C++中的多线程编程及线程同步
文章目录
- 前言
- 多线程的核心价值
- C++多线程编程基础
- 线程同步机制
- 总结
前言
在当今计算领域,无论是追求极致响应速度的桌面应用、处理海量并发请求的服务器后端,还是需要实时处理数据的科学计算与游戏引擎,多线程技术已然成为提升软件性能与用户体验的核心手段。它通过“分而治之”的策略,将应用程序的任务负载分配到多个执行流中,从而最大限度地挖掘现代多核处理器的并行计算潜力,对于提高软件的流畅度、响应能力和整体执行效率具有不可替代的重要作用。
本文旨在系统地介绍C++语言中的多线程编程,并给出案例。
多线程的核心价值
-
提升性能与吞吐量:在拥有多个CPU核心的系统中,单线程程序只能利用其中一个核心,造成巨大的计算资源浪费。多线程程序可以将计算密集型任务(如图像处理、数据编码、物理模拟)分解成多个子任务,并由多个线程并行执行,从而显著缩短任务总耗时,实现近乎线性的性能加速。
-
增强响应性与流畅度:在图形用户界面(GUI)应用程序中,如果将耗时操作(如文件读写、网络请求)放在主线程(通常是UI线程)中执行,会导致界面“冻结”,无法响应用户操作。通过创建后台工作线程来处理这些阻塞性任务,可以确保UI线程始终保持流畅的交互响应,从而极大提升用户体验。
-
简化异步任务模型:对于需要同时处理多个I/O操作(如网络通信、数据库访问)的服务端程序,多线程模型比传统的异步回调模型更直观、更易于理解和编码。每个连接可以分配一个独立的线程,使得代码逻辑清晰,接近于同步编程的思维方式。
C++多线程编程基础
在C++11标准之前,多线程编程严重依赖平台特定的API。C++11的引入将多线程支持纳入标准库,带来了可移植且类型安全的线程管理工具。
创建线程并启动
#include <iostream>
#include <thread>// 1. 普通函数作为线程入口
void background_task(int id) {std::cout << "线程 " << id << " 正在执行,线程ID: " << std::this_thread::get_id() << std::endl;
}// 2. Lambda表达式作为线程入口
auto lambda_task = [](const std::string& message) {std::cout << "Lambda线程: " << message << std::endl;
};int main() {// 创建并启动线程std::thread t1(background_task, 1); // 传递函数指针和参数std::thread t2(lambda_task, "Hello from Lambda!"); // 传递Lambda和参数// 等待线程完成 (重要!)t1.join(); // 主线程阻塞,直到t1执行完毕t2.join(); // 主线程阻塞,直到t2执行完毕std::cout << "主线程结束。" << std::endl;return 0;
}
输出:

线程同步机制
当多个线程需要访问共享数据或资源时,如果不加控制,就会引发数据竞争,导致程序行为不确定、崩溃或产生错误结果。线程同步机制正是为了解决这一问题而生的,有以下几种方式:
1. 互斥锁:std::mutex
互斥锁是最基本的同步原语,它保证了同一时间只有一个线程可以进入被保护的代码段(临界区)。
#include <thread>
#include <mutex>
#include <vector>
#include <iostream>std::mutex g_mutex; // 全局互斥锁
int shared_counter = 0;void increment_counter(int iterations) {for (int i = 0; i < iterations; ++i) {g_mutex.lock(); // 进入临界区前加锁++shared_counter; // 安全地修改共享数据g_mutex.unlock(); // 离开临界区后解锁}
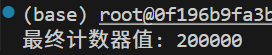
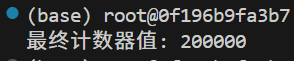
}int main() {std::thread t1(increment_counter, 100000);std::thread t2(increment_counter, 100000);t1.join();t2.join();std::cout << "最终计数器值: " << shared_counter << std::endl; // 正确输出 200000return 0;
}
输出:
这种方式可能存在的问题:直接使用lock()和unlock()容易因异常或提前返回而导致锁无法释放,造成死锁。
2. 锁守卫:std::lock_guard 和 std::unique_lock,可在一定程度上解决上述死锁问题
区别:
lock_guard是基于互斥锁std::mutex实现的,unique_lock是基于通用锁 std::unique_lock 实现。unique_lock可以实现比lock_guard更灵活的锁操作:lock_guard是不可移动的(moveable),即不能拷贝、赋值、移动,只能通过构造函数初始化和析构函数销毁,unique_lock是可移动的,可以拷贝、赋值、移动。unique_lock提供了更多的控制锁的行为,比如锁超时、不锁定、条件变量等。ORB-SLAM算法中常用这个。unique_lock比lock_guard更重,因为它有更多的功能,更多的开销。如果只需要简单的互斥保护,使用lock_guard更好。
lock_guard 案例:
#include <thread>
#include <mutex>
#include <vector>
#include <iostream>std::mutex g_mutex; // 全局互斥锁
int shared_counter = 0;void safe_increment(int iterations) {for (int i = 0; i < iterations; ++i) {std::lock_guard<std::mutex> lock(g_mutex); // 构造即加锁++shared_counter;// lock 析构时自动解锁}
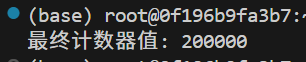
}int main() {// 使用安全的增量函数shared_counter = 0; // 重置计数器std::thread t1(safe_increment, 100000);std::thread t2(safe_increment, 100000);t1.join();t2.join();std::cout << "最终计数器值: " << shared_counter << std::endl; // 正确输出 200000return 0;
}
输出
unique_lock案例:
#include <iostream>
#include <mutex>
#include <thread>std::mutex g_mutex; // 全局互斥锁
int shared_counter = 0;void worker(int iterations)
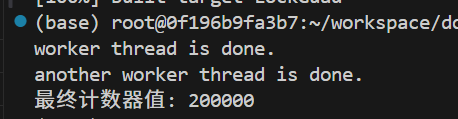
{std::lock_guard<std::mutex> lg(g_mutex); // lock_guard 方式上锁for (int i = 0; i < iterations; ++i) {++shared_counter; // 安全地修改共享数据}std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "worker thread is done." << std::endl;
} // lock_guard 不支持手动解锁,会在此自动释放锁void another_worker(int iterations)
{std::unique_lock<std::mutex> ul(g_mutex); // unique_lock 方式上锁for (int i = 0; i < iterations; ++i) {++shared_counter; // 安全地修改共享数据}std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "another worker thread is done." << std::endl;ul.unlock(); // 手动释放锁//do something...
