[论文阅读] AI+SRE(网站可靠性工程) | 字节跳动ErrorPrism:微服务错误追踪准确率97%!告别日志“一团乱麻”
字节跳动ErrorPrism:微服务错误追踪准确率97%!告别日志“一团乱麻”
论文信息
- 论文原标题:ErrorPrism: Reconstructing Error Propagation Paths in Cloud Service Systems
- 主要作者及研究机构:核心团队来自字节跳动
- 发表情况:accepted by the 40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025
- 论文链接:https://arxiv.org/pdf/2509.26463
一段话总结
为解决云服务微系统中因错误包装(函数逐层添加错误上下文形成错误链)导致的错误混淆(日志扁平化掩盖错误传播路径)问题,研究者提出ErrorPrism框架——通过静态分析(构建函数调用图、提取错误相关字符串并计算传递闭包,大幅缩减搜索空间)与LLM代理(基于ReAct框架迭代反向搜索,结合代码语义消歧)的混合架构,实现错误传播路径的自动化重建。在字节跳动67个生产微服务的102个真实错误上评估,ErrorPrism准确率达97.0%,显著优于传统静态分析(90.7%精度)和其他LLM-based方法(如Pure LLM 50.5%准确率),且平均推理时间仅5.93s(比字节内部通用SWE代理快8.4倍),为微服务根因分析(RCA)提供高效实用的工具。
思维导图
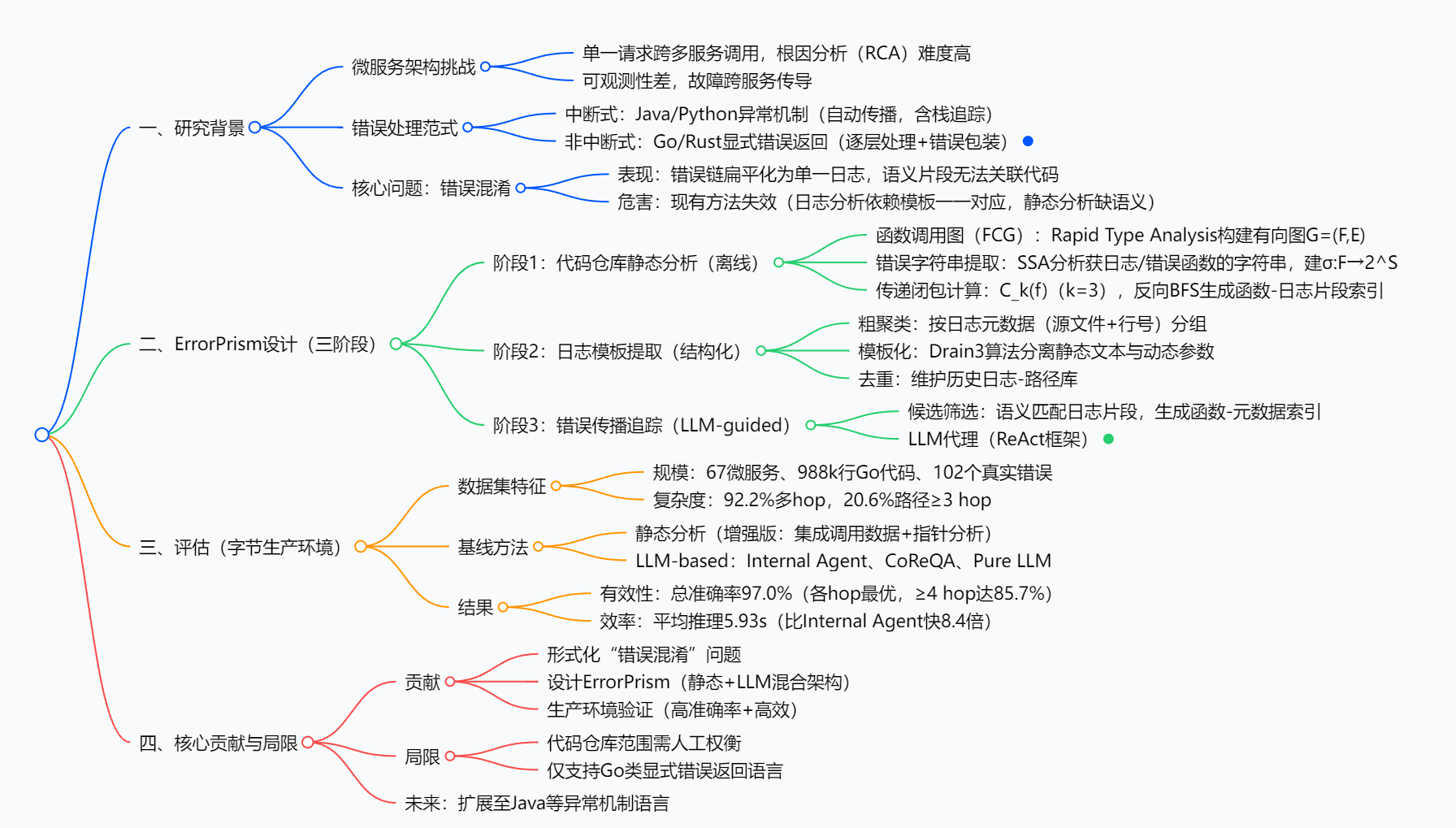
研究背景:微服务错误追踪,像在“乱麻里找线头”
你有没有过这样的经历?网购的快递丢了,只收到一句“快递派送失败”,却不知道是分拣错了、快递员漏拿了,还是地址写错了——微服务的错误追踪,比这还难。
现在的系统基本都是“微服务架构”,比如你刷短视频,一个请求要经过“推荐服务→用户服务→存储服务”好几个环节。一旦出错,每个环节的开发者都会给错误“加备注”(这就是“错误包装”):比如存储服务返回“连接超时”,用户服务加一句“查用户数据失败”,推荐服务再补一句“推荐列表生成失败”,最后日志里就只剩一句“推荐列表生成失败:查用户数据失败:连接超时”。
这串日志看起来有信息,但问题来了:
- 你不知道“连接超时”是哪个函数报的?
- 不知道“查用户数据失败”是怎么传到推荐服务的?
- 更不知道是不是中间有个异步任务断了线?
这就是“错误混淆”——错误链被压成了一行扁平日志,像把好几根线揉成了乱麻,找不到头。
之前的解决办法要么“笨”要么“瞎”:
- 传统日志分析:像只看快递单上的“派送失败”,不知道中间环节;
