llama.cpp:本地大模型推理的高性能 C++ 框架
一、基本介绍
llama.cpp是由Georgi Gerganov发起的纯C/C++开源框架,专注于在本地设备(如普通PC、树莓派、嵌入式终端)上实现低资源、高性能的大语言模型(LLM)推理。其核心目标是打破云端依赖,让开发者能在消费级硬件上本地运行Meta LLaMA、Mistral、Gemma等主流开源模型,兼顾隐私保护与推理效率。
二、核心特点
1. 极致轻量与高效
- 纯C/C++实现:无第三方依赖,对CPU架构(x86、ARM)深度优化,支持4-bit、8-bit等低精度量化(如GGUF格式),大幅降低模型体积(例如7B参数模型可压缩至4GB以内)和内存占用。
- 多硬件加速:支持多核CPU并行计算,同时兼容CUDA(NVIDIA GPU)、Metal(Apple Silicon)、Vulkan等GPU后端,提升推理速度。
2. 跨平台支持
可运行于Linux、macOS、Windows、Android、iOS等主流系统,甚至能在树莓派、Steam Deck等嵌入式设备上部署,覆盖从服务器到终端的全场景。
3. 开源与生态丰富
- 完全开源(GitHub: ggml-org/llama.cpp),社区活跃,衍生出Web界面(如LM Studio)、Python/Node.js绑定等工具。
- 支持LLaMA、Mistral、Falcon、Gemma等多种开源模型,且可通过
convert.py工具将Hugging Face模型转换为gguf格式。
4. 离线隐私保护
完全离线运行,无需联网,避免数据泄露风险,适合医疗、金融等对数据敏感的场景。
三、主要功能
1. 模型转换与量化
- 格式转换:通过
convert_hf_to_gguf.py脚本将Hugging Face的PyTorch模型(如Qwen1.5-7B)转换为llama.cpp专用的GGUF格式(支持多架构、多精度混合存储)。 - 量化压缩:使用
llama-quantize工具对模型进行量化(如q4_0、q8_0),在保持推理性能的同时减少内存占用(例如4-bit量化可将7B模型体积压缩至3.8GB)。
2. 模型推理
- 命令行工具(llama-cli):通过命令行与模型交互,支持对话模式(
-cnv参数)、GPU卸载(-ngl参数,如-ngl 24表示卸载24层到GPU)。 - 服务器模式(llama-server):启动RESTful API服务,支持OpenAI风格API调用(如
client.chat.completions.create),方便与LangChain、LlamaIndex等框架集成。
3. 多语言绑定
提供Python、Go、Node.js、Rust等语言的绑定(如llama-cpp-python),允许开发者在不同编程环境中调用llama.cpp的功能。
四、典型应用场景
- 本地对话助手:通过命令行或Web界面与模型交互,实现私人AI助手。
- 开发集成:作为后端服务供聊天机器人、文本生成等应用调用,支持高并发。
- 研究实验:在边缘设备(如树莓派)上低成本测试大模型性能,验证模型压缩与推理优化效果。
五、官方仓库
git clone https://github.com/ggml-org/llama.cpp.git
六、Docker 镜像
1、镜像版本
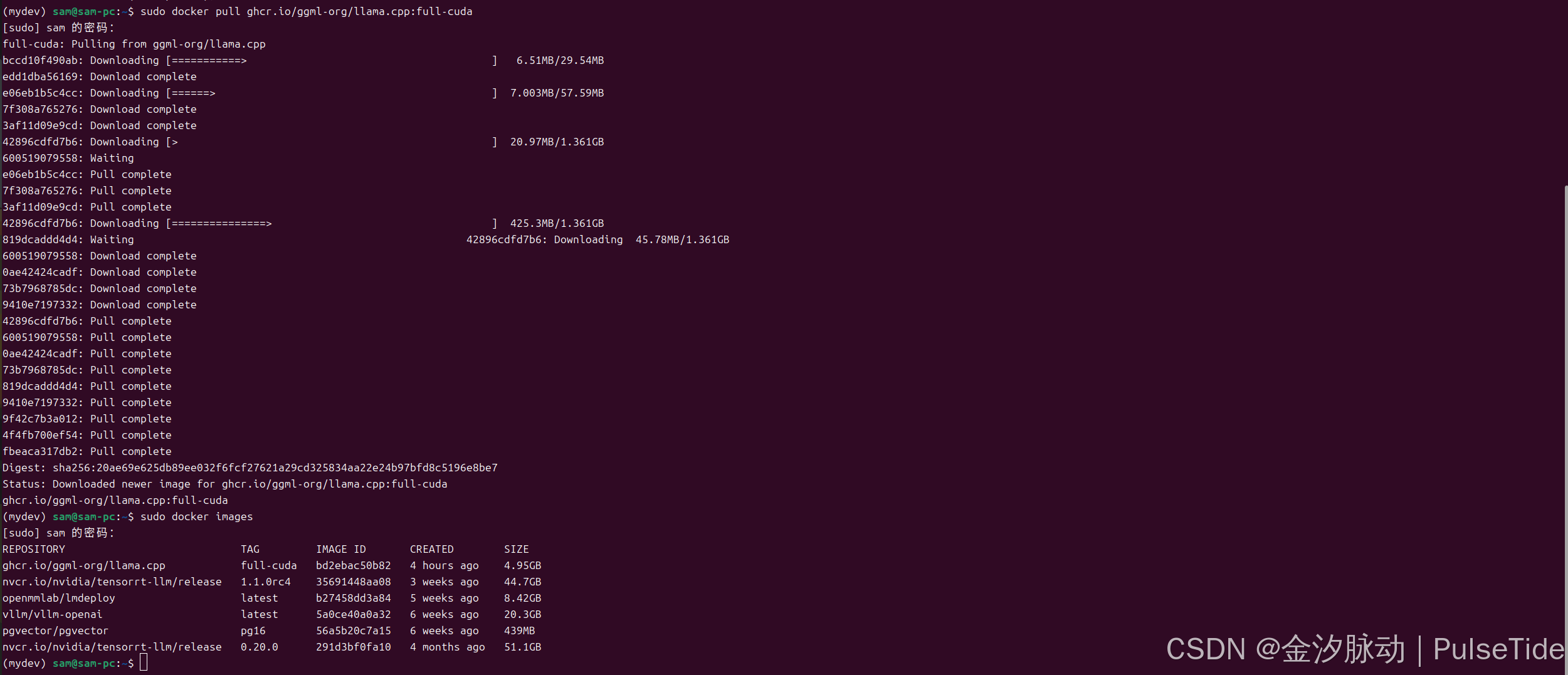
拉取 docker 镜像(cuda版本):
sudo docker pull ghcr.io/ggml-org/llama.cpp:full-cuda
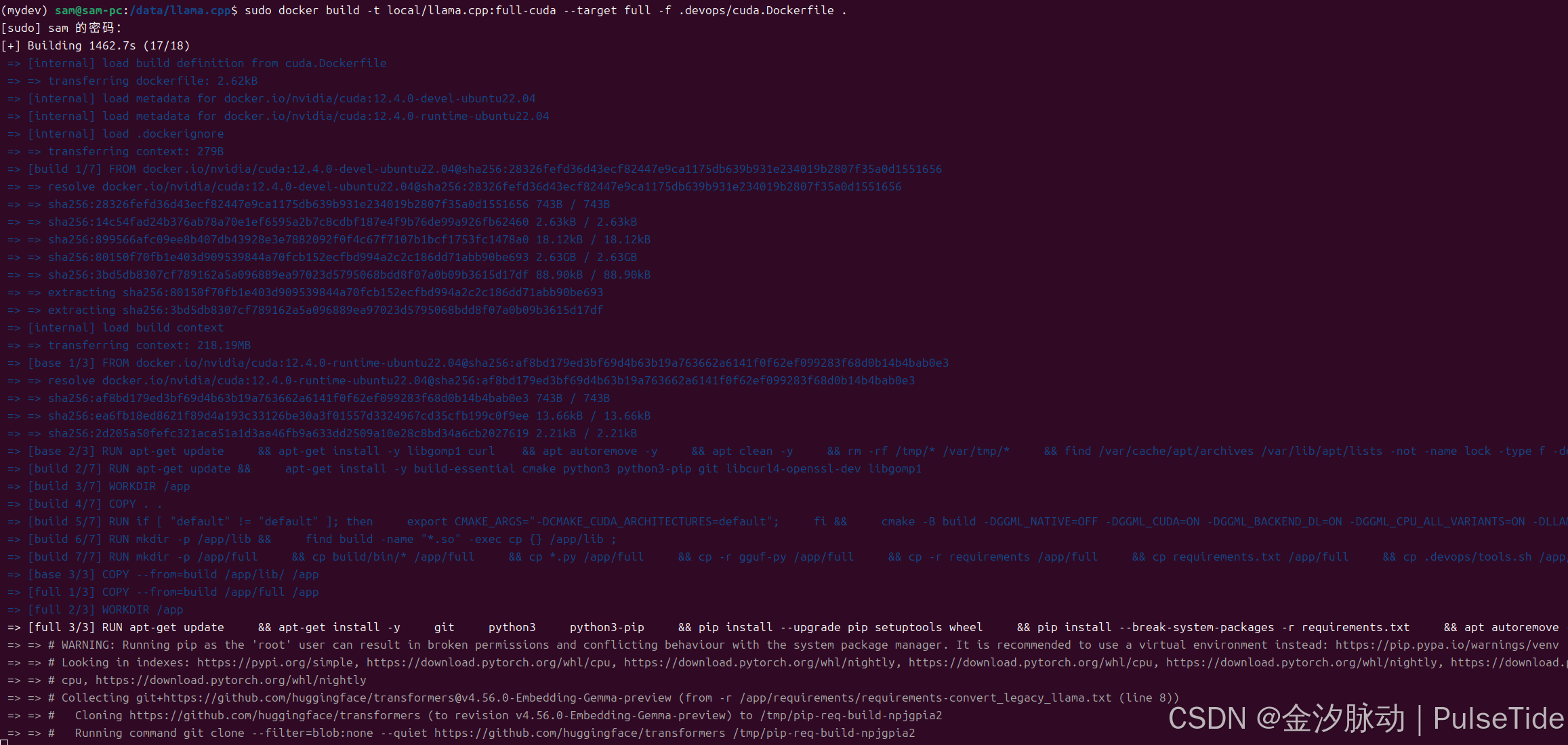
或者本地构建镜像(需要魔法):
