中国网站访问量排行广州开发区西区
背景意义
研究背景与意义
随着城市化进程的加快和自然灾害频发,房屋损坏问题日益凸显,给人们的生活和财产安全带来了严重威胁。房屋损坏不仅影响居民的居住条件,还可能导致经济损失和社会不稳定。因此,及时、准确地识别和评估房屋损坏情况,对于灾后恢复和重建工作至关重要。传统的房屋损坏评估方法多依赖人工检查,不仅效率低下,而且容易受到主观因素的影响,导致评估结果的不准确性。近年来,计算机视觉技术的快速发展为房屋损坏的自动化评估提供了新的解决方案,尤其是基于深度学习的图像分割技术,能够在复杂环境中实现高效、精准的目标检测与分割。
YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到广泛关注。YOLOv8作为该系列的最新版本,结合了多种先进的深度学习技术,具备更强的特征提取能力和更快的推理速度。然而,针对房屋损坏图像的分割任务,YOLOv8仍存在一定的局限性,尤其是在处理复杂背景和多类别损坏的情况下。因此,改进YOLOv8以适应房屋损坏图像分割的需求,具有重要的理论价值和实际意义。
本研究基于“House Damage 2”数据集,旨在构建一个改进的YOLOv8房屋损坏图像分割系统。该数据集包含3000张图像,涵盖27个类别的房屋损坏情况,包括火灾损坏、自然灾害损坏、结构性损坏等多种类型。这些类别的细分不仅反映了房屋损坏的多样性,也为模型的训练提供了丰富的样本。通过对这些数据的深入分析和处理,可以有效提升模型在实际应用中的鲁棒性和准确性。
本研究的意义在于,首先,通过改进YOLOv8模型,能够提高房屋损坏图像的分割精度,进而为灾后评估和重建提供科学依据。其次,基于深度学习的自动化评估系统将显著提高评估效率,降低人工成本,帮助相关部门快速响应灾后救援需求。此外,本研究还将为后续的研究提供参考,推动房屋损坏评估领域的技术进步和应用拓展。
综上所述,基于改进YOLOv8的房屋损坏图像分割系统的研究,不仅具有重要的学术价值,也为实际应用提供了切实可行的解决方案。通过这一研究,期望能够为房屋损坏的自动化评估开辟新的思路,为提升城市抗灾能力和居民生活质量贡献力量。
图片效果
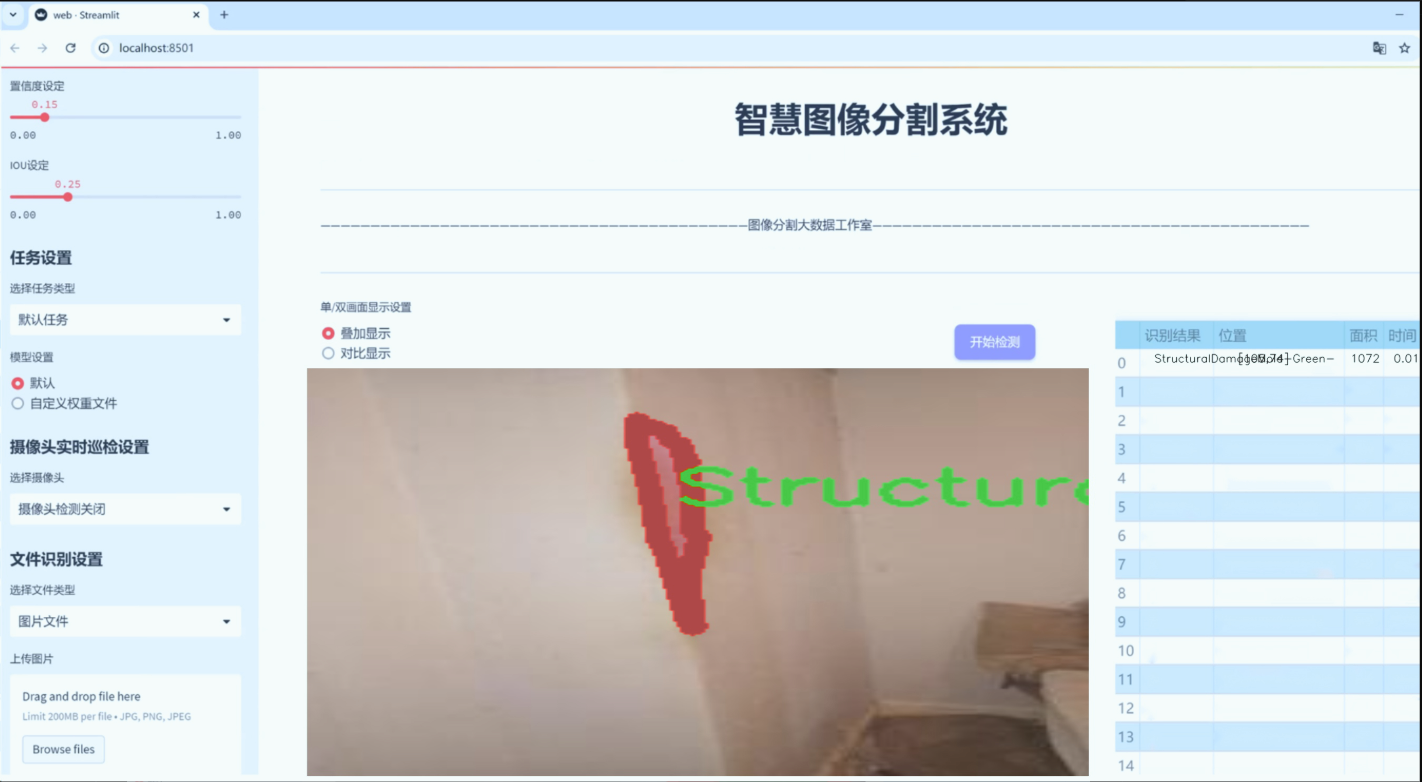
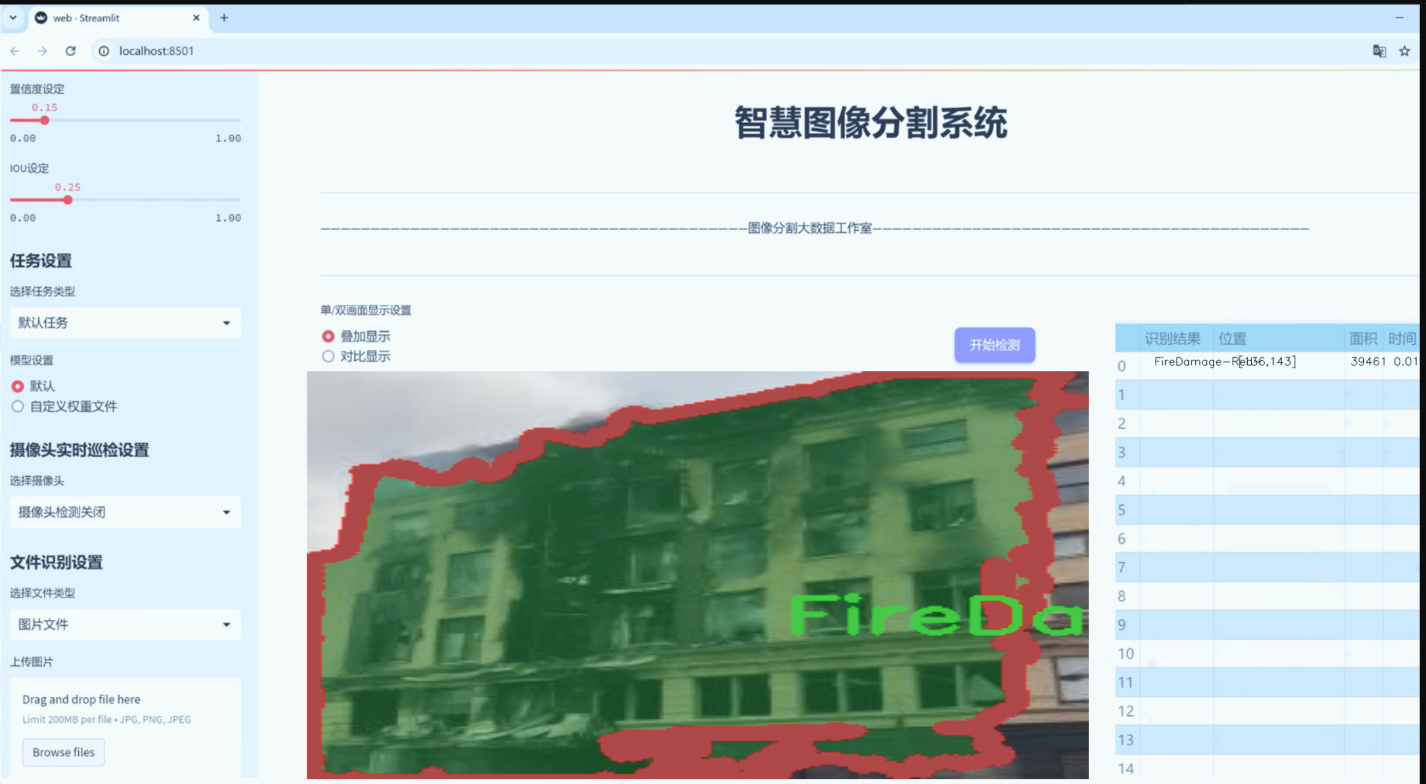
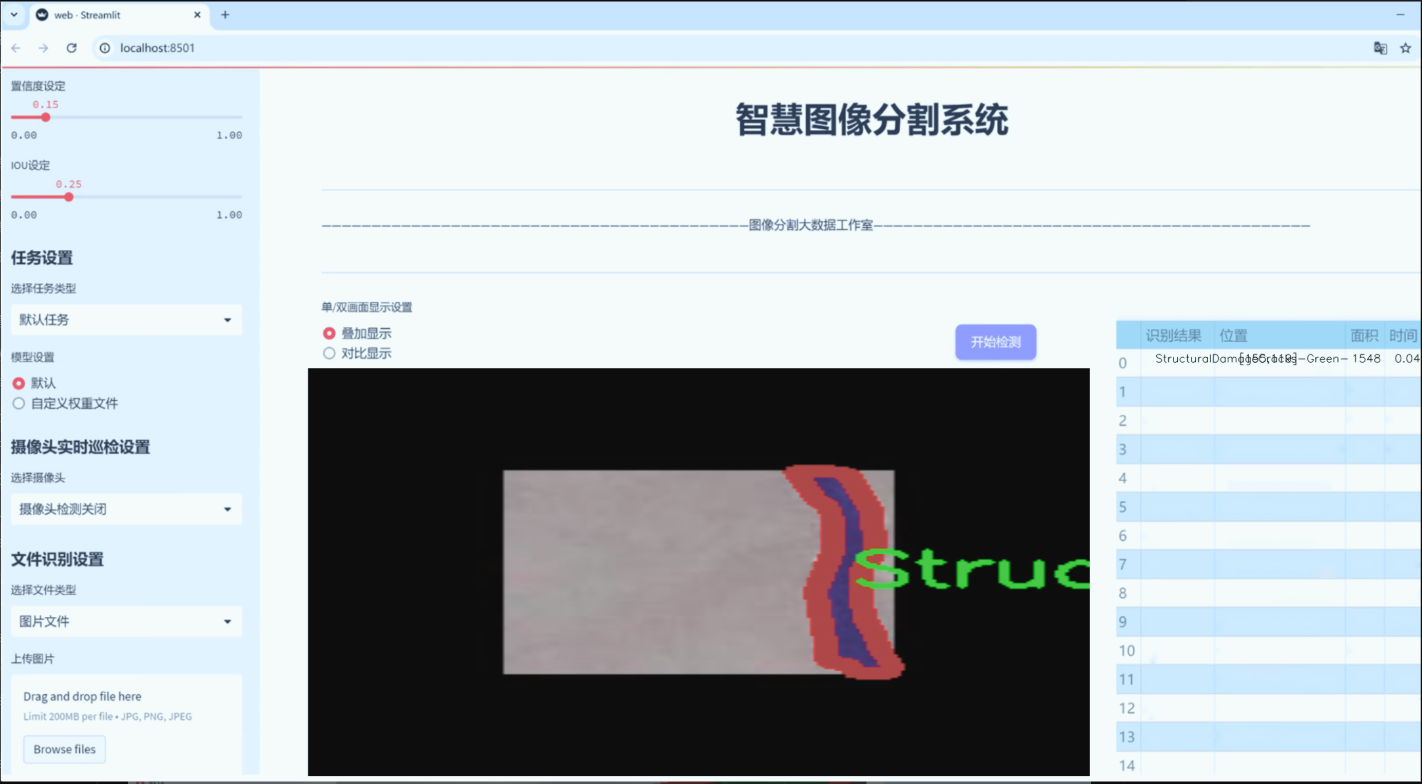
数据集信息
数据集信息展示
在本研究中,我们使用了名为“House Damage 2”的数据集,以训练和改进YOLOv8-seg模型,旨在实现高效的房屋损坏图像分割系统。该数据集专注于房屋在不同情况下所受到的损害,提供了丰富的标注信息,涵盖了22个类别,能够有效支持模型的训练和评估。
“House Damage 2”数据集的类别设计充分考虑了房屋损坏的多样性,涵盖了火灾、自然灾害、结构性损坏和水损害等多种情况。具体而言,数据集中包括三种火灾损害类型,分别为“FireDamage-Amber-”、“FireDamage-Green-”和“FireDamage-Red-”,这些类别的设定不仅反映了火灾对建筑物的不同影响程度,也为模型提供了细致的分类依据。火灾损害的多样性强调了不同燃烧条件下对建筑材料和结构的影响,为后续的损害评估提供了重要参考。
