福州网站建设加q479185700免费网站建站平台
- textRank的工具包实现
- 其他可能的实现方法,对比结果
- 查找分类的相关算法
目录
1. 关键词提取TF-IDF + TextRank
1.1. TF-IDF算法
1.2. TextRank算法
1.3. 双算法提取关键词
2. 问题分类
2.1. 预处理
2.2. 获取BERT向量
2.3. 一级标签预测
2.4. 二级标签预测
3. 测试
3.1. 关键词匹配度未发挥作用
3.2. 预测结果对比表
1. 关键词提取TF-IDF + TextRank
1.1. TF-IDF算法
是一种统计方法,评估一个词语在文档中的重要程度。
TF-IDF 值
- TFIDF(t,d,D)=TF(t,d)×IDF(t,D)
- TF(词频)
- 词语在当前文档中出现的频率,高频词重要
- TF(t,d)=词语 t 在文档 d 中出现的次数 / 文档d的总词数
- IDF(逆文档频率)
- 词语在整个语料库中的稀有程度,全局重要性,语料库中出现越少的词权重越高,稀有词区分度高
- IDF(t,D)=log(语料库中文档总数 N / (包含词语 t 的文档数+1))
- 加1避免分母为零
缺点
- 忽略语义:无法捕捉词语间的语义关系(如"深度学习"和"神经网络"的关联)、同义词
- 稀疏性问题:长尾词可能被过度加权
- 依赖语料库:受限于训练语料的覆盖范围,专业领域新词可能权重异常
1.2. TextRank算法
特点:
- 图模型:将文本转化为图结构,词语为节点,关系为边
- 迭代计算:基于PageRank思想,通过投票机制计算节点重要性
- 上下文感知:考虑词语的局部窗口共现关系
优点:
- 语义感知:能捕捉词语间的关联性,如"机器学习"和"算法"
- 无需训练:直接处理单文档,适合动态文本
- 短语提取:可识别复合词,如"自然语言处理"
1.3. 双算法提取关键词
特殊字符过滤
text = re.sub(r"[^\w\u4e00-\u9fa5??!!]", "", text)TF-IDF 提取:
jieba.analyse.extract_tags(text,topK=10, # 提取前10个关键词withWeight=False, # 不返回权重allowPOS=('n', 'v', 'a', 'nr', 'ns', 'nz') # 仅保留名词、动词、形容词等
)- 原理:基于词频 - 逆文档频率,强调在当前文本中出现频繁但在语料库中不常见的词
- 词性筛选:保留名词(n)、动词(v)、形容词(a)、人名(nr)、地名(ns)、其他专有名词(nz),过滤虚词、副词等无实际意义的词
TextRank 提取:
jieba.analyse.textrank(text,topK=10,withWeight=False,allowPOS=('n', 'v', 'a', 'nr', 'ns', 'nz')
)- 原理:基于图模型,通过词与词的共现关系计算重要性
- 优势:能捕捉文本内部语义关联
关键词合并与筛选
combined = []seen = set()for kw in tfidf_kws + textrank_kws:if kw not in seen:seen.add(kw)combined.append(kw)# 保留前5-7个关键词return " ".join(combined[:7]) if combined else ""- 去重逻辑:通过
seen集合合并两种算法的结果,优先保留先出现的关键词,去重 - 长度控制:保留前 5-7 个关键词,用空格拼接为字符串
- 边界处理:若未提取到关键词,返回空字符串
