MybatisPlus实战:
注解在使用时的注意事项: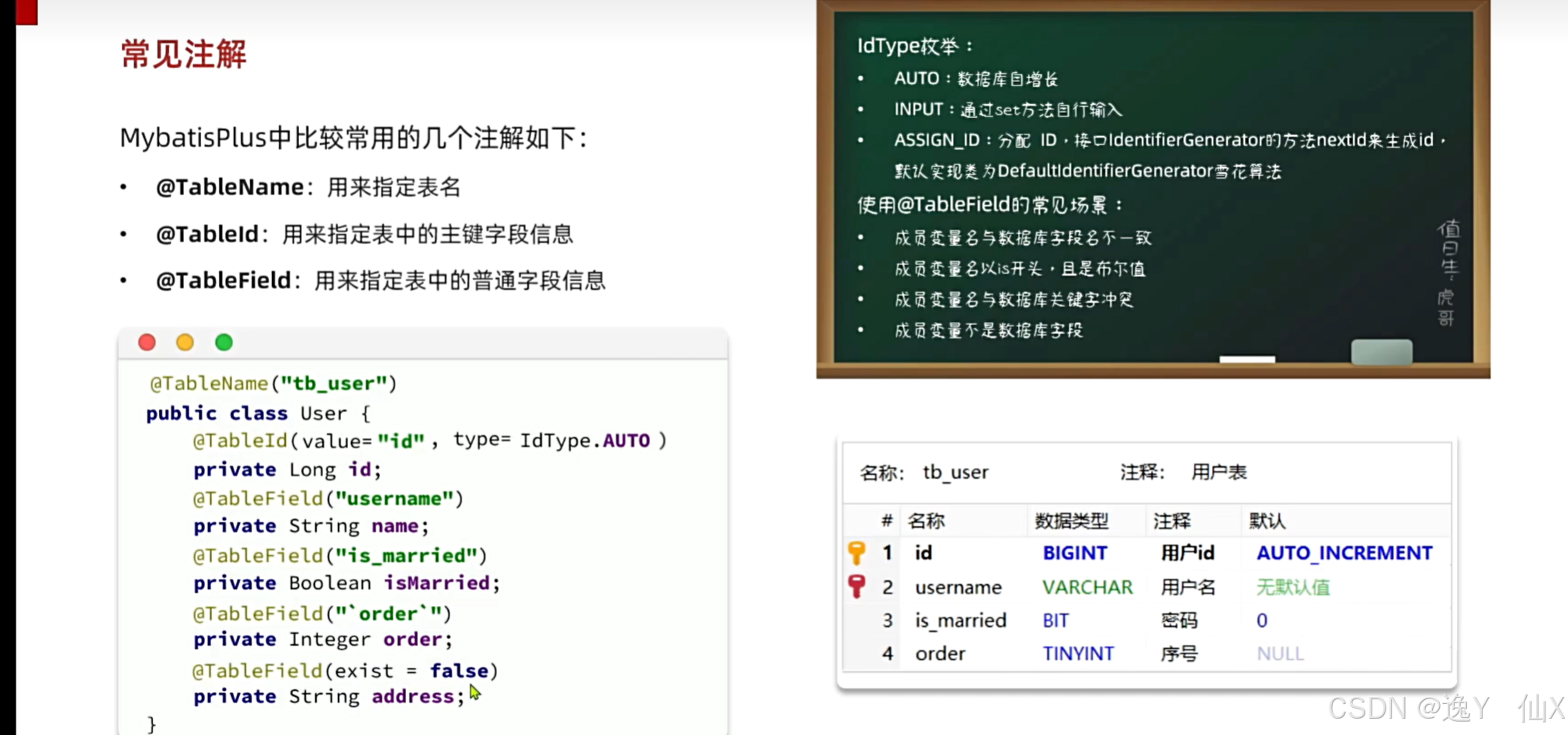
常见配置:
server:
port: 8080
spring:
datasource:
password: abc123
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
mybatis-plus:
type-aliases-package: com.hdk.entity #开启别名
mapper-locations: classpath*:/mapper/**/*.xml
configuration:
cache-enabled: true
global-config:
db-config:
id-type: auto #设置为自增,默认是雪花算法
条件构造器:(Wrapper)
常见方法截图:
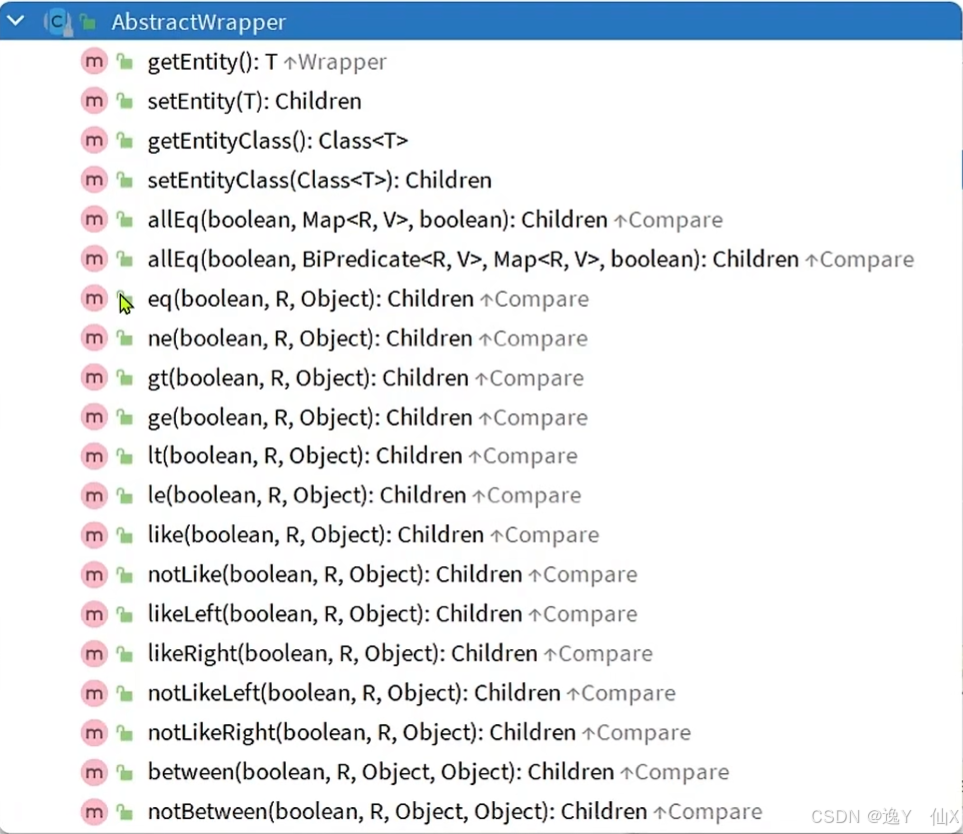
使用方法展示:
//查询名字中带有张的,他的id和name
@Test
public void test2(){
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.like("name", "张").select("id","name");
List<User> users = userMapper.selectList(userQueryWrapper);
users.forEach(System.out::println);
}
//更新张梦梦的年龄为22
@Test
public void test3(){
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name","张梦梦").set("age",22);
int success = userMapper.update(updateWrapper);
if(success>0){
System.out.println("成功");
}
}
//将id为 11,12 的人的年龄设置为12岁
@Test
public void test4(){
List<Integer> ids=new ArrayList<>();
ids.add(11);
ids.add(12);
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.in("id",ids).set("age",12);
int success = userMapper.update(updateWrapper);
if(success>0){
System.out.println("成功");
}
}展示测试LambdaQueryWrapper
