AI赋能千行百业:金融、医疗、教育、制造业的落地实践与未来展望
引言:从理论到实践,AI正重塑产业格局
人工智能(AI)已经不再是科幻小说的情节或实验室里的概念,它正以前所未有的速度和深度,渗透到社会经济的每一个角落。从优化复杂的金融交易到辅助医生进行精准诊断,从为学生提供个性化学习路径到让工厂的机器“开口说话”,AI正在成为驱动产业变革的核心引擎。本文将聚焦于金融、医疗、教育和制造业这四个关键领域,通过具体的落地案例、代码、流程图和Prompt示例,深入剖析AI技术如何解决行业痛点,创造真实价值,并展望其未来的发展趋势。
第一部分:AI + 金融 —— 重塑风险与效率的边界
金融业是数据密集型行业,天生适合AI技术的应用。AI正在重塑金融服务的核心环节,尤其是在风险控制和投资决策方面,展现出巨大的潜力。
1.1 落地案例:智能风控与实时反欺诈
行业痛点: 传统的风控模型多依赖于专家制定的规则库,难以应对日益复杂和隐蔽的欺诈手段。新型欺诈行为(如团伙欺诈、账户盗用)模式多变,规则引擎更新滞后,导致误报率高、漏报风险大。
AI解决方案: 利用机器学习模型,特别是梯度提升决策树和深度学习网络,对用户的历史交易行为、设备信息、地理位置、操作习惯等上百个维度进行实时分析。模型能够学习到正常行为的“基线”,并精准识别出偏离基线的异常模式,从而在欺诈行为发生前进行预警和拦截。
案例描述: 某大型商业银行引入了基于图神经网络(GNN)的反欺诈系统。该系统将用户、设备、IP地址、商户等抽象为图中的节点,将交易关系抽象为边。当一笔交易发生时,模型会分析其在图谱中的局部结构,例如,一个新注册的设备在短时间内与多个看似无关的账户发生交易,这很可能是一个欺诈团伙。系统能在100毫秒内完成风险评估,并自动触发二次验证或直接拦截交易,将欺诈损失降低了70%以上。
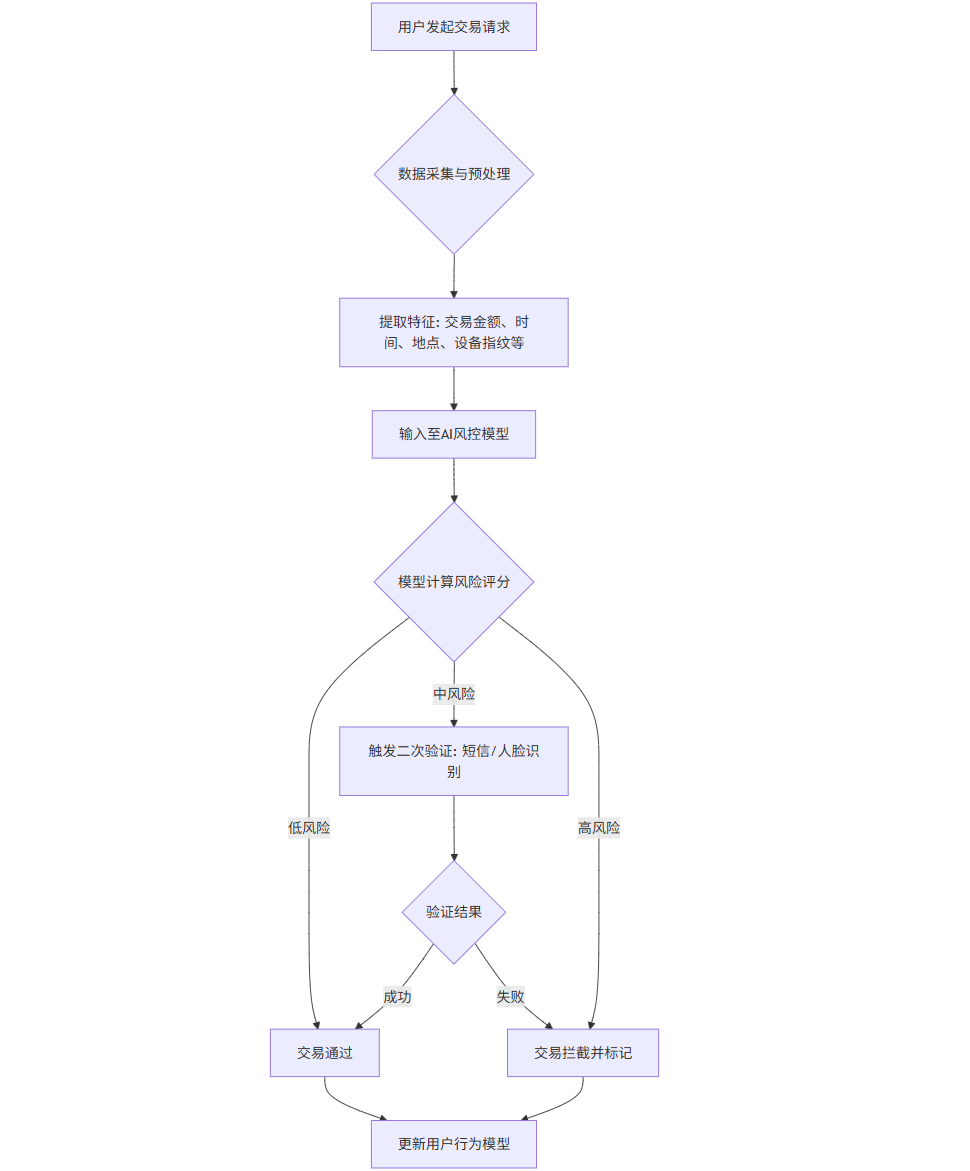
Mermaid流程图:AI实时反欺诈流程
graph TD
A[用户发起交易请求] --> B{数据采集与预处理};
B --> C[提取特征: 交易金额、时间、地点、设备指纹等];
C --> D[输入至AI风控模型];
D --> E{模型计算风险评分};
E -- 低风险 --> F[交易通过];
E -- 中风险 --> G[触发二次验证: 短信/人脸识别];
E -- 高风险 --> H[交易拦截并标记];
G --> I{验证结果};
I -- 成功 --> F;
I -- 失败 --> H;
F --> J[更新用户行为模型];
H --> J;
代码示例:使用Isolation Forest进行异常交易检测
这是一个简化的Python示例,使用scikit-learn库中的Isolation Forest算法来模拟异常交易检测。该算法适用于无监督的异常检测场景。
import numpy as np
import pandas as pd
from sklearn.ensemble import IsolationForest# 1. 模拟生成交易数据
# 假设我们有三个特征:交易金额(元), 交易时间(小时), 用户年龄
np.random.seed(42)
normal_transactions = np.random.randn(500, 3) * [100, 3, 10] + [500, 14, 35]
# 生成一些异常交易:金额特别大或时间在凌晨
anomalous_transactions = np.array([[10000, 15, 40], # 金额异常大[200, 3, 25], # 时间在凌晨[15000, 20, 50], # 金额和时间都异常[800, 2.5, 30] # 时间在凌晨