- 纯静态分析:能找函数调用关系,但分不清“连接超时”是哪个环节的,比如10个函数都有“连接超时”,它不知道该选哪个;
- 纯LLM:给它全量代码,它会看晕,准确率才50%,还慢得要死。
字节跳动每天要处理海量微服务日志,SRE(运维工程师)经常要花几小时手动翻代码找错误路径,急得上火——这就是ErrorPrism要解决的问题。
创新点:ErrorPrism的“独门秘籍”
ErrorPrism能在众多方法里脱颖而出,靠的是三个“不一般”:
-
“静态分析+LLM”混合拳,解决“范围”和“语义”的矛盾
传统方法要么范围太大(纯LLM看全量代码),要么不会理解语义(静态分析分不清相似错误)。ErrorPrism先用静态分析把范围缩到“几十个候选函数”,再让LLM专注看这些函数,既不费时间,又能理解语义。 -
针对“错误包装”的“传递闭包”计算
它专门为Go语言的“显式错误返回”设计了“传递闭包”:比如函数A调用B,B调用C,C有“连接超时”错误,那A和B也会被标记为“可能含连接超时相关错误”,这样就算错误被包装了,也能追到源头。 -
用生产级数据验证,不是“实验室玩具”
很多论文只用模拟数据测试,ErrorPrism直接拿字节跳动67个真实微服务、102个真实错误来测——这些错误里92%要跨多个环节追踪,20%要跨3个以上环节,和工业界实际情况完全一致,结果可信度拉满。
研究方法:ErrorPrism的“三步破案法”
ErrorPrism找错误路径,就像侦探破案,分三步走,每步都有明确目标:
第一步:静态分析(离线“画地图标重点”)
这一步是“提前准备”,不用等错误发生,离线处理代码:
- 画函数调用图:把微服务里所有函数的调用关系画成一张图,比如“推荐服务的func A调用用户服务的func B”,一目了然;
- 提错误字符串:把每个函数里的错误日志(比如“连接超时”)、错误创建语句(比如errors.New(“连接超时”))都摘出来,记下来“哪个函数有哪个错误词”;
- 算传递闭包:比如设定“最多追3层调用”,那如果func C有“连接超时”,就把调用C的B、调用B的A都标记上“可能和连接超时有关”,这样后续找错误时,不用看全量代码,只看这些标记过的函数就行。
第二步:日志模板提取(“把重复日志归大类”)
字节每天有几百万条错误日志,不可能每条都分析。这一步就是“合并同类项”:
- 按“文件+行号”分组:比如“推荐服务/log.go第100行”打印的日志,不管内容里的动态参数(如用户ID),都归为一组;
- 拆静态和动态内容:用Drain3算法把日志拆成“固定部分”(比如“查用户数据失败:%s”)和“变量部分”(比如具体的错误原因),只保留固定部分做分析;
- 存历史模板:之前分析过的模板就不再重复算,省时间。
第三步:LLM代理追踪(“侦探按线索找源头”)
这一步是“实时破案”,拿到错误日志后:
- 筛候选函数:比如日志里有“查用户数据失败”“连接超时”,就从第一步标记的函数里,找同时含这两个词的函数,形成“候选名单”;
- LLM代理迭代查:给LLM配三个“工具”:
- 看函数的传递闭包(知道这个函数的上游是谁);
- 看函数源代码(知道这个函数有没有包装错误);
- 模糊搜索(比如跨服务调用时,找RPC相关的函数);
然后LLM从“打印日志的函数”开始,反向找上游:比如先看打印“推荐列表失败”的func A,再看A调用的func B,再看B调用的func C,直到找到最早报“连接超时”的func C,形成完整路径。
实验方法与主要成果:ErrorPrism到底有多厉害?
实验设计:用真实数据说话
- 测试环境:字节跳动67个生产微服务,共98.8万行Go代码;
- 测试错误:从300万条日志里筛选出102个真实错误,其中92.2%要跨多个环节追踪,20.6%要跨3个以上环节;
- 基线方法:和4种常见方法比(增强版静态分析、字节内部SWE代理、CoReQA、纯LLM);
- 评估指标:准确率(路径对不对)、推理时间(快不快)。
核心结果:又准又快,碾压基线
| 方法 | 总准确率 | 平均推理时间 | 长路径(≥4 hop)准确率 |
|---|---|---|---|
| ErrorPrism | 97.0% | 5.93s | 85.7% |
| 增强版静态分析 | 90.7%(精度) | - | 66.1% |
| 字节内部代理 | 87.1% | 49.75s | 57.1% |
| CoReQA | 57.4% | - | 14.3% |
| 纯LLM | 50.5% | - | 0% |
实际案例:帮SRE省几小时
有一次字节控制平面告警,日志是“resource belongs to: failed to split resourceID of access policy: invalid resourceID: Delete-123-456-cluster-prod-west-a”。手动找的话,要查“splitResourceID”函数的20多个实现,还要看异步通道的错误传递,得花几小时。ErrorPrism自动追到根因:splitResourceID函数硬编码了“按横杠分割”,但集群ID里有多个横杠,导致分割失败——全程5秒搞定。
核心价值:解决工业界真痛点
- 省时间:SRE不用手动翻代码,错误定位时间从几小时缩到几秒;
- 提准确率:97%的准确率,比纯LLM高近一倍,不会指错方向;
- 能落地:直接在字节生产环境用,适配真实微服务的复杂度(跨服务、异步调用)。
关键问题:问答式理清核心逻辑
Q1:ErrorPrism是怎么解决“错误混淆”的?
A:分两步:①用静态分析“缩小范围”,通过函数调用图和传递闭包,把和错误日志相关的函数筛出来,避免看全量代码;②用LLM“理解语义”,比如日志里的“查用户数据失败”,LLM能结合函数代码,分清是“查数据库失败”还是“传参错误”,找到真正的上游函数。两者结合,既不混乱,又不盲目。
Q2:为什么选“静态分析+LLM”的混合架构,而不是只用一种?
A:只用静态分析会“认死理”——比如10个函数都有“连接超时”,它分不清哪个和当前错误有关;只用LLM会“看晕”——全量代码太多,LLM记不住调用关系,准确率低还慢。混合架构刚好互补:静态分析把范围缩到“几十个候选函数”,LLM专注看这些函数,又快又准。
Q3:ErrorPrism只支持Go语言,未来能扩展到其他语言吗?
A:目前只支持Go这类“显式错误返回”的语言(错误要手动返回,会包装)。未来计划扩展到Java、Python这类“异常机制”的语言——这类语言的错误会自动传播,有栈追踪,但栈追踪可能跨服务断裂,需要调整静态分析的逻辑,比如结合异常捕获语句来画路径。
Q4:实验用的是字节的生产数据,其他公司能用吗?
A:能。ErrorPrism的核心逻辑不依赖字节的特定环境:①静态分析部分只要能解析目标语言的代码(如Go、未来的Java),就能画调用图;②日志模板提取用的是通用的Drain3算法;③LLM代理的工具逻辑(看闭包、看代码)也能适配其他公司的代码仓库。只要接入自己的代码仓库和日志系统,就能用。
3. 详细总结
1. 引言:微服务可靠性管理的核心挑战
微服务架构虽提升扩展性,但导致故障传导复杂(单一请求触发多服务调用),根因分析(RCA)难度远超单体系统。其核心痛点源于错误处理范式差异与“错误混淆”问题:
- 错误处理范式对比:
范式类型 代表语言 处理逻辑 关键特点 中断式 Java、Python 异常中断执行流,自动传播至处理器 日志含栈追踪,无需逐层处理 非中断式(主流) Go、Rust 错误作为显式返回值,开发者需逐层处理 支持“错误包装”,添加上下文形成错误链 - 关键问题:错误混淆
- 成因:错误链被扁平化为单一日志字符串,无显式指针关联语义片段与代码位置;
- 具体问题:①路径歧义(如“operation failed”出现在多个无关函数);②跨异步/服务调用路径断裂;③开发者实践不一致(欠包装/过包装);
- 现有方法失效:
- 日志分析方法(如DeepLog):依赖“日志-模板一一对应”假设,无法适配动态错误链;
- 传统静态分析:无法处理异步/跨服务调用,缺乏语义理解能力,无法消歧。
2. 问题定义:错误传播路径重建目标
- 输入:①错误日志L(复合字符串,含多层错误上下文);②微服务源代码仓库C;
- 输出:错误传播路径(有序函数序列<fₙ, fₙ₋₁, …, f₁>),其中:
- fₙ:最终打印错误日志的函数;
- f₁:错误起源函数;
- 相邻函数fᵢ与fᵢ₋₁:存在直接/间接调用关系,fᵢ₋₁将错误传递给fᵢ。
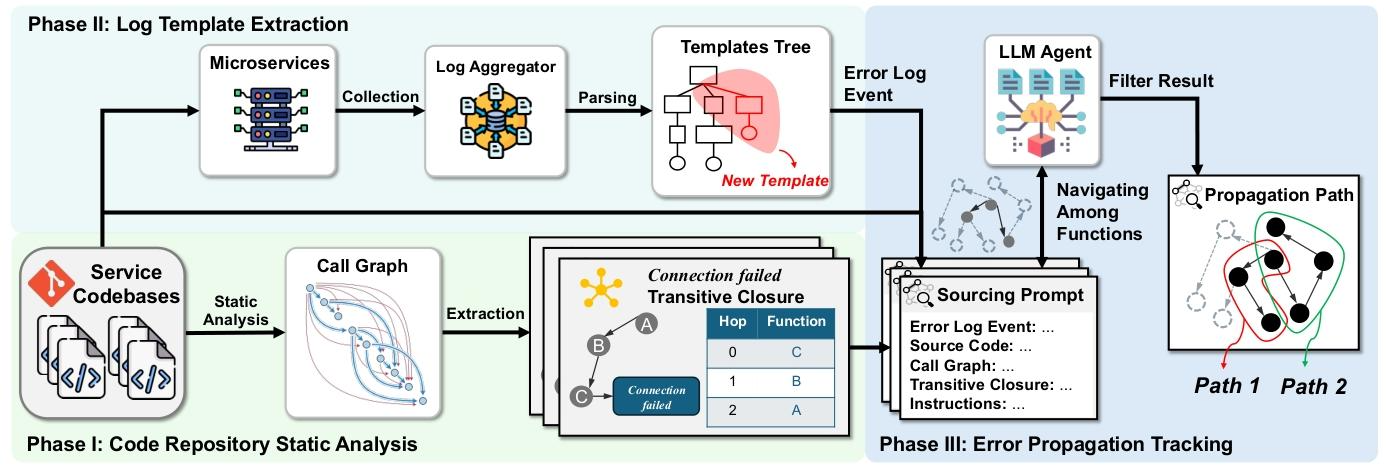
3. ErrorPrism方法论:静态分析与LLM的协同设计
ErrorPrism通过“静态分析缩减搜索空间+LLM代理语义消歧”的混合架构,分三阶段实现路径重建:
3.1 阶段1:代码仓库静态分析(离线预处理)
核心目标:将海量代码筛选为小范围候选函数,减少后续LLM推理负担。
- 步骤1:构建函数调用图(FCG)
- 算法:采用Rapid Type Analysis解析Go代码,识别函数定义与调用关系;
- 输出:有向图G=(F,E)(F为函数集合,E为调用边集合,如(fᵢ,fⱼ)表示fᵢ调用fⱼ)。
- 步骤2:提取错误相关字符串常量
- 方法:对每个函数的SSA(静态单赋值)表示进行intra-procedural数据流分析;
- 目标:提取日志语句(如logger.Error)和错误创建函数(如errors.New、fmt.Errorf)引用的字符串常量;
- 输出:映射σ:F→2^S(S为字符串常量集合,σ(f)表示函数f直接引用的错误相关字符串)。
- 步骤3:计算字符串传递闭包
- 定义:Cₖ(f)表示函数f在调用深度≤k时可间接访问的所有字符串常量(k设为3,平衡效果与效率);
- 公式:
[
\mathcal{C}{k}(f)=\left{\begin{array}{ll}
\sigma(f) & if k=0 \
\sigma(f) \cup \bigcup{(f, g) \in \mathcal{E}} \mathcal{C}_{k-1}(g) & if k \geq 1
\end{array}\right.
] - 计算方式:反向BFS(从字符串常量出发,向上追踪调用者至3 hop);
- 输出:函数-可贡献日志片段索引(为后续日志匹配提供依据)。
3.2 阶段2:日志模板提取(结构化处理海量日志)
核心目标:将 billions 级原始日志转化为少量可分析的日志模板,避免重复计算。
- 步骤1:粗聚类:按日志元数据(源文件路径+行号)分组,确保同组日志来自同一打印语句;
- 步骤2:模板化:采用Drain3算法解析每组日志,分离静态文本(可追踪至代码)与动态参数(如ID、时间,不可追踪);
- 步骤3:去重优化:维护历史日志模板-路径库,仅处理新模板,减少冗余计算。
3.3 阶段3:错误传播追踪(LLM-guided迭代重建)
核心目标:基于静态分析结果,用LLM解决路径歧义与跨服务/异步调用断裂问题。
- 步骤1:候选函数筛选
- 解析日志模板的静态文本片段(如“receive package %d from source %s”→[“receive package”,“from source”]);
- 匹配规则:函数若含至少一个与所有片段匹配的字符串,则列为候选;
- 输出:候选函数索引(函数ID→文件路径+完整源代码)。
- 步骤2:LLM代理推理(基于ReAct框架,模拟SRE诊断流程)
- 工具集:
- view_callee_closure(f):查询函数f的传递闭包Cₖ(f),快速筛选潜在上游函数;
- check_function_code(f):获取函数f的源代码,分析控制流与错误包装逻辑;
- fuzzy_search_in_closure(keyword):模糊搜索关键词,解决跨服务/RPC调用路径断裂(如解析RPC字符串参数定位目标函数);
- 迭代流程:
- 起点:从日志打印函数fₙ开始(日志元数据提供精准定位);
- 推理:LLM代理调用工具,分析fₙ的上游调用函数,结合日志语义(如“webhook拒绝”对应写操作)消歧;
- 扩展:将确定的上游函数fₙ₋₁加入BFS队列,重复推理;
- 终止:找到错误源函数f₁或队列空,输出完整路径。
- 工具集:
4. 评估:生产环境验证(字节跳动平台)
4.1 评估设计
- 数据集特征(生产级):
- 覆盖67个微服务(Go语言,共988k行代码);
- 原始日志:300万+条错误日志,经Drain3解析为257个模板,最终筛选102个真实错误;
- 路径复杂度:92.2%的错误需多hop追踪,20.6%的错误路径≥3 hop(分布如下):
错误传播hops 0 hop 1 hop 2 hop 3 hop 4 hop 5 hop ≥6 hop 案例数量 42 31 14 8 4 2 1 - ground truth:由事后故障报告和工程师手动代码分析验证。
- 基线方法:
方法类型 具体方法 核心逻辑 静态分析 增强版静态分析 集成可观测平台调用数据,用流敏感intra-procedural指针分析剪枝无效路径 LLM-based Internal Agent 字节内部通用SWE代理,ReAct框架,无专项错误追踪优化 LLM-based CoReQA RAG模式,单轮检索相关函数,一次性提示LLM生成路径 LLM-based Pure LLM 输入完整微服务代码,无筛选/迭代,单轮生成路径(测试LLM raw能力) - 评估指标:
- 有效性:准确率(预测路径与ground truth完全匹配的比例),静态分析用Precision(正确函数占候选函数的比例);
- 效率:推理时间(单条日志模板的路径重建平均时间)。
4.2 评估结果
- 有效性结果(关键数据见表):
方法 0 hop 1 hop 2 hop 3 hop ≥4 hop 总准确率/精度 ErrorPrism 100% 100% 95.2% 100% 85.7% 97.0% 静态分析 100% 90.4% 98.8% 72.9% 66.1% 90.7%(精度) Internal Agent 100% 87.1% 90.5% 84.6% 57.1% 87.1% CoReQA 75% 67.7% 54.8% 53.8% 14.3% 57.4% Pure LLM 100% 64.5% 45.2% 30.8% 0% 50.5% - 关键结论:ErrorPrism在所有hop长度下表现最优,尤其在长路径(≥4 hop)上优势显著(85.7% vs 静态分析66.1%);静态分析提供有效候选但无法消歧,LLM代理是消歧核心。
- 效率结果:
- ErrorPrism平均推理时间5.93s,比Internal Agent(49.75s)快8.4倍;
- 长尾原因:长路径错误的静态分析剪枝效果差,需更多LLM迭代;
- 对比:Pure LLM和CoReQA无长尾但准确率低(单轮设计无法补充上下文)。
5. 生产案例研究
- 故障场景:控制平面告警,错误日志“resource belongs to: failed to split resourceID of access policy: invalid resourceID: Delete-123-456-cluster-prod-west-a”;
- 手动分析难点:错误跨接口调用(r.BelongTo有20+实现)和异步通道(Go channel),根因为splitResourceID函数硬编码分割规则(无法处理含连字符的集群ID);
- ErrorPrism表现:LLM代理通过①语义匹配(“access policy”→AccessPolicy接口实现)、②追踪err变量跨通道流动,自动重建完整路径,精准定位根因函数,替代工程师数小时的手动分析。
6. 局限与核心贡献
- 局限:
- 代码仓库范围需人工权衡(过宽影响效率,过窄漏关键代码);
- 仅支持Go类显式错误返回语言,暂不支持Java等异常机制语言;
- 核心贡献:
- 首次形式化“错误混淆”问题,明确微服务错误追踪的关键挑战;
- 设计ErrorPrism混合架构,结合静态分析的结构精度与LLM的语义推理能力;
- 在字节跳动生产环境验证(102个错误,97%准确率),证明工具实用性。
4. 关键问题
问题1:ErrorPrism解决“错误混淆”的核心逻辑是什么?其与传统静态分析、纯LLM方法的本质区别在哪里?
