李宏毅机器学习笔记16
目录
摘要
Abstract
1.GAN的训练难点
2.判断generator好坏
3.评估方法
Inception score(IS)
Frechet inception Distance(FID)
摘要
本周继续学习李宏毅老师2025春季机器学习课程,本周学习内容是GAN在训练中会遇见的问题及简单的解决方法,以及判断generator好坏会遇见的问题和评估好坏的方法。
Abstract
This week, I continued with Prof. Hung-yi Lee's 2025 Spring Machine Learning Course. The learning content covered issues commonly encountered during GAN training along with basic solutions, as well as challenges in evaluating the generator's performance and methods for assessing its quality.
1.GAN的训练难点
GAN有一个本质上困难的地方,discriminator做的事情是分辨真的图片与产生出来的图片也就是假的图片的差异,generator在做的事情是产生假的图片骗过discriminator,实际上这discriminator和generator是相互激励的,如果其中一个发生问题停止训练,那么另一个就会跟着停下。例如discriminator没有办法发现真假图片的差异,那么generator就失去了他进步的目标无法进步,那么generator无法进步,discriminator也就无法进步,最后陷入死循环都无法进步。
训练GAN最难的其实是用GAN产生文字,如果用GAN生成一段文字,这个是最困难的。如果要生成一段文字看你会有一个sequence to sequence的model,有一个decoder,decoder会产生一段文字,sequence to sequence的model就是我们的generator。
