常见深度学习算法图解笔记
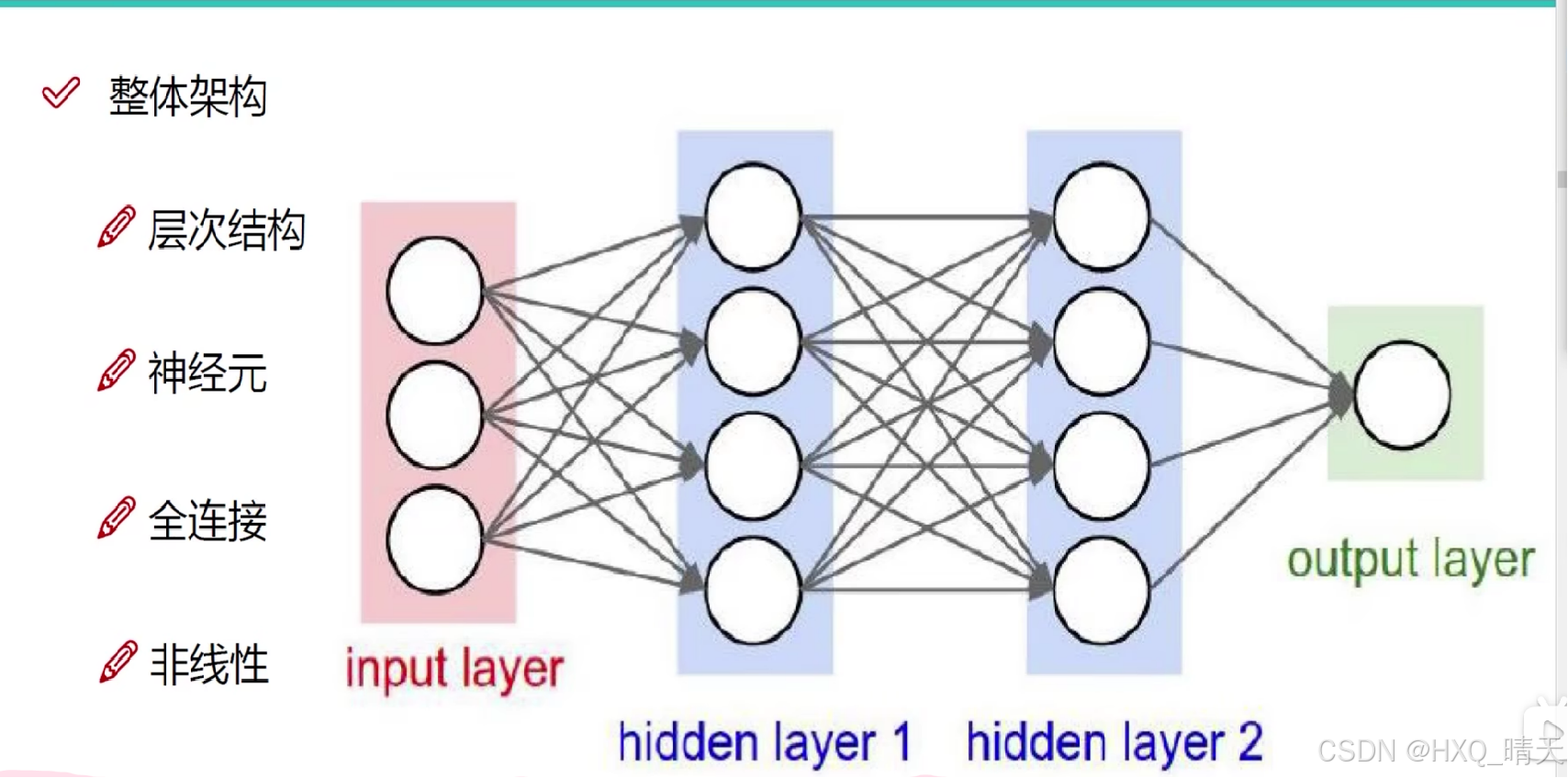
深度学习整体架构
与传统的机器学习方法不同,深度学习模型能够自动从原始数据中提取特征,减少了手动特征工程的需求。 深度学习模型通常包含多个隐藏层,这些层可以学习数据的高层抽象和复杂特征。
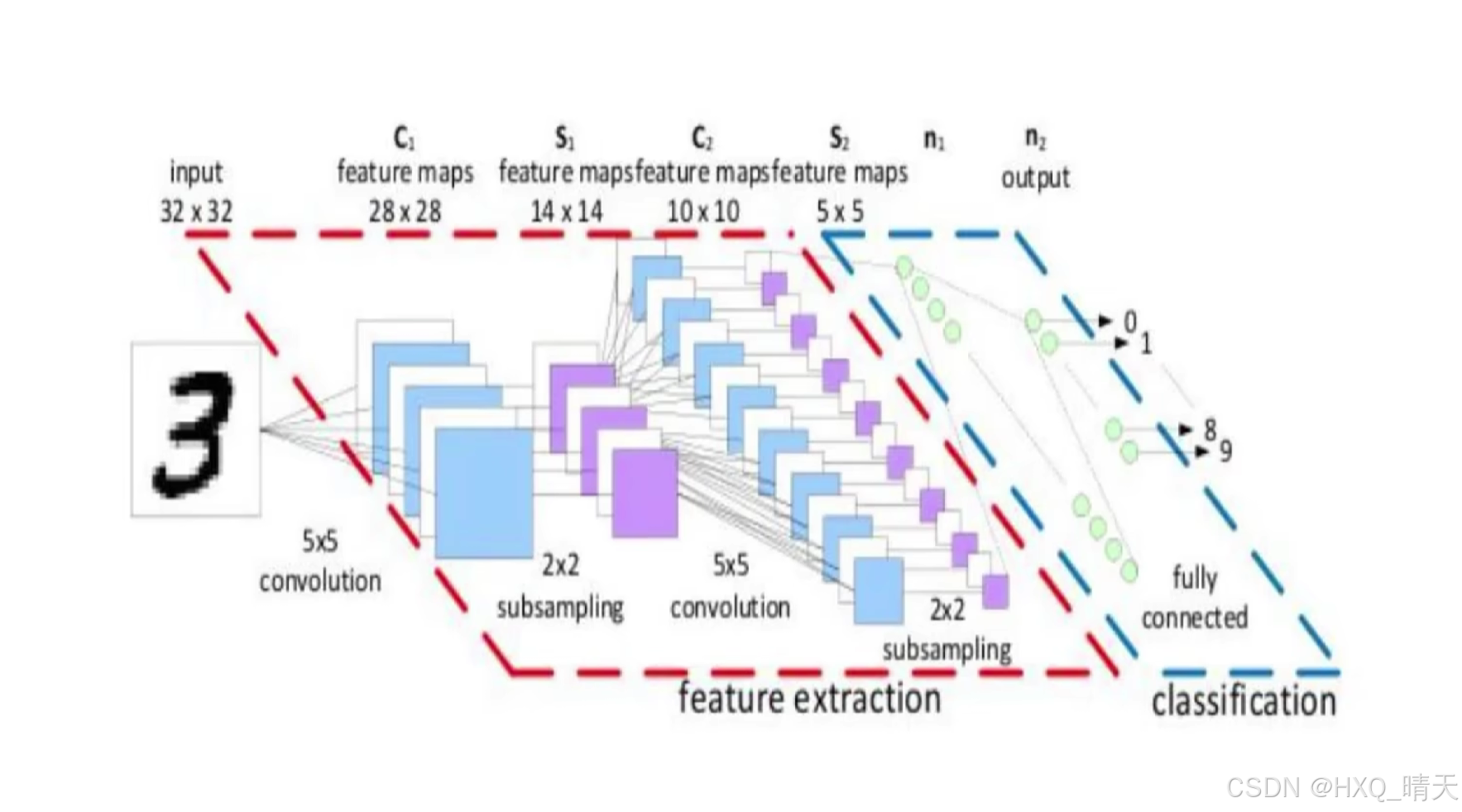
一、卷积神经网络
