实测Triton-Copilot:AI如何助力高性能算子开发
文章简介
在高性能计算与AI模型规模急剧扩张的当下,手写高性能算子的开发周期长、技术门槛高,已成为制约研发效率的关键瓶颈。本文应FlagOS团队邀请,对其新在节前开放的 Triton-Copilot 项目进行深度体验。它并非一个简单的代码生成工具,而是一个旨在通过 “多层级Agent驱动” 与 “人机协同验证闭环” 来实现系统软件开发范式变革的平台。[1]
本文将从一个不具备Pytorch和Triton专家知识的开发者视角出发,通过完整的矩阵加法实例,从自然语言的想法出发到交付功能正确、经过性能验证的Triton代码,从而体现开发效率的变革。
我们期待以此文与社区同行交流,共同探索。
项目主页 https://triton-copilot.baai.ac.cn/
一、 引言:直面高性能算子开发的效率瓶颈
高性能GPU算子是现代AI模型的基石,但其开发长期面临严峻挑战:依赖资深工程师、手写代码周期长(通常需1-2天)、且调试优化门槛极高。这一效率瓶颈,正随着模型复杂度的提升而日益凸显。[1]
我们近期受FlagOS团队委托,体验了其旨在解决这一问题的开源项目——Triton-Copilot。该项目的愿景远超一个辅助工具,它试图构建一个多层级、Agent驱动的软件栈,以期从根本上变革FlagOS的开发效率范式。[1]
值得一提的是,笔者本人并非Triton或PyTorch的领域专家,这一背景或许更能代表面临性能优化挑战的广大应用层开发者,从而客观评估其易用性与实用性。相对应的,笔者就相关代码生成过程询问了DeepSeek和官方文档作为对比测试。
二、 Triton-Copilot项目介绍[1]
正式开始之前,有必要先理解Triton-Copilot的架构设计与核心思想。它将自己定位为一个完整的算子开发自动化平台,其系统架构主要分为四层:
- 基建层:提供底层的开发工具集、智能Wiki和知识库,为Agent的运行提供环境与知识支撑。
- Agent层:作为系统的调度中枢,负责管理、记忆与协同多个AI智能体。
- 应用层:封装了算子生成、迁移优化、工程集成等关键研发流程。
- 产品层:直接面向用户,提供如“算子Agent”等具体服务。
其核心优势与差异化特性在于:
- 人机协同工作流:采用
Ground Truth + AI生成 + 验证 + 循环修正的流程,将人类经验与AI能力结合,确保代码正确性。 - 自动性能对比:能在多版本实现中自动进行性能评测,辅助开发者锁定最优解。
- 跨芯片支持:依托底层FlagTree架构,目前已支持Nvidia GPU与天数GPU,用户可通过Web界面无缝切换,实现了算子开发的硬件无关性。
- 工程落地性强:流程完整且自动化程度高,兼具开发效率与大规模部署的便利性。
三、 实战演练:剖析“人机协同”的完整工作流
我们以最基础的矩阵加法算子为例,完整走通Triton-Copilot的六个开发阶段,该流程完美体现了其“人机协同”的设计哲学。
第一阶段:算子信息收集
在Web界面中,我们通过自然语言描述需求:“帮我生成一个加法算子”。系统会引导我们结构化地定义输入参数(如矩阵尺寸M、N,数据类型dtype),形成明确的算子开发目标。
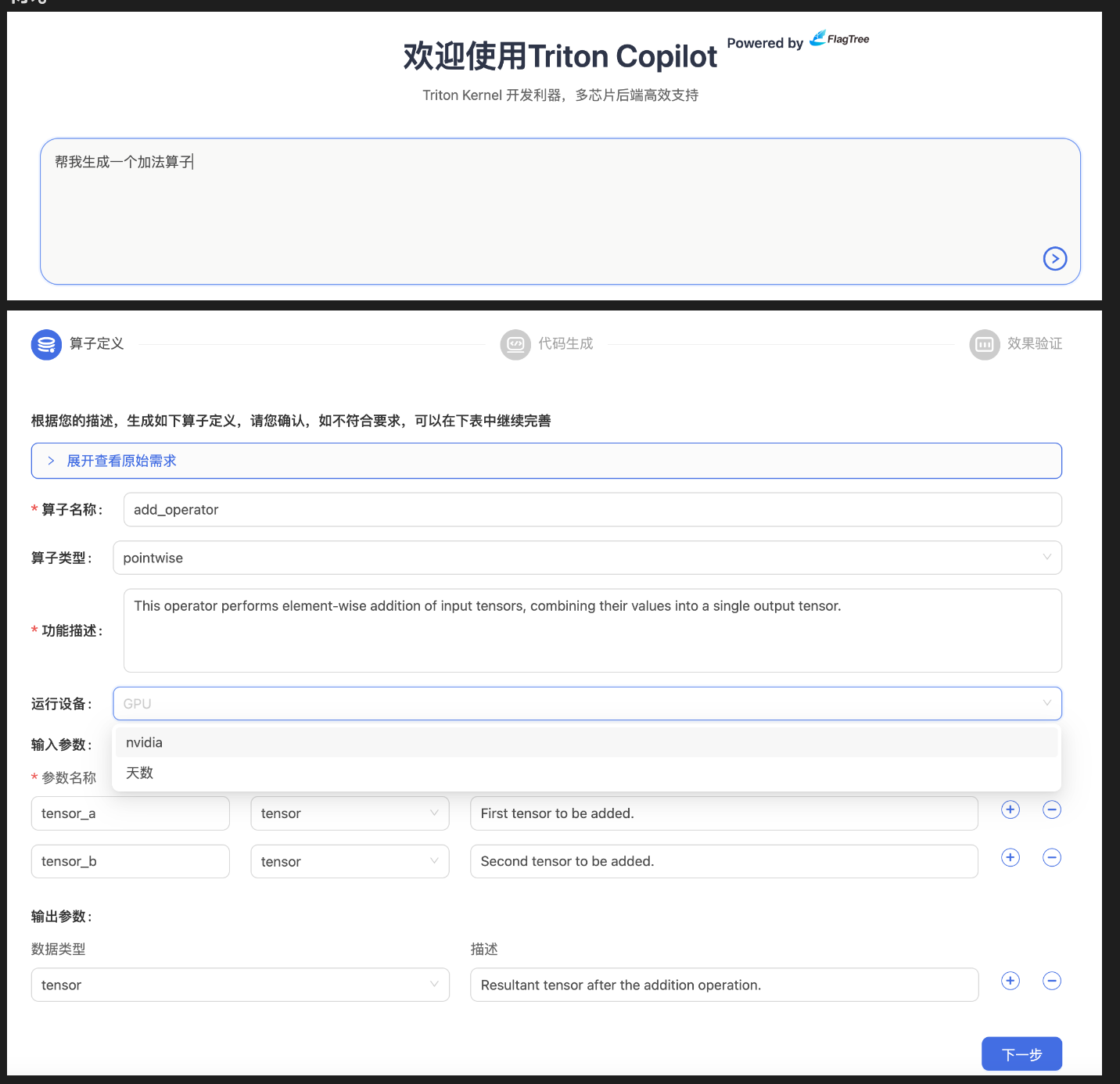
在这里你可以选择英伟达或者天数的GPU。
第二阶段:Ground Truth 代码生成
系统首先基于PyTorch自动生成一个标准实现。该实现将作为后续功能验证与性能对比的基准,确保逻辑正确性。
横向对比:对Triton-Copilot给出的代码,DeepSeek给出的代码和pytorch官网的信息进行交叉比对。由于pytorch已经实现了加法,因此,这里考察的是一个已有算子的调用工作。
Triton-Copilot给出的
import torchdef add_operator(tensor_a, tensor_b):return torch.add(tensor_a, tensor_b)
DeepSeek给出的
Q: 帮我使用pytorch内置函数生成一个加法算子
class TorchAdd(nn.Module):def __init__(self, alpha=1.0):super(TorchAdd, self).__init__()self.alpha = alphadef forward(self, x, y):return torch.add(x, y, alpha=self.alpha)# 使用示例
add_op = TorchAdd()
a = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
b = torch.tensor([[0.5, 1.0], [1.5, 2.0]])
result = add_op(a, b)
print(f"torch.add 结果:\n{result}")
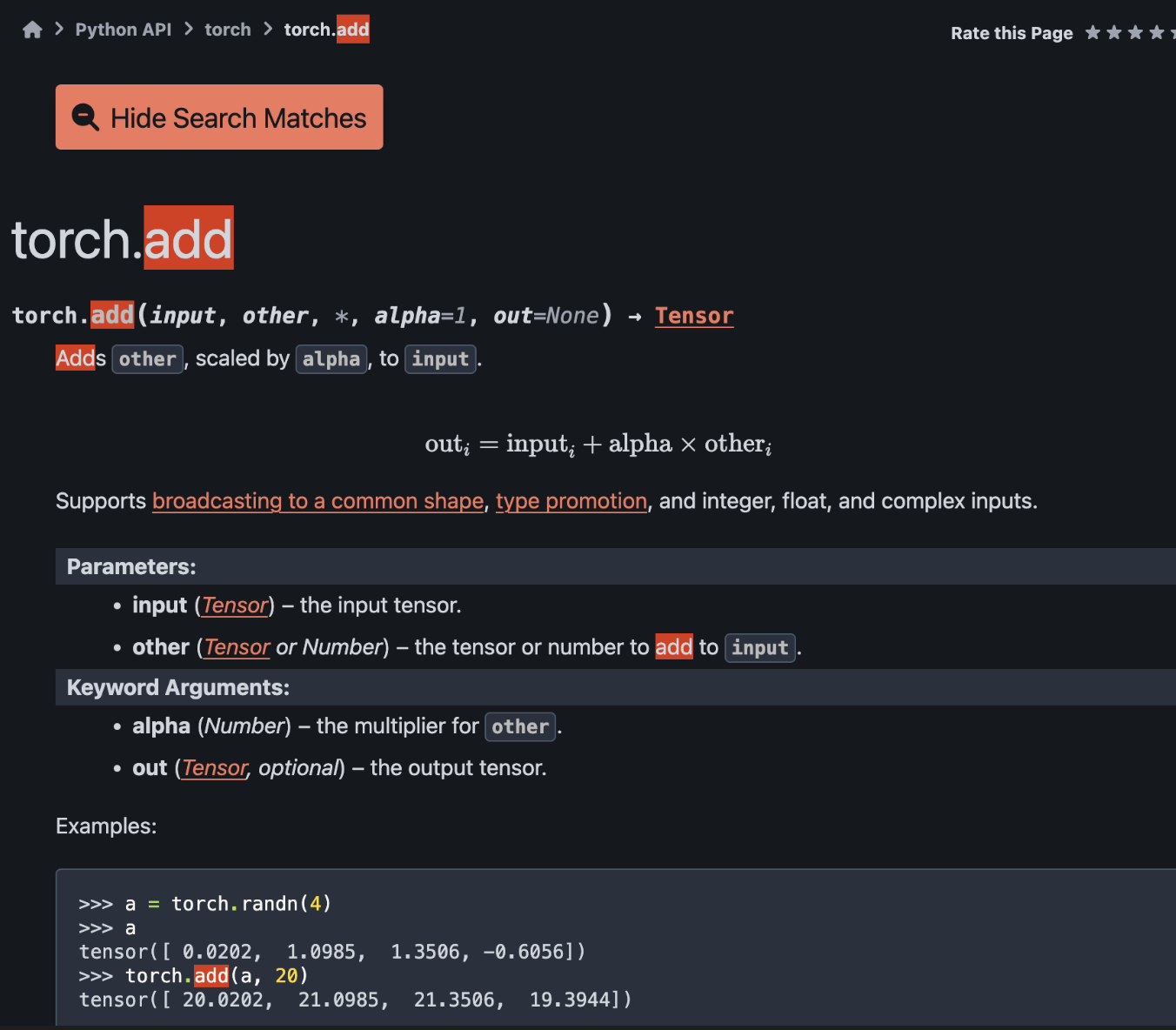
pytorch官网
第三阶段:Ground Truth 测试
系统会自动生成并执行测试用例,验证PyTorch参考实现的正确性。在实测环节时,这一步貌似和后续的步骤重合了,我们在点击下一步之后来到了Triton Kernel 代码生成。
第四阶段:Triton Kernel 代码生成
核心环节到来:系统根据自动生成Triton GPU Kernel代码。在此阶段,开发者可以审阅生成的代码,并进行必要的人工修正与干预。
横向对比:我们同时使用DeepSeek聊天框请求生成相同的Triton算子。结果显示,在此简单场景下,两者代码核心逻辑一致。
Triton-Copilot
import torch
import triton
import triton.language as tl@triton.jit
def add_operator_kernel(tensor_a_ptr, # *Pointer* to first input tensortensor_b_ptr, # *Pointer* to second input tensoroutput_ptr, # *Pointer* to output tensorn_elements, # Total number of elementsBLOCK_SIZE: tl.constexpr, # Number of elements each program should process
):pid = tl.program_id(axis=0) # We use a 1D launch grid so axis is 0block_start = pid * BLOCK_SIZEoffsets = block_start + tl.arange(0, BLOCK_SIZE)mask = offsets < n_elements# Load data from tensor_a and tensor_ba = tl.load(tensor_a_ptr + offsets, mask=mask)b = tl.load(tensor_b_ptr + offsets, mask=mask)# Perform additionoutput = a + b# Store resulttl.store(output_ptr + offsets, output, mask=mask)def add_operator(tensor_a: torch.Tensor, tensor_b: torch.Tensor):# Ensure tensors have the same shapeassert tensor_a.shape == tensor_b.shape, "Tensors must have the same shape"# Create output tensoroutput = torch.empty_like(tensor_a)# Get number of elementsn_elements = output.numel()# Define gridgrid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)# Launch kerneladd_operator_kernel[grid](tensor_a,tensor_b,output,n_elements,BLOCK_SIZE=1024)return output
对比DeepSeek聊天窗口
Q: 帮我使用pytorch和triton生成一个加法算子
import torch
import triton
import triton.language as tl@triton.jit
def add_kernel(x_ptr, # 第一个输入张量的指针y_ptr, # 第二个输入张量的指针output_ptr, # 输出张量的指针n_elements, # 张量中的元素数量BLOCK_SIZE: tl.constexpr, # 每个程序应该处理的元素数量
):# 有多个"程序"处理不同的数据。我们在这里识别我们是哪一个pid = tl.program_id(axis=0)block_start = pid * BLOCK_SIZEoffsets = block_start + tl.arange(0, BLOCK_SIZE)# 创建一个掩码以防止内存操作超出范围mask = offsets < n_elements# 从DRAM中加载x和y,以屏蔽掉块外的任何额外元素x = tl.load(x_ptr + offsets, mask=mask)y = tl.load(y_ptr + offsets, mask=mask)# 执行加法output = x + y# 将输出写回DRAMtl.store(output_ptr + offsets, output, mask=mask)def triton_add(x: torch.Tensor, y: torch.Tensor):# 检查输入形状是否匹配assert x.shape == y.shape, "Input tensors must have the same shape"# 预分配输出output = torch.empty_like(x)n_elements = output.numel()# SPMD启动网格表示并行运行的块数# 我们稍后推导出块大小grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )# 启动内核add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)return output# 更优化的版本,支持不同的广播和数据类型
@triton.jit
