【cuda学习日记】5.1 共享内存
纯概念的一节
5.1.1 共享内存
(Shared Memory) SMEM, 共享内存实际上是可受用户控制的一级缓存。每个SM中,一级缓存和共享内存共享一个64KB的内存段 。
相较于二级缓存和全局内存,共享内存和一级缓存在物理上更接近SM。因此,共享内存相较于全局内存而言,延迟要低大约20~30倍,而带宽高其大约10倍。
当每个线程块开始执行时,会分配给它一定数量的共享内存。这个共享内存的地址空
间被线程块中所有的线程共享。它的内容和创建时所在的线程块具有相同生命周期。共享内存被SM中的所有常驻线程块划分,因此,共享内存是限制设备并行性的关键资源。一个核函数使用的共享内存越多,处于并发活跃状态的线程块就越少。
在设备上启动的核函数配置一级缓存和共享内存的大小:
cudaError_t cudaDeviceSetCacheConfig(cudaFuncCache cacheConfig);
/* cacheConfig支持的参数
cudaFuncCachePreferNone -- no prefer (default)
cudaFuncCachePreferShared -- 48KB SMEM 16KB L1 cache
cudaFuncCachePreferL1 -- 48KB l1 and 16KB SMEM
cudaFuncCachePreferEqual -- 32KB L1 Cache and 32KB SMEM
*/
那种模式更好:
·当核函数使用较多的共享内存时,倾向于更多的共享内存
·当核函数使用更多的寄存器时,倾向于更多的一级缓存
编译的时候加上 -Xptxas -v 可以知道核函数用了多少资源:
以上一篇转置问题代码为例:
nvcc transpose.cu -Xptxas -v -o transpose.exe
输出(部分):
ptxas info : Used 9 registers, used 0 barriers, 344 bytes cmem[0]
ptxas info : Compiling entry function '_Z19tranposediagonalRowPfS_ii' for 'sm_52'
ptxas info : Function properties for _Z19tranposediagonalRowPfS_ii
0 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
当内核使用的寄存器数量超过了硬件限制所允许的数量时,应该为寄存器溢出配置一个更大的一级缓存。
5.1.2 分配
共享内存用 shared 修饰符进行声明。
如果在核函数中进行声明,那么这个变量的作用域就局限在该内核中。如果在文件的任何核函数外进行声明,那么这个变量的作用域对所有核函数来说都是全局的。
5.1.3 共享内存存储体
为了获得高内存带宽,共享内存被分为32个同样大小的内存模型,它们被称为存储体,每个存储体可以存储8个字节大小的数据 (计算能力2.x为4位),它们可以被同时访问。有32个存储体是因为在一个线程束中有32个线程。
5.1.4 同步
同步是所有并行计算语言的重要机制。共享内存可以同时被线程块中的多个线程访问。当不同步的多个线程修改同一个共享内存地址时,将导致线程内的冲突。
同步的两个基本方法:
·障碍 – 所有调用的线程等待其余调用的线程到达障碍点
·内存栅栏 – 所有调用的线程必须等到全部内存修改对其余调用线程可见时才能继续执行
5.1.4.1 显示障碍
在CUDA中,障碍只能在同一线程块的线程间执行。核函数中,以下函数来指定障碍点
void __syncthreads();
要求块中的线程必须等待直到所有线程都到达该点。__syncthreads还确保在障碍点之前,被这些线程访问的所有全局和共享内存对同一块中的所有线程都可见。
下面的代码可能会导致块中的线程无限期地等待对方,因为块中的所有线程没有达到相同的障碍点。
if (threadId % 2 == 0){
__syncthreads();
} else{
__syncthreads();
}
如果一个CUDA核函数要求跨线程块全局同步,那么通过在同步点分割核函数并执行多个内核启动可能会达到预期的效果。
5.1.4.2 内存栅栏
内存栅栏的功能可确保栅栏前的任何内存写操作对栅栏后的其他线程都是可见的。根据所需范围,有3种内存栅栏:块、网格或系统。
void __threadfence_block();
5.1.4.3 Volatile修饰符
在全局或共享内存中使用volatile修饰符声明一个变量,可以防止编译器优化,编译器优化可能会将数据暂时缓存在寄存器或本地内存中。当使用volatile修饰符时,编译器假定任何其他线程在任何时间都可以更改或使用该变量的值。因此,这个变量的任何引用都会直接被编译到全局内存读指令或全局内存写指令中,它们都会忽略缓存.