2. 问题分类
实现问答数据的自动分类(自动标注一级、二级标签)
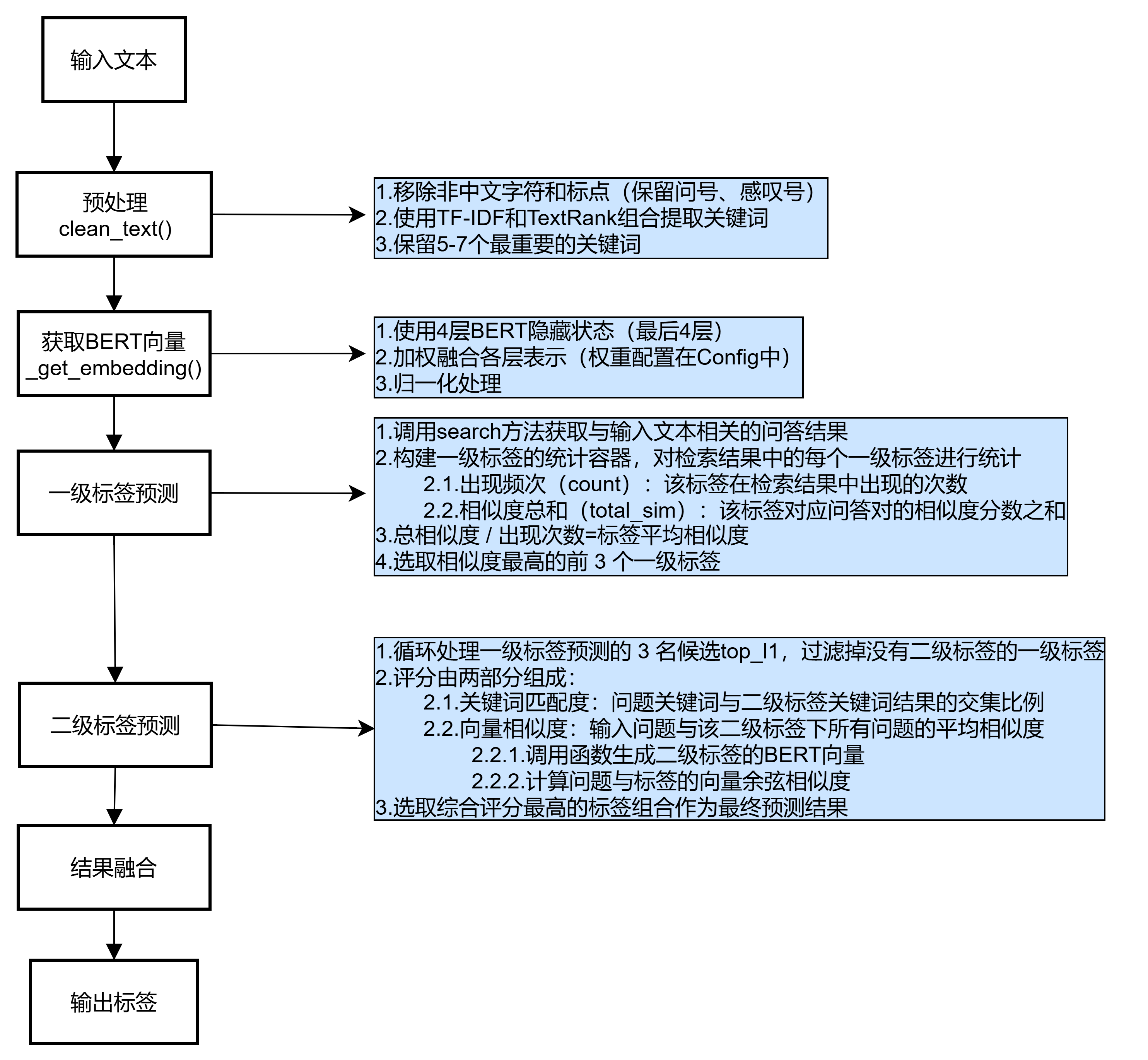
2.1. 预处理
调用clean_text()函数
- 移除非文本字符,保留中文字符、基本标点和重要词汇结合
- TF-IDF 和 TextRank 算法提取关键词
- 合并去重后保留前 7 个关键词作为核心特征
2.2. 获取BERT向量
调用_get_embedding()函数
- 加载预训练 BERT 模型和分词器
- 取模型最后 4 层的隐藏状态
- 按预设权重([0.15, 0.25, 0.35, 0.25])融合各层 CLS 向量
- 对融合向量进行归一化处理
2.3. 一级标签预测
search_results = self.search(text) # 统计一级标签出现频率和平均相似度
l1_stats = defaultdict(lambda: {'count': 0, 'total_sim': 0.0})
for result in search_results:l1 = result['tags']['level1']l1_stats[l1]['count'] += 1l1_stats[l1]['total_sim'] += result['similarity']# 计算每个一级标签的平均相似度l1_scores = {l1: stat['total_sim']/stat['count'] for l1, stat in l1_stats.items()}if not l1_scores:return {'level1': '其他', 'level2': '无'}# 取相似度最高的前3个候选
top_l1 = sorted(l1_scores.items(), key=lambda x: x[1], reverse=True)[:3]- 通过
search方法获取与输入文本相关的问答结果,包含问题、答案、相似度、标签 - 用
defaultdict构建一级标签的统计容器,对检索结果中的每个一级标签进行统计- 出现频次(
count):该标签在检索结果中出现的次数 - 相似度总和(
total_sim):该标签对应问答对的相似度分数之和
- 出现频次(
- 总相似度 / 出现次数=标签平均相似度
- 选取相似度最高的前 3 个一级标签
2.4. 二级标签预测
keywords = set(cleaned.split())
best_score = -1
best_tags = {'level1': top_l1[0][0], 'level2': '无'}for l1, l1_score in top_l1:if l1 not in self.tag_config.LEVEL2:continuefor l2 in self.tag_config.LEVEL2[l1]:# 关键词匹配l2_cleaned = clean_text(l2) l2_keywords = set(jieba.lcut(l2_cleaned)) kw_score = len(keywords & l2_keywords) / max(len(l2_keywords), 1)# 向量相似度l2_vec = self._get_embedding(l2_cleaned) vec_score = np.dot(query_vec, l2_vec) # 综合评分total_score = 0.6 * vec_score + 0.4 * kw_scoreif total_score > best_score:best_score = total_scorebest_tags = {'level1': l1, 'level2': l2}- 按空格分割预处理后的
