【LLM】基于ms-Swift大模型SFT和RL的训练实践
note
- 微调SFT和GRPO是确实能学到新知识的
- 使用简单的、可验证的、基于结果的奖励(例如,判断对错)是有效的,并且能降低奖励操纵(reward hacking)的风险
- 推理模型带来了新的安全挑战,例如奖励操纵(reward hacking)、过度思考(overthinking)以及特定的越狱(jailbreaking)漏洞。
文章目录
- note
- 一、Swift框架SFT微调
- 1、数据格式
- 2、微调方法
- 二、Swift框架GRPO训练
- 1、数据集定义
- 2、奖励函数定义
- (1)GRPO目标函数
- (2)本次实验的奖励函数
- 3、训练参数设置及原因
- 4、训练相关日志
- 三、Megatron-SWIFT训练
- 1、环境准备和训练步骤
- 2、训练技巧
- 四、Swift框架MoE训练
- Reference
一、Swift框架SFT微调
1、数据格式
# 通用格式
{"messages": [{"role": "system", "content": "<system-prompt>"},{"role": "user", "content": "<query1>"},{"role": "assistant", "content": "<response1>"}
]}
# 带think的格式
{"messages": [{"role": "user", "content": "Where is the capital of Zhejiang?"},{"role": "assistant", "content": "<think>\n...\n</think>\n\nThe capital of Zhejiang is Hangzhou."}
]}
- (重要!)
NPROC_PER_NODE: torchrun中--nproc_per_node的参数透传。默认为1。若设置了NPROC_PER_NODE`或者NNODES环境变量,则使用torchrun启动训练或推理。 - 使用swift框架时,四种格式(
messages、sharegpt、alpaca、query-response)在AutoPreprocessor处理下都会转换成ms-swift标准格式中的messages字段,即都可以直接使用--dataset <dataset-path>接入,即可直接使用json数据 - 默认使用ModelScope进行模型和数据集的下载。如果要使用HuggingFace,指定–use_hf true即可。
- 其他具体参考官方文档。
2、微调方法
lora微调脚本例子如下,10分钟在单卡3090上对Qwen2.5-7B-Instruct进行自我认知微调:
# 22GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \--model Qwen/Qwen2.5-7B-Instruct \--train_type lora \--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \'AI-ModelScope/alpaca-gpt4-data-en#500' \'swift/self-cognition#500' \--torch_dtype bfloat16 \--num_train_epochs 1 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--learning_rate 1e-4 \--lora_rank 8 \--lora_alpha 32 \--target_modules all-linear \--gradient_accumulation_steps 16 \--eval_steps 50 \--save_steps 50 \--save_total_limit 2 \--logging_steps 5 \--max_length 2048 \--output_dir output \--system 'You are a helpful assistant.' \--warmup_ratio 0.05 \--dataloader_num_workers 4 \--model_author swift \--model_name swift-robot
SFT经验:纯干货!关于 SFT 的22条经验分享
二、Swift框架GRPO训练
1、数据集定义
示例训练数据:
{"messages": [{"role": "user", "content": "Tell me tomorrow's weather"}]}
{"messages": [{"role": "user", "content": "What is 1 + 1?"}, {"role": "assistant", "content": "It equals 2"}, {"role": "user", "content": "What about adding 1?"}]}
{"messages": [{"role": "user", "content": "What is your name?"}]}
Coundown Game任务:给定几个数字,进行加减乘除后得到目标数值。
数据量:5w条
[INFO:swift] train_dataset: Dataset({features: ['nums', 'messages', 'target'],num_rows: 49500
})
[INFO:swift] val_dataset: Dataset({features: ['nums', 'messages', 'target'],num_rows: 500
})
