大模型原理与实践:第六章-大模型训练流程实践_第1部分-模型预训练(Trainer、DeepSeed)
第六章 大模型训练流程实践
总目录
-
第一章 NLP基础概念完整指南
- 第1部分-概念和发展历史
- 第2部分-各种任务(实体识别、关系抽取、文本摘要、机器翻译、自动问答)
- 第3部分-文本表示(词向量、语言模型、ELMo)
-
第二章 Transformer 架构原理
- 第1部分-注意力机制
- 第2部分Encoder-Decoder架构
- 第3部分-完整Transformer模型)
-
第三章 预训练语言模型
- 第1部分-Encoder-only(BERT、RoBERTa、ALBERT)
- 第2部分-Encoder-Decoder-T5
- 第3部分-Decoder-Only(GPT、LLama、GLM)
-
第四章 大语言模型
- 第1部分-发展历程、上下文、指令遵循、多模态
- 第2部分-LLM预训练、监督微调、强化学习
-
第五章 动手搭建大模型
- 第1部分-动手实现一个LLaMA2大模型
- 第2部分-自己训练 Tokenizer
- 第3部分-预训练一个小型LLM
-
第六章 大模型训练实践
- 第1部分-模型预训练
- 第2部分-模型有监督微调
- 第3部分-高效微调
-
第七章 大模型应用
- 第1部分-待写
目录
- 6.1 模型预训练
- 6.1.1 框架介绍
- 6.1.2 初始化 LLM
- 6.1.3 预训练数据处理
- 6.1.4 使用 Trainer 进行训练
- 6.1.5 使用 DeepSpeed 实现分布式训练
6.1 模型预训练
在第五章中,我们从零开始搭建了 LLaMA2 模型,并完整实现了预训练和微调的全流程。本章将深入探讨大模型的训练流程实践,重点介绍如何利用主流的大模型框架高效地进行模型训练和性能优化。
虽然从零手写实现 LLM 训练有助于深入理解模型原理,但在实际应用中存在以下局限性:
- 开发工作量大:手写实现 LLM 结构需要大量时间,难以快速跟进最新的模型结构创新
- 训练效率低:从零实现的训练代码无法有效支持多卡分布式训练,训练效率受到限制
- 兼容性差:与现有预训练 LLM 不兼容,无法直接使用开源社区的预训练模型参数
因此,本章将介绍 LLM 领域的主流训练框架 Transformers,并结合分布式框架 DeepSpeed、高效微调框架 PEFT 等,实践完整的模型 Pretrain 和 SFT 流程,更好地对接业界主流的 LLM 技术方案。
6.1.1 框架介绍
Transformers 是由 Hugging Face 开发的 NLP 框架,通过模块化设计实现了对 BERT、GPT、LLaMA、T5、ViT 等上百种主流模型架构的统一支持。该框架具有以下核心优势:
模型加载便捷性
开发者无需重复实现基础网络结构,通过 AutoModel 类即可一键加载任意预训练模型。Hugging Face 提供了图形化的模型浏览界面,方便用户查找和下载所需模型。
分布式训练支持
框架内置的 Trainer 类封装了分布式训练的核心逻辑,支持以下多种分布式训练策略:
- PyTorch 原生 DDP(Distributed Data Parallel)
