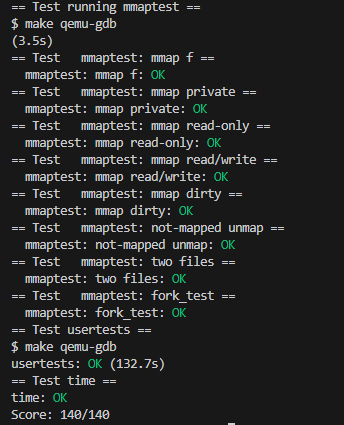
MIT 6.S081 Lab11:mmap
Lab: mmap
这个实验的本质就是实现mmap和munmap的系统调用。
mmap介绍和用途
mmap系统调用是UNIX系统一个十分强大的功能,给用户进程规划自己地址空间的一个强大工具,具体内容可以要求内核将一个文件或者其他对象直接映射到该进程的虚拟地址空间中。
具体函数原型如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);-
addr:建议的起始地址。进程可以建议一个希望映射开始的虚拟地址。通常设置为NULL,让内核自动选择一个合适的地址。如果非空,内核会尽量满足,但不会保证。 -
length:映射区域的长度,单位是字节。 -
prot:保护模式,指定了对映射内存的访问权限。可以是以下值的组合:-
PROT_READ:页面可读。 -
PROT_WRITE:页面可写。 -
PROT_EXEC:页面可执行。 -
PROT_NONE:页面不可访问。
-
-
flags:控制映射行为的标志。这是mmap强大功能的关键。重要的标志包括:-
MAP_SHARED:共享映射。对映射区域的修改会写回到文件中,并且对其他映射了同一文件的进程是可见的。这是实现进程间通信(IPC)的基础。 -
MAP_PRIVATE:私有映射。会创建一个写时复制 的映射。对映射区域的修改不会写回文件,并且对其他进程不可见。进程最初会看到文件的原始内容,但当它尝试写入时,会为该页面创建一个私有副本,所有修改都发生在副本上。这通常用于加载动态库或初始化一段内存。 -
MAP_ANONYMOUS/MAP_ANON:匿名映射。此时不需要文件描述符(fd设为 -1)。它映射的不是文件,而是一块由内核初始化为零的物理内存。常用于分配大块内存(类似于malloc,但更底层)。
-
-
fd:文件描述符。代表要映射的文件。如果使用MAP_ANONYMOUS,此参数应设为 -1。 -
offset:文件偏移量。指定从文件的哪个位置开始映射,必须是系统页大小的整数倍。
mmap在操作系统中的用途非常广泛,具体用途如下:
1.首先是简化了文件操作,相比于传统的read/write操作,mmap使得进程可以直接操作内存从而实现操作文件的目的,简化流程也提高了效率。
2.MAP_SHARED共享映射,是实现IPC之间的基石。通过将同样一个文件或者匿名文件共享映射给不同的进程中,实现了进程间的通信,这也是共享内存的逻辑。(进程间通信还包括管道(匿名管道支持有亲缘关系的进程,命名管道支持无亲缘关系的进程)、共享内存、消息队列(内核维护一个消息链表,每个消息由类型和优先级,进程通过消息队列标识访问)、信号、套接字等)。
3.MAP_ANON匿名映射,当程序申请较大空间时,不从堆区通过sbk系统调用申请,而是通过mmap匿名映射一块物理内存,通过延迟分配等技巧供进程使用。
实验思路和实现
本次实验并没有要求我们实现全部的mmap功能,规定addr恒等于0,也就是完全由内核决定将文件映射到进程的哪个虚拟地址。
回顾进程的虚拟地址空间,如下图:
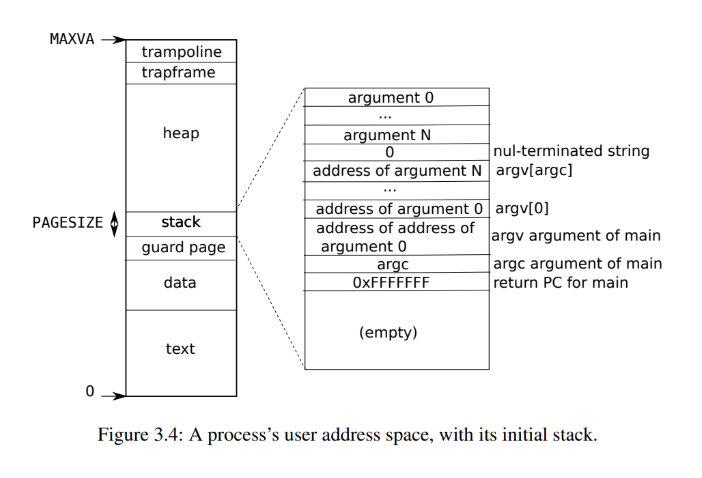
除了堆区和栈区,其余的空间都不太好塞,并且发现栈区全部只有一个PAGESIZE,可能不够文件放的,我们只能放到堆区。但堆区进程自己使用的时候是从下到上生长的,我们不可能和他同样的生长方式或者在中间,最好的方式从trapframe从上往下生长,这样尽可能做到不冲突。
之后我们根据提示创建一个VMA的结构,考虑这个区域是个进程使用的,我们创建在proc.h中并将其添加到进程数组中,代码如下:
struct mmap_vma
{uint64 addr; //起始首地址uint64 length; //长度int prot; //权限int flags; //私有映射还是共享映射struct file *fd; //映射的文件int used; //是否在使用