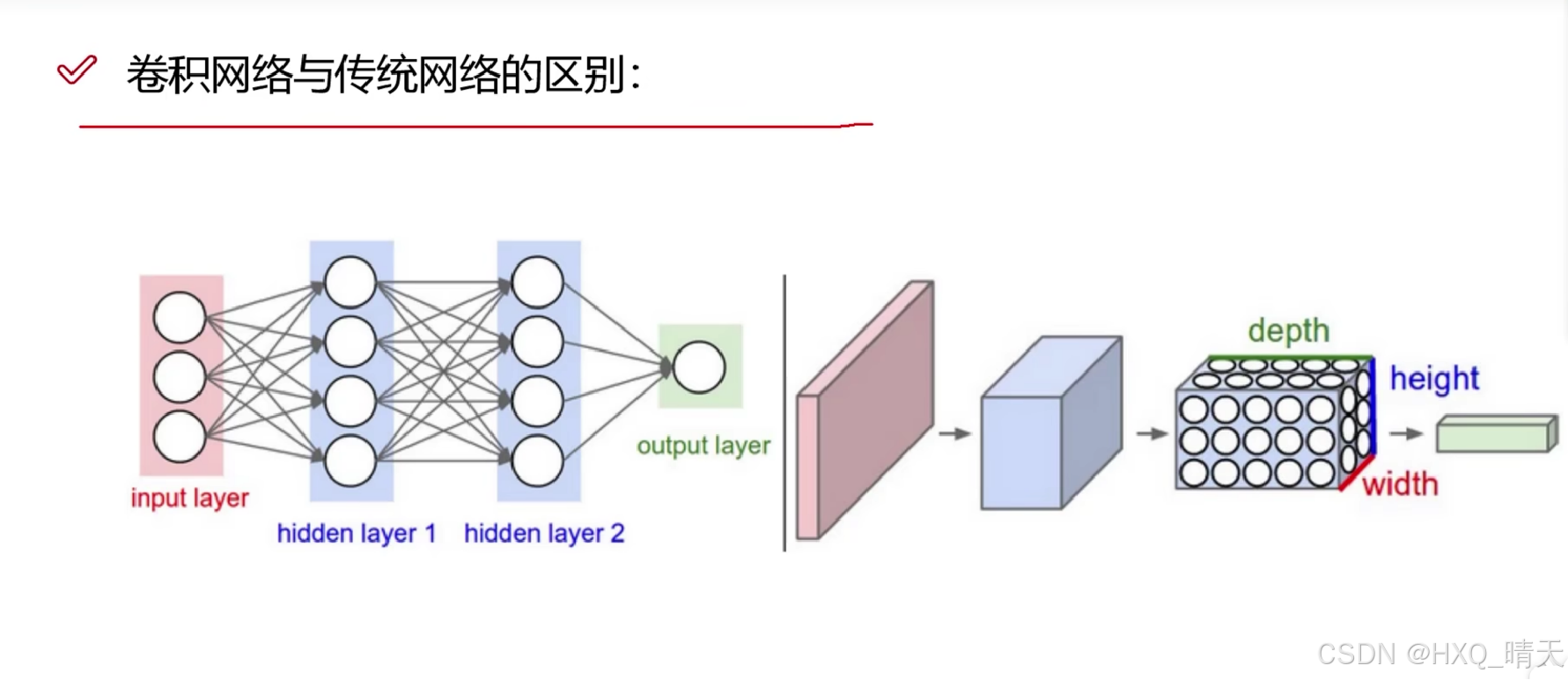
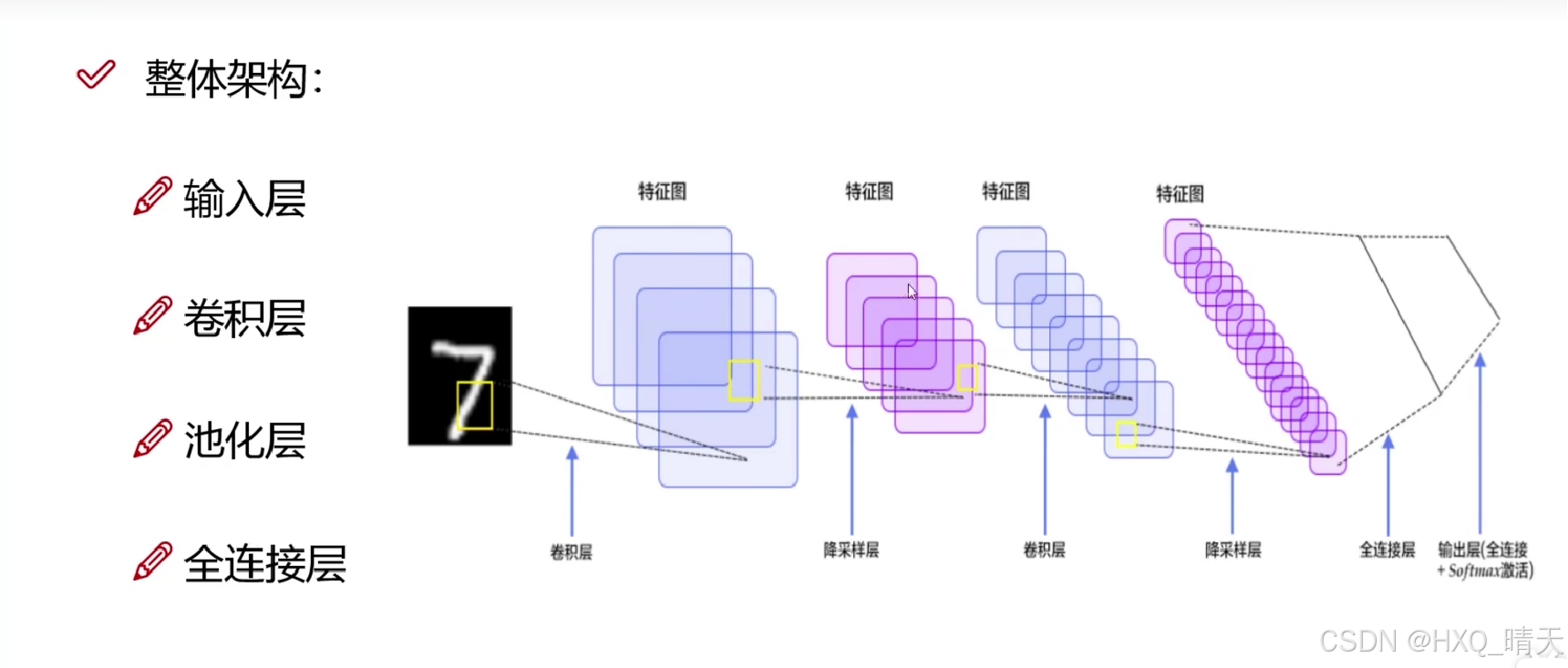
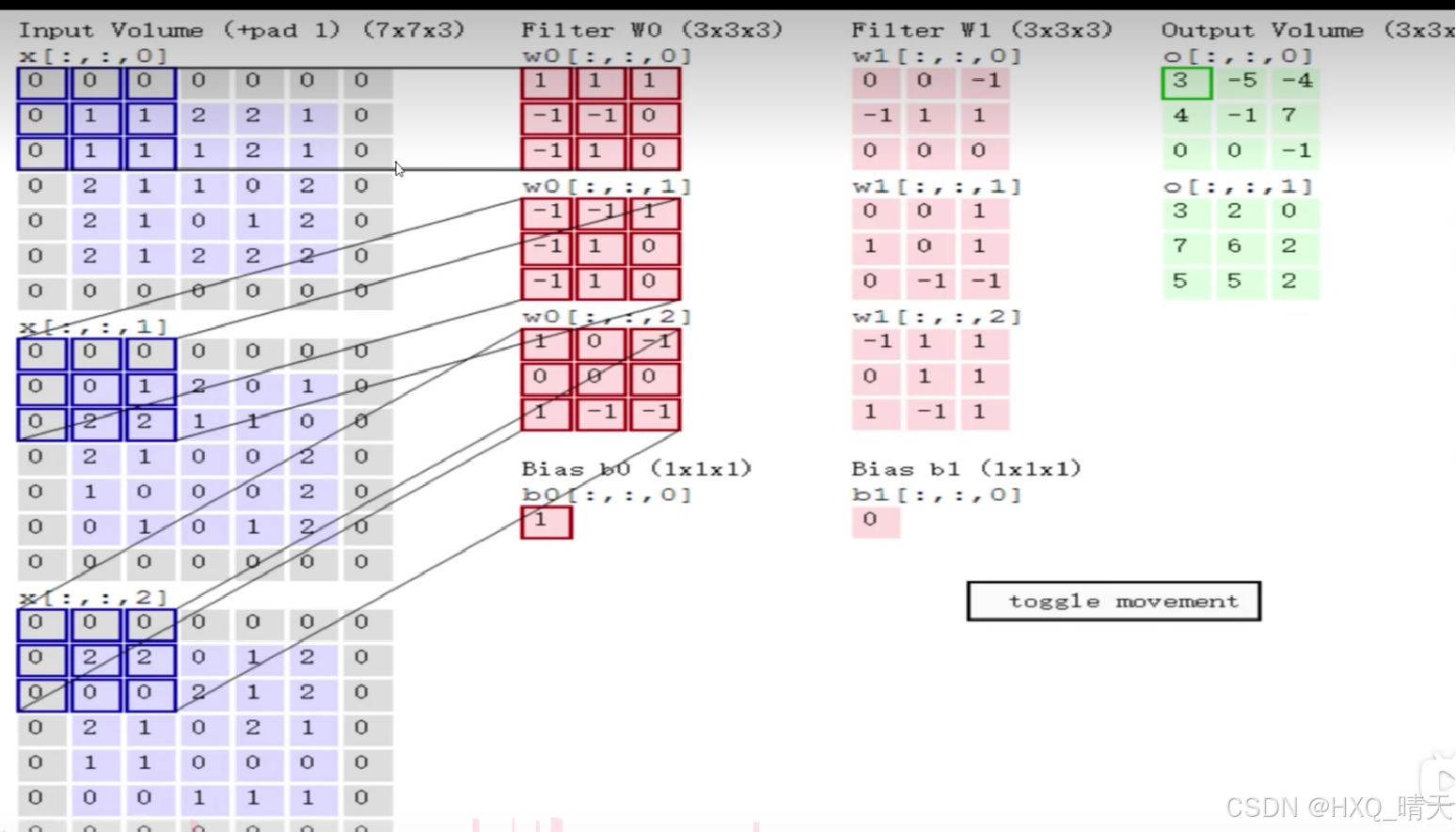

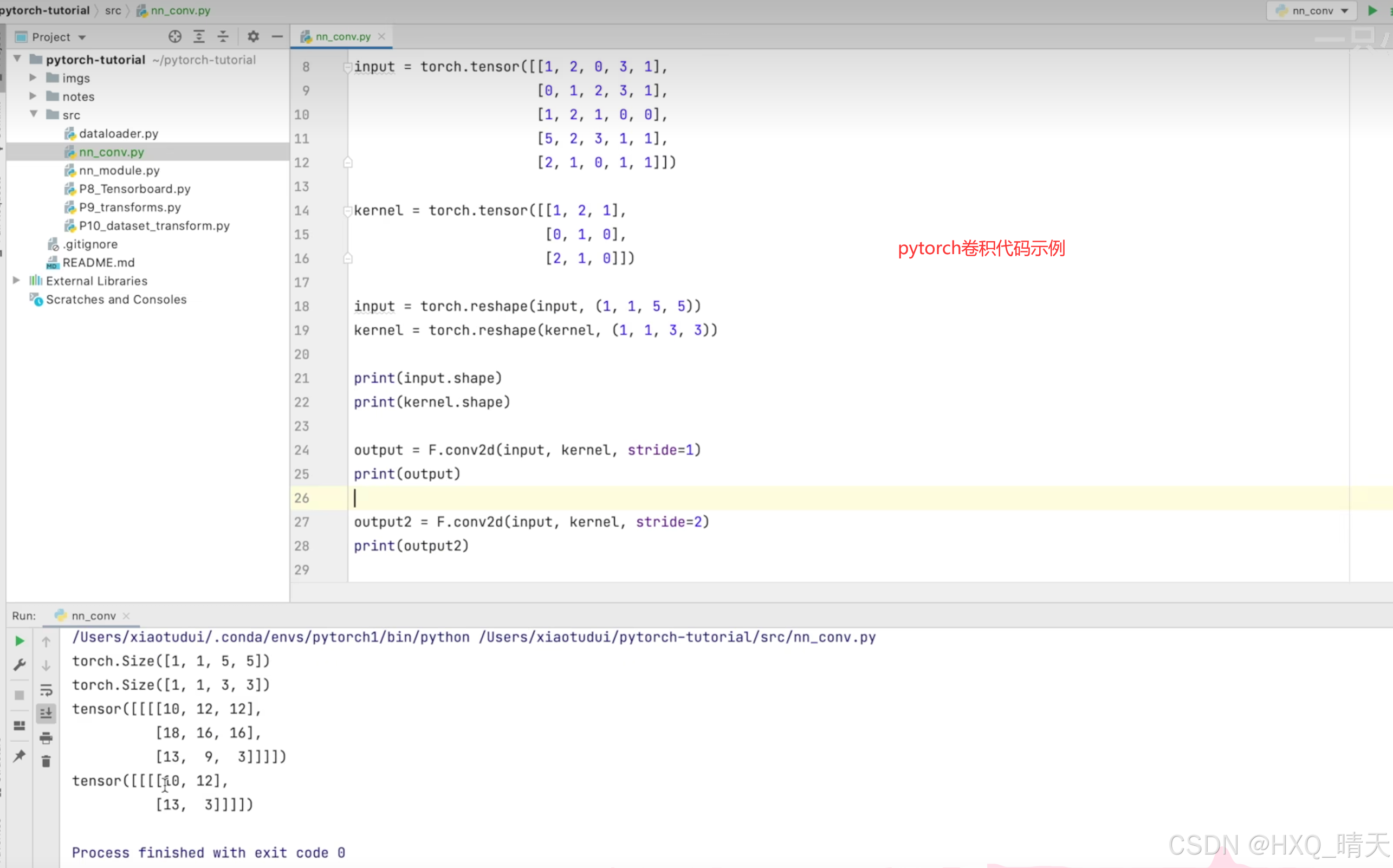
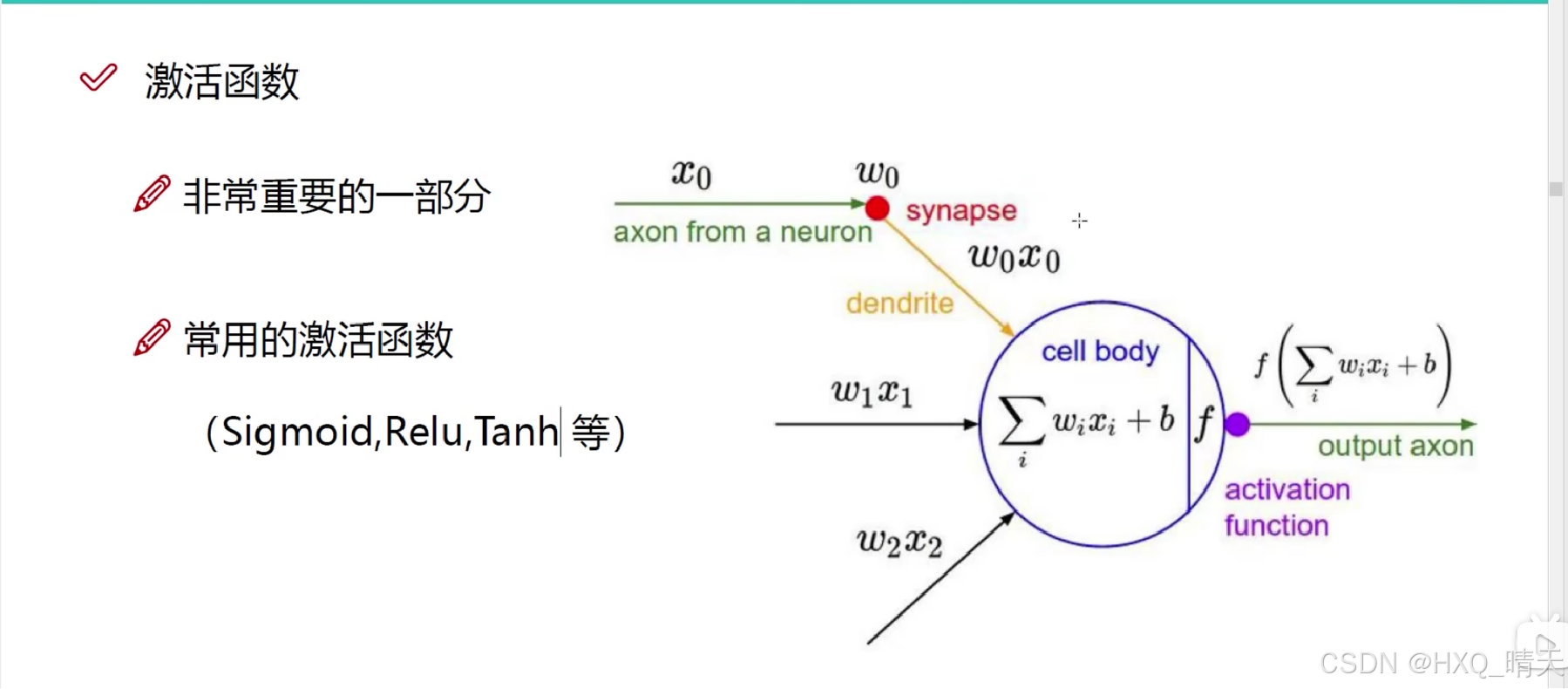