//测试LambdaQueryWrapper //updataLambdaQueryWrapper同理 @Test public void test5(){ LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>(); userLambdaQueryWrapper.select(User::getId,User::getName,User::getAge).le(User::getAge,22); List<User> users=userMapper.selectList(userLambdaQueryWrapper); for (User user : users) { System.out.println(user); } }
详解条件查询的各种操作:
我们在查询时,如果不使用我们的lambda的方式查询的话,我们的字段需要自己写字段名,但是这就涉及到我们需要将所有的字段写死,违反了我们开闭原则
通过设置我们的字段,如果是空,就不适用这个字段进行查询:
@Test
public void Test3() {
String name=null; //实际开发时这个数据时我们的用户传递的,在前端返回的值
User one = userService.lambdaQuery().eq(name != null, User::getName, name).one();
}//现在是演示的我们的使用的时service,但是实际上我们可以使用的是我们的mapper里面的方式多条件查询:
小编只是展示了如何使用这种方式,在mapper和service的使用。
@Test
public void moreParam(){
String name="小牛";
Integer age=10;
//直接使用service层
List<User> one = userService.lambdaQuery().eq(User::getName, name).eq(User::getAge, age).list();
//使用mapper层:
List<User> user= mapper.selectList( new LambdaQueryWrapper<User>().eq(name!=null,User::getName,name).eq(age!=null,User::getAge,age));
}| == | eq |
| != | ne |
| > | gt |
| < | lt |
| >= | ge |
| <= | le |
| 范围查询 | between |
| 不在范围 | notBetween |
| 模糊查询 | like |
| 判空 | isNull |
| 非空 | isNotNull |
| 包含查询 | in |
| 不包含 | notIn |
| 子查询(嵌套查询) | insql |
| notInSql | |
| 分组查询: | group by |
| 聚合查询: | |
| 排序查询: | order by |