};#define VMA_SZ 16struct proc {...struct mmap_vma mmap_vmas[VMA_SZ]; //VMA数组
};接下来逐步实现sys_mmap系统调用,总体思路就是先接受参数,之后在进程的虚拟空间中找到一块区域用作vma,最后返回首地址,具体代码如下:
uint64 sys_mmap(void )
{//系统调用第一步,首先接受所有的参数uint64 addr; //起始首地址uint64 length; //长度int prot; //权限int flags; //私有映射还是共享映射struct file *fd; //映射的文件int pfd; //进程提供的文件描述符int offset; //映射文件的偏移uint64 failed = 0xffffffffffffffff;if(argaddr(0, &addr) < 0) return failed;if(argaddr(1, &length) < 0) return failed;if(argint(2, &prot) < 0) return failed;if(argint(3, &flags) < 0) return failed;if(argfd(4, &pfd, &fd) < 0) return failed;if(argint(5, &offset) < 0) return failed;if(addr || offset) return failed; //条件检查,只要求addr和offset都为0if(!fd->writable && (prot & PROT_WRITE) && flags == MAP_SHARED) return failed; //权限检查,文件不可写,但映射过去要求写,且要求写回struct proc *p = myproc();//之后寻找一个空闲的vmaint index = -1; //空闲vma数组iduint64 sta_addr = sta_addr = get_mmap_space(length, p->mmap_vmas, &index);//映射的虚拟首地址if(sta_addr < 0 || index == -1) return failed; //函数出现问题 if(sta_addr < p->sz) return failed; //堆区空间和mmap空间冲突,地址不够用喽//修改信息p->mmap_vmas[index].used = 1;p->mmap_vmas[index].addr = sta_addr;p->mmap_vmas[index].length = length;p->mmap_vmas[index].flags = flags;p->mmap_vmas[index].prot = prot;p->mmap_vmas[index].fd = fd;filedup(fd); //最后别忘了增加file的引用次数。return sta_addr;
}这里发现有一个函数get_mmap_space,用来寻找该进程的虚拟空间的一个区域用来当作映射空间。具体的思路参照了tzyz大佬的思路,但实现略有不同。
首先明确几点,1.上方我们已经说过了,从trapframe往下作为映射空间,并且一个页不能被两个vma区域占据(不然的话释放该页就有点麻烦)。2.我这里规定的是vma的首地址和页首地址对齐。3.具体怎么找一个vma,一个方法是先寻找当前所有的vma的最低地址,然后在最低地址下方往下找,这样可以保证vma绝对不会冲突。但会引起部分空间的浪费,具体问题如下图所示:
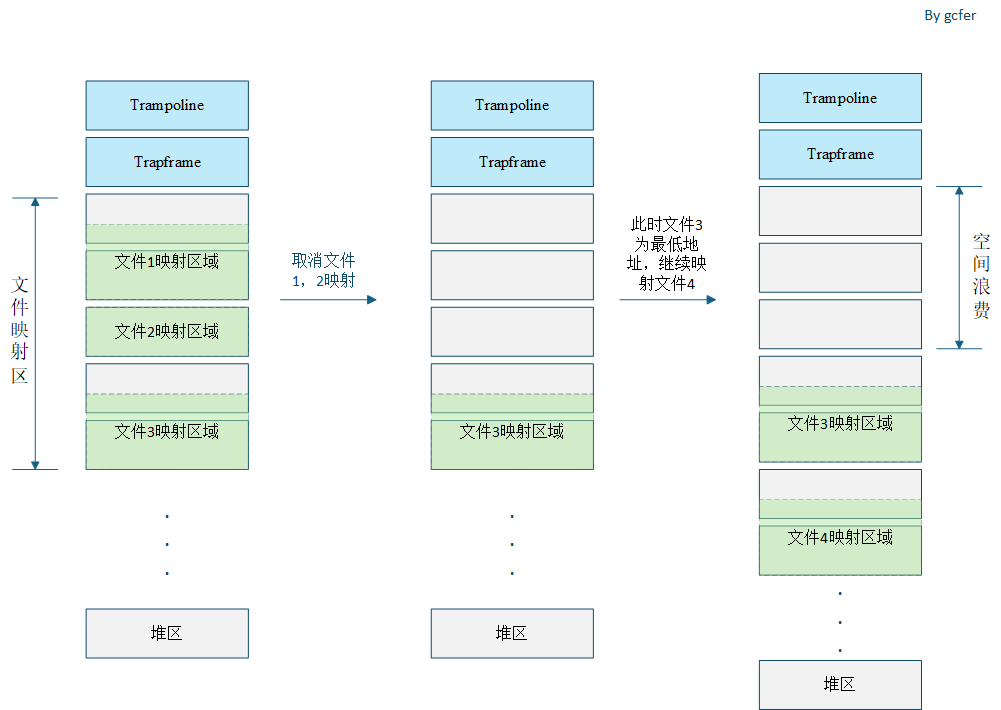
虽然一个进程的虚拟地址空间很大很大(XV6操作系统中是2^38),很难被映射区和堆区用完,但完备性的思考,这个问题还是要解决的。
解决办法:首先将所有的vma按照首地址从大到小排序,然后依次考虑每两个vma之间的间隙是否能够插入当前vma(最上方的vma考虑的是和trapframe的间隙),倘若所有间隙都不够插入,则在最下方vma往下生长的插入vma。
