准确性。
1.4.2 多智能体开发关键考量
- 角色定义:为每个子智能体明确职责(如“写作智能体负责生成初稿,审核智能体负责校验逻辑”);
- 通信协议:规定子智能体间的信息传递格式(如输出Key、上下文字段);
- 冲突处理:通过“监督智能体(Supervisor)”协调子智能体分歧(如两个智能体生成的内容冲突时,由监督智能体决策)。
二、从单进程到分布式:智能体的规模化部署
当智能体应用在企业内规模化落地时,单进程架构面临“团队协作效率低、维护成本高”的问题,需向分布式架构演进,核心依赖A2A协议(Agent2Agent)实现跨进程智能体通信。
2.1 分布式智能体的核心驱动力
- 组织架构适配:类似微服务从单体拆分,不同团队可独立开发、维护子智能体(如财务团队维护“报销智能体”,HR团队维护“招聘智能体”);
- 性能与可扩展性:独立部署子智能体可避免单进程资源瓶颈,支持按需扩容(如“高峰期为客服智能体增加实例”);
- 技术栈解耦:不同子智能体可使用不同技术栈(如Python开发NLP智能体,Java开发业务智能体),无需统一语言。
2.2 A2A协议:分布式智能体的“通信标准”
A2A协议是Google推出的开放标准,解决“异构智能体协同”问题,类似AI领域的“USB-C接口”,实现不同团队、不同技术栈智能体的高效通信。
2.2.1 A2A协议核心角色与元素
-
核心角色:
- 用户(User):发起任务请求的最终使用者;
- A2A客户端(Client Agent):代表用户调用远端智能体的应用/服务;
- A2A服务端(Remote Agent):提供服务的远端智能体,以“黑盒”形式运行(客户端无需感知其内部逻辑)。
-
核心元素:
- Agent Card(智能体卡片):JSON格式的“数字名片”,包含智能体名称、服务地址、支持功能、鉴权方式(如
https://agent.example.com/.well-known/agent-card.json),客户端通过解析卡片发现并交互; - Task(任务):状态化长任务的载体(如“生成月度报告”),包含唯一ID和生命周期(提交→处理中→完成);
- Message(消息):单次通信的基本单元(如“查询天气”),支持文本、文件、结构化数据;
- Artifact(产出物):任务完成后的结果(如文档、图表),支持流式传输。
- Agent Card(智能体卡片):JSON格式的“数字名片”,包含智能体名称、服务地址、支持功能、鉴权方式(如
2.2.2 A2A协议工作流程
- 发现Agent Card:客户端通过注册中心、固定URI获取远端智能体的Agent Card;
- 授权认证:按Agent Card声明的鉴权方式(如OAuth2、API密钥)获取Token;
- 发起请求:
- 同步请求:通过
message/send接口发送单次消息,实时获取响应; - 流式请求:通过
message/stream接口建立长连接,实时接收任务进度(如“报告生成到30%”)。
- 同步请求:通过
三、消息驱动的智能体开发:应对AI场景的异步挑战
传统消息队列(如RocketMQ、Kafka)无法满足AI场景“长会话、大消息、优先级调度”的需求,需针对性优化,核心是**“轻量级主题(Lite-Topic)”** 与“智能资源调度”。
3.1 AI场景对消息队列的特殊需求
- 长会话隔离:AI对话可能持续数小时,需避免会话上下文丢失;
- 大消息传输:多模态交互(如上传图片、长文档)需支持数十MB消息;
- 资源调度:GPU算力昂贵,需优先处理高价值任务(如VIP用户请求)。
3.2 核心优化:轻量级主题(Lite-Topic)
RocketMQ针对AI场景提出“为每个会话动态创建独立主题”的方案,例如为“用户A的北京旅行规划会话”创建chatbot/session-A主题,所有对话历史、工具结果均在该主题中流转:
- 优势:
- 会话隔离:避免不同会话上下文混淆;
- 持久化:连接中断后可从主题中恢复上下文,避免GPU算力浪费;
- 性能无损:单集群支持百万级Lite-Topic,并发无压力。
3.3 智能资源调度:优先级与定速消费
- 削峰填谷:缓存突发请求(如高峰期客服咨询),让AI服务按算力自适应消费,避免服务崩溃;
- 定速消费:为消费者组设置每秒调用配额(如“每秒调用模型10次”),最大化GPU利用率;
- 优先级调度:标记高价值任务(如VIP用户请求)为高优先级消息,优先消费,保障核心业务体验。
四、上下文工程:超越提示词,构建AI的“动态认知环境”
提示词工程仅优化“单次交互指令”,而上下文工程是**“系统级方案”**,通过动态整合外部知识、记忆、工具,为大模型构建“思考所需的完整认知环境”,解决提示词工程的固有局限(如动态任务适配、长上下文利用低效)。
4.1 上下文工程与提示词工程的核心差异
| 维度 | 提示词工程 | 上下文工程 |
|---|---|---|