5.1.4.4 存储体冲突
在共享内存中当多个地址请求落在相同的内存存储体中时,就会发生存储体冲突,这会导致请求被重复执行。
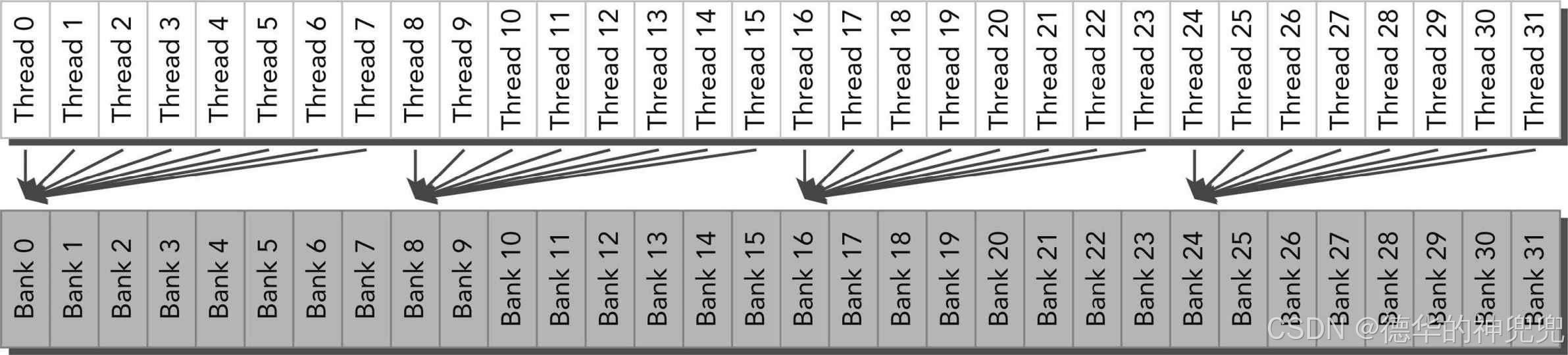
最优的并行访问模式:
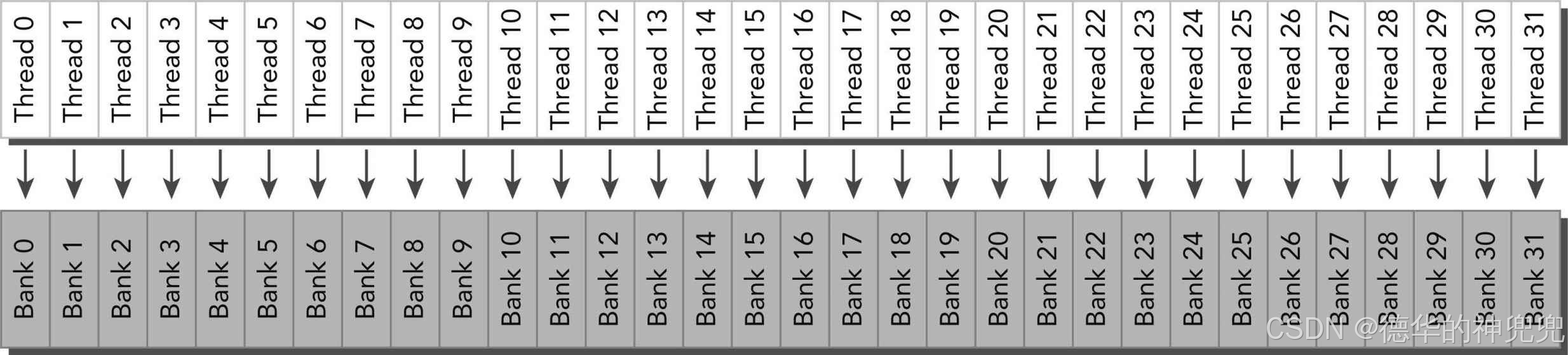
随机访问模式:
每个线程访问不同的存储体,所以也没有存储体冲突。
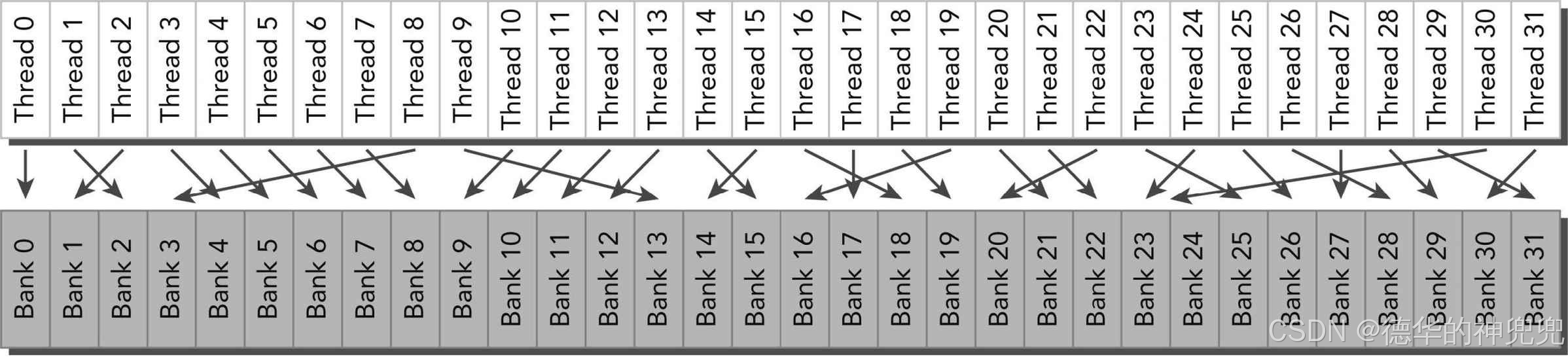
几个线程访问同一存储体。对于这样一个请求,会产生两种可能的行为:
·如果线程访问同一个存储体中相同的地址,广播访问无冲突
·如果线程访问同一个存储体中不同的地址,会发生存储体冲突