ML4T - 第8章第0节 数据准备Data prep
目录
一、获取 Quandl 调整后行情
二、获取 Lasso 预测值
三、统一索引名 & 确定时间窗口
四、对齐行情 & 预测
五、整体代码
这个脚本的作用:(准备阶段)
脚本把“Lasso 预测值”与“Quandl 调整后行情”按最佳超参、统一日期-股票对齐,生成可直接用于策略回测的完整数据表 08_backtest.h5。
一、获取 Quandl 调整后行情
with pd.HDFStore(DATA_DIR / 'assets.h5') as store:
prices = (store['quandl/wiki/prices']
.filter(like='adj')
.rename(columns=lambda x: x.replace('adj_', ''))
.swaplevel(axis=0))
二、获取 Lasso 预测值
# with pd.HDFStore(PROJECT_DIR / '07_linear_models/data.h5') as store:
with pd.HDFStore(PROJECT_DIR / 'data.h5') as store:
print(store.info())
predictions = store[predictions]
# 用 Spearman 秩相关系数 衡量“预测值”与“真实值”的单调性,挑整体表现最好的 alpha。
best_alpha = predictions.groupby('alpha').apply(lambda x: spearmanr(x.actuals, x.predicted)[0]).idxmax()
predictions = predictions[predictions.alpha == best_alpha]
三、统一索引名 & 确定时间窗口
predictions.index.names = ['ticker', 'date']
tickers = predictions.index.get_level_values('ticker').unique()
start = predictions.index.get_level_values('date').min().strftime('%Y-%m-%d')
stop = (predictions.index.get_level_values('date').max() + pd.DateOffset(1)).strftime('%Y-%m-%d')
四、对齐行情 & 预测
idx = pd.IndexSlice
prices = prices.sort_index().loc[idx[tickers, start:stop], :]
predictions = predictions.loc[predictions.alpha == best_alpha, ['predicted']]
return predictions.join(prices, how='right')
五、整体代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'Stefan Jansen' # https://github.com/stefan-jansen/machine-learning-for-trading/blob/main/08_ml4t_workflow/00_data/data_prep.py
__modified_author__ = 'MangoQuant' # https://blog.csdn.net/2401_82851462from pathlib import Path
import numpy as np
import pandas as pd
from scipy.stats import spearmanrpd.set_option('display.expand_frame_repr', False)
np.random.seed(42)# PROJECT_DIR = Path('..', '..')
PROJECT_DIR = Path('.')DATA_DIR = PROJECT_DIR / 'data'def get_backtest_data(predictions='lasso/predictions'):"""Combine chapter 7 lr/lasso/ridge regression predictionswith adjusted OHLCV Quandl Wiki data"""# 获取 Quandl 调整后行情with pd.HDFStore(DATA_DIR / 'assets.h5') as store:prices = (store['quandl/wiki/prices'].filter(like='adj').rename(columns=lambda x: x.replace('adj_', '')).swaplevel(axis=0))# 获取 Lasso 预测值# with pd.HDFStore(PROJECT_DIR / '07_linear_models/data.h5') as store:with pd.HDFStore(PROJECT_DIR / 'data.h5') as store:print(store.info())predictions = store[predictions]# 用 Spearman 秩相关系数 衡量“预测值”与“真实值”的单调性,挑整体表现最好的 alpha。