Unity Burst编译
官网文档:https://docs.unity3d.com/Packages/com.unity.burst@1.8/manual/index.html
Unity 之Burst 底层原理:https://zhuanlan.zhihu.com/p/623274986
Burst 编译器入门(五):https://developer.unity.cn/projects/5e62f15eedbc2a1feeebb83e
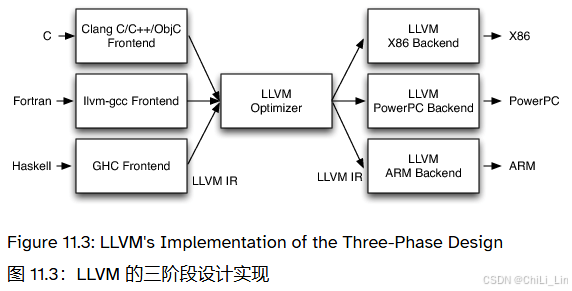
LLVM:https://llvm.org/
LLVM:https://aosabook.org/en/v1/llvm.html
編譯器 LLVM 淺淺玩:https://medium.com/@zetavg/%E7%B7%A8%E8%AD%AF%E5%99%A8-llvm-%E6%B7%BA%E6%B7%BA%E7%8E%A9-42a58c7a7309#20b5
一个故事看懂CPU的SIMD技术:https://www.cnblogs.com/xuanyuan/p/16048303.html
介绍
- Burst 是一个编译器,目的是把代码跑的更高效。主要优化技术密集的任务。
- LLVM的激进优化。
- SIMD向量化:循环操作转为单指令多数据指令。(一个加法变四个加法一起算)
- 循环展开:if等分支展开,比如经常true的再优化。Hint intrinsics
- 自动内联:把小函数自动内联展开。
- 无GC检测:因为操作都是非托管数据,所以省去一些不必要的检测。
- LLVM的激进优化。
- 2019年官方说的: Burst必须只能在JobSystem中使用,其他地方是不能用的。
- 从 IL/.NET 字节码转换为使用 LLVM 编译器的优化原生 CPU 代码。
- C#代码 -> IL -> LLVM IR -> 原生机器码
- 适用于:
- 物理碰撞。
- 粒子系统刷新。
- 图形算法处理。
LLVM
- 模块化编译器,是一组库,可以针对特定问题优化。

和 IL2CPP 的关系
-
互不影响,两套编译方式。
-
普通代码走IL2CPP编译成C++机器码。
-
标记
[BurstCompile]的代码,有Burst单独编译优化,生成更高效的机器码。
调试
-
https://docs.unity3d.com/Packages/com.unity.burst@1.8/manual/editor-burst-inspector.html
-
Unity菜单:
Jobs/Burst/Open Inspector

