DeepSeek模型认识:R1V3
前言
人类思维大致可以分为两种,一种是思维发散的通用型(如文科生),另一种是思维严谨的推理型(如理科生)。类似的,Deepseek也发展演化出了不同模型。
DeepSeek-V3 和 DeepSeek-R1 是深度求索(DeepSeek)推出的两款高性能大语言模型,尽管两者均基于混合专家(MoE)架构,但在设计目标、训练方法、应用场景和性能表现上存在显著差异。以下是两者的核心区别:
一、模型定位与设计目标
1. DeepSeek-V3
- 通用型模型:专注于自然语言处理、知识问答、内容创作等通用任务,目标是实现高性能与低成本的平衡,适用于智能客服、个性化推荐系统等场景。
- 训练重点:通过算法优化降低训练成本,采用多令牌预测(MTP)和无辅助损失负载均衡策略提升效率,支持128K上下文窗口。
2. DeepSeek-R1
- 推理专用模型:专为数学、代码生成和复杂逻辑推理任务设计,通过大规模强化学习(RL)提升推理能力,对标OpenAI o1系列。
- 创新训练方法:完全摒弃监督微调(SFT),采用纯强化学
习(如GRPO算法)训练基座模型,并通过冷启动数据优化可读性。
二、训练方法与技术路
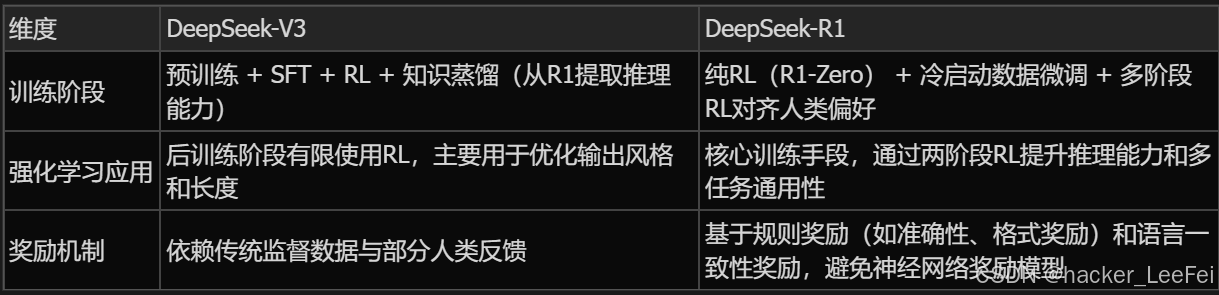
三、性能表现对比
3. 推理与数学能力
- R1在AIME 2024(79.8% vs V3的68.7%)、MATH-500(97.3% vs V3的89.4%)等数学基准测试中显著优于V3。
- R1的Codeforces Elo评分达2029,超越96.3%的人类参赛者,而V3为1950。
4. 通用任务能力
- V3在MMLU(88.5% vs R1的90.8%)、GPQA(59.1% vs R1的71.5%)等知识类评测中稍逊于R1,但在长文本生成和内容创作上更具优势。
5. 成本与效率
- V3的API成本显著更低(输入0.14/百万token,输出0.14/百万token,输出0.28/百万token),而R1成本更高(输入0.55,输出0.55,输出2.19)。
- V3的训练成本仅557.6万美元,R1未公开但推测更高。
四、应用场景与部署

五、开源生态与社区影响
1. 开源策略
- V3和R1均遵循MIT协议开源,但R1进一步开放了推理能力蒸馏至Qwen、Llama等小模型的方案,推动社区生态发展。
- R1的蒸馏模型(如32B和70B版本)性能接近OpenAI o1-mini,显著优于同类开源模型。
2. 行业影响
- V3被视为国产开源模型的标杆,证明低成本训练可达到顶尖性能。
- R1通过纯RL训练突破,被视为“推理模型的新范式”,引发AI圈对强化学习潜力的重新评估。
六、总结
DeepSeek-V3和R1分别代表了通用性能与垂直领域推理能力的极致优化。V3更适合低成本、高泛化性的场景,而R1则在数学、代码等复杂任务中表现卓越,并通过蒸馏技术赋能小模型。两者的互补性为开发者提供了灵活选择,同时推动开源社区向更高阶的推理能力迈进。