【Python LeetCode 专题】面试经典 150 题
- 数组 / 字符串
- 快慢指针(双指针)总结
- 88. 合并两个有序数组
- 27. 移除元素
- 26. 删除有序数组中的重复项
- 80. 删除有序数组中的重复项 II
- `Boyer-Moore` 投票算法
- 169. 多数元素
- 扩展:寻找 n/3 多数元素
- 翻转法
- 189. 轮转数组
- 贪心
- 121. 买卖股票的最佳时机
- 122. 买卖股票的最佳时机 II
- 55. 跳跃游戏
- 45. 跳跃游戏 II
- 274. H 指数
- 前缀 / 后缀
- 238. 除自身以外数组的乘积
- 134. 加油站
- 双指针
- 125. 验证回文串
- 滑动窗口
- 矩阵
- 哈希表
- 380. O(1) 时间插入、删除和获取随机元素
- 二叉树
- 104. 二叉树的最大深度
- 100. 相同的树
- 226. 翻转二叉树
- 分治
- 回溯
- 52. N 皇后 II
- 多维动态规划
- 97. 交错字符串
数组 / 字符串
快慢指针(双指针)总结
“快慢指针” 主要用于 数组的原地修改问题,避免额外空间开销,同时保证 O(n) 线性时间复杂度。
| 题目 | 题目要求 | 快指针 i | 慢指针 p |
|---|---|---|---|
| 合并两个有序数组 | nums1 和 nums2 归并排序 | 遍历 nums1 & nums2,从后向前合并 | 指向 nums1 末尾,填充较大值 |
| 移除元素 | nums 中移除 val,保持相对顺序 | 遍历 nums,查找非 val 元素 | 记录下一个非 val 元素存放位置 |
| 删除有序数组中的重复项 | 只保留 1个,相对顺序不变 | 遍历 nums,查找不同的元素 | 记录下一个唯一元素存放位置 |
| 删除有序数组中的重复项 II | 只保留 最多 2 个 | 遍历 nums,查找满足出现≤2次的元素 | 记录下一个可存放元素的位置 |
快慢指针的核心思路:
- 遍历数组(快指针
i负责遍历数组) - 找到符合条件的元素(如不同于前一个元素、出现次数不超过 2 次等)
- 将其存放到正确的位置(
p负责记录符合条件的元素存放位置) - 最终
p代表新的数组长度
88. 合并两个有序数组

下面两行代码就可以解决,
nums1[m:] = nums2 # 把 nums2 拼接到 nums1 从下标 m 开始后面
nums1.sort() # 默认升序排序
不过还是规规矩矩用双指针法写一下吧,

class Solution:
def merge(self, nums1: List[int], m: int, nums2: List[int], n: int) -> None:
"""
Do not return anything, modify nums1 in-place instead.
"""
# 指针分别指向 nums1 和 nums2 的最后一个有效元素
p1, p2 = m - 1, n - 1
# 指针 p 指向合并后数组的最后一个位置
p = m + n - 1
# 从后往前合并
while p1 >= 0 and p2 >= 0:
if nums1[p1] > nums2[p2]:
nums1[p] = nums1[p1]
p1 -= 1
else:
nums1[p] = nums2[p2]
p2 -= 1
p -= 1
# 如果 nums2 还有剩余元素,填充到 nums1
while p2 >= 0:
nums1[p] = nums2[p2]
p2 -= 1
p -= 1
27. 移除元素

class Solution:
def removeElement(self, nums: List[int], val: int) -> int:
# 维护一个慢指针 k 指向下一个存放非 val 元素的位置
k = 0
# 遍历数组
for num in nums:
if num != val: # 只有当元素不等于 val 时,才放入 nums[k] 位置
nums[k] = num
k += 1 # k 向前移动
return k # 返回新的数组长度
26. 删除有序数组中的重复项

class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
# 慢指针 k 记录下一个存放唯一元素的位置
k = 1
# 遍历数组
for i in range(1, len(nums)):
if nums[i] != nums[i - 1]: # 只有当当前元素不等于前一个元素时才存入
nums[k] = nums[i]
k += 1 # 移动慢指针
return k # 返回唯一元素的个数
80. 删除有序数组中的重复项 II