| 聚合条件筛选: | having |
等值查询:
范围查询:
@Test
public void betweentTest(){
Integer max=17;
Integer min=10;
List<User> list = userService.lambdaQuery().between(max != null && min != null, User::getAge, min, max).list();
list.forEach(System.out::println);
}@Test
public void betweentTest(){
Integer max=17;
Integer min=10;
List<User> list = userService.lambdaQuery().notBetween(max != null && min != null, User::getAge, min, max).list();
list.forEach(System.out::println);
}模糊查询:
likeLeft:左面时任何数据都可以,但是最后结尾是我们传入的值
likeRight:开头是我们的数据,右面是什么都可以
@Test
public void likeTest2(){
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.likeRight(User::getName, "用");
;
System.out.println( mapper.selectList(userLambdaQueryWrapper).size());
}inSql使用
@Test
public void INsqlTest2(){
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.inSql(User::getAge, "select age from user where age >10");
System.out.println( mapper.selectList(userLambdaQueryWrapper).size());
}分组查询:
@Test
public void testGroup(){
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.groupBy(User::getAge,User::getName).select(User::getAge,User::getName);
}聚合条件筛选having()
@Test
public void testGroup(){
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.groupBy(User::getAge,User::getName).select(User::getAge,User::getName).having("age>22");