# 可修改文件 .devops/cuda.Dockerfile 进行自定义配置
sudo docker build -t local/llama.cpp:full-cuda --target full -f .devops/cuda.Dockerfile .
2、推理与部署
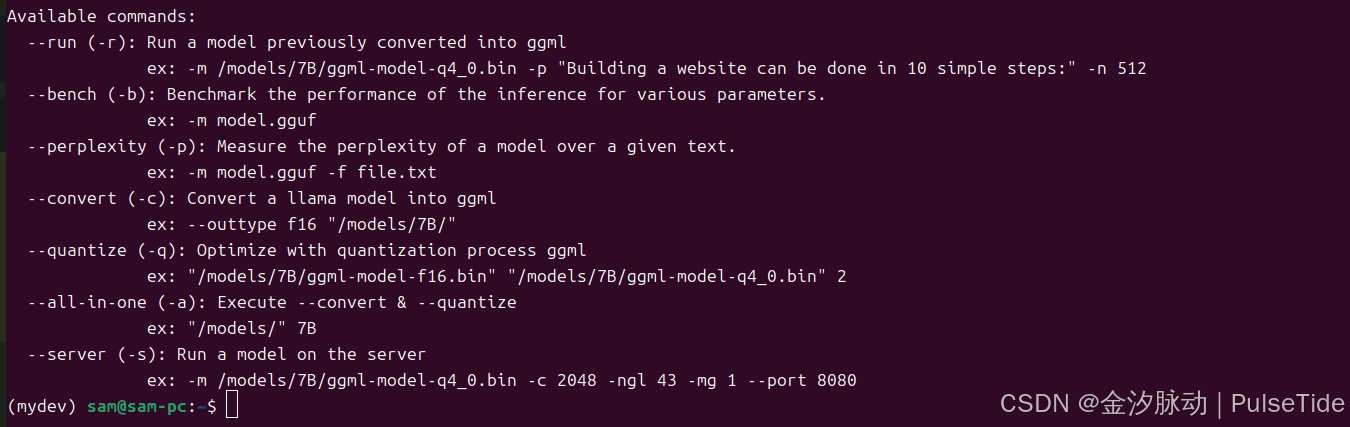
可用的指令如下:
Available commands: --run (-r): Run a model previously converted into ggmlex: -m /models/7B/ggml-model-q4_0.bin -p "Building a website can be done in 10 simple steps:" -n 512--bench (-b): Benchmark the performance of the inference for various parameters.ex: -m model.gguf--perplexity (-p): Measure the perplexity of a model over a given text.ex: -m model.gguf -f file.txt--convert (-c): Convert a llama model into ggmlex: --outtype f16 "/models/7B/" --quantize (-q): Optimize with quantization process ggmlex: "/models/7B/ggml-model-f16.bin" "/models/7B/ggml-model-q4_0.bin" 2--all-in-one (-a): Execute --convert & --quantizeex: "/models/" 7B--server (-s): Run a model on the serverex: -m /models/7B/ggml-model-q4_0.bin -c 2048 -ngl 43 -mg 1 --port 8080
2.1、在线推理
docker run --gpus all -v /path/to/models:/models local/llama.cpp:full-cuda --run -m /models/7B/ggml-model-q4_0.gguf -p "Building a website can be done in 10 simple steps:" -n 512 --n-gpu-layers 1
# docker run --gpus all -v /path/to/models:/models local/llama.cpp:light-cuda -m /models/7B/ggml-model-q4_0.gguf -p "Building a website can be done in 10 simple steps:" -n 512 --n-gpu-layers 1
基础部分
-
docker run
启动一个新的 Docker 容器。 -
--gpus all
允许容器使用宿主机的所有 GPU 资源(需要 NVIDIA 驱动和 Docker GPU 支持)。 -
-v /path/to/models:/models
将宿主机的/path/to/models目录挂载到容器的/models路径,使容器能访问外部模型文件。 -
local/llama.cpp:full-cuda
使用名为local/llama.cpp、标签为full-cuda的本地镜像(该镜像应已编译支持 CUDA 的 Llama.cpp)。
Llama.cpp 参数
-
--run
启动模型推理(可能是某些 Llama.cpp 分支的特定参数)。 -
-m /models/7B/ggml-model-q4_0.gguf