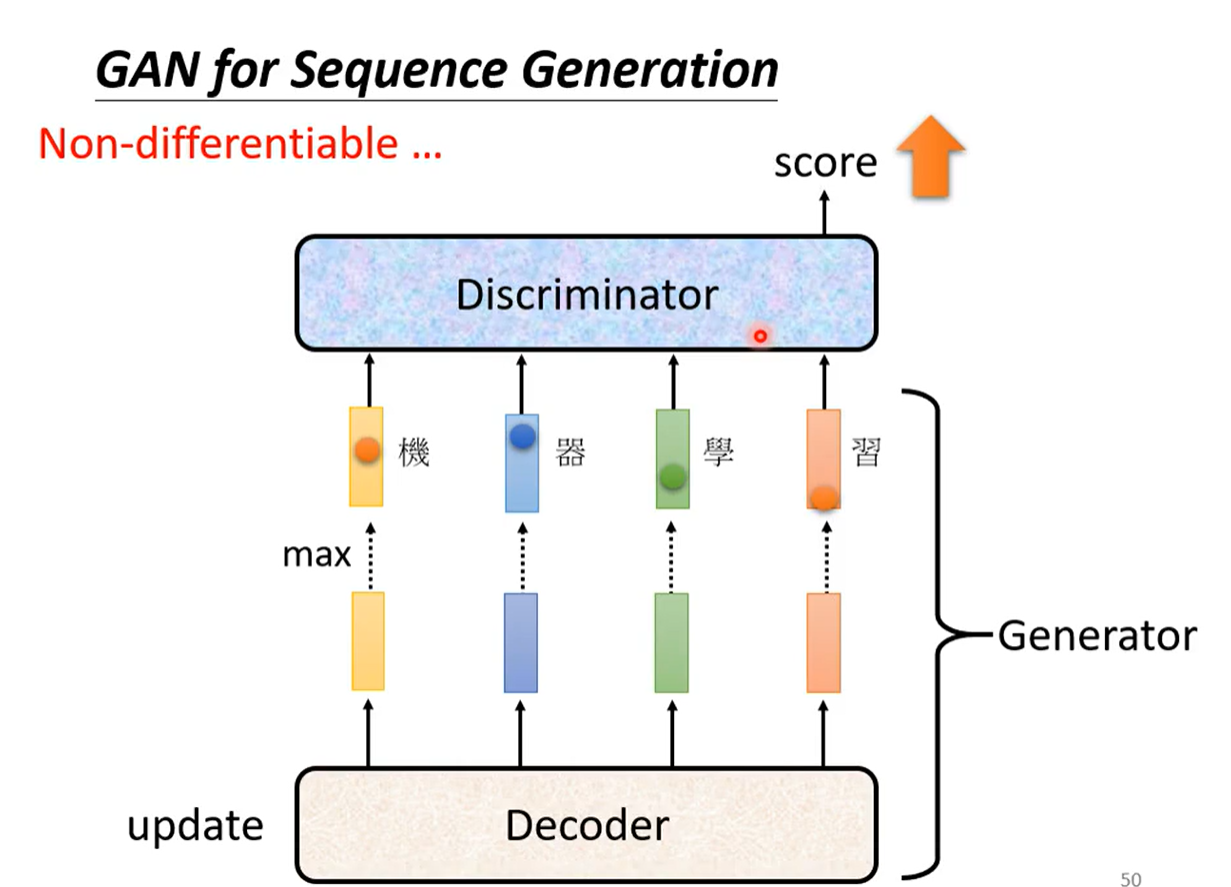
generator负责产生一段文字,discriminator负责分辨这段文字是机器产生的还是真实的文字。他们看上去与影像类的GAN没什么不同,都是discriminator分辨真假,generator产生去骗过discriminator。
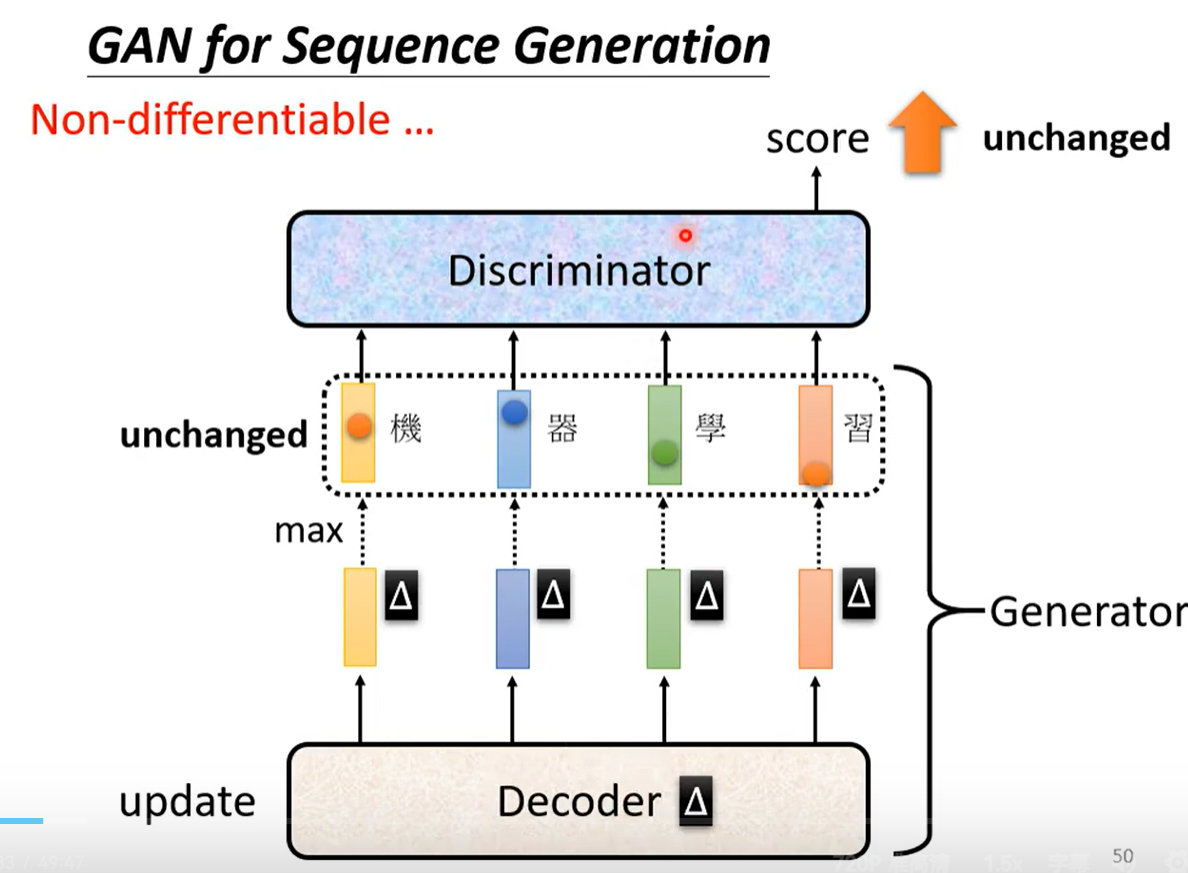
其实实际的难点在如果用gradient descent去训练decoder,让discriminator的分数越大越好,会发现做不到。为什么会做不到呢?假设decoder的参数有一点小小的变化时,输出的distribution也会有小小的变化,因为变化很小,所以他不会影响分数最大的那一个token(token是每次产生多少的单位),对于discriminator来说,输出的分数是一模一样的,所以decoder的参数有一点小小的变化时,discriminator输出是没有改变的,就根本没办法算微分。
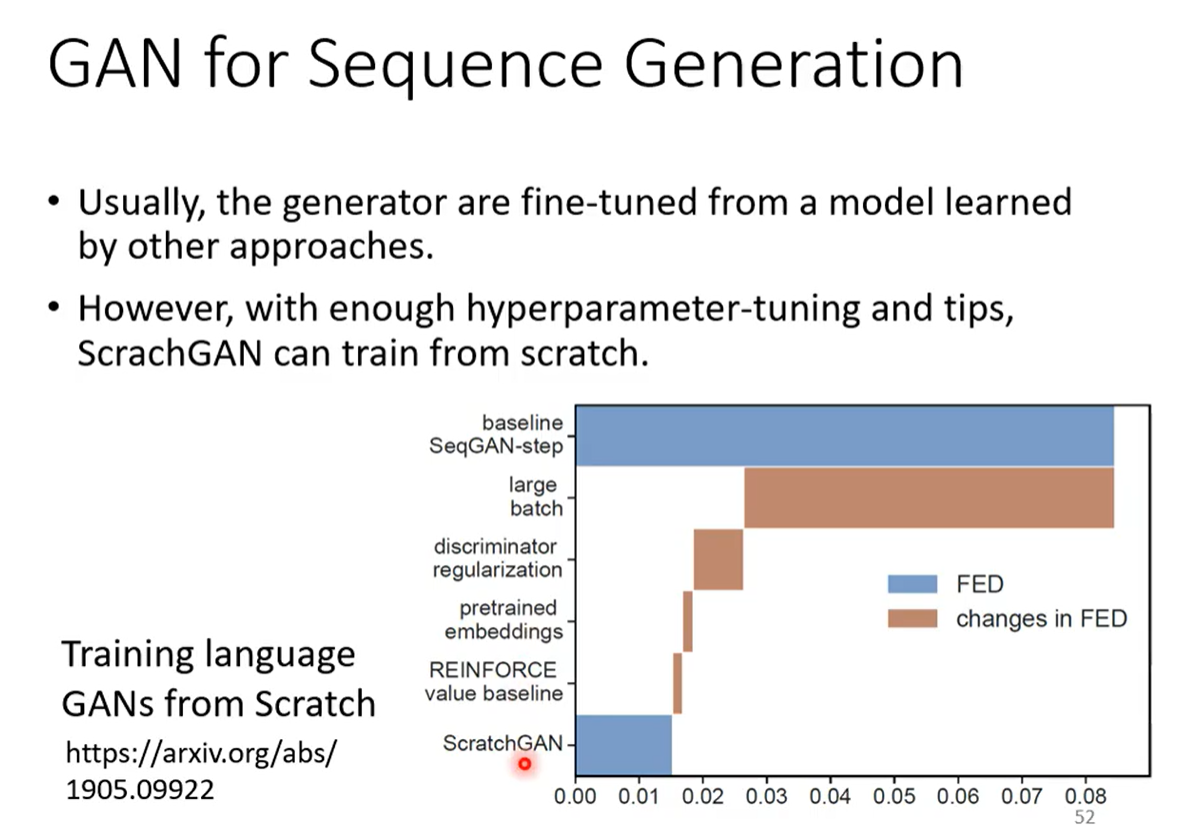
目前也可以解决GAN在文字上训练的难题,最关键的就是调整看hyper parameter和其他很多tips,但是开始要有sequence GAN-step的技术,没有这个训练不起来的,接下来需要一个很大的batch size(通常是上千),和其他的需求,如上图种的条形图所示。有了这些就可以把GAN训练起来。
2.判断generator好坏
评估一个generator的好坏并没有那么容易,通常觉得人自己分辨就可以判断,但是这样显然不行。对于特定的任务,是有办法设计方法的。

例如生成动画人物的头像,这样我们可以用动画人物的人脸侦测系统,观察系统可以侦测倒多少张脸,根据侦测到人脸的多少就可以判断generator的好坏。
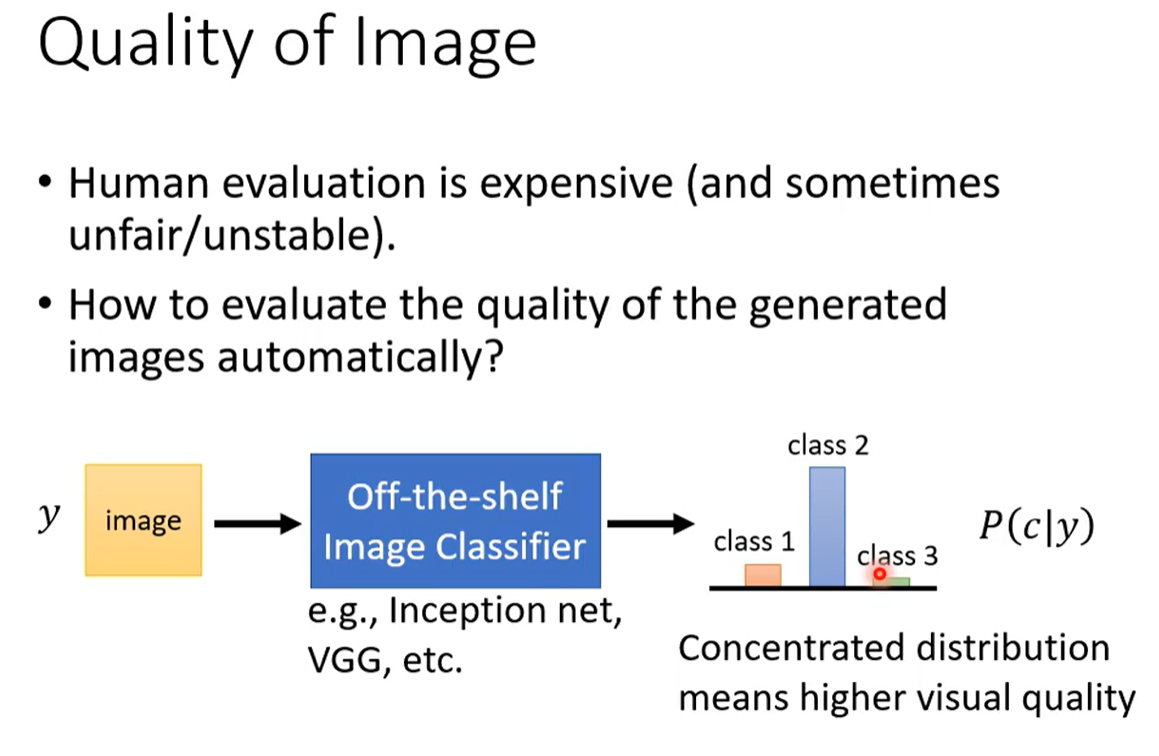