}排序查询:
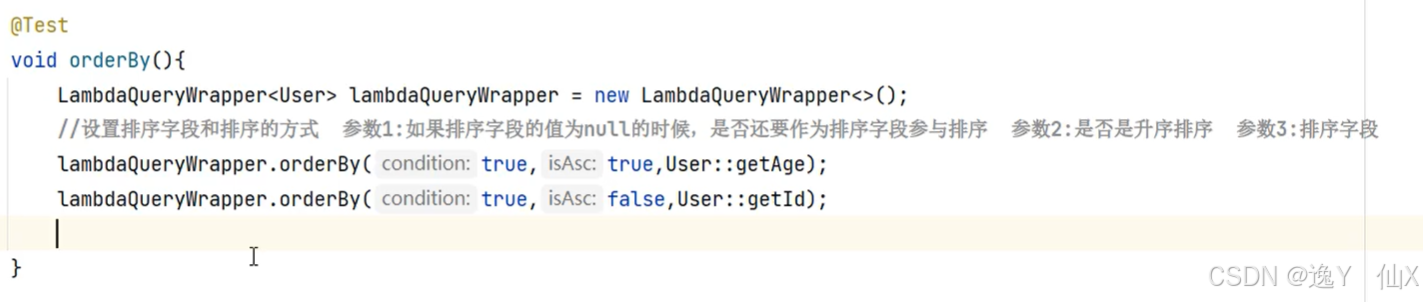
第一个参数是,如果是null是我们是否使用他进行排序。第二个是时候是升序,第三个是字段名
@Test
public void testOrder(){
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.orderBy(false,false,User::getId,User::getAge);
} 内嵌逻辑func():
内嵌逻辑func():
课程地址:065-内嵌逻辑查询-func_哔哩哔哩_bilibili
展示AND嵌套:
select * from `user` where name like '用%' and (age>20 or id <3);
//select * from `user` where name like '用%' and (age>20 or id <3);
@Test
public void test444444444444(){
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.like(false,User::getName,"用")
.and(i->i.ge(User::getAge,10).or(j->j.le(User::getId,3)));
}自定义查询apply和分页查询last
@Test
public void test5(){
LambdaQueryWrapper<User> wrapper=new LambdaQueryWrapper<>();
Integer age =null;
wrapper.ge(age!=null,User::getAge,age).last("limit 5");
List<User> list =mapper.selectList( wrapper);
list.forEach(System.out::println);
}
@Test
public void test6(){
LambdaQueryWrapper<User> wrapper=new LambdaQueryWrapper<>();
wrapper.apply("age=27");
List<User> list =mapper.selectList( wrapper);
list.forEach(System.out::println);
}尝试我们的last是不是可以放置查询条件,也就是where之内的条件:
通过下面的案例我们可以看见是不可以的,但是我们看着这个拼接的方式,是不是就可以考虑使用他来拼接我们的排序或者是分组
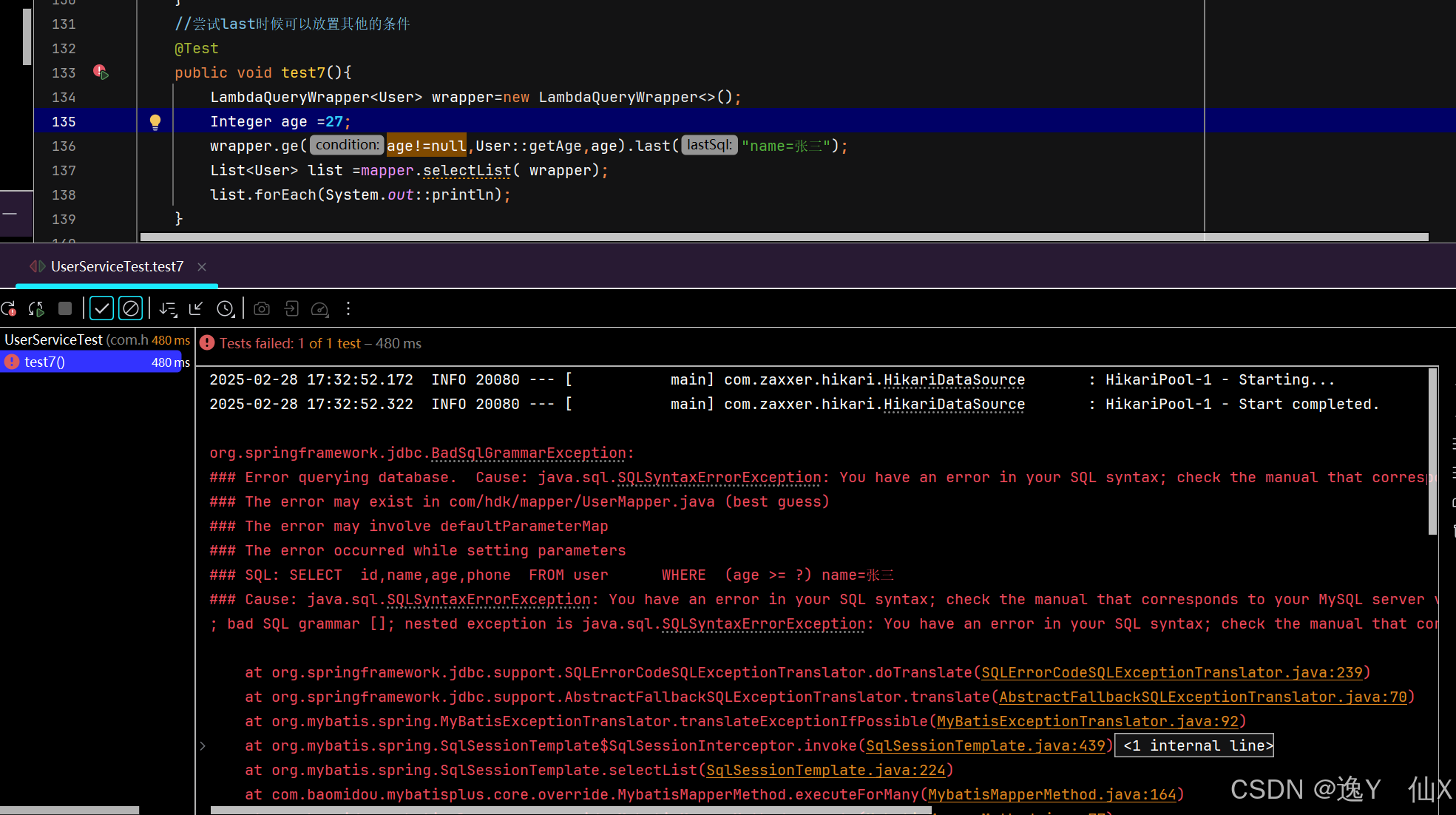