测试
-
对比各种遍历耗时
- 测试了
List<T>和 定长数组,相同操作都是定长数组更快一点。
- 测试了
-
测试长度遍历一千万,测了一百万差异差不多。
测试代码
private const int TEST_COUNT = 10000000;
private float[] _managedArray = new float[TEST_COUNT]; // 托管
private NativeArray<float> _nativeArray; // 非托管
private void Run()
{
_nativeArray = new NativeArray<float>(TEST_COUNT, Allocator.Persistent);
for (int i = 0; i < TEST_COUNT; i++)
{
_managedArray[i] = i;
_nativeArray[i] = i;
}
// 测试List,同下面Array
...
//
Debug.LogError("Test Array");
using (new MyStopWatch("ManagedArray"))
{
for (int i = 0; i < TEST_COUNT; i++)
_managedArray[i] = i + 5;
}
using (new MyStopWatch("TestNativeArray"))
{
for (int i = 0; i < TEST_COUNT; i++)
_nativeArray[i] = i + 5;
}
using (new MyStopWatch("TestNativeList Job"))
{
var job = new NativeArrayJob { Data = _nativeArray };
job.Run();
}
using (new MyStopWatch("TestNativeList Burst Job"))
{
var job = new NativeArrayBurstJob { Data = _nativeArray };
job.Run();
}
using (new MyStopWatch("TestNativeArray Burst JobParallelFor"))
{
// List动态扩容,不支持多线程写入
var job = new NativeArrayBurstJobParallelFor() { Data = _nativeArray };
job.Schedule(TEST_COUNT, 64).Complete();
}
using (new MyStopWatch("TestNativeArray Burst"))
{
TestNativeArrayBurst(ref _nativeArray);
}
using (new MyStopWatch("TestNativeArray Burst Break"))
{
TestNativeArrayBurstBreak(ref _nativeArray);
}
// Natvie容器要自己释放
_nativeList.Dispose();
}
// 普通带Burst编译
[BurstCompile]
private static void TestNativeArrayBurst([NoAlias]ref NativeArray<float> list)
{
for (int i = 0; i < TEST_COUNT; i++)
list[i] = i + 5;
}
// 带Burst编译,但是加分支打断SIMD向量化
[BurstCompile]
private static void TestNativeArrayBurstBreak([NoAlias]ref NativeArray<float> list)
{
for (int i = 0; i < TEST_COUNT; i++)
{
if (i == 0) list[i] = i + 7; // 加个分支,打断Loop vectorization
list[i] = i + 5;
}
}
// 普通Job
struct NativeArrayJob : IJob
{
public NativeArray<float> Data;
public void Execute()
{
for (int i = 0; i < TEST_COUNT; i++)
Data[i] = i + 5;
}
}
// 带Burst的Job
[BurstCompile]
struct NativeArrayBurstJob : IJob
{
public NativeArray<float> Data;
public void Execute()
{
for (int i = 0; i < TEST_COUNT; i++)
Data[i] = i + 5;
}
}
// 带Burst的多线程Job
[BurstCompile]
struct NativeArrayBurstJobParallelFor : IJobParallelFor
{
public NativeArray<float> Data;
public void Execute(int index)
{
Data[index] = index + 6;
}
}
测试结果
-
PC端跑一千万次循环
array[i]=i+5
-
MUMU模拟器 64位,跑一亿次循环
array[i]=i+5
| 安卓跑一亿次array[i]=i+5 | 耗时 | 代码 |
|---|---|---|
| 普通数组 | 80ms |  |
| NativeArray | 32ms |  |
| 丢到Job中执行 | 34ms |  |
| Burst编译的Job | 31ms |  |
Burst编译的多线程Job。不支持NativeList<T>,因为可能出现动态扩容,导致线程不安全。 | 28ms |  |
| 普通Burst函数 | 34ms |  |
| 普通Burst函数,但是打断SIMD向量化 | 78ms | 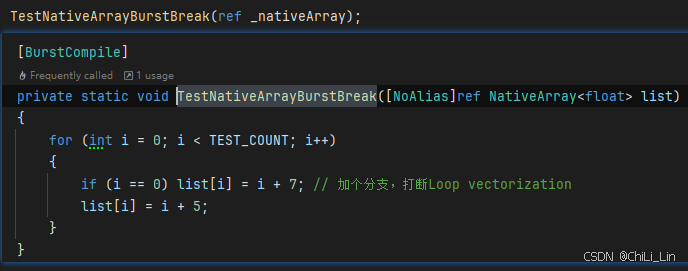 |
- 跑一亿次循环
array[i]=math.sin(i+5),左图:MUMU模拟器 64位,右图:RedmiNote12

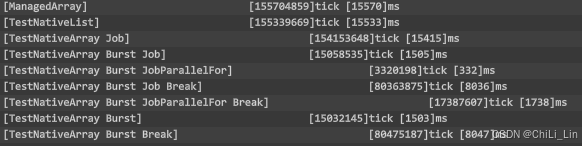
| 安卓跑一亿次sin(i+5) | 模拟器耗时/ms | 真机耗时/ms |
|---|---|---|
| 普通数组 | 6080 | 15570 |
| NativeArray | 5922 | 15533 |
| 丢到Job中执行 | 5903 | 15415 |
| Burst编译的Job | 2125 | 1505 |
| Burst编译的多线程Job | 573 | 332 |
| 普通Burst函数 | 2116 | 1503 |
| 普通Burst函数,但是打断SIMD向量化 | 23520 | 8047 |
| Burst编译的Job,但是打断SIMD向量化 | 23165 | 8036 |
| Burst编译的多线程Job,但是打断SIMD向量化 | 5944 | 1738 |
- 模拟器下,同样循环内容下(有
if和math.sin),burst编译反而跑的更慢了。可能中低端设备负优化了?
SIMD向量化
-
https://docs.unity3d.com/Packages/com.unity.burst@1.8/manual/optimization-loop-vectorization.html
-
如果有分支或者计算结果有前后依赖,就无法向量化。简单的计算可以手动向量化用
float4等。

总结
-
复杂计算效率
Burst + JobParallelFor>Burst + Job>=Burst>Job>= 常规。 -
平常开发不涉及大量计算,直接用托管
List<T>等常规容器就好了。托管环境Native容器虽然也快一点,但需要自己释放。