])all_transactions = np.vstack([normal_transactions, anomalous_transactions])
df = pd.DataFrame(all_transactions, columns=['Amount', 'Time', 'Age'])# 2. 训练Isolation Forest模型
# contamination参数表示数据集中异常值的预期比例
model = IsolationForest(contamination=0.01, random_state=42)
model.fit(df)# 3. 预测异常
# 预测结果: 1表示正常, -1表示异常
predictions = model.predict(df)
df['Anomaly'] = predictions# 4. 输出被检测为异常的交易
anomalies = df[df['Anomaly'] == -1]
print("检测到的异常交易:")
print(anomalies)# 在实际应用中,当新交易进来时,可以直接调用 model.predict(new_data)
# new_transaction = np.array([[12000, 16, 45]])
# print(model.predict(new_transaction)) # 输出应为 [-1]
1.2 落地案例:量化交易与智能投顾
行业痛点: 个人投资者在信息获取、分析能力和情绪控制上处于劣势,容易做出非理性决策。传统投顾服务门槛高,无法覆盖大众市场。
AI解决方案:
- 量化交易: 利用强化学习算法,让AI在模拟市场环境中自主学习最优的交易策略。AI可以处理海量的历史行情、新闻舆情、公司财报等数据,发现人眼难以察觉的微观规律。
- 智能投顾: 基于现代投资组合理论,结合用户的风险偏好、财务状况和投资目标,利用算法自动构建、管理和调整全球化的资产投资组合。
案例描述: 一家金融科技公司推出了智能投顾平台“AI财富管家”。用户首次登录时,只需回答几个关于年龄、收入、投资经验和风险承受能力的问题。AI引擎会基于这些信息,通过马科维茨模型和蒙特卡洛模拟,生成一个个性化的股债配置方案。平台还会利用NLP技术每日分析全球财经新闻,动态调整仓位,例如,当监测到市场恐慌情绪上升时,会自动增加债券等避险资产的比例。
Prompt示例:利用LLM分析市场情绪
假设我们使用一个大型语言模型(如GPT-4)来辅助分析市场新闻,以下是一个精心设计的Prompt:
# 角色
你是一位资深的金融市场分析师,擅长从海量新闻中提取关键信息并评估市场情绪。# 任务
请分析以下三条关于科技股的新闻,并完成以下任务:
1. 分别总结每条新闻的核心观点。
2. 评估每条新闻对“全球科技股市场”的整体情绪影响(正面/负面/中性),并给出1-5分的情绪强度评分(1为极度负面,5为极度正面)。
3. 综合三条新闻,给出一个对今日科技股市场的总体情绪展望,并建议投资者应采取“观望”、“谨慎买入”还是“适度减仓”的策略。# 新闻内容
[新闻1] 苹果公司发布最新季度财报,iPhone销量超出市场预期,但CEO警告称供应链瓶颈可能影响下季度生产。
[新闻2] 某国反垄断机构宣布对全球社交媒体巨头Meta展开新一轮调查,市场担忧其可能面临巨额罚款。
[新闻3] 一家AI芯片初创公司宣布获得新一轮10亿美元融资,其新一代芯片性能较上一代提升300%,引发行业轰动。# 输出格式