通过 template, 使用 numbers 和 target 完成任务定义,并给到 query 字段供模型采样使用。同时,我们需要保留 nums 和 target 两个字段,用于后续的奖励函数计算。
class CoundownTaskPreprocessor(ResponsePreprocessor):def preprocess(self, row: Dict[str, Any]) -> Dict[str, Any]:numbers = row['nums']target = row.pop('response', None)query = f"""Using the numbers {numbers}, create an equation that equals {target}.You can use basic arithmetic operations (+, -, *, /) and each number can only be used once.Show your work in <think> </think> tags. And return the final equation and answer in <answer> </answer> tags,for example <answer> (1 + 2) / 3 * 4 = 4 </answer>."""row.update({'target': target, 'query': query})return super().preprocess(row)register_dataset(DatasetMeta(ms_dataset_id='zouxuhong/Countdown-Tasks-3to4',subsets=['default'],preprocess_func=CoundownTaskPreprocessor(),tags=['math']))
2、奖励函数定义
- 奖励函数计算:数据集格式取决于所使用的奖励函数。可能需要额外的列来支持特定的奖励计算。例如:
- 当使用内置的 accuracy 或 cosine 奖励时,数据集必须包含一个 solution 列以计算回复的准确性。
- 数据集中的其他列将作为
**kwargs传递给奖励函数以实现进一步的自定义。
- 自定义奖励函数:为了根据您的具体需求调整奖励函数,可以参考链接:外部奖励插件,https://github.com/modelscope/ms-swift/tree/main/examples/train/grpo/plugin。该插件提供了实现自定义奖励函数的示例和模板。
(1)GRPO目标函数
GRPO核心思想是通过构建多个模型输出的群组,并计算群组内的相对奖励来估计基线,从而避免了传统策略优化算法中需要使用与策略模型大小相同的评论模型。
- 大幅度降低 RL 训练的计算成本,同时还能保证模型能够有效地学习到策略。
- 具体来说,在传统的 RL 训练中,评论模型需要与策略模型具有相同的大小,增加计算资源的消耗。而 GRPO 算法利用群组内的相对信息来估计基线,避免了使用Critic Model的需要。
- 此外,GRPO 算法还引入了一些额外的优化策略(奖励缩放和策略裁剪),提升训练的稳定性。

From PPO to GRPO:
- PPO 作为 Actor-Critic 算法被广泛运用于 Post-Training,核心目标是最大化下面的目标函数
- 其中,πθ\pi_\thetaπθ 和 πθold\pi_{\theta o l d}πθold 分别表示当前策略模型和旧策略模型,q,oq, oq,o 是从问题数据集和旧策略 πθold\pi_{\theta o l d}πθold 中采样的输入和输出,AtA_tAt 是基于广义优势估计(GAE)计算的优势值,依赖于奖励序列 {r2t}\left\{r_{2 t}\right\}{r2t} 和学习的价值函数 VψV_\psiVψ 。因此,PPO需要同时训练策略模型和价值函数。为避免奖励模型的过度优化,标准做法是在每个词元的奖励中添加与参考模型的KL惩罚项
JPPO(θ)=E[q∼P(Q),o∼πθΔu(o∣q)]1∣o∣∑t=1∣o∣min[πθ(ot∣q,oε)πθαt(ot∣q,o<t)At,clip(πθ(ot∣q,o<t)πθdit(ot∣q,o<t),1−ε,1+ε)At]rt=rφ(q,o≤t)−βlogπθ(ot∣q,o<t)πref(ot∣q,o<t),\mathcal{J}_{P P O}(\theta)=\mathbf{E}\left[q \sim P(Q), o \sim \pi_{\theta_{\Delta u}}(o \mid q)\right] \frac{1}{|o|} \sum_{t=1}^{|o|} \min \left[\frac{\pi_\theta\left(o_t \mid q, o_{\varepsilon}\right)}{\pi_{\theta_{\alpha t}\left(o_t \mid q, o_{<t}\right)}} A_t, \operatorname{clip}\left(\frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\left.\pi_{\theta_{d i t}\left(o_t \mid q, o_{<t}\right)}, 1-\varepsilon, 1+\varepsilon\right)} A_t\right] \quad r_t=r_{\varphi}\left(q, o_{\leq t}\right)-\beta \log \frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{r e f}\left(o_t \mid q, o_{<t}\right)},\right. JPPO(θ)=E[q∼P(Q),o∼πθΔu(o∣q)]∣o∣1t=1∑∣o∣min[πθαt(ot∣q,o<t)πθ(ot∣q,oε)At,clip(πθdit(ot∣q,o<t),1−ε,1+ε)πθ(ot∣q,o<t)At]rt=rφ(q,o≤t)−βlogπref(ot∣q,o<t)πθ(ot∣q,o<t),