具体代码如下:
//去进程的虚拟地址空间中找到一个区域,进行映射,返回首地址且首地址需要和页对齐
uint64 get_mmap_space(uint64 length, struct mmap_vma *vma, int *index)
{//最普遍的思路是寻找已有的vma的最小地址,再往后找即可,但这样上方的vma地址被取消映射就浪费掉了//所以这里先将所有的vma的起始地址按照从大到小排序,先看间隙中能否插入//1.先将vma数组排序,就16个,采用冒泡排序int i,j;for(i = 0; i < VMA_SZ - 1; i++){int swap = 0;for(j = 0; j < VMA_SZ - 1; j++){if(!vma[j + 1].used) continue; //如果后面那个没使用,直接跳过if(!vma[j].used || vma[j].addr < vma[j+1].addr) //小的往后放.{struct mmap_vma tmp = vma[j];vma[j] = vma[j+1];vma[j+1] = tmp;swap = 1;}}if(!swap) break; //当没有发生交换时直接退出}if(vma[VMA_SZ - 1].used) return -1; //由于从大到小排序,如果最后一个都被使用了直接返回-1*index = VMA_SZ - 1; //取最后一个的编号//2.枚举间隙,考虑当前vma区域和上个之间的间隙是否能够插入lengthuint64 last_addr = TRAPFRAME;for(i = 0; i < VMA_SZ; i++){if(vma[i].used){//这里的PGROUNDUP(vma[i].addr + vma[i].length)是往上找第一个页首地址 + 当前需要长度//即顶部的地址(未达到)<= 上一个的起始地址说明间隙可以if(PGROUNDUP(vma[i].addr + vma[i].length) + length <= last_addr)return PGROUNDUP(vma[i].addr + vma[i].length);}else //之后都是未使用的,直接break;break;last_addr = vma[i].addr;}//3.间隙不够,只能往下找一个last_addr = PGROUNDDOWN(last_addr); //由于不同的vma不可共用同一个页,所以这里先取到这个页的首地址return PGROUNDDOWN(last_addr - length);//这里直接返回页首地址即可。}系统调用这一块写完了,目前发现mmaptest第一个f还无法通过,因为还没有在trap中实际分配页面,和虚拟内存中的lazy allocation和copy on write类似,先在usertrap中做如下操作:
//这里识别是读取和写页错误,并且是mmap区域的页错误else if((r_scause() == 13 || r_scause() == 15) && get_mmap_index(p, r_stval()) != -1){// printf("mmaptest!!!!!!!");if(mmap_fault_handler(p, r_stval()) < 0) bad = 1;}else {bad = 1;}if(bad == 1) {printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());p->killed = 1;}以上增加了bad,方便调试用的。
接着get_mmap_index函数就是寻找当前虚拟地址是否是当前进程的vma区域中的,是的话返回索引下标,否则返回-1,代码也很简单就是遍历一下当前进程的vma数组查找即可,如下:
//返回该地址属于哪个vma,没有返回-1
int get_mmap_index(struct proc *p, uint64 addr)