请使用JSON格式进行结构化输出,包含 "news_analysis" (列表) 和 "overall_outlook" (对象) 两个键。
这个Prompt通过设定角色、明确任务、提供上下文和规定输出格式,能够引导LLM生成高质量、结构化的分析报告,直接为投资决策提供参考。
图表:AI投顾与传统投顾对比
[图表:AI投顾与传统投顾多维度对比]
- 图表类型: 雷达图
- 维度: 门槛成本、个性化程度、响应速度、服务覆盖广度、情绪化影响(越低越好)。
- 数据解读:
- AI投顾: 在门槛成本、响应速度、服务覆盖广度上得分极高,在个性化程度上得分较高,在情绪化影响上得分极低(几乎为零)。
- 传统投顾: 在个性化程度上得分最高,但在其他四个维度上得分均显著低于AI投顾,尤其在门槛成本和情绪化影响上。
- 结论: 图表直观地展示了AI投顾在普惠金融和效率上的巨大优势,而传统投顾的核心价值在于深度人性化的沟通。
第二部分:AI + 医疗 —— 精准诊断与个性化治疗的革命
医疗健康是AI应用最具社会价值的领域之一。AI正在帮助医生从繁重的重复性工作中解放出来,提高诊断的准确性和效率,并加速新药研发的进程。
2.1 落地案例:医学影像智能分析
行业痛点: 放射科医生每天需要阅读大量的影像片子(如CT、MRI、X光),工作强度大,容易因视觉疲劳导致漏诊或误诊。尤其是在基层医院,经验丰富的专家资源稀缺。
AI解决方案: 基于卷积神经网络(CNN)的计算机视觉技术,可以训练出能够自动识别和标注医学影像中病灶的AI模型。这些模型经过海量标注数据的训练,其识别精度在某些特定任务上(如肺结节、糖网病筛查)已经能媲美甚至超越人类专家。
案例描述: 某三甲医院引入了“AI肺结节辅助诊断系统”。医生上传患者的胸部CT影像后,AI系统会在几秒钟内自动完成扫描,将疑似肺结节的位置用不同颜色的框标记出来,并给出结节的大小、密度、恶性概率等量化指标。医生只需对AI的标记进行复核和确认即可,将单次阅片时间从平均15分钟缩短至3分钟,同时将小于5mm的微小结节检出率提升了20%。
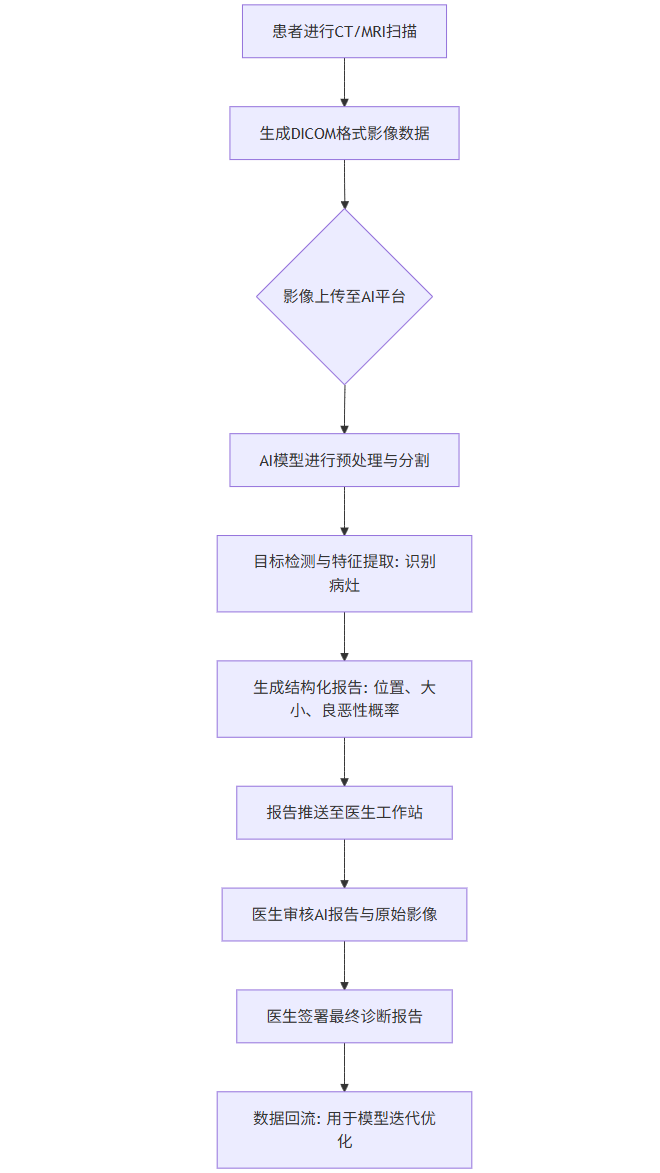
Mermaid流程图:AI辅助影像诊断流程
graph TD
A[患者进行CT/MRI扫描] --> B[生成DICOM格式影像数据];
B --> C{影像上传至AI平台};
C --> D[AI模型进行预处理与分割];
D --> E[目标检测与特征提取: 识别病灶];
E --> F[生成结构化报告: 位置、大小、良恶性概率];
F --> G[报告推送至医生工作站];
G --> H[医生审核AI报告与原始影像];
H --> I[医生签署最终诊断报告];
I --> J[数据回流: 用于模型迭代优化];
图片描述:AI辅助诊断界面
[图片:AI辅助肺结节诊断系统界面截图]
- 画面内容: 屏幕分为左右两部分。左侧是原始的胸部CT横断面影像,右侧是AI分析后的界面。右侧上方列出患者信息,中间是一个3D重建的肺部模型,上面用红色高亮标记了所有检测到的结节。下方是一个表格,详细列出了每个结节的编号、位置坐标、直径、平均CT值以及AI评估的恶性风险百分比(例如,Nodule-03: 85% Risk)。医生可以点击表格中的任何一项,左侧的原始影像会自动定位到对应的切片层面。
代码示例:使用Keras构建简单的图像分类模型