指定模型路径:容器内挂载的 7B 参数量模型,量化格式为q4_0(4-bit 量化)。 -
-p "Building a website can be done in 10 simple steps:"
输入提示词(prompt),要求模型续写“如何用10个简单步骤构建网站”。 -
-n 512
限制模型生成的最大 token 数量为 512。 -
--n-gpu-layers 1
将模型的 1 层计算卸载到 GPU(其余部分在 CPU 运行),加速推理。
关键细节
- CUDA 加速:
full-cuda镜像和--gpus all表明使用 GPU 加速,适合大模型推理。 - 模型量化:
q4_0是低精度量化格式,牺牲少量质量换取更低显存占用。 - GPU 层数:
--n-gpu-layers 1可能偏低,通常设为更大的值(如 20-40)以最大化 GPU 利用率。
预期行为
容器会加载 7B 模型,根据提示生成一段关于“构建网站步骤”的文本,生成长度不超过 512 token,并利用 GPU 加速部分计算。
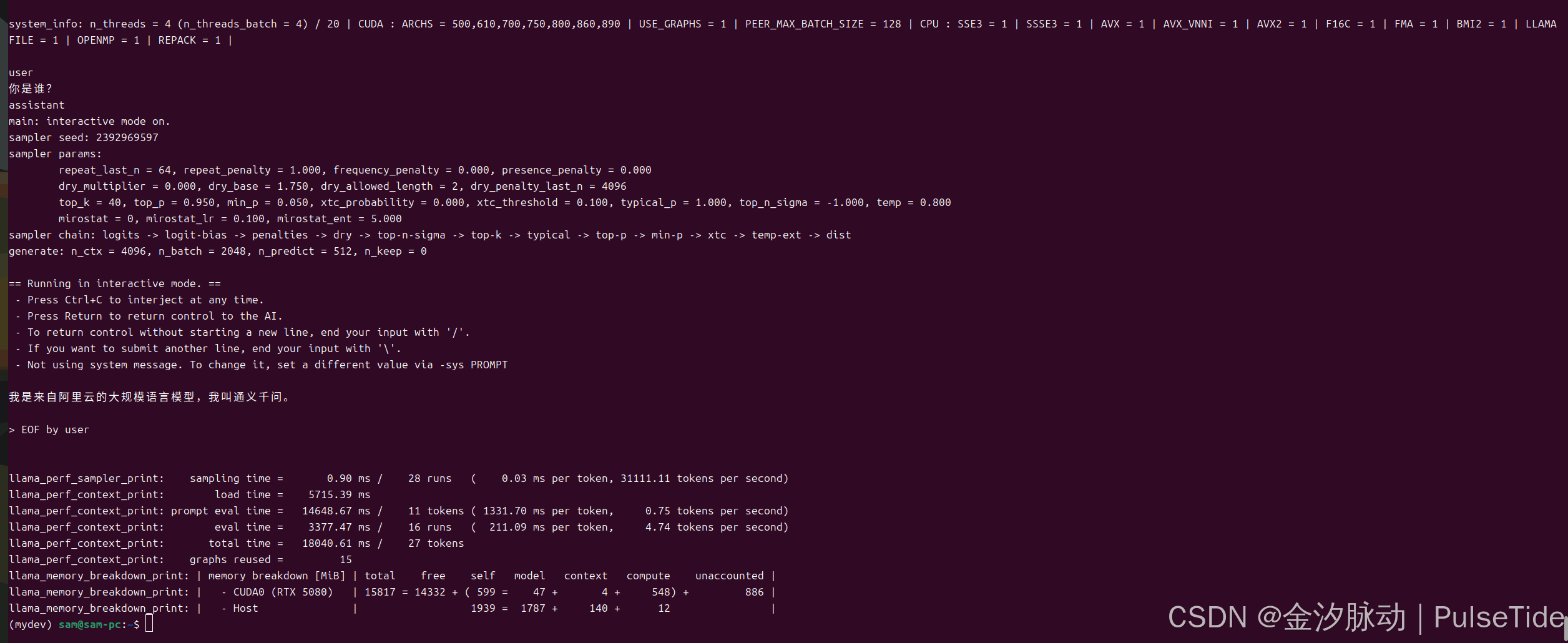
例如,使用 Qwen3-0.6B-GGUF 进行文本推理:
sudo docker run --gpus all -v ~/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B-GGUF:/models/Qwen3-0.6B-GGUF ghcr.io/ggml-org/llama.cpp:full-cuda --run -m /models/Qwen3-0.6B-GGUF/Qwen3-0.6B-Q8_0.gguf -p "你是谁?" -n 512 --n-gpu-layers 1
2.2、模型服务
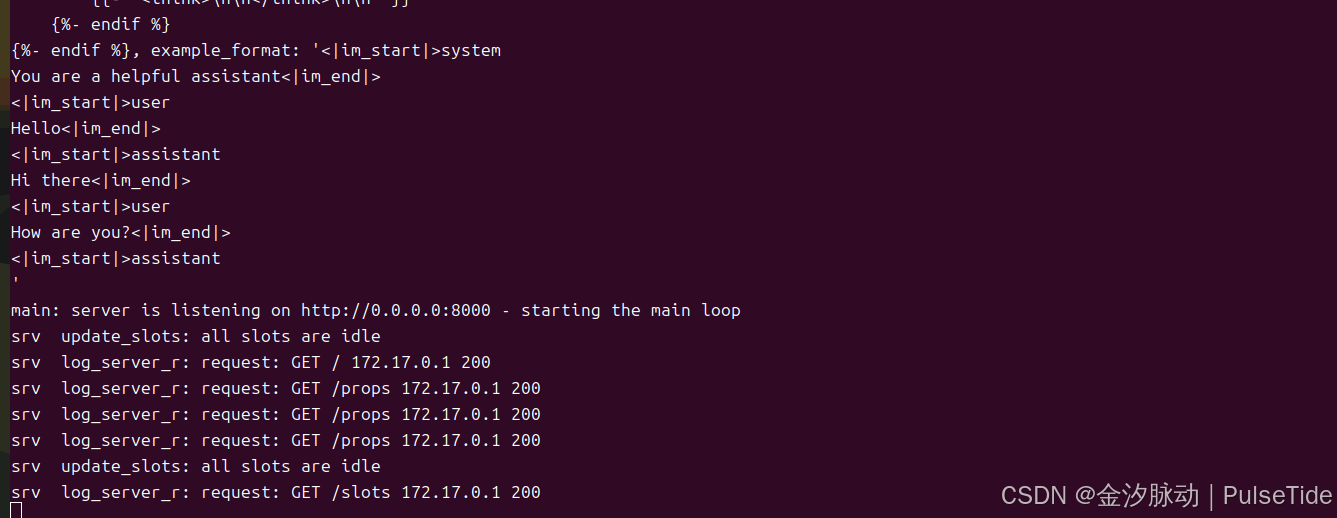
docker run --gpus all -v /path/to/models:/models local/llama.cpp:server-cuda -m /models/7B/ggml-model-q4_0.gguf --port 8000 --host 0.0.0.0 -n 512 --n-gpu-layers 1
例如,使用 Qwen3-0.6B-GGUF 模型服务:
sudo docker run --gpus all -p 8000:8000 -v ~/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B-GGUF:/models/Qwen3-0.6B-GGUF ghcr.io/ggml-org/llama.cpp:full-cuda --server -m /models/Qwen3-0.6B-GGUF/Qwen3-0.6B-Q8_0.gguf --port 8000 --host 0.0.0.0 -n 512 --n-gpu-layers 1
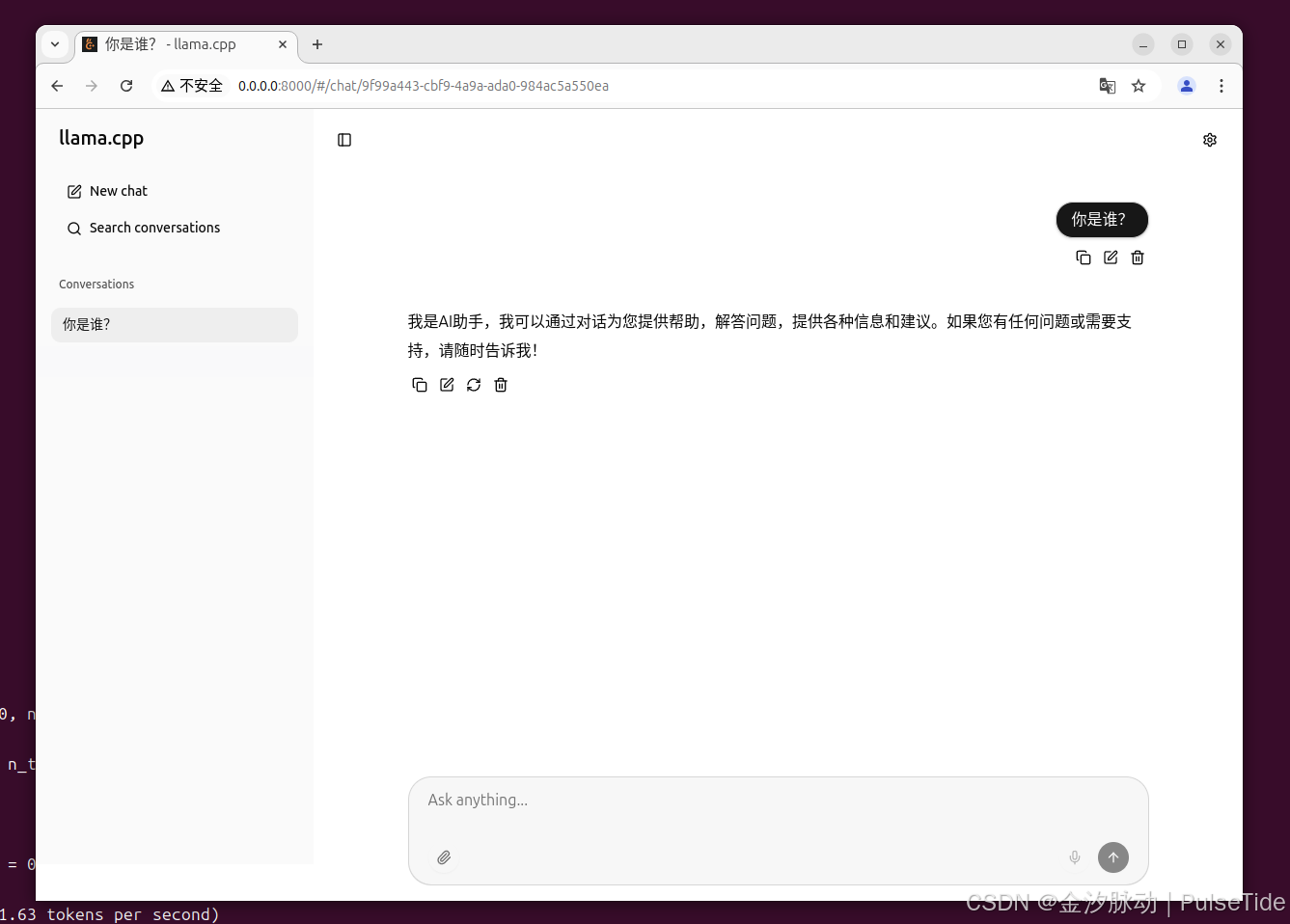
OpenAI API 调用:
from openai import OpenAI
import osdef get_response():client = OpenAI(api_key="", base_url="http://0.0.0.0:8000/v1",)completion = client.chat.completions.create(model="Qwen3-0.6B-Q8_0.gguf",messages=[{'role': 'system', 'content': 'You are a helpful assistant.'},{'role': 'user', 'content': '你是谁?'}])# json 数据print(completion.model_dump_json())print(completion.choices[0].message.content)if __name__ == '__main__':get_response()