经过权重参数计算之后,进行一次非线性变换,通过在每一层中使用激活函数,可以增加网络的深度和复杂性,使网络能够学习更复杂的特征。
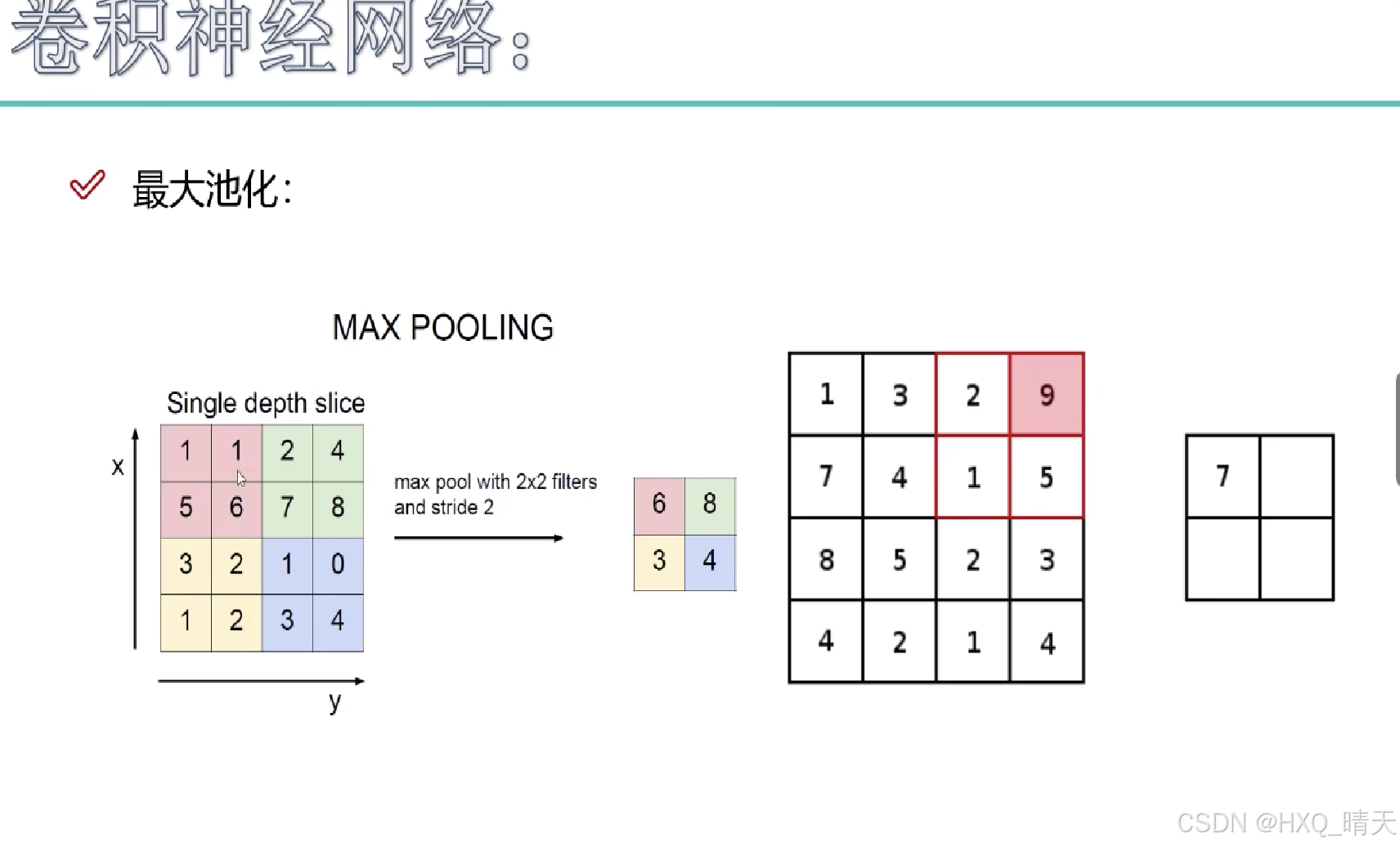
整体架构
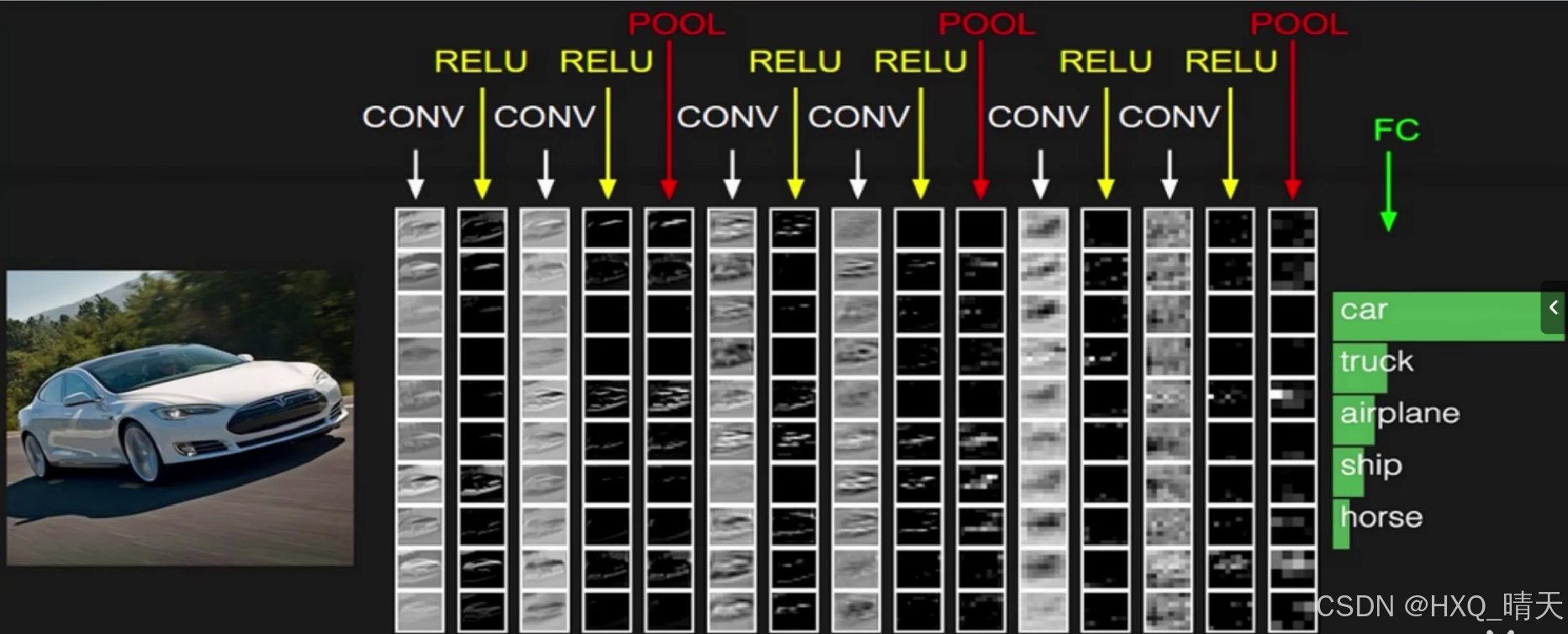
二、残差网络ResNet
何凯明等人在2015年提出的ResNet,在ImageNet比赛classification任务上获得第一名,获评CVPR2016最佳论文。因为它“简单与实用”并存,之后许多目标检测、图像分类任务都是建立在ResNet的基础上完成的,成为计算机视觉领域重要的基石结构。
自从深度神经网络在ImageNet大放异彩之后,后来问世的深度神经网络就朝着网络层数越来越深的方向发展。直觉上我们不难得出结论:增加网络深度后,网络可以进行更加复杂的特征提取,因此更深的模型可以取得更好的结果。 但事实并非如此,人们发现随着网络深度的增加,模型精度并不总是提升,并且这个问题显然不是由过拟合(overfitting)造成的,因为网络加深后不仅测试误差变高了,它的训练误差竟然也变高了。作者提出,这可能是因为更深的网络会伴随梯度消失/爆炸问题,从而阻碍网络的收敛。作者将这种加深网络深度但网络性能却下降的现象称为退化问题(degradation problem)
当传统神经网络的层数从20增加为56时,网络的训练误差和测试误差均出现了明显的增长,也就是说,网络的性能随着深度的增加出现了明显的退化。ResNet就是为了解决这种退化问题而诞生的。
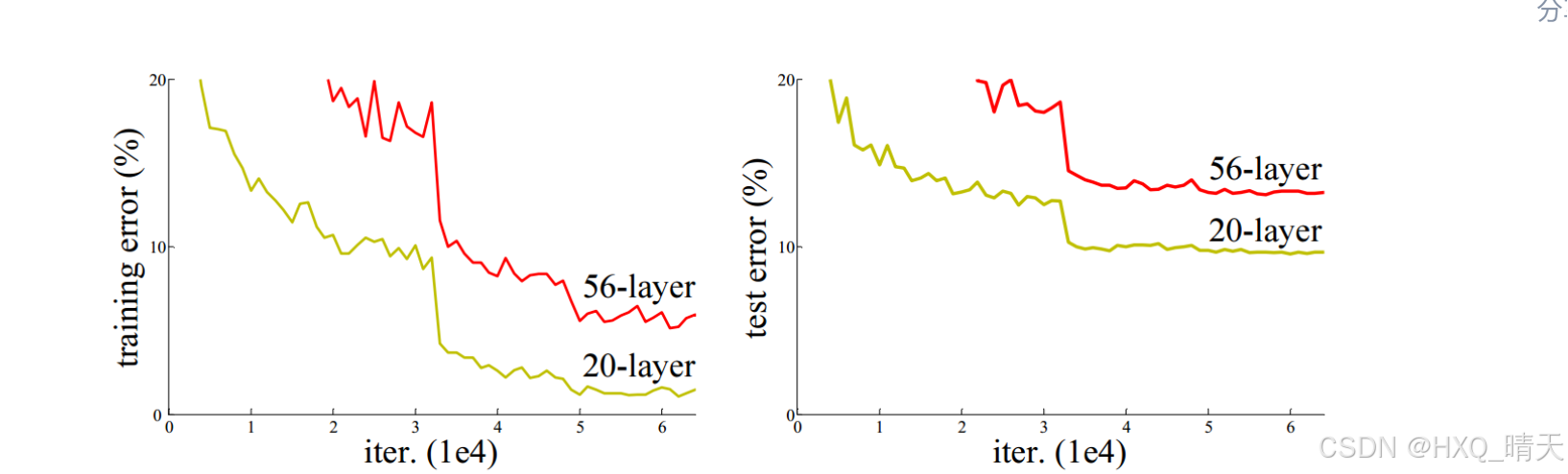
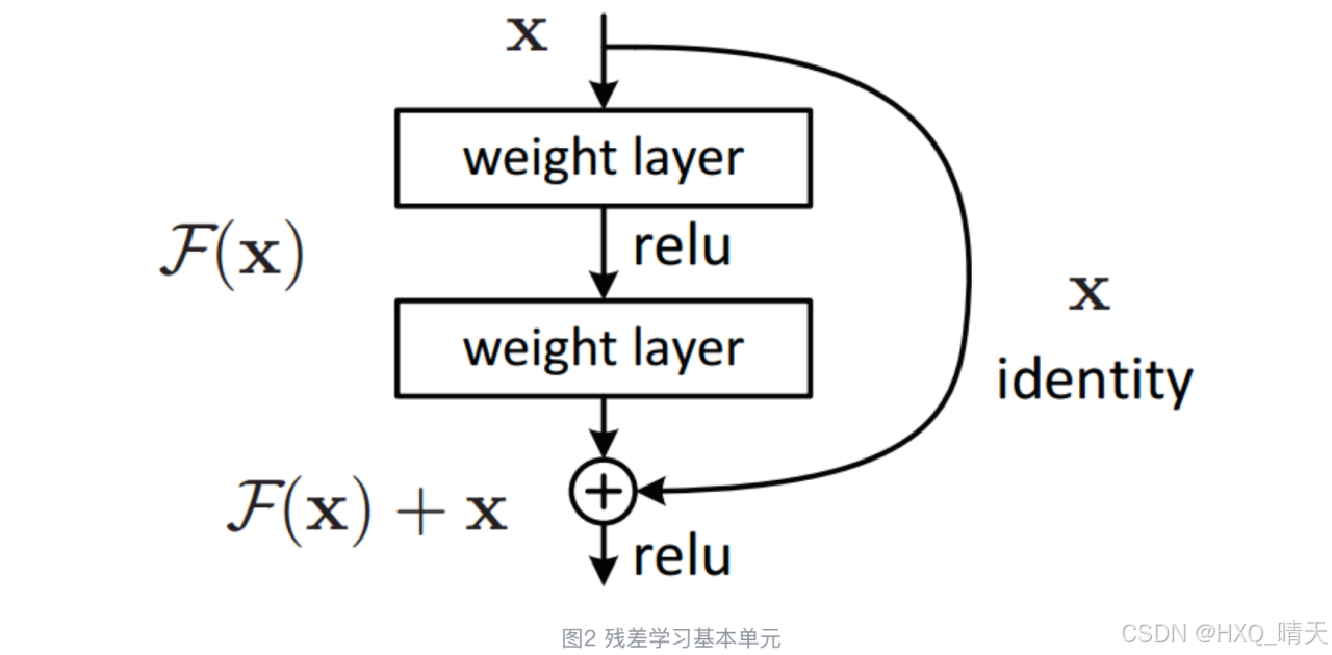
构建恒等映射(Identity mapping)来解决这个问题。增加网络层数,但训练误差不增加。20层的网络是56层网络的一个子集,56层网络的解空间包含着20层网络的解空间。