Transformer 模型知识点及详细内容
Transformer 模型知识点及详细内容

-
Transformer 模型概述
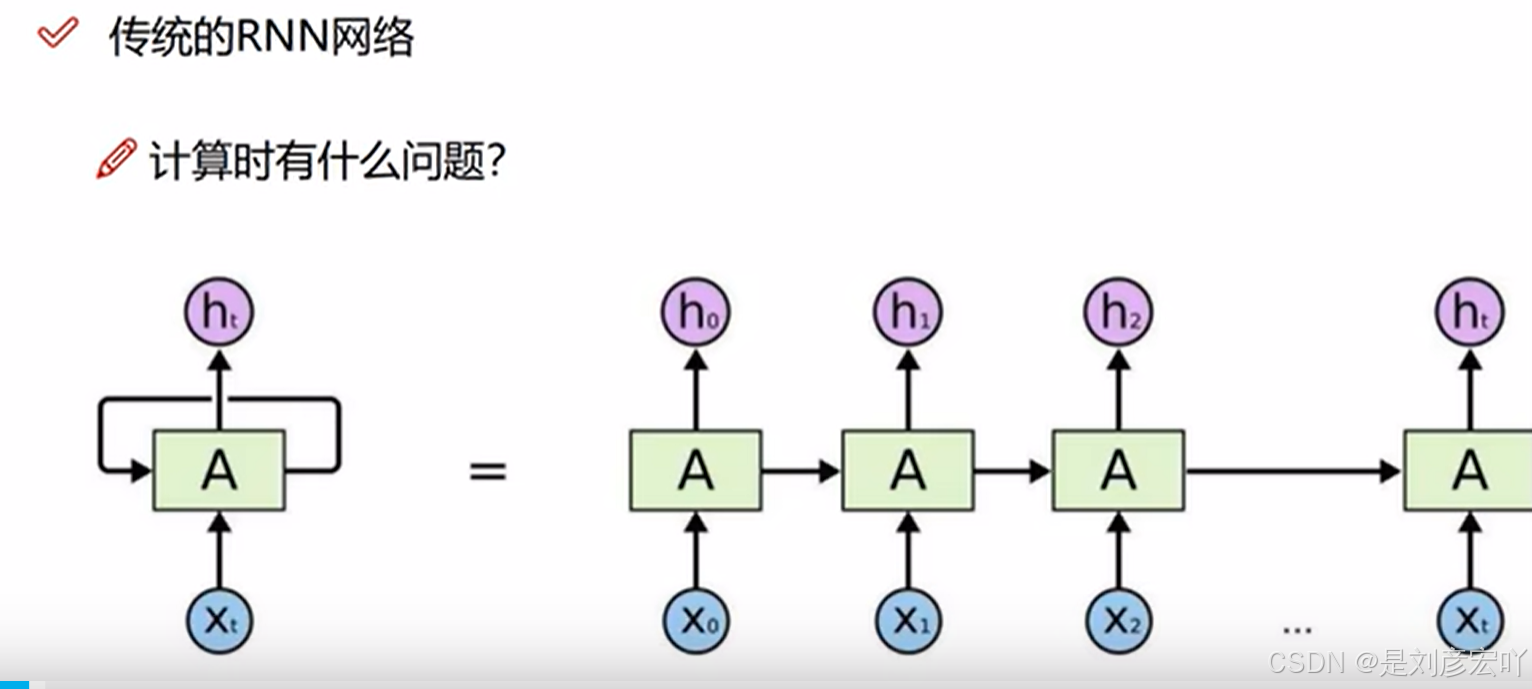
- 提出背景:2017年Google在论文《Attention is All You Need》中提出,用Self-Attention结构取代RNN,支持并行计算。
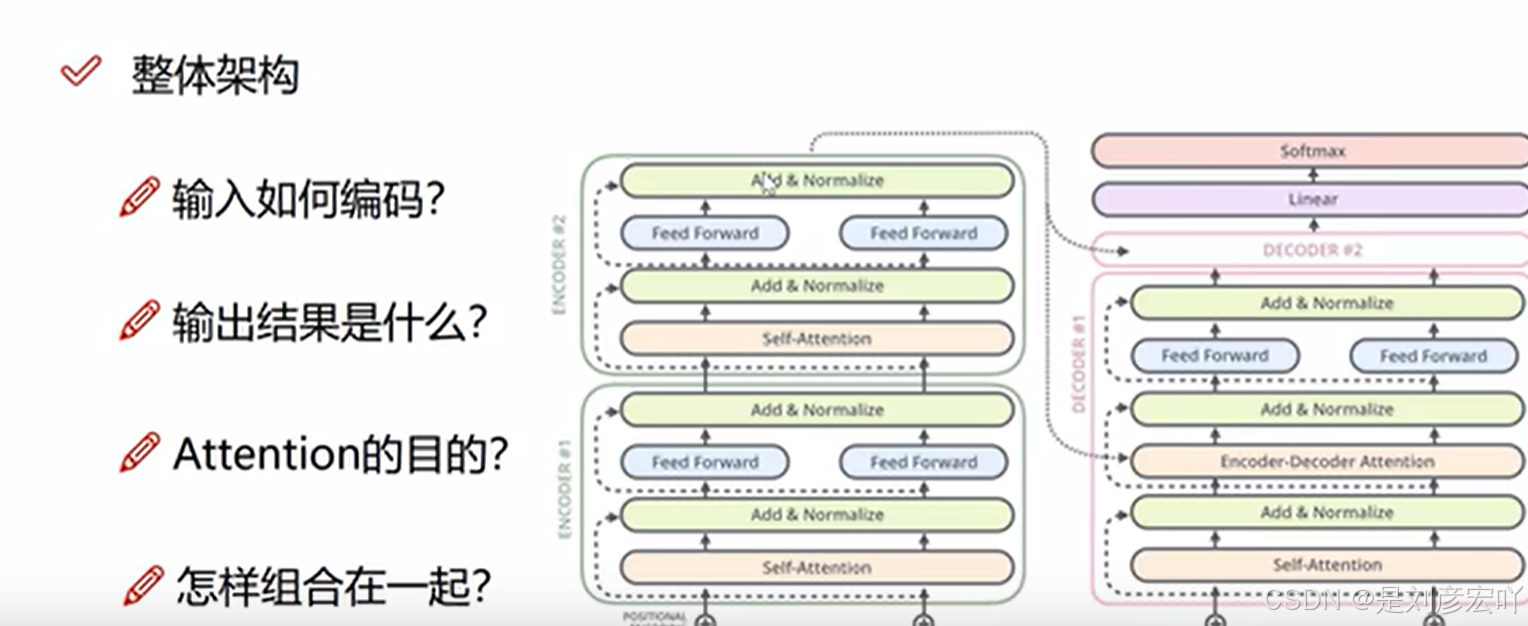
- 核心架构:Encoder-Decoder结构,编码器和解码器均由多层堆叠组成(论文中使用6层)。
- 核心优势:并行计算能力、长距离依赖捕捉能力强。
-
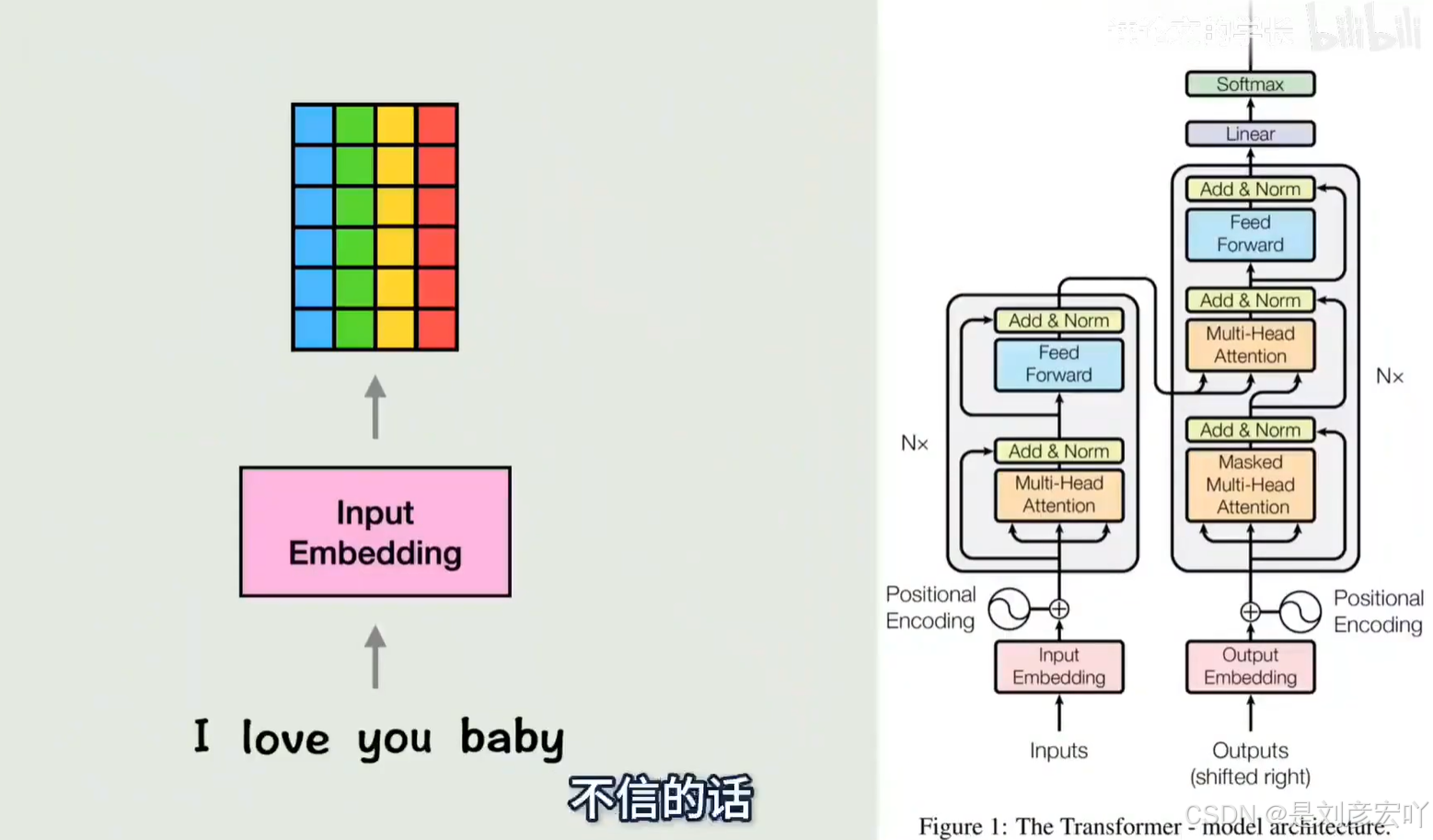
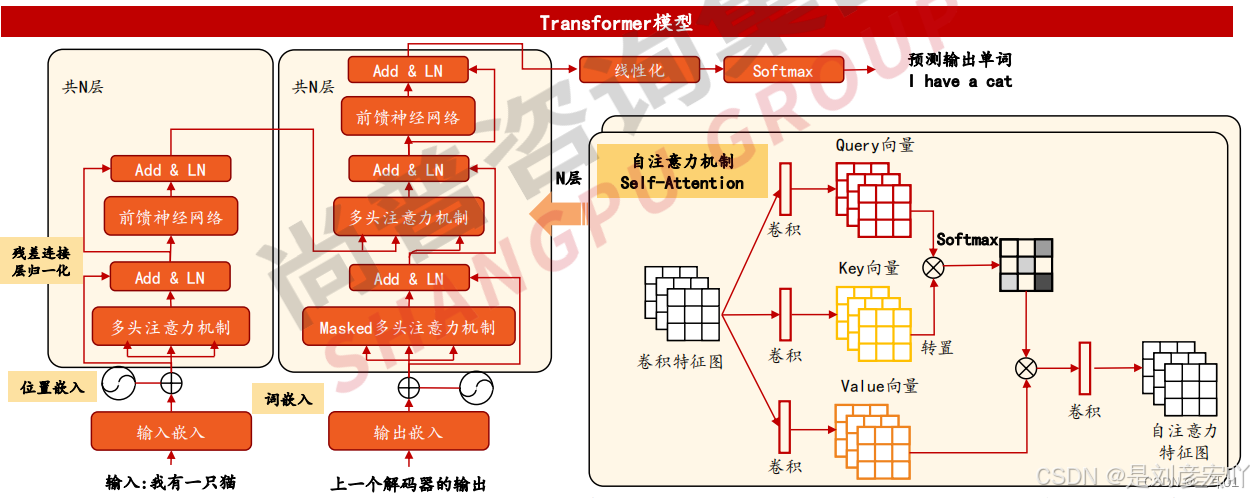