} // 如果锁未释放,unique_lock 会在此自动释放锁int main()
{std::thread t1(worker, 100000);std::thread t2(another_worker, 100000);t1.join();t2.join();std::cout << "最终计数器值: " << shared_counter << std::endl; // 正确输出 200000return 0;
}
输出:
3. 条件变量:std::condition_variable
条件变量用于实现线程间的等待与通知机制,允许一个线程等待某个条件成立,而另一个线程在条件改变时通知等待的线程。这是实现生产者-消费者模型等协作模式的关键。
#include <queue>
#include <condition_variable>
#include <thread>
#include <mutex>
#include <iostream>std::queue<int> data_queue;
std::mutex queue_mutex;
std::condition_variable data_cond;// 生产者线程
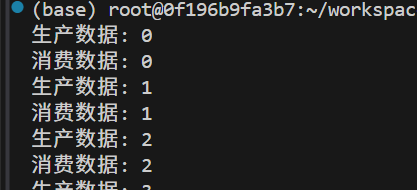
void data_producer() {for (int i = 0; i < 10; ++i) {std::this_thread::sleep_for(std::chrono::milliseconds(100));{std::lock_guard<std::mutex> lock(queue_mutex);data_queue.push(i);std::cout << "生产数据: " << i << std::endl;}data_cond.notify_one(); // 通知一个等待的消费者}
}// 消费者线程
void data_consumer() {while (true) {std::unique_lock<std::mutex> lock(queue_mutex);// 等待条件成立:队列非空。等待时会自动释放锁,被唤醒后重新获取锁。data_cond.wait(lock, []{ return !data_queue.empty(); });int data = data_queue.front();data_queue.pop();lock.unlock(); // 尽早释放锁std::cout << "消费数据: " << data << std::endl;if (data == 9) break; // 结束条件}
}int main() {std::thread producer(data_producer);std::thread consumer(data_consumer);producer.join();consumer.join();return 0;
}
输出
4. 原子操作:std::atomic
对于简单的计数器、标志位等,使用互斥锁开销过大。C++提供了std::atomic模板,能够保证对该变量的操作是不可分割的,无需显式加锁,性能极高。
#include <atomic>
#include <thread>
#include <iostream>std::atomic<int> atomic_counter(0);void atomic_increment(int iterations) {for (int i = 0; i < iterations; ++i) {++atomic_counter; // 原子操作,线程安全}
}int main() {std::thread t1(atomic_increment, 100000);std::thread t2(atomic_increment, 100000);t1.join();t2.join();// 正确输出 200000std::cout << "最终计数器值: " << atomic_counter.load() << std::endl;return 0;
}
输出
5. 异步线程std::future
std::future:提供了一种更高级的异步任务执行和结果获取方式,它抽象了线程管理的细节,让开发者更专注于任务本身。
#include <future>
#include <iostream>
#include <thread>// 模拟一个耗时的计算任务
int compute_heavy_task() {std::this_thread::sleep_for(std::chrono::seconds(2));return 42;
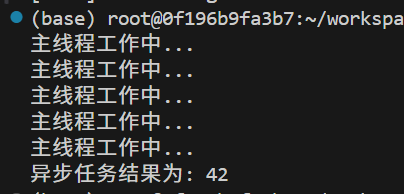
}int main() {// 异步启动任务std::future<int> result = std::async(std::launch::async, compute_heavy_task);// ... 主线程可以同时做其他工作 ...for(int i = 0; i < 5; ++i) {std::cout << "主线程工作中..." << std::endl;std::this_thread::sleep_for(std::chrono::milliseconds(500));}// 获取异步任务结果(如果需要,会阻塞等待)int value = result.get();std::cout << "异步任务结果为: " << value << std::endl;return 0;
}
总结
多线程编程是C++开发者迈向高性能应用开发的必经之路。它通过并行化极大地提升了软件的执行效率,并通过将阻塞操作移至后台显著增强了应用的流畅度。C++标准库提供了一套强大而全面的工具集,从基础的std::thread到关键的同步原语(mutex, condition_variable),再到高效的std::atomic。然而,线程引入了复杂性,尤其是数据竞争和死锁问题。成功的关键在于深刻理解并正确运用线程同步机制。