- DeepSpeed ZeRO 优化
- Megatron-LM 模型并行
通过简单的配置文件,即可实现数据并行、模型并行、流水线并行的混合并行训练。在 8 卡 A100 集群上可轻松支持百亿参数模型的高效训练。
生态集成
Transformers 支持与以下工具无缝集成:
- DeepSpeed:分布式训练加速
- PEFT:高效参数微调
- Wandb/SwanLab:训练可视化监控
- Datasets:数据集加载与处理
- Evaluate:模型评估指标
社区生态

Hugging Face 基于 Transformers 框架搭建了庞大的 AI 社区,提供:
- 数亿个预训练模型参数
- 25万+ 不同类型数据集
- 完善的文档和示例代码
这使得开发者可以便捷地使用任一预训练模型,在开源模型及数据集的基础上快速实现个人模型的开发与应用。
在 LLM 时代,模型结构的调整和重新预训练越来越少,开发者更多的业务应用在于使用预训练好的 LLM 进行后训练(Post Train)和监督微调(SFT),来支持下游业务应用。Transformers 已逐步成为学界、业界 NLP 技术的主流框架。新发布的开源 LLM(如 DeepSeek、Qwen)也都会第一时间在 Transformers 社区开放其预训练权重与模型调用示例。
6.1.2 初始化 LLM
下载模型配置
我们可以使用 Transformers 的 AutoModel 类直接初始化已经实现好的模型。本节以 Qwen-2.5-1.5B 模型架构为例进行说明。
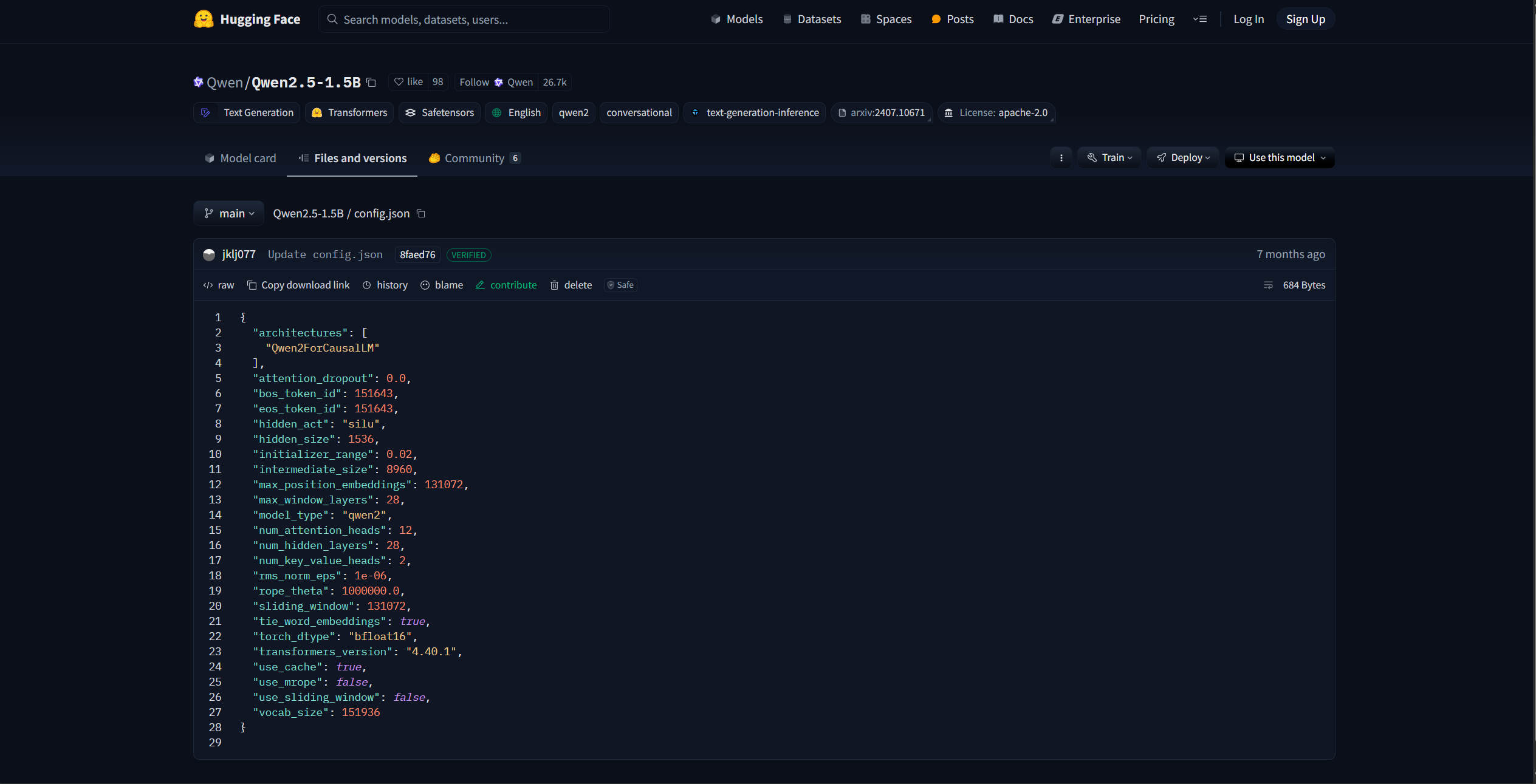
在 HuggingFace 模型库中,每个模型都包含一个 config.json 配置文件,该文件定义了模型的核心架构参数:
- 模型架构类型(architecture)
- 隐藏层大小(hidden_size)
- 注意力头数(num_attention_heads)
- 模型层数(num_hidden_layers)
- 词表大小(vocab_size)
- 等其他关键参数
首先,我们需要下载模型配置文件。HuggingFace 提供了便捷的命令行工具:
import os# 设置环境变量,使用 HuggingFace 镜像网站(国内访问更快)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 下载模型到本地目录
os.system('huggingface-cli download --resume-download Qwen/Qwen2.5-1.5B --local-dir your_local_dir')
参数说明:
Qwen/Qwen2.5-1.5B:模型标识符,可从 HuggingFace 模型页面直接复制--local-dir your_local_dir:指定本地保存路径--resume-download:支持断点续传
加载模型配置
下载完成后,使用 AutoConfig 类加载配置文件:
from transformers import AutoConfig# 指定下载的模型参数本地路径