Encoder-Decoder 架构
- 编码组件(Encoder):
- 由多层编码器堆叠(如6层),每层结构相同但参数独立。
- 每层包含两个子层:
- Self-Attention层:计算输入序列中所有词之间的关系。
- 前馈神经网络(FFN):全连接层,逐位置独立处理。
- 解码组件(Decoder):
- 结构与编码器类似,但额外增加Encoder-Decoder Attention层(关注编码器输出)。
- 每层包含三个子层:
- Masked Self-Attention层:防止未来信息泄露。
- Encoder-Decoder Attention层:基于编码器输出的Key-Value对计算注意力。
- 前馈神经网络(FFN)。
- 编码组件(Encoder):
-
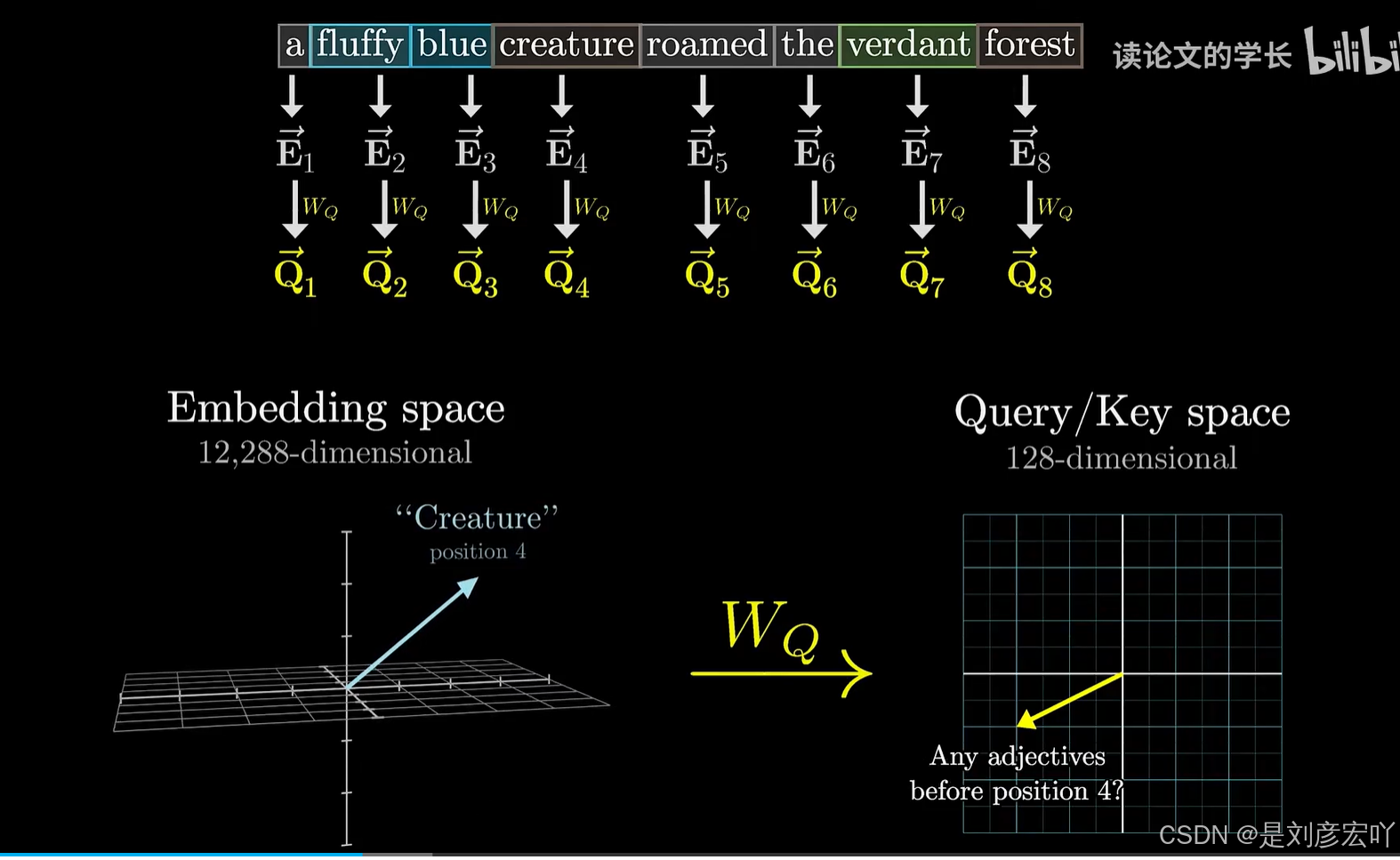