cleaned,得到关键词集合,初始化最佳评分、标签结果 - 循环处理一级标签预测的 3 名候选
top_l1,过滤掉没有二级标签的一级标签 - 评分由两部分组成:
- 关键词匹配度
kw_score(40% ):问题关键词与二级标签关键词结果的交集比例 - 向量相似度
vec_score(60% ):输入问题与该二级标签下所有问题的平均相似度- 调用函数生成二级标签的BERT向量
- 计算问题与标签的向量余弦相似度
- 关键词匹配度
- 选取综合评分最高的标签组合作为最终预测结果
3. 测试
3.1. 关键词匹配度未发挥作用
根据调试结果,关键词部分的匹配度始终为0,未发挥作用
处理问题: 什么是佛教中的四圣谛?
预处理完成: 圣谛 佛教
向量维度: (768,)
候选一级标签: [('道理', 0.6594605436445109), ('修行', 0.6436407618586859), ('生活', 0.6339292906486615)]
二级标签'道理/人生'评分: 0.58 (向量:0.96, 关键词:0.00)
二级标签'道理/天道'评分: 0.58 (向量:0.97, 关键词:0.00)
最终预测: {'level1': '道理', 'level2': '天道'}
二级标签'修行/佛家'评分: 0.59 (向量:0.99, 关键词:0.00)
二级标签'修行/儒家'评分: 0.58 (向量:0.96, 关键词:0.00)
二级标签'修行/道家'评分: 0.58 (向量:0.97, 关键词:0.00)
最终预测: {'level1': '修行', 'level2': '佛家'}
二级标签'生活/健康'评分: 0.57 (向量:0.96, 关键词:0.00)
二级标签'生活/教育'评分: 0.58 (向量:0.96, 关键词:0.00)
二级标签'生活/食品'评分: 0.57 (向量:0.96, 关键词:0.00)
最终预测: {'level1': '修行', 'level2': '佛家'}
预测结果: {'level1': '修行', 'level2': '佛家'}
3.2. 预测结果对比表
| 测试问题 | 实际预测 | 理想预测 |
| 什么是佛教中的四圣谛? | 修行,佛家 | 修行,佛家 |
| 孔子说的'己所不欲勿施于人'如何实践? | 修行,儒家 | 修行,儒家 |
| 庄子讲的'逍遥游'是什么境界? | 修行,道家 | 修行,道家 |
| 每天快走30分钟有什么健康益处? | 生活,健康 | 生活,健康 |
| 如何培养孩子的阅读习惯? | 道理,人生 | 生活,教育 |
| 隔夜菜到底能不能吃? | 生活,教育 | 生活,食品 |
| 如何面对生活中的重大挫折? | 生活,教育 | 道理,人生 |
| 为什么说'善恶终有报'? | 道理,天道 | 道理,天道 |
准确率统计
| 指标 | 数量 | 比例 |
| 完全正确 | 5 | 62.5% |
| 一级标签正确 | 1 | 12.5% |
| 完全错误 | 2 | 25% |
对于修行一级标签预测较好,另外两个一级标签较差;初步分析可能与数据源的样本数量有关,心法问答.csv的标签分布如下:
| 一级标签 | 二级标签 | 数量 |
| 修行33 | 儒家 | 24 |
| 道家 | 8 | |
| 佛家 | 1 | |
| 生活25 | 教育 | 22 |
| 健康 | 2 | |
| 食品 | 1 | |
| 道理18 | 人生 | 10 |
| 天道 | 8 |