{"id":"chatcmpl-USlPwruNMyJjwnTws7Nkm8DdtmKSvxLn","choices":[{"finish_reason":"stop","index":0,"logprobs":null,"message":{"content":"<think>\n好的,用户问我是谁。我需要回答清楚。首先,作为AI助手,我是一个由语言模型训练而成的智能助手。我的存在是因为人类对知识的渴望和对解决问题的需求。我可以帮助用户回答各种问题,提供信息,或者提供支持。\n\n接下来,要确保回答简洁明了,同时保持友好和专业。用户可能希望了解我的功能和特点,或者他们可能有其他问题。我应该明确说明我的身份,并表达愿意提供帮助的态度。同时,可以鼓励用户提问,创造更互动的交流环境。\n\n需要注意的是,回答要符合中文语境,避免使用复杂或晦涩的词汇。保持口语化,让用户感觉亲切自然。最后,确认回答是否符合用户的需求,是否需要进一步帮助。\n</think>\n\n我是AI助手,由语言模型训练而成。我可以通过文字、语音等方式与您互动,提供信息、解答问题或协助您完成各种任务。如果您有任何疑问或需要帮助,请随时告诉我!","refusal":null,"role":"assistant","annotations":null,"audio":null,"function_call":null,"tool_calls":null}}],"created":1759411919,"model":"Qwen3-0.6B-Q8_0.gguf","object":"chat.completion","service_tier":null,"system_fingerprint":"b6665-95ce0985","usage":{"completion_tokens":203,"prompt_tokens":22,"total_tokens":225,"completion_tokens_details":null,"prompt_tokens_details":null},"timings":{"cache_n":21,"prompt_n":1,"prompt_ms":26.934,"prompt_per_token_ms":26.934,"prompt_per_second":37.12779386648845,"predicted_n":203,"predicted_ms":3265.087,"predicted_per_token_ms":16.0841724137931,"predicted_per_second":62.17292219165983}}
<think>
好的,用户问我是谁。我需要回答清楚。首先,作为AI助手,我是一个由语言模型训练而成的智能助手。我的存在是因为人类对知识的渴望和对解决问题的需求。我可以帮助用户回答各种问题,提供信息,或者提供支持。接下来,要确保回答简洁明了,同时保持友好和专业。用户可能希望了解我的功能和特点,或者他们可能有其他问题。我应该明确说明我的身份,并表达愿意提供帮助的态度。同时,可以鼓励用户提问,创造更互动的交流环境。需要注意的是,回答要符合中文语境,避免使用复杂或晦涩的词汇。保持口语化,让用户感觉亲切自然。最后,确认回答是否符合用户的需求,是否需要进一步帮助。
</think>我是AI助手,由语言模型训练而成。我可以通过文字、语音等方式与您互动,提供信息、解答问题或协助您完成各种任务。如果您有任何疑问或需要帮助,请随时告诉我!