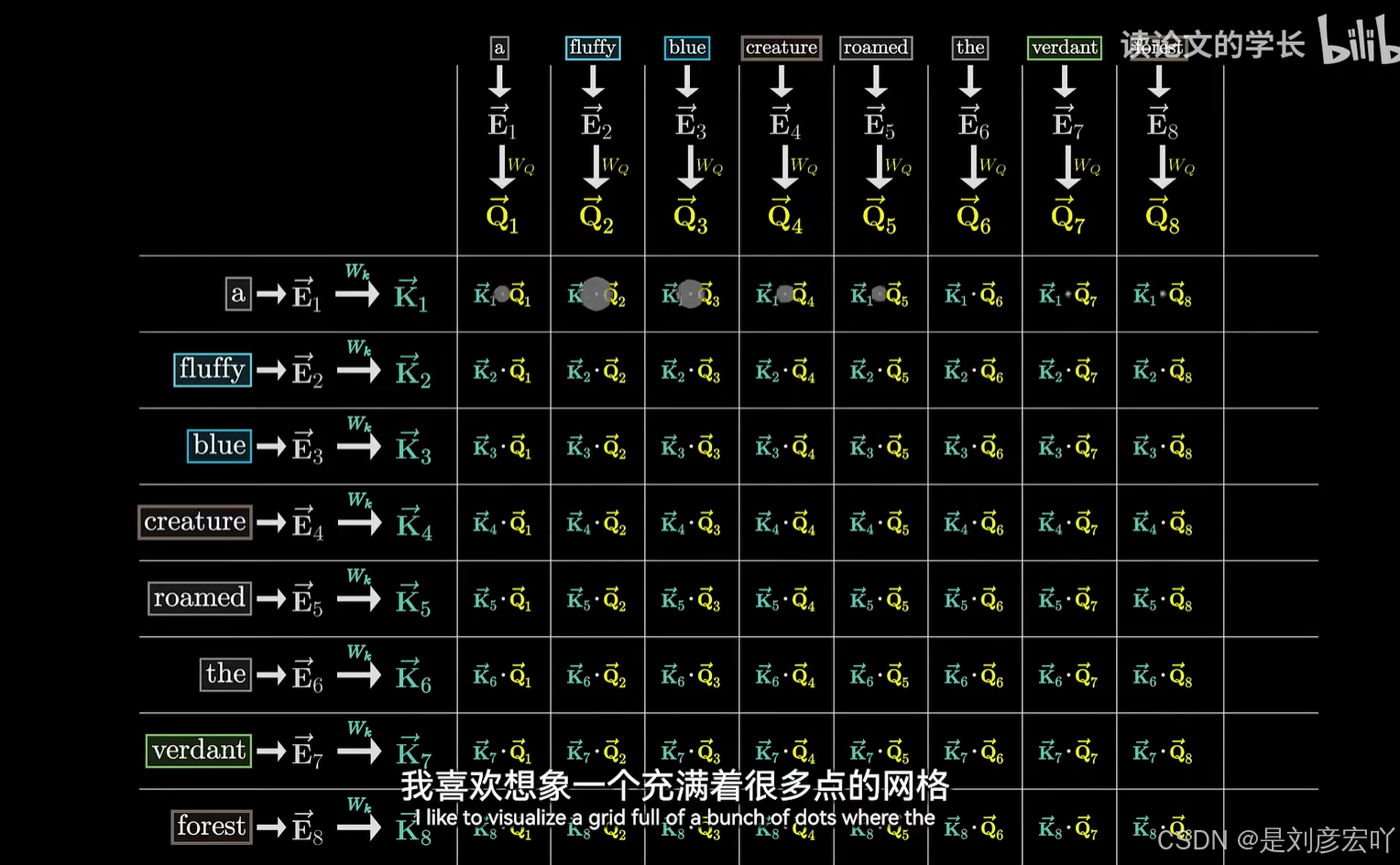
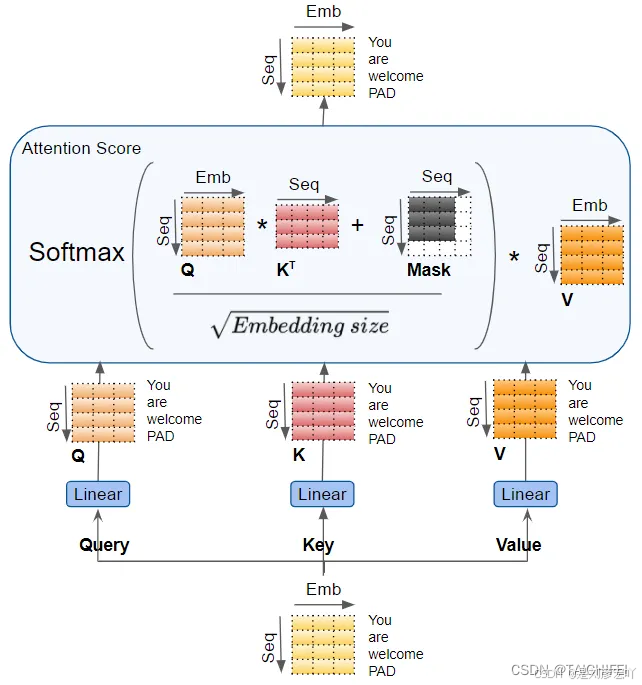
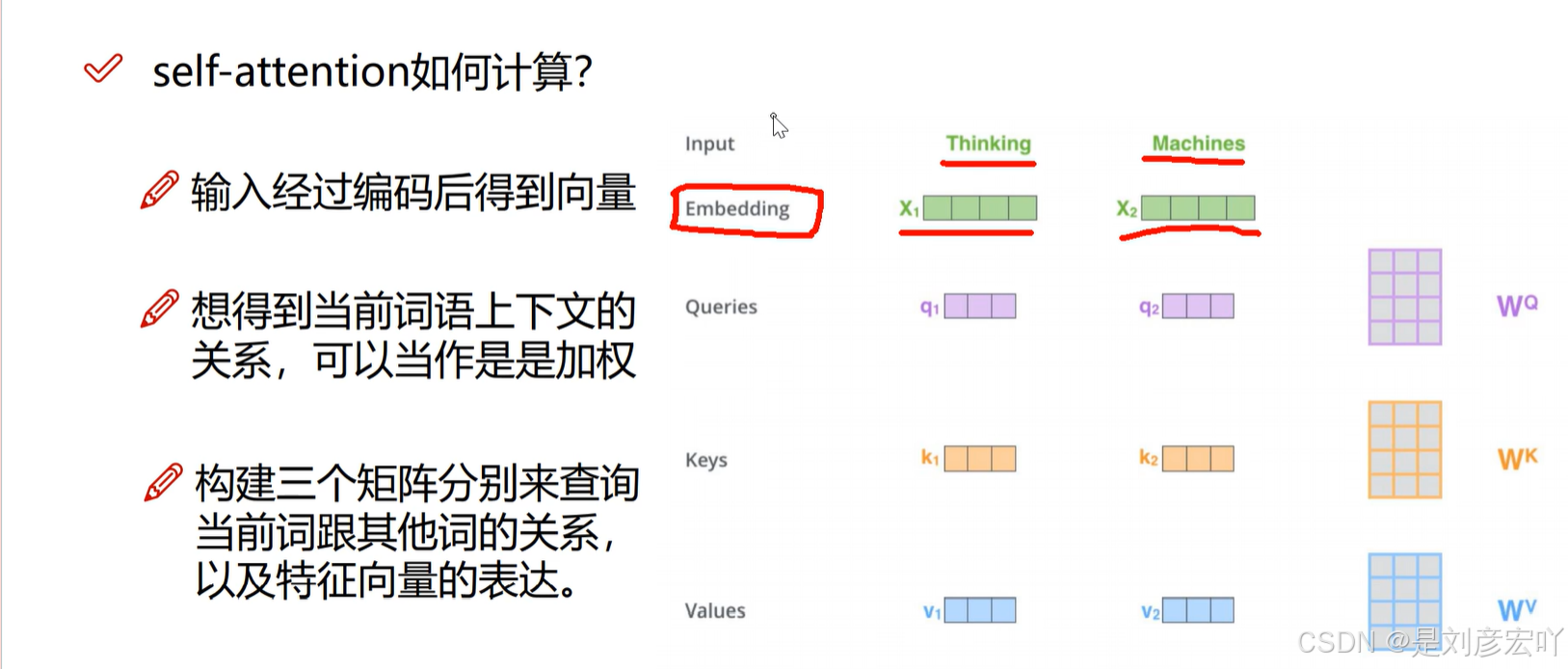
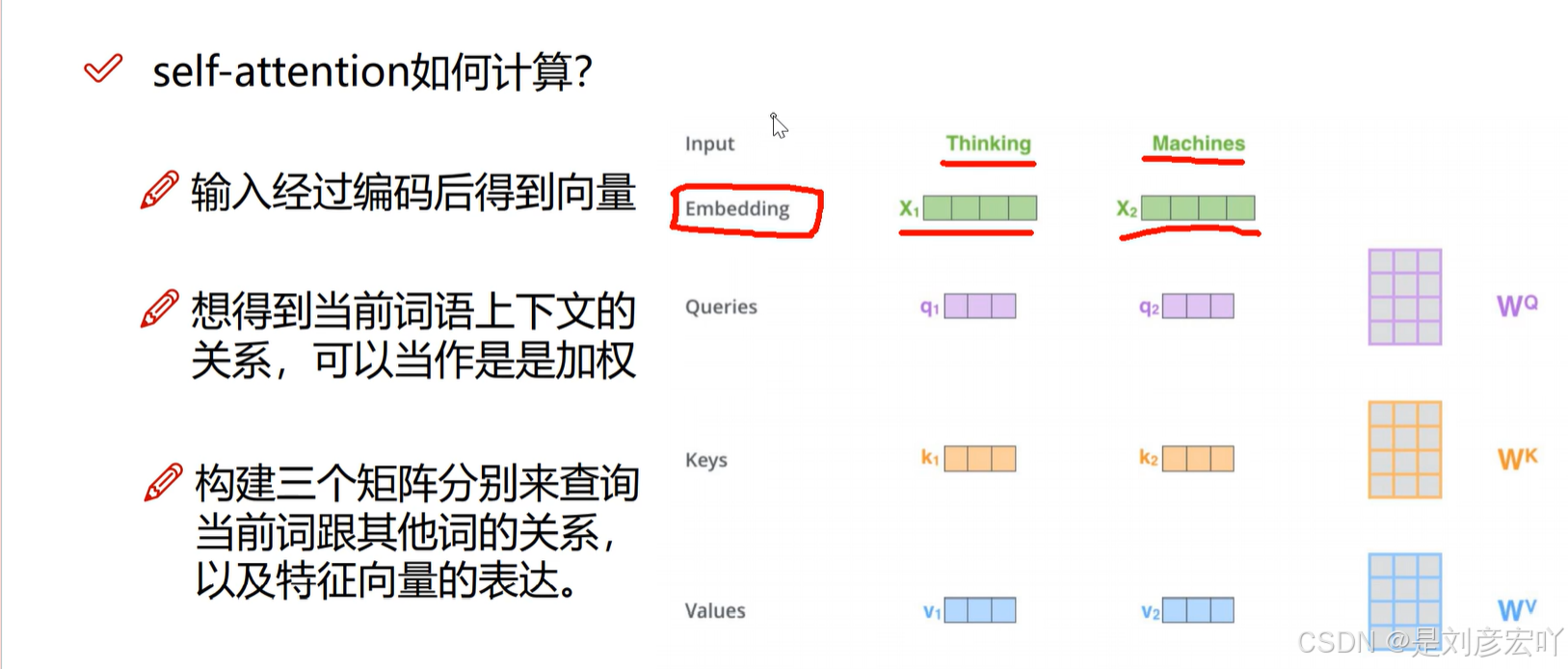
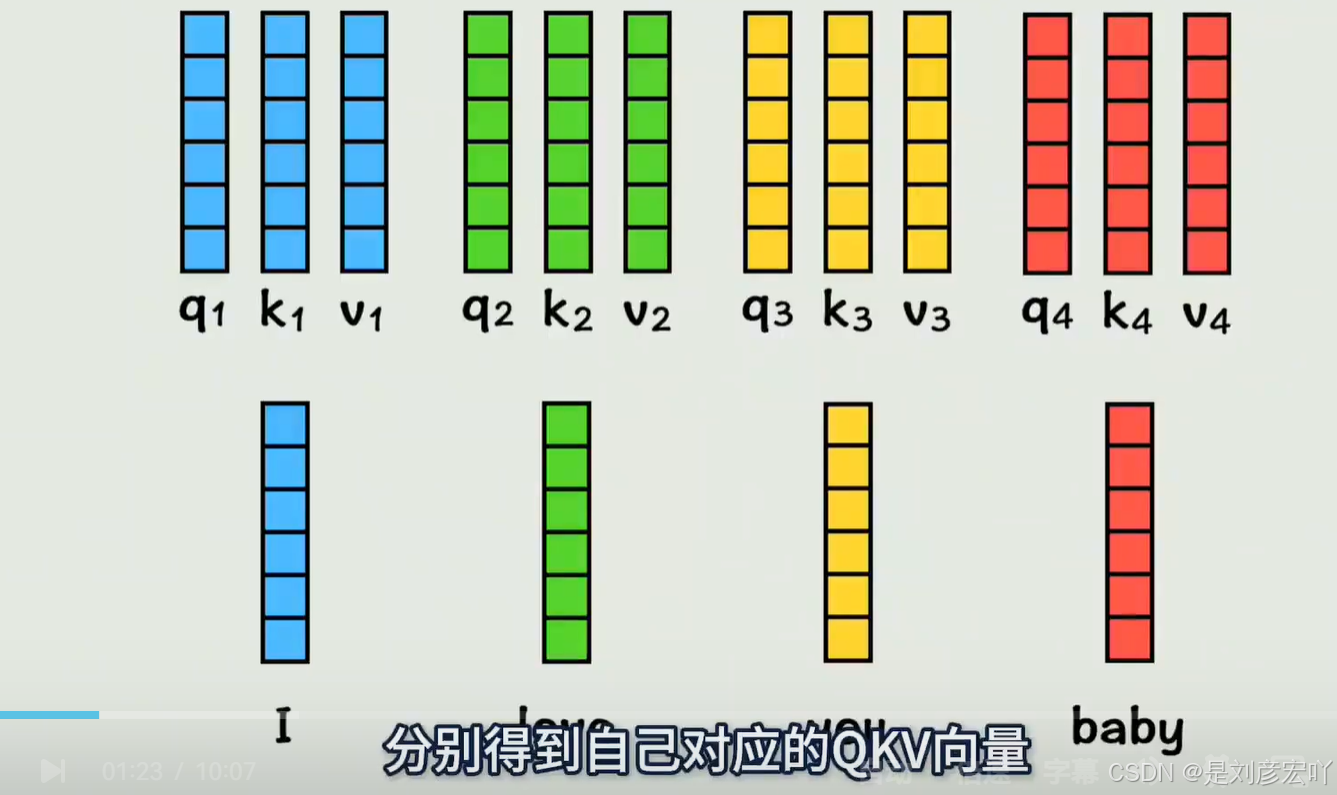
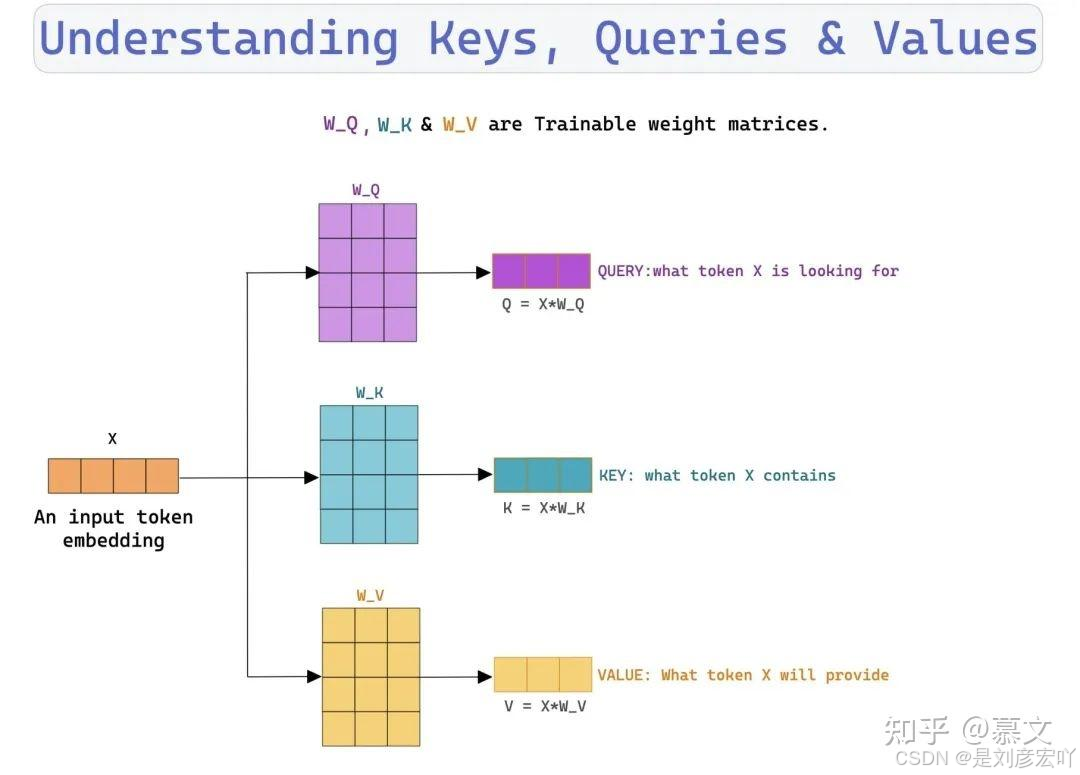
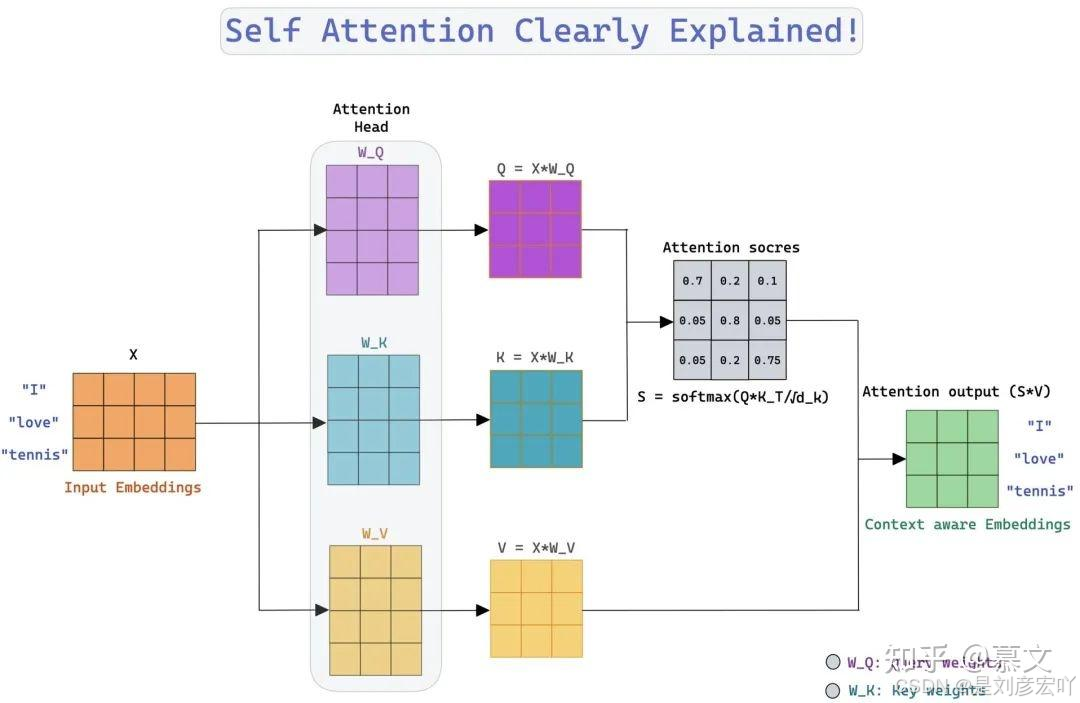
Self-Attention 机制
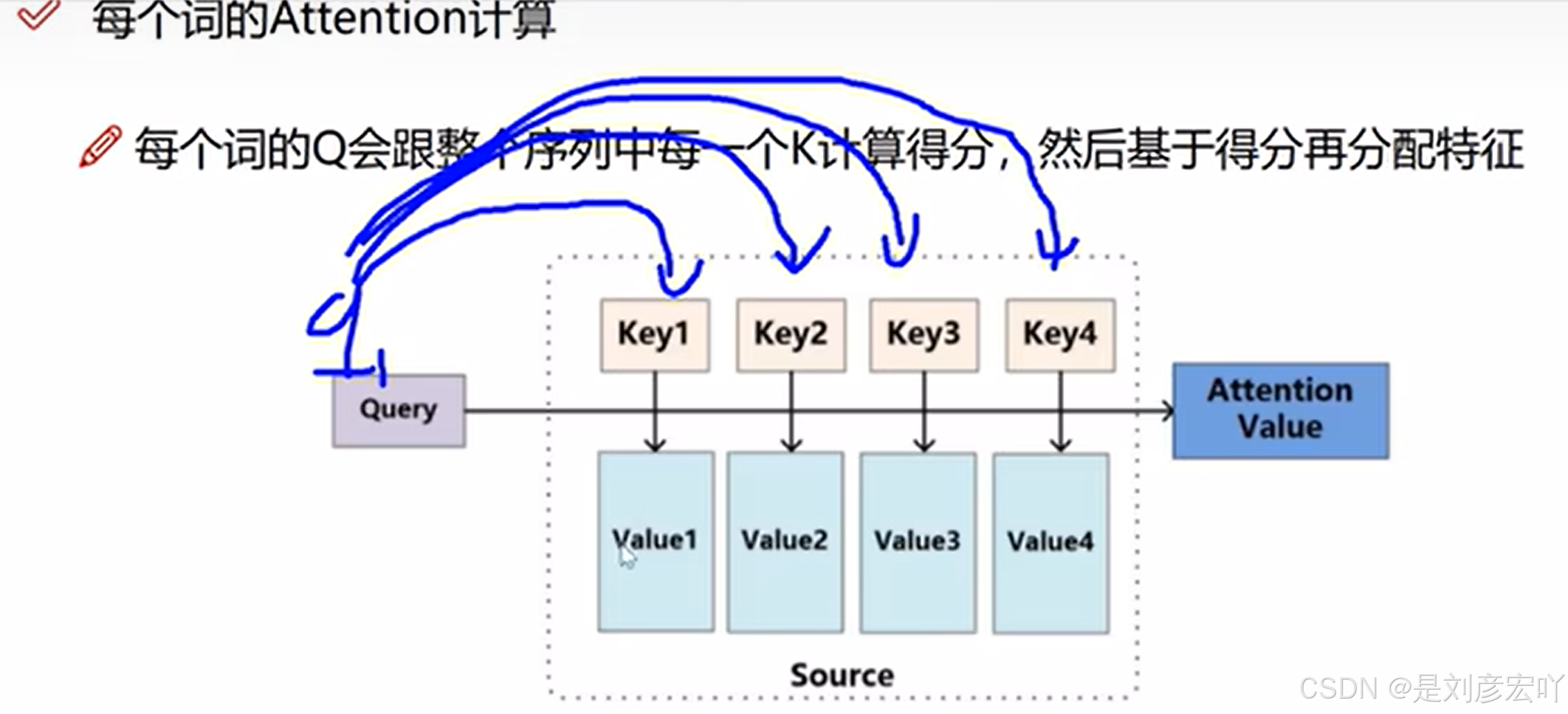
- 核心概念:
- Query (Q)、Key (K)、Value (V):均来自同一输入,通过线性变换得到。