{int i;for(i = 0; i < VMA_SZ; i++) //遍历所有的vma,查看是否在其中{if(addr >= p->mmap_vmas[i].addr && addr < p->mmap_vmas[i].addr + p->mmap_vmas[i].length)return i;}return -1;
}随后mmap_fault_handler就是具体给当前地址所在页分配一个物理页面,具体逻辑在代码中有详细的注释,这里比较坑的点在于用户要求映射的空间>文件大小,所以从文件中读取数据加载到物理页时可能读不到东西,这里要允许读不到东西。具体代码如下:
int mmap_fault_handler(struct proc *p, uint64 addr)
{//首先判断权限对不对int index = get_mmap_index(p, addr); if((r_scause() == 13 && !(p->mmap_vmas[index].prot & PROT_READ)) ||(r_scause() == 15 && !(p->mmap_vmas[index].prot & PROT_WRITE))) {printf("mmap port filed\n");return -1;}//接着分配一个实际的物理页uint64 *pa = kalloc(); if(!pa){printf("kalloc failed!\n");return -1;} memset(pa, 0, PGSIZE); //物理页清空//接下来将文件中的内容搬到此物理页addr = PGROUNDDOWN(addr); //虚拟地址找到页首地址uint64 offset = addr - p->mmap_vmas[index].addr; //距离文件的偏移ilock(p->mmap_vmas[index].fd->ip); //要读取文件中的内容,首先要获取该inode节点的锁//这点注意,因为可能映射的空间大于文件大小,所以可能读取内容不足一页设置可能不读取(当offset>=文件大小时)if(readi(p->mmap_vmas[index].fd->ip, 0, (uint64)pa, offset, PGSIZE) < 0){iunlock(p->mmap_vmas[index].fd->ip);printf("readi from file filed!\n");return -1;} iunlock(p->mmap_vmas[index].fd->ip); //这里inode节点使用完毕需要释放锁//最后将虚拟地址和物理地址在页表中映射//PTE的权限int perm = PTE_U | PTE_V;if(p->mmap_vmas[index].prot | PROT_READ) perm |= PTE_R;if(p->mmap_vmas[index].prot | PROT_WRITE) perm |= PTE_W;if(p->mmap_vmas[index].prot | PROT_EXEC) perm |= PTE_X;//将虚拟地址和物理地址进行关联if(mappages(p->pagetable, addr, PGSIZE, (uint64)pa, perm) < 0){printf("mappages filed\n");kfree(pa);return -1;}return 0;
}随后继续mmaptest测试发现第一个f还是过不了,但报错的原因是munmap还没有实现,那继续实现munmap,主要思路:接收参数,判断操作是否合法(不可以中间挖洞),将数据写回,以及修改vma区域信息。代码如下:
int munmap(uint64 addr, uint64 length)