def add_kernel_advanced(x_ptr, y_ptr, output_ptr,x_stride, y_stride, output_stride,n_elements,BLOCK_SIZE: tl.constexpr,
):pid = tl.program_id(axis=0)block_start = pid * BLOCK_SIZEoffsets = block_start + tl.arange(0, BLOCK_SIZE)mask = offsets < n_elements# 计算实际的内存偏移量x_offsets = offsets // output_stride * x_stridey_offsets = offsets // output_stride * y_stridex = tl.load(x_ptr + x_offsets, mask=mask)y = tl.load(y_ptr + y_offsets, mask=mask)output = x + ytl.store(output_ptr + offsets, output, mask=mask)def triton_add_advanced(x: torch.Tensor, y: torch.Tensor):output = torch.empty_like(x)n_elements = output.numel()# 计算步长x_stride = x.stride(0) if x.dim() > 0 else 0y_stride = y.stride(0) if y.dim() > 0 else 0output_stride = output.stride(0) if output.dim() > 0 else 0grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )add_kernel_advanced[grid](x, y, output,x_stride, y_stride, output_stride,n_elements,BLOCK_SIZE=1024)return output
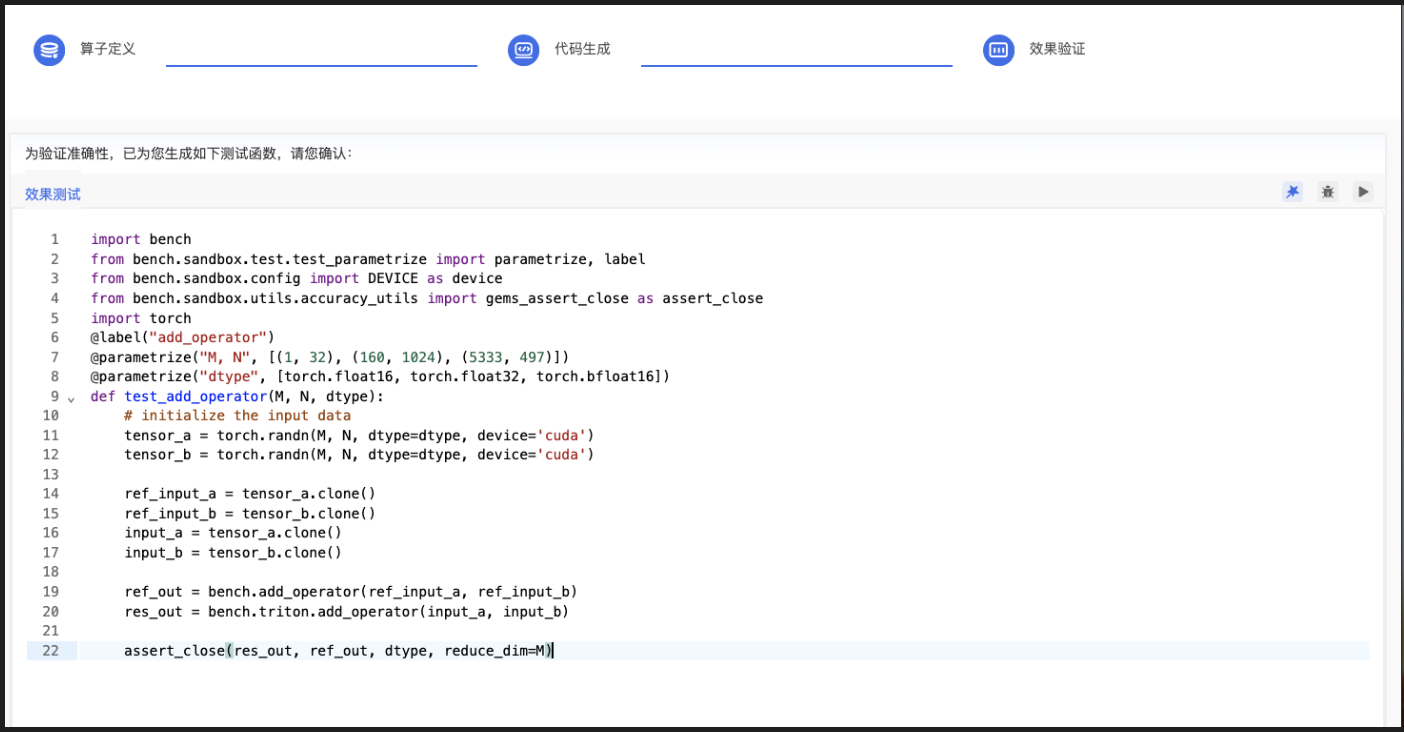
第五阶段:Triton Kernel 测试生成
系统同步生成针对Triton Kernel的测试代码,并自动执行,严格验证其功能与PyTorch参考实现完全等价。
这里我们看到实际上生成的测试结果包含了第三步的Ground Truth 测试。
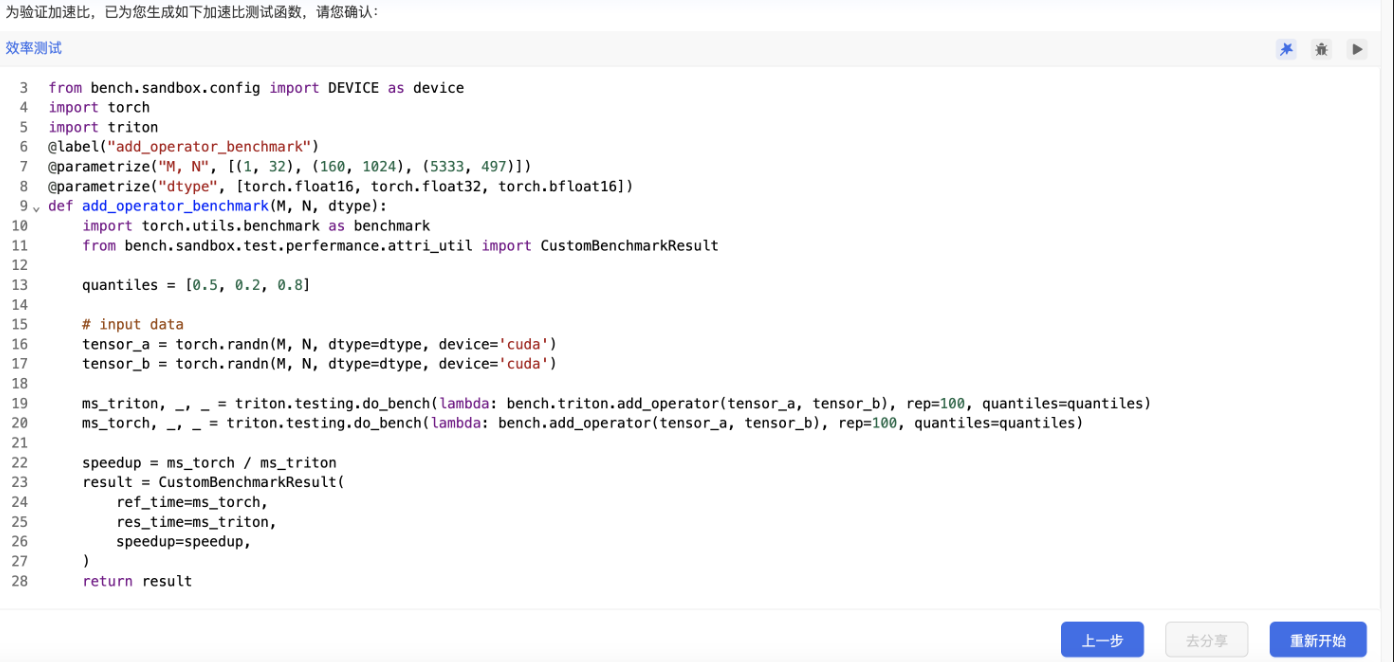
第六阶段:Triton Kernel 加速比测试生成
最后是性能验证阶段。系统会在指定的GPU后端(可在Nvidia与天数GPU间选择)上,自动运行性能基准测试,并生成一份详细的性能报告,你需要点击“播放”按钮。
