【完整源码+数据集+部署教程】 运动员动作分割系统: yolov8-seg-GFPN
背景意义
研究背景与意义
随着体育科学的不断发展,运动员的动作分析在提高运动表现、预防运动损伤和优化训练方案等方面扮演着越来越重要的角色。传统的运动员动作分析方法多依赖于人工观察和录像回放,这不仅耗时耗力,而且主观性强,容易受到观察者的经验和情绪影响。近年来,计算机视觉技术的迅猛发展为运动员动作分析提供了新的解决方案,尤其是基于深度学习的目标检测与分割技术,已经在多个领域取得了显著的成果。其中,YOLO(You Only Look Once)系列模型因其高效的实时检测能力和较高的准确性,逐渐成为运动员动作分析的重要工具。
在众多YOLO模型中,YOLOv8作为最新版本,进一步提升了目标检测和分割的性能,具有更强的特征提取能力和更快的推理速度。针对运动员动作分割的需求,基于改进YOLOv8的运动员动作分割系统的研究具有重要的理论和实践意义。该系统不仅能够实时识别运动员的动作,还能够对不同类别的运动器械进行精准分割,为运动员的动作分析提供了更加全面和细致的数据支持。
本研究所使用的数据集包含1600张图像,涵盖了四个类别:运动员(atleta)、器械(barra)、重物(discos)以及YOLO分割模块(yolo_segmentation)。这些数据的多样性和丰富性为模型的训练和测试提供了良好的基础。通过对这些图像的分析,可以深入探讨运动员在不同器械和重物下的动作表现,进而为教练员和运动员提供科学的训练建议和改进方案。
此外,基于改进YOLOv8的运动员动作分割系统不仅能够提升运动员的训练效率,还能在比赛中为运动员提供实时反馈,帮助他们及时调整动作,减少受伤风险。通过对运动员动作的精准分割与分析,教练员可以更好地理解运动员的技术动作,从而制定个性化的训练计划,提升运动员的竞技水平。
在学术研究方面,本研究的创新之处在于将YOLOv8模型应用于运动员动作分割领域,并通过改进算法提升其在复杂场景下的表现。这不仅丰富了计算机视觉在体育领域的应用研究,也为后续相关研究提供了新的思路和方法。此外,研究成果有望推动运动科学、计算机视觉和人工智能等多学科的交叉融合,促进相关领域的共同发展。
综上所述,基于改进YOLOv8的运动员动作分割系统的研究,不仅具有重要的理论价值,也具备广泛的应用前景。通过深入探讨运动员的动作特征,推动运动训练的科学化、系统化,最终实现提高运动员竞技水平和保障运动安全的目标。