如果我们将56层网络的最后36层全部短接,这些层进来是什么出来也是什么(也就是做一个恒等映射),那这个56层网络不就等效于20层网络了吗,至少效果不会相比原先的20层网络差吧。同样是56层网络,不引入恒等映射为什么就不行呢?因为梯度消失现象使得网络难以训练,虽然网络的深度加深了,但是实际上无法有效训练网络,训练不充分的网络不但无法提升性能,甚至降低了性能。
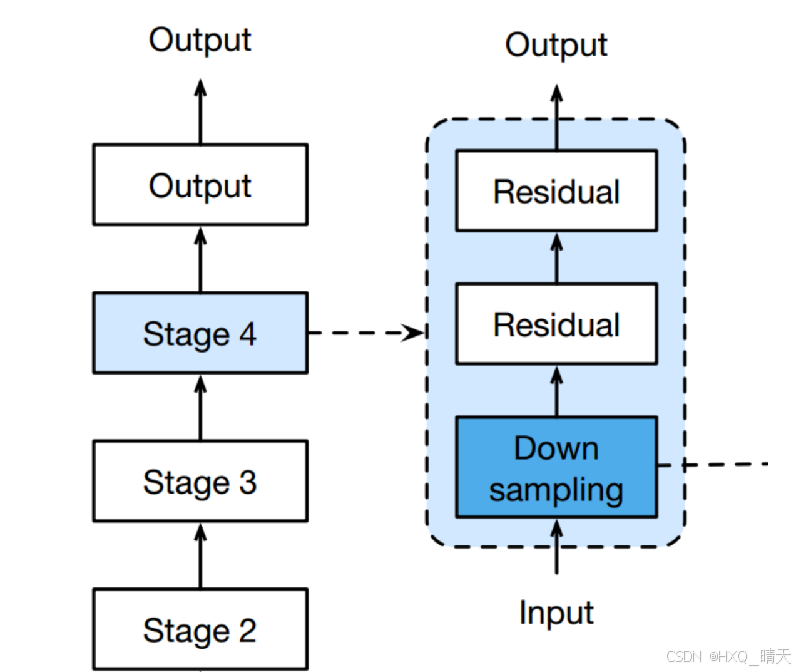
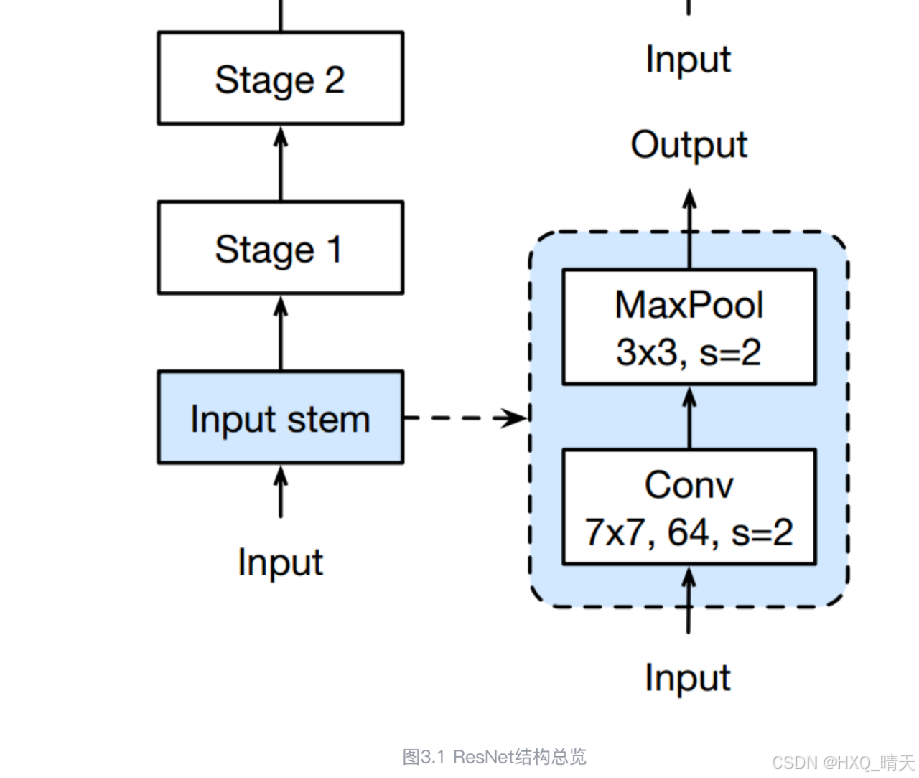
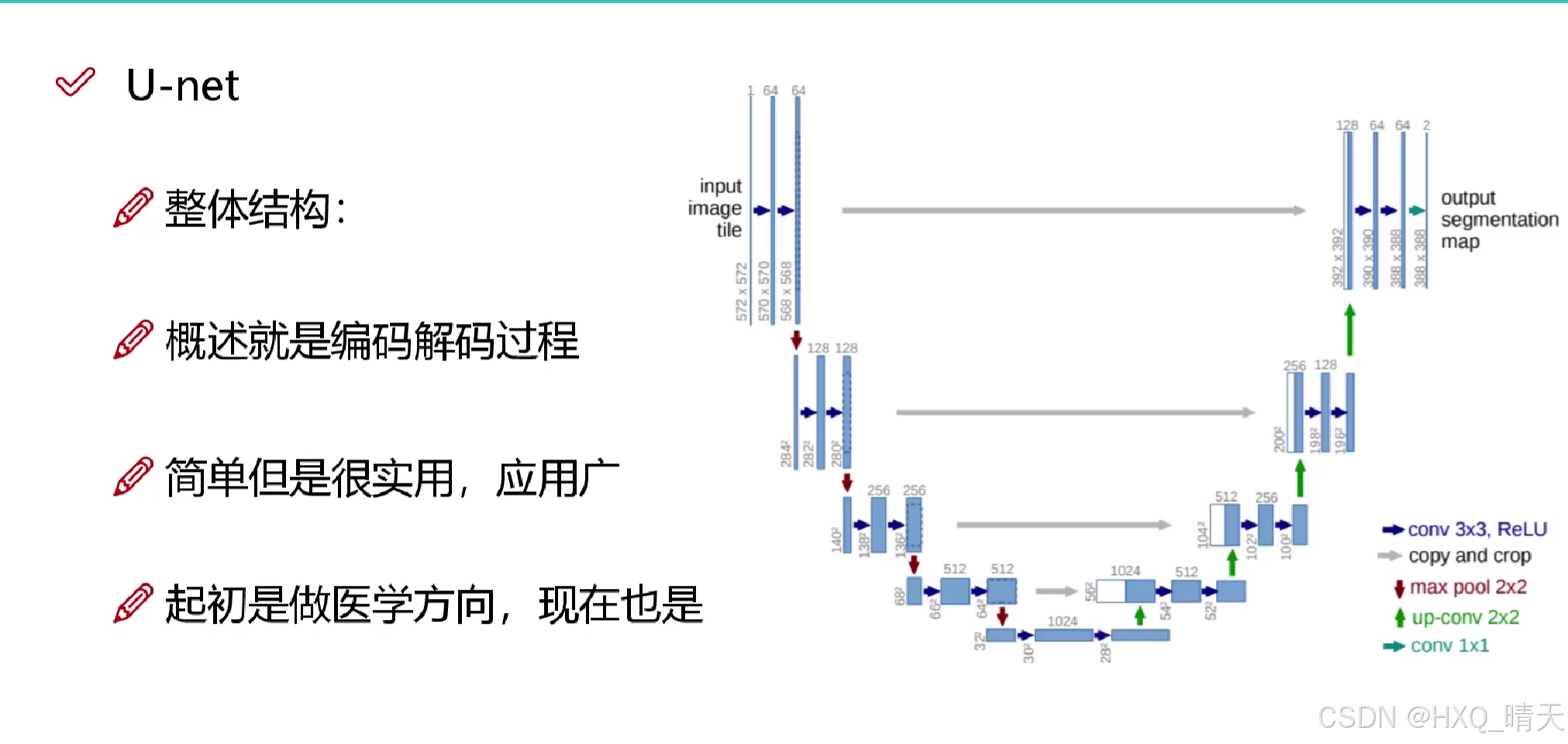
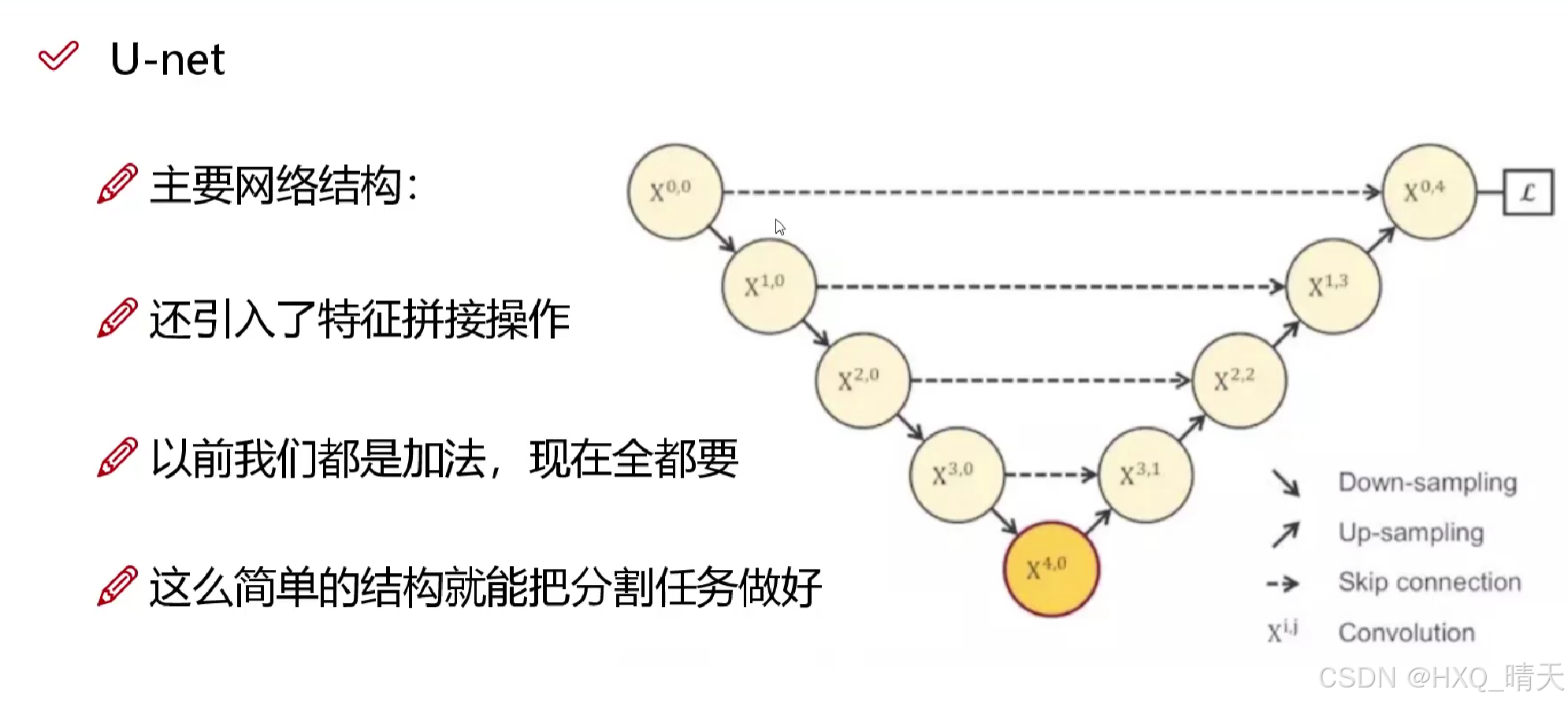
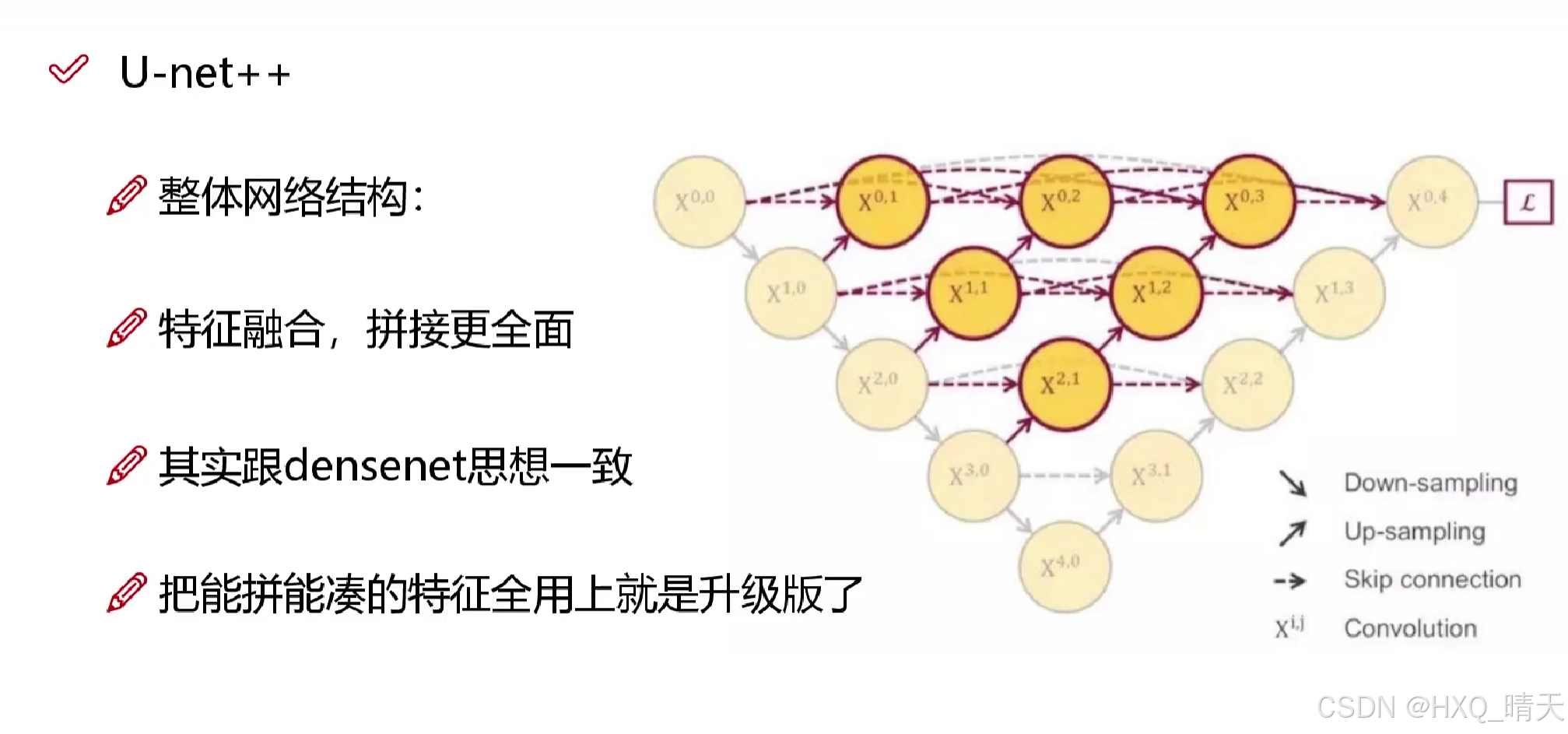
三、. U-Net