3、格式转化
llama.cpp 仅支持 GGUF 格式的模型,因此部署前需要将其他模型格式转为 GGUF:
usage: convert_hf_to_gguf.py [-h] [--vocab-only] [--outfile OUTFILE][--outtype {f32,f16,bf16,q8_0,tq1_0,tq2_0,auto}][--bigendian] [--use-temp-file] [--no-lazy][--model-name MODEL_NAME] [--verbose][--split-max-tensors SPLIT_MAX_TENSORS][--split-max-size SPLIT_MAX_SIZE] [--dry-run][--no-tensor-first-split] [--metadata METADATA][--print-supported-models] [--remote] [--mmproj][--mistral-format][--disable-mistral-community-chat-template][model]
# 示例1、Qwen2.5-3B-Instruct
sudo docker run --rm --gpus all -p 8000:8000 -v ~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct:/models/Qwen2.5-3B-Instruct ghcr.io/ggml-org/llama.cpp:full-cuda --convert --outtype f16 "/models/Qwen2.5-3B-Instruct"
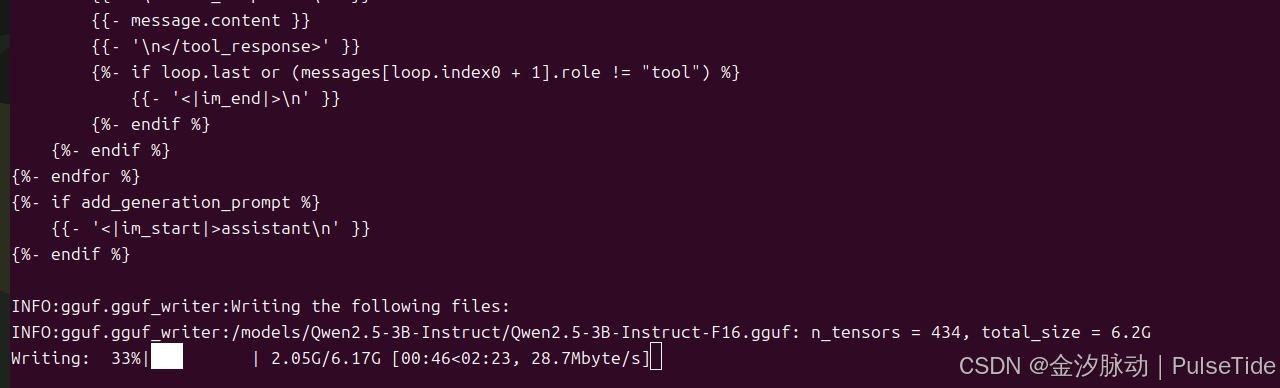
在模型目录下生成对应的 gguf 文件:
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:/models/Qwen2.5-3B-Instruct/Qwen2.5-3B-Instruct-F16.gguf: n_tensors = 434, total_size = 6.2G
Writing: 100%|██████████| 6.17G/6.17G [02:43<00:00, 37.8Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to /models/Qwen2.5-3B-Instruct/Qwen2.5-3B-Instruct-F16.gguf

# 示例2、对 gpt-oss-20b 进行格式转换
sudo docker run --rm --gpus all -p 8000:8000 -v ~/.cache/modelscope/hub/models/openai-mirror/gpt-oss-20b:/models/gpt-oss-20b ghcr.io/ggml-org/llama.cpp:full-cuda --convert --outtype f16 "/models/gpt-oss-20b"
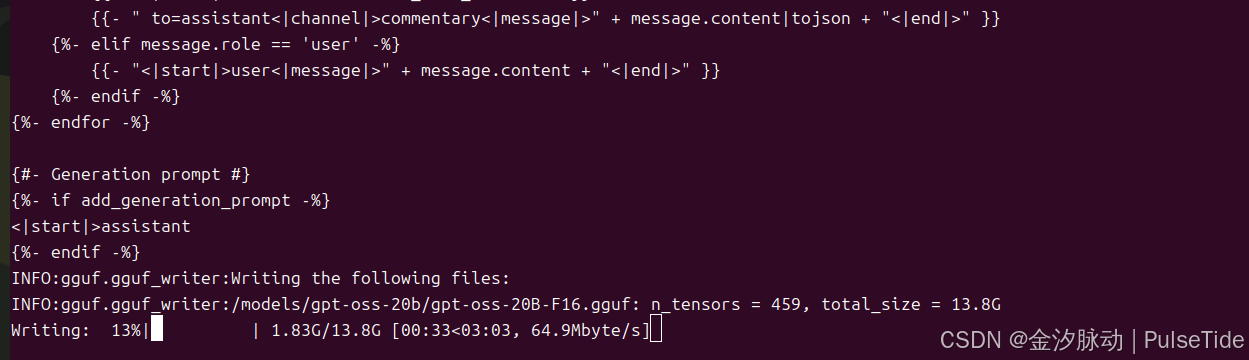
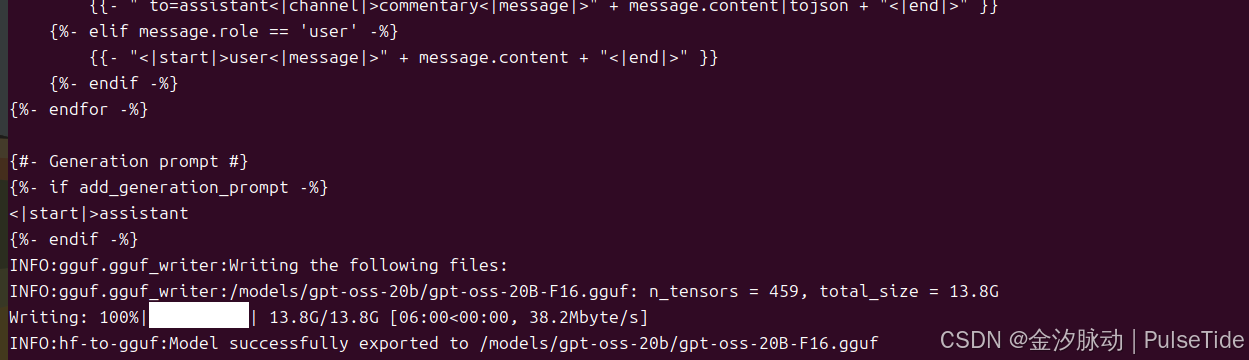
4、模型量化
压缩指令说明:
usage: ./llama-quantize [--help] [--allow-requantize] [--leave-output-tensor] [--pure] [--imatrix] [--include-weights][--exclude-weights] [--output-tensor-type] [--token-embedding-type] [--tensor-type] [--prune-layers] [--keep-split] [--override-kv]model-f32.gguf [model-quant.gguf] type [nthreads]--allow-requantize: Allows requantizing tensors that have already been quantized. Warning: This can severely reduce quality compared to quantizing from 16bit or 32bit--leave-output-tensor: Will leave output.weight un(re)quantized. Increases model size but may also increase quality, especially when requantizing--pure: Disable k-quant mixtures and quantize all tensors to the same type--imatrix file_name: use data in file_name as importance matrix for quant optimizations--include-weights tensor_name: use importance matrix for this/these tensor(s)--exclude-weights tensor_name: use importance matrix for this/these tensor(s)--output-tensor-type ggml_type: use this ggml_type for the output.weight tensor--token-embedding-type ggml_type: use this ggml_type for the token embeddings tensor--tensor-type TENSOR=TYPE: quantize this tensor to this ggml_type. example: --tensor-type attn_q=q8_0Advanced option to selectively quantize tensors. May be specified multiple times.--prune-layers L0,L1,L2...comma-separated list of layer numbers to prune from the modelAdvanced option to remove all tensors from the given layers--keep-split: will generate quantized model in the same shards as input--override-kv KEY=TYPE:VALUEAdvanced option to override model metadata by key in the quantized model. May be specified multiple times.