那么对于更一般的例子,我们也有一个方法,跑一个影像分类系统,把GAN产生的图片丢到里面,看他产生什么样的结果。影像分类系统输入是一张图片,输出是一个概率分布,越集中就代表生成的图片越好,虽然我们不知道产生的图片有什么东西,但是如果丢到影像分类系统以后,他输出来的分布非常集中就代表影像系统非常肯定他现在看到什么东西,就代表产生出来的图片也许是比较接近真实的图片,所以影像分类系统才能分辨出来。如果产生了一个四不像的图片,根本看不出来是什么,那么影像系统会非常困惑,他的几率分布会非常平坦,分布非常平均。

但是光用这个方法是不行的,光用这个办法会被一个叫more collapse的问题骗过去。more collapse就是在训练GAN的时候,会遇到一个情况,假设蓝色的星星是真正的资料分布,黄色的星星是GAN生成的资料分布,会发现生成的图片一直就是那几张。这可以理解为discriminator的一个盲点,当generator 学会产生这种图片后,他就永远可以骗过discriminator,discriminator没办法看出这样的图片是假的,就发生了more collapse的状况。

还有另一种与more collapse相似但是比more collapse更难侦测的问题叫more dropping,more dropping是这样的,同样蓝色的星星是真正的资料分布,黄色的星星是GAN生成的资料分布,产生的资料只有真实资料的一部分。如上图中的实例,各式各样的人脸都有,第一个没有什么问题,但是下一个产生出来的就能看出问题,来来去去只有那么几张脸。
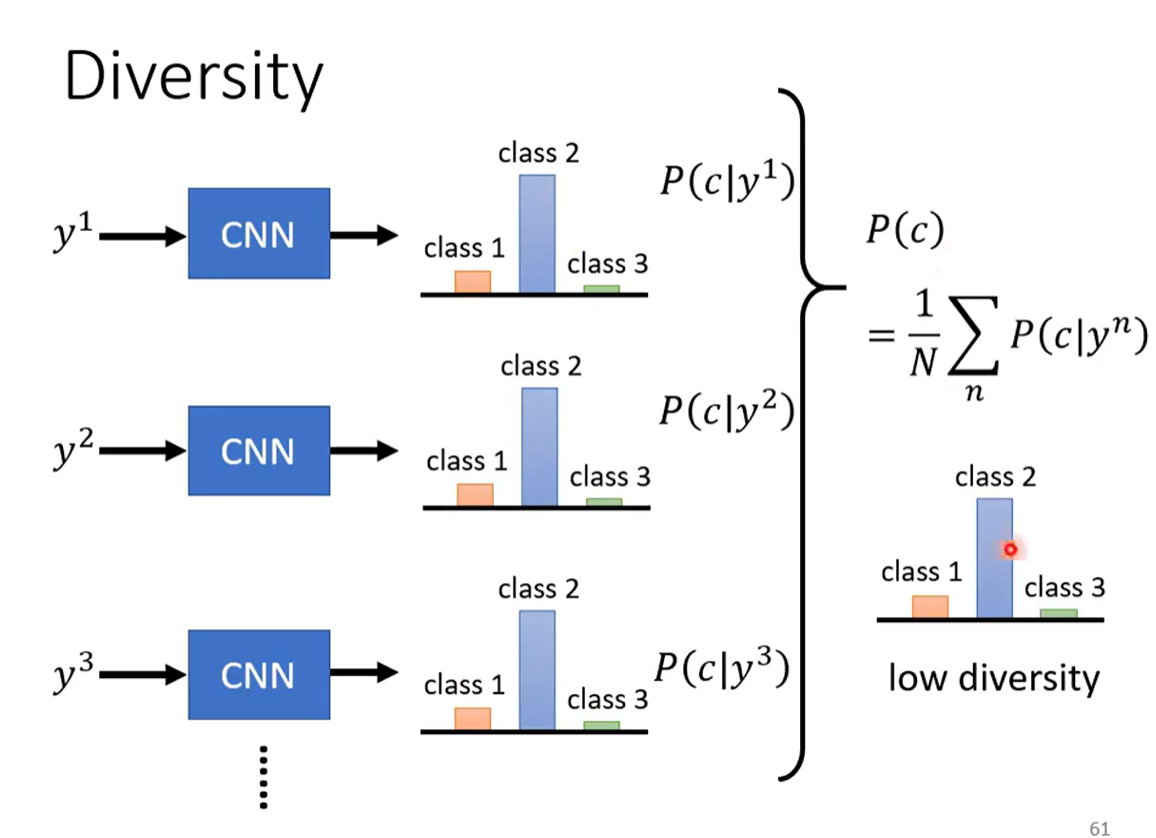
解决的办法是同样借助图像分类,把所有的图片丢进去,然后把得到的分布平均起来,看看平均的分布,如果平均的分布非常集中,就说明现在的多样性不够。
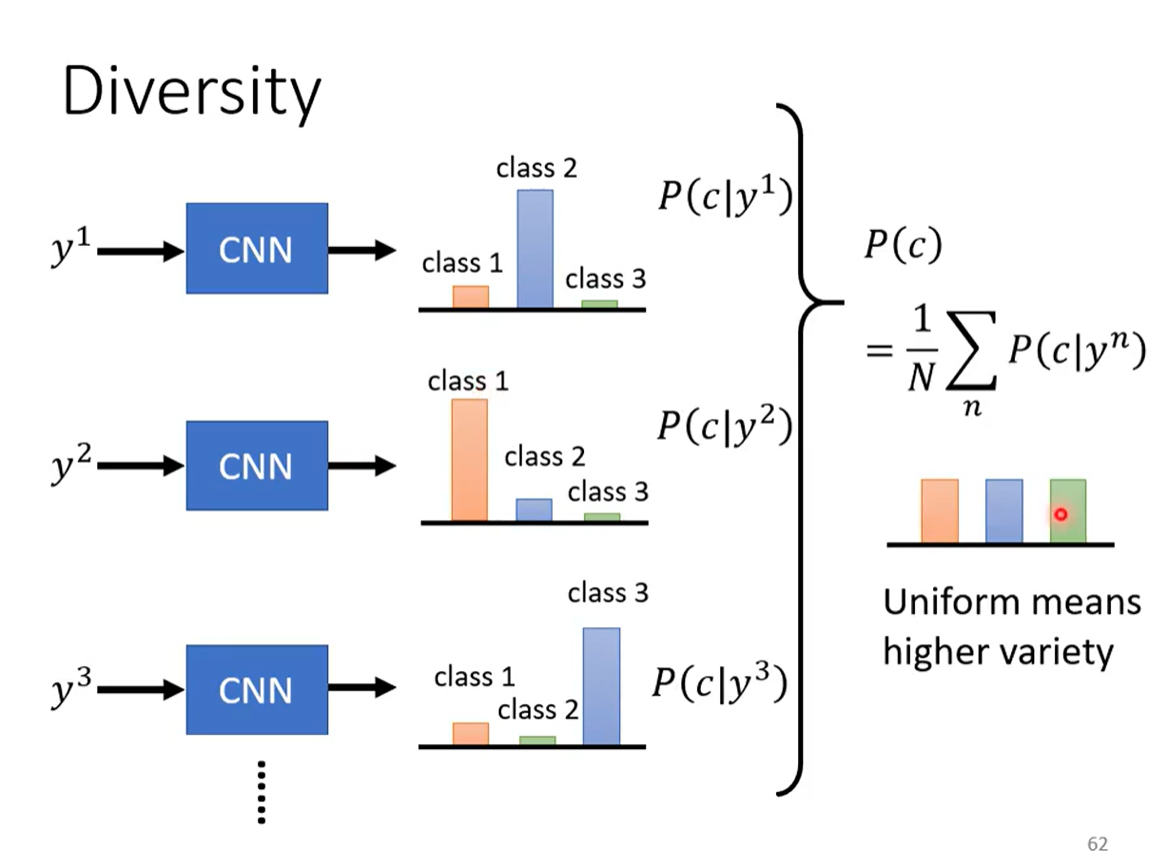
如果多样性足够,把所有的图片丢进去,得到平均的分布是非常平坦的。
3.评估方法