import bench
from bench.sandbox.test.test_parametrize import parametrize, label
from bench.sandbox.config import DEVICE as device
import torch
import triton
@label("add_operator_benchmark")
@parametrize("M, N", [(1, 32), (160, 1024), (5333, 497)])
@parametrize("dtype", [torch.float16, torch.float32, torch.bfloat16])
def add_operator_benchmark(M, N, dtype):import torch.utils.benchmark as benchmarkfrom bench.sandbox.test.perfermance.attri_util import CustomBenchmarkResultquantiles = [0.5, 0.2, 0.8]# input datatensor_a = torch.randn(M, N, dtype=dtype, device='cuda')tensor_b = torch.randn(M, N, dtype=dtype, device='cuda')ms_triton, _, _ = triton.testing.do_bench(lambda: bench.triton.add_operator(tensor_a, tensor_b), rep=100, quantiles=quantiles)ms_torch, _, _ = triton.testing.do_bench(lambda: bench.add_operator(tensor_a, tensor_b), rep=100, quantiles=quantiles)speedup = ms_torch / ms_tritonresult = CustomBenchmarkResult(ref_time=ms_torch,res_time=ms_triton, speedup=speedup, )return result
┏━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┓
┃ 加速比 ┃ M ┃ N ┃ dtype ┃ PyTorch (ms) ┃ Triton (ms) ┃
┡━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━┩