Note: --include-weights and --exclude-weights cannot be used togetherAllowed quantization types:2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B38 or MXFP4_MOE : MXFP4 MoE8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B19 or IQ2_XXS : 2.06 bpw quantization20 or IQ2_XS : 2.31 bpw quantization28 or IQ2_S : 2.5 bpw quantization29 or IQ2_M : 2.7 bpw quantization24 or IQ1_S : 1.56 bpw quantization31 or IQ1_M : 1.75 bpw quantization36 or TQ1_0 : 1.69 bpw ternarization37 or TQ2_0 : 2.06 bpw ternarization10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B23 or IQ3_XXS : 3.06 bpw quantization26 or IQ3_S : 3.44 bpw quantization27 or IQ3_M : 3.66 bpw quantization mix12 or Q3_K : alias for Q3_K_M22 or IQ3_XS : 3.3 bpw quantization11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B25 or IQ4_NL : 4.50 bpw non-linear quantization30 or IQ4_XS : 4.25 bpw non-linear quantization15 or Q4_K : alias for Q4_K_M14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B17 or Q5_K : alias for Q5_K_M16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B0 or F32 : 26.00G @ 7BCOPY : only copy tensors, no quantizing
# 对 Qwen2.5-3B-Instruct-F16.gguf 进行 Q4_K_M 量化
sudo docker run --rm --gpus all -v ~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct:/models/Qwen2.5-3B-Instruct ghcr.io/ggml-org/llama.cpp:full-cuda --quantize "/models/Qwen2.5-3B-Instruct/Qwen2.5-3B-Instruct-F16.gguf" Q4_K_M
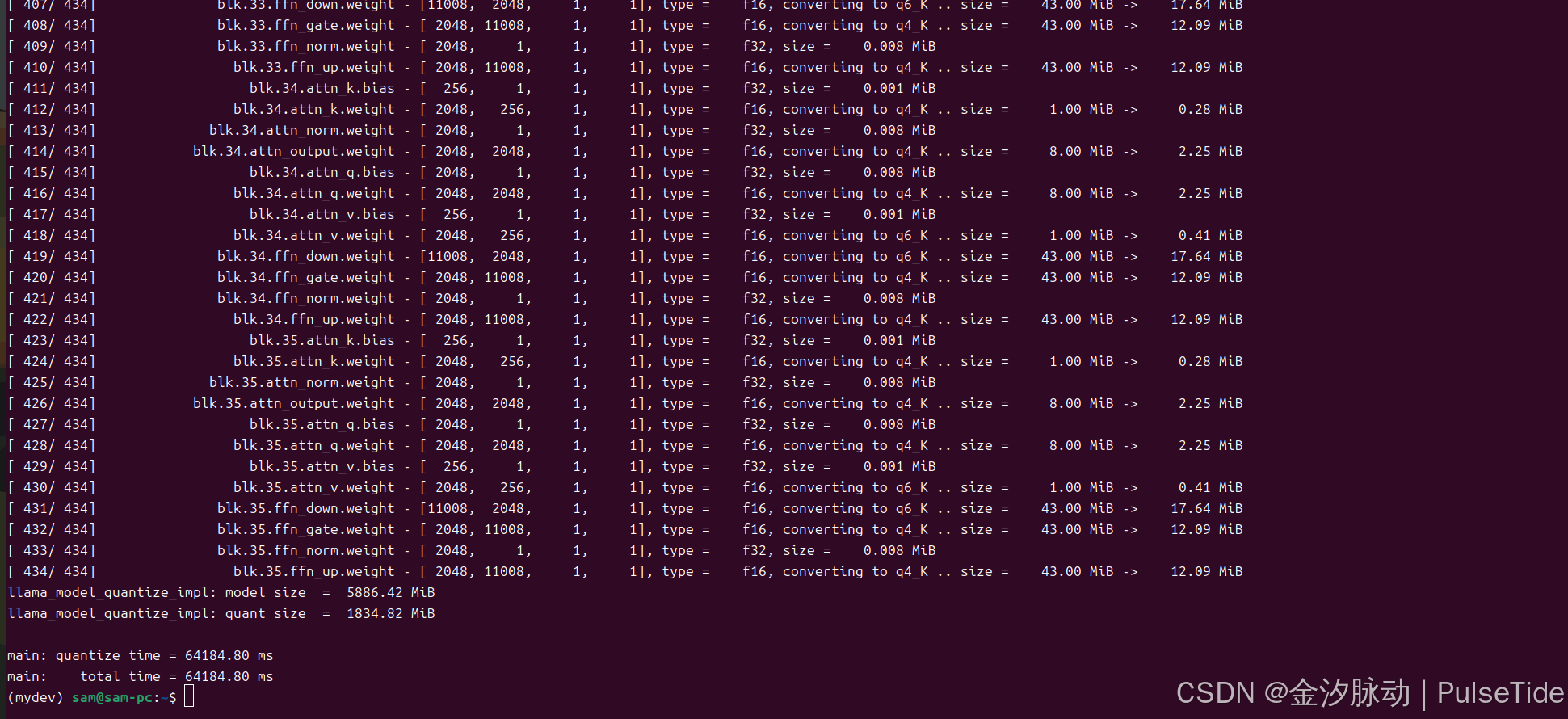
[ 427/ 434] blk.35.attn_q.bias - [ 2048, 1, 1, 1], type = f32, size = 0.008 MiB
[ 428/ 434] blk.35.attn_q.weight - [ 2048, 2048, 1, 1], type = f16, converting to q4_K .. size = 8.00 MiB -> 2.25 MiB
[ 429/ 434] blk.35.attn_v.bias - [ 256, 1, 1, 1], type = f32, size = 0.001 MiB
[ 430/ 434] blk.35.attn_v.weight - [ 2048, 256, 1, 1], type = f16, converting to q6_K .. size = 1.00 MiB -> 0.41 MiB
[ 431/ 434] blk.35.ffn_down.weight - [11008, 2048, 1, 1], type = f16, converting to q6_K .. size = 43.00 MiB -> 17.64 MiB
[ 432/ 434] blk.35.ffn_gate.weight - [ 2048, 11008, 1, 1], type = f16, converting to q4_K .. size = 43.00 MiB -> 12.09 MiB
[ 433/ 434] blk.35.ffn_norm.weight - [ 2048, 1, 1, 1], type = f32, size = 0.008 MiB
[ 434/ 434] blk.35.ffn_up.weight - [ 2048, 11008, 1, 1], type = f16, converting to q4_K .. size = 43.00 MiB -> 12.09 MiB
llama_model_quantize_impl: model size = 5886.42 MiB
llama_model_quantize_impl: quant size = 1834.82 MiBmain: quantize time = 64184.80 ms
main: total time = 64184.80 ms
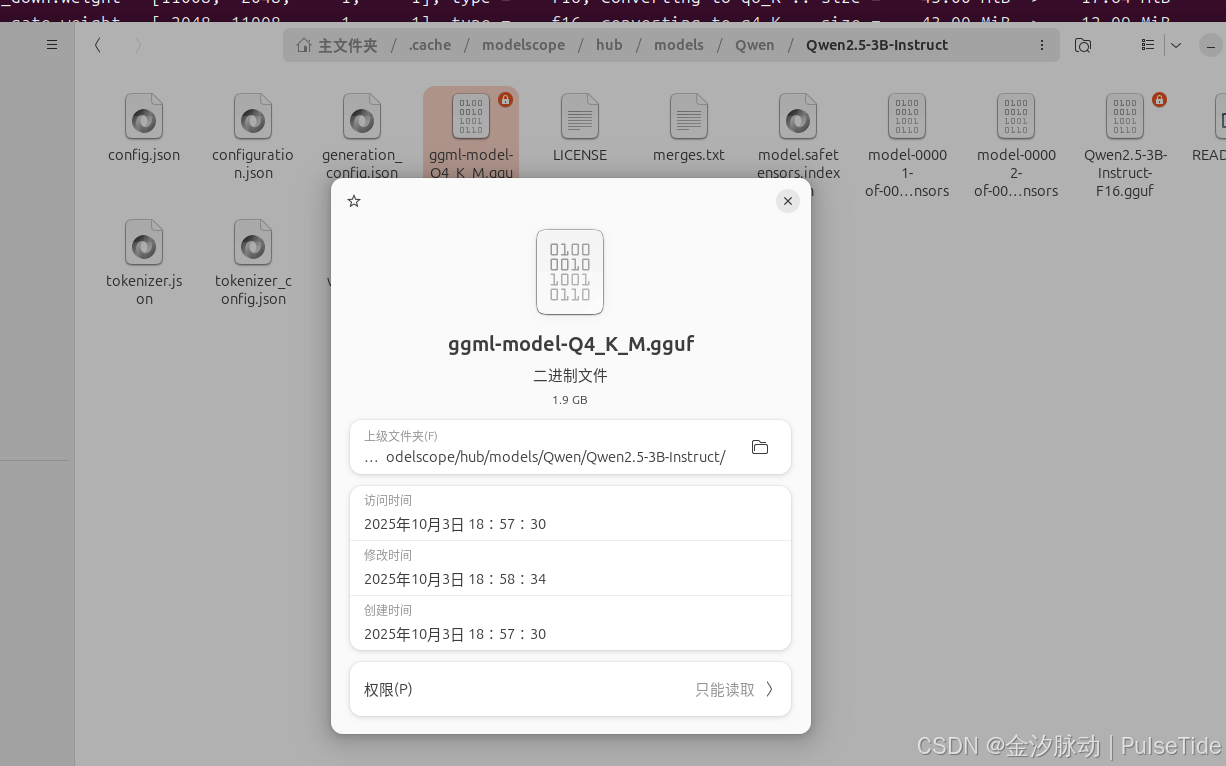
量化前:6.2GB,量化后:1.9GB:
# 运行量化模型
sudo docker run --rm --gpus all -v ~/.cache/modelscope/hub/models/Qwen/Qwen2.5-3B-Instruct:/models/Qwen2.5-3B-Instruct ghcr.io/ggml-org/llama.cpp:full-cuda --run -m /models/Qwen2.5-3B-Instruct/ggml-model-Q4_K_M.gguf -p "你是谁?" -n 512 --n-gpu-layers 1
量化等级建议:
- 显存紧张场景:选择
Q4_K_M,兼顾性能和资源消耗。 - 高精度需求:优先
Q5_K_M或Q6_K,接近原始模型表现。 - 极端轻量化:
Q3_K_M比Q4_0更优,误差更低。 - 调试研究:使用
Q8_0观察无损量化效果,但实际部署不推荐。
七、多语言绑定
1、python 绑定
官方仓库:
git clone https://github.com/abetlen/llama-cpp-python.git

注意根据自己的设备情况,选择 CPU 推理还是 GPU 推理,对应开启硬件加速 FLAG 进行安装 llama-cpp-python :
# 普通安装
# pip install llama-cpp-python# 开启 CUDA 支持(加速推理)
# CMAKE_ARGS="-DGGML_CUDA=on" pip install llama-cpp-python# 指定 CUDA 版本
pip install llama-cpp-python --extra-index-url https://abetlen.github.io/llama-cpp-python/whl/cu124

这里指定 CUDA 版本(高版本向下兼容),如果速度较慢,可以直接复制链接到下载器下载 whl 文件,手动安装:

使用高级 API:
from llama_cpp import Llamallm = Llama(model_path="/home/sam/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B-GGUF/Qwen3-0.6B-Q8_0.gguf",# n_gpu_layers=-1, # Uncomment to use GPU acceleration# seed=1337, # Uncomment to set a specific seed# n_ctx=2048, # Uncomment to increase the context window
)
output = llm("Q: 说出太阳系中的行星的名字 A: ", # Promptmax_tokens=32, # Generate up to 32 tokens, set to None to generate up to the end of the context windowstop=["Q:", "\n"], # Stop generating just before the model would generate a new questionecho=True # Echo the prompt back in the output
) # Generate a completion, can also call create_completion
print(output)
运行报错:conda 环境中 GLIBCXX_3.4.30 not found
Traceback (most recent call last):File "/home/sam/anaconda3/envs/mydev/lib/python3.11/site-packages/llama_cpp/_ctypes_extensions.py", line 67, in load_shared_libraryreturn ctypes.CDLL(str(lib_path), **cdll_args) # type: ignore^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/home/sam/anaconda3/envs/mydev/lib/python3.11/ctypes/__init__.py", line 376, in __init__self._handle = _dlopen(self._name, mode)^^^^^^^^^^^^^^^^^^^^^^^^^
OSError: /home/sam/anaconda3/envs/mydev/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.30' not found (required by /home/sam/anaconda3/envs/mydev/lib/python3.11/site-packages/llama_cpp/lib/libggml-cuda.so)During handling of the above exception, another exception occurred:Traceback (most recent call last):File "/data/PythonWorkspace/PythonProject01/llama.cpp.demo.py", line 1, in <module>from llama_cpp import LlamaFile "/home/sam/anaconda3/envs/mydev/lib/python3.11/site-packages/llama_cpp/__init__.py", line 1, in <module>from .llama_cpp import *File "/home/sam/anaconda3/envs/mydev/lib/python3.11/site-packages/llama_cpp/llama_cpp.py", line 38, in <module>_lib = load_shared_library(_lib_base_name, _base_path)^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "/home/sam/anaconda3/envs/mydev/lib/python3.11/site-packages/llama_cpp/_ctypes_extensions.py", line 69, in load_shared_libraryraise RuntimeError(f"Failed to load shared library '{lib_path}': {e}")