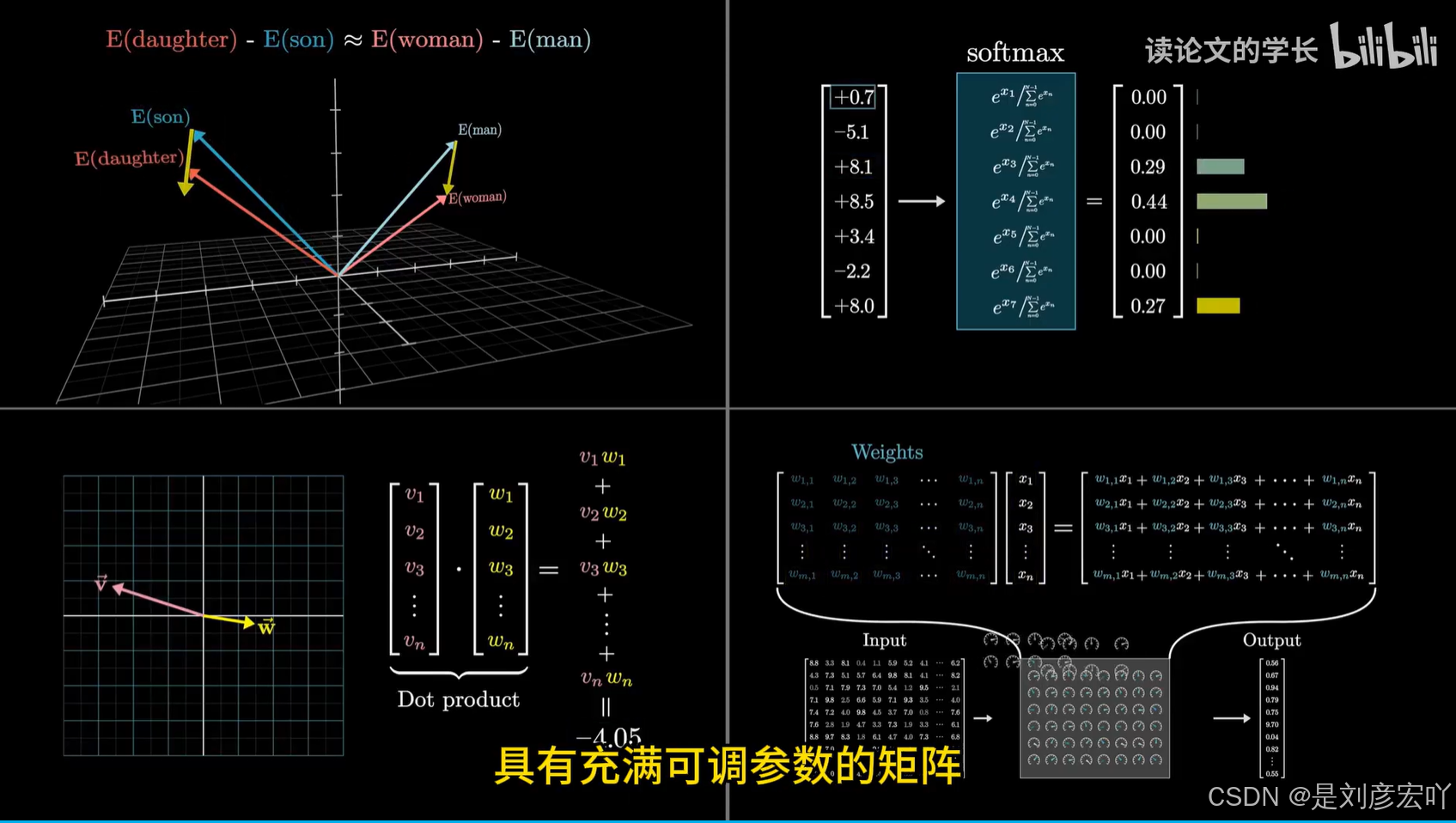
- 计算步骤:
- 计算Q与K的点积,缩放后得到注意力分数。
- 通过Softmax归一化为概率分布。
- 加权求和V向量,得到输出。
- 公式:
[
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
] - 示例:
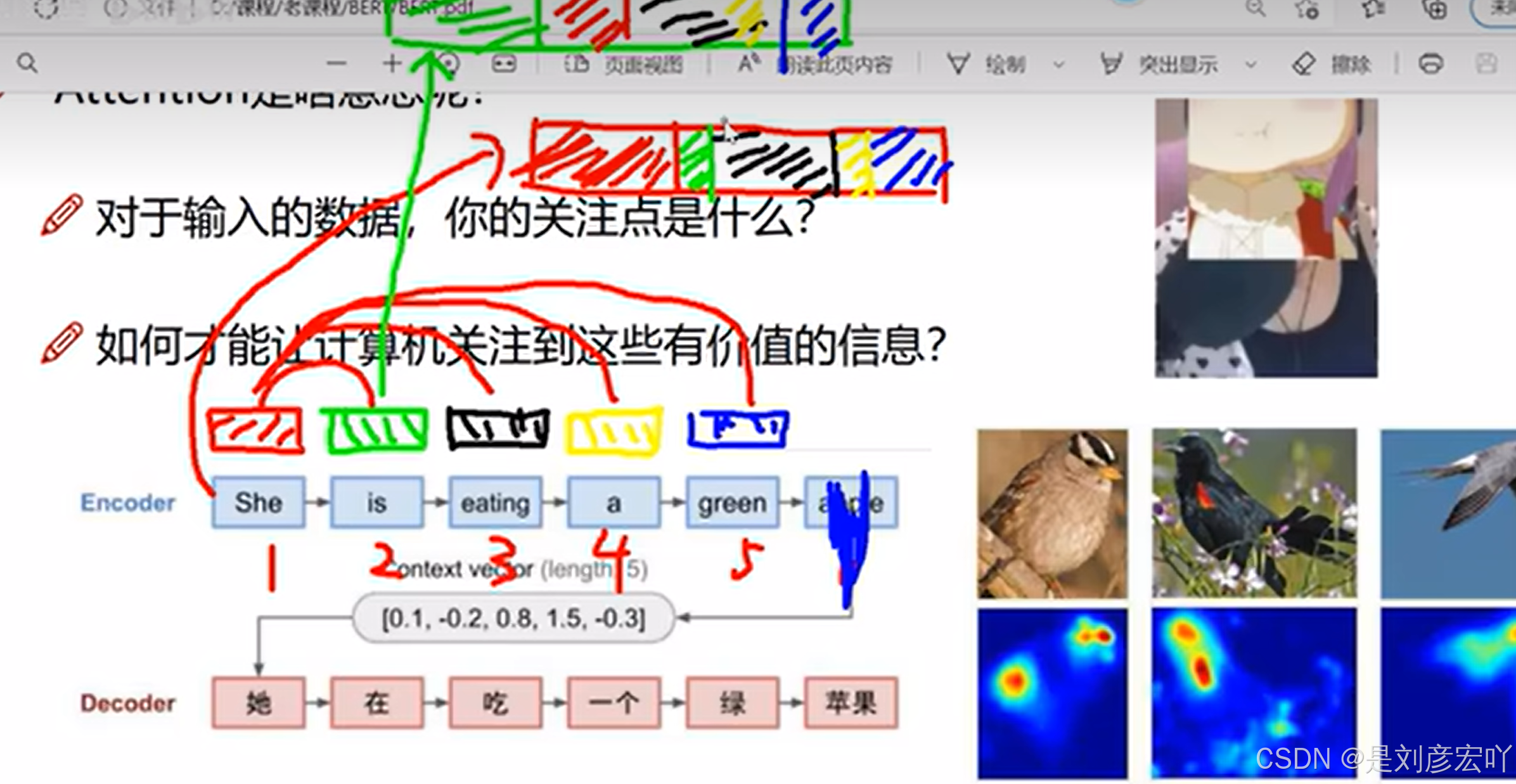
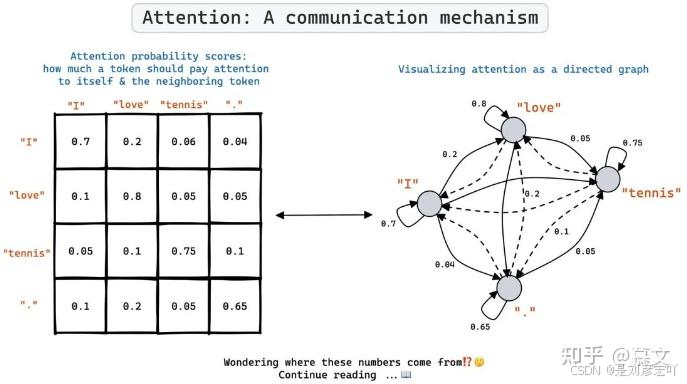
- 句子“The animal didn’t cross the street because it was too tired”中,“it”通过Self-Attention与“animal”关联。
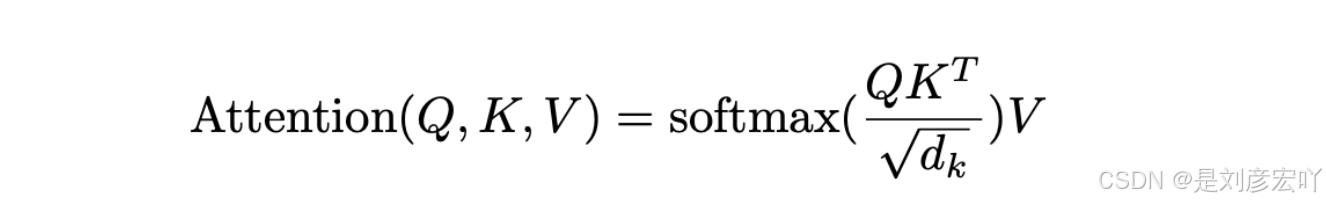


