【AI论文】SLA:通过精细可调的稀疏线性注意力机制突破扩散变换器中的稀疏性局限
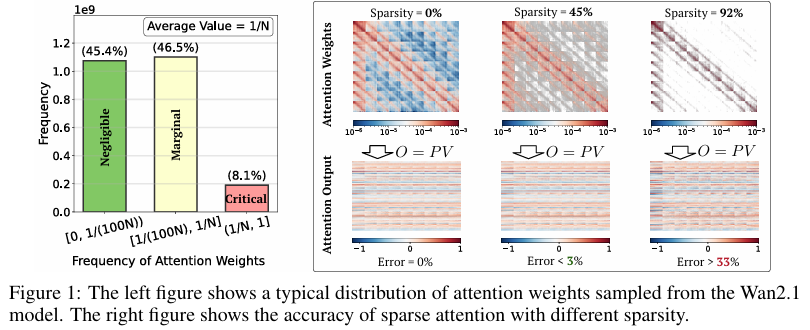
摘要:在扩散变换器(Diffusion Transformer, DiT)模型中,尤其是针对视频生成任务时,由于序列长度较长且注意力机制具有平方复杂度,注意力计算延迟成为主要瓶颈。我们发现注意力权重可自然分解为两部分:占比小但秩高的大权重值,以及其余秩很低的权重值。这自然提示我们可对第一部分采用稀疏加速方法,对第二部分采用低秩加速方法。基于这一发现,我们提出了SLA(稀疏线性注意力,Sparse-Linear Attention)——一种融合稀疏注意力与线性注意力的可训练注意力方法,用于加速扩散模型。SLA将注意力权重分为关键、边缘和可忽略三类,对关键权重采用O(N²)复杂度的注意力计算,对边缘权重采用O(N)复杂度的注意力计算,并跳过可忽略权重。SLA将这些计算整合到单个GPU内核中,并支持前向与反向传播。仅需通过SLA进行少量微调步骤,DiT模型的注意力计算量即可减少20倍,从而在保持生成质量不变的情况下实现显著加速。实验表明,SLA在不影响端到端生成质量的前提下,可将注意力计算量减少95%,性能优于基准方法。此外,我们为SLA实现了高效的GPU内核,在Wan2.1-1.3B模型上,注意力计算速度提升了13.7倍,视频生成的端到端速度提升了2.2倍。Huggingface链接:Paper page,论文链接:2509.24006
研究背景和目的
研究背景:
在视频生成领域,Diffusion Transformer (DiT) 模型因其强大的生成能力而备受关注。然而,随着视频序列长度的增加,注意力机制的计算复杂度呈二次方增长,成为制约模型效率的主要瓶颈。特别是在处理长视频序列时,传统的全注意力机制(Full Attention)因其高计算成本而难以满足实时性要求。尽管已有多种稀疏注意力(Sparse Attention)和线性注意力(Linear Attention)方法被提出以减少计算量,但这些方法在实际应用中仍面临诸多挑战。例如,线性注意力方法在视频生成任务中往往难以保持生成质量,而稀疏注意力方法则难以达到非常高的稀疏度。
研究目的:
本研究旨在提出一种新的注意力机制——SLA(Sparse-Linear Attention),通过融合稀疏注意力和线性注意力,以在保持生成质量的同时显著降低计算复杂度。
具体目标包括:
- 减少计算复杂度:通过将注意力权重分为关键、边缘和可忽略三类,对关键权重应用稀疏注意力,对边缘权重应用线性注意力,并跳过可忽略权重,从而显著降低计算复杂度。
- 保持生成质量:在减少计算量的同时,确保生成视频的质量不受影响,甚至在某些情况下有所提升。
- 提高训练效率:通过设计高效的GPU内核和训练策略,使得SLA能够在少量微调步骤内快速适应新任务。
研究方法
1. 注意力权重分类:
SLA的核心思想是将注意力权重分为三类:关键权重、边缘权重和可忽略权重。关键权重具有高值和高秩,对生成结果影响显著;边缘权重具有较低的值和低秩,对生成结果有一定影响;可忽略权重则接近于零,对生成结果影响极小。
通过这种分类,SLA能够针对不同类别的权重应用不同的注意力机制。
2. 稀疏注意力与线性注意力融合:
对于关键权重,SLA使用稀疏注意力(如FlashAttention)进行计算,确保高精度;对于边缘权重,SLA使用线性注意力进行计算,以降低计算复杂度;对于可忽略权重,SLA直接跳过计算。通过将稀疏注意力和线性注意力融合到一个统一的框架中,SLA能够在保持生成质量的同时显著降低计算量。