GRPO放弃了通常与policy模型大小相同的critic模型,从群体分数来估计基线。具体来说,对每个q,GRPO从旧的policy采样一组输出,然后通过下面的目标函数优化policy。GRPO 的目标函数为:
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθodd (O∣q)]1G∑i=1G(min(πθ(oi∣q)πθdd(oi∣q)Ai,clip(πθ(oi∣q)πθdd (oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∥πref)),DKL(πθ∥πref)=πref(oi∣q)πθ(oi∣q)−logπref(oi∣q)πθ(oi∣q)−1\begin{gathered} \mathcal{J}_{G R P O}(\theta)=\mathbb{E}\left[q \sim P(Q),\left\{o_i\right\}_{i=1}^G \sim \pi_{\theta_{\text {odd }}}(O \mid q)\right] \\ \frac{1}{G} \sum_{i=1}^G\left(\min \left(\frac{\pi_\theta\left(o_i \mid q\right)}{\pi_{\theta_{d d}}\left(o_i \mid q\right)} A_i, \operatorname{clip}\left(\frac{\pi_\theta\left(o_i \mid q\right)}{\pi_{\theta_{\text {dd }}}\left(o_i \mid q\right)}, 1-\varepsilon, 1+\varepsilon\right) A_i\right)-\beta \mathbb{D}_{K L}\left(\pi_\theta \| \pi_{r e f}\right)\right), \\ \mathbb{D}_{K L}\left(\pi_\theta \| \pi_{r e f}\right)=\frac{\pi_{r e f}\left(o_i \mid q\right)}{\pi_\theta\left(o_i \mid q\right)}-\log \frac{\pi_{r e f}\left(o_i \mid q\right)}{\pi_\theta\left(o_i \mid q\right)}-1 \end{gathered} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθodd (O∣q)]G1i=1∑G(min(πθdd(oi∣q)πθ(oi∣q)Ai,clip(πθdd (oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∥πref)),DKL(πθ∥πref)=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1
其中,ε\varepsilonε 和 β\betaβ 是超参, Ai 是advantage,如下。
Ai=ri−mean({r1,r2,…,rG})std({r1,r2,…,rG})A_i=\frac{r_i-\operatorname{mean}\left(\left\{r_1, r_2, \ldots, r_G\right\}\right)}{\operatorname{std}\left(\left\{r_1, r_2, \ldots, r_G\right\}\right)} Ai=std({r1,r2,…,rG})ri−mean({r1,r2,…,rG})
步骤流程:

几个步骤:

具体细节:

(2)本次实验的奖励函数
本次实验的奖励函数:
- 格式奖励函数:Deepseek-R1 中提到的格式奖励函数,已经在swift中内置,通过
--reward_funcs format可以直接使用 - 准确性奖励函数:使用 external_plugin 的方式定义准确性奖励函数,将代码放在
swift/examples/train/grpo/plugin/plugin.py中。- 奖励函数的输入包括 completions、target 和 nums 三个字段,分别表示模型生成的文本、目标答案和可用的数字。
- 每个都是list,支持多个 completion 同时计算。注意这里除了 completions 之外的参数都是数据集中定义的字段透传而来,如果有任务上的变动,可以分别对数据集和奖励函数做对应的改变即可。
class CountdownORM(ORM):def __call__(self, completions, target, nums, **kwargs) -> List[float]:"""Evaluates completions based on Mathematical correctness of the answerArgs:completions (list[str]): Generated outputstarget (list[str]): Expected answersnums (list[str]): Available numbersReturns:list[float]: Reward scores"""rewards = []for completion, gt, numbers in zip(completions, target, nums):try:# Check if the format is correctmatch = re.search(r"<answer>(.