- 核心概念:
-
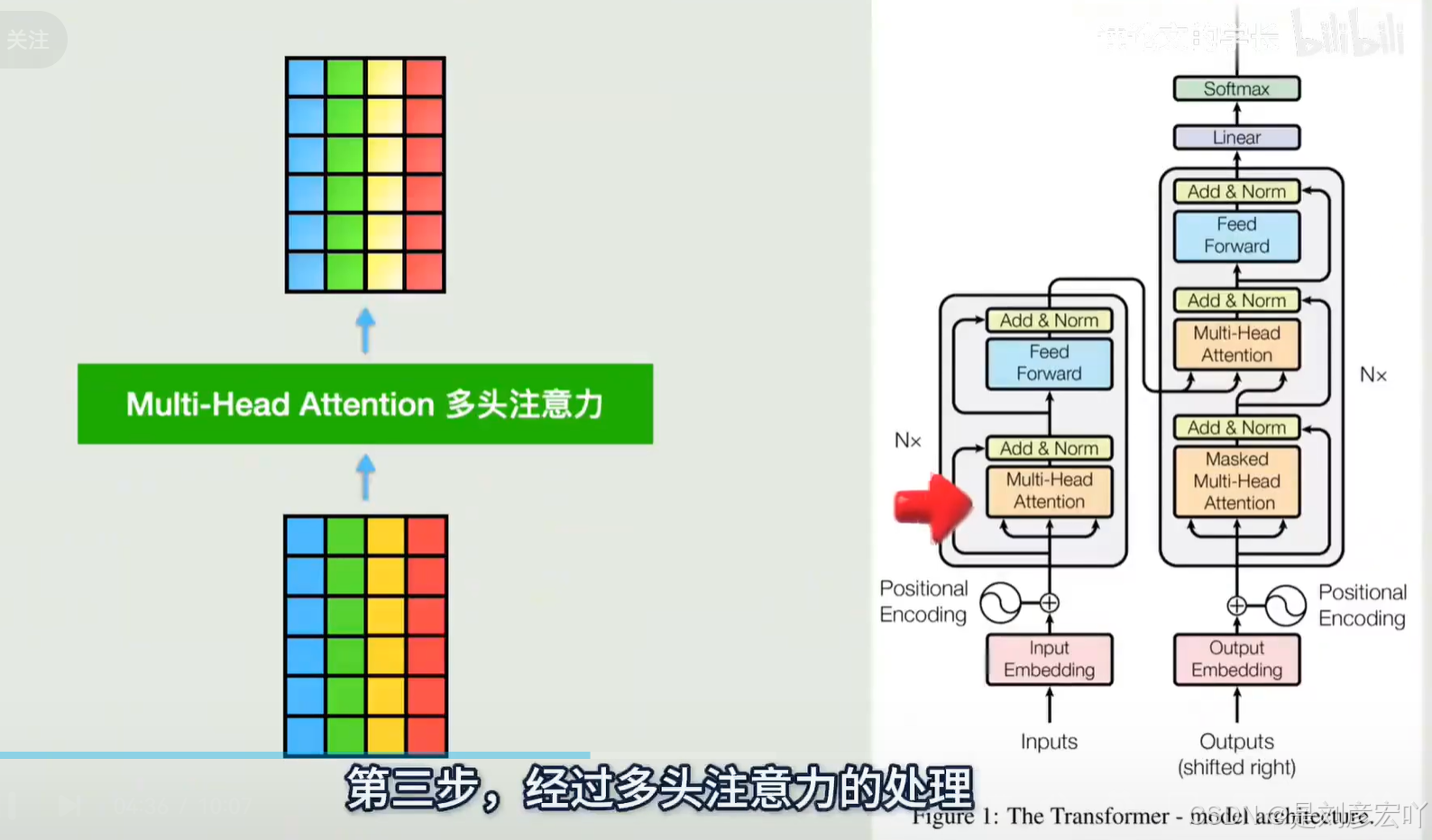
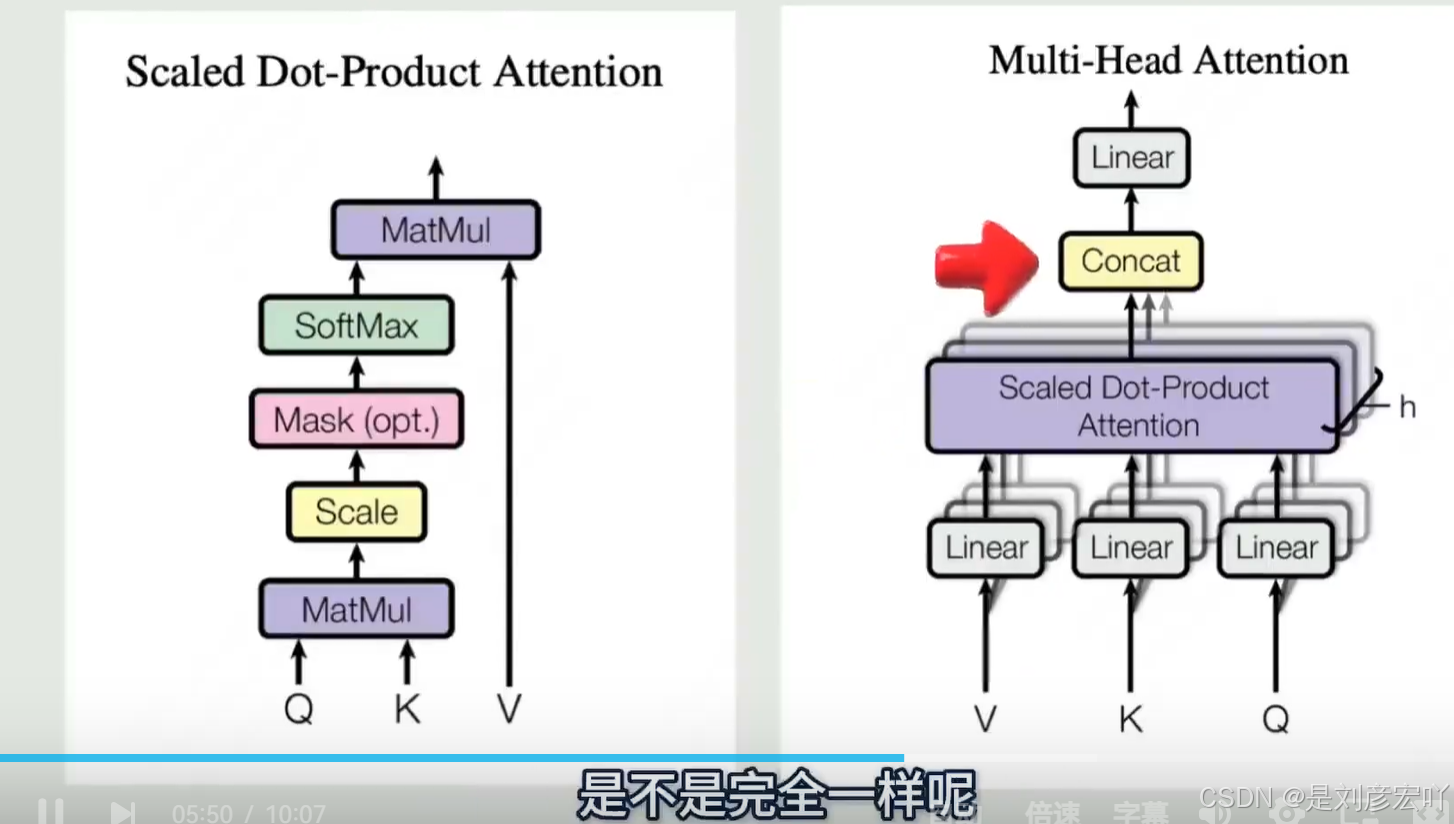
多头注意力(Multi-Head Attention)
- 原理:将Q、K、V分别映射到多个子空间(如8个头),独立计算注意力后拼接。
- 优点:
- 捕捉不同子空间的关联关系(如语法、语义)。
- 防止过拟合(参数总量不变,维度降低)。
- 公式:
[
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, …, \text{head}_h)W^O
]
其中,(\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V))。
-
位置前馈网络(Position-wise FFN)