class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
"""
Do not return anything, modify nums in-place instead.
"""
if len(nums) <= 2:
return len(nums) # 数组长度小于等于2时,直接返回
# 指针 p 记录下一个存放元素的位置
p = 2
for i in range(2, len(nums)):
if nums[i] != nums[p - 2]: # 只有当 nums[i] ≠ nums[p-2] 时,才可以保留
nums[p] = nums[i]
p += 1 # 递增存放位置
return p # p 就是去重后的数组长度
Boyer-Moore 投票算法
Boyer-Moore 投票算法(Boyer-Moore Voting Algorithm) 是一种用于在 数组中寻找出现次数超过 ⌊n/2⌋ 的元素(即 多数元素)的高效算法。
该算法的 时间复杂度为 O ( n ) O(n) O(n),空间复杂度为 O ( 1 ) O(1) O(1),只需要一次遍历和常数级额外空间,非常高效。
- 若一个元素出现超过
n/2次,它的 票数净增量一定是正的。- 其他元素的 抵消票数永远无法超过多数元素的总数。
- 这样,多数元素的 最终
count绝对不会归零,即使在过程中count可能降为零,换新的candidate后,最终的candidate仍然是多数元素。
169. 多数元素

可以使用 Boyer-Moore 投票算法 来 高效找出多数元素。该算法的时间复杂度为
O
(
n
)
O(n)
O(n),空间复杂度为
O
(
1
)
O(1)
O(1)。
- 核心思想:抵消计数,如果某个元素是多数元素(出现次数
> ⌊n/2⌋),那么它最终一定会成为 唯一剩下的候选人。 - 计数规则:遇到相同的元素,
count +1;遇到不同的元素,count -1。当count == 0时,换一个候选人。
由于 多数元素的出现次数超过 ⌊n/2⌋,即使被其他元素抵消,也最终会留在 candidate 里。
class Solution:
def majorityElement(self, nums: List[int]) -> int:
"""
Boyer-Moore 投票算法
"""
candidate = None # 维护一个 候选元素
count = 0 # 计数器
for num in nums:
if count == 0:
candidate = num # 选择新的候选多数元素
count += (1 if num == candidate else -1) # 增加票数 或 抵消票数
return candidate # 因为题目说多数元素一定存在,最终 candidate 即为结果
扩展:寻找 n/3 多数元素
如果需要找 出现次数超过 n/3 的元素,则可以维护 两个候选人 和 两个计数器:
class Solution:
def majorityElement(self, nums: List[int]) -> List[int]:
candidate1, candidate2, count1, count2 = None, None, 0, 0
for num in nums:
if count1 == 0:
candidate1, count1 = num, 1
elif count2 == 0:
candidate2, count2 = num, 1
elif num == candidate1: # 投票给候选人 1
count1 += 1
elif num == candidate2: # 投票给候选人 2
count2 += 1
else: # 没有投票给两个候选人中的任何一人
count1 -= 1
count2 -= 1
# 第二遍遍历,检查候选人是否真的超过 n/3
return [c for c in (candidate1, candidate2) if nums.count(c) > len(nums) // 3]
翻转法
翻转法中,交换变量使用 a, b = b, a,本质上是 元组打包(tuple packing)+ 元组解包(tuple unpacking),它的底层实现依赖于:栈操作+引用变更,不会创建新的对象,只是 交换变量指向的内存地址。
ROT_TWO是 Python 字节码中的一个栈操作指令,用于 交换栈顶的两个元素。case ROT_TWO: { PyObject *top = STACK_POP(); // 取出栈顶元素(指针引用) PyObject *second = STACK_POP(); // 取出次栈顶元素(指针引用) STACK_PUSH(top); // 先压入原来的栈顶 STACK_PUSH(second); // 再压入原来的次栈顶 DISPATCH(); }
PyObject *top和PyObject *second只是指向原来 Python 对象的指针,并没有创建新的对象。STACK_POP()只是修改了栈指针,而不是拷贝对象。STACK_PUSH()只是把相同的指针重新放回去,没有额外的内存分配。
因此,交换是 “原地” 进行的,不涉及对象复制或新分配。
189. 轮转数组