我们验证了自己的猜想,可以直接使用分组或者是排序,但是他是最后一个条件,不能在他之后再放置任何的条件了。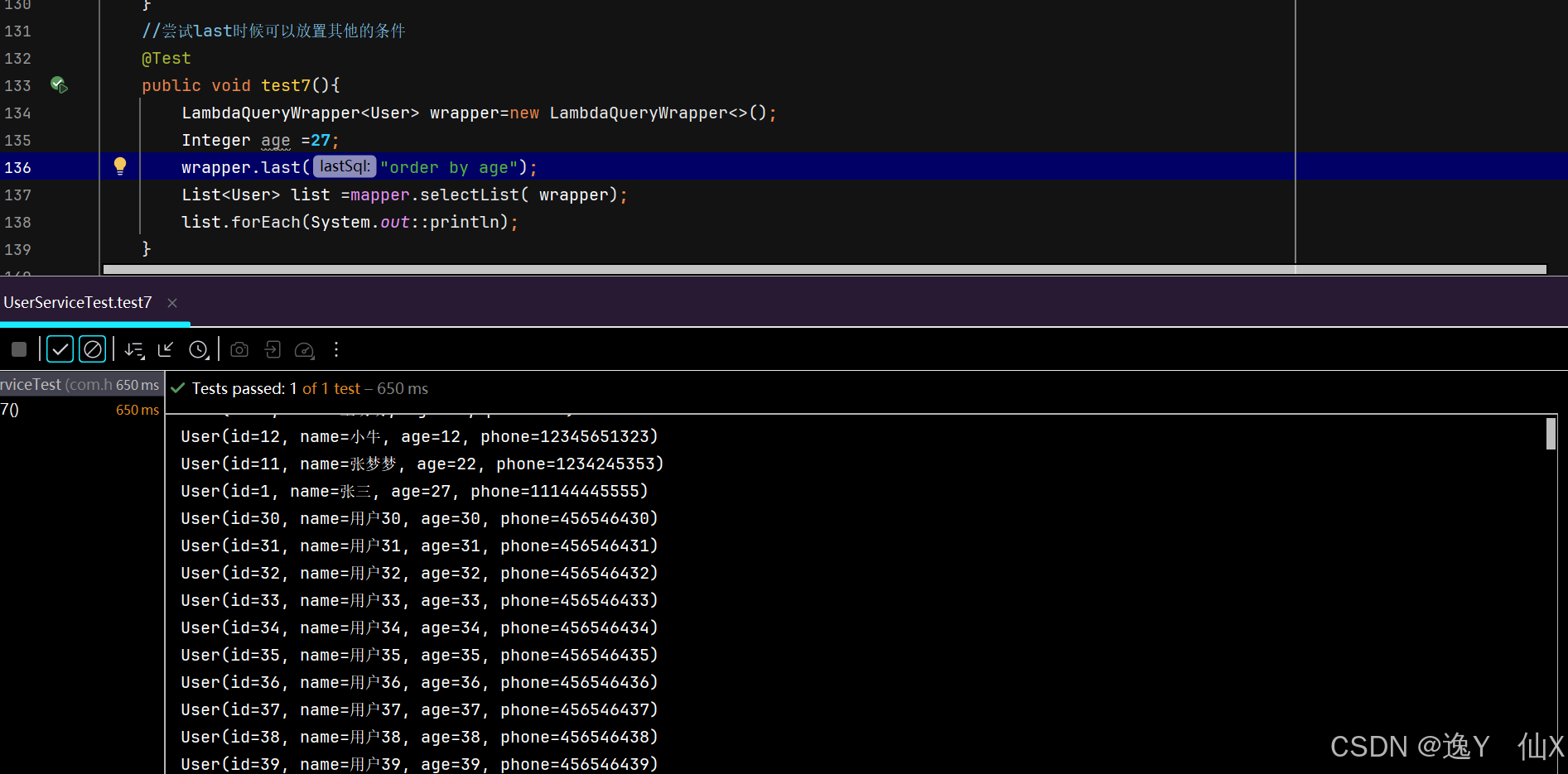
自定义SQL
假设我们现在的条件是将我们现在表中,id值为1,2,11 的人的年龄增加iint add(一个变量)岁,这样的话是不是是还是没有办法直接使用我们的mp自带的函数了,所以需要自定义SQL片段。使用的方式如下,课程地址是:06.核心功能-自定义SQL_哔哩哔哩_bilibili

基于这种动态的更新:
- 首先是创建我们的where条件,使用我们的MybatisPlus:
- 自定义Sql
//测试自定义SQL
@Test
public void test6(){
List<Integer> ids=new ArrayList<>();
ids.add(1);
ids.add(2);
ids.add(11);
//使用框架设置查询的条件
QueryWrapper<User> wrapper=new QueryWrapper<>();
wrapper.in("id",ids);
int age=10;
//使用自定义的sql
userMapper.updateAgeById(wrapper,age);
}import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.toolkit.Constants;
import com.hdk.entity.User;
import org.apache.ibatis.annotations.Param;
public interface UserMapper extends BaseMapper<User> {
/**
* 注意我们必须将他命名为ew,不然无法解析
* @param wrapper
* @param age
* @return
*/
int updateAgeById(@Param("ew") QueryWrapper<User> wrapper,@Param("age") int age);
}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.hdk.mapper.UserMapper">
<!-- ${ew.customSqlSegment} 这个的意思就是我们的where 条件使用我们的ew中自己定义的-->
<update id="updateAgeById">
update user
set age = age + #{age} ${ew.customSqlSegment}
</update>
</mapper>IService接口:
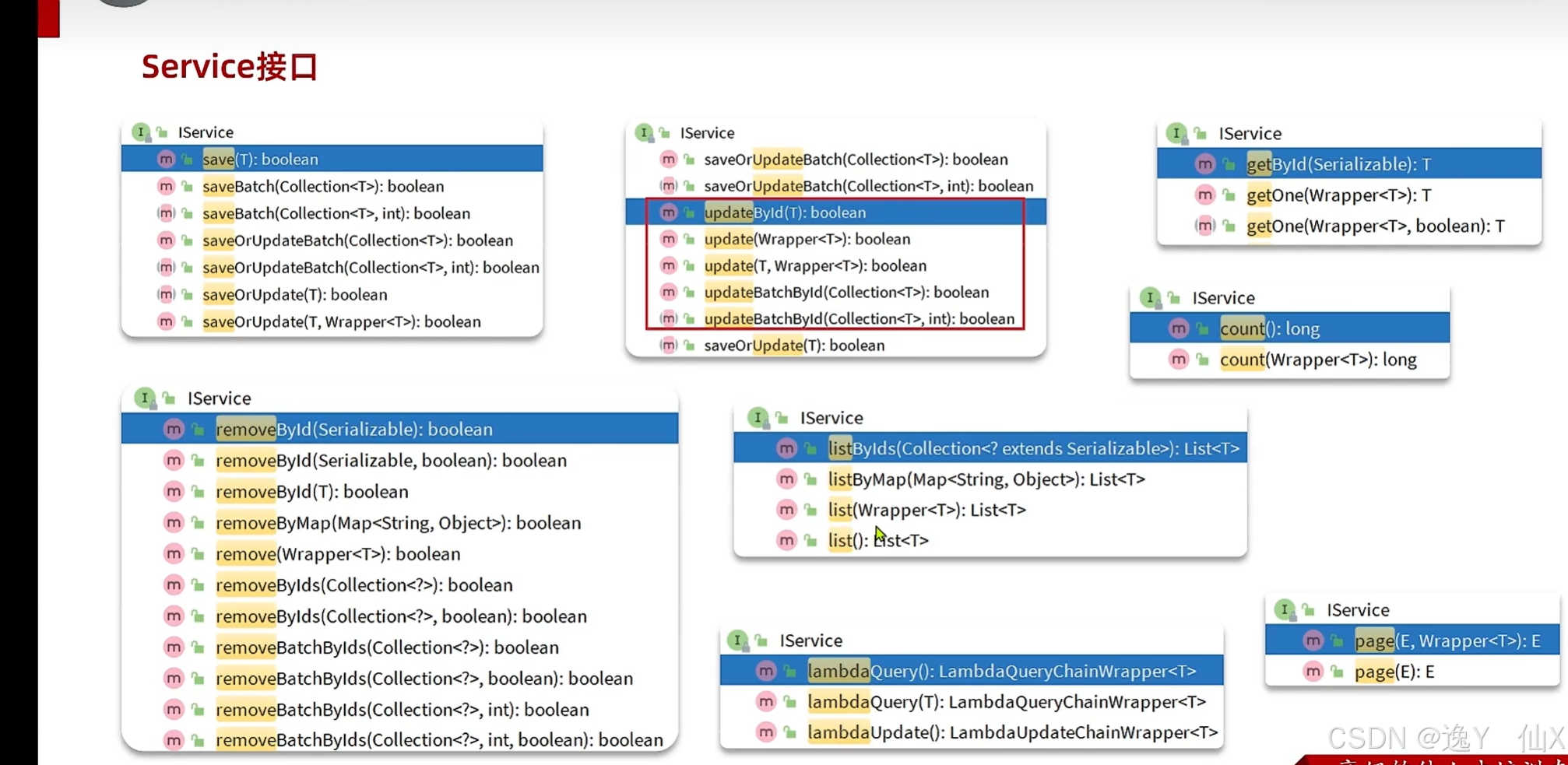
开发时的使用方式:
我们的自定义的service接口实现IService接口,我们的实现类继承ServiceImpl方法
