基础的神经网络架构-奶茶店的 “标准化制作体系”
基础的神经网络架构-奶茶店的 “标准化制作体系”
- 速读
- 前馈神经网络(FNN):经典款奶茶的“固定配方制作机”
- 场景
- 技术描述
- 工程价值与适用场景
- 经典场景改进
- 循环神经网络(RNN):续杯与定制单的“记忆式制作台”
- 场景
- 技术描述
- 工程价值与适用场景
- 经典场景改进
- 卷积神经网络(CNN):原料质检与新品外观的“细节识别仪”
- 场景
- 技术描述
- 工程价值与适用场景
- 经典场景改进
- 未完待续
速读
要是把神经网络塞进奶茶店当店员,那分工可太明确了:FNN 是 “早高峰战神流水线”,抱着固定配方咔咔怼料,1 分钟出 3 杯全糖去冰珍珠奶,稳如老狗只求快;RNN 是 “老客专属记忆台”,顾客刚进门就递上 “还是少糖三分冰 + 多加芋泥?”,连上次漏说的 “不要珍珠” 都记着,省得重复废话;CNN 是 “瑕疵捕捉显微镜”,拿个小相机扫茶叶 ——“霉点!pass!”,翻奶盖 ——“厚度不够 2cm!返工!”,连草莓蒂上藏的小烂斑都能圈出来,主打一个细节不翻车。
前馈神经网络(FNN):经典款奶茶的“固定配方制作机”
场景
早高峰许多顾客只要“经典珍珠奶茶”,配方和流程固定。柜台按既定 SOP(煮茶→加奶→放糖→加珍珠)流水线出杯,每一杯的制作流程相同、互不依赖。
技术描述
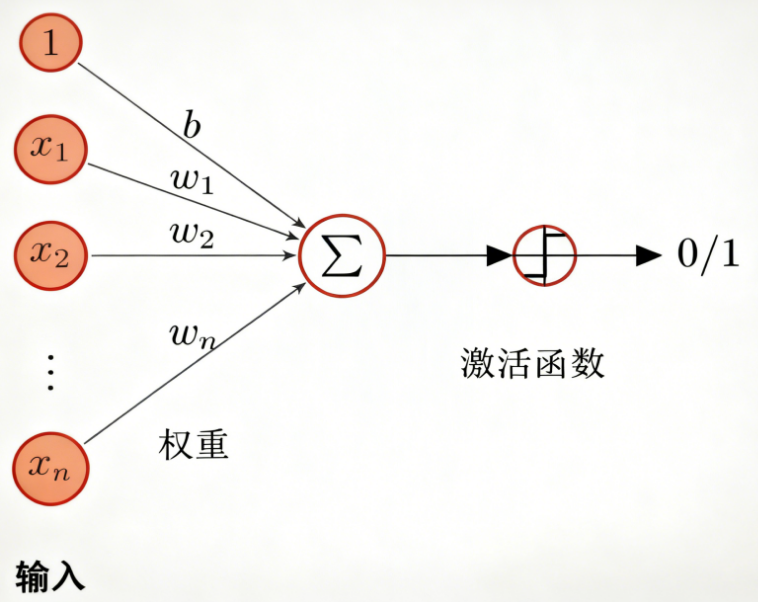
FNN(也称全连接网络、MLP)的本质是对固定维度输入做一次或多次仿射变换与非线性映射,典型一层隐藏层形式为:
h=σ(Wx+b),y=Vh+ch = \sigma(Wx + b), \quad y = Vh + c h=σ(Wx+b),y=Vh+c
其中x∈Rdx \in \mathbb{R}^dx∈Rd为固定维度输入,网络不含时间维或跨样本状态传递。因此,FNN 适合独立同分布样本的静态函数逼近或分类任务。
工程价值与适用场景
优点:结构简单、参数相对可控、训练与推理实现容易;适用于结构化数据回归/分类、作为基线模型。
局限:不能原生建模序列依赖或上下文关系;若输入本身含有空间/时序结构(如图像、序列数据),直接用 FNN 效率和效果可能不佳。
经典场景改进