翻转法 利用 三次反转 完成 原地修改,时间
O
(
n
)
O(n)
O(n),空间
O
(
1
)
O(1)
O(1),高效且简洁。
class Solution:
def rotate(self, nums: List[int], k: int) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
n = len(nums)
k = k % n # 防止 k 大于 n,取模优化
# 定义反转函数
def reverse(start: int, end: int):
while start < end:
nums[start], nums[end] = nums[end], nums[start]
start += 1
end -= 1
reverse(0, n - 1) # 反转整个数组
reverse(0, k - 1) # 反转前 k 个元素
reverse(k, n - 1) # 反转后 n-k 个元素
贪心
121. 买卖股票的最佳时机

先考虑最简单的 暴力遍历,即枚举出所有情况,并从中选择最大利润。时间复杂度为
O
(
N
2
)
O(N^2)
O(N2) 。考虑到题目给定的长度范围 1≤prices.length≤10^5,需要思考更优解法。
- 由于卖出肯定在买入后,所以 从前往后遍历维护一个最小价格
min_price,肯定是碰到越小价格更有可能利润更大。 - 由于要求最大利润,所以 维护一个最大利润
max_profit,当天的利润就是当天的价格减去遇到的最低价price - min_price,遇到更高利润就更新。
class Solution:
def maxProfit(self, prices: List[int]) -> int:
min_price, max_profit = float('+inf'), 0 # 最低价格,最高利润
for price in prices:
min_price = min(min_price, price) # 更新最低价格
max_profit = max(max_profit, price - min_price) # 更新最高利润
return max_profit
122. 买卖股票的最佳时机 II

基本思路:所有上涨交易日都买卖(赚到所有利润),所有下降交易日都不买卖(绝不亏钱)。

class Solution:
def maxProfit(self, prices: List[int]) -> int:
max_profit = 0
for i in range(1, len(prices)):
if prices[i] - prices[i-1] > 0:
max_profit += prices[i] - prices[i-1] # 累积 盈利
return max_profit
55. 跳跃游戏

思路:尽可能到达最远位置。如果能到达某个位置,那一定能到达它前面的所有位置。
class Solution:
def canJump(self, nums: List[int]) -> bool:
n = len(nums)
max_index = 0 # 记录最远可跳跃的位置
for i in range(n):
if i > max_index: # 无法到达 i 位置就无法到达最后下标
return False
max_index = max(max_index, nums[i] + i) # 更新最远位置
if max_index >= n-1:
return True
45. 跳跃游戏 II

- 贪心策略:每次选择能跳得最远的位置,从而尽可能减少跳跃的次数。
- 维护当前跳跃区间:在每一步,会有一个“当前区间”,它表示 从当前跳跃开始,能够到达的最远位置。在区间内,更新最远可以跳到的位置。
- 跳跃次数:每次更新最远的位置后,意味着完成了一次跳跃,需要跳到下一个区间。
class Solution:
def jump(self, nums: List[int]) -> int:
jumps = 0 # 跳跃次数
current_end = 0 # 当前跳跃区间的右端
farthest = 0 # 能跳到的最远位置
# 遍历数组,跳跃的次数
for i in range(len(nums) - 1): # 不需要遍历最后一个位置
farthest = max(farthest, i + nums[i]) # 更新最远可以到达的位置
# 如果当前已经到达了当前跳跃区间的右端
if i == current_end:
jumps += 1 # 需要跳跃一次
current_end = farthest # 更新跳跃区间的右端
# 如果当前跳跃区间的右端已经超过了最后一个位置,直接返回跳跃次数
if current_end >= len(nums) - 1:
return jumps
return jumps
274. H 指数

- 排序:首先将
citations数组按 从大到小排序。 - 遍历排序后的数组:从第一个元素开始,检查每个元素是否满足条件
citations[i] >= i + 1,其中i + 1是当前论文的排名。 - 最大
h值:最终,最大的i + 1使得citations[i] >= i + 1即为h指数。
class Solution:
def hIndex(self, citations: List[int]) -> int:
citations.sort(reverse=True) # 对引用次数进行降序排序
# 遍历已排序的 citations 数组,找到最大 h 指数
for i in range(len(citations)):
if citations[i] < i + 1: # 论文 i + 1 应该有 citations[i] 次引用
return i # 返回 h 指数
return len(citations) # 如果所有的论文的引用次数都满足,返回数组长度
前缀 / 后缀
238. 除自身以外数组的乘积