import com.baomidou.mybatisplus.extension.service.IService;
import com.hdk.entity.User;
import org.springframework.stereotype.Service;
@Service
public interface UserService extends IService<User> {
}
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hdk.entity.User;
import com.hdk.mapper.UserMapper;
import com.hdk.service.UserService;
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
复杂更新和查找
我们直接使用Lambda方式查询”:
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hdk.entity.User;
import com.hdk.mapper.UserMapper;
import com.hdk.service.UserService;
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
public User queryUser(String name,Integer age){
//他是小写的,这是唯一注意的
User one = lambdaQuery().eq(name != null, User::getName, name).eq(age != null, User::getAge, age).one();
return one;
}
}使用lambda方式进行插入:
public Integer updateUser(String name,Integer age){
lambdaUpdate().set(name != null, User::getName, name).set(age != null, User::getAge, age).ge(User::getId,1);
return 1;在开发中我们对于对象之间的拷贝,可以使用的方式有很多,这里为大家展示一种:
/**
* 使用的是spring自带的类,但是功能不是很好,没有太好的封装
* public static void copyProperties(Object source, Object target) throws BeansException {
* copyProperties(source, target, null, (String[]) null);
* }
*/
public class Controller {
public void test(){
UserDto userDto=null;
BeanUtils.copyProperties(new User(4645,"梨花"), userDto);
}
}
批量添加:
在进行批量添加时,需要将我们的数据库的设置打开,不然的话也是默认是一条一条的添加:
逻辑删除:
我们Mybatjisplus提供了逻辑删除的功能,只需要进行一下配置就可以了,配置文件信息如下:
server:
port: 8080
spring:
datasource:
password: abc123
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
mybatis-plus:
type-aliases-package: com.hdk.entity #开启别名
mapper-locations: classpath*:/mapper/**/*.xml
configuration:
cache-enabled: true
global-config:
db-config:
id-type: auto #设置为自增,默认是雪花算法
logic-delete-field: delete #设置我们的逻辑删除字段是delete
logic-delete-value: false #设置逻辑删除的只是false
logic-not-delete-value: true #没有删除时的字段是true代码生成器:MybatisX
静态工具:
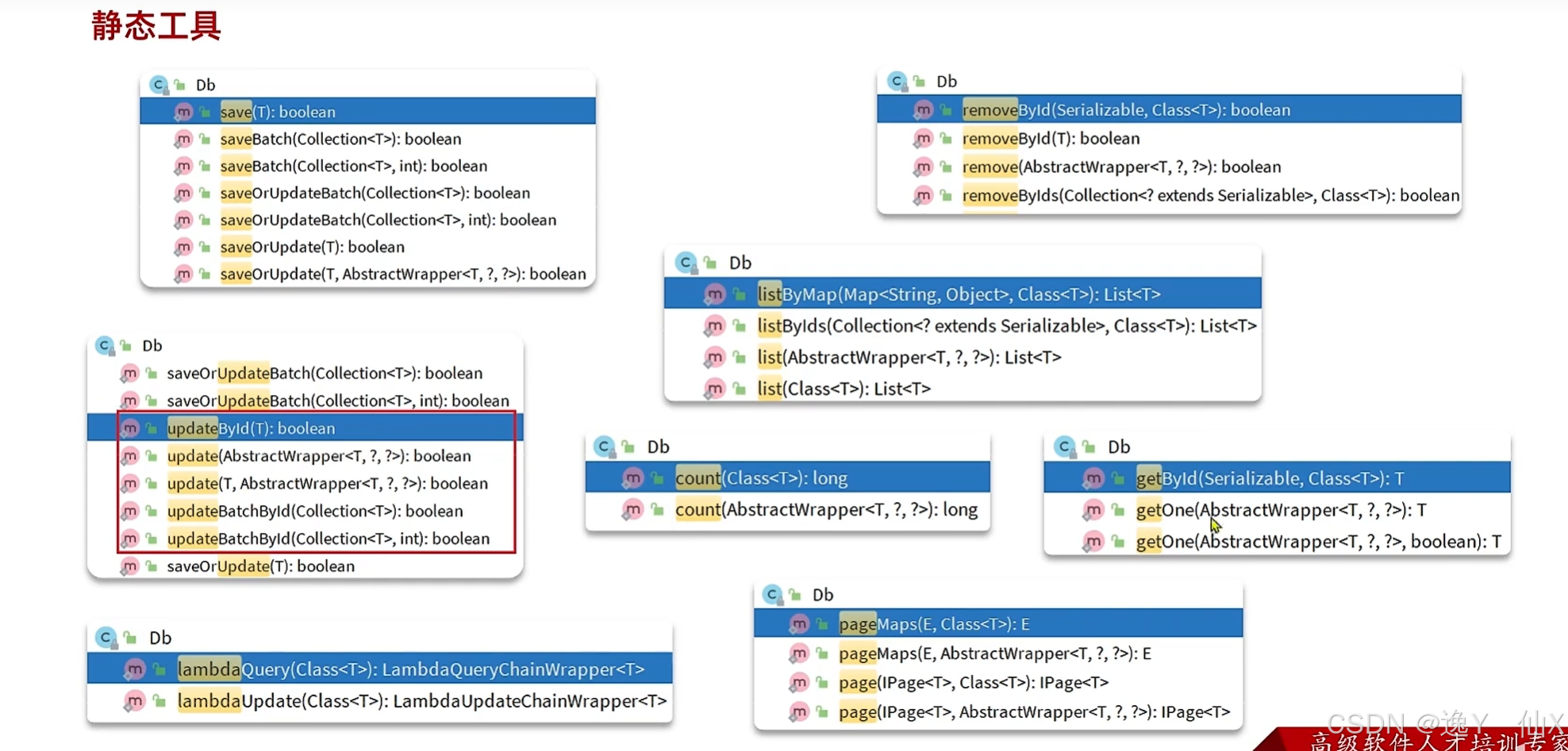
我们在实际的开发中可能会出现多个service相互注入,造成循环依赖问题,这个时候就可以使用我们的静态工具了。
假设我们在查询用户时,需要返回他的地址信息,这是我们通常会注入我们的addressService但是我们这是在查询地址时,想要返回这个地址中的人员信息,这是又选择注入我们的userService,这就会出现循环依赖,这是我们可以通过注入我们的mapper曾解决,但是mapper的功能是没有我们的service强大的,所以,我们可以使用DB这个工具类。使用方式如下:
public void testDb(){
User one = Db.lambdaQuery(User.class).eq(User::getId, 1).one();
}枚举处理器:
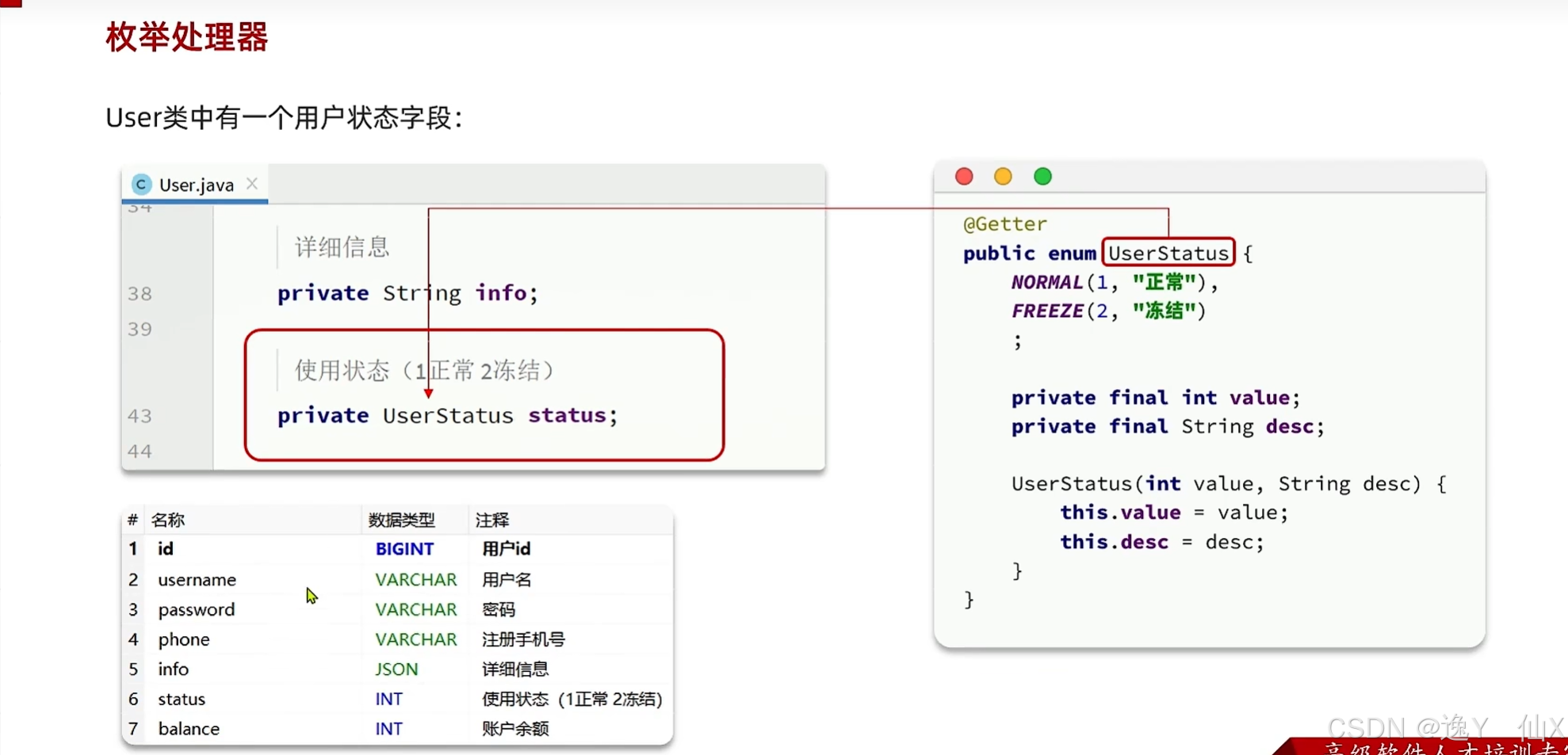
mp对于mybatis的类型处理器进行了加强,我们可以直接使用他加强的枚举处理器进行处理枚举类型的转换。
创建枚举类:
标注@Enumvalue注解,表明那个是数据库中的字段值:
@Getter
public enum UserStatus {
normal(1,"正常"),
freeze(2,"冻结");
@EnumValue
private int value;
private String desc;
UserStatus(int value, String desc) {