这是一个用于医学影像分类的简化CNN模型示例。在实际应用中,模型结构会更复杂(如U-Net用于分割),数据量也大得多。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout# 假设我们有一个数据集,包含两类图像:'normal' 和 'pneumonia' (肺炎)
# 图像尺寸为 150x150, 3个颜色通道 (RGB)
IMG_HEIGHT = 150
IMG_WIDTH = 150
IMG_CHANNELS = 3# 1. 构建CNN模型
model = Sequential([# 输入层Conv2D(32, (3, 3), activation='relu', input_shape=(IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS)),MaxPooling2D(2, 2),# 第二个卷积-池化层Conv2D(64, (3, 3), activation='relu'),MaxPooling2D(2, 2),# 第三个卷积-池化层Conv2D(128, (3, 3), activation='relu'),MaxPooling2D(2, 2),# 展平层,将2D图像数据转换为1D向量Flatten(),# 全连接层Dense(512, activation='relu'),Dropout(0.5), # Dropout用于防止过拟合# 输出层,使用sigmoid激活函数进行二分类Dense(1, activation='sigmoid')
])# 2. 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy', # 二元交叉熵损失函数metrics=['accuracy'])# 3. 打印模型摘要
model.summary()# 接下来,你需要用ImageDataGenerator加载和预处理数据,然后调用 model.fit() 进行训练
# train_datagen = ImageDataGenerator(rescale=1./255)
# train_generator = train_datagen.flow_from_directory(...)
# model.fit(train_generator, epochs=10, ...)
2.2 落地案例:AI加速新药研发
行业痛点: 新药研发是一个周期长(平均10年以上)、成本高(平均数十亿美元)、失败率高的过程。其中,早期化合物发现和临床试验阶段是最大的瓶颈。
AI解决方案:
- 靶点发现: 利用NLP技术分析海量的科研文献、基因数据和临床数据,快速识别与疾病相关的潜在药物靶点。
- 化合物筛选与生成: 使用生成式AI模型(如GANs、VAEs)设计具有理想药理特性(如高活性、低毒性)的全新分子结构,或通过虚拟筛选从数亿级别的化合物库中快速找到候选药物。
- 预测临床试验结果: 通过机器学习模型分析患者数据,预测特定患者群体对药物的反应,从而优化临床试验设计,提高成功率。
案例描述: Google DeepMind的AlphaFold2模型通过预测蛋白质的3D结构,解决了生物学领域50年来的重大挑战,极大地加速了对疾病机理的理解和药物设计。此外,许多Biotech公司利用AI平台,在几个月内就完成了传统方法需要数年才能完成的先导化合物筛选工作。例如,Insilico Medicine利用其生成式AI平台,在不到18个月的时间内,就发现了一种治疗特发性肺纤维化的新药,并进入了临床试验阶段。
图表:传统药物研发与AI驱动研发周期对比
[图表:传统药物研发与AI驱动研发周期对比图]
- 图表类型: 甘特图或时间轴对比图。
- 内容:
- 上方时间轴(传统): 展示一个长达10-15年的流程,包括“靶点发现 (2-6年)”、“先导化合物优化 (3-6年)”、“临床前研究 (1-3年)”、“临床试验I/II/III期 (6-7年)”。每个阶段用不同颜色的长条表示,总长度很长。
- 下方时间轴(AI驱动): 展示一个显著缩短的流程,可能为5-8年。“靶点发现 (6-12个月)”、“AI化合物生成与筛选 (12-24个月)”、“优化的临床前研究 (1年)”、“精准设计的临床试验 (3-4年)”。条形图更短,且部分阶段可以并行。
- 结论: 图表清晰地展示了AI如何通过并行化和智能化,将新药研发的“死亡之谷”大大缩短,为患者带来希望。
第三部分:AI + 教育 —— 因材施教与个性化学习的未来
AI技术正在打破传统教育“一刀切”的模式,向着“因材施教”的终极理想迈进。它能够关注到每个学生的独特性,提供定制化的学习体验。
3.1 落地案例:自适应学习平台
行业痛点: 在一个班级里,学生的学习进度、知识掌握程度和认知风格各不相同。老师难以兼顾所有学生,导致“优等生吃不饱,后进生跟不上”的现象。
AI解决方案: 自适应学习平台通过AI算法持续追踪学生的学习行为(答题正确率、答题速度、求助次数等),构建每个学生的知识图谱和能力模型。系统会根据学生的实时表现,动态调整推送的学习内容、练习题难度和教学方式,确保学生始终在自己的“最近发展区”内学习。
案例描述: 某在线教育平台的K12数学产品,采用了自适应学习引擎。当一个学生在学习“一元二次方程”时,如果系统检测到他连续解错需要使用配方法的题目,就会自动推送一个关于配方法的短视频教程,并提供几道更基础的练习题进行巩固。如果学生轻松掌握,系统则会跳过当前章节,直接进入更具挑战性的“韦达定理”应用。这种模式让学习效率提升了约30%。
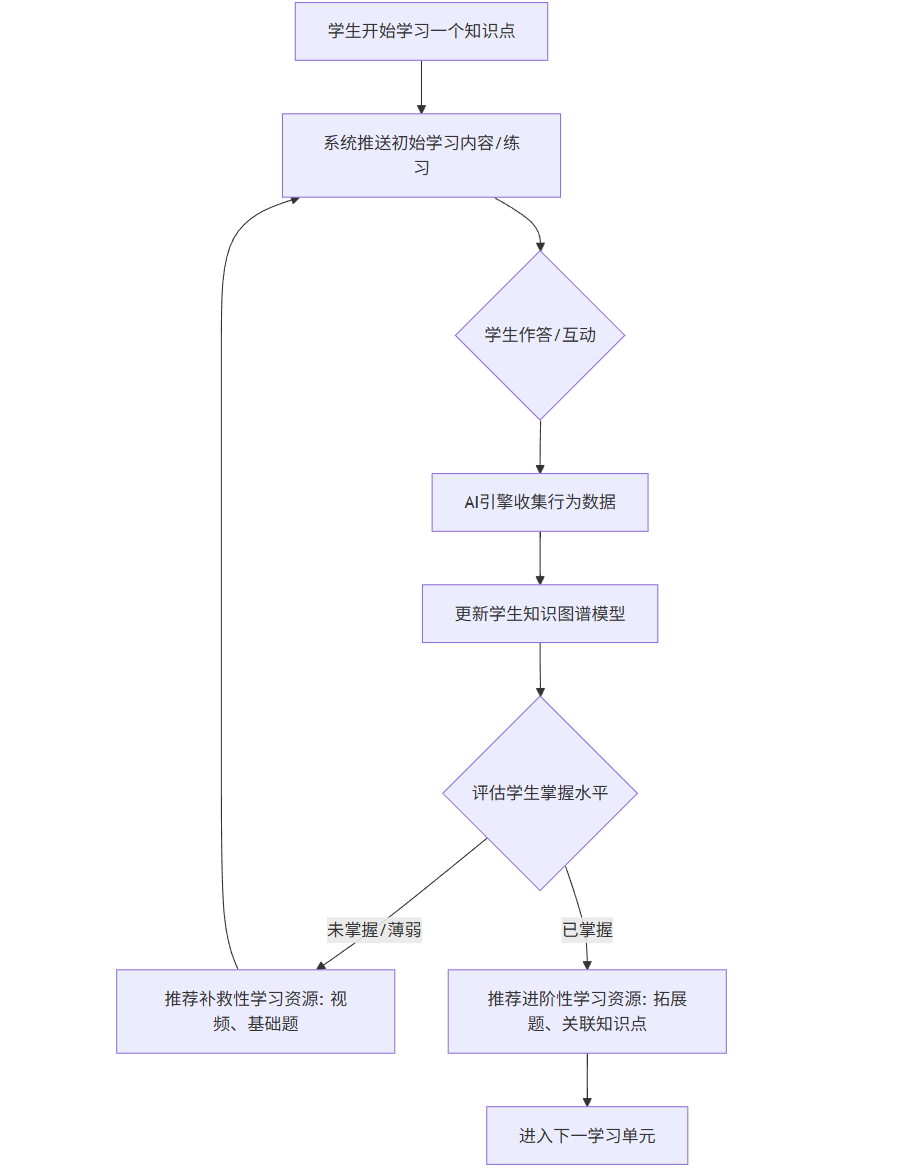
Mermaid流程图:自适应学习循环
graph TD
A[学生开始学习一个知识点] --> B[系统推送初始学习内容/练习];
B --> C{学生作答/互动};
C --> D[AI引擎收集行为数据];
D --> E[更新学生知识图谱模型];
E --> F{评估学生掌握水平};
F -- 未掌握/薄弱 --> G[推荐补救性学习资源: 视频、基础题];
F -- 已掌握 --> H[推荐进阶性学习资源: 拓展题、关联知识点];
G --> B;
H --> I[进入下一学习单元];
代码示例:简单的学习路径推荐逻辑
这是一个用Python伪代码表示的自适应学习推荐逻辑。
# 模拟学生知识状态,值为0-1,代表掌握程度
student_knowledge_state = {"linear_equations": 0.9, # 已掌握"quadratic_equations": 0.4, # 未掌握"geometry_basics": 0.7 # 基本掌握
}def recommend_next_topic(current_topic, mastery_level):"""根据当前主题和掌握程度,推荐下一个学习内容"""print(f"当前主题: {current_topic}, 掌握度: {mastery_level:.2f}")if mastery_level < 0.6:# 掌握度低,推荐巩固练习print(f"-> 建议:继续学习 '{current_topic}' 的基础概念和练习。")