model_path = "qwen-1.5b"# 加载配置文件
config = AutoConfig.from_pretrained(model_path)# 查看配置信息
print(config)
输出内容:
Qwen2Config {"architectures": ["Qwen2ForCausalLM"],"hidden_size": 1536,"num_hidden_layers": 28,"num_attention_heads": 12,"vocab_size": 151936,...
}
自定义配置
你也可以修改配置文件,定制模型结构:
# 修改隐藏层大小
config.hidden_size = 2048# 修改注意力头数
config.num_attention_heads = 16# 修改层数
config.num_hidden_layers = 24
初始化新模型
使用 AutoModelForCausalLM 类基于配置生成模型:
from transformers import AutoModelForCausalLM# 从配置初始化一个随机参数的新模型
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)# 查看模型结构
print(model)

模型类型说明:
AutoModelForCausalLM:用于因果语言模型(Causal Language Model),适用于 GPT 类模型AutoModelForSequenceClassification:用于序列分类任务
加载预训练模型
在实际应用中,我们通常会加载预训练好的模型权重进行后续训练:
from transformers import AutoModelForCausalLM# 加载预训练权重
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True
)# 打印模型参数量
n_params = sum(p.numel() for p in model.parameters())
print(f"模型参数量: {n_params/1e6:.2f}M")
输出内容:
模型参数量: 1540.00M
初始化 Tokenizer
Tokenizer 负责将文本转换为模型可处理的数值序列:
from transformers import AutoTokenizer# 加载预训练的 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)# 测试 Tokenizer
text = "你好,世界!"
tokens = tokenizer(text)
print(f"原文本: {text}")
print(f"Token IDs: {tokens['input_ids']}")
print(f"解码结果: {tokenizer.decode(tokens['input_ids'])}")
输出内容:
原文本: 你好,世界!
Token IDs: [108386, 99438, 98667, 99589, 151645]
解码结果: 你好,世界!