此外,数据集中还包含了自然灾害引起的损害,具体包括地震和龙卷风造成的损害。类别如“NaturalDamageEarthquake-Amber-”、“NaturalDamageEarthquake-Green-”、“NaturalDamageEarthquake-Red-”以及“NaturalDamageTornados-Amber-”、“NaturalDamageTornados-Green-”、“NaturalDamageTornados-Red-”分别对应不同程度的损害。这些类别的设置不仅反映了自然灾害的复杂性,也为模型在实际应用中应对不同类型的损害提供了必要的训练数据。
在结构性损坏方面,数据集同样提供了多种类别,包括“StructuralDamageCollapses-Amber-”、“StructuralDamageCollapses-Green-”、“StructuralDamageCollapses-Red-”、“StructuralDamageCracks-Amber-”、“StructuralDamageCracks-Green-”、“StructuralDamageCracks-Red-”以及“StructuralDamageMold-Amber-”、“StructuralDamageMold-Green-”、“StructuralDamageMold-Red-”。这些类别涵盖了从建筑物倒塌到裂缝和霉变等多种结构性问题,确保模型能够在面对不同的结构损害时,做出准确的判断和分割。
最后,数据集中还包括了水损害的相关类别,如“WaterDamage-Amber-”、“WaterDamage-Green-”和“WaterDamage-Red-”,这些类别的设定使得模型能够识别和分割由于水浸、渗漏等原因造成的损害情况。水损害的分类不仅丰富了数据集的内容,也为模型在应对水灾后的房屋损坏评估提供了重要的数据支持。
总的来说,“House Damage 2”数据集以其多样化的类别和详尽的标注信息,为YOLOv8-seg模型的训练提供了坚实的基础。通过对不同类型房屋损坏的细致分类,该数据集不仅增强了模型的学习能力,也提升了其在实际应用中的有效性和准确性。这种精细化的分类体系为后续的研究和应用提供了广阔的前景,尤其是在灾后评估和恢复过程中,能够为决策者提供更为准确的信息支持。





核心代码
以下是经过简化和注释的核心代码部分,主要包括 SwinTransformer 的结构和功能实现。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class PatchEmbed(nn.Module):
“”" 将图像分割成补丁并进行嵌入的模块 “”"