return current_topicelse:# 掌握度高,推荐下一个关联主题if current_topic == "linear_equations":next_topic = "quadratic_equations"elif current_topic == "quadratic_equations":next_topic = "geometry_basics"else:next_topic = "advanced_algebra"print(f"-> 恭喜!已掌握 '{current_topic}',建议开始学习新主题: '{next_topic}'")return next_topic# 模拟学习过程
current = "quadratic_equations"
mastery = student_knowledge_state[current]# AI推荐下一步
next_step = recommend_next_topic(current, mastery)# 假设学生经过学习,掌握了二次方程
student_knowledge_state["quadratic_equations"] = 0.85
print("\n--- 学习后 ---")
mastery_after_study = student_knowledge_state[next_step]
recommend_next_topic(next_step, mastery_after_study)
3.2 落地案例:AI助教与内容生成
行业痛点: 教师需要花费大量时间批改作业、回答重复性问题、备课和制作课件,这些重复性劳动占用了他们与学生进行深度互动的时间。
AI解决方案:
- AI助教: 基于大型语言模型的智能问答机器人,可以7x24小时回答学生在学习平台上的各种问题,从“这个公式怎么推导”到“帮我检查一下这段代码的bug”。
- 内容生成: AI可以根据教师提供的教学大纲,自动生成教案、课件、练习题、阅读材料甚至模拟试卷,极大地减轻了教师的备课负担。
案例描述: 某高校引入了AI助教“小思老师”。学生在课程论坛上提问后,“小思老师”能在几秒内给出详尽的解答,并附上相关的知识点链接。它还能自动批改客观题作业,并对主观题给出初步的评分和修改建议。教师从每天上百条重复性问答中解放出来,可以专注于组织课堂讨论和进行项目式教学。
Prompt示例:让AI生成个性化教案
这是一个给LLM的Prompt,用于为不同水平的学生生成一份关于“光合作用”的教案。
# 角色
你是一位经验丰富的生物学教师,擅长将复杂的知识用生动、易懂的方式传授给不同年龄段的学生。# 任务
请为以下两种不同水平的学生,分别设计一份关于“光合作用”的45分钟教案。# 学生画像
1. **水平A:初中生 (13-15岁)*** 特点:对生物有好奇心,但缺乏化学基础知识。需要大量比喻和视觉化元素。* 目标:理解光合作用的基本概念、原料、产物和场所。2. **水平B:高中生 (16-18岁)*** 特点:已具备化学基础,了解基本的化学反应式。能够进行更深层次的思考。* 目标:掌握光合作用的光反应和暗反应两个阶段的具体过程,理解其能量转换和物质转换的本质。# 输出要求
请为每个学生画像提供一份结构化的教案,包含以下部分:
- **教学目标:** (3-5条)
- **教学重点与难点:**
- **教学过程:** (包含导入、新课讲授、互动环节、小结,并注明每个环节的大致时间)
- **板书设计/PPT要点:** (列出关键点)
- **课后作业:** (1-2道思考题)请使用Markdown格式,并用清晰的标题区分两个版本的教案。