- 结构:两个全连接层,中间用ReLU激活。
- 公式:
[
\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2
] - 特点:逐位置独立计算,输入输出维度相同(如512)。
-
残差连接与层归一化
- 残差连接:每子层输出为( \text{LayerNorm}(x + \text{Sublayer}(x)) ),缓解梯度消失。
- 层归一化:对每个样本的特征维度归一化(区别于BatchNorm)。
-
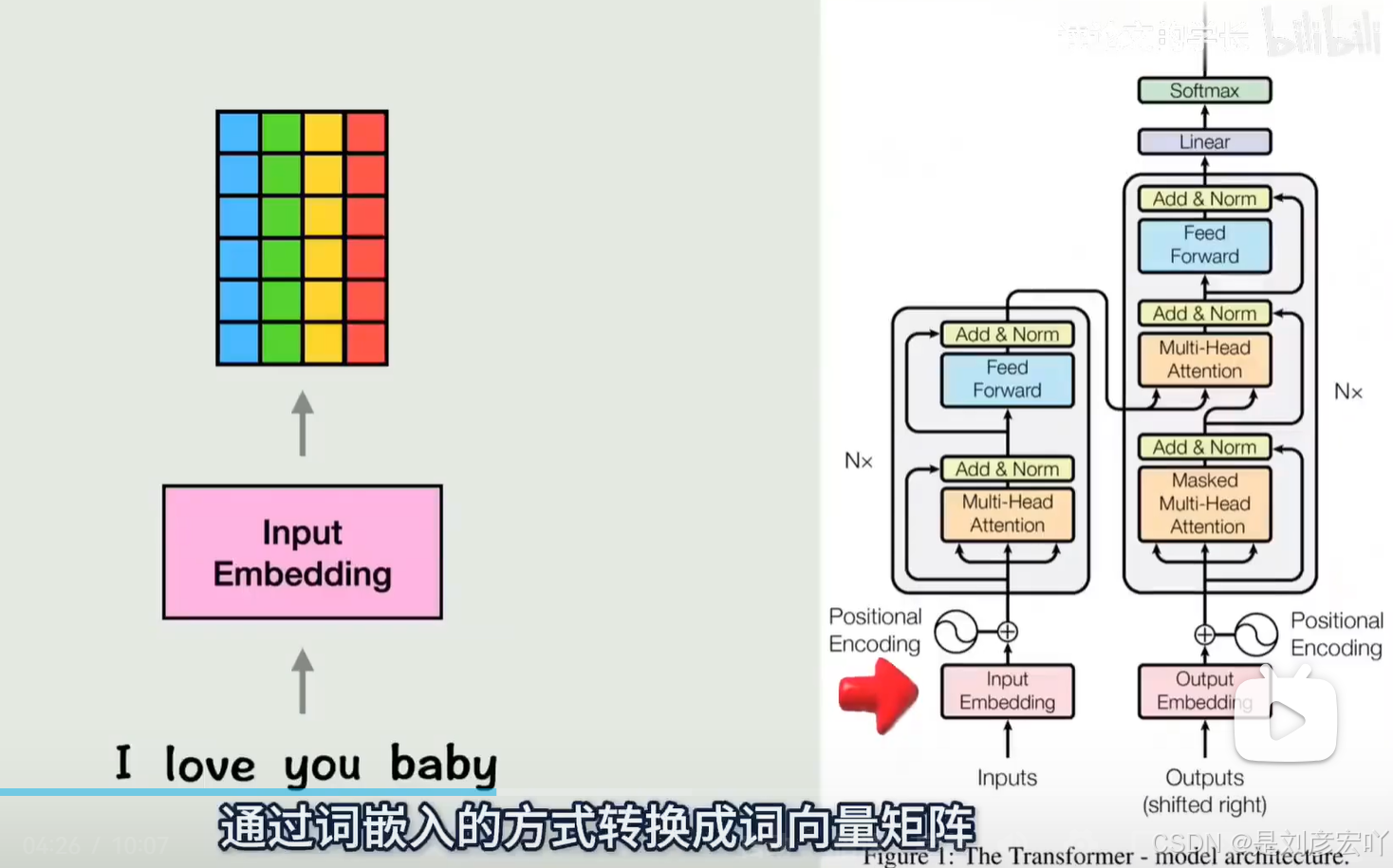
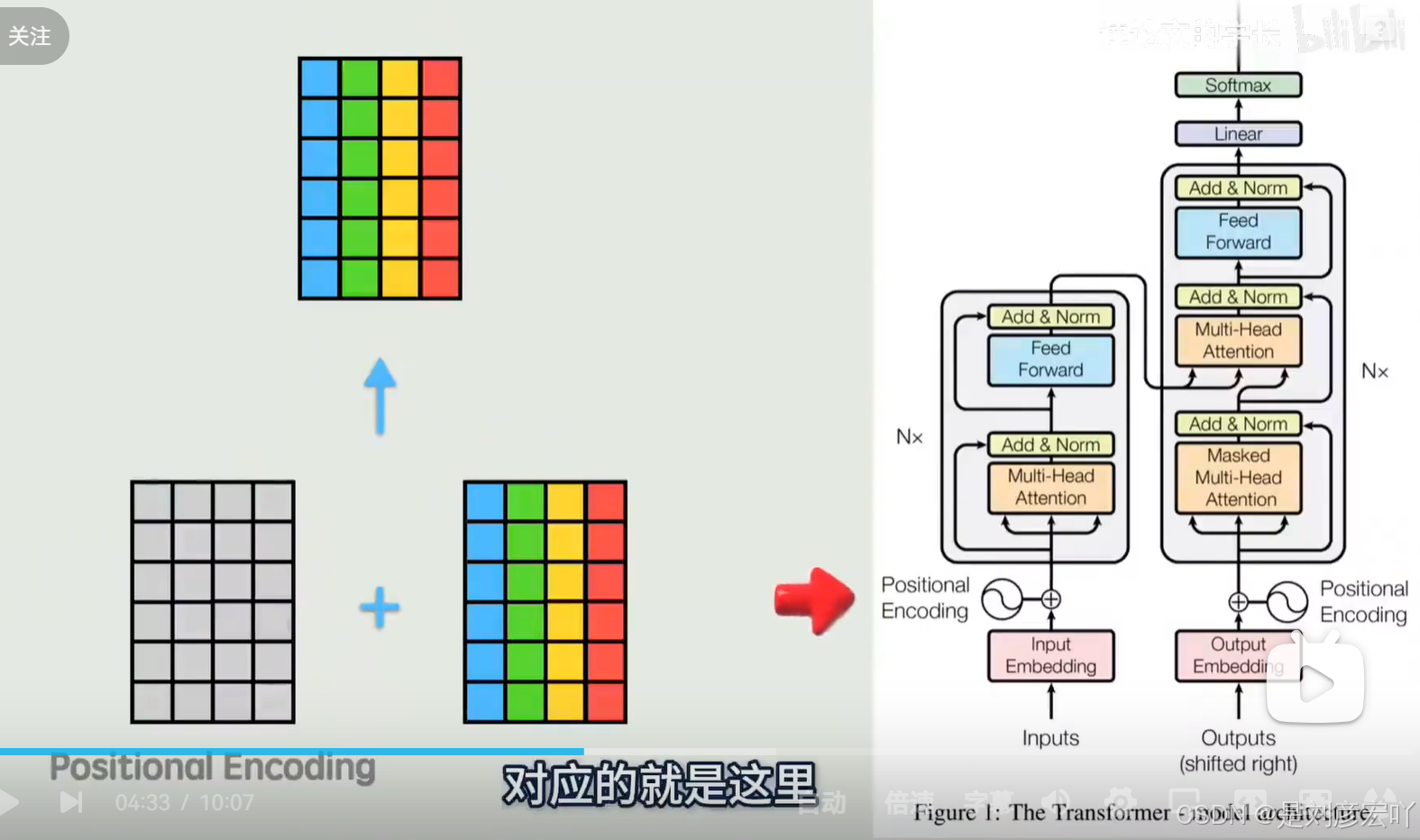
位置编码(Positional Encoding)
- 作用:为输入序列添加位置信息,弥补Self-Attention的无序性。
- 公式:
[