this.value = value;
this.desc = desc;
}
}配置枚举处理器:
server:
port: 8080
spring:
datasource:
password: abc123
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
mybatis-plus:
type-aliases-package: com.hdk.entity #开启别名
mapper-locations: classpath*:/mapper/**/*.xml
configuration:
cache-enabled: true
default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler #配置枚举处理器
global-config:
db-config:
id-type: auto #设置为自增,默认是雪花算法
Json处理器:
使用方式: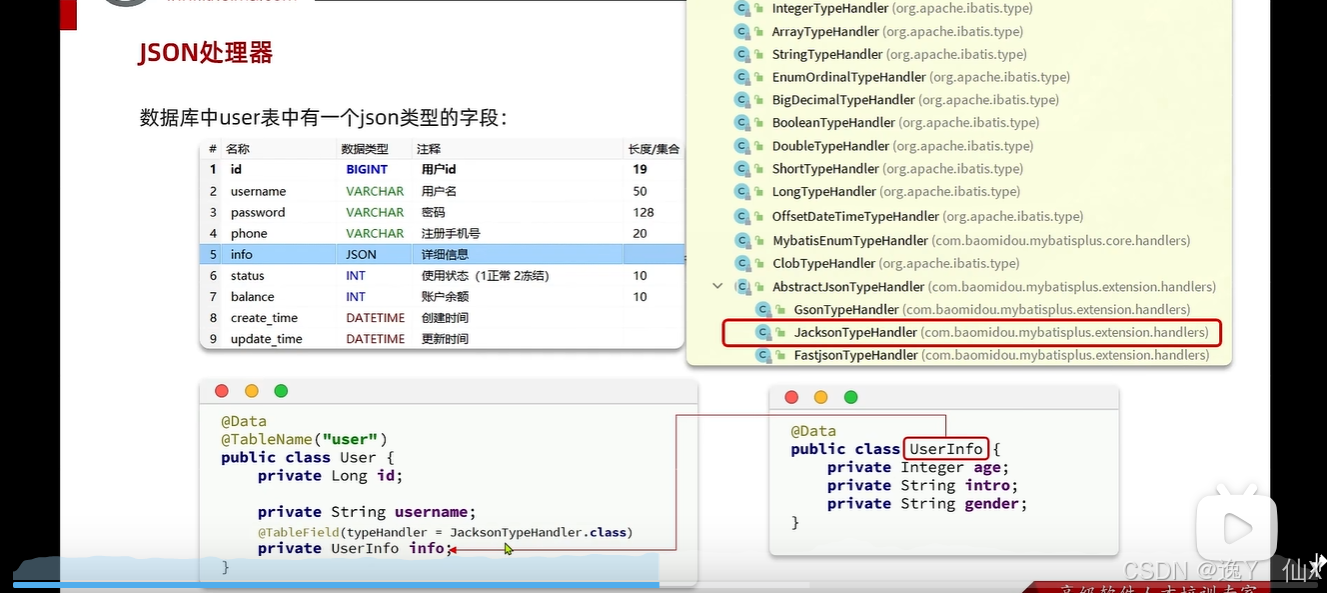
可以直接将我们数据库中的Json字段接受。
分页插件:
创建分页配置:
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusconfiguration {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
//创建mybatisplus插件类
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
//将分页常见设置,并设置数据库类型
PaginationInnerInterceptor paginationInnerInterceptor = new PaginationInnerInterceptor(DbType.MYSQL);
//设置插件
mybatisPlusInterceptor.addInnerInterceptor(paginationInnerInterceptor);
//返回结果
return mybatisPlusInterceptor;
}
}实现分页功能:
@Test
public void pageTest() {
int pageNo = 2;
int pageSize = 3;
Page<User> page = Page.of(pageNo, pageSize);
userService.page(page);
System.out.println(page.getTotal()); //共多少条数据
System.out.println(page.getPages()); //共多少页
List<User> records = page.getRecords();
records.forEach(System.out::println);
}