def __init__(self, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):super().__init__()self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) # 使用卷积将图像补丁嵌入到高维空间self.norm = norm_layer(embed_dim) if norm_layer is not None else None # 可选的归一化层def forward(self, x):""" 前向传播函数 """x = self.proj(x) # 将输入图像通过卷积层进行嵌入if self.norm is not None:x = self.norm(x.flatten(2).transpose(1, 2)) # 进行归一化return x
class SwinTransformer(nn.Module):
“”" Swin Transformer 主体结构 “”"
def __init__(self, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], embed_dim=96):super().__init__()self.patch_embed = PatchEmbed(embed_dim=embed_dim) # 初始化补丁嵌入层self.layers = nn.ModuleList() # 存储各个层的列表# 构建每一层的 Swin Transformerfor i_layer in range(len(depths)):layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer), # 随层数增加嵌入维度depth=depths[i_layer], # 当前层的深度num_heads=num_heads[i_layer] # 当前层的注意力头数)self.layers.append(layer) # 将层添加到列表中def forward(self, x):""" 前向传播函数 """x = self.patch_embed(x) # 通过补丁嵌入层处理输入outs = [] # 存储每层的输出# 逐层处理输入for layer in self.layers:x = layer(x) # 通过当前层outs.append(x) # 保存当前层的输出return outs # 返回所有层的输出
BasicLayer 和其他必要的类可以在这里定义
def SwinTransformer_Tiny(weights=‘’):
“”" 创建一个小型的 Swin Transformer 模型 “”"
model = SwinTransformer(depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]) # 初始化模型
if weights:
model.load_state_dict(torch.load(weights)[‘model’]) # 加载预训练权重
return model
代码注释说明:
PatchEmbed 类:负责将输入图像分割成小块(补丁),并通过卷积层将其嵌入到高维空间。可选的归一化层用于对嵌入结果进行标准化处理。
SwinTransformer 类:实现了 Swin Transformer 的核心结构,包含多个层,每一层都是一个 BasicLayer。每层的嵌入维度和注意力头数根据层数动态调整。