答案:ErrorPrism通过“静态分析缩减空间+LLM代理语义消歧”的协同逻辑解决错误混淆:①静态分析阶段:构建函数调用图、提取错误字符串并计算传递闭包,将日志片段精准映射到候选函数,把搜索空间从“全量代码”压缩至“数十个候选函数”,避免纯LLM的盲目推理;②LLM代理阶段:基于ReAct框架调用工具(如查看函数代码、模糊搜索),分析控制流(如区分读写操作)、错误包装逻辑(如fmt.Errorf的%w用法)和日志语义(如“webhook拒绝”对应写操作),解决静态分析无法处理的路径歧义与跨服务/异步调用断裂问题。
本质区别:传统静态分析缺乏语义理解,只能提供候选路径无法消歧;纯LLM(如Pure LLM)面对海量代码时推理混乱,准确率仅50.5%;ErrorPrism的混合架构兼具“静态分析的高效筛选”与“LLM的精准消歧”,实现“效率+准确率”双优。
问题2:ErrorPrism的评估数据集为何强调“生产级”特征?这些特征对评估结果的可信度有何影响?
答案:评估数据集的“生产级”特征体现在三方面:①规模真实:覆盖字节跳动67个真实生产微服务(非实验室模拟),代码量达988k行(Go语言),匹配工业界微服务复杂度;②错误真实:从300万+原始日志中筛选102个真实错误,每个错误的ground truth经事后故障报告和工程师手动代码分析验证(避免人工构造错误的偏差);③场景全面:92.2%的错误需多hop追踪,20.6%的错误路径≥3 hop,涵盖跨接口、异步通道、RPC调用等工业界常见难点。
这些特征确保评估结果的“落地可信度”:ErrorPrism在复杂生产环境中达97%准确率,证明其不是“实验室玩具”,而是能解决工业界实际问题的工具;若采用小规模或模拟数据集,评估结果可能高估性能,无法反映真实部署效果。
问题3:ErrorPrism在效率上优于其他LLM-based方法(如Internal Agent)的关键原因是什么?这种效率优势是否会导致准确率损失?
答案:ErrorPrism效率优势的关键原因是静态分析预处理的“聚焦作用”:静态分析提前将海量代码筛选为小范围候选函数(仅需LLM推理数十个候选函数),而Internal Agent(字节内部通用SWE代理)采用“无差别代码探索”——需反复读取完整代码文件、分析无关函数,导致对话历史膨胀(每次LLM调用输入token量激增),平均推理时间达49.75s;ErrorPrism的LLM仅需聚焦候选函数,推理步骤少,平均时间仅5.93s(快8.4倍)。
这种效率优势不会导致准确率损失,反而提升准确率:①静态分析的聚焦作用减少无关代码对LLM的干扰,让推理更精准;②LLM代理可将节省的时间用于更深度的语义分析(如验证webhook配置文件),进一步消歧。数据显示,ErrorPrism总准确率97.0%,显著高于Internal Agent的87.1%,实现“效率与准确率”的协同提升。
总结
ErrorPrism是字节跳动针对微服务“错误混淆”问题提出的实用工具,核心是“静态分析压缩范围+LLM代理语义消歧”的混合架构。它在67个生产微服务的102个真实错误上实现了97%的准确率,平均5.93秒就能重建错误传播路径,比传统方法更准、比纯LLM方法更快,真正解决了SRE手动定位错误的痛点。目前虽只支持Go语言,但思路可扩展到其他语言,是工业界微服务可靠性管理的一个实用突破。