best_alpha = predictions.groupby('alpha').apply(lambda x: spearmanr(x.actuals, x.predicted)[0]).idxmax()predictions = predictions[predictions.alpha == best_alpha]# 统一索引名 & 确定时间窗口predictions.index.names = ['ticker', 'date']tickers = predictions.index.get_level_values('ticker').unique()start = predictions.index.get_level_values('date').min().strftime('%Y-%m-%d')stop = (predictions.index.get_level_values('date').max() + pd.DateOffset(1)).strftime('%Y-%m-%d')# 对齐行情 & 预测idx = pd.IndexSliceprices = prices.sort_index().loc[idx[tickers, start:stop], :]predictions = predictions.loc[predictions.alpha == best_alpha, ['predicted']]return predictions.join(prices, how='right')df = get_backtest_data('lasso/predictions')
print(df.info())
# df.to_hdf('backtest.h5', 'data')
df.to_hdf('08_backtest.h5', 'data')
print("08_backtest.h5 saved")
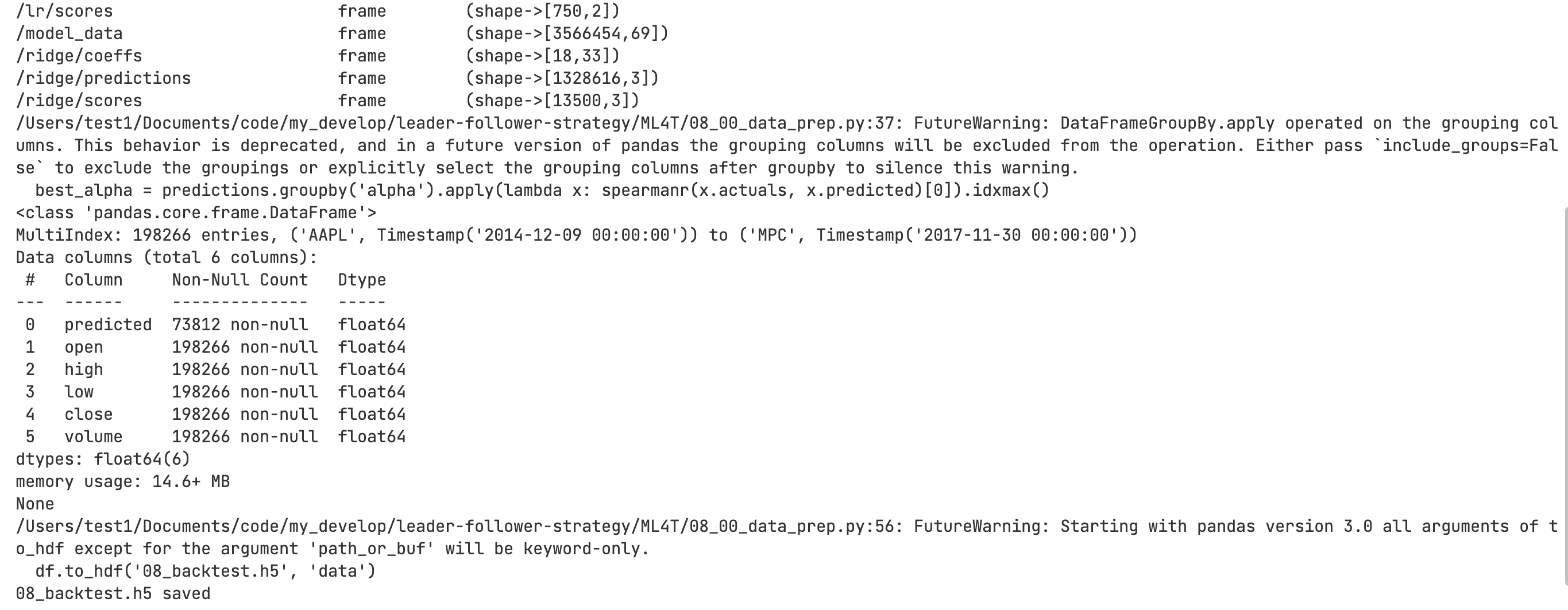
运行后结果:
test1@budas-MacBook-Pro ML4T % python 08_00_data_prep.py
<class 'pandas.io.pytables.HDFStore'>
File path: data.h5
/lasso/coeffs frame (shape->[8,33])
/lasso/predictions frame (shape->[590496,3])
/lasso/scores frame (shape->[6000,3])
/logistic/coeffs frame (shape->[11,33])
/logistic/predictions frame (shape->[811932,4])
/logistic/scores frame (shape->[825,5])
/lr/predictions frame (shape->[73812,2])
/lr/scores frame (shape->[750,2])
/model_data frame (shape->[3566454,69])
/ridge/coeffs frame (shape->[18,33])
/ridge/predictions frame (shape->[1328616,3])
/ridge/scores frame (shape->[13500,3])
/Users/test1/Documents/code/my_develop/leader-follower-strategy/ML4T/08_00_data_prep.py:37: FutureWarning: DataFrameGroupBy.apply operated on the grouping columns. This behavior is deprecated, and in a future version of pandas the grouping columns will be excluded from the operation. Either pass `include_groups=False` to exclude the groupings or explicitly select the grouping columns after groupby to silence this warning.best_alpha = predictions.groupby('alpha').apply(lambda x: spearmanr(x.actuals, x.predicted)[0]).idxmax()
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 198266 entries, ('AAPL', Timestamp('2014-12-09 00:00:00')) to ('MPC', Timestamp('2017-11-30 00:00:00'))
Data columns (total 6 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 predicted 73812 non-null float641 open 198266 non-null float642 high 198266 non-null float643 low 198266 non-null float644 close 198266 non-null float645 volume 198266 non-null float64
dtypes: float64(6)
memory usage: 14.6+ MB
None
/Users/test1/Documents/code/my_develop/leader-follower-strategy/ML4T/08_00_data_prep.py:56: FutureWarning: Starting with pandas version 3.0 all arguments of to_hdf except for the argument 'path_or_buf' will be keyword-only.df.to_hdf('08_backtest.h5', 'data')
08_backtest.h5 saved