PostgreSQL + Redis + Elasticsearch 实时同步方案实践:从触发器到高性能搜索
在现代系统架构中,我们常常既希望:
- PostgreSQL 担任主数据存储;
- Redis 提供高速缓存;
- Elasticsearch 提供模糊搜索和全文索引。
但如何让这三者实时同步数据,既可靠又简单?
本文将带你从原理到实现,构建一个轻量级、高性能、可扩展的同步方案。
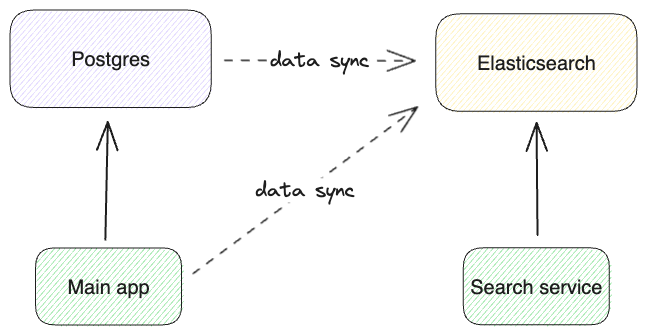
一、问题背景
在中大型业务系统中,我们常见这样的三层数据结构:
| 系统 | 职责 | 特点 |
|---|---|---|
| PostgreSQL | 结构化主数据存储 | 强一致、可靠 |
| Redis | 高频访问缓存 | 高速读写 |
| Elasticsearch | 搜索/模糊查询 | 支持全文匹配、分词 |
理想状态下,当 PostgreSQL 中的数据发生变化时:
- Redis 缓存应立即更新;
- Elasticsearch 索引应保持一致。
但如果数据量大、变更频繁,人工同步或定时同步就会滞后。
这时我们需要一种轻量但实时的方案。
二、常见同步方案对比
| 方案 | 实时性 | 实现复杂度 | 运维成本 | 适用场景 |
|---|---|---|---|---|
| 定时扫描 + 更新时间字段 | 分钟级 | ⭐ | ⭐ | 简单系统 |
| Kafka / Debezium CDC | 毫秒级 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 大型分布式系统 |
| Trigger + LISTEN/NOTIFY + Worker | 秒级 | ⭐⭐ | ⭐⭐ | ✅ 中小系统首选 |
📌 本文选用第三种方案:
PostgreSQL Trigger + LISTEN/NOTIFY + 异步 Worker 实时同步
它无需额外组件,延迟可低至 1 秒以内,兼顾可靠性与简洁性。
三、系统架构设计
同步流程如下图所示:
🔧 核心机制说明:
- Trigger:PostgreSQL 在表数据增删改时触发。
- NOTIFY:数据库内置的轻量级消息通道。
- Worker:独立进程监听事件,异步更新 Redis/ES。
- 幂等性设计:重复更新不会出错,保证数据最终一致。
四、PostgreSQL 端实现
1️⃣ 创建触发函数
CREATE OR REPLACE FUNCTION notify_data_change()
RETURNS trigger AS $$
DECLAREpayload JSON;
BEGINIF (TG_OP = 'DELETE') THENpayload := json_build_object('table', TG_TABLE_NAME, 'action', TG_OP, 'id', OLD.id);ELSEpayload := json_build_object('table', TG_TABLE_NAME, 'action', TG_OP, 'id', NEW.id);END IF;PERFORM pg_notify('data_changes', payload::text);RETURN NEW;
END;
$$ LANGUAGE plpgsql;
2️⃣ 为目标表添加触发器
CREATE TRIGGER data_change_trigger
AFTER INSERT OR UPDATE OR DELETE ON your_table
FOR EACH ROW EXECUTE FUNCTION notify_data_change();
⚠️ 注意:
- 触发器只传递轻量级 JSON(表名 + 操作 + 主键 ID);
- Worker 再根据 ID 查询最新完整数据。
五、Worker 实时监听与同步实现
以下示例使用 Python + psycopg2 + redis + elasticsearch-py:
import psycopg2, select, json, redis
from elasticsearch import Elasticsearch# 初始化连接
r = redis.Redis(host='localhost', port=6379, db=0)
es = Elasticsearch(['http://localhost:9200'])
conn = psycopg2.connect("dbname=test user=postgres password=123456")
conn.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)cur = conn.cursor()
cur.execute("LISTEN data_changes;")
print("Listening on channel data_changes...")def fetch_row(cur, table, id):cur.execute(f"SELECT * FROM {table} WHERE id = %s", (id,))return cur.fetchone(), [desc[0] for desc in cur.description]while True:if select.select([conn], [], [], 5) == ([], [], []):continueconn.poll()while conn.notifies:notify = conn.notifies.pop(0)payload = json.loads(notify.payload)action, table, id_ = payload['action'], payload['table'], payload['id']if action in ['INSERT', 'UPDATE']:cur2 = conn.cursor()row, columns = fetch_row(cur2, table, id_)if not row:continuedoc = dict(zip(columns, row))# Redis 同步r.hset(f"{table}:{id_}", mapping=doc)# Elasticsearch 同步es.index(index=table, id=id_, document=doc)cur2.close()elif action == 'DELETE':r.delete(f"{table}:{id_}")es.delete(index=table, id=id_, ignore=[404])
六、可靠性与性能优化
| 问题 | 解决方案 |
|---|---|
| Worker 停机期间可能漏消息 | 启动时根据 updated_at 字段扫描补偿 |
| 通知频繁引发阻塞 | Worker 内部用队列异步处理(如 asyncio 或 Redis Stream) |
| Redis/ES 更新失败 | 增加重试机制或死信队列 |
| 数据量极大 | 可考虑引入 Kafka / Debezium 替代触发器同步 |
七、方案优劣对比总结
| 特性 | Trigger + LISTEN | Debezium (CDC) | 定时扫描 |
|---|---|---|---|
| 实时性 | ✅ 秒级 | ✅ 毫秒级 | ❌ 分钟级 |
| 复杂度 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐ |
| 成本 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐ |
| 可维护性 | ✅ 高 | ⚠️ 中 | ✅ 高 |
| 适用规模 | 中小型 | 大型 | 小型 |
| 实现语言 | 任意 (Python/Node/Go) | Java/Kafka | 任意 |
📌 结论:
对于中小型项目、单库多缓存/索引场景,
最推荐方案是 ——
PostgreSQL Trigger + LISTEN/NOTIFY + 异步 Worker 实时同步。
八、最终方案架构图
九、结语
本方案实现了:
- 🔁 PostgreSQL、Redis、Elasticsearch 的秒级数据一致;
- ⚡ 支持模糊搜索(由 ES 负责);
- 🧩 低耦合、可扩展、可监控;
- 🧰 部署简单,无需引入重型中间件。
对于希望“简单、实时、可靠”的中小团队来说,
这就是一条足够优雅的生产级道路。
实用小工具
App Store 截图生成器、应用图标生成器 、在线图片压缩和 Chrome插件-强制开启复制-护眼模式-网页乱码设置编码
乖猫记账,AI智能分类的最佳聊天记账App。
Elasticsearch可视化客户端工具