forward 方法:在输入通过补丁嵌入后,逐层处理并收集每层的输出。
SwinTransformer_Tiny 函数:用于创建一个小型的 Swin Transformer 模型,并可选择加载预训练权重。
通过以上注释,读者可以更好地理解每个模块的功能和整体架构。
这个程序文件实现了Swin Transformer模型的核心部分,主要用于计算机视觉任务。Swin Transformer是一种层次化的视觉Transformer架构,使用了移动窗口机制来处理图像。以下是对代码的详细讲解。
首先,导入了必要的库,包括PyTorch和一些辅助函数。接着定义了一个名为Mlp的类,它实现了一个多层感知机(MLP),包含两个线性层和一个激活函数(默认为GELU),并在每个线性层后添加了Dropout以防止过拟合。
接下来,定义了两个辅助函数window_partition和window_reverse,它们用于将输入张量分割成窗口以及将窗口合并回原始形状。这对于窗口注意力机制是必需的。
WindowAttention类实现了基于窗口的多头自注意力机制(W-MSA),支持相对位置偏置。它的构造函数中定义了输入通道数、窗口大小、注意力头数等参数,并初始化了相对位置偏置表。前向传播函数计算查询、键、值,并应用注意力机制。
SwinTransformerBlock类实现了Swin Transformer的基本块,包含了窗口注意力和MLP。它支持窗口的循环移位,允许模型在不同的窗口中捕捉上下文信息。前向传播中,输入经过归一化、窗口分割、注意力计算、窗口合并和MLP处理。
PatchMerging类用于将特征图合并为更小的补丁,以降低特征图的分辨率并增加通道数。它通过线性层实现了这种合并。
BasicLayer类表示Swin Transformer的一个基本层,包含多个Swin Transformer块。它还计算了SW-MSA的注意力掩码,并在必要时进行下采样。
PatchEmbed类负责将输入图像分割成补丁并进行嵌入。它使用卷积层将图像转换为补丁表示,并在必要时进行归一化。
SwinTransformer类是整个模型的主体,负责构建不同层次的Swin Transformer。它初始化了补丁嵌入、绝对位置嵌入、各层的基本层,并在前向传播中处理输入图像。
最后,定义了一个update_weight函数,用于更新模型权重,并提供了一个SwinTransformer_Tiny函数来创建一个小型的Swin Transformer模型实例,并可选择加载预训练权重。
整体而言,这个文件实现了Swin Transformer的各个组件,并通过模块化的设计使得模型的构建和使用变得灵活和高效。
11.5 ultralytics\data\base.py
以下是经过简化并注释的核心代码部分,主要保留了数据集的基本结构和功能:
import glob
import os
from pathlib import Path
import cv2
import numpy as np
from torch.utils.data import Dataset
class BaseDataset(Dataset):