一家奶茶店不能够只会做一种奶茶,它必须得会做很多种,所以一个奶茶店里需要很多个FNN。这个概念和混合专家模型(Mixture of Experts, MoE)很像。如果硬让一条流水线兼容所有配方,要么流程混乱、要么速度骤降。这时候改成 “多配方流水线 + 智能调度员”:摆 3 条专用流水线(3 个 “专家” FNN,分别专精经典、波霸、布丁配方),再配一个 “调度员”(门控网络)—— 订单一来,调度员先判断 “要啥款”,直接把订单甩给对应流水线,既保持每条线 “固定配方出杯” 的高效,又能灵活应对多品类需求。
循环神经网络(RNN):续杯与定制单的“记忆式制作台”
场景
面对经常复购的顾客,制作台会参考该顾客最近订单来复现偏好(例如“少糖、三分冰”),从而减少顾客重复说明的成本。
技术描述
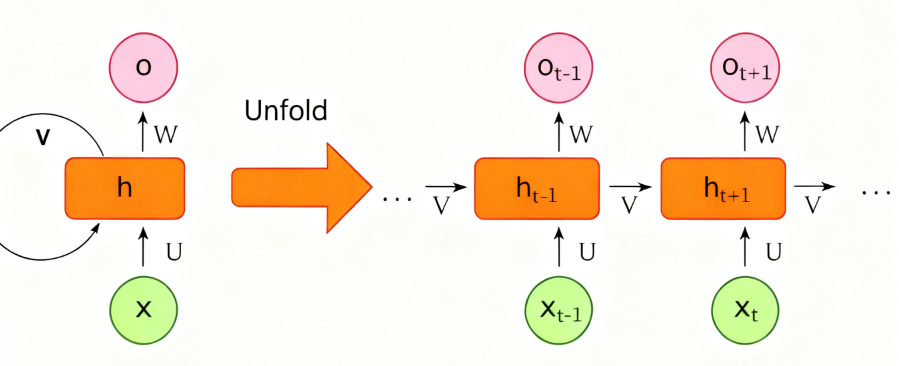
经典 RNN 在时间步ttt运算可写为:
ht=ϕ(Wxxt+Whht−1+b),yt=g(Vht+c)h_t = \phi(W_x x_t + W_h h_{t-1} + b), \quad y_t = g(V h_t + c)ht=ϕ(Wxxt+Whht−1+b),yt=g(Vht+c)
其中hth_{t}ht是隐藏状态,用以在步骤间传递信息。经典 RNN 在长序列上可能遭遇梯度消失或梯度爆炸的问题(反向传播时梯度在多次时间步传递中指数级衰减或增大),这会导致难于学习长时依赖。
工程价值与适用场景
适合:会话建模、短期行为序列、逐步生成(例如时间步预测)等场景。
局限:并行化能力较弱(时间步有序性),在非常长的序列或需要高度并行的场景下效率受限。现在许多长序列任务更偏向用 Transformer 及其变体。
经典场景改进
如果老客连续 5 天点 “少糖 + 芋泥多加”,第 6 天换 “少糖 + 布丁”—— 普通 RNN 做的 “记忆台” 会把前 5 天的 “芋泥偏好” 和第 6 天的 “布丁” 混在一起,最后做出来的奶茶既不像芋泥也不像布丁。这个时候就会有两个常见的改进:LSTM和GRU。
LSTM 加了 “细胞状态(cell state)” 这条 “信息传送带”,还有三个 “门”(遗忘门、输入门、输出门)控制信息 “删、加、用”,彻底解决 “传话游戏” 的梯度消失问题。遗忘门可以删除台账里的旧偏好,输入门会将新偏好加入到台账中。LSTM随后会通过状态更新将新旧偏好合并,并通过偏好输出新的奶茶,精准匹配老客新需求。