{//判断操作是否合法struct proc *p = myproc();int index = get_mmap_index(p, addr);if(index == -1 || addr < p->mmap_vmas[index].addr || addr + length > p->mmap_vmas[index].addr + p->mmap_vmas[index].length){printf("addr length exceed!");return -1;} //将addr开始长度为len的写回并取消映射,这里用一个函数表示了if(mmap_writeback(addr, length, index) < 0){printf("sys_munmap failed!!\n");return -1;}//修改vma块的信息if(p->mmap_vmas[index].addr == addr) //起点相等{p->mmap_vmas[index].addr = addr + length;}p->mmap_vmas[index].length -= length;if(p->mmap_vmas[index].length <= 0) //释放完了{p->mmap_vmas[index].used = 0; //不使用了fileclose(p->mmap_vmas[index].fd); //文件引用减少}return 1;
}//取消映射
uint64 sys_munmap(void)
{//接受参数uint64 addr; //起始首地址uint64 length; //长度if(argaddr(0, &addr) < 0) return -1;if(argaddr(1, &length) < 0) return -1;//调用munmapreturn munmap(addr, length);
}这里分成两块,将munmap封装成函数(放在vm.c中),之后会用到,先这样写。
其中文件写回逻辑较为复杂,单独用一个函数处理,由于该函数负责将虚拟空间的数据返回文件,所以放在vm.c中,他的思路是假设addr和length都是PGSIZE的倍数(mmaptest中的确如此),枚举每一页找到其pte,查看脏位PTE_D(需要自己定义,具体参考RISC-V手册)并根据映射区的prot是否为MAP_SHARED决定是否写回。其中两点需要注意:1.设计文件操作,注意事务和锁的使用。2.这里写回同理,当映射区>文件大小时,无法写入足够的数据,要允许不写完。具体代码如下:
//把带脏位的页帧写回文件,并且取消映射.
//三个参数分别代表起始地址,长度和在vma中的索引
//这里假设addr和length都是PGSIZE的倍数,方便处理
uint64 mmap_writeback(uint64 addr, uint64 length,int index)
{struct proc *p = myproc();uint64 a;for(a = addr; a < addr + length; a += PGSIZE) //枚举每一页{pte_t *pte = walk(p->pagetable, a, 0);if(!pte || !((*pte) & PTE_V)) //两种情况,指针没有或者内容没有continue;//如果需要写回if((p->mmap_vmas[index].flags & MAP_SHARED) && (*pte) & PTE_D){uint64 offset = a - p->mmap_vmas[index].addr; //计算偏差//这里设计文件系统,事务,上锁等begin_op();ilock(p->mmap_vmas[index].fd->ip);writei(p->mmap_vmas[index].fd->ip, 1, a, offset, PGSIZE); //这里和映射的问题相同,可能写不回那么多数据,映射区>文件大小时iunlock(p->mmap_vmas[index].fd->ip);end_op();}//将该物理页释放uint64 pa = PTE2PA(*pte);kfree((uint64*)pa);//取消映射*pte = 0;}return 0;
}继续跟随提示,去修改exit中的内容。
但是这里为什么要修改exit中的内容呢???