“”"
基础数据集类,用于加载和处理图像数据。
参数:img_path (str): 图像文件夹的路径。imgsz (int, optional): 图像大小,默认为640。augment (bool, optional): 是否应用数据增强,默认为True。classes (list): 包含的类别列表,默认为None。
"""def __init__(self, img_path, imgsz=640, augment=True, classes=None):"""初始化BaseDataset,设置基本配置和选项。"""super().__init__()self.img_path = img_path # 图像路径self.imgsz = imgsz # 图像大小self.augment = augment # 是否进行数据增强self.im_files = self.get_img_files(self.img_path) # 获取图像文件列表self.labels = self.get_labels() # 获取标签数据self.update_labels(include_class=classes) # 更新标签,仅包含指定类别self.ni = len(self.labels) # 数据集中图像的数量def get_img_files(self, img_path):"""读取图像文件,返回有效的图像文件路径列表。"""f = [] # 存储图像文件for p in img_path if isinstance(img_path, list) else [img_path]:p = Path(p) # 处理路径if p.is_dir(): # 如果是目录f += glob.glob(str(p / '**' / '*.*'), recursive=True) # 递归查找所有图像文件elif p.is_file(): # 如果是文件with open(p) as t:t = t.read().strip().splitlines() # 读取文件内容f += [x for x in t] # 添加到文件列表else:raise FileNotFoundError(f'{p} 不存在')# 过滤出有效的图像文件格式im_files = sorted(x for x in f if x.split('.')[-1].lower() in ['jpg', 'jpeg', 'png', 'bmp'])assert im_files, f'没有在 {img_path} 中找到图像'return im_filesdef update_labels(self, include_class):"""更新标签,仅包含指定的类别。"""for i in range(len(self.labels)):if include_class is not None:cls = self.labels[i]['cls']# 过滤标签,仅保留指定类别j = np.isin(cls, include_class)self.labels[i]['cls'] = cls[j]def load_image(self, i):"""加载数据集中索引为 'i' 的图像,返回图像及其原始和调整后的尺寸。"""