Inception score(IS)
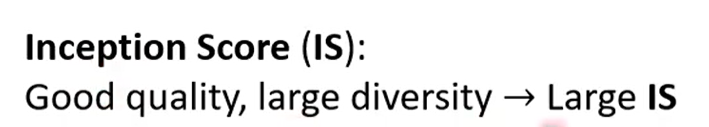
Inception score是用inception network量,如果quality高,diversity又大那么Inception score就比较大。
Frechet inception Distance(FID)
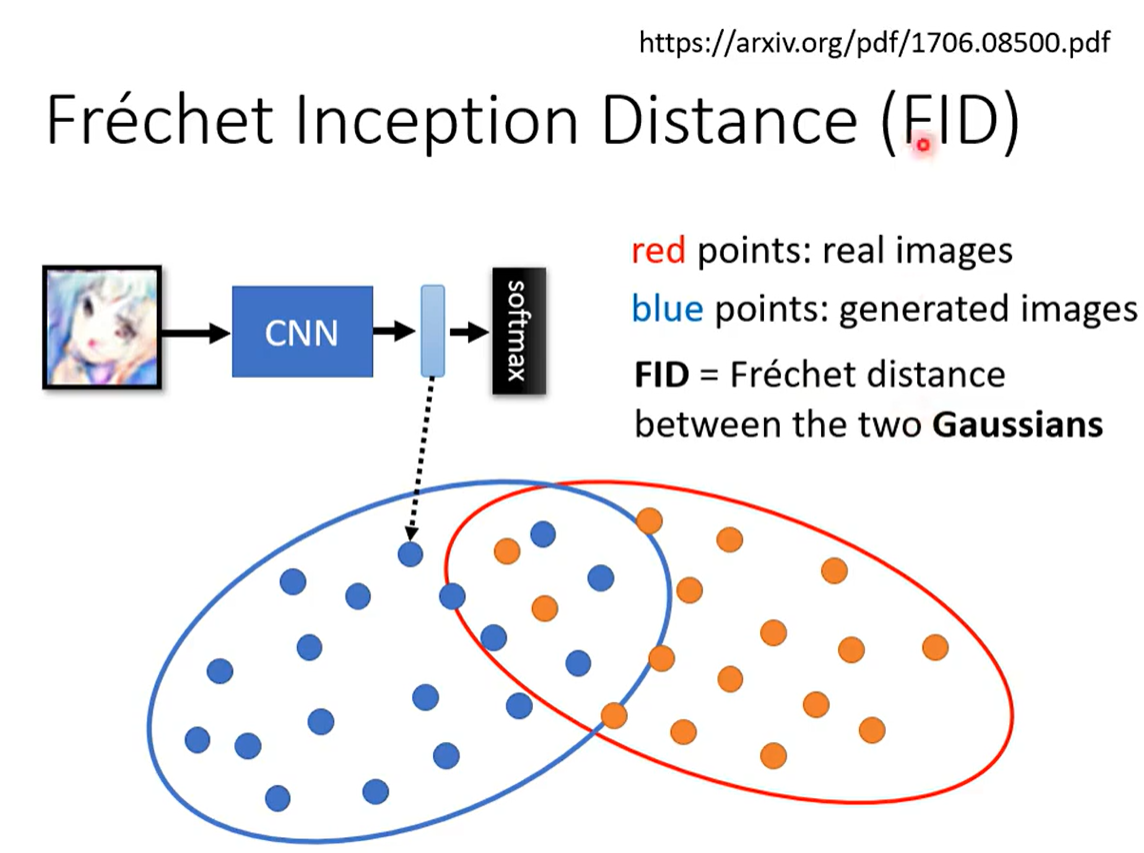
如果把生成的动画头像放入inception network里最后的输出他的类别会是人脸,但是我们在softmax之前的hidden layer的输出拿出来,可能是上千维的向量,用这个向量代表这张图片,假设橙色的点是真实的图片,蓝色的点是生成的图片,两组资料都是gaussian的分布,计算两组资料gaussian分布的Frechet Distance即可。结果越小意味着真实图像分布和生成图像分布非常接近。这表明生成的图像不仅质量高,而且多样性好。