这个Prompt通过提供丰富的上下文(角色、任务、学生画像)和明确的输出结构,能够引导LLM生成高质量、高度定制化的教学内容,真正实现“因材施教”的辅助。
第四部分:AI + 制造业 —— 驱动工业4.0的智能引擎
制造业是国民经济的支柱,AI正在推动其从“自动化”向“智能化”转型,实现提质、增效、降本、减存。
4.1 落地案例:预测性维护
行业痛点: 传统的设备维护方式是“坏了再修”(事后维修)或“定期检修”(预防性维修)。前者会导致意外停机,造成巨大生产损失;后者则可能造成过度维修,浪费资源。
AI解决方案: 在设备上安装大量传感器(振动、温度、声音、电流等),实时收集设备运行数据。利用机器学习模型(如LSTM、随机森林)分析这些时间序列数据,学习设备从正常到故障前的微妙变化模式,从而提前数天甚至数周预测到潜在的故障,并发出预警。
案例描述: 某汽车制造厂的冲压车间,对核心设备——大型压力机实施了预测性维护。AI系统通过分析设备电机的电流和振动数据,成功预测到一台压力机的轴承将在未来两周内出现磨损。工厂利用周末计划停机时间,仅花费2小时就更换了轴承,避免了一次可能导致整个生产线停摆数天的突发故障,挽回了数百万元的损失。
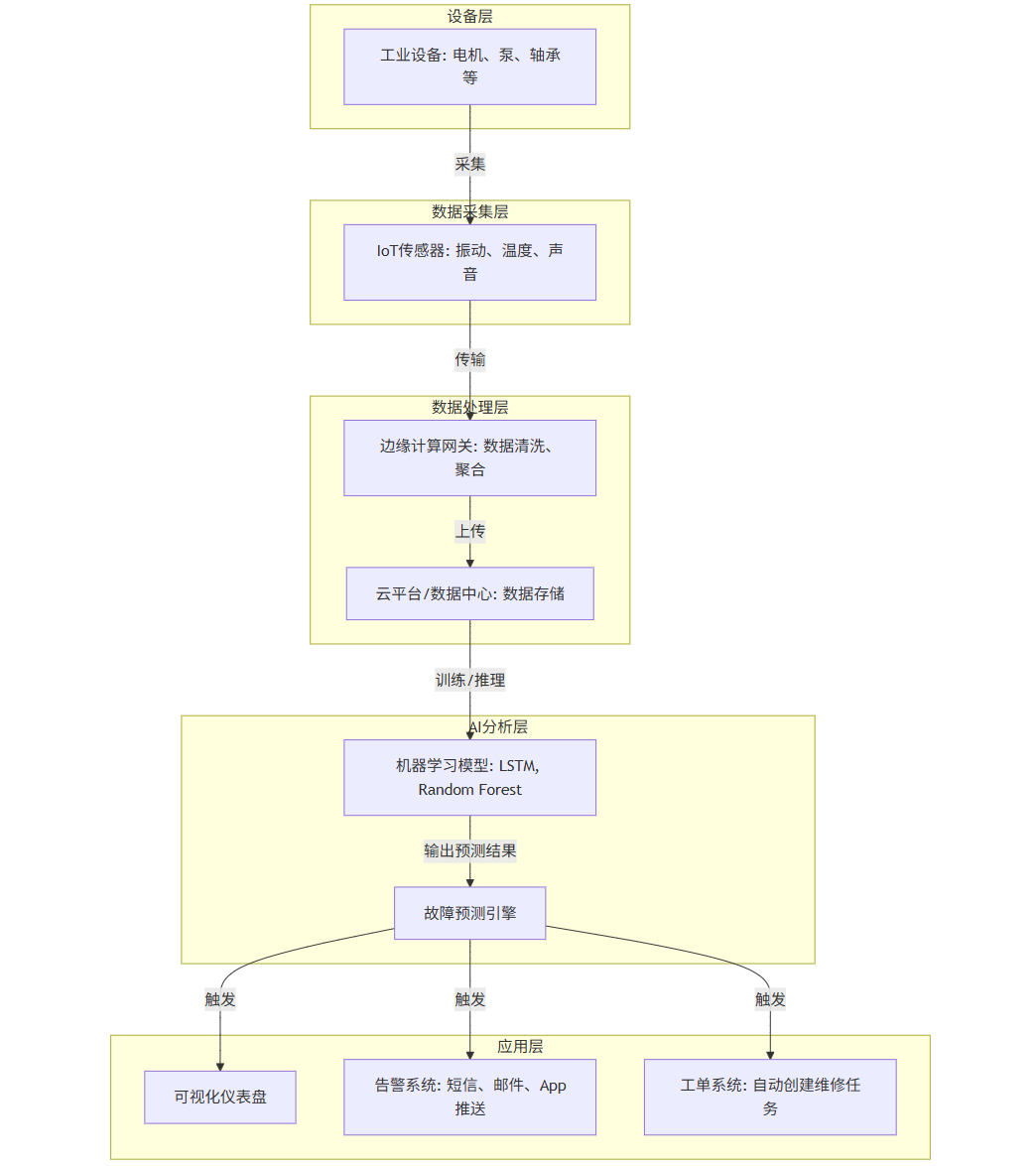
Mermaid流程图:预测性维护系统架构
graph TD
subgraph 设备层
A[工业设备: 电机、泵、轴承等]
end
subgraph 数据采集层
B[IoT传感器: 振动、温度、声音]
end
subgraph 数据处理层
C[边缘计算网关: 数据清洗、聚合]
D[云平台/数据中心: 数据存储]
end
subgraph AI分析层
E[机器学习模型: LSTM, Random Forest]
F[故障预测引擎]
end
subgraph 应用层
G[可视化仪表盘]
H[告警系统: 短信、邮件、App推送]
I[工单系统: 自动创建维修任务]
end
A -- 采集 --> B
B -- 传输 --> C
C -- 上传 --> D
D -- 训练/推理 --> E
E -- 输出预测结果 --> F
F -- 触发 --> G
F -- 触发 --> H
F -- 触发 --> I
代码示例:使用LSTM进行时间序列故障预测
这是一个使用Keras的LSTM网络来预测设备未来状态的简化示例。
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense# 1. 模拟生成传感器时间序列数据
# 假设我们有1000个时间步的数据,每个时间步有1个特征(如振动值)
np.random.seed(42)
t = np.linspace(0, 100, 1000)
# 正常运行的振动数据
normal_data = np.sin(t) + np.random.normal(0, 0.1, 1000)
# 故障前的振动数据(振幅增大)
fault_data = np.sin(t) * 3 + np.random.normal(0, 0.2, 1000)
full_data = np.concatenate([normal_data, fault_data])# 2. 数据预处理:创建时间序列样本