*?)<\/answer>", completion)if match is None:rewards.append(0.0)continue# Extract the "answer" part from the completionequation = match.group(1).strip()if '=' in equation:equation = equation.split('=')[0]# Extract all numbers from the equationused_numbers = [int(n) for n in re.findall(r'\d+', equation)]# Check if all numbers are used exactly onceif sorted(used_numbers) != sorted(numbers):rewards.append(0.0)continue# Define a regex pattern that only allows numbers, operators, parentheses, and whitespaceallowed_pattern = r'^[\d+\-*/().\s]+$'if not re.match(allowed_pattern, equation):rewards.append(0.0)continue# Evaluate the equation with restricted globals and localsresult = eval(equation, {"__builti'ns__": None}, {})# Check if the equation is correct and matches the ground truthif abs(float(result) - float(gt)) < 1e-5:rewards.append(1.0)else:rewards.append(0.0)except Exception as e:# If evaluation fails, reward is 0rewards.append(0.0)return rewards
orms['external_countdown'] = CountdownORM
3、训练参数设置及原因
选取 Qwen2.5-3B-Instruct 作为基础模型进行训练,选取 Instruct 而不是基模的主要原因是可以更快地获取 format reward。我们在三卡 GPU 上进行实验,因此vllm的推理部署在最后一张卡上,而进程数设置为2,在剩下两张卡上进行梯度更新。
由于任务较为简单,我们设置 max_completion_length 和 vllm_max_model_len 为1024,如果有更复杂的任务,可以适当加大模型输出长度。注意,这两个参数越大,模型训练需要的显存越多,训练速度越慢,单个step的训练时间与max_completion_length呈现线性关系。
在我们的实验中,总batch_size为 num_processes×per_device_train_batch_size×gradient_accumulation_steps=2×8×8=128num\_processes \times per\_device\_train\_batch\_size \times gradient\_accumulation\_steps = 2 \times 8 \times 8 = 128num_processes×per_device_train_batch_size×gradient_accumulation_steps=2×8×8=128 而参数设置有一个限制,即:num_processes×per_device_train_batch_sizenum\_processes \times per\_device\_train\_batch\_sizenum_processes×per_device_train_batch_size 必须整除 num_generationsnum\_generationsnum_generations,其中,num_generationsnum\_generationsnum_generations就是GRPO公式中的 GGG,故我们设置为8。
注意:
- 这里单卡batch_size设置也与显存息息相关,请根据显存上限设置一个合适的值。
- 总的steps数量 :num_steps=epochs×len(datasets)×num_generations÷batch_sizenum\_steps = epochs \times len(datasets) \times num\_generations \div batch\_sizenum_steps=epochs×len(datasets)×num_generations÷batch_size,需要根据这个来合理规划训练的学习率和warmup设置。
- 设置是学习率和 beta,学习率比较好理解,而beta则是是以上公式的 β\betaβ,即KL散度的梯度的权重。这两个参数设置的越大,模型收敛原则上更快,但训练往往会不稳定。经过实验,我们分别设置为
5e-7和0.001。在实际训练中,请根据是否出现不稳定的震荡情况适当调整这两个参数。 - 对于KL散度,可以参考为什么GRPO坚持用KL散度。
- 具体的参数介绍:https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html
CUDA_VISIBLE_DEVICES=0,1,2 \
WANDB_API_KEY=your_wandb_key \
NPROC_PER_NODE=2 \