f = self.im_files[i] # 获取图像文件路径im = cv2.imread(f) # 读取图像if im is None:raise FileNotFoundError(f'未找到图像 {f}')# 调整图像大小im = cv2.resize(im, (self.imgsz, self.imgsz), interpolation=cv2.INTER_LINEAR)return im, im.shape[:2] # 返回图像和其尺寸def __getitem__(self, index):"""返回给定索引的图像和标签信息。"""label = self.labels[index] # 获取标签label['img'], label['ori_shape'] = self.load_image(index) # 加载图像return label # 返回图像和标签def __len__(self):"""返回数据集中标签的数量。"""return len(self.labels)def get_labels(self):"""用户可以自定义标签格式,这里返回一个示例标签列表。"""# 示例标签结构return [{'cls': np.array([0]), 'bboxes': np.array([[0, 0, 1, 1]])} for _ in range(len(self.im_files))]
代码注释说明:
类定义:BaseDataset类继承自Dataset,用于处理图像数据集。
初始化方法:__init__方法中设置了图像路径、图像大小、数据增强标志和类别列表,并调用相关方法获取图像文件和标签。
获取图像文件:get_img_files方法读取指定路径下的图像文件,支持目录和文件列表输入,并过滤出有效的图像格式。
更新标签:update_labels方法根据指定类别更新标签,仅保留相关类别的标签信息。
加载图像:load_image方法根据索引加载图像,并调整其大小。
获取数据项:__getitem__方法返回指定索引的图像和标签信息。
获取数据集长度:__len__方法返回标签的数量。
获取标签:get_labels方法可以自定义标签格式,这里提供了一个示例结构。
这个程序文件定义了一个名为 BaseDataset 的类,主要用于加载和处理图像数据,特别是在计算机视觉任务中,例如目标检测。该类继承自 PyTorch 的 Dataset 类,提供了一系列功能来管理图像和标签数据。
在初始化方法 init 中,类接收多个参数,包括图像路径、图像大小、是否缓存图像、数据增强选项、超参数、批处理大小等。根据这些参数,类会读取图像文件并生成相应的标签数据。get_img_files 方法用于从指定路径中获取图像文件,支持从文件夹和文件列表中读取,并确保只返回支持的图像格式。若指定了 fraction 参数,则会根据该比例选择数据集中的一部分图像。
update_labels 方法用于更新标签,只保留指定类别的标签,支持单类训练的选项。load_image 方法负责加载指定索引的图像,并根据需要调整图像大小,保持宽高比或拉伸为正方形。此外,如果启用了数据增强,该方法还会将图像存入缓冲区,以便后续处理。