图片效果
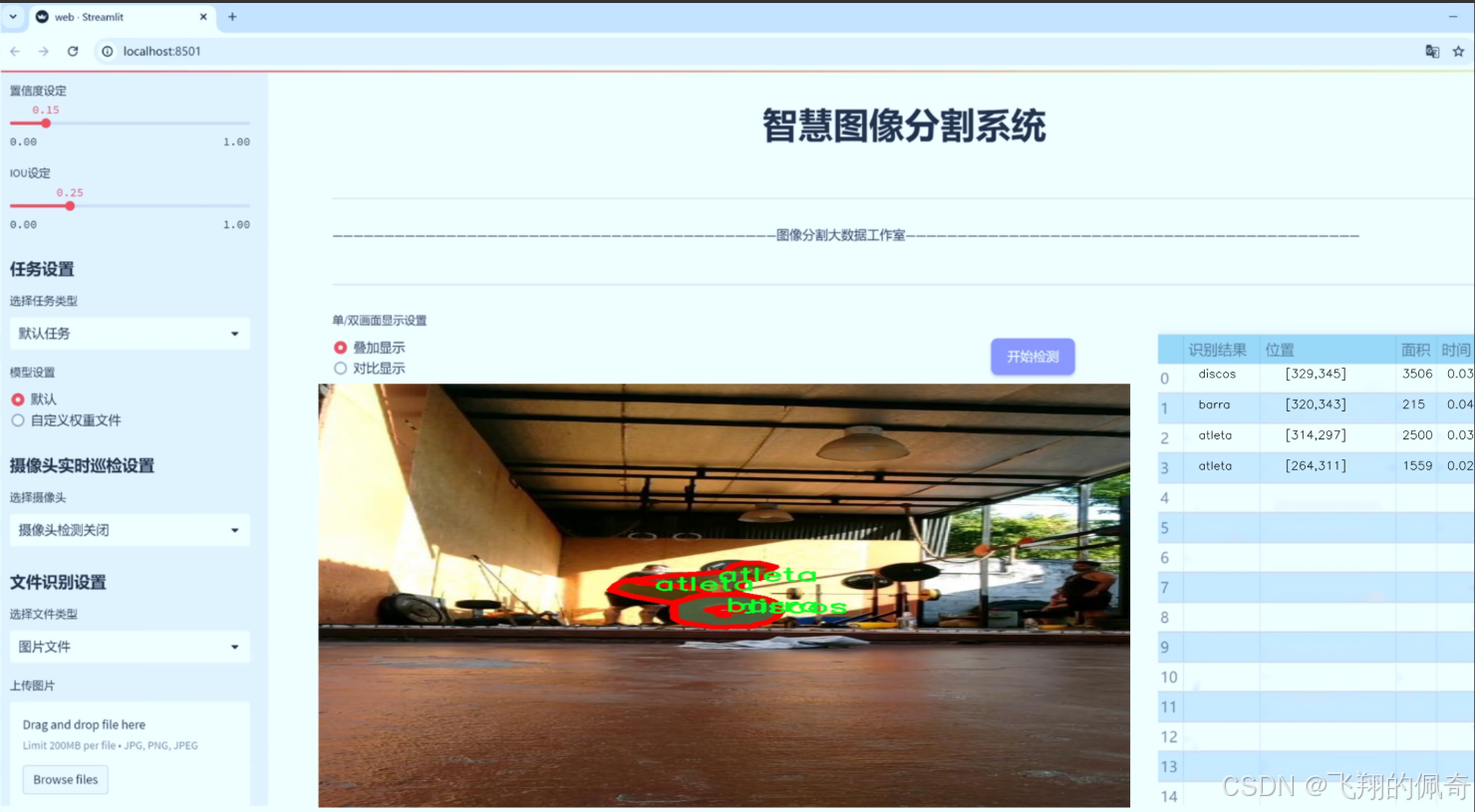
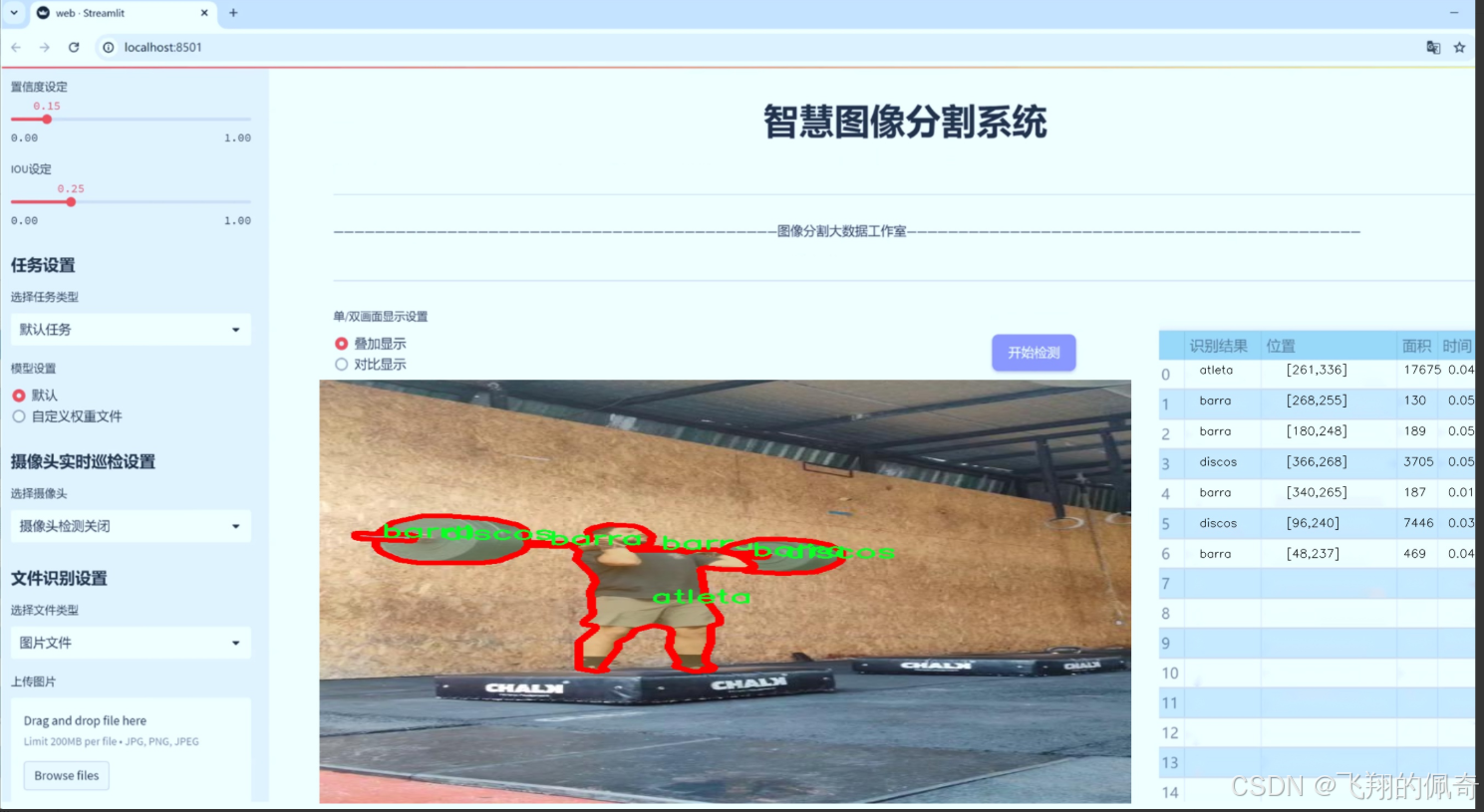
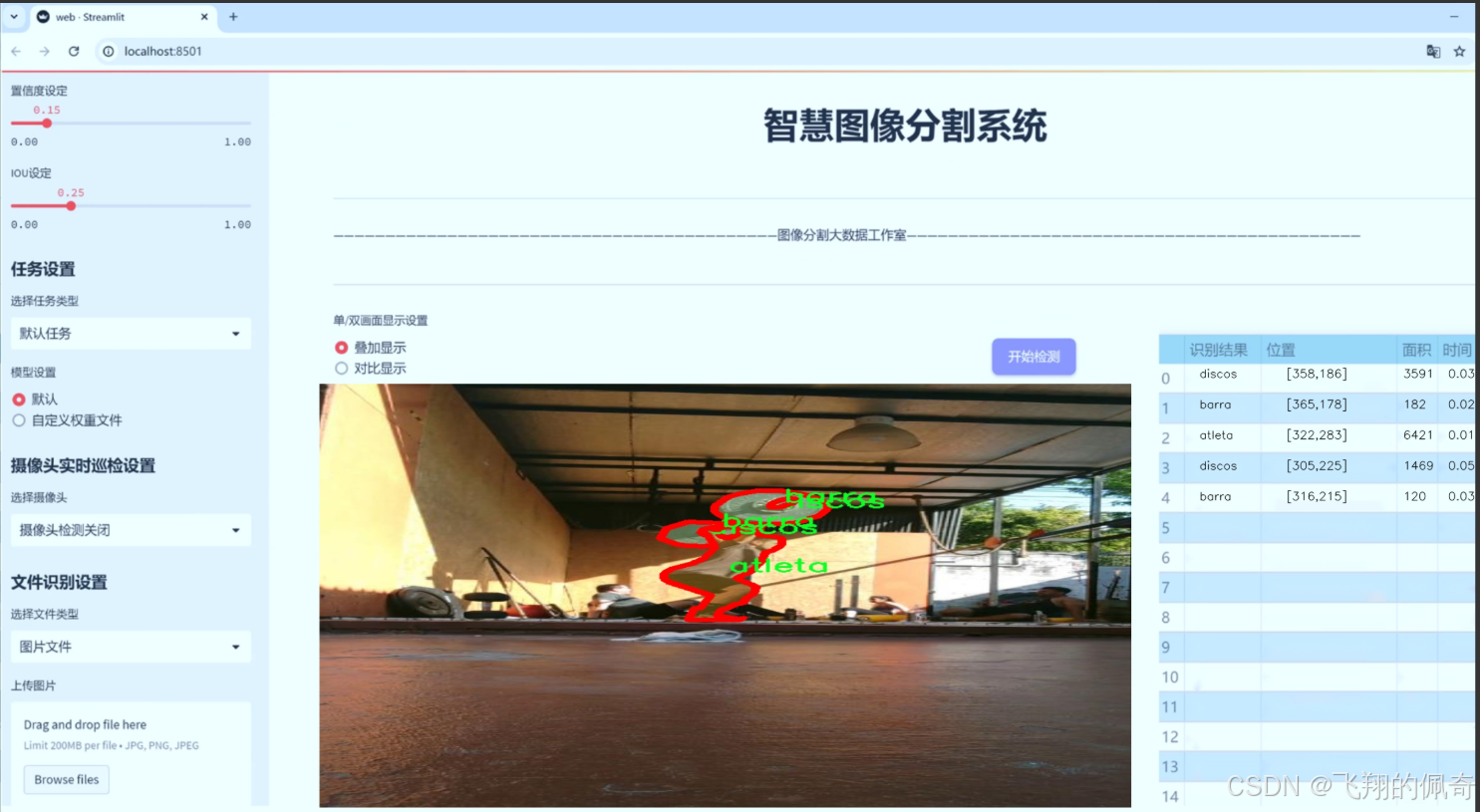
数据集信息
数据集信息展示
在本研究中,我们采用了名为“yolo_segmentation”的数据集,以训练和改进YOLOv8-seg的运动员动作分割系统。该数据集专注于运动员在进行各种训练和比赛时的动作捕捉,旨在通过高效的图像分割技术,提升对运动员动作的理解和分析能力。数据集的设计考虑到了运动员在不同环境下的表现,确保能够涵盖多种场景和条件,以便为模型提供丰富的训练样本。
“yolo_segmentation”数据集包含三种主要类别,分别是“atleta”(运动员)、“barra”(杠杆)和“discos”(圆盘)。这些类别的选择反映了运动员在训练和比赛中常见的元素,能够有效地帮助模型识别和分割运动员的动作。具体而言,“atleta”类别涵盖了各种运动员的姿态和动作,能够为模型提供多样化的运动表现样本;“barra”类别则代表了运动员在使用杠杆进行训练时的情境,强调了杠杆在运动过程中的重要性;而“discos”类别则聚焦于运动员在使用圆盘进行训练时的动态表现,展现了不同器械对运动员动作的影响。
数据集的构建过程经过精心设计,确保每个类别的样本数量均衡且多样化,以提高模型的泛化能力。通过对不同运动员在多种环境下的动作进行捕捉,数据集涵盖了从基础训练到高强度比赛的多种场景。这种多样性不仅能够帮助模型学习到运动员在不同条件下的表现,还能提高其在实际应用中的鲁棒性。
此外,数据集中的图像均经过精细标注,确保每个类别的边界清晰可辨。这种高质量的标注对于训练深度学习模型至关重要,因为它直接影响到模型的学习效果和最终的分割精度。我们采用了先进的标注工具和技术,确保每个样本的标注准确无误,进而为YOLOv8-seg模型的训练提供坚实的基础。
在训练过程中,我们将“yolo_segmentation”数据集与YOLOv8-seg模型相结合,利用其强大的特征提取和分割能力,旨在实现对运动员动作的精准识别和分割。通过对运动员动作的深入分析,我们希望能够为运动科学研究、运动员训练以及相关领域提供更为科学的依据和指导。
总之,“yolo_segmentation”数据集为改进YOLOv8-seg的运动员动作分割系统提供了丰富的训练资源。其精心设计的类别和高质量的标注,确保了模型在运动员动作识别和分割任务中的有效性和准确性。随着研究的深入,我们期待该数据集能够为运动员的训练和表现分析带来新的突破,推动运动科学的进一步发展。





核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
from pathlib import Path
import torch
from ultralytics.engine.model import Model
from ultralytics.utils.torch_utils import model_info, smart_inference_mode
from .predict import NASPredictor
from .val import NASValidator
class NAS(Model):
“”"
YOLO NAS模型用于目标检测。
该类提供YOLO-NAS模型的接口,并扩展了Ultralytics引擎中的`Model`类。
旨在通过预训练或自定义训练的YOLO-NAS模型来简化目标检测任务。
"""def __init__(self, model='yolo_nas_s.pt') -> None:"""初始化NAS模型,使用提供的模型或默认的'yolo_nas_s.pt'模型。"""# 确保模型文件不是YAML配置文件assert Path(model).suffix not in ('.yaml', '.yml'), 'YOLO-NAS模型仅支持预训练模型。'super().__init__(model, task='detect') # 调用父类构造函数@smart_inference_mode()
def _load(self, weights: str, task: str):"""加载现有的NAS模型权重,或在未提供权重时创建新的NAS模型。"""import super_gradientssuffix = Path(weights).suffix # 获取权重文件的后缀if suffix == '.pt':self.model = torch.load(weights) # 从.pt文件加载模型elif suffix == '':self.model = super_gradients.training.models.get(weights, pretrained_weights='coco') # 