PE_{(pos, 2i)} = \sin(pos/10000^{2i/d_{\text{model}}}) \
PE_{(pos, 2i+1)} = \cos(pos/10000^{2i/d_{\text{model}}})
] - 特点:可处理任意长度序列,无需训练(固定模式)。
-
Mask 机制
- Padding Mask:遮盖无效填充位置(如短序列补零部分),避免Softmax关注无意义位置。
- Sequence Mask:解码器中防止未来信息泄露(上三角矩阵掩码)。
-
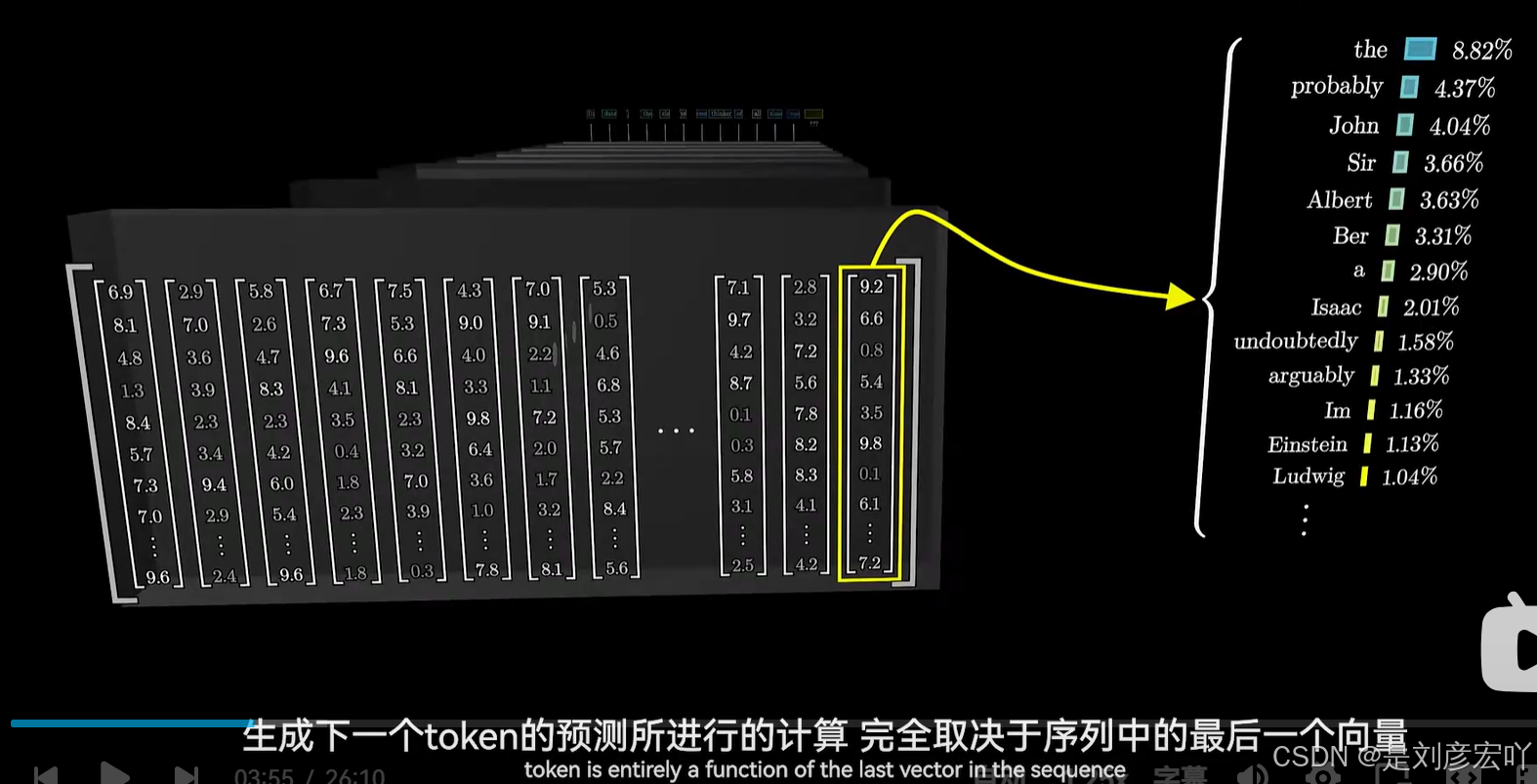
输出层(Linear + Softmax)
- 流程:
- 线性层将解码器输出映射到词汇表大小的logits向量。
- Softmax转换为概率分布,选择最高概率词作为输出。
- 流程:
-
关键图示与示例
- 图1.1:整体架构图(Encoder-Decoder堆叠)。
- 图1.10:Self-Attention可视化(“it”关注“animal”)。
- 图1.18:多头注意力拼接过程。
- 图1.26:残差连接与层归一化流程。
- 参数配置
- 词向量维度((d_{\text{model}})):512。
- 多头注意力头数((h)):8,每个头的维度((d_k = d_v = 64))。
- FFN隐藏层维度:2048。
总结
Transformer的核心创新在于Self-Attention机制和多头注意力,摒弃了RNN的序列依赖,实现了并行化与长距离依赖的高效捕捉。其模块化设计(如残差连接、层归一化)提升了训练稳定性,位置编码解决了序列顺序问题。这些特性使其成为NLP领域的基础模型架构(如BERT、GPT的基石)。
最新动画讲解教程,一步一步深入浅出解释Transformer原理