│ 0.875 │ 1 │ 32 │ float16 │ 8.064 │ 9.216 │
│ 0.872 │ 160 │ 1024 │ float16 │ 7.872 │ 9.024 │
│ 0.804 │ 5333 │ 497 │ float16 │ 21.312 │ 26.496 │
│ 0.869 │ 1 │ 32 │ float32 │ 6.784 │ 7.808 │
│ 0.894 │ 160 │ 1024 │ float32 │ 8.864 │ 9.920 │
│ 0.941 │ 5333 │ 497 │ float32 │ 32.480 │ 34.528 │
│ 1.004 │ 1 │ 32 │ bfloat16 │ 7.808 │ 7.776 │
│ 1.158 │ 160 │ 1024 │ bfloat16 │ 8.928 │ 7.712 │
│ 0.769 │ 5333 │ 497 │ bfloat16 │ 20.480 │ 26.624 │
├────────────┼────────────┼────────────┼────────────┼────────────────┼────────────────┤
│ 0.910 │ — │ — │ — │ 13.621 │ 15.456 │
└────────────┴────────────┴────────────┴────────────┴────────────────┴────────────────┘
数据分析:数据显示,在部分场景(如bfloat16, [160, 1024])下,生成的Triton Kernel实现了1.158的加速比。在这个基础场景验证下我们验证了Triton-Copilot能够产出可运行的代码,而且可以在线完成对于代码的性能测试。
整个流程,从输入自然语言到获取性能报告,在零基础人员的简单场景体验下,总计耗时约一小时,亲身验证了其将开发周期从“天”缩短至“小时”的承诺。
四、 总结与展望
至此,通过本次从非算子开发专家视角的实践,笔者亲历了Triton-Copilot的六阶段算子生成流程,与“人机协同 + 验证闭环” 的用户体验。感谢FlagOS团队的邀请,有幸体验FlagOS开发效率的范式变革的最新成果。
笔者深信,工具的进步最终是为了赋能整个社区。 本着开放的心态,向所有对此感兴趣的研究者与开发者推荐这一项目:
- 访问项目主页:
https://triton-copilot.baai.ac.cn/ - 内容参考:[1] 国庆特别版|万字长文,技术解读众智FlagOS v1.5四大新进展(https://mp.weixin.qq.com/s/BCryw30j_eMwe0Pr80VtcA)