可以分两步来完成这个任务:
-
前缀积:首先计算每个位置的前缀积,即从数组的最左侧到当前位置之前所有元素的乘积。这可以通过一个临时数组
answer来实现,其中answer[i]表示nums[0]到nums[i-1]的乘积。 -
后缀积:然后计算每个位置的后缀积,即从数组的最右侧到当前位置之后所有元素的乘积。这可以通过另一个临时变量
right来实现,直接从右到左更新answer数组。
class Solution:
def productExceptSelf(self, nums: List[int]) -> List[int]:
n = len(nums)
# 初始化答案数组
answer = [1] * n
# 计算前缀积,存入 answer 数组
left_product = 1
for i in range(n):
answer[i] = left_product
left_product *= nums[i]
# 计算后缀积,直接更新 answer 数组
right_product = 1
for i in range(n-1, -1, -1):
answer[i] *= right_product
right_product *= nums[i]
return answer
134. 加油站

双指针
125. 验证回文串

c.lower()将字符c转换为小写。c.isalnum()判断字符c是否是字母或数字。如果是字母或数字,就保留该字符;否则跳过。- 通过 字符串的切片操作
[::-1]获取字符串filtered_s的反转版本。
class Solution:
def isPalindrome(self, s: str) -> bool:
# 只保留字母和数字,并转换为小写
filtered_s = ''.join(c.lower() for c in s if c.isalnum())
# 比较正着读和反着读是否相同
return filtered_s == filtered_s[::-1]
双指针:利用 两个指针从字符串的两端开始同时向中间移动,检查字符是否相等,同时跳过所有非字母和数字的字符。
class Solution:
def isPalindrome(self, s: str) -> bool:
# 初始化左右指针
left, right = 0, len(s) - 1
while left < right:
# 跳过非字母数字字符
while left < right and not s[left].isalnum():
left += 1
while left < right and not s[right].isalnum():
right -= 1
# 比较字符,忽略大小写
if s[left].lower() != s[right].lower():
return False
# 移动指针
left += 1
right -= 1
return True
滑动窗口
矩阵
哈希表
380. O(1) 时间插入、删除和获取随机元素

基本思路是结合使用 **哈希表(字典)**和 列表(数组)。
- 插入操作
insert(val):- 用一个哈希表(
val -> index)来 记录每个元素的值及其在列表中的位置。这样查找和删除元素时都能在 O ( 1 ) O(1) O(1) 时间内完成。 - 列表
list用来存储元素,以便可以 快速地随机获取一个元素。
- 用一个哈希表(
- 删除操作
remove(val):- 需要从列表中删除一个元素,并且保证其他元素的顺序尽量不被破坏,同时保持 O ( 1 ) O(1) O(1) 的时间复杂度。
- 可以通过 将要删除的元素与列表中的最后一个元素交换位置,然后从哈希表中删除该元素。这样删除操作的时间复杂度是 O ( 1 ) O(1) O(1)。
- 随机获取操作
getRandom():利用 列表的下标来随机访问元素,时间复杂度是 O ( 1 ) O(1) O(1)。
import random
class RandomizedSet:
def __init__(self):
# 哈希表存储值及其索引,列表存储值
self.val_to_index = {}
self.list = []
def insert(self, val: int) -> bool:
if val in self.val_to_index:
return False # 如果已经存在,返回 False
# 插入操作:将元素添加到列表末尾,并在哈希表中记录该值和索引
self.val_to_index[val] = len(self.list)
self.list.append(val)
return True
def remove(self, val: int) -> bool:
if val not in self.val_to_index:
return False # 如果元素不存在,返回 False
# 找到元素的索引
index = self.val_to_index[val]
# 将要删除的元素与最后一个元素交换位置
last_element = self.list[-1]
self.list[index] = last_element
self.val_to_index[last_element] = index
# 删除该元素
self.list.pop()
del self.val_to_index[val]
return True
def getRandom(self) -> int:
return random.choice(self.list) # 随机返回列表中的一个元素
# Your RandomizedSet object will be instantiated and called as such:
# obj = RandomizedSet()
# param_1 = obj.insert(val)
# param_2 = obj.remove(val)
# param_3 = obj.getRandom()
二叉树
104. 二叉树的最大深度

# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def maxDepth(self, root: Optional[TreeNode]) -> int:
# 如果当前节点为空,返回深度 0
if not root:
return 0
# 递归计算左子树和右子树的最大深度
left_depth = self.maxDepth(root.left)
right_depth = self.maxDepth(root.right)
# 当前节点的深度是左右子树深度的最大值 + 1
return max(left_depth, right_depth) + 1
100. 相同的树

class Solution:
def isSameTree(self, p: Optional[TreeNode], q: Optional[TreeNode]) -> bool:
if not p and not q: # 两棵树都为空
return True
elif not p or not q: # 只有一棵树为空
return False
if p.val != q.val: # 两棵树都不空但节点值不同
return False
# 两棵树都不空且节点值相同,递归比较
return self.isSameTree(p.left, q.left) and self.isSameTree(p.right, q.right)
226. 翻转二叉树

分治
回溯
52. N 皇后 II
class Solution:
def totalNQueens(self, n: int) -> int:
num = 0 # 记录不同解决方案数
line, diag1, diag2 = [0] * n, [0] * (2 * n), [0] * (2 * n)
def backtrack(x):
nonlocal num # 声明 num 为 nonlocal 变量,允许修改外部的 num
if x == n:
num += 1 # 如果所有皇后都放置完毕,则方案数加1
return
for y in range(n): # 对每一列
# 如果该列、左对角线或右对角线已被占用,则跳过
if line[y] or diag1[x + y] or diag2[x - y + (n - 1)]:
continue
# 否则是合理的方案,继续递归下一行
line[y] = diag1[x + y] = diag2[x - y + (n - 1)] = 1
backtrack(x + 1)
line[y] = diag1[x + y] = diag2[x - y + (n - 1)] = 0
backtrack(0)
return num
Q1. 为什么 num 需要 nonlocal?line 和其他两个列表却不需要?
nonlocal是用来修改外层作用域(但不是全局作用域)的 不可变 变量(如整数、字符串等)的。- 对于 可变 类型(如列表、字典、集合等),可以直接修改它们的元素而不需要使用
nonlocal。
参考文章:Python 变量作用域
多维动态规划
97. 交错字符串
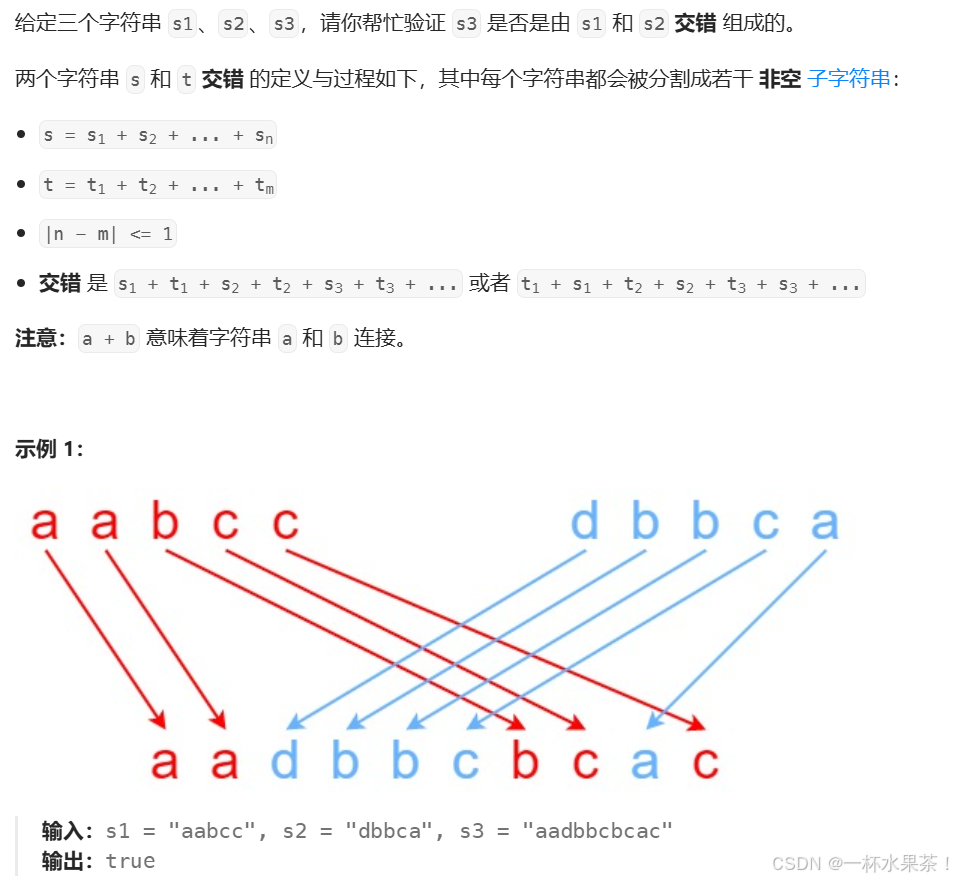
交错的定义是:从 s1 和 s2 中选择字符,并且字符按顺序从左到右插入到 s3 中。
-
DP 数组定义:
dp[i][j]为True表示s3的前i + j个字符能通过将s1的前i个字符和s2的前j个字符交错组成。dp[i][j]为False表示无法通过s1和s2的前i和j个字符交错组成s3的前i + j个字符。
-
初始化 DP 表:
dp[0][0] = True,因为两个空字符串交错就是空字符串。- 初始化第一列和第一行,分别表示只使用
s1或只使用s2时是否可以组成s3。
-
填充 DP 表:对于 每个位置
dp[i][j],考虑两种情况:- 如果上一个状态是
dp[i-1][j]且s1[i-1] == s3[i + j - 1],则可以由s1的字符推导过来。 - 如果上一个状态是
dp[i][j-1]且s2[j-1] == s3[i + j - 1],则可以由s2的字符推导过来。
- 如果上一个状态是
-
时间复杂度:
O(n * m),其中n和m分别是s1和s2的长度。需要填充一个大小为(n+1) * (m+1)的 DP 表,时间复杂度是线性的。 -
空间复杂度:
O(n * m),使用了一个大小为(n+1) * (m+1)的 DP 数组。
class Solution:
def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
# 如果 s1, s2, s3 长度不匹配,直接返回 False
if len(s1) + len(s2) != len(s3):
return False
# 创建 DP 表,dp[i][j] 表示 s1[:i] 和 s2[:j] 能否交错组成 s3[:i+j]
dp = [[False] * (len(s2) + 1) for _ in range(len(s1) + 1)]
# 边界条件,dp[0][0] 表示两个空字符串交错组成空字符串
dp[0][0] = True
# 初始化第一列
for i in range(1, len(s1) + 1):
dp[i][0] = dp[i - 1][0] and s1[i - 1] == s3[i - 1]
# 初始化第一行
for j in range(1, len(s2) + 1):
dp[0][j] = dp[0][j - 1] and s2[j - 1] == s3[j - 1]
# 填充整个 DP 表
for i in range(1, len(s1) + 1):
for j in range(1, len(s2) + 1):
dp[i][j] = (dp[i - 1][j] and s1[i - 1] == s3[i + j - 1]) or \
(dp[i][j - 1] and s2[j - 1] == s3[i + j - 1])
# 返回 dp[len(s1)][len(s2)] 即为最终结果
return dp[len(s1)][len(s2)]
上面的代码巧用 and 和 or 来判断条件,代替了下面繁杂的代码,
n1, n2, n3 = len(s1), len(s2), len(s3)
for i in range(1, n1+1): # 初始化 dp[i][0]
if s1[i-1] == s3[i-1]:
dp[i][0] = True
else:
break
for j in range(1, n2+1): # 初始化 dp[0][j]
if s2[j-1] == s3[j-1]:
dp[0][j] = True
else:
break
for i in range(1, n1+1): # 复制 dp[i][j], i,j >= 1
for j in range(1, n2+1):
if s3[i+j-1] == s1[i-1]:
dp[i][j] = dp[i-1][j]
elif s3[i+j-1] == s2[j-1]:
dp[i][j] = dp[i][j-1]