swift rlhf \--rlhf_type grpo \--model Qwen/Qwen2.5-3B-Instruct \--external_plugins examples/train/grpo/plugin/plugin.py \--reward_funcs external_countdown format \--use_vllm true \--vllm_device auto \--vllm_gpu_memory_utilization 0.6 \--train_type full \--torch_dtype bfloat16 \--dataset 'zouxuhong/Countdown-Tasks-3to4#50000' \--max_length 2048 \--max_completion_length 1024 \--num_train_epochs 1 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 8 \--learning_rate 5e-7 \--gradient_accumulation_steps 8 \--eval_steps 500 \--save_steps 100 \--save_total_limit 20 \--logging_steps 1 \--output_dir output/GRPO_COUNTDOWN \--warmup_ratio 0.01 \--dataloader_num_workers 4 \--num_generations 8 \--temperature 1.0 \--system 'You are a helpful assistant. You first thinks about the reasoning process in the mind and then provides the user with the answer.' \--deepspeed zero3 \--log_completions true \--vllm_max_model_len 1024 \--report_to wandb \--beta 0.001 \--num_iterations 1
4、训练相关日志
{'loss': 1.693e-05, 'grad_norm': 0.16142532, 'learning_rate': 4.9e-07, 'reward': 1.3671875, 'reward_std': 0.30654377, 'frac_reward_zero_std': 0.703125, 'rewards/CountdownORM/mean': 0.68359375, 'rewards/CountdownORM/std': 0.46552831, 'rewards/Format/mean': 0.68359375, 'rewards/Format/std': 0.46552831, 'completions/mean_length': 666.88476562, 'completions/min_length': 193.0, 'completions/max_length': 1025.0, 'completions/clipped_ratio': 0.31640625, 'kl': 0.02148874, 'clip_ratio/low_mean': 0.0, 'clip_ratio/low_min': 0.0, 'clip_ratio/high_mean': 0.0, 'clip_ratio/high_max': 0.0, 'clip_ratio/region_mean': 0.0, 'epoch': 0.08, 'global_step/max_steps': '30/390', 'percentage': '7.69%', 'elapsed_time': '2h 25m 21s', 'remaining_time': '1d 5h 4m 23s', 'memory(GiB)': 74.92, 'train_speed(iter/s)': 0.00344}
{'loss': 1.81e-05, 'grad_norm': 0.13969626, 'learning_rate': 4.9e-07, 'reward': 1.40820312, 'reward_std': 0.23111643, 'frac_reward_zero_std': 0.7734375, 'rewards/CountdownORM/mean': 0.703125, 'rewards/CountdownORM/std': 0.45732781, 'rewards/Format/mean': 0.70507812, 'rewards/Format/std': 0.45645362, 'completions/mean_length': 646.10742188, 'completions/min_length': 205.0, 'completions/max_length': 1025.0, 'completions/clipped_ratio': 0.29492188, 'kl': 0.02341532, 'clip_ratio/low_mean': 0.0, 'clip_ratio/low_min': 0.0, 'clip_ratio/high_mean': 0.0, 'clip_ratio/high_max': 0.0, 'clip_ratio/region_mean': 0.0, 'epoch': 0.08, 'global_step/max_steps': '31/390', 'percentage': '7.95%', 'elapsed_time': '2h 28m 10s', 'remaining_time': '1d 4h 35m 59s', 'memory(GiB)': 74.92, 'train_speed(iter/s)': 0.003487}