GRU 觉得 LSTM 的 “三门 + 细胞状态 + 隐藏态” 太繁琐,于是 合并细胞状态和隐藏态,并 把 “遗忘门 + 输入门” 合并成 “更新门”,只保留两个门:更新门(Update Gate)、重置门(Reset Gate)。重置门的作用是:老客突然说 “这次要全糖”—— 重置门临时把 “少糖偏好” 屏蔽,先按全糖算。而更新门的作用是:老客第 7 天说 “还是少糖 + 布丁”—— 更新门一边保留 “少糖、布丁”(旧),一边过滤 “全糖”(临时需求)。最终,GRU也会将新旧记忆进行加权融合,在保留长期偏好的同时,又不被短期干扰。
卷积神经网络(CNN):原料质检与新品外观的“细节识别仪”
场景
用摄像头拍摄茶叶、草莓或成品奶茶图片,自动判断是否霉变、是否摆放合规或是否满足新品外观要求(例如奶盖厚度、分层是否清晰)。
技术描述
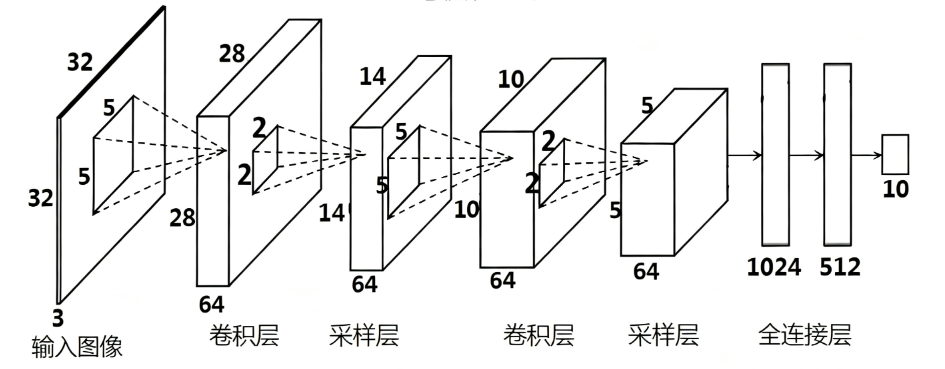
CNN 的基本思想是用局部卷积核(filter)在图像上滑动,提取局部特征;随后用池化/下采样降低空间分辨率并增强鲁棒性;最终通过全连接层或卷积分类头输出结果。
两个重要概念:感受野(receptive field)——某一层单元可以“看到”的原图区域,随着层数加深感受野扩大;参数共享——同一卷积核在不同位置使用,显著减少参数量并利用平移不变性。
工程价值与适用场景
适合:图像分类、目标检测、分割、视觉质检等任务。
风险点:对光照、遮挡、分布偏移敏感,需要现实场景下的鲁棒性评估与持续监控。
经典场景改进
原来的 “视觉质检仪”(普通 CNN)只能检查 “茶叶表面霉斑” 这类浅层问题,但遇到 “多层包装的原料(比如铝箔袋里的茶叶)”“需要对比多层纹理的成品(比如渐变分层奶盖)” 时,深层质检环节容易 “记不清最初的特征”(深层 CNN 梯度消失,学不到有效信息)。现在给质检流程加了 “直通电梯”(ResNet):每一层质检后,都把 “当前看到的特征” 和 “最开始的原始特征” 用电梯直接传递到下下层,这样即使叠了 100 层质检,深层也能清楚知道 “最开始的茶叶长啥样”,既能抓深层细微瑕疵(比如包装内层的褶皱),又不会因为层数太深而 “糊涂”。
未完待续
后续还会添加无监督与生成篇(Autoencoder / GAN / Diffusion)、序列与全局篇(Transformer / Attention / 长依赖)、结构化数据篇(GNN)等大类模型的简单介绍。再然后会对他们其中的一些经典算法进行详细介绍。