3. 高效GPU内核实现:
为了进一步提高计算效率,SLA实现了一个高效的GPU内核,该内核能够同时处理稀疏注意力和线性注意力的计算。
通过优化内存访问模式和并行计算策略,SLA的GPU内核在注意力计算上实现了显著的加速。
4. 训练策略:
SLA采用少量微调步骤的训练策略,即在预训练模型的基础上,仅使用少量数据进行微调即可达到较好的性能。
这种训练策略不仅减少了训练时间,还降低了对大规模标注数据的依赖。
研究结果
1. 计算复杂度降低:
实验结果表明,SLA能够显著降低注意力机制的计算复杂度。
在Wan2.1-1.3B模型上,SLA实现了95%的注意力计算减少,同时保持了视频生成质量。与全注意力机制相比,SLA在注意力计算上实现了20倍的减少,在端到端视频生成上实现了2.2倍的加速。
2. 生成质量保持:
在多个视频生成基准测试中,SLA生成的视频质量与全注意力机制生成的视频质量相当,甚至在某些情况下有所提升。
例如,在VBench评估维度上,SLA生成的视频在成像质量、整体一致性、美学质量和主题一致性等方面均达到了较高水平。
3. 训练效率提高:
通过少量微调步骤的训练策略,SLA能够在短时间内快速适应新任务。
在Wan2.1-1.3B模型上,仅使用2000个微调步骤即可达到较好的性能,显著减少了训练时间和计算资源消耗。
4. 与基线方法的比较:
与现有的稀疏注意力方法和线性注意力方法相比,SLA在计算复杂度和生成质量之间取得了更好的平衡。例如,与VSA和VMoBa等稀疏注意力方法相比,SLA在保持较高生成质量的同时实现了更高的稀疏度;与仅使用线性注意力的方法相比,SLA在生成质量上具有明显优势。
研究局限
1. 特定模型架构的依赖:
SLA的研究主要基于Wan2.1-1.3B模型进行验证,其性能可能受到模型架构的影响。
在不同模型架构上应用SLA时,可能需要调整超参数或重新设计注意力权重分类策略。
2. 参数选择的敏感性:
SLA的性能对超参数的选择较为敏感,如关键权重和边缘权重的比例、块大小等。
不合适的超参数选择可能导致生成质量下降或计算复杂度增加。因此,在实际应用中需要仔细调整超参数以获得最佳性能。
3. 长序列处理的挑战:
尽管SLA在中等长度视频序列上表现良好,但在处理极长视频序列时仍面临挑战。随着序列长度的增加,注意力权重的分类和计算可能变得更加复杂和耗时。因此,如何进一步优化SLA以处理极长视频序列是一个值得研究的问题。
未来研究方向
1. 扩展到其他生成任务:
未来的研究可以将SLA扩展到其他生成任务,如文本生成、图像生成等。
通过调整注意力权重分类策略和计算方法,SLA有望在其他生成任务中实现类似的计算复杂度降低和生成质量保持。
2. 结合其他优化技术:
SLA可以与其他优化技术相结合,如量化、剪枝等,以进一步降低模型计算复杂度和内存消耗。
通过综合运用多种优化技术,可以进一步提高SLA在实际应用中的效率和性能。
3. 探索自适应注意力权重分类:
当前的SLA方法使用固定的阈值进行注意力权重分类,未来的研究可以探索自适应的注意力权重分类策略。通过根据输入序列的特征动态调整阈值,可以进一步提高SLA的适应性和鲁棒性。
4. 应用到实际场景中:
最终,未来的研究可以将SLA应用到实际场景中,如视频编辑、虚拟现实等。
通过在实际场景中验证SLA的有效性和实用性,可以进一步推动其在视频生成领域的应用和发展。