截取一点训练日志(如上)可以看到:
- frac_reward_zero_std ≈ 0.67–0.75:同一批(或同 prompt 的多次采样)里,奖励的标准差经常是 0——说明生成几乎没多样性(温度/采样太保守)或奖励函数对不同生成不敏感。这会让策略梯度几乎没有信号。
- train_speed ≈ 0.0032 iter/s(≈5 分钟/步):非常慢,多半是外置 vLLM 采样 + 长输出导致的吞吐瓶颈。
- KL ≈ 0.02–0.09:不算异常,但偏低意味着对基模的约束较弱/探索不多;结合“奖励方差低”,学习信号可能稀薄。
wandb日志观察和分析:
1、reward/mean整体是逐渐增加的,为了快速训练demo本次设置的num_generations为4能有这样的结果也算符合预期了
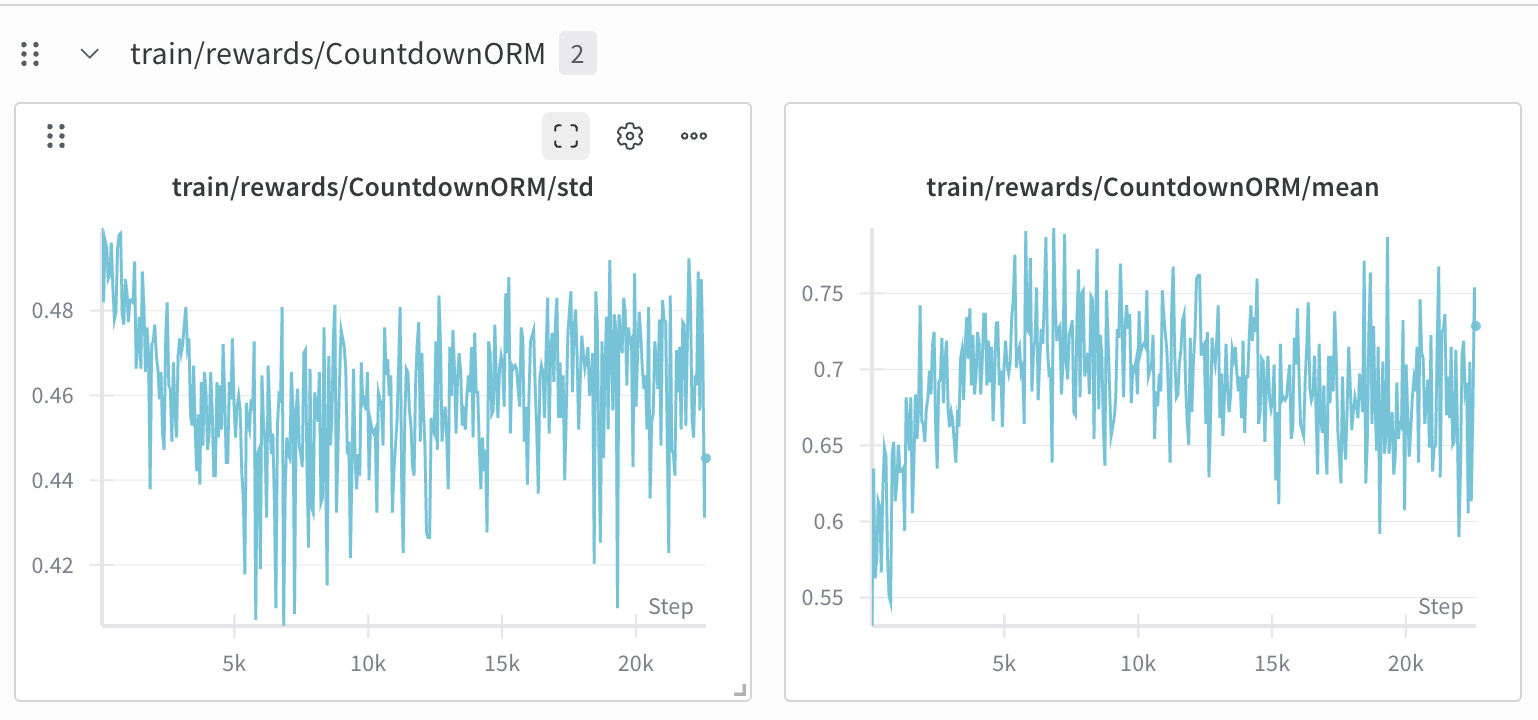
2、frac_reward_zero_std 长时间 ≥0.75,意味着同一 prompt 的 G 条回答拿到几乎相同奖励(或被离散化到同一分值)
解决:G设置更大,采样防止太保守(如temp、top_p调高等),使用DAPO算法
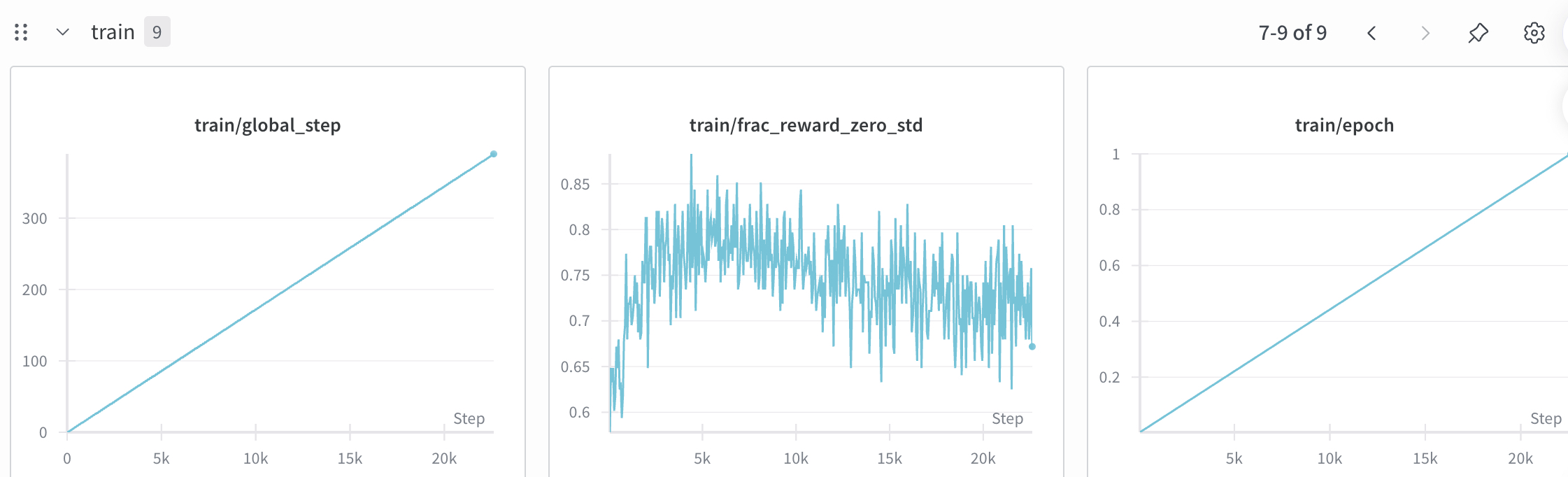
3、KL 长时间很低但偶发尖刺 → 比率/优势瞬时失配(off-policy 爆点)
证据:绝大多数 step KL≈0.x 或更低,但在 ~15k 处突然飙到 10–20;同点 loss、grad_norm 也尖峰。
解释:平时 KL 约束或采样让策略几乎不偏离参考,但偶尔某些 batch 的重要性比率 r 爆炸(奖励和对数比可能同向放大),触发大梯度。
GRPO 特性:在 token-级做比率 + 组优势,遇到长序列/奖励很偏或 MoE 路由变化 时更易出现尖刺。
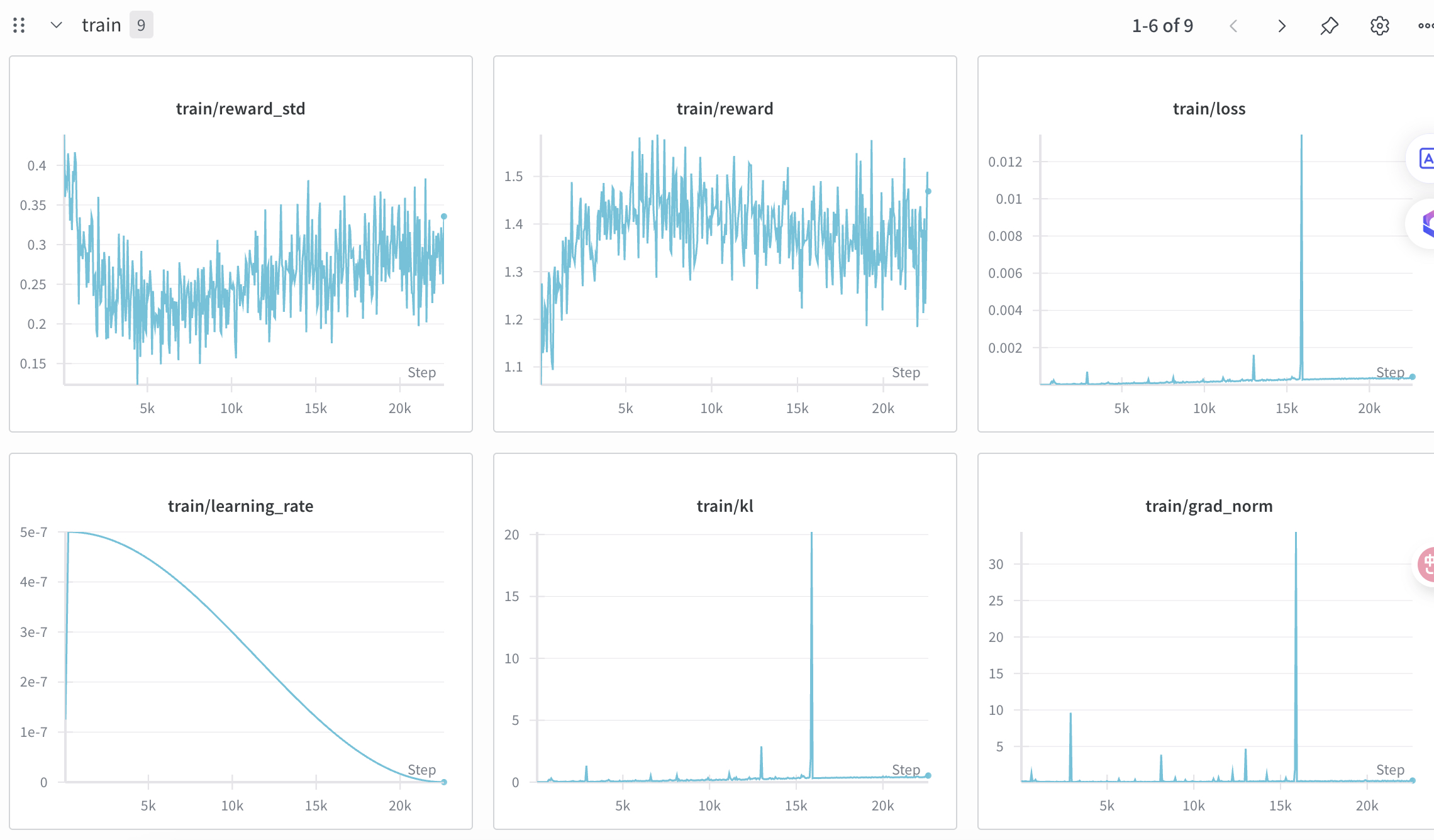
4、训练GRPO的loss从0开始,逐渐增加(策略偏离参考策略)
参考:https://github.com/huggingface/open-r1/issues/239#issuecomment-2646297851
三、Megatron-SWIFT训练
- Qwen3-235B-A22B-Instruct-250718 单机8卡H20 LoRA训练的最佳实践参考:https://github.com/modelscope/ms-swift/pull/5033。
- ms-swift 引入了 Megatron 并行技术以加速大模型的CPT/SFT/DPO。ms-swift引入了Megatron的并行技术来加速大模型的训练,包括数据并行、张量并行、流水线并行、序列并行,上下文并行,专家并行。
- 支持Qwen3、Qwen3-MoE、Qwen2.5、Llama3、Deepseek-R1、GLM4.5等模型的CPT/SFT/DPO。
- Megatron-SWIFT使用与ms-swift相同的dataset和template处理模块,因此同样支持packing、loss_scale、agent训练等技术
1、环境准备和训练步骤
(1)需要将HF格式的权重转为Megatron格式
CUDA_VISIBLE_DEVICES=0 \
swift export \--model Qwen/Qwen2.5-7B-Instruct \--to_mcore true \--torch_dtype bfloat16 \--output_dir Qwen2.5-7B-Instruct-mcore \--test_convert_precision true
(2)下面训练所需显存资源为2*80GiB。若使用多机训练,建议共享磁盘,并将–save指定为相同的路径。
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 \
megatron sft \--load Qwen2.5-7B-Instruct-mcore \--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \'AI-ModelScope/alpaca-gpt4-data-en#500' \'swift/self-cognition#500' \--tensor_model_parallel_size 2 \--sequence_parallel true \--micro_batch_size 16 \--global_batch_size 16 \--recompute_granularity full \--recompute_method uniform \--recompute_num_layers 1 \--finetune true \--cross_entropy_loss_fusion true \--lr 1e-5 \--lr_warmup_fraction 0.05 \--min_lr 1e-6 \--max_epochs 1 \--save megatron_output/Qwen2.5-7B-Instruct \--save_interval 100 \--max_length 2048 \--system 'You are a helpful assistant.' \--num_workers 4 \--no_save_optim true \--no_save_rng true \--dataset_num_proc 4 \--model_author swift \--model_name swift-robot
(3)将Megatron格式权重转为HF格式:
CUDA_VISIBLE_DEVICES=0 \