def create_dataset(data, look_back=60):X, Y = [], []for i in range(len(data) - look_back - 1):X.append(data[i:(i + look_back)])# 预测未来10个时间步的平均值是否超过阈值Y.append(1 if np.mean(data[i + look_back : i + look_back + 10]) > 1.5 else 0)return np.array(X), np.array(Y)look_back = 60
X, y = create_dataset(full_data, look_back)
X = np.reshape(X, (X.shape[0], X.shape[1], 1)) # LSTM需要的3D输入 [samples, timesteps, features]# 3. 构建LSTM模型
model = Sequential([LSTM(50, input_shape=(look_back, 1)),Dense(1, activation='sigmoid')
])model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()# 4. 训练模型 (实际应用中需要划分训练集和测试集)
# model.fit(X, y, epochs=10, batch_size=32)# 5. 预测
# new_data = ... # 新的60个时间步的数据
# prediction = model.predict(np.reshape(new_data, (1, look_back, 1)))
# if prediction > 0.5:
# print("警告:检测到潜在故障风险!")
4.2 落地案例:AI视觉质检
行业痛点: 人工质检是制造业的常见环节,但存在速度慢、成本高、标准不一、容易疲劳等问题。对于微小、高速移动的缺陷,人眼几乎无法检测。
AI解决方案: 在生产线上架设工业相机,拍摄产品的高清图像。利用基于CNN的计算机视觉模型,对图像进行实时分析,自动检测出产品表面的划痕、污点、裂纹、印刷错误、装配缺陷等。
案例描述: 一家消费电子厂商在生产手机屏幕时,部署了AI视觉质检系统。系统由多个高分辨率相机和光源组成,能在0.5秒内完成对一块屏幕的正反面检测。AI模型能识别出直径小于0.01mm的亮点、划痕等微小瑕疵,并将不合格品自动从产线上剔除。质检效率比人工提升了20倍,漏检率从5%降低至0.1%以下。
图片描述:AI视觉质检现场
[图片:工厂生产线上的AI视觉质检系统]
- 画面内容: 一条现代化的自动化生产线。传送带上平稳地移动着金属零件。在传送带上方,一个坚固的机械臂悬挂着一个工业相机和环形光源,正对下方的零件。旁边的一个显示器上,实时显示着相机捕捉到的图像,软件界面用红色方框清晰地框出了零件表面的一个微小划痕,并标注了“Defect: Scratch”。背景中,几名工程师正在监控中央控制大屏上的数据。
结论:人机协同,共创智能新纪元
从金融的风险管理到医疗的生命守护,从教育的因材施教到制造的精益求精,AI的应用已经从概念验证走向规模化落地,成为推动社会进步的关键力量。我们看到的共同点是,AI并非要完全取代人类,而是作为一种强大的工具,增强人类的能力,将人从重复、繁琐、高风险的劳动中解放出来,去从事更具创造性、战略性和人文关怀的工作。
展望未来,随着大模型、边缘计算、物联网等技术的进一步融合,AI的应用将更加无处不在。但与此同时,我们也必须正视数据隐私、算法偏见、伦理法规和就业结构调整等挑战。唯有在技术发展与人文关怀之间找到平衡,建立负责任的AI治理体系,我们才能真正迈向一个由人机协同驱动的、更加智能、高效和公平的未来新纪元。