RuntimeError: Failed to load shared library '/home/sam/anaconda3/envs/mydev/lib/python3.11/site-packages/llama_cpp/lib/libllama.so': /home/sam/anaconda3/envs/mydev/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.30' not found (required by /home/sam/anaconda3/envs/mydev/lib/python3.11/site-packages/llama_cpp/lib/libggml-cuda.so)
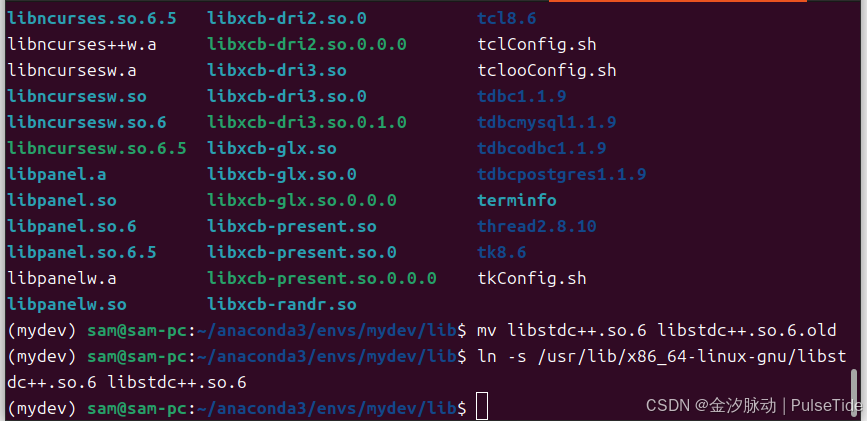
检查系统库:
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX

系统库中有 GLIBCXX_3.4.30,此时只需要修改软链接:
cd /home/sam/anaconda3/envs/mydev/bin/../lib/
mv libstdc++.so.6 libstdc++.so.6.old
ln -s /usr/lib/x86_64-linux-gnu/libstdc++.so.6 libstdc++.so.6
运行效果:
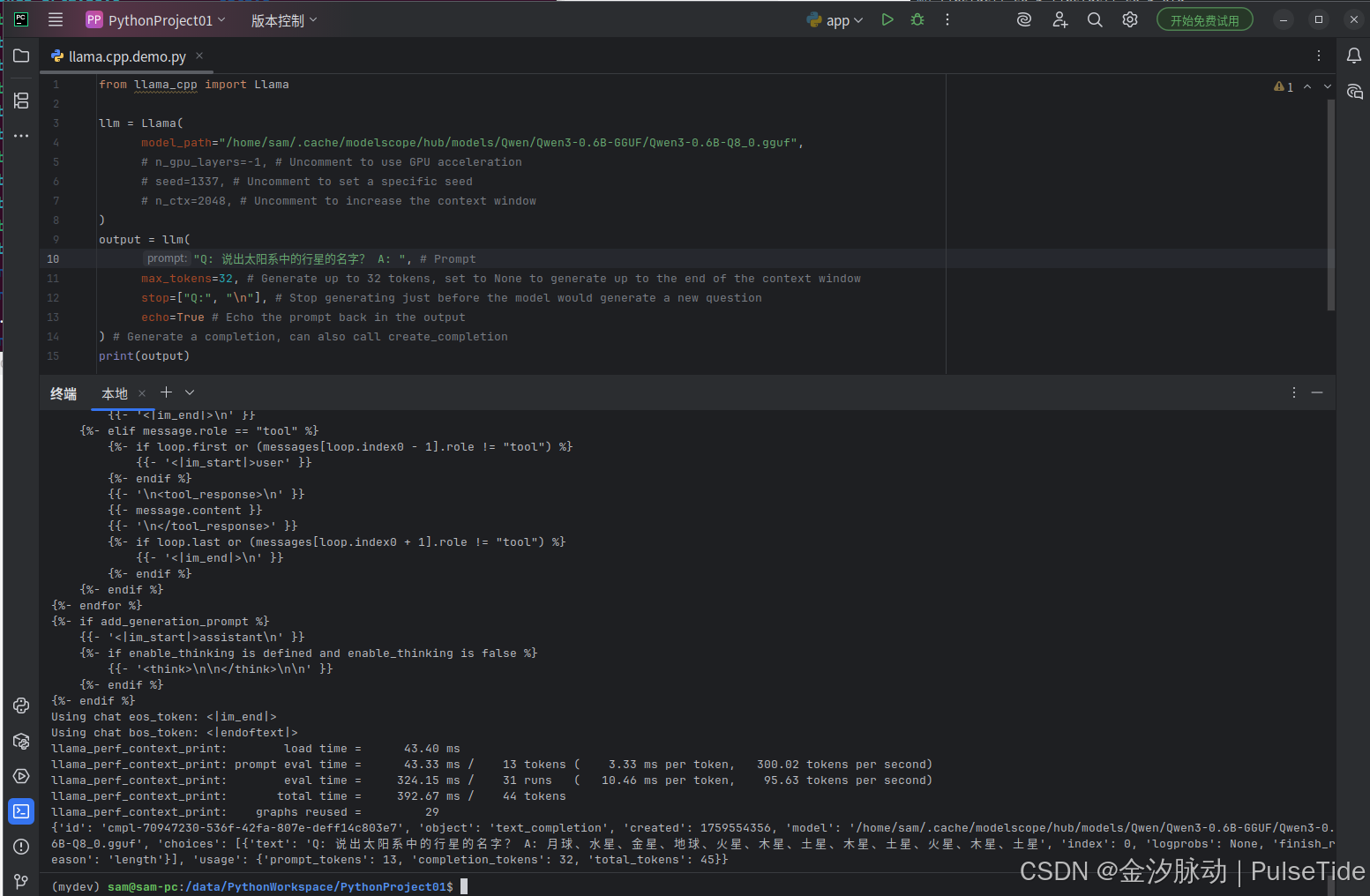
响应格式:
{'id': 'cmpl-70947230-536f-42fa-807e-deff14c803e7', 'object': 'text_completion', 'created': 1759554356, 'model': '/home/sam/.cache/modelscope/hub/models/Qwen/Qwen3-0.6B-GGUF/Qwen3-0.6B-Q8_0.gguf', 'choices': [{'text': 'Q: 说出太阳系中的行星的名字? A: 月球、水星、金星、地球、火星、木星、土星、木星、土星、火星、木星、土星', 'index': 0, 'logprobs': None, 'finish_reason': 'length'}], 'usage': {'prompt_tokens': 13, 'completion_tokens': 32, 'total_tokens': 45}}
2、其他绑定
- Python: ddh0/easy-llama
- Python: abetlen/llama-cpp-python
- Go: go-skynet/go-llama.cpp
- Node.js: withcatai/node-llama-cpp
- JS/TS (llama.cpp server client): lgrammel/modelfusion
- JS/TS (Programmable Prompt Engine CLI): offline-ai/cli
- JavaScript/Wasm (works in browser): tangledgroup/llama-cpp-wasm
- Typescript/Wasm (nicer API, available on npm): ngxson/wllama
- Ruby: yoshoku/llama_cpp.rb
- Rust (more features): edgenai/llama_cpp-rs
- Rust (nicer API): mdrokz/rust-llama.cpp
- Rust (more direct bindings): utilityai/llama-cpp-rs
- Rust (automated build from crates.io): ShelbyJenkins/llm_client
- C#/.NET: SciSharp/LLamaSharp
- C#/VB.NET (more features - community license): LM-Kit.NET
- Scala 3: donderom/llm4s
- Clojure: phronmophobic/llama.clj
- React Native: mybigday/llama.rn
- Java: kherud/java-llama.cpp
- Java: QuasarByte/llama-cpp-jna
- Zig: deins/llama.cpp.zig
- Flutter/Dart: netdur/llama_cpp_dart
- Flutter: xuegao-tzx/Fllama
- PHP (API bindings and features built on top of llama.cpp): distantmagic/resonance (more info)
- Guile Scheme: guile_llama_cpp
- Swift srgtuszy/llama-cpp-swift
- Swift ShenghaiWang/SwiftLlama
- Delphi Embarcadero/llama-cpp-delphi