cache_images 方法允许将图像缓存到内存或磁盘,以提高加载速度。它会根据可用内存检查是否可以将图像缓存到 RAM 中,check_cache_ram 方法则用于评估所需内存与可用内存的关系。
set_rectangle 方法用于设置 YOLO 检测的边界框形状为矩形,适用于长宽比不一的图像。getitem 方法返回指定索引的图像及其标签信息,并应用预定义的图像变换。
get_image_and_label 方法获取图像和标签信息,并返回经过处理的标签。len 方法返回数据集中标签的数量。update_labels_info 方法可以根据需要自定义标签格式。
最后,build_transforms 和 get_labels 方法是抽象方法,用户需要根据自己的需求实现具体的图像增强和标签格式。这种设计使得 BaseDataset 类具有很好的灵活性和可扩展性,适合不同的计算机视觉任务。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是一个计算机视觉框架,主要用于目标检测和跟踪任务。它实现了多种模型架构(如 RT-DETR 和 Swin Transformer),以及与这些模型相关的功能模块(如动态蛇形卷积和匹配算法)。程序的整体结构模块化,便于扩展和维护。主要包括以下几个部分:
模型定义:实现了不同的神经网络架构,如 RT-DETR 和 Swin Transformer,支持复杂的特征提取和处理。
数据处理:提供了数据集的加载和处理功能,支持图像增强和标签管理。
匹配算法:实现了目标跟踪中的匹配算法,计算成本矩阵并执行线性分配。
卷积操作:实现了动态卷积操作,以增强模型对复杂特征的捕捉能力。
这种设计使得框架可以灵活地适应不同的计算机视觉任务,并且可以通过增加新的模块或修改现有模块来进行扩展。
文件功能整理表
文件路径 功能描述
ultralytics/models/rtdetr/val.py 实现 RT-DETR 模型的验证功能,包括数据集构建、图像处理、预测结果后处理和评估指标更新。
ultralytics/trackers/utils/matching.py 实现目标跟踪中的匹配算法,包括线性分配、成本矩阵计算(IoU、特征嵌入)和相似度融合。
ultralytics/nn/extra_modules/dynamic_snake_conv.py 实现动态蛇形卷积模块,支持基于窗口的自注意力机制和多层感知机,增强模型的特征提取能力。
ultralytics/nn/backbone/SwinTransformer.py 实现 Swin Transformer 模型,包含基本块、窗口注意力机制和补丁嵌入,适用于视觉任务。
ultralytics/data/base.py 定义基础数据集类,负责图像和标签的加载、处理和增强,支持缓存和标签更新功能。
这个表格总结了每个文件的主要功能,便于理解程序的整体结构和各个模块的作用。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