swift export \--mcore_model megatron_output/Qwen2.5-7B-Instruct/vx-xxx \--to_hf true \--torch_dtype bfloat16 \--output_dir megatron_output/Qwen2.5-7B-Instruct/vx-xxx-hf \--test_convert_precision true# 对HF模型格式进行推理
CUDA_VISIBLE_DEVICES=0 \
swift infer \--model megatron_output/Qwen2.5-7B-Instruct/vx-xxx-hf \--stream true \--temperature 0 \--max_new_tokens 2048
2、训练技巧
- 增加训练吞吐量方法:使用packing、增加DP、减少重计算、增加计算通信overlap。
- 并行技术选择:
- Megatron-SWIFT的并行技术采用zero1(默认开启
use_distributed_optimizer)+各种并行技术的组合。 - DP的速度最快,但显存占用较多,使用其他并行技术以降低显存占用。
- TP/EP通信量较大,尽量不跨节点(NVLink域内),跨节点建议使用PP/DP;专家层建议使用EP而不是ETP,ETP更节约显存,但速度较慢。
- MoE 并行折叠:MoE 相关的并行组与 Dense 组分离。Attention使用 tp-cp-dp-pp 组,MoE 使用 etp-ep-dp-pp 组。
- Megatron-SWIFT的并行技术采用zero1(默认开启
- 权重转换并行数的选择:Megatron-SWIFT在mcore端使用torch_dist存储格式,训练时可以调整并行数,不需要在权重转化时指定并行数。
四、Swift框架MoE训练
- 并行技术选择:
- Megatron-SWIFT的并行技术采用zero1(默认开启
use_distributed_optimizer)+各种并行技术的组合。 - DP的速度最快,但显存占用较多,使用其他并行技术以降低显存占用。
- TP/EP通信量较大,尽量不跨节点(NVLink域内),跨节点建议使用PP/DP;专家层建议使用EP而不是ETP,ETP更节约显存,但速度较慢。
- MoE 并行折叠:MoE 相关的并行组与 Dense 组分离。Attention使用 tp-cp-dp-pp 组,MoE 使用 etp-ep-dp-pp 组。
- Megatron-SWIFT的并行技术采用zero1(默认开启
- 并行相关的核心参数:
--expert_model_parallel_size(EP,专家并行)
决定每层 MoE 的“专家分片”方式。Megatron Core 明确:MoE + Tensor 并行必须开 Sequence Parallel(SP),否则通信/显存都不对劲。EP 与 TP/PP/DP 一起决定总并行度。
NVIDIA Docs- **怎么设:**优先让 DP × TP × PP × EP = 总进程数(GPU 数);比如 16 张卡、PP=2、EP=8,则 TP×DP=1。若再要 TP>1,一定加 --sequence_parallel(见下)。
--pipeline_model_parallel_size(PP):模型分层切成多段流水并行。MoE 层在各段内部仍按 EP/TP 规则并行。怎么设: 受模型深度/显存影响,通常 2 或 4;示例里是 2。--tensor_model_parallel_size(TP)(可选):MoE 与 TP 同时使用时,Megatron 要求打开 --sequence_parallel(下)。**怎么设:**TP>1 才考虑,注意通信与显存。--sequence_parallel(SP):MoE+TP 必开。Megatron 文档明确注记;否则可能 OOM/不收敛。- 参考链接:Mixture of Experts package.Nvidia官方文档
- MoE相关的参数:
- –moe_permute_fusion、–moe_grouped_gemm、–moe_shared_expert_overlap
这些是 Megatron Core 的 MoE 加速/融合优化,用于减少 permute、把小 GEMM 分组、与共享专家重叠计算,显著提速、降通信开销。示例脚本默认开启 --moe_aux_loss_coeff(专家负载均衡损失系数)
MoE 训练里为防止路由塌缩,需要一个 aux loss;典型量级 1e-3~1e-2。示例用 1e-3 是常见安全值。Megatron Core 的 MoE API 文档也提到均衡损失的重要性。
- –moe_permute_fusion、–moe_grouped_gemm、–moe_shared_expert_overlap
- 其他参数:
- –micro_batch_size 与 --global_batch_size,全局批次 ≈ micro_batch_size × 数据并行大小 × 累积步数
- –max_length 与 --packing:长度 8k(如 8192)对 MoE 显存/吞吐压力很大;能开 packing 就开,但要确认任务允许样本拼接。示例有 --packing true
- 注意力与算子融合提速:
--attention_backend flash使用flash attention,--cross_entropy_loss_fusion true开启交叉熵融合内核能进一步提速 - 保存与评估:–save_interval/–eval_interval 设短些以尽早发现路由塌缩、负载不均等问题
# ZeRO3: 91.2s/it; 16 * 80GiB
# Megatron-LM: 9.6s/it; 16 * 60GiB
# Launch using Alibaba Cloud DLC
# https://help.aliyun.com/zh/pai/user-guide/general-environment-variables
# ref: https://github.com/modelscope/ms-swift/blob/main/examples/train/multi-node/dlc/train.sh
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NNODES=$WORLD_SIZE \
NODE_RANK=$RANK \
megatron sft \--load Qwen3-30B-A3B-Base-mcore \--dataset 'liucong/Chinese-DeepSeek-R1-Distill-data-110k-SFT' \--load_from_cache_file true \--split_dataset_ratio 0.01 \--pipeline_model_parallel_size 2 \--expert_model_parallel_size 8 \--moe_permute_fusion true \--moe_grouped_gemm true \--moe_shared_expert_overlap true \--moe_aux_loss_coeff 1e-3 \--micro_batch_size 1 \--global_batch_size 16 \--packing true \--recompute_granularity full \--recompute_method uniform \--recompute_num_layers 1 \--max_epochs 3 \--finetune true \--cross_entropy_loss_fusion true \--lr 1e-5 \--lr_warmup_fraction 0.05 \--min_lr 1e-6 \--save megatron_output/Qwen3-30B-A3B-Base \--eval_interval 200 \--save_interval 200 \--max_length 8192 \--num_workers 8 \--dataset_num_proc 8 \--no_save_optim true \--no_save_rng true \--sequence_parallel true \--attention_backend flash
如果是单机4卡进行lora微调Qwen3-30B-A3B-Base-mcore:
# 前提:已是 *mcore* 权重;若是 HF 权重,先 swift export --to_mcore(文档有示例)PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
NPROC_PER_NODE=4 \
megatron sft \--load /path/to/Qwen3-30B-A3B-Base-mcore \--dataset 'your/dataset#N' \--train_type lora \--lora_rank 16 \--lora_alpha 32 \--lora_dropout 0.05 \--target_modules all-linear \\# —— MoE 并行拓扑(4 卡):DP=1, TP=1, PP=1, EP=4 —— #--pipeline_model_parallel_size 1 \--expert_model_parallel_size 4 \--sequence_parallel true \ # TP=1 时可选;保留不伤身,TP>1 时必须\# —— MoE/算子优化 —— #--moe_permute_fusion true \--moe_grouped_gemm true \--moe_shared_expert_overlap true \--moe_aux_loss_coeff 1e-3 \\# —— batch/长度/重计算 —— #--micro_batch_size 4 \--global_batch_size 16 \--packing true \--max_length 4096 \--recompute_granularity selective \--recompute_modules core_attn moe \\# —— 训练细节 —— #--finetune true \--cross_entropy_loss_fusion true \--lr 1e-4 \--lr_warmup_fraction 0.05 \--min_lr 1e-5 \--max_epochs 1 \--save megatron_output/Qwen3-30B-A3B-LoRA \--save_interval 200 \--eval_interval 200 \--num_workers 8 --dataset_num_proc 8 \--no_save_optim true --no_save_rng true \--attention_backend flash
Reference
[1] swift框架微调:https://github.com/modelscope/ms-swift/tree/main/examples/train/think_model
[2] qwen3 moe分布式训练: [Fine-tuning] Qwen3-MoE Megatron Training Implementation and Best Practices👋 #1278
[3] Swift微调命令参数
[4] MS-SWIFT微调Qwen3
[5] swift官方文档GRPO训练过程:https://swift.readthedocs.io/zh-cn/latest/BestPractices/GRPO%E5%AE%8C%E6%95%B4%E6%B5%81%E7%A8%8B.html