| 核心目标 | 优化单次指令,获取最佳输出 | 构建动态认知环境,确保推理准确性与可靠性 |
| 工作范围 | 单轮/有限多轮交互 | 整合多源数据(知识库、记忆、工具) |
| 关键技术 | 指令设计、角色扮演、范例引导 | RAG、向量数据库、记忆管理、工作流编排 |
| 本质 | “术”:提升单次沟通效率 | “道”:构建AI持续解决问题的系统框架 |
4.2 核心组件:构建动态认知环境
上下文工程通过四大组件协同,为大模型提供“思考素材”:
- 外部知识库:通过RAG技术接入实时/私有知识(如企业文档、互联网信息),解决大模型“知识陈旧”问题;
- 记忆系统:短期记忆(当前对话上下文)保障多轮流畅性,长期记忆(用户偏好、历史任务)实现个性化;
- 工具扩展:为模型提供API/函数调用能力(如查天气、调数据库),突破“仅文本生成”的局限;
- 运行时管理:通过上下文压缩(摘要)、重排(解决“中间遗忘”),高效利用有限的上下文窗口。
4.3 RAG技术:上下文工程的核心支撑
RAG(检索增强生成)是“为大模型开卷考试”,通过“索引→检索→生成”三阶段,让模型基于外部知识库生成准确答案,解决大模型“知识滞后、幻觉、缺乏私域知识”的问题。
4.3.1 RAG基础范式
- 索引阶段(Indexing):将非结构化知识转化为可检索格式;
- 文档解析:提取PDF/Word等格式的文本内容;
- 文本分块:将长文档切分为语义完整的“块”(如按段落、按语义边界);
- 语义向量化:通过Embedding模型(如Qwen3-Embedding)将文本块转化为向量,存入向量数据库;
- 检索阶段(Retrieval):匹配用户查询与知识库;
- query向量化:用户查询通过相同Embedding模型转化为向量;
- 相似度搜索:在向量数据库中查找与query最相似的Top-K文本块;
- 生成阶段(Generation):整合检索结果生成答案;
- 构建增强Prompt:将检索到的文本块与用户query结合(如“根据以下上下文回答问题:[文本块1][文本块2] 问题:[用户query]”);
- 模型生成:LLM基于增强Prompt生成答案,确保事实准确性。
4.3.2 RAG工程化挑战与优化
- 知识单元完整性:
- 问题:固定分块易截断逻辑(如拆分表格、代码块);
- 优化:采用“语义分块”(通过Embedding计算句子相似度,在语义断裂处拆分)、“父子块映射”(索引时存子块,生成时用完整父块);
- 查询理解模糊:
- 问题:用户查询口语化(如“AI原生应用咋回事”),与知识库术语不匹配;
- 优化:query改写(LLM将模糊查询转化为精准表述,如“AI原生应用的核心特征是什么”)、复杂问题分解(将“对比A/B产品”拆分为“查A性能→查B性能→对比差异”);
- 检索精度与效率平衡:
- 问题:向量检索擅长语义匹配,但不擅长精确查询(如产品型号);
- 优化:混合检索(向量检索+关键词检索)、重排序(用交叉编码器对召回结果二次打分,提升精准度)。
4.4 RAG的未来方向:从事实检索到推理智能
RAG正从“静态检索工具”向“智能知识基础设施”演进,核心方向包括:
- Agentic RAG:让Agent自主决策是否检索、何时检索(如“先判断自身知识是否足够,不足则触发检索”),适合动态复杂任务;
- 多模态RAG:支持图像、音频、视频等非文本知识检索(如“以图搜商品”“检索视频片段”),解锁多模态知识资产价值;
- 知识图谱融合:结合知识图谱的结构化关系(如“糖尿病→并发症→肾病”),实现多跳推理,提升回答的逻辑性与可解释性(适合医疗、法律场景)。
4.5 上下文管理与记忆系统
智能体需“记住过去、规划未来”,依赖多级记忆系统与运行时策略:
- 多级记忆系统:
- 短期记忆:管理当前会话上下文(如最近5轮对话),通过滑动窗口、关键信息保留优化Token消耗;
- 长期记忆:存储跨会话知识(如用户偏好“喜欢靠窗机票”),通过定期摘要(每5轮对话总结一次)从短期记忆提取;
- 运行时上下文处理策略:
- 写入(Write):将中间结果、记忆存入外部存储;
- 选择(Select):精准召回与当前任务相关的记忆、工具;
- 压缩(Compress):对冗长上下文摘要,减少Token消耗;
- 隔离(Isolate):多智能体独立上下文窗口,避免干扰。
总结
AI应用开发框架与上下文工程是AI原生应用的“双核”:框架决定了智能体的“协作模式”,从单智能体的基础交互到多智能体的分布式协同,解决了“如何组织AI能力”的问题;上下文工程则赋予了智能体“思考能力”,通过RAG、记忆系统构建动态认知环境,解决了“如何让AI可靠决策”的问题。
未来,随着Agentic RAG、多模态融合等技术的成熟,AI原生应用将从“工具级助手”升级为“系统级伙伴”,而掌握开发框架与上下文工程的核心逻辑,是企业把握AI规模化落地机遇的关键。