6.1.3 预训练数据处理
加载数据集
与第五章类似,我们使用出门问问序列猴子开源数据集作为预训练数据。Hugging Face 的 datasets 库提供了便捷的数据加载功能:
from datasets import load_dataset# 加载 JSONL 格式的预训练数据
ds = load_dataset('json', data_files='/path/to/mobvoi_seq_monkey_general_open_corpus.jsonl'
)# 查看数据集结构
print(ds)
输出内容:
DatasetDict({train: Dataset({features: ['text'],num_rows: 1000000})
})
注意事项:
- 数据集较大时加载可能耗时较长或占用大量内存
- 建议测试时先使用部分数据(可通过切片或过滤实现)
查看数据样本
# 查看第一条数据
print(ds["train"][0])# 保存列名(后续处理需要)
column_names = list(ds["train"].features)
print(f"数据集列名: {column_names}")
输出内容:
显示原始文本内容。
数据集列名: ['text']
数据 Tokenize
使用加载好的 tokenizer 对数据集进行批量处理:
def tokenize_function(examples):"""对批量文本进行分词Args:examples: 包含 'text' 字段的字典,每个字段是文本列表Returns:包含 'input_ids' 和 'attention_mask' 的字典"""output = tokenizer([item for item in examples["text"]])return output# 批量处理数据集
tokenized_datasets = ds.map(tokenize_function, # 处理函数batched=True, # 批量处理模式num_proc=10, # 使用10个进程并行处理remove_columns=column_names, # 移除原始文本列load_from_cache_file=True, # 使用缓存加速desc="Running tokenizer on dataset" # 进度条描述
)# 查看处理后的数据
print(tokenized_datasets["train"][0])
输出内容:
{'input_ids': [151644, 8948, 198, 2610, ...],'attention_mask': [1, 1, 1, 1, ...]
}
文本块拼接
在预训练中,为了提高训练效率,通常将多个文本段拼接成固定长度的文本块:
from itertools import chain# 设置文本块长度
block_size = 2048def group_texts(examples):"""将多个文本段拼接成固定长度的块工作流程:1. 将所有文本的 token 拼接成一个长序列2. 将长序列切分成 block_size 长度的块3. 为 CLM 任务设置 labels(与 input_ids 相同)Args:examples: tokenized 数据批次Returns:包含固定长度文本块的字典"""# 步骤1: 拼接所有文本concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}# 计算总长度total_length = len(concatenated_examples[list(examples.keys())[0]])# 步骤2: 截断到 block_size 的整数倍if total_length >= block_size:total_length = (total_length // block_size) * block_size# 步骤3: 切分成固定长度块result = {k: [t[i : i + block_size] for i in range(0, total_length, block_size)]for k, t in concatenated_examples.items()}# CLM 任务:labels 与 input_ids 相同result["labels"] = result["input_ids"].copy()return result# 批量处理
lm_datasets = tokenized_datasets.map(group_texts,batched=True,num_proc=10,load_from_cache_file=True,desc=f"Grouping texts in chunks of {block_size}",batch_size=40000 # 每批处理的样本数
)# 获取训练数据集
train_dataset = lm_datasets["train"]print(f"处理后的数据集大小: {len(train_dataset)}")
print(f"每个样本长度: {len(train_dataset[0]['input_ids'])}")
输出内容:
处理后的数据集大小: 50000
每个样本长度: 2048
6.1.4 使用 Trainer 进行训练
Transformers 提供的 Trainer 类封装了完整的训练逻辑,支持自动混合精度、梯度累积、检查点保存等功能。
配置训练参数
from transformers import TrainingArguments# 定义训练超参数
training_args = TrainingArguments(output_dir="output", # 模型输出路径per_device_train_batch_size=4, # 每个设备的batch sizegradient_accumulation_steps=4, # 梯度累积步数(实际 bs = 4 * 4 = 16)logging_steps=10, # 每10步打印一次日志num_train_epochs=1, # 训练轮数save_steps=100, # 每100步保存一次checkpointlearning_rate=1e-4, # 学习率gradient_checkpointing=True, # 启用梯度检查点(节省显存)fp16=True, # 使用混合精度训练(如果GPU支持)logging_dir="output/logs", # TensorBoard日志路径save_total_limit=3, # 最多保留3个checkpointwarmup_steps=100, # 学习率预热步数weight_decay=0.01, # 权重衰减
)
实例化 Trainer
from transformers import Trainer, default_data_collator
from torchdata.datapipes.iter import IterableWrapper# 创建训练器
trainer = Trainer(model=model, # 模型args=training_args, # 训练参数train_dataset=IterableWrapper(train_dataset), # 训练数据eval_dataset=None, # 验证数据(可选)tokenizer=tokenizer, # Tokenizerdata_collator=default_data_collator # 数据整理器(CLM默认)