这里查看了kernel/proc.c中的exit()和wait()函数以及user/init.c程序,大致捋出来了程序回收的全流程,具体如下图所示:
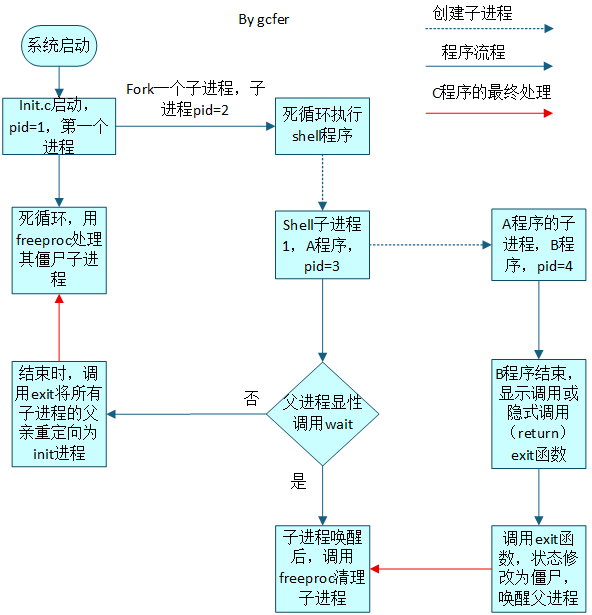
可以观察到对于程序C而言,程序自身结束一定会先调用exit函数,这个函数主要清理进程用户层级的数据(即用户进程能够看见的),比如映射的文件,子进程的管理(将子进程重定向给init进程)等。之后若父进程显性调用wait,则父进程调用freeproc,否则父进程消亡时会将子进程C给init进程,init进程会调用freeproc。总的来说,C进程的父进程(fork创建时的父进程或者init进程)会调用freeproc清理C进程,freeproc主要清理的就是该进程的内核级数据,包括但不限于内存页的释放,trampoline、trapframe的释放、进程表的清理等。
所以这里就清楚了,mmap映射区域这一块属于进程用户层的数据,所以当进程销毁时,要在exit释放所有的映射区。
在exit使用munmap函数了(这就是之前将munmap分开的理由),具体添加如下:
//这里枚举当前进程的所有vma块,取消映射,//注意,这里放到释放文件之前,因为写回需要用到文件int i;for(i = 0; i < VMA_SZ; i++){if(p->mmap_vmas[i].used){munmap(p->mmap_vmas[i].addr, p->mmap_vmas[i].length);}}这样就可以通过mmaptest测试。
但fork test还没通过,原因在于fork时我们需要将父进程的映射区都放到子进程中,这个也很简单,在fork中添加如下代码:
//遍历父进程的所有vma区域,有就拿过来for(i = 0; i < VMA_SZ; i++){if(p->mmap_vmas[i].used) //这里所有信息都拿过来{np->mmap_vmas[i].used = p->mmap_vmas[i].used;np->mmap_vmas[i].addr = p->mmap_vmas[i].addr;np->mmap_vmas[i].length = p->mmap_vmas[i].length;np->mmap_vmas[i].prot = p->mmap_vmas[i].prot;np->mmap_vmas[i].flags = p->mmap_vmas[i].flags;np->mmap_vmas[i].fd = p->mmap_vmas[i].fd;filedup(np->mmap_vmas[i].fd); //同时子进程也引用了该文件,增加引用次数。}}即可通过fork test。此外,提示中还提到,最简单的写法就是上述这样,仅仅将vma搬过去,当子进程缺页时单独分配物理页。但发现这种情况和之前的实验Copy-on-Write Fork相同,完全可以父进程和子进程共享同一个物理页,也就是仅当某个进程某个地址用到时才分配物理页供父子进程共享,完全可以但懒得实现了。(浅浅思考下,细节还是有点多的。。。)
完结撒花!!!结果图如下: