浦东新区网站优化推广wordpress自适应框架
目录
一、Amazon S3的基本定义与核心概念
二、Amazon S3的诞生背景与历史发展
三、Amazon S3的架构设计与技术实现
四、Amazon S3解决的关键问题与创新特性
五、Amazon S3的关键特性与功能
六、Amazon S3与同类产品的对比
七、Amazon S3的使用方法与最佳实践
八、Amazon S3的开发技巧与高级功能
九、Amazon S3的未来趋势与发展方向
十、总结与建议
参考资料:
Amazon Simple Storage Service (Amazon S3) 是AWS提供的对象存储服务,自2006年发布以来已成为云计算领域的基石服务。作为一项完全托管的云存储解决方案,S3允许用户存储和检索任意数量的数据,从几KB的小文件到数TB的大文件,均支持通过标准的HTTP/HTTPS协议访问 。S3采用扁平化存储模型,以存储桶和对象为核心概念,提供高可靠性、高可用性和强一致性,同时通过丰富的存储类和生命周期管理策略优化存储成本。本文将深入剖析Amazon S3的技术架构、核心功能、解决的问题以及最佳实践,为技术开发人员提供全面的参考指南。
一、Amazon S3的基本定义与核心概念
Amazon S3是一项对象存储服务,采用分布式架构设计,旨在提供高可扩展性、高可靠性和低延迟的数据存储解决方案 。与传统的文件存储或块存储不同,S3将数据以对象形式存储,每个对象包含数据本身和描述数据的元数据。S3的核心概念包括存储桶(Bucket)、对象(Object)、键名(Key)以及存储类,这些概念构成了S3存储模型的基础。
存储桶是S3中存储对象的容器,类似于传统文件系统中的文件夹。每个存储桶在全球范围内必须具有唯一名称,且遵循特定的命名规则,如只能包含小写字母、数字、句点和破折号,长度在3到63个字符之间,且必须以字母或数字开头和结尾 。存储桶的命名规则确保了全球访问的一致性和唯一性,同时也避免了常见的命名冲突问题。
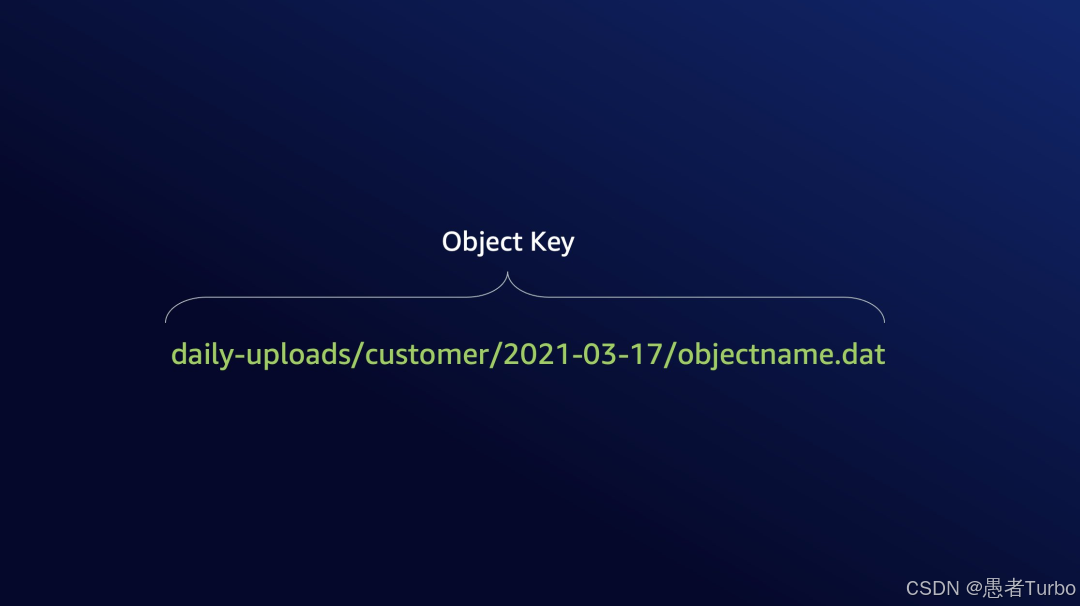
对象是S3的基本存储单元,由数据和元数据组成。每个对象通过键名在存储桶内唯一标识,键名可以是任意长度的字符串,支持层级路径结构(如"images/user123/profile.jpg"),使用户能够以类似文件系统的方式组织对象 。S3不支持对对象的直接修改,而是通过创建新版本实现更新,这一设计简化了数据一致性管理,并支持版本控制功能。
存储类是S3的另一重要概念,它决定了对象存储的位置、访问速度和成本。S3提供多种存储类,包括:
| 存储类 | 访问速度 | 持久性 | 成本特性 | 适用场景 |
|---|---|---|---|---|
| Amazon S3 Standard | 高频访问 | 99.999999999% | 较高 | 关键业务数据、需要频繁访问的场景 |
| Amazon S3 Standard-IA | 中等访问 | 99.999999999% | 较低 | 不常访问但需要快速访问的归档数据 |
| Amazon S3 One Zone-IA | 中等访问 | 99.999999999% | 更低 | 对成本敏感且允许单区域存储的归档数据 |
| Amazon S3 Glacier Instant Retrieval | 低延迟 | 99.999999999% | 极低 | 长期归档但需要快速检索的数据 |
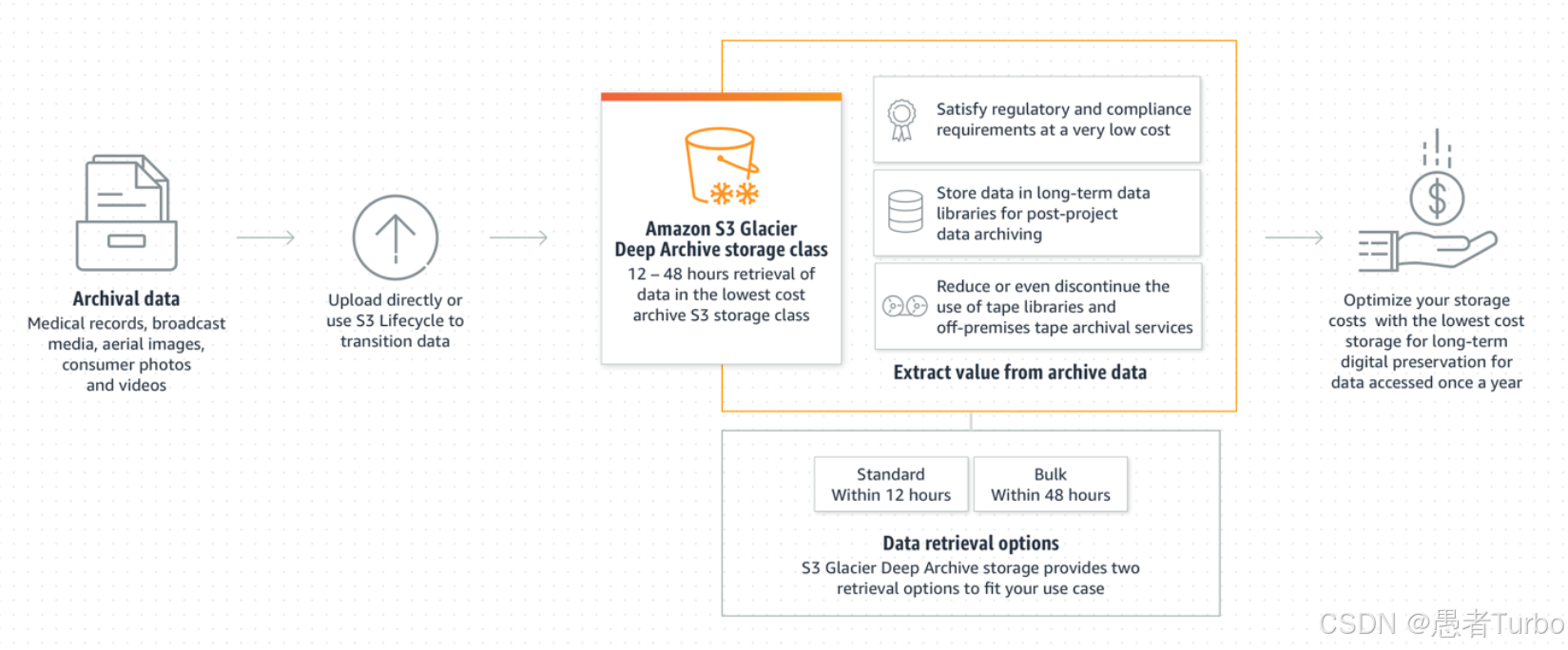
| Amazon S3 Glacier Deep Archive | 超低延迟 | 99.999999999% | 最低 | 长期归档且极少访问的数据 |
存储类的选择直接影响数据的访问速度和存储成本,开发者可以根据数据的访问频率和重要性灵活选择。对于需要频繁访问的生产数据,可以选择S3 Standard;而对于归档数据,可以选择S3 Glacier Deep Archive以降低存储成本。
此外,S3还支持多种高级功能,如版本控制、对象锁定、生命周期管理、加密和访问控制等,这些功能共同构成了S3的强大功能集合,使其能够满足各种复杂的数据存储需求。
二、Amazon S3的诞生背景与历史发展
Amazon S3的诞生源于云计算早期对简单、可靠且可扩展存储解决方案的需求。2006年3月14日,亚马逊云科技发布了S3,这是云计算领域的首个对象存储服务,也是AWS的核心产品之一。S3的推出标志着云计算从基础设施即服务(IaaS)向平台即服务(PaaS)和软件即服务(SaaS)的扩展,为开发者提供了一种无需管理底层存储硬件即可存储和检索数据的简便方式。
S3的诞生背景可以追溯到亚马逊内部对可扩展存储解决方案的需求。随着亚马逊电商平台业务的快速增长,传统的存储架构难以满足海量数据存储和高并发访问的需求。为解决这一问题,亚马逊开发了基于Dynamo的分布式存储系统,随后将其封装为S3服务对外提供 。Dynamo是一种高可用的键值存储系统,采用一致性哈希算法实现数据分片和分布,支持自动扩展和故障恢复 ,这些特性为S3提供了强大的底层支持。
S3的推出不仅满足了亚马逊自身的业务需求,也为云计算行业树立了新的标准。S3采用RESTful API设计,简化了数据存储和检索的操作,使开发者能够轻松地将数据存储在云端并实现全球访问。这一设计理念后来被众多云计算提供商效仿,成为对象存储领域的标准模型。
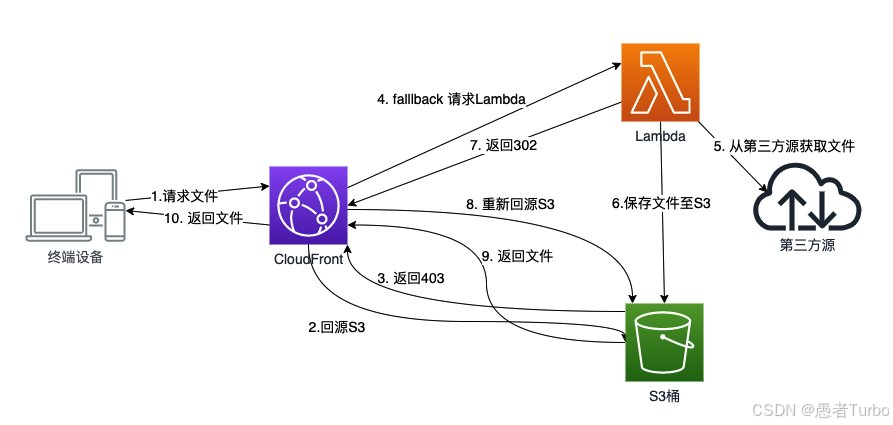
自2006年发布以来,S3经历了持续的演进和创新。2019年,亚马逊云科技发布了Amazon EventBridge,进一步增强了S3与Serverless服务的集成;2021年,推出了S3 Select功能,允许直接查询压缩数据;2023年,发布了目录存储桶和表存储桶,针对低延迟和分析场景优化。这些创新使S3从一个简单的对象存储服务发展成为支持复杂数据湖和分析工作负载的平台。
截至2023年,Amazon S3上存放着280万亿个对象,平均每秒响应1亿多个请求,每秒执行40亿次校验计算,展示了其惊人的规模和可靠性。S3的成功不仅在于其技术特性,更在于其简单易用的API和强大的生态系统集成,使其成为云计算时代数据存储的首选解决方案。

三、Amazon S3的架构设计与技术实现
Amazon S3基于Dynamo和Blob File System构建,采用分布式架构设计,确保高可用性、高可靠性和低延迟 。S3的核心架构包括存储层、元数据管理层和接口层,各层协同工作,提供强大的存储服务。
存储层负责实际数据的存储和管理,采用多副本冗余策略确保数据可靠性 。每个对象在存储层被存储为多个副本,通常为3个,分布在不同的物理设备和可用区上 。这种冗余策略使得即使某个物理设备或可用区发生故障,数据仍然可以访问,保证了服务的高可用性。
元数据管理层负责管理对象和存储桶的元数据,如对象键、存储桶信息、访问控制策略等 。S3的元数据管理基于Dynamo数据库,采用一致性哈希算法实现元数据的分片和分布 ,确保元数据的高效访问和管理。Dynamo的去中心化设计使得元数据管理无需依赖单点服务器,提高了系统的可靠性和扩展性。
接口层提供RESTful API,使用户能够通过标准的HTTP/HTTPS协议访问和管理S3资源。S3的API设计简洁且功能全面,支持对象的创建、读取、更新和删除等基本操作 ,同时也支持高级功能如版本控制、对象锁定和生命周期管理等。

在数据分布和分片方面,S3采用一致性哈希算法将对象均匀分布在整个存储集群中 。对象的键名经过哈希计算后确定其存储位置,确保负载均衡和线性扩展 。这种分片策略使得S3能够轻松应对海量数据存储和高并发访问的需求。
S3的强一致性模型是其另一重要特性。对于PUT和DELETE操作,S3提供"写后读"一致性,确保操作立即生效。这一特性通过主从副本机制实现,所有写操作必须写入主副本并等待多数副本确认,确保数据的一致性 。相比之下,其他云存储服务如Azure Blob Storage默认采用最终一致性模型,需要额外配置才能实现强一致性。
S3的存储桶类型也是其架构设计的重要部分。除了通用存储桶外,S3还提供目录存储桶和表存储桶,针对不同应用场景优化:
- 通用存储桶:适用于大多数应用场景,支持跨所有存储类(除S3 Express One Zone外)存储对象,提供高可用性和强一致性。
- 目录存储桶:专为低延迟和数据驻留场景设计,支持单可用区部署(如S3 Express One Zone)和专用本地区域(DLZ)数据驻留。
- 表存储桶:针对分析和机器学习工作负载优化,支持Apache Iceberg格式,提供列式查询性能。
表存储桶的创新在于其元数据管理优化,通过预计算和缓存元数据索引,显著提高了查询性能,使S3能够直接支持分析查询,无需额外的ETL步骤。这一特性使S3成为数据湖和分析工作负载的理想存储平台。
四、Amazon S3解决的关键问题与创新特性
Amazon S3解决了一系列传统存储架构面临的挑战,同时通过创新特性提供了更高效、更可靠的数据存储解决方案。
首先,S3解决了海量数据存储的扩展性问题 。传统存储架构如文件系统或关系型数据库在面对海量数据时面临严重的扩展瓶颈,难以应对PB甚至EB级数据的存储需求。S3的分布式架构和扁平化模型使其能够轻松扩展,支持单个存储桶存储超过5万亿个对象,满足大规模数据存储的需求。
其次,S3解决了数据可靠性和持久性问题。传统存储架构依赖单一服务器或有限的副本策略,难以保证数据的高可靠性。S3采用多副本冗余策略,将数据存储在多个物理设备和可用区上,确保即使发生硬件故障或数据中心问题,数据仍然可用 。S3提供99.999999999%(11个9)的数据持久性,远高于传统存储架构的可靠性水平。
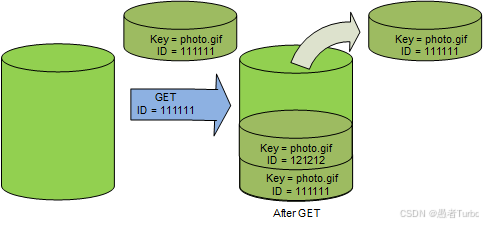
第三,S3解决了元数据管理的性能瓶颈 。传统文件系统采用树状结构管理元数据,随着数据量的增长,元数据查询性能急剧下降。S3采用扁平化模型,通过Dynamo的分布式元数据管理,避免了层级查询的开销,提高了元数据访问效率 。S3的元数据查询性能远高于传统文件系统 ,使其能够支持海量对象的高效管理。
第四,S3解决了数据访问的延迟问题。传统存储架构在跨区域访问时面临较高的延迟,影响用户体验。S3支持跨区域复制和多区域接入点,通过将数据复制到不同区域,减少用户访问延迟。目录存储桶和S3 Express One Zone存储类进一步优化了低延迟场景的数据访问,通过单可用区部署减少数据传输距离,提高访问速度。
最后,S3解决了数据存储的成本优化问题 。传统存储架构难以根据数据访问频率动态调整存储策略,导致存储成本过高。S3通过智能分层和生命周期管理,根据数据访问模式自动调整存储策略,降低存储成本。S3 Intelligent-Tiering能够自动分析对象的访问模式,并将其迁移至最适合的存储类,无需用户手动干预。
S3的创新特性还包括:
- 事件驱动架构:通过S3 Events触发Lambda等Serverless服务,实现数据处理的自动化。
- 对象锁定:支持WORM(一次写入多次读取)存储,满足合规性要求,防止对象被删除或修改。
- 预签名URL:提供安全的临时访问权限,无需修改存储桶策略即可共享数据。
- 存储桶标签:支持成本分配和管理,帮助用户根据业务维度(如成本中心、应用程序名称)分配存储成本。
- 强一致性模型:对于PUT和DELETE操作提供强一致性,简化数据管理。
S3的目录存储桶和表存储桶是其近年来的重要创新,针对特定应用场景优化了存储架构和访问性能。目录存储桶通过单区域部署和集中元数据管理降低延迟,支持数据驻留需求;表存储桶通过元数据预计算和缓存,优化了分析查询性能,使S3能够直接支持机器学习和大数据分析工作负载。
五、Amazon S3的关键特性与功能
Amazon S3的关键特性使其成为云计算时代数据存储的首选解决方案。这些特性不仅解决了传统存储架构的挑战,也为现代应用提供了强大的存储能力。
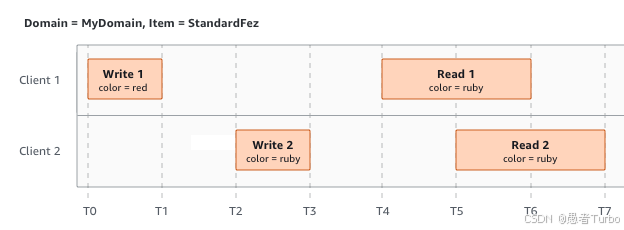
强一致性模型是S3的核心特性之一。与许多云存储服务不同,S3为PUT和DELETE操作提供"写后读"一致性,确保操作立即生效。这一特性通过主从副本机制实现,所有写操作必须写入主副本并等待多数副本确认,确保数据的一致性 。强一致性简化了数据管理,使得开发者无需处理复杂的最终一致性问题,提高了应用的可靠性和易用性。
版本控制是S3的另一重要特性。S3的版本控制允许存储对象的多个版本,防止意外删除或覆盖,为数据恢复提供了可靠机制。通过启用版本控制,用户可以恢复任何时间点的对象版本,即使对象已被删除或覆盖。版本控制与对象锁定结合使用,可以提供更严格的数据保护,满足合规性要求。
存储类与生命周期管理是S3成本优化的核心功能。S3提供多种存储类,从高可用性、高访问速度的Standard到低延迟、低成本的Glacier Deep Archive,满足不同数据访问模式和成本要求。生命周期策略允许用户根据数据访问频率自动迁移对象至不同存储类,无需手动干预。可以设置将30天未访问的对象自动迁移至Standard-IA,60天未访问的对象迁移至Glacier,显著降低存储成本。
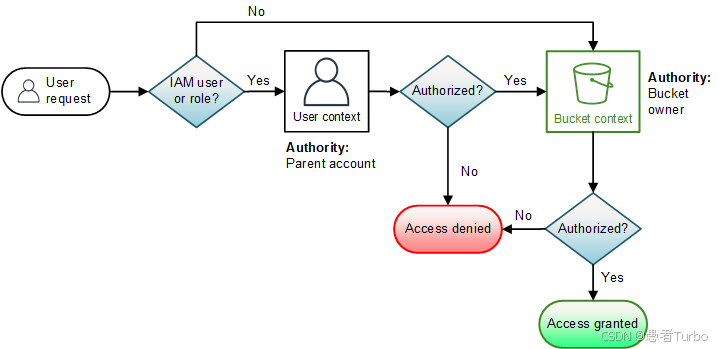
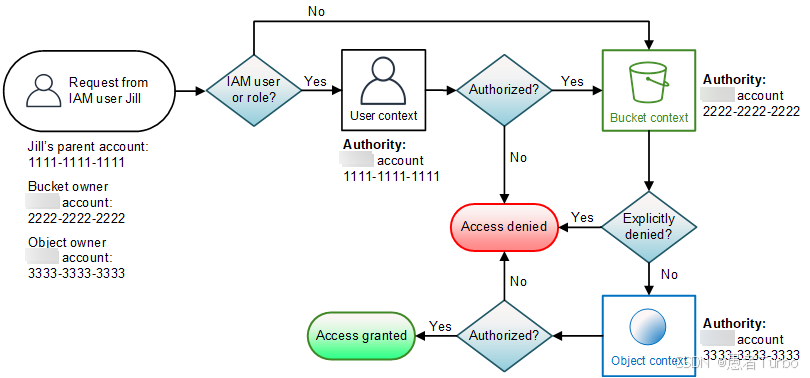
访问控制与安全是S3的另一关键特性。S3提供多种访问控制机制,包括:
- IAM策略:基于身份的访问控制,控制用户和角色对S3资源的访问权限 。
- 存储桶策略:基于资源的访问控制,控制存储桶和对象的访问权限 。
- 访问控制列表(ACL):传统访问控制机制,但AWS建议优先使用存储桶策略和IAM策略 。
- 对象标签:基于标签的访问控制和成本管理,支持细粒度权限控制和成本分配。
SSE加密(服务器端加密)是S3安全的重要组成部分。S3支持多种加密方式,包括使用AWS托管密钥的SSE-S3、使用客户自主管理密钥的SSE-KMS以及使用客户提供的加密密钥的SSE-C 。这些加密方式确保数据在存储和传输过程中的安全性,满足不同安全需求。
事件通知是S3与Serverless架构集成的重要功能。S3 Events可以在对象上传、删除或修改时触发通知,将通知发送到SNS主题、SQS队列或Lambda函数。通过事件通知,开发者可以构建响应式应用,实现数据处理的自动化。例如,上传图像文件时自动触发图像处理Lambda函数,或上传日志文件时自动触发数据分析工作流。
S3 Select是S3的另一创新功能,允许直接查询压缩数据,减少数据传输量和处理时间。S3 Select支持SQL-like查询语法,可以只检索对象中需要的部分数据,而非整个对象。这对于处理大型日志文件或数据库备份非常有用,可以显著提高查询效率和降低处理成本。
存储桶标签与成本优化是S3管理的重要功能。存储桶标签是键值对形式的元数据,可以用于成本分配和管理。通过为存储桶添加标签,用户可以将成本分配到不同的业务部门或项目,便于成本管理和分析。AWS Cost Explorer支持按存储桶标签汇总成本数据,帮助用户更好地理解存储成本分布。
S3 Transfer Acceleration是S3的性能优化功能,通过优化上传路径,显著提高远距离数据上传速度 。对于全球分布的应用,Transfer Acceleration可以将数据上传速度提高数倍,降低数据传输时间和成本。这一功能特别适合内容分发、媒体处理等需要快速上传大量数据的应用场景。
六、Amazon S3与同类产品的对比
在云计算领域,对象存储已成为标准服务,各大云提供商都提供了类似的产品。Amazon S3、Microsoft Azure Blob Storage和Google Cloud Storage是市场上主要的对象存储服务,它们在功能、性能和成本方面各有特点。
在一致性模型方面,S3提供PUT/DELETE操作的强一致性,而Azure Blob和Google Cloud Storage默认采用最终一致性模型 。强一致性简化了数据管理,使得开发者无需处理复杂的最终一致性问题,提高了应用的可靠性和易用性。这一差异使得S3在需要强一致性的场景(如金融交易、关键业务数据)中更具优势。
在存储类和成本优化方面,S3提供更丰富的存储类和更精细的生命周期管理策略。S3的存储类包括Standard、Standard-IA、One Zone-IA、Glacier Instant Retrieval、Glacier Flexible Retrieval和Glacier Deep Archive,覆盖从高可用性、高访问速度到低延迟、低成本的多种需求。S3 Intelligent-Tiering能够自动分析对象的访问模式,并将其迁移至最适合的存储类,无需用户手动干预。相比之下,Azure Blob和Google Cloud Storage的存储类相对较少,自动化程度也较低。
在API设计和生态系统集成方面,S3的RESTful API设计简洁且功能全面,同时与AWS生态系统深度集成。S3 Events可以无缝触发Lambda函数,实现数据处理的自动化。Azure Blob和Google Cloud Storage的API设计也较为完善,但与各自生态系统集成的深度和广度不及S3。Google Cloud Storage的事件通知需要通过Cloud Pub/Sub实现,配置相对复杂。
在性能方面,S3的目录存储桶和表存储桶针对特定应用场景进行了优化。目录存储桶通过单区域部署和集中元数据管理降低延迟,支持数据驻留需求;表存储桶通过元数据预计算和缓存,优化了分析查询性能,使S3能够直接支持机器学习和大数据分析工作负载。Azure Blob的Page Blob支持更好的随机读写性能,适合需要频繁修改数据的场景 ;Google Cloud Storage的冷存储成本可能略低于S3 Glacier,但整体生态系统集成不如S3成熟。
在安全特性方面,S3提供了更全面的安全功能,包括对象锁定、屏蔽公共访问权限、存储桶标签等 。S3 Object Lock支持WORM存储,满足合规性要求,防止对象被删除或修改;S3 Public Access Block可以全面屏蔽存储桶和对象的公共访问权限,提高安全性 。Azure Blob和Google Cloud Storage也提供了类似的安全功能,但功能的完整性和易用性不及S3。
在开发支持方面,S3提供了更丰富的SDK和开发工具,支持多种编程语言和框架。AWS SDK和CLI提供了全面的S3操作支持,同时与AWS其他服务深度集成,简化了开发流程。Azure Blob和Google Cloud Storage的SDK和开发工具也较为完善,但生态系统集成的广度和深度不及S3。
七、Amazon S3的使用方法与最佳实践
Amazon S3提供了多种使用方法,包括AWS管理控制台、AWS CLI、AWS SDK和REST API等 。这些方法各有优缺点,适用于不同场景和需求。AWS管理控制台适合快速创建和管理存储桶,AWS CLI适合命令行操作和自动化脚本,AWS SDK适合集成到应用程序中,REST API则提供了最底层的访问方式。
使用AWS CLI操作S3是一种高效且灵活的方式,适合自动化脚本和批量操作。以下是一些基本的CLI命令示例:
创建存储桶:
aws s3api create-bucket --bucket amzn-s3-demo-bucket --region us-east-1上传文件到存储桶:
aws s3 cp example.txt s3://amzn-s3-demo-bucket/下载文件从存储桶:
aws s3 cp s3://amzn-s3-demo-bucket/example.txt .列出存储桶中的对象:
aws s3 ls s3://amzn-s3-demo-bucket/删除存储桶及其内容:
aws s3 rm --recursive s3://amzn-s3-demo-bucket/
aws s3api delete-bucket --bucket amzn-s3-demo-bucket使用AWS SDK(如Python的Boto3)操作S3是大多数应用程序的首选方式,提供了更丰富的功能和更好的错误处理。以下是一个使用Boto3上传文件到S3的示例:
import boto3# 创建S3客户端
s3 = boto3.client('s3')# 上传文件到S3
response = s3.upload_file('example.txt','amzn-s3-demo-bucket','example.txt'
)print("File uploaded successfully:", response)对于大型文件(大于5GB),分片上传(Multipart Upload)是更高效的方式,可以避免网络中断导致的上传失败,并提高上传速度:
import boto3
from botocore.exceptions import ClientErrordef upload_large_file(file_name, bucket, object_name=None):if object_name is None:object_name = file_name# 创建S3客户端s3 = boto3.client('s3')try:# 初始化分片上传response = s3.create_multipart_upload(Bucket=bucket,Key=object_name)upload_id = response['UploadId']# 分片上传文件parts = []part_number = 1with open(file_name, 'rb') as f:while True:data = f.read(1024 * 1024 * 5) # 每个分片5MBif not data:breakresponse = s3.upload_part(Bucket=bucket,Key=object_name,UploadId=upload_id,PartNumber=part_number,Body=data)parts.append({'PartNumber': part_number,'ETag': response['ETag']})part_number += 1# 完成分片上传response = s3complete_multipart_upload(Bucket=bucket,Key=object_name,UploadId=upload_id,MultipartUpload={'Parts': parts})except ClientError as e:print("上传失败:", e)return Falsereturn TrueS3的事件通知配置是实现数据处理自动化的关键步骤。以下是一个配置S3事件通知的示例,当对象上传到特定前缀时触发Lambda函数:
{"Version": "2012-10-17","Statement": [{"Sid": "LambdaExecution","Effect": "Allow","Principal": {"Service": "lambda.amazonaws.com"},"Action": "s3:PutObject","Resource": "arn:aws:s3:::amzn-s3-demo-bucket/images/*"}]
}配置事件通知:
aws s3api put-bucket通知 --bucket amzn-s3-demo-bucket --通知-configuration file://notification.json存储桶策略与IAM策略的最小权限原则是S3安全的最佳实践。应遵循"最小权限"原则,只授予必要的操作权限,避免过度授权。例如,以下是一个限制特定IP范围访问存储桶的策略:
{"Version": "2012-10-17","Statement": [{"Effect": "Deny","Principal": "*","Action": "s3:*","Resource": ["arn:aws:s3:::amzn-s3-demo-bucket","arn:aws:s3:::amzn-s3-demo-bucket/*"],"Condition": {"NotIPRange": {"aws:SourceIp": ["203.0.113.0/24","198.51.100.0/24"]}}}]
}预签名URL生成是安全共享S3对象的有效方式,无需修改存储桶策略即可临时授予访问权限:
import boto3
from datetime import datetime, timedelta# 创建S3客户端
s3 = boto3.client('s3')# 生成预签名URL(有效期7天)
url = s3.generate_presigned_url('get_object',Params={'Bucket': 'amzn-s3-demo-bucket', 'Key': 'example.txt'},expires_in=timedelta(days=7).total_seconds()
)print("Pre signed URL:", url)使用高性能S3客户端(如基于Amazon CRT的客户端)可以提高大文件上传下载的性能和可靠性:
# 安装依赖
# pip install aws-crt-boto3import botocore
from botocore import client# 创建高性能S3客户端
s3高性能客户端 = botocore.client('s3',region_name='us-east-1',credentials=botocore credentials credentials,endpoint_url='https://s3.amazonaws.com',config=botocore.config.Config(max丝=1000,connect超时=5000,read超时=5000,指数退避=botocore.config RetryingConfig(max_attempts=5,mode='适配器',backoff_type='指数',delay=1,max_delay=60))
)存储桶标签与成本优化是S3管理的重要实践。通过为存储桶添加标签,可以将成本分配到不同的业务维度:
# 添加存储桶标签
response = s3.putbucket_tagging(Bucket='amzn-s3-demo-bucket',Tagging={'TagSet': [{'Key': 'Purpose', 'Value': 'Testing'},{'Key': 'Environment', 'Value': 'Development'}]}
)跨账户访问权限 配置是S3多账户协作的重要功能。通过存储桶策略,可以安全地授予其他账户访问权限:
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"AWS": "arn:aws:iam::123456789012:role/s3-access-role"},"Action": "s3:GetObject","Resource": "arn:aws:s3:::amzn-s3-demo-bucket/*"}]
}S3的生命周期管理 是降低存储成本的重要工具。以下是一个将对象自动迁移至不同存储类的生命周期策略:
{"Version": "2012-10-17","Rules": [{"ID": "TransitionToIA","Status": "Enabled","NoncurrentVersionTransition": {"StorageClass": "STANDARD-IA","TransitionAfterDays": 30},"Transition": {"StorageClass": "GLACIER","TransitionAfterDays": 60}," expiration": {"DeleteMarkerAfterDays": 90,"Days": 120},"Prefix": "logs/"}]
}配置生命周期策略:
aws s3api putbucket_lifecycle --bucket amzn-s3-demo-bucket --lifecycle-configuration file://lifecycle.jsonS3的强一致性与最终一致性 是需要特别注意的方面。对于PUT和DELETE操作,S3提供强一致性;而对于GET和HEAD操作,则可能采用最终一致性 ,取决于具体场景和配置。在需要强一致性的场景中,应确保操作完成后再进行读取;而在允许最终一致性的场景中,可以接受短暂的不一致状态,提高系统性能。
使用S3表存储桶 是构建数据湖和分析平台的重要实践。表存储桶针对分析和机器学习工作负载优化,支持Apache Iceberg格式:
# 创建表存储桶
response = s3.create_bucket(Bucket='amzn-s3-demo-table-bucket',CreateBucketConfiguration={'LocationConstraint': 'us-east-1'},ObjectLockEnabledForBucket=True,TableBucket=True
)print("Table bucket created successfully:", response)使用S3目录存储桶 是构建低延迟应用的重要实践。目录存储桶通过单区域部署和集中元数据管理降低延迟:
# 创建目录存储桶
response = s3.create_bucket(Bucket='amzn-s3-demo-directory-bucket',CreateBucketConfiguration={'LocationConstraint': 'us-east-1'},DirectoryBucket=True
)print("Directory bucket created successfully:", response)八、Amazon S3的开发技巧与高级功能
Amazon S3的开发技巧和高级功能可以帮助开发者更高效地利用S3,构建高性能、高可靠性的应用。
分页操作是处理大量对象的必备技巧。S3的API返回结果通常分页,开发者需要处理分页令牌:
# 分页列出存储桶中的对象
def list_objects_withpagination(bucket_name, prefix=None, max_items=1000):client = boto3.client('s3')config = botocore.config.Config(max丝=1000,connect超时=5000,read超时=5000)client = boto3.client('s3', config=config)ContinuingToken = Nonewhile True:args = {'Bucket': bucket_name,'MaxItems': max_items}if ContinuingToken:args['ContinuingToken'] = ContinuingTokenif prefix:args['Prefix'] = prefixresponse = client.list_objects_v2(**args)objects = response.get('Contents', [])for obj in objects:yield objContinuingToken = response.get('NextContinuingToken')if not ContinuingToken:break错误处理与重试策略是S3开发的重要方面。S3 API可能返回各种错误,如403 Forbidden、404 Not Found等,开发者需要设计合理的错误处理和重试策略:
# 错误处理与指数退避重试
import random
import time
from botocore.exceptions import ClientErrordef safe upload(file_name, bucket, object_name=None, max_attempts=5):if object_name is None:object_name = file_namefor attempt in range(1, max_attempts + 1):try:s3 = boto3.client('s3')response = s3.upload_file(file_name, bucket, object_name)return responseexcept ClientError as e:if e响应码 == 403:print(f"Access denied (attempt {attempt}):", e)return Noneelif e响应码 == 404:print(f"Bucket not found (attempt {attempt}):", e)return Noneelse:print(f"Error (attempt {attempt}):", e)# 指数退避sleep_time = 2 ** attemptsleep_time += random.uniform(0, 1)time.sleep(sleep_time)print(f"Failed after {max_attempts} attempts.")return None使用S3 Select查询压缩数据 是提高查询效率的重要技巧。S3 Select允许直接查询压缩的CSV、JSON等格式的数据,无需下载整个对象:
import boto3# 使用S3 Select查询压缩的JSON数据
def query_compressed_json(bucket, key, query):s3 = boto3.client('s3')response = s3.select_object_content(Bucket=bucket,Key=key,ExpressionType='SQL',Expression=query,InputSerDeConfiguration={'SerDeType': 'OpenRecord','OpenRecordSerDeConfiguration': {'Record Delimiter': '\n'}},OutputSerDeConfiguration={'SerDeType': 'JSON','JSONSerDeConfiguration': {'.记录路径': '$'}})records = []for event in response['Payload']:if 'Records' in event:records.append(event['Records']['Payload'].decode('utf-8'))return '\n'.join(records)# 查询示例
query = "SELECT s.* FROM S3Object s WHERE s.status_code = '500'"
result = query_compressed_json('amzn-s3-demo-bucket', 'logs/compressed.json', query)
print("Query result:", result)使用S3元数据表 是加速数据发现的重要工具。S3元数据表自动捕获对象的元数据,并将其存储在只读、完全托管的Apache Iceberg表中:
# 查询S3元数据表
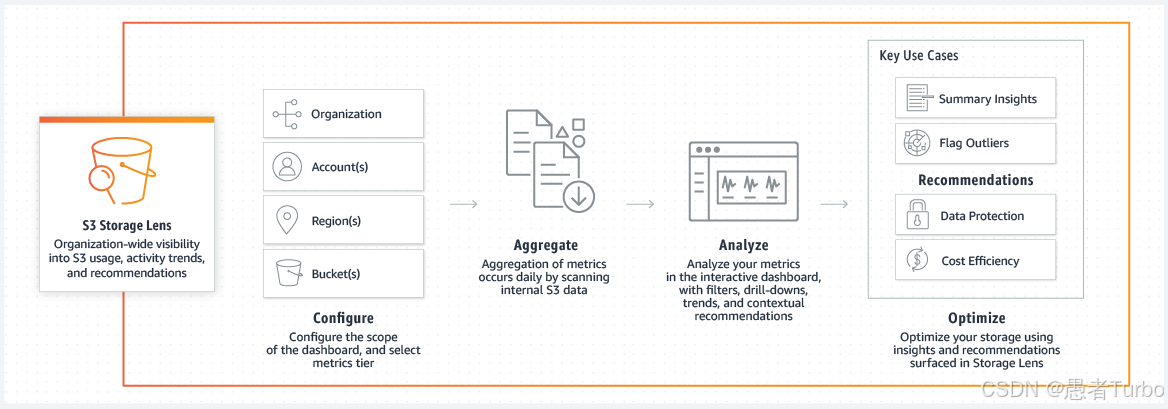
def query_s3_metadata_table(table_name, query):glue = boto3.client('glue')athena = boto3.client('athena')# 创建或获取元数据表try:response = glue.get_table(DatabaseName='s3_metadata',Name=table_name)except glue.exceptions TableDoesNotExist:# 创建元数据表response = glue.create_table(DatabaseName='s3_metadata',TableInput={'Name': table_name,'Storage桶': '冰川','SerDeInfo': {'Name': '冰川','SerDeType': '冰川'},'Location': f's3://s3-metadata-tables/{table_name}'})# 执行Athena查询response = athena.start_queryExecution(QueryString(query),QueryExecutionContext({'Database': 's3_metadata','Table': table_name}),ResultConfiguration({'OutputLocation': 's3://query-results/'}))return response['QueryExecutionId']使用S3存储桶分析 是优化存储成本的重要工具。S3 Storage Lens提供超过60个使用率和活动指标,帮助用户了解和优化存储:
# 配置S3 Storage Lens分析
def configure_s3_storage Lens(bucket_name):s3控制台 = boto3.client('s3控制台')response = s3控制台.putbucket LensConfiguration(Bucket=bucket_name,LensConfiguration={'BucketLevelMetrics': True,'PrefixLevelMetrics': True,'StorageClassAnalysis': True})return response使用S3批量操作 是管理大量对象的重要工具。S3批量操作允许通过单个API请求执行复制、恢复等操作:
# 执行S3批量操作(复制对象)
def execute_s3_batch_operation(bucket_name, source_prefix, destination_prefix, operation_type='copy'):s3 = boto3.client('s3')response = s3.start_batch_operation(Bucket=bucket_name,BatchOperationConfiguration={'Operation': {'Type': operation_type,'Copy': {'SourcePrefix': source_prefix,'DestinationPrefix': destination_prefix}},'Filter': {'Prefix': source_prefix}})return response['OperationId']使用S3 Transfer Acceleration 是提高远距离上传下载速度的重要工具。Transfer Acceleration通过优化上传路径,显著提高远距离数据上传速度 :
# 启用S3 Transfer Acceleration
def enable_s3_transfer acceleration(bucket_name):s3 = boto3.client('s3')response = s3.putbucket accelerationconfiguration(Bucket=bucket_name,AccelerationConfiguration={'Status': 'Enabled'})return response使用S3 Object Lock 是满足合规性要求的重要工具。Object Lock支持WORM存储,防止对象被删除或修改:
# 启用S3 Object Lock
def enable_s3_object_lock(bucket_name):s3 = boto3.client('s3')response = s3.putbucket objectlockconfiguration(Bucket=bucket_name,ObjectLockConfiguration={'ObjectLockEnabled': 'Enabled','Rule': {'DefaultRetention': {'Mode': 'COMPLIANCE','Days': 30}}})return response使用S3版本控制 是防止数据意外删除或覆盖的重要工具:
# 启用S3版本控制
def enable_s3_versioning (bucket_name):s3 = boto3.client('s3')response = s3.putbucket versioning(Bucket=bucket_name,VersioningConfiguration={'Status': 'Enabled'})return response使用S3存储桶标签 是成本管理和分类的重要工具:
# 添加S3存储桶标签
def add_s3_bucket_tags (bucket_name, tags):s3 = boto3.client('s3')response = s3.putbucket tagging(Bucket=bucket_name,Tagging={'TagSet': [{'Key': k, 'Value': v} for k, v in tags.items()]})return response使用S3存储桶策略 是安全控制的重要工具:
# 添加S3存储桶策略
def add_s3_bucket_policy (bucket_name, policy):s3 = boto3.client('s3')response = s3.putbucket policy(Bucket=bucket_name,Policy=policy)return response九、Amazon S3的未来趋势与发展方向
随着云计算和大数据技术的不断发展,Amazon S3也在持续演进,以满足不断变化的市场需求。未来S3的发展方向将集中在性能优化、安全增强和生态系统集成三个方面。
在性能优化方面,S3将继续提升存储桶类型(目录存储桶和表存储桶)的性能和功能,针对低延迟和分析场景提供更优化的存储解决方案。S3的元数据管理将更加智能化,通过机器学习预测访问模式并优化数据分布,进一步降低延迟和提高吞吐量。此外,S3将继续增强与AWS其他服务的集成,如Snowball、DataSync等,提供更全面的数据迁移和管理工具 。
在安全增强方面,S3将继续完善数据保护和合规性功能,如增强的对象锁定、更细粒度的访问控制和审计功能。S3将支持更多加密选项和密钥管理策略,满足不同安全需求。此外,S3将加强数据完整性保护,提供更强大的校验和验证机制,确保数据在存储和传输过程中的完整性。
在生态系统集成方面,S3将继续深化与Serverless架构的集成,如增强的事件通知功能和更紧密的Lambda集成。S3将支持更多分析和机器学习工具的直接集成,如与Athena、Redshift和Glue的深度集成,简化数据湖和分析平台的构建。此外,S3将加强与其他云服务提供商的互操作性,提供更灵活的多云数据管理解决方案。
随着边缘计算和物联网技术的发展,S3将扩展到边缘场景,提供更低延迟的数据访问和处理能力。例如,通过与AWS Local Zones和Edge locations的集成,S3可以在边缘位置存储和处理数据,满足实时分析和响应的需求。
最后,S3将继续推动成本优化和可持续性发展,通过更智能的存储分层和生命周期管理,降低存储成本并提高资源利用率。同时,S3将探索更环保的存储技术,减少能源消耗和碳排放,支持可持续发展目标。
十、总结与建议
Amazon S3作为云计算领域的对象存储服务,已经从简单的数据存储工具发展成为支持复杂数据湖和分析工作负载的平台。S3的核心优势在于其高可靠性、高可用性、强一致性以及丰富的存储类和生命周期管理策略,使其能够满足各种复杂的数据存储需求。
对于技术开发人员,建议从以下几个方面充分利用S3:
首先,理解S3的存储模型和核心概念 ,包括存储桶、对象、键名和存储类等,这是正确使用S3的基础。其次,根据应用需求选择合适的存储类,如对于关键业务数据选择Standard,对于归档数据选择Glacier Deep Archive,优化存储成本和性能。
第三,充分利用S3的安全功能 ,如对象锁定、屏蔽公共访问权限、存储桶标签等,确保数据的安全性和合规性。第四,通过事件通知和Serverless集成,构建响应式应用,实现数据处理的自动化。例如,上传图像文件时自动触发图像处理Lambda函数,或上传日志文件时自动触发数据分析工作流。
最后,定期审查和优化S3使用,包括存储桶策略、访问控制、生命周期管理和标签等,确保资源的高效利用和成本控制。使用S3 Storage Lens分析工具,了解存储使用情况和活动趋势,发现优化机会并采取相应措施。
随着S3的持续演进,目录存储桶和表存储桶将成为构建低延迟应用和数据湖的重要工具,技术开发人员应关注这些新特性并探索其在应用中的应用。同时,S3与Serverless架构的深度集成也将继续发展,为开发者提供更强大的数据处理能力。
总的来说,Amazon S3作为云计算时代的数据存储基石,将继续发挥重要作用,并不断演进以满足新的需求和挑战。技术开发人员应深入了解S3的技术架构和功能特性,充分利用其优势,构建高性能、高可靠性的应用。
参考资料:
- Amazon S3 文档
- Amazon S3 Api 列表
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!关于愚者Turbo:
🌟博主GitHub
🌞博主知识星球