)
开始训练
# 启动训练
train_result = trainer.train()# 保存最终模型
trainer.save_model()# 打印训练统计
print(f"训练损失: {train_result.training_loss:.4f}")
print(f"训练时长: {train_result.metrics['train_runtime']:.2f}秒")
输出内容:
训练损失: 2.3456
训练时长: 3600.00秒
注: 完整代码可参考 ./code/pretrain.ipynb 文件。
6.1.5 使用 DeepSpeed 实现分布式训练
由于预训练规模大、时间长,生产环境中通常需要:
- 使用 Python 脚本而非 Jupyter Notebook(避免中断)
- 使用多卡分布式训练(提高效率)
本节介绍如何使用 DeepSpeed 框架实现高效的分布式训练。
训练脚本结构
创建 pretrain.py 脚本,完整实现训练流程。
1. 导入依赖库
import logging
import math
import os
import sys
from dataclasses import dataclass, field
from torchdata.datapipes.iter import IterableWrapper
from itertools import chain
import deepspeed
from typing import Optional, Listimport datasets
import pandas as pd
import torch
from datasets import load_dataset
import transformers
from transformers import (AutoConfig,AutoModelForCausalLM,AutoTokenizer,HfArgumentParser,Trainer,TrainingArguments,default_data_collator,set_seed,
)
import datetime
from transformers.testing_utils import CaptureLogger
from transformers.trainer_utils import get_last_checkpoint
import swanlab
2. 定义超参数类
@dataclass
class ModelArguments:"""模型相关参数"""model_name_or_path: Optional[str] = field(default=None,metadata={"help": "预训练模型路径(用于继续训练)"})config_name: Optional[str] = field(default=None, metadata={"help": "模型配置文件路径(用于从零训练)"})tokenizer_name: Optional[str] = field(default=None, metadata={"help": "Tokenizer路径"})torch_dtype: Optional[str] = field(default=None,metadata={"help": "模型数据类型","choices": ["auto", "bfloat16", "float16", "float32"],},)@dataclass
class DataTrainingArguments:"""数据相关参数"""train_files: Optional[List[str]] = field(default=None, metadata={"help": "训练数据文件路径列表"})block_size: Optional[int] = field(default=None,metadata={"help": "文本块长度(如2048)"})preprocessing_num_workers: Optional[int] = field(default=None,metadata={"help": "数据预处理并行进程数"})
3. 主函数实现
def main():# 解析命令行参数parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))model_args, data_args, training_args = parser.parse_args_into_dataclasses()# 配置日志系统logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",handlers=[logging.StreamHandler(sys.stdout)],)logger = logging.getLogger(__name__)log_level = training_args.get_process_log_level()logger.setLevel(log_level)datasets.utils.logging.set_verbosity(log_level)transformers.utils.logging.set_verbosity(log_level)transformers.utils.logging.enable_default_handler()transformers.utils.logging.enable_explicit_format()# 记录训练环境信息logger.warning(f"进程排名: {training_args.local_rank}, "f"设备: {training_args.device}, "f"GPU数量: {training_args.n_gpu}, "f"分布式训练: {bool(training_args.local_rank != -1)}, "f"混合精度: {training_args.fp16 or training_args.bf16}")logger.info(f"训练参数: {training_args}")# 检查并恢复checkpointlast_checkpoint = Noneif os.path.isdir(training_args.output_dir):last_checkpoint = get_last_checkpoint(training_args.output_dir)if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:raise ValueError(f"输出路径 ({training_args.output_dir}) 已存在且非空")elif last_checkpoint is not None:logger.info(f"从 checkpoint 恢复训练: {last_checkpoint}")# 设置随机种子set_seed(training_args.seed)# 初始化模型if model_args.config_name is not None:# 从零训练config = AutoConfig.from_pretrained(model_args.config_name)logger.warning("从零初始化模型")logger.info(f"配置文件: {model_args.config_name}")model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())logger.info(f"新模型参数量: {n_params/2**20:.2f}M")elif model_args.model_name_or_path is not None:# 继续训练logger.warning("加载预训练模型")logger.info(f"模型路径: {model_args.model_name_or_path}")model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path,trust_remote_code=True)n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())logger.info(f"预训练模型参数量: {n_params/2**20:.2f}M")else:raise ValueError("必须指定 config_name 或 model_name_or_path")# 加载 Tokenizertokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name)logger.info("Tokenizer 加载完成")# 加载和处理数据(此处省略,与6.1.3节相同)# ...# 初始化 SwanLab 监控swanlab.init(project="pretrain", experiment_name="qwen-1.5b-pretrain")# 创建 Trainerlogger.info("初始化 Trainer")trainer = Trainer(model=model,args=training_args,train_dataset=IterableWrapper(train_dataset),tokenizer=tokenizer,data_collator=default_data_collator)# 确定 checkpointcheckpoint = Noneif training_args.resume_from_checkpoint is not None:checkpoint = training_args.resume_from_checkpointelif last_checkpoint is not None:checkpoint = last_checkpoint# 开始训练logger.info("开始训练")train_result = trainer.train(resume_from_checkpoint=checkpoint)# 保存模型trainer.save_model()logger.info(f"模型已保存至: {training_args.output_dir}")# 记录训练指标metrics = train_result.metricstrainer.log_metrics("train", metrics)trainer.save_metrics("train", metrics)trainer.save_state()if __name__ == "__main__":main()
DeepSpeed 配置
创建 ds_config_zero2.json 配置文件:
{"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"bf16": {"enabled": "auto"},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto"}},"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "none","pin_memory": true},"allgather_partitions": true,"allgather_bucket_size": 2e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 2e8,"contiguous_gradients": true},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","steps_per_print": 100,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}
配置说明:
zero_optimization.stage: 2:使用 ZeRO-2 优化(第四章详细介绍过)bf16.enabled: "auto":自动检测是否支持 BFloat16optimizer:使用 AdamW 优化器scheduler:使用线性预热学习率调度器
启动脚本
创建 pretrain.sh 启动脚本:
#!/bin/bash# 指定可见GPU
export CUDA_VISIBLE_DEVICES=0,1# 使用 DeepSpeed 启动分布式训练
deepspeed pretrain.py \--config_name autodl-tmp/qwen-1.5b \--tokenizer_name autodl-tmp/qwen-1.5b \--train_files autodl-tmp/dataset/pretrain_data/mobvoi_seq_monkey_general_open_corpus_small.jsonl \--per_device_train_batch_size 16 \--gradient_accumulation_steps 4 \--do_train \--output_dir autodl-tmp/output/pretrain \--evaluation_strategy no \--learning_rate 1e-4 \--num_train_epochs 1 \--warmup_steps 200 \--logging_dir autodl-tmp/output/pretrain/logs \--logging_strategy steps \--logging_steps 5 \--save_strategy steps \--save_steps 100 \--preprocessing_num_workers 10 \--save_total_limit 1 \--seed 12 \--block_size 2048 \--bf16 \--gradient_checkpointing \--deepspeed ./ds_config_zero2.json \--report_to swanlab# --resume_from_checkpoint ${output_model}/checkpoint-20400 # 可选:从checkpoint恢复
启动训练:
bash pretrain.sh
输出内容:
[2024-10-06 10:00:00] INFO: 进程排名: 0, 设备: cuda:0, GPU数量: 2
[2024-10-06 10:00:01] INFO: 开始训练
[2024-10-06 10:00:05] INFO: Step 5, Loss: 3.2456
[2024-10-06 10:00:10] INFO: Step 10, Loss: 3.1234
...
SwanLab 会在终端输出监控 URL,点击即可实时查看训练指标(loss曲线、学习率变化等)。