获取预训练模型# 标准化模型属性self.model.fuse = lambda verbose=True: self.model # 定义融合方法self.model.stride = torch.tensor([32]) # 设置步幅self.model.names = dict(enumerate(self.model._class_names)) # 设置类别名称self.model.is_fused = lambda: False # 返回是否已融合self.model.yaml = {} # 清空yaml信息self.model.pt_path = weights # 设置权重路径self.model.task = 'detect' # 设置任务类型为检测def info(self, detailed=False, verbose=True):"""记录模型信息。参数:detailed (bool): 是否显示详细信息。verbose (bool): 控制输出的详细程度。"""return model_info(self.model, detailed=detailed, verbose=verbose, imgsz=640) # 获取模型信息@property
def task_map(self):"""返回任务与相应预测器和验证器类的映射字典。"""return {'detect': {'predictor': NASPredictor, 'validator': NASValidator}} # 映射检测任务
代码说明:
导入模块:引入必要的库和模块,包括路径处理、PyTorch和Ultralytics的相关功能。
NAS类:继承自Model类,专门用于YOLO-NAS模型的目标检测。
初始化方法:确保传入的模型文件是预训练模型,并调用父类的初始化方法。
加载模型:根据权重文件的后缀加载模型,并标准化模型的属性,以便后续使用。
模型信息:提供获取模型信息的功能,可以选择详细程度和输出控制。
任务映射:定义一个属性,返回与任务相关的预测器和验证器的映射关系。
这个程序文件定义了一个名为 NAS 的类,作为 YOLO-NAS 模型的接口,主要用于对象检测任务。该类继承自 Ultralytics 引擎中的 Model 类,旨在简化使用预训练或自定义训练的 YOLO-NAS 模型进行对象检测的过程。
在文件开头,提供了一个简单的使用示例,说明如何导入 NAS 类并创建一个模型实例,随后使用该模型对图像进行预测。用户可以通过传入模型名称(如 ‘yolo_nas_s’)来初始化模型,默认情况下使用的是 ‘yolo_nas_s.pt’。
在 init 方法中,程序首先检查传入的模型路径是否以 .yaml 或 .yml 结尾,若是则抛出异常,因为 YOLO-NAS 模型只支持预训练模型,不接受 YAML 配置文件。接着,调用父类的初始化方法,并指定任务为 ‘detect’(检测)。
_load 方法用于加载模型权重。如果传入的权重文件后缀为 .pt,则直接使用 torch.load 加载模型;如果没有后缀,则通过 super_gradients 库获取预训练模型。该方法还对模型进行了一些标准化处理,例如设置模型的步幅、类别名称等属性。
info 方法用于记录和返回模型的信息,用户可以选择是否显示详细信息和控制输出的详细程度。
最后,task_map 属性返回一个字典,映射任务到相应的预测器和验证器类,这里主要是为对象检测任务提供了对应的 NASPredictor 和 NASValidator 类。
整体而言,这个文件为 YOLO-NAS 模型提供了一个结构化的接口,使得用户能够方便地加载模型、进行预测以及获取模型信息。
12.系统整体结构(节选)
整体功能和构架概括
Ultralytics 项目是一个用于目标检测和图像处理的深度学习框架,主要基于 YOLO(You Only Look Once)模型。该项目包含多个模块和工具,支持模型的训练、预测、超参数调优和对象计数等功能。每个模块的设计旨在提供清晰的接口和高效的功能,使得用户能够方便地进行模型的使用和调整。
模型预测:predict.py 提供了 YOLO 模型的预测功能,支持对输入图像进行目标检测,并对预测结果进行后处理。
超参数调优:raytune.py 集成了 Ray Tune,用于在训练过程中报告指标,以便进行超参数优化。
模型组织:init.py 负责组织和导出与 SAM 模型相关的类,简化模块的使用。
对象计数:object_counter.py 提供了一个实时对象计数的工具,允许用户通过鼠标操作定义计数区域,并在视频流中进行对象计数。
模型接口:model.py 定义了 YOLO-NAS 模型的接口,支持模型的加载、信息获取和任务映射。
文件功能整理表
文件路径 功能描述
ultralytics/models/yolo/detect/predict.py 提供 YOLO 模型的预测功能,处理输入图像并进行目标检测。
ultralytics/utils/callbacks/raytune.py 集成 Ray Tune,报告训练过程中的指标以进行超参数调优。
ultralytics/models/sam/init.py 组织和导出与 SAM 模型相关的类,简化模块的使用。
ultralytics/solutions/object_counter.py 实时对象计数工具,允许用户定义计数区域并在视频流中计数。
ultralytics/models/nas/model.py 定义 YOLO-NAS 模型的接口,支持模型加载和信息获取。
这个表格清晰地总结了每个文件的主要功能,便于理解整个项目的结构和各个模块的作用。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)......# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)......# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param)# 绘制面积、周长、圆度和色彩值metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]for idx, (metric_name, metric_value) in enumerate(metrics):......return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():ret, frame = cap.read()if not ret:break......# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:processed_image = process_frame(